
Souvent, les programmeurs doivent gérer le code inconnu de quelqu'un d'autre. Cela peut être l'étude de projets open source intéressants et la nécessité de travailler - en cas de rejoindre un nouveau projet, lors de l'analyse d'une grande quantité de code hérité, etc. Je pense que chacun de vous est tombé sur cela.
Au cours d'un tel travail, j'ai toujours ressenti le besoin d'un outil spécialement conçu pour faciliter le processus d'immersion rapide dans de grands volumes de code inconnu. Au fil du temps, des idées de plus en plus intéressantes sont apparues dans différents domaines, et toutes ont nécessité l'étude de grands volumes de code d'autrui. Réseaux décentralisés, crypto-monnaies, compilateurs, systèmes d'exploitation - ce sont tous de grands projets nécessitant l'étude de quantités importantes de code. À un moment donné, j'ai décidé: il vous suffit de prendre et de fabriquer cet outil spécial. Dans cet article, je présente à votre attention ce qui en est résulté.
Qu'est-ce qui peut généralement aider à apprendre le code? Bien sûr, c'est bien quand il y a une documentation détaillée pour le code - en règle générale, il n'est pas là; un bon style de codage et les commentaires sont bons aussi, mais ce n'est généralement pas suffisant. Il existe également divers générateurs de documentation de code, tels que doxygen. En analysant la structure du code et les commentaires de documentation spéciaux, ils génèrent de la documentation sous forme d'hypertexte au format html. Le principal inconvénient d'une telle documentation est sa non-interactivité; dans le processus d'étude du code, le programmeur peut avoir une nouvelle compréhension, et afin de le refléter dans la documentation, vous devez écrire de nouveaux commentaires documentaires et régénérer à nouveau toute la documentation.
De plus, une telle documentation ne se rapporte pas directement au code dans l'environnement de développement, c'est-à-dire cliquer sur l'hyperlien n'ouvrira pas le fichier avec ce code dans l'EDI. Il existe une bonne analogie pour de tels outils, enracinés dans les temps anciens: les premiers désassembleurs étaient des outils en ligne de commande qui généraient du code sans intervention de l'utilisateur. Vint ensuite le premier désassembleur interactif ("IDA pro"), qui supposait la participation active de l'utilisateur au processus de désassemblage - attribution de noms de variables et de fonctions, définition de structures, rédaction de commentaires sur le code, etc.
L'analyse de gros volumes de code étranger dans une langue de haut niveau est à certains égards très similaire au démontage. Ainsi, j'ai commencé à développer une idée de ce que je veux exactement. La plupart des IDE ont des panneaux d'affichage de fichiers et d'affichage de classes classiques qui affichent la structure des fichiers et les espaces de nom / classe à l'intérieur. Mais cette structure est généralement étroitement liée à la syntaxe du langage et ne vous permet pas de faire une charge sémantique personnalisée. Ainsi, la première chose que je voulais avoir était la capacité interactive de construire des arbres arbitraires contenant des références de code nommées de manière significative - aux mêmes classes et fonctions, ou à des endroits arbitraires du tout. Et le second est le désir de marquer le code directement dans l'éditeur. Les marques peuvent avoir diverses significations: du simple «appris», «trié», «réécrit», au code appartenant à différents groupes sémantiques. Vous pouvez le marquer avec un commentaire, mais je voulais quelque chose de plus visible. Par exemple, des changements dans la couleur d'arrière-plan d'un morceau de code. Les séparateurs de couleurs KDPV sont donc une analogie assez précise du monde réel.
Après les premières expériences, j'ai rapidement réalisé que cela devrait être un plug-in pour l'environnement de développement moderne, et non mon propre éditeur. Travailler avec deux éditeurs en même temps est stupide et peu pratique; la perspective de répéter toutes les possibilités de l'environnement de développement n'a pas inspiré la joie, et pourquoi faire ce qui a déjà été fait? Par conséquent, le plugin. Qt Creator a été choisi comme premier IDE simplement parce que les opérations de navigation de code les plus populaires (Aller à la définition, Rechercher des références, etc.) sont effectuées aussi rapidement que possible. L'environnement suivant sera Visual Studio, puis en cas de succès du concept lui-même - implémentation pour d'autres IDE.
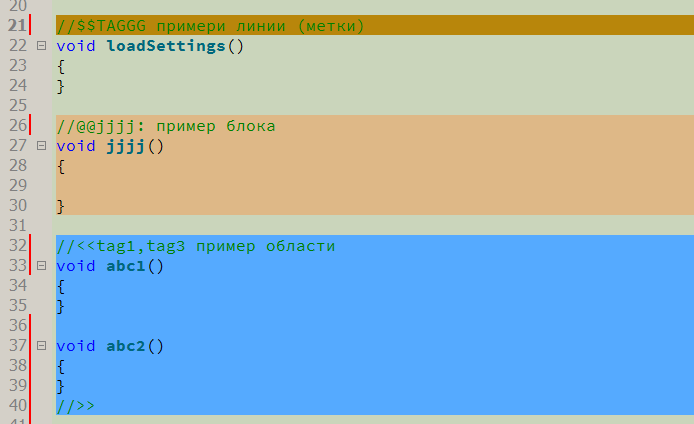
Maintenant, comment tout est arrangé. Le concept de «commentaires marqueurs» est introduit. Il s'agit d'un commentaire régulier d'un langage de programmation (pour le moment c'est un commentaire sur une seule ligne "//" utilisé dans de nombreux langages - C, C ++, C #, Java, ...), suivi d'une séquence de caractères spéciaux, suivie d'un identifiant et / ou de balises, qui peut être suivi d'un commentaire humain normal. J'ai introduit trois types de commentaires marqueurs
- Commentaire pour mettre en évidence une zone arbitraire. Le seul type nécessitant un commentaire de marqueur «close». Commence par "// <<" et se termine par "// >>".
- Commentaire pour indiquer une ligne arbitraire dans le code. Désigné par "// $$"
- Commentaire pour mettre en évidence un bloc de code syntaxiquement correct. Il commence par "// @@" et inclut le bloc de code ci-dessous, limité par des accolades "{" et "}", qui sont utilisés pour les blocs de code dans la plupart des langages de programmation de type C. Une analyse complète des accolades a été implémentée - les accolades imbriquées sont autorisées et l'analyseur ignore correctement les accolades dans les lignes et les commentaires.
De plus, immédiatement après les caractères spéciaux, un ou plusieurs identificateurs, séparés par des virgules, suivent. Les identificateurs sont des «balises» et peuvent signifier ce que le programmeur veut - des signes «étudiés», «réécrits», «comprendre», la paternité du code, la relation du code avec certains groupes sémantiques, etc. Vous pouvez également spécifier un identifiant unique - il est placé en premier et séparé du reste par deux points. Si vous le souhaitez, vous pouvez spécifier explicitement la couleur d'arrière-plan de l'extrait de code - une grille est placée à la fin de la liste des balises, après quoi la couleur au format RVB est indiquée (bien que cette méthode ne soit pas la meilleure - nous parlerons d'une autre méthode, plus "correcte" plus tard). Et à la toute fin, vous pouvez mettre un espace, puis vous pouvez écrire un commentaire régulier lisible par l'homme. J'ai essayé de choisir la syntaxe de manière à ce qu'elle soit aussi simple que possible pour une entrée rapide, n'encombrait pas le code et était pratique pour les commentaires ordinaires.
Bien que la saisie manuelle des commentaires des marqueurs soit possible, elle est censée utiliser des boutons de barre d'outils spéciaux pour cela. Le curseur est placé à la position souhaitée du code et le bouton est enfoncé (ou l'une des dernières options est sélectionnée dans le menu).
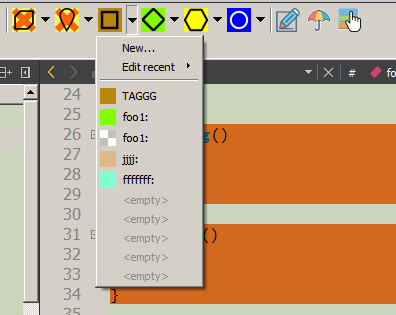
Si nécessaire, une boîte de dialogue de saisie sera ouverte où vous pourrez saisir des balises et des identificateurs de commentaires de marqueur, une description détaillée et également sélectionner une couleur d'arrière-plan. Ces données seront saisies non seulement dans le code, mais aussi dans l'arborescence «CRContentTree», affichée sur le côté dans le panneau d'arborescence (où FileView, ClassView, etc.). Il convient de noter que la couleur d'arrière-plan peut être «transparente» - dans ce cas, la couleur d'arrière-plan du bloc englobant (le cas échéant) est utilisée ou le rétro-éclairage n'est pas utilisé du tout.
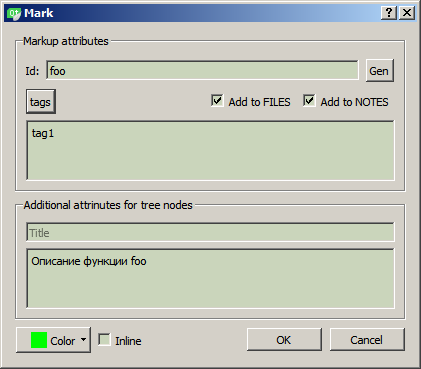
Pour le moment, l'arborescence se compose de trois parties principales (nœuds de niveau supérieur): FICHIERS, TAGS et NOTES (ce n'est peut-être pas la solution finale, car le concept n'est pas encore évident, ainsi que la commodité d'une telle structure).
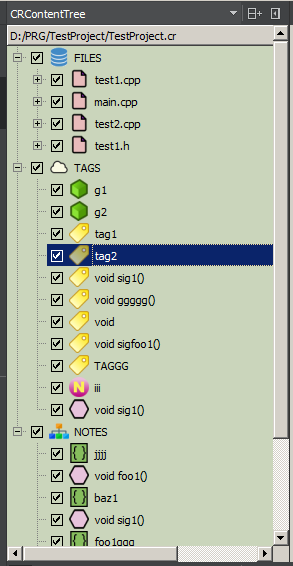
FILES est la structure de fichiers du projet, qui est extraite du fichier de projet ou de l'emplacement des sources sur le disque. Les nœuds de fichiers sont créés lors de la génération initiale de l'arborescence. Double-cliquer sur un nœud de fichier ouvre généralement le fichier dans l'éditeur IDE. Vous pouvez spécifier l'ajout de commentaires de marqueur dans FICHIERS - puis un nœud enfant apparaîtra dans le fichier correspondant. C'est là que des identificateurs de commentaire de marqueur uniques sont ajoutés. Le système vérifie l'unicité de l'identifiant au sein du nœud de fichier de l'arborescence et permet de générer automatiquement un nom unique.
TAGS est un nuage de tags de projet global; les balises ne sont pas liées au fichier de code source et peuvent apparaître dans n'importe quel fichier de projet autant de fois que vous le souhaitez.
NOTES est un endroit pour stocker des nœuds groupés de manière arbitraire et non liés à la structure du fichier. Chaque nœud contient à la fois un chemin de fichier et un identifiant. L'objectif principal est de créer des groupes logiques personnalisés. Par exemple, "toutes les fonctions qui doivent être réécrites" ou "toutes les fonctions liées à la cryptographie", ou "la séquence des fonctions de communication réseau avec le serveur" (puisque les nœuds dans l'arborescence sont ordonnés, le simple fait de placer les nœuds l'un après l'autre peut afficher n'importe quelle séquence).
Chaque nœud d'arbre a un menu contextuel. Le nœud peut être supprimé (bien que cela ne supprime pas les commentaires des marqueurs du code - tant que je ne suis pas sûr que cela soit nécessaire), vous pouvez le modifier. Vous pouvez ajouter des nœuds qui ne sont pas associés à des commentaires de marqueur: vous pouvez ajouter par exemple un lien (Link). Un double-clic sur un tel nœud ouvrira une ressource associée dans un programme associé, par exemple, un hyperlien dans un navigateur.
Chaque nœud peut être désactivé en décochant la case dans le nœud. Cela entraînera la mise en évidence de ce nœud et de tous les nœuds enfants dans le code à supprimer. Ainsi, en supprimant, par exemple, les coches des trois nœuds racine (FICHIERS, TAGS et NOTES), vous pouvez désactiver la mise en surbrillance de tous les commentaires des marqueurs, à l'exception de ceux dont la couleur est indiquée explicitement dans le code (à travers les barres).
Un double-clic sur le nœud ouvre le fichier correspondant dans l'EDI et positionne le curseur à la position de code correspondante. Pour les balises qui peuvent se produire à plusieurs reprises, au lieu d'ouvrir le fichier, une liste de toutes les occurrences est formée, qui est chargée dans le panneau de sortie CR, et en double-cliquant sur la ligne correspondante de cette liste, vous pouvez ouvrir le fichier et le positionner dans le code.
Chaque nœud possède un champ pour une description détaillée (texte multi-lignes de longueur arbitraire). Cette description est chargée dans la zone «CR Info» avec une simple sélection d'un nœud dans l'arborescence (d'un simple clic de souris), ainsi que de placer le curseur n'importe où dans la zone en surbrillance dans le code et de cliquer sur le bouton «Rechercher» de la barre d'outils. L'édition est toujours disponible, le texte modifié est enregistré automatiquement (par perte de focus). Je pense à prendre en charge le format Markdown dans ce domaine, mais jusqu'à présent, mes mains n'ont pas atteint ce point.
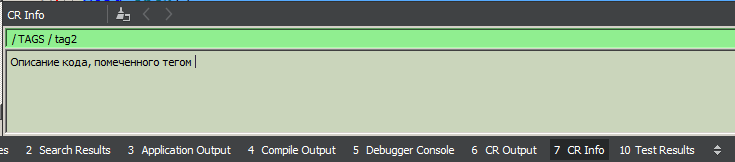
Il n'est pas toujours souhaitable (ou pas toujours pratique) d'insérer des commentaires dans le code. Par conséquent, la deuxième possibilité est les «signatures», c'est-à-dire utiliser comme marqueurs du code lui-même. Une signature est une certaine séquence de jetons (à l'exclusion des espaces et des sauts de ligne, c'est-à-dire que «foo (1,2,3)» et «foo (1, 2, 3) sont une seule et même chose). Il existe trois types de signatures:
- bloc - un bloc est mis en surbrillance, commençant par une signature et comprenant une séquence de code entre crochets.
- une seule ligne - la ligne entière avec la signature est mise en évidence
- symbolique - seule la séquence de signature est mise en évidence. Il est pratique d'utiliser ces signatures pour mettre en évidence des noms individuels - variables, fonctions, classes.
Le travail avec les blocs de signature est le même qu'avec les blocs de marqueur. De même, des nœuds dans une arborescence sont créés.
Si pour les nœuds marqueurs, l'identifiant et les balises ont été créés séparément, alors pour les nœuds de signature, il est suggéré d'indiquer exactement comment nous voulons considérer la signature - en tant qu'identifiant (attaché à un fichier) ou en tant que balise globale. Par exemple, pour les «noms», il est logique d'utiliser le mode balise - le nom correspondant sera alors mis en évidence dans le code tout au long du projet.
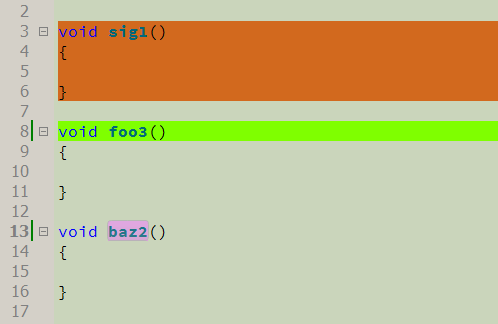
Une autre caractéristique intéressante est la construction de la couverture du code. Une fonction spéciale scanne le code et détermine les endroits qui ne sont pas marqués du tout, et forme une liste de ces endroits dans la «sortie CR». Cela ne prend pas en compte les lignes vides et les commentaires, c'est-à-dire l'analyse ne prend en compte que le code significatif. En double-cliquant sur la ligne de liste, vous pouvez vous rendre à cet endroit dans le code, et après l'avoir étudié, le marquer d'une manière ou d'une autre.
Un peu sur le format de stockage de la base de données. En fait, seuls les commentaires des marqueurs sont stockés dans le code source; le contenu de l'arborescence est stocké dans un fichier xml spécial avec l'extension ".cr". Il n'y a pas de liaison explicite du fichier de base de données aux projets, bien que lorsque vous ouvrez un projet, une tentative soit faite pour ouvrir un fichier cr avec le même nom si aucun fichier cr n'a été précédemment téléchargé.
Pour résumer. En général, j'ai implémenté presque tout ce que je voulais. Le concept est nouveau et inhabituel, et il faut donc du temps et des commentaires des utilisateurs pour comprendre ce qui doit être développé et ce qui peut être abandonné. Pour tenter de réaliser autant d'opportunités que possible, quelque chose s'est avéré être un peu trop compliqué, ce qui est inévitable. L'interface elle-même n'est peut-être pas encore établie et va changer. Mais dans l'ensemble, cela semble avoir très bien fonctionné.
Ce qui est dans les plans. Cette version est une démo, en grande partie brute et non destinée à un usage commercial. J'ai un rêve - créer mon propre produit commercial, en apportant même un revenu modeste mais régulier, suffisant pour faire d'autres projets intéressants. De plus, certaines choses ne sont pas adaptées à un usage commercial. J'imagine comment adapter un système similaire pour le mode multi-utilisateurs, en tenant compte du fait que le code peut être édité par plusieurs personnes travaillant simultanément via le système de contrôle de version. Il est également possible de regarder vers la génération d'une documentation familière (html), éventuellement des outils pour une intégration plus profonde avec le code (analyse au lieu de lexical / bracket, réception automatique des listes de classes et de méthodes et conversion en nœuds d'arbre). Bien sûr, la correction de bugs (qui sont toujours là) et l'amélioration des fonctionnalités sont nécessaires. Et bien sûr, j'attends vos commentaires avec des idées et des suggestions :)
C'est tout pour le moment (bien qu'il y ait encore quelques petites fonctionnalités que je n'ai pas mentionnées dans l'article - par exemple, j'ai jugé nécessaire d'ajouter des onglets, car sans eux, c'est vraiment triste - bien qu'il existe plusieurs plugins pour les onglets; certaines commandes Qt de base sont également affichées sur la barre d'outils Créateur non lié au plugin; etc.).
Lien de téléchargement:
https://www.dropbox.com/s/9iiw5x7elwy3tpe/CodeRainbow4.zip?dl=0Configuration requise: Windows, Qt Creator> = 4.5.1 compilé par MSVC2015 32 bits (c'est l'assemblage standard distribué sur download.qt.io)
installation: décompressez l'archive et copiez le plugin dans le dossier c: /Qt/Qt5.10.1/Tools/QtCreator/lib/qtcreator/plugins (ceci est un exemple de placement Qt standard, si vous avez Qt installé différemment ou une autre version - le chemin sera différent) et (re) lancez Qt Creator.