
Les tests de régression sont une partie très importante du travail sur la qualité des produits. Et plus il y a de produits et plus ils se développent rapidement, plus cela demande d'efforts.
Yandex a appris à faire évoluer les tâches de test manuel pour la plupart des produits avec l'aide d'évaluateurs - des employés distants travaillant à temps partiel pièce par pièce, et maintenant des centaines d'évaluateurs participent aux tests de produits Yandex, en plus des testeurs réguliers.
Ce message dit:
- Comment avez-vous réussi à rendre les tâches de test manuel aussi formalisées que possible et à former avec elles des centaines d'employés à distance;
- Comment avez-vous réussi à mettre le processus sur des rails industriels, à fournir des tests dans divers environnements, à résister au SLA en termes de vitesse et de qualité;
- Quelles difficultés ils ont rencontrées et comment elles ont été résolues (et certaines n'ont pas encore décidé);
- Quelle contribution les tests des évaluateurs ont-ils apportée au développement des produits Yandex, comment cela a-t-il affecté la fréquence des versions et le nombre de bugs passés.
Le texte est basé sur la transcription du
rapport d'
Olga Megorskaya de notre conférence de mai Heisenbug 2018 Piter:
Depuis le jour du rapport, certains chiffres ont réussi à changer, dans de tels cas, nous avons indiqué les données réelles entre parenthèses. Voici une perspective à la première personne:Aujourd'hui, nous allons parler de l'utilisation de techniques de crowdsourcing pour étendre les tâches de test manuel.
J'ai un titre de poste assez étrange: chef du département des expertises. Je vais essayer de dire avec des exemples ce que je fais. Chez Yandex, j'ai deux principaux vecteurs de responsabilité:

D'une part, tout cela est lié au crowdsourcing. Je suis responsable de notre plateforme de crowdsourcing Yandex.Tolok.
Et d'autre part, les équipes qui, si vous essayez de donner une définition universelle, peuvent être attribuées à des «postes vacants non productifs massifs». Il comprend beaucoup de choses différentes, y compris l'un de nos projets récents: les tests manuels avec l'aide de foules, que nous appelons «tests par des évaluateurs».
Ma principale activité chez Yandex est de rassembler les colonnes gauche et droite de l'image et d'essayer d'optimiser les tâches et les processus de production de masse en utilisant le crowdsourcing. Et aujourd'hui, nous allons simplement en parler en utilisant l'exemple des tâches de test.
Qu'est-ce que le crowdsourcing?
Commençons par ce qu'est le crowdsourcing. Nous pouvons dire qu'il s'agit de remplacer l'expertise d'un spécialiste spécifique par la soi-disant «sagesse de la foule» dans les cas où l'expertise d'un spécialiste est soit très coûteuse, soit difficile à mettre à l'échelle.
Le crowdsourcing est activement utilisé dans divers domaines depuis de nombreuses années. Par exemple, la NASA aime beaucoup les projets de crowdsourcing. Là, avec l'aide de la «foule», ils explorent et découvrent de nouveaux objets dans la galaxie. Cela semble être une tâche très difficile, mais avec l'aide du crowdsourcing, cela se résume à une tâche assez simple. Il existe un
site spécial sur lequel des centaines de milliers de photos prises par des télescopes spatiaux sont affichées, et ils demandent à quiconque souhaite y rechercher certains objets. Et quand beaucoup de gens trouvent étrangement similaires à l'objet dont ils ont besoin, alors des spécialistes de haut niveau sont déjà connectés et commencent à l'explorer.
D'une manière générale, le crowdsourcing est une telle méthode lorsque nous prenons une grande tâche de haut niveau et la divisons en de nombreuses sous-tâches simples et homogènes, dans lesquelles de nombreux artistes indépendants se réunissent. Chacun des interprètes peut résoudre une ou plusieurs de ces petites tâches, et tous ensemble, ils travaillent finalement pour une grande cause commune et collectent d'excellents résultats pour une tâche de haut niveau.
Crowdourcing Yandex
Nous avons déjà commencé plusieurs années à développer notre système de crowdsourcing. Initialement, il était utilisé pour des tâches liées à l'apprentissage automatique: pour collecter des données d'entraînement, pour configurer des réseaux de neurones, des algorithmes de recherche, etc.
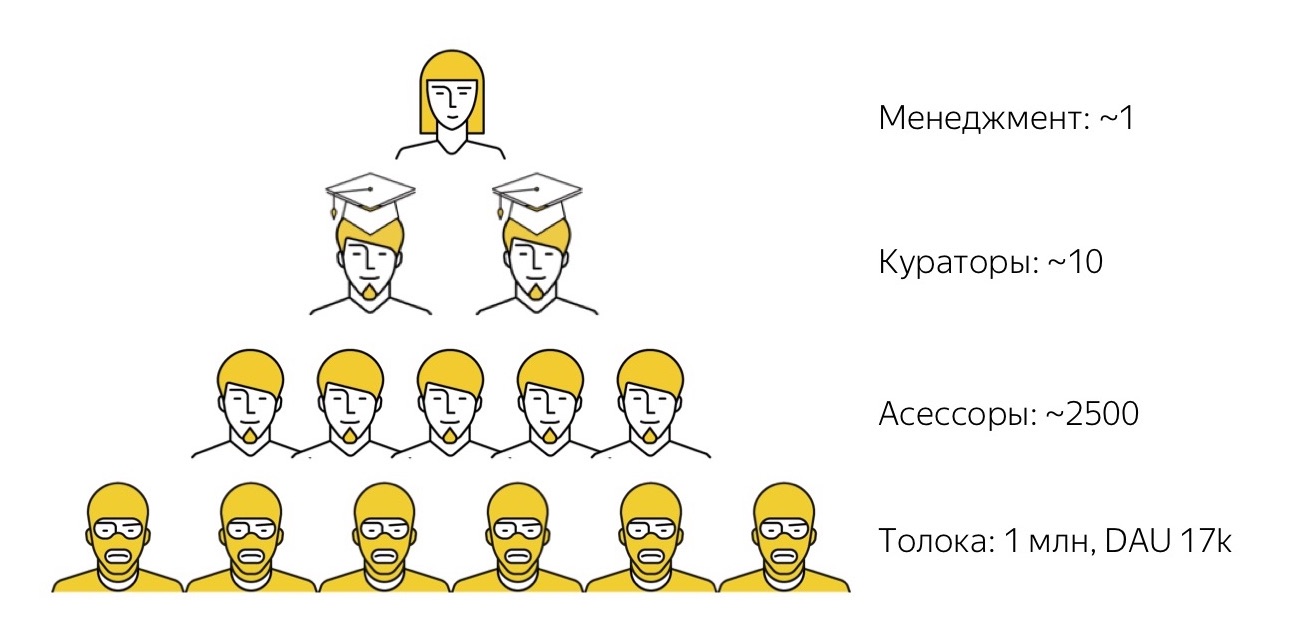
Comment fonctionne notre écosystème de crowdsourcing? Premièrement, nous avons
Yandex.Toloka . Il s'agit d'une plateforme ouverte de crowdsourcing sur laquelle n'importe qui peut s'inscrire soit en tant que client (publier ses tâches, fixer un prix pour eux et collecter des données), soit en tant qu'exécuteur testamentaire (trouver des tâches intéressantes, les compléter et recevoir une petite récompense). Nous avons lancé le plafond il y a quelques années. Nous avons maintenant plus d'un million d'artistes inscrits (nous les appelons des tokers) et chaque jour dans le système, environ 17 000 personnes accomplissent des tâches.
Depuis que nous avons initialement créé le Toloka avec un œil sur les tâches liées à l'apprentissage automatique, il est traditionnellement de coutume que la plupart des tâches exécutées par les tolokers soient des tâches très simples et triviales pour une personne, mais toujours assez difficiles pour l'algorithme. Par exemple, regardez une photo et dites si elle a du contenu pour adultes ou non, ou écoutez un enregistrement audio et décryptez ce que vous avez entendu.
Toloka est un outil très puissant en termes de performances et de quantité de données qu'il aide à collecter, mais plutôt non trivial à utiliser. Les personnes sur la photo portent une cagoule jaune parce que tous les artistes de Tolok sont anonymes et inconnus des clients. Et gérer ces milliers d'anonymus, s'assurer qu'ils font exactement ce dont vous avez besoin n'est pas une tâche facile. Par conséquent, toutes les tâches que nous avons, nous ne pouvons pas les résoudre jusqu'à présent avec l'aide de cette foule absolument «sauvage». Bien que nous nous efforçons de le faire, j'en dirai plus à ce sujet plus tard.
Par conséquent, pour les tâches de niveau supérieur, nous avons le prochain niveau d'interprètes. Ce sont ces gens que nous appelons évaluateurs. Le mot même «assesseurs» peut être un peu étrange. Elle vient du mot «évaluation», c'est-à-dire «évaluation», parce qu'au départ, des évaluateurs étaient utilisés avec nous pour recueillir des évaluations subjectives de la qualité des résultats de la recherche. Ces données ont ensuite été utilisées comme cible pour l'apprentissage automatique de la fonction de classement de recherche. Depuis lors, beaucoup de temps s'est écoulé, les évaluateurs ont commencé à effectuer de nombreuses autres tâches différentes, alors maintenant c'est un mot familier: les tâches ont changé, mais le mot reste.
En fait, nos évaluateurs sont des employés à plein temps de Yandex, mais travaillent à temps partiel et à distance. Ce sont des gars qui travaillent sur leur propre équipement. Nous interagissons uniquement avec eux à distance: nous les sélectionnons à distance, les formons à distance, travaillons à distance avec eux et, si nécessaire, les tirons à distance. Avec la plupart d'entre eux, nous ne nous croisons jamais en personne dans la vie. Ils travaillent selon n'importe quel horaire qui leur convient, de jour comme de nuit: ils ont des normes minimales équivalentes à environ 10-15 heures par semaine, et ils peuvent travailler cette fois d'une manière qui leur convient. Les évaluateurs résolvent divers problèmes: ils sont liés à la recherche, au support technique, à certaines traductions de bas niveau et aux tests, dont nous parlerons plus tard.
En règle générale, quelle que soit la tâche que nous entreprenons, les personnes les plus talentueuses se distinguent toujours du groupe d'évaluateurs qui l'exécutent mieux, pour qui cette tâche est plus intéressante. Nous les distinguons, leur donnons le titre fort de super-haut-parleurs, et ces gars-là remplissent déjà des fonctions de haut niveau de conservateurs: ils vérifient la qualité du travail des autres, les conseillent, les soutiennent, etc.
Et ce n'est qu'au sommet de notre pyramide que nous avons le premier employé à temps plein qui siège au bureau et gère ces processus. Nous avons beaucoup moins de ces personnes qui sont déjà à un niveau beaucoup plus élevé et ont de solides compétences techniques et managériales, littéralement peu. Un tel système nous permet de conclure que ces unités de personnes "de haut niveau" construisent des pipelines et gèrent des chaînes de production, dans lesquelles des dizaines, des centaines et même des milliers de personnes sont davantage impliquées.
En soi, ce régime n'est pas nouveau, mais Gengis Khan l'a appliqué avec succès. Elle a plusieurs propriétés intéressantes que nous essayons d'utiliser. La première propriété est tout à fait compréhensible - un tel schéma est très facile à mettre à l'échelle. Si une tâche doit soudainement commencer à faire plus, nous n'avons pas besoin de chercher de l'espace supplémentaire dans le bureau pour planter une personne quelque part. En général, nous pouvons penser à très peu de choses: verser simplement plus d'argent, embaucher plus d'artistes pour cet argent, et plus de gars talentueux dans les casquettes académiques sortiront probablement de ces artistes, et tout ce système continuera à évoluer.
La deuxième propriété (et cela m'a surpris) est qu'une telle pyramide est très bien reproduite quel que soit le domaine dans lequel elle est appliquée. Cela s'applique également au domaine dont nous allons parler aujourd'hui - les tâches de test manuel.
Test de foule
Lorsque nous avons commencé le processus de test avec l'aide de la foule, le plus gros problème était le manque de référence positive. Il n'y avait aucune expérience à laquelle nous pourrions nous référer et dire: "Eh bien, ces gars-là ont fait cela, ils testent déjà avec l'aide de foules dans un circuit très similaire à nous, et tout va bien là-bas, ce qui signifie que tout ira bien pour nous." Par conséquent, nous avons dû nous fier uniquement à notre expérience personnelle, séparée du domaine des tests et davantage liée à la mise en place de processus de production similaires, mais dans d'autres domaines.
Par conséquent, nous avons dû faire ce que nous pouvions. Que pouvons-nous faire? Essentiellement, décomposer une tâche en tâches de différents niveaux de difficulté et les disperser le long des étages de notre pyramide. Voyons ce que nous avons.
Tout d'abord, nous avons examiné les tâches avec lesquelles nos testeurs de Yandex sont occupés et leur avons demandé de répartir conditionnellement ces tâches à différents niveaux de difficulté. Il s'agit d'une "moyenne hospitalière":
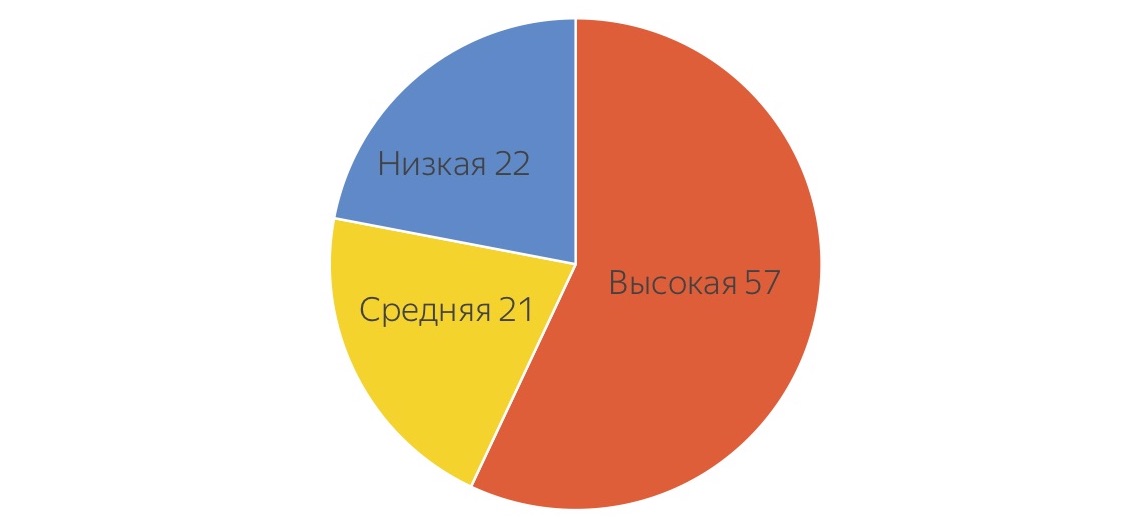
Ils ont estimé que seulement 57% de leur temps est consacré à des tâches complexes de haut niveau, et quelque part environ 20% est consacré à une routine de très bas niveau dont tout le monde veut se débarrasser, et à des tâches un peu plus compliquées, qui peuvent également être déléguées. Encouragés par ces chiffres, montrant que près de la moitié du travail peut être transféré quelque part, nous avons procédé à la construction de tests utilisant la foule.
Quels sont nos objectifs?
- Faites en sorte que les tests ne soient plus le goulot d'étranglement qui apparaît périodiquement dans les processus de production lorsque la version est prête, mais il attend que les tests réussissent.
- Libérez nos spécialistes cool, très intelligents et de haut niveau - testeurs à plein temps - de la routine, en les occupant de tâches vraiment intéressantes et de niveau supérieur.
- Améliorez la variété des environnements dans lesquels nous testons les produits.
- Apprendre à gérer les charges de pointe parce que nos testeurs ont dit qu'ils avaient souvent des charges inégales. Même si, en moyenne, une équipe fait face à des tâches, lorsqu'un pic survient, il faut beaucoup de temps pour le ratisser.
- Étant donné que nous, à Yandex, dépensions encore pas mal d'argent pour des tests d'externalisation dans certains projets, nous pensions que nous aimerions obtenir un peu plus de résultats pour notre argent que nous dépensons, afin d'optimiser nos dépenses d'externalisation.
Je tiens à souligner que parmi ces objectifs, il n'est pas nécessaire de remplacer les testeurs par des foules, de les enfreindre d'une manière ou d'une autre, etc. Tout ce que nous voulions faire était d'aider les équipes de test, en éliminant la routine de bas niveau.
Voyons voir ce que nous avons fini avec. Je dirai tout de suite que les principales tâches de test sont désormais effectuées non pas par le niveau le plus bas de la «pyramide», par les tolkers, mais par les évaluateurs, nos employés à temps plein. De plus, nous en discuterons principalement, à l'exception de la toute fin.
Les évaluateurs effectuent maintenant les tâches de test de régression pour nous et ils font toutes sortes de sondages comme «regardez cette application et laissez vos commentaires». Environ 300 personnes sont maintenant qualifiées pour la tâche de recours à part entière (
note: depuis que le rapport est devenu 500 ). Mais ce chiffre est conditionnel, car le système que nous avons construit fonctionne pour un nombre arbitraire de personnes: autant que nous en avons besoin. Maintenant, nos besoins de production sont couverts par environ autant de personnes. Cela ne signifie pas qu'à chaque instant, ils sont tous prêts et prêts à exécuter la tâche: comme les évaluateurs travaillent selon un horaire flexible, à tout moment, 100 à 150 personnes sont prêtes à se connecter. Mais le bassin d'artistes est à peu près le même. Et des tâches simples, telles que les sondages, lorsque vous avez juste besoin de recueillir des commentaires informels des utilisateurs, nous passons par beaucoup plus de personnes: des centaines et des milliers d'évaluateurs participent à ces sondages.
Puisqu'il s'agit de personnes qui travaillent sur leur propre équipement, chaque évaluateur a ses propres appareils personnels. Par défaut, il s'agit d'un ordinateur de bureau et d'une sorte d'appareil mobile. En conséquence, nous testons nos produits sur les appareils personnels des évaluateurs. Mais il est clair qu'ils ne disposent pas de tous les appareils possibles. Par conséquent, si nous avons besoin de tests dans un environnement rare, nous utilisons l'accès à distance via la batterie d'appareils.
Maintenant, les tests de foule sont déjà utilisés comme processus de production standard pour environ 40 (
note: maintenant 60 ) services et équipes Yandex: il s'agit de Mail, Disk et Browser (mobile et bureau), et Maps, et Search, et beaucoup, beaucoup qui. C'est curieux. Lorsque nous nous sommes fixés pour la fin du troisième trimestre à l'automne 2017, nous avions un objectif ambitieux: attirer au moins en quelque sorte, «même par fraude, même en soudoyant», au moins cinq équipes qui utiliseraient nos processus de test avec l'aide de la foule. Et nous avons persuadé tout le monde, a déclaré: "N'ayez pas peur, allez, essayez-le!" Mais après seulement quelques mois, nous avions des dizaines d'équipes.
Et maintenant, nous résolvons un autre problème: comment réussir à connecter de plus en plus de nouvelles équipes qui souhaitent rejoindre ces processus. Nous pouvons donc supposer que maintenant c'est déjà une pratique standard dans Yandex, qui vole très bien.
Qu'avons-nous fait en termes d'indicateurs de production? Maintenant, nous effectuons environ 3000 cas de tests de régression par jour (
note: en octobre 2018, il y avait déjà 7000 cas ). Les tests, en fonction de la taille, prennent de plusieurs heures à (au pic) 2 jours. La plupart passent en quelques heures, en une journée. L'introduction d'un tel système nous a permis de réduire les coûts d'environ 30% par rapport à la période où nous avions recours à l'externalisation. Cela a permis aux équipes de publier beaucoup plus souvent, en moyenne, plusieurs fois, car les versions ont commencé à passer à la vitesse disponible pour le développement, et non à celle qui était disponible pour les tests, alors qu'elle devenait parfois un goulot d'étranglement.
Maintenant, je vais essayer de dire comment nous avons généralement construit le processus de production, ce qui nous a permis d'arriver à ce schéma.
L'infrastructure
Commençons par l'infrastructure technique. Ceux d'entre vous qui ont vu Toloka comme une plate-forme, imaginez à quoi ressemble son interface: vous pouvez vous connecter au système, sélectionner les tâches qui vous intéressent et les terminer. Pour les employés internes, nous avons une instance interne de Toloka, dans laquelle nous répartissons, entre autres, des tâches de différents types pour nos évaluateurs.
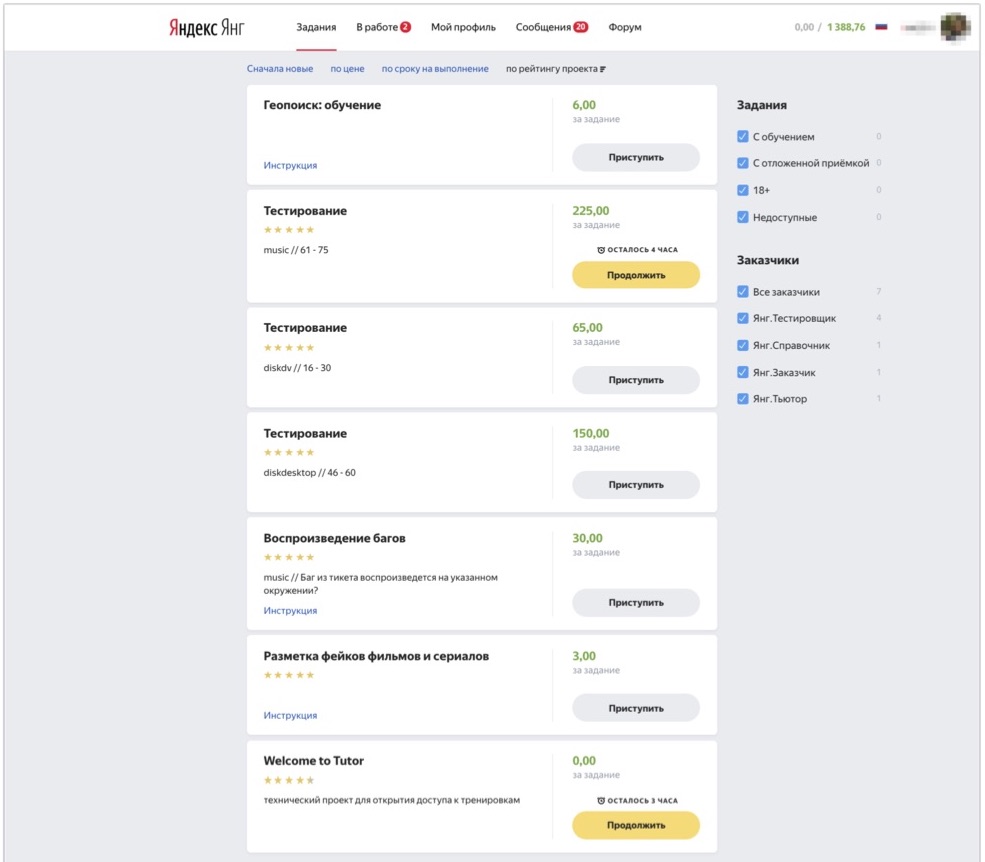
L'image montre à quoi ressemble cette interface. Vous pouvez voir ici les tâches disponibles pour l'évaluateur: il existe plusieurs tâches de test et plusieurs tâches d'un type différent, que l'évaluateur de cet exemple sait également effectuer. Et donc la personne vient, voit les tâches qui lui sont disponibles en ce moment, clique sur «Continuer», reçoit les cas de test pour analyse et commence à les exécuter.
Les fermes constituent une partie importante de notre infrastructure. Tous les appareils ne sont pas à portée de main, la tâche est donc en fait un couple: un cas de test et l'environnement dans lequel vous devez le vérifier. Lorsqu'une personne clique sur le bouton Continuer, le système vérifie si elle dispose d'un environnement dans lequel tester. Si tel est le cas, la personne prend simplement la tâche et la teste sur un appareil personnel. Sinon, nous l'envoyons via un accès à distance à la ferme.
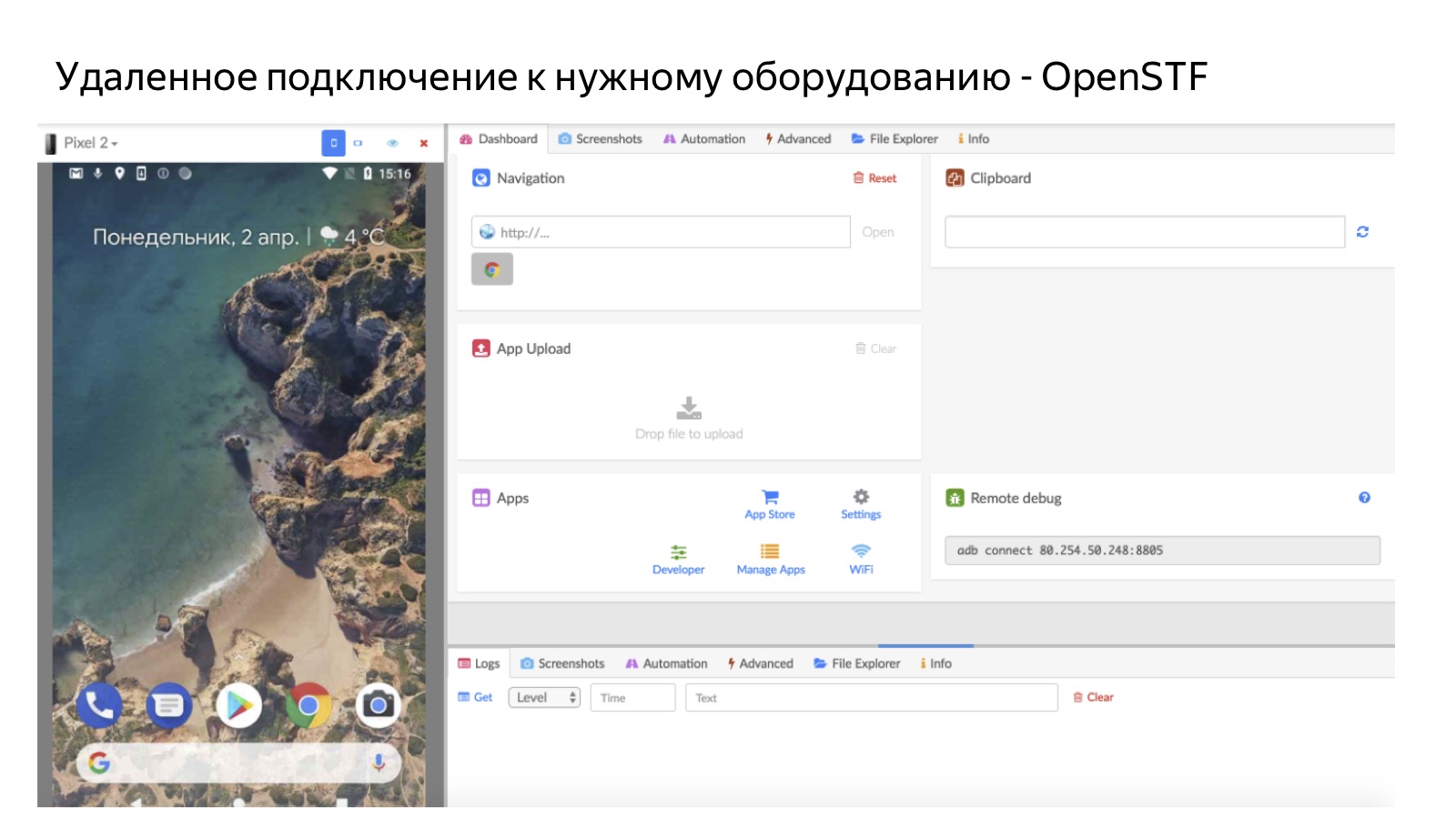
L'image montre à quoi elle ressemble, en utilisant l'exemple d'une ferme mobile. Ainsi, une personne se connecte à distance à un téléphone mobile qui se trouve dans notre bureau à la ferme. Pour Android, nous utilisons des solutions open source OpenSTF. Il n'y a pas de bonnes solutions pour iOS - dans la mesure où nous avons déjà fait les nôtres (mais nous en parlerons en détail la prochaine fois), car nous n'avons pu trouver ni open source ni quelque chose qui aurait du sens à acheter. Il est clair que la ferme est utile dans les cas où nous n'avons pas de personnes qui ont les bons appareils. Et un autre avantage important est que la ferme a un taux d'utilisation très élevé: chaque fois et peu importe la personne qui entre, nous pouvons l'envoyer à la ferme à tout moment. C'est mieux que de distribuer des appareils en personne, car les appareils qui sont remis à une personne ne sont disponibles pour travailler que lorsque cette personne est prête à travailler.
Nous avons parlé un peu de la façon dont il a été mis en œuvre pour nos évaluateurs d'un point de vue technique, et maintenant la partie la plus intéressante pour moi: les principes de la façon dont nous avons organisé cette production.
Les principes d'organisation de la production en foule
Pour moi, dans ce projet, il était intéressant que le domaine semble très spécifique, mais tous les principes d'organisation de la production sont assez universels: les mêmes que ceux utilisés pour organiser la production de masse dans d'autres domaines.
1. Formalisation
Le premier principe (pas le plus important, mais l'un des plus importants, un de nos «baleines, éléphants et tortues») est la formalisation des tâches. Je pense que vous le savez tous par vous-même. Presque n'importe quelle tâche est plus facile à faire vous-même. C'est un peu plus difficile à expliquer à votre collègue qui est assis à côté de vous dans la pièce pour qu'il fasse exactement ce dont vous avez besoin. Et la tâche est de s'assurer que des centaines d'artistes que vous n'avez jamais vus, qui travaillent à distance, à tout moment arbitraire, font exactement ce que vous attendez d'eux - cette tâche est plusieurs ordres de grandeur plus compliquée et implique un seuil assez élevé pour entrer pour commencer à faire ça du tout. Dans le contexte des tâches de test, la tâche avec nous, bien sûr, est un cas de test qui doit être passé et traité.
Et quels cas de test devraient être afin de pouvoir les utiliser dans une tâche telle que le test de foule?
Premièrement - et il s'est avéré que ce n'est pas du tout une question de fait - les cas types devraient généralement l'être.
Il y a eu des moments où des équipes sont venues vers nous qui voulaient se connecter à des tests par des évaluateurs, nous avons dit: "Génial, apportez vos cas de test, nous allons les parcourir!" En ce moment, le client était triste, parti, ne revenait pas toujours. Après plusieurs appels de ce type, nous avons réalisé que j'avais probablement besoin d'aide à cet endroit. Parce que si un testeur d'une équipe de certains services teste lui-même régulièrement ses services, il n'a pas vraiment besoin de cas de test complets et bien décrits. Et si nous voulons déléguer cette tâche à un grand nombre d'artistes, nous ne pouvons tout simplement pas nous en passer.Mais même dans les cas où il y avait des cas de test, ils étaient presque toujours compréhensibles uniquement pour les personnes qui sont très profondément immergées dans le service. Et toutes les autres personnes hors contexte, il était très difficile de comprendre ce qui se passe ici et ce qui doit être fait. Par conséquent, il était important de réviser les cas de test afin qu'ils soient compréhensibles pour une personne non plongée dans le contexte.Et la dernière chose: si nous réduisons la tâche de test à des cas spécifiques de passage strictement formels, il est très important de s'assurer que ces cas sont constamment mis à jour, mis à jour et mis à jour.Je vais donner quelques exemples.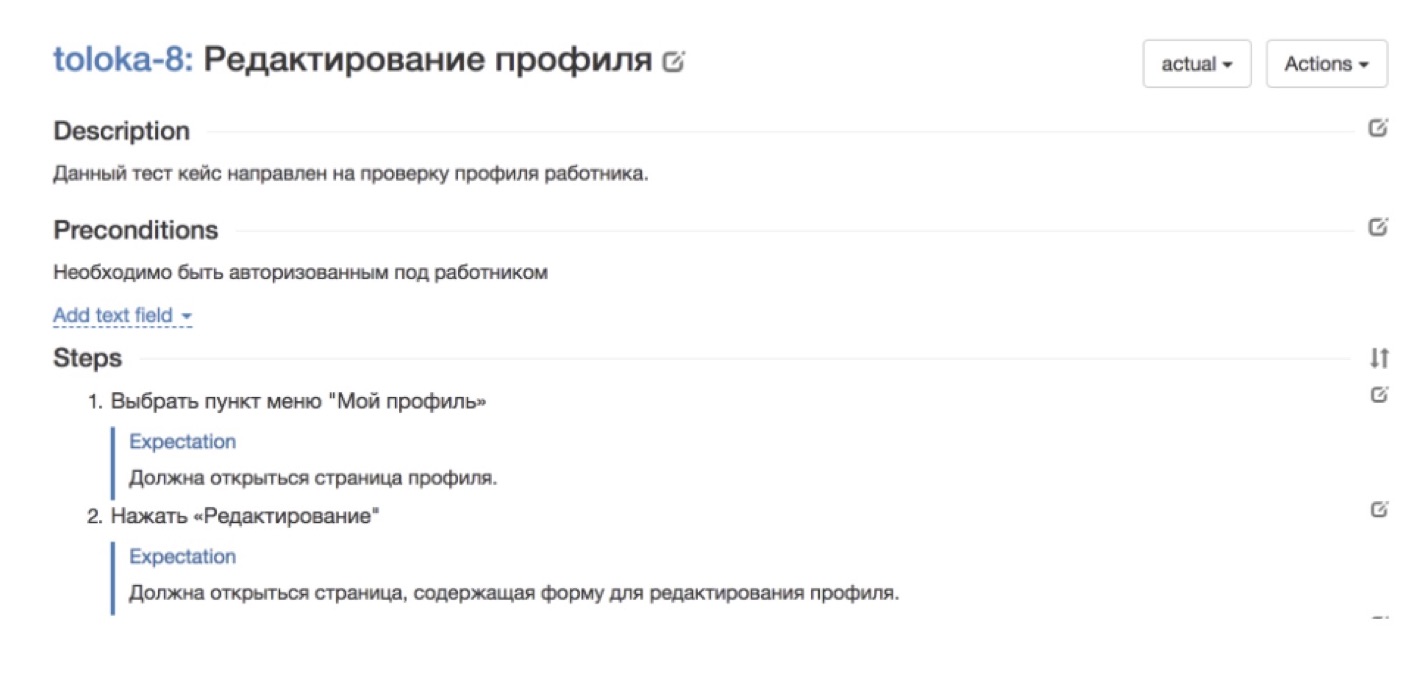 L'image ci-dessus, par exemple, montre un bon cas de notre service natif Tolok, dans lequel vous devez vérifier l'exactitude du profil de l'artiste. Tout se décompose par étapes. Il y a chaque pas à faire. Il y a une attente de ce qui devrait se produire à chaque étape. Un tel cas sera clair pour tout le monde.
L'image ci-dessus, par exemple, montre un bon cas de notre service natif Tolok, dans lequel vous devez vérifier l'exactitude du profil de l'artiste. Tout se décompose par étapes. Il y a chaque pas à faire. Il y a une attente de ce qui devrait se produire à chaque étape. Un tel cas sera clair pour tout le monde.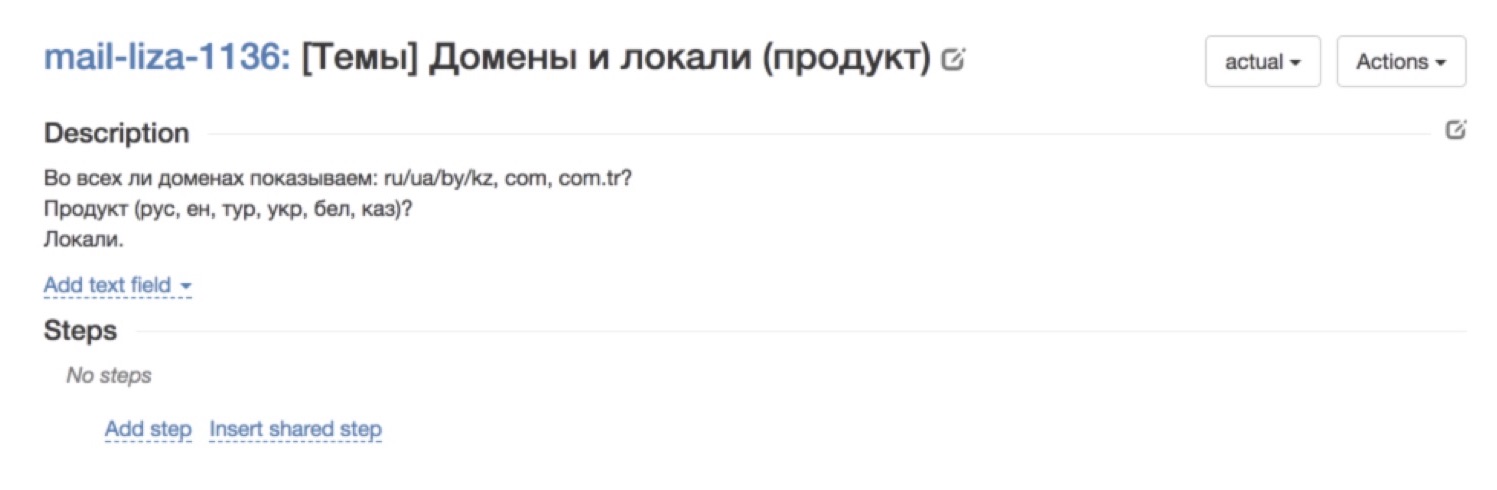 Et voici un exemple de cas non réussi. En général, ce qui se passe n'est pas clair. La description semble être là, mais en réalité - qu'est-ce que vous attendez de moi? Des cas de ce genre - ce n'est pas tout de suite, ils passent très mal.Comment avons-nous construit le processus de formalisation des cas de test afin que, premièrement, nous les ayons tous, constamment apparus et réapprovisionnés, et, deuxièmement, qu'ils soient suffisamment compréhensibles pour les évaluateurs?Par essais et erreurs, nous sommes arrivés à ce schéma:
Et voici un exemple de cas non réussi. En général, ce qui se passe n'est pas clair. La description semble être là, mais en réalité - qu'est-ce que vous attendez de moi? Des cas de ce genre - ce n'est pas tout de suite, ils passent très mal.Comment avons-nous construit le processus de formalisation des cas de test afin que, premièrement, nous les ayons tous, constamment apparus et réapprovisionnés, et, deuxièmement, qu'ils soient suffisamment compréhensibles pour les évaluateurs?Par essais et erreurs, nous sommes arrivés à ce schéma: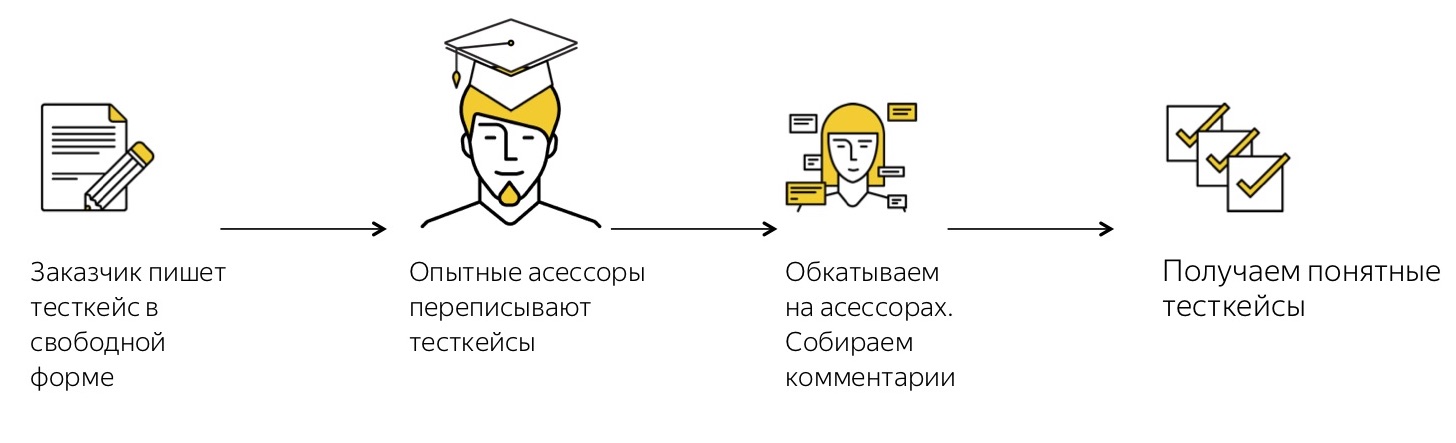 Notre client, c'est-à-dire une sorte de service ou d'équipe, vient et sous une forme arbitraire arbitraire qui lui convient, décrit les cas de test dont il a besoin.Après cela, notre évaluateur intelligent qui examine ce texte librement formulé et le traduit en cas de test bien formalisés, bien formalisés et peints en petits détails. Pourquoi est-il important que cet évaluateur? Parce que lui-même était à la place de ces personnes qui prennent des cas de test dans des domaines complètement différents, et comprend à quel point le cas de test devrait être détaillé pour que ses collègues le comprennent.Après cela, nous courons dans un cas: nous donnons des missions aux évaluateurs et collectons les commentaires. Le processus est organisé de sorte que si une personne ne comprend pas ce qui est exigé d'elle dans un cas de test, elle l'ignore. En règle générale, après la première fois, il y a un pourcentage assez important de passes. Quoi qu'il en soit, peu importe la façon dont nous avons formalisé les cas de test à l'étape précédente, il n'est jamais impossible de deviner ce qui sera incompréhensible pour les gens. Par conséquent, la première exécution est presque toujours une version de test, ses fonctions les plus importantes sont de recueillir des commentaires. Après avoir recueilli les commentaires, reçu les commentaires des évaluateurs, appris ce qu'ils ont compris ou non, nous réécrivons et ajoutons à nouveau les cas de test. Et après quelques itérations, nous obtenons des cas de test sympas et très clairement formulés qui sont compréhensibles par tout le monde.Ce rangement a un effet secondaire intéressant. Tout d'abord, il s'est avéré que pour de nombreuses équipes, c'est généralement une caractéristique mortelle. Tout le monde vient vers nous et dit: "Pouvez-vous vraiment écrire des cas de test pour moi?" C'est la chose la plus importante que nous attirions nos clients. Le deuxième effet, inattendu pour moi - l'ordre dans les cas de test a d'autres effets en attente. Par exemple, nous avons des rédacteurs techniques qui écrivent la documentation utilisateur, et écrire sur la base de tels cas de test bien conçus et compréhensibles est beaucoup plus facile pour eux. Auparavant, ils devaient distraire le service pour savoir ce qui devait être décrit, mais maintenant nous pouvons utiliser nos cas de test clairs et cool.
Notre client, c'est-à-dire une sorte de service ou d'équipe, vient et sous une forme arbitraire arbitraire qui lui convient, décrit les cas de test dont il a besoin.Après cela, notre évaluateur intelligent qui examine ce texte librement formulé et le traduit en cas de test bien formalisés, bien formalisés et peints en petits détails. Pourquoi est-il important que cet évaluateur? Parce que lui-même était à la place de ces personnes qui prennent des cas de test dans des domaines complètement différents, et comprend à quel point le cas de test devrait être détaillé pour que ses collègues le comprennent.Après cela, nous courons dans un cas: nous donnons des missions aux évaluateurs et collectons les commentaires. Le processus est organisé de sorte que si une personne ne comprend pas ce qui est exigé d'elle dans un cas de test, elle l'ignore. En règle générale, après la première fois, il y a un pourcentage assez important de passes. Quoi qu'il en soit, peu importe la façon dont nous avons formalisé les cas de test à l'étape précédente, il n'est jamais impossible de deviner ce qui sera incompréhensible pour les gens. Par conséquent, la première exécution est presque toujours une version de test, ses fonctions les plus importantes sont de recueillir des commentaires. Après avoir recueilli les commentaires, reçu les commentaires des évaluateurs, appris ce qu'ils ont compris ou non, nous réécrivons et ajoutons à nouveau les cas de test. Et après quelques itérations, nous obtenons des cas de test sympas et très clairement formulés qui sont compréhensibles par tout le monde.Ce rangement a un effet secondaire intéressant. Tout d'abord, il s'est avéré que pour de nombreuses équipes, c'est généralement une caractéristique mortelle. Tout le monde vient vers nous et dit: "Pouvez-vous vraiment écrire des cas de test pour moi?" C'est la chose la plus importante que nous attirions nos clients. Le deuxième effet, inattendu pour moi - l'ordre dans les cas de test a d'autres effets en attente. Par exemple, nous avons des rédacteurs techniques qui écrivent la documentation utilisateur, et écrire sur la base de tels cas de test bien conçus et compréhensibles est beaucoup plus facile pour eux. Auparavant, ils devaient distraire le service pour savoir ce qui devait être décrit, mais maintenant nous pouvons utiliser nos cas de test clairs et cool.Je vais vous donner un exemple.
 Voici à quoi ressemblait le cas de test avant de passer par notre hachoir à viande: il est très maigre, le champ de description n'est pas rempli, il dit "eh bien, regardez la capture d'écran dans l'application" et c'est tout.
Voici à quoi ressemblait le cas de test avant de passer par notre hachoir à viande: il est très maigre, le champ de description n'est pas rempli, il dit "eh bien, regardez la capture d'écran dans l'application" et c'est tout.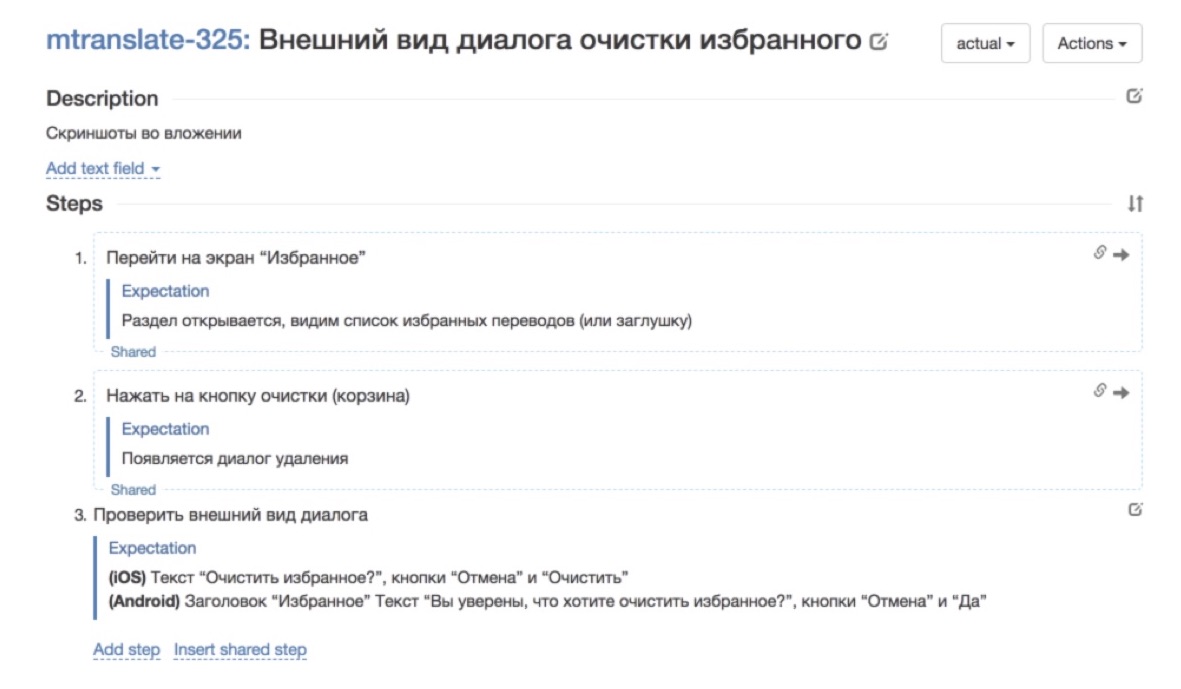 C'est ainsi qu'il a commencé à s'occuper de sa réécriture - des étapes et des attentes ajoutées à chaque étape. Tant mieux déjà. Il est beaucoup plus agréable de travailler avec un tel cas de test.
C'est ainsi qu'il a commencé à s'occuper de sa réécriture - des étapes et des attentes ajoutées à chaque étape. Tant mieux déjà. Il est beaucoup plus agréable de travailler avec un tel cas de test.2. Apprentissage évolutif
La tâche suivante est ma préférée, la plus, il me semble, créative dans tout cela. Il s'agit d'une tâche d'apprentissage évolutive. Pour que nous puissions fonctionner avec de tels nombres - «ici, nous avons 200 évaluateurs, voici 1 000 et ici en général 17 000 employés travaillent chaque jour» - il est important de pouvoir former rapidement et de manière évolutive les gens.
Il est très important d'arriver à un tel système lorsque vous ne passez pas plus de temps à former un nombre arbitraire de personnes qu'à former un spécialiste spécifique. C'est, par exemple, ce que nous avons rencontré en travaillant avec l'externalisation. Les spécialistes sont très sympas, mais pour les plonger dans le contexte du travail, le service a pris beaucoup de temps, et en sortie on a toujours une personne qui est immergée dans le contexte pendant six mois. Et c'est un schéma très évolutif. Il s'avère que chaque personne suivante doit être immergée dans le contexte de la tâche pendant encore six mois. Et il fallait élargir ce goulot d'étranglement.
Pour tout poste vacant en masse, pas seulement dans les tests, nous recrutons des personnes via plusieurs canaux. Pour les tests, nous le faisons. Premièrement, nous attirons des gens qui, en principe, sont intéressés par les tâches de test, des gars quelque part au niveau des testeurs juniors, pour eux, c'est un bon début, une immersion dans le domaine. Mais il y a toujours un nombre limité de ces personnes sur le marché, et nous avons besoin de n'avoir aucune restriction sur l'embauche de personnes, afin de ne jamais nous reposer sur le nombre d'artistes.
Par conséquent, en plus de trouver des testeurs spécifiquement pour ces tâches, nous effectuons un ensemble de personnes qui ont simplement répondu à la position générale de l’évaluateur. Nous plaidons pour cette approche: peu importe les personnes que vous prenez, s'il y en a beaucoup, vous pouvez construire un processus afin de sélectionner les plus capables d'entre elles et de les diriger pour résoudre le problème que vous poursuivez. Dans le contexte des tests, nous construisons une formation afin qu'il soit possible pour des personnes arbitraires qui ne savaient même rien du test d'enseigner au moins les bases minimales pour qu'elles commencent à comprendre quelque chose. Grâce à cette approche, nous ne rencontrons jamais un manque d'interprètes et le nombre de personnes qui travaillent pour nous sur ces tâches, tout se résume à la question de combien d'argent nous sommes prêts à y consacrer.
Je ne sais pas combien de fois vous rencontrez ce sujet, mais dans toutes sortes d'articles scientifiques populaires, en particulier sur l'apprentissage automatique et les réseaux de neurones, il est souvent écrit que l'apprentissage automatique est très similaire à la formation humaine. Nous montrons à l'enfant 10 cartes avec l'image de la balle, et pour la 11e fois il comprendra et dira: «Oh! C'est une balle! " En fait, la vision par ordinateur et toutes les autres technologies d'apprentissage automatique fonctionnent également par essence.
Je veux parler de la situation inverse: la formation des personnes peut être construite de la même manière formelle que les machines de formation. De quoi avons-nous besoin pour cela? Nous avons besoin d'un ensemble de formation - un ensemble d'exemples pré-marqués sur lesquels une personne sera formée. Nous avons besoin d'un ensemble de contrôle, sur lequel nous pouvons vérifier s'il a bien étudié ou non. Comme dans l'apprentissage automatique, vous avez besoin d'un ensemble de test sur lequel nous comprenons comment notre fonction fonctionne généralement. Et nous avons besoin d'une métrique formelle qui mesurera la qualité du travail effectué. C'est sur ces principes que nous avons construit une formation aux tâches des tests de régression les plus simples.
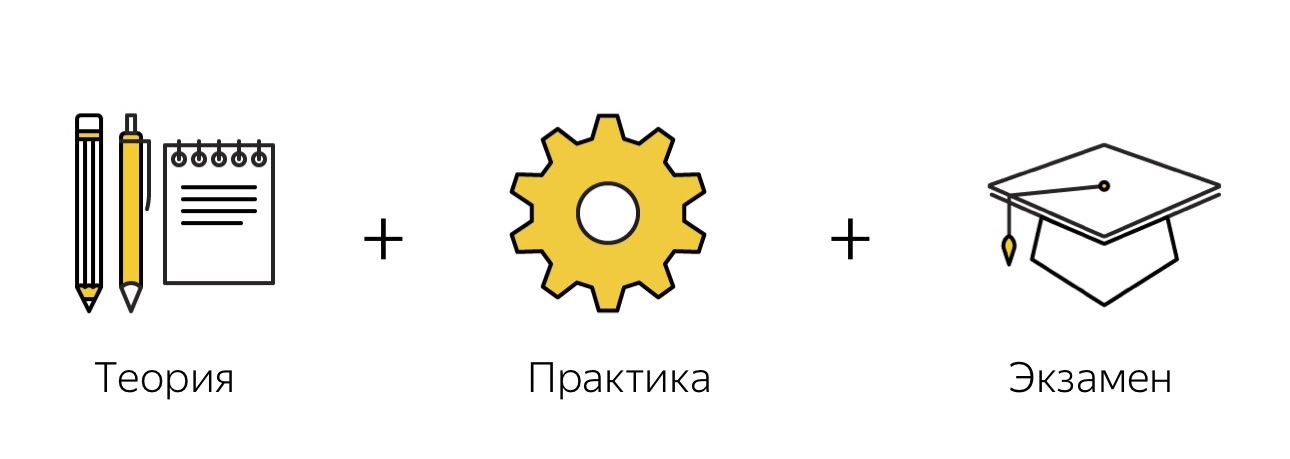
L'image montre à quoi ressemble cette formation avec nous. Il se compose de plusieurs parties. Il y a d'abord une théorie, puis une pratique, puis un examen, sur lequel on vérifie si une personne a compris l'essence du problème ou n'a pas compris.
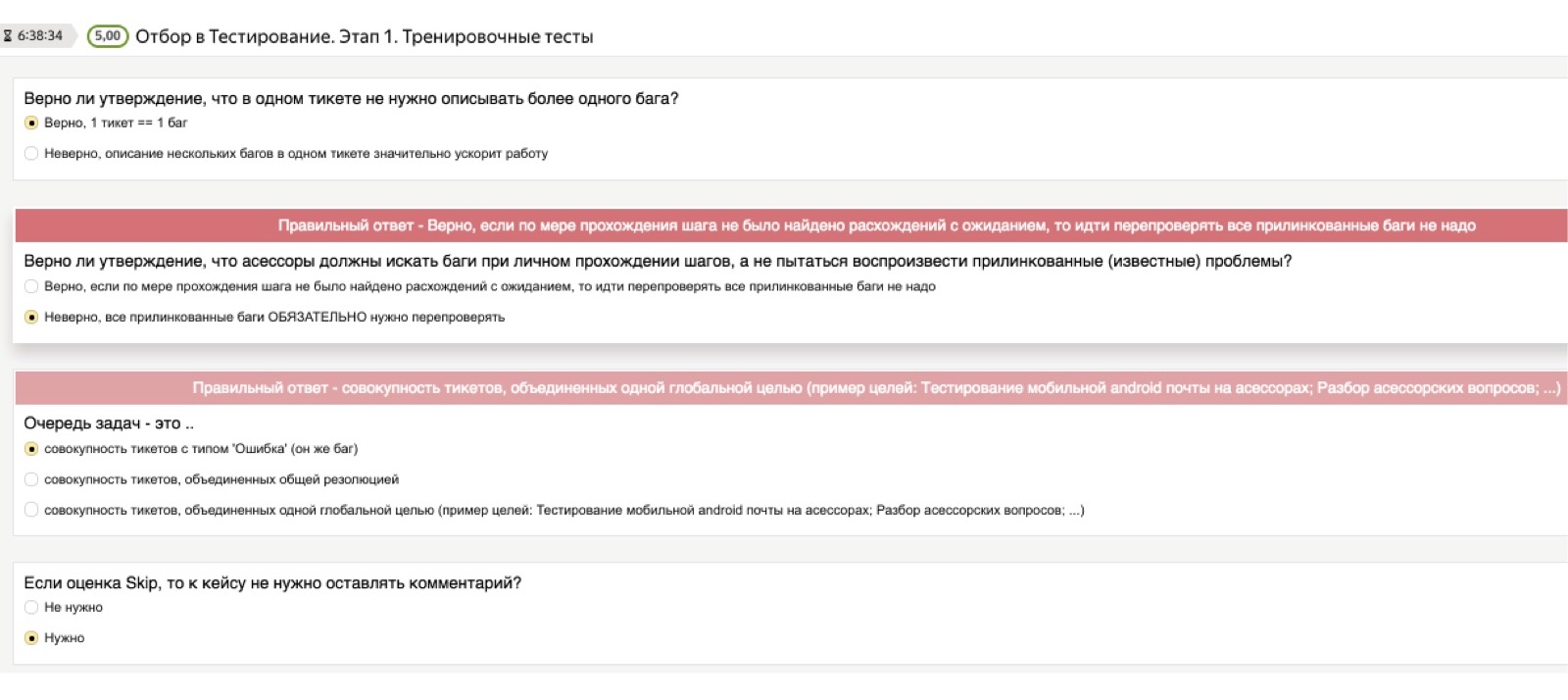
Commençons par la théorie. Il est clair que pour toute tâche effectuée par l'évaluateur, nous avons une instruction volumineuse, complète et complète avec un grand nombre d'exemples, où tout est décrit en détail. Mais personne ne le lit.
Par conséquent, afin de vérifier que les connaissances théoriques se sont réellement installées dans la tête d'une personne, nous donnons toujours accès aux instructions, mais après cela, nous utilisons ce que nous appelons conditionnellement un «test théorique». Il s'agit d'un tel test, dans lequel nous préchargeons des questions importantes pour nous et les bonnes réponses. Les questions peuvent être les plus stupides. Je pense que ce seront pour vous des exemples comiques, mais pour les personnes confrontées à des tests pour la première fois de leur vie, ce ne sont pas du tout des choses évidentes. Par exemple: "Si j'ai rencontré plusieurs bogues, dois-je commencer plusieurs tickets - un pour chaque bogue - ou tout vider dans une pile?" Ou: "Et si je veux faire une capture d'écran, mais la capture d'écran ne fonctionne pas pour moi?"
Ces questions peuvent être très différentes, arbitrairement de bas niveau, et il est important pour nous qu'une personne les étudie indépendamment au stade de l'étude de la théorie. Par conséquent, le test théorique consiste en des questions de ce type: "J'ai trouvé plusieurs bugs, dois-je avoir un ticket ou plusieurs?" Si une personne choisit la mauvaise réponse, un dé rouge tombe qui dit: "Non, attendez, la bonne réponse est différente, faites attention." Même si une personne n'a pas lu les instructions, elle ne peut pas passer ce test.

Le point suivant est la pratique. Comment s'assurer que les personnes qui ne savaient rien du tout et qui ne répondaient pas spécifiquement à la vacance du testeur, comprenaient ce qui devait être fait ensuite? Nous arrivons ici à cet ensemble d'entraînement. Je pense que vous trouverez immédiatement un grand nombre de bugs sur cette image. Voici à quoi ressemble la tâche de formation de l'évaluateur: voici une capture d'écran devant vous, trouvez tous les bugs dessus. Qu'est-ce qui ne va pas ici? La calculatrice sort. Quoi d'autre? La mise en page a disparu.

Ou voici un exemple plus complexe, avec un astérisque. La boîte aux lettres du destinataire principal est ouverte, c'est moi à qui cette lettre a été envoyée. Je vois donc une telle image devant moi. Quel est le bug ici? Le plus gros problème ici est qu'une copie aveugle est montrée, et en tant que destinataire de la lettre, je vois qui c'était dans la copie aveugle.
Après avoir passé une douzaine d'exemples de ce genre, même une personne qui est infiniment loin des tests, commence déjà à comprendre ce que c'est et ce qui est exigé de lui davantage lors de la réussite des tests. La partie pratique est un ensemble d'exemples dans lesquels nous connaissons déjà des bogues; nous demandons à la personne de les trouver et à la fin nous lui montrons: "Regardez, le bug était là", afin qu'il corrèle ses suppositions avec nos bonnes réponses.
Et la dernière partie est ce que nous appelons un examen. Nous avons un assemblage de test spécial, dont les bogues nous sont déjà connus, et nous demandons à la personne de le parcourir. Ici, nous ne lui montrons plus les réponses correctes et incorrectes, mais regardons simplement ce qu'il a pu trouver.
La beauté de ce système et son évolutivité réside dans le fait que tous ces processus se déroulent de manière absolument autonome, sans la participation d'un manager. Nous gérons autant de personnes que vous le souhaitez: tous ceux qui veulent lire les instructions, tous ceux qui veulent passer le test théorique, tous ceux qui veulent faire la pratique - tout cela se fait automatiquement au simple toucher d'un bouton, et nous n'avons aucune inquiétude du tout.
La dernière partie - l'examen - est également réussie par tous ceux qui le souhaitent, puis, enfin, nous commençons à les examiner attentivement. Comme il s'agit d'un assemblage de test et que nous connaissons tous ses bogues à l'avance, nous pouvons déterminer automatiquement quel pourcentage de bogues une personne a trouvé. S'il est très bas, alors nous ne cherchons pas plus loin, nous écrivons un battement automatique: "Merci beaucoup pour vos efforts!" - et ne donnez pas à cette personne accès aux missions de combat. Si nous voyons que presque tous les bogues ont été trouvés, alors à ce moment-là, une personne se connecte déjà qui regarde comment les billets sont émis correctement, combien tout est fait correctement selon la procédure, du point de vue de nos instructions.
Si nous constatons qu'une personne maîtrise à la fois la théorie et la pratique et réussit bien l'examen, alors nous laissons ces personnes participer à nos processus de production. Ce schéma est bon en ce qu'il ne dépend pas du nombre de personnes que nous traversons. Si nous avons besoin de plus de personnes, nous inondons simplement plus de personnes à l'entrée et obtenons plus à la sortie.
C'est un système cool, mais, bien sûr, il serait naïf de croire qu'après cela, vous pouvez déjà avoir un testeur prêt à l'emploi. Même les gars qui ont réussi notre formation ont de nombreuses questions dont ils ont besoin pour aider rapidement. Et ici, nous sommes confrontés à de nombreux problèmes inattendus pour nous.
Les gens posent beaucoup de questions. De plus, ces questions peuvent être si étranges que vous n'auriez jamais pensé dans votre vie que les réponses à ces questions devraient être ajoutées aux instructions, décrites dans un test ou quelque chose comme ça. Si vous y réfléchissez, c'est une situation normale. Chacun de nous, lorsque nous nous trouvons dans un domaine qui nous est inconnu, a peu de chances de poser une question qui semble idiote à un spécialiste.
Ici, la situation est aggravée par le fait que nous avons plusieurs centaines de ces personnes, et même si chacun de nous pose des questions à une personne en particulier, la probabilité de poser une question stupide est faible, au total il s'avère: Oh mon dieu Que se passe-t-il? Cela nous submerge! »
Parfois, les questions semblent étranges. Par exemple, une personne écrit: «Je ne comprends pas ce que signifie« puiser dans Annuler ». Ils lui disent: «Ami! Cela revient à cliquer sur le bouton "Annuler". " Il: «Oh! Je vous remercie! Maintenant, je comprends tout. "
Ou une autre personne dit: "Tout semble aller bien, mais quelque chose est un peu cassé, je ne peux pas comprendre si c'est une erreur ou non." Mais après une minute, il comprend lui-même où il en est arrivé à la tâche de test; une photo cassée n'est probablement pas très normale. Ici, il a compris, et d'accord.
Ou voici un exemple intéressant qui nous a vraiment plongés depuis longtemps dans l'abîme de la recherche. Un homme vient et dit:

Tout le monde ne comprend pas ce qui se passe, d'où il vient - nous avons essayé si fort, décrit des cas de test - jusqu'à ce que nous découvrions qu'il a une sorte d'extension de navigateur spéciale qui se traduit du russe en anglais, puis de l'anglais en russe , et à la fin, nous obtenons une hérésie.
En fait, il y a beaucoup de telles questions, l'étude de chacune d'elles prend un certain temps non nul. Et à un moment donné, nos clients - les services de l'équipe Yandex qui ont utilisé des tests par des évaluateurs - ont commencé à se déchirer les cheveux et à dire: «Écoutez, nous passerions beaucoup moins de temps si nous testions tout cela nous-mêmes, que de nous asseoir dans ces bavardoirs et de répondre à ces questions étranges. "
Par conséquent, nous sommes arrivés à un système de chat à deux niveaux. Il y a une inondation conditionnelle, où nos évaluateurs communiquent avec leurs conservateurs, ces «gars au chapeau» - 90% des problèmes sont résolus ici. Et seuls les problèmes les plus importants et les plus complexes sont transformés en un chat dédié dans lequel l'équipe de service est assise. Cela a grandement facilité la vie de toutes les équipes, tout le monde a soupiré calmement.
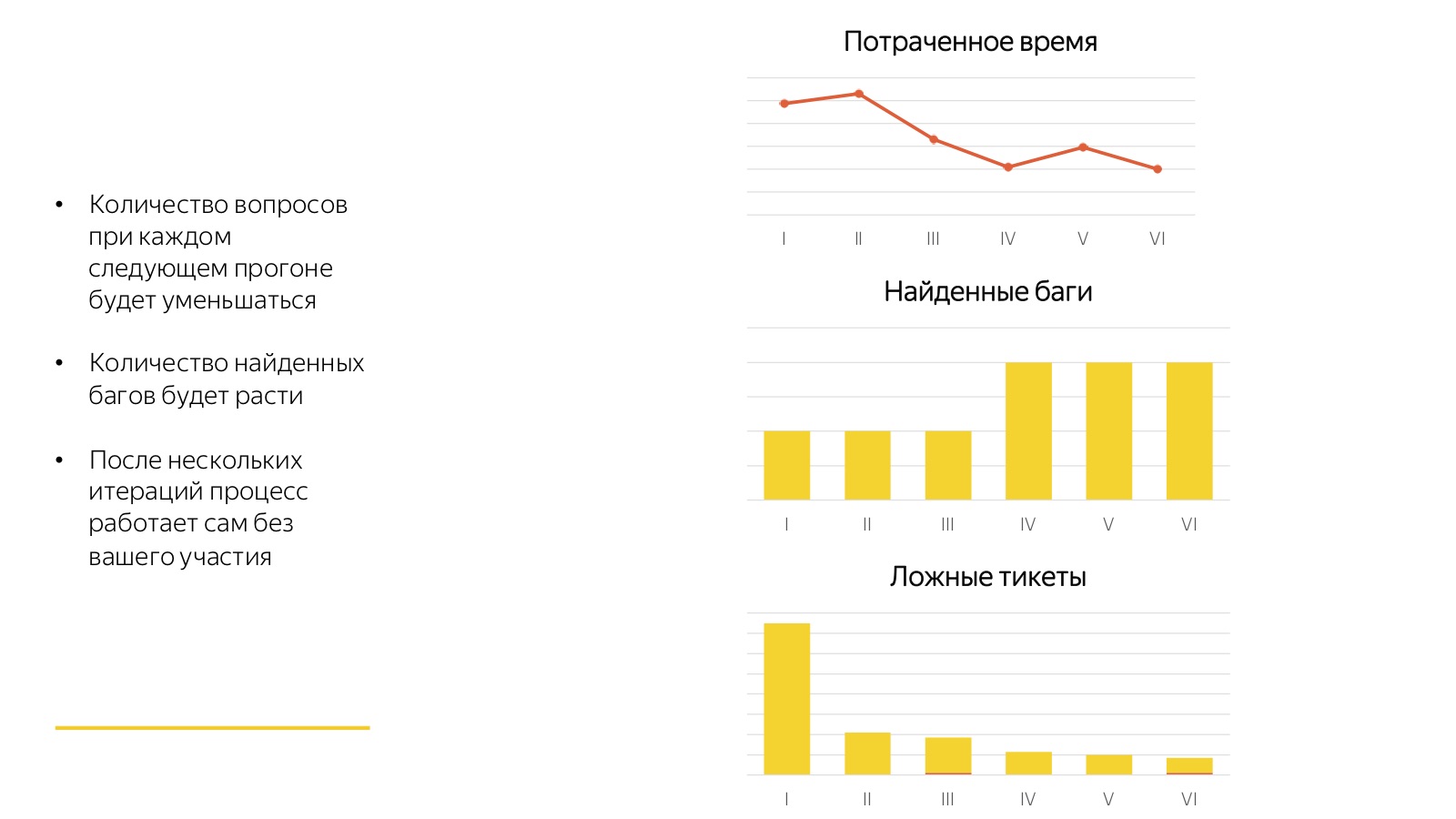
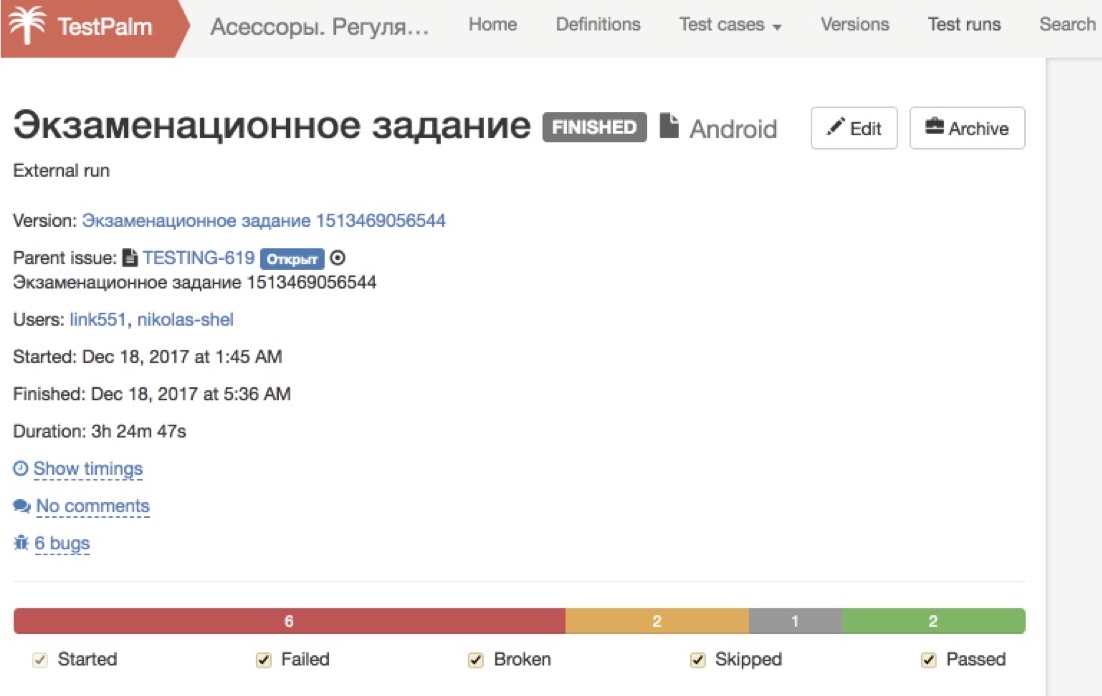
Ces horreurs dont je parle ne sont pas si terribles. La bonne nouvelle est que tous ces processus convergent très rapidement. Tout premier lancement est toujours très mauvais. Dans l'image ci-dessus, 6 départs consécutifs de la même régression sont visibles.
Regardez combien de temps les membres du personnel ont consacré à répondre aux questions, pour la première fois lorsque les évaluateurs ne comprenaient pas de quoi ils parlaient et ce qu'ils attendaient d'eux. Ils ont trouvé quelques bugs, ils ont commencé beaucoup de tickets pour rien du tout. Par conséquent, la première fois est horreur-horreur-horreur, la deuxième fois est horreur-horreur et la troisième fois, 80% de tous les processus convergent. Et puis vient le processus élaboré: les évaluateurs s'habituent à la nouvelle tâche, et après chaque lancement, nous recueillons des commentaires, complétons les cas de test et trions quelque chose. Et il se révèle une usine sympa qui fonctionne au clic d'un bouton et ne nécessite aucune implication d'un spécialiste à temps plein.
3. Contrôle qualité
Un point très important, sans lequel tout cela ne fonctionnera pas, est le contrôle de la qualité.
Nos évaluateurs travaillent sur des salaires à la pièce: toutes leurs tâches sont très clairement réglementées et quantifiées, chaque unité de travail a son propre tarif standard, et ils sont payés pour le nombre d'unités terminées. Toloka fonctionne exactement de la même manière, et en général n'importe quelle foule. Ce système présente de nombreux avantages, il est très flexible, mais il a aussi ses inconvénients. Dans un système à rémunération à la pièce, tout entrepreneur tentera d'optimiser son travail - consacrera le moins de temps et d'efforts possible à la tâche pour obtenir beaucoup plus d'argent par unité de temps. Par conséquent, tout système basé sur le crowdsourcing est garanti de fonctionner avec la qualité minimale que vous lui permettez. Si vous n'avez aucun contrôle sur la qualité, elle tombera aussi bas que possible.
La bonne nouvelle est que vous pouvez le combattre, il peut être contrôlé. Si nous pouvons quantifier la qualité du travail, la tâche se résume à une tâche assez simple. C'est en théorie. En pratique, ce n'est pas si simple du tout, en particulier dans les tâches de test. Parce que les tests, contrairement à de nombreuses autres tâches de masse que nous avons résolues avec l'aide d'évaluateurs, traitent d'événements rares et toutes sortes de statistiques fonctionnent très mal là-bas. Il est très difficile de comprendre à quelle fréquence une personne trouve effectivement des bogues, si en principe il y a très peu de bogues. Par conséquent, nous devons pervertir et utiliser plusieurs méthodes de contrôle de la qualité à la fois, qui ensemble nous donneront une certaine image de la qualité avec laquelle l'interprète travaille.
Le premier est une vérification du chevauchement. "Chevauchement" signifie que nous assignons chaque tâche à plusieurs personnes. Nous le faisons naturellement, car chaque scénario de test doit être testé dans plusieurs environnements. Ainsi, il s'avère que le même cas de test a été vérifié dans les environnements A, B et C. Nous avons trois résultats de trois personnes - passant le même cas de test. Ensuite, nous examinons si les résultats ont divergé.
Il arrive parfois qu'un bogue ait été trouvé dans un environnement, mais pas dans deux autres. C'est peut-être vraiment le cas, ou peut-être l'erreur de quelqu'un: soit une personne a trouvé un bug supplémentaire, soit ces deux ont triché et n'ont rien trouvé. En tout cas, c'est un cas suspect. Si nous rencontrons cela, nous envoyons une nouvelle vérification supplémentaire afin de nous assurer et de vérifier qui avait raison et qui était à blâmer. Un tel schéma nous permet d'attraper des personnes qui, par exemple, ont commencé des tickets supplémentaires là où elles n'étaient pas nécessaires, ou ont raté où elles étaient nécessaires. Dans le même temps, nous regardons à quel point le ticket a été correctement ouvert, si tout est conforme à la procédure: des captures d'écran sont-elles ajoutées, si nécessaire, une description claire est ajoutée, etc.
En plus de cela, et surtout cela ne concerne que l'exactitude de la billetterie, il est agréable et pratique de contrôler automatiquement certaines choses qui, d'une part, semblent être des bagatelles, mais, d'autre part, affectent assez fortement le flux de travail. Par conséquent, nous vérifions automatiquement s'il existe une application sur le ticket, si des captures d'écran sont ajoutées, s'il y a des commentaires dans le ticket ou s'il a simplement été fermé sans regarder combien de temps a été consacré à celui-ci afin d'identifier les cas suspects. Ici, vous pouvez trouver de nombreuses heuristiques différentes et les appliquer. Le processus est presque sans fin.
Vérifier les chevauchements est une bonne chose, mais cela donne une évaluation quelque peu biaisée, car nous ne vérifions que les cas controversés. Parfois, vous voulez faire une vérification ponctuelle honnête. Pour ce faire, nous utilisons des séries de tests. Au stade de la formation, nous avions des assemblages de tests spécialement assemblés dans lesquels nous savons à l'avance où il y a des bugs et où non. Nous utilisons des lancements similaires pour le contrôle de la qualité et vérifions combien de bogues une personne a trouvé et combien manqués. C'est une façon cool, cela donne l'image la plus complète du monde. Mais il est assez coûteux à utiliser: alors que nous collectons encore un nouvel ensemble de test ... Nous utilisons cette approche assez rarement, tous les quelques mois.
Dernier point important: même si nous avons déjà tout fait, nous devons absolument analyser pourquoi les bugs ont été sautés. Nous vérifions s'il était possible de trouver ce bogue par les étapes du cas de test. Si c'était possible, mais que la personne a raté, alors, alors, la personne est une tasse, et vous devez avoir un certain effet sur elle. Et si ce cas n'était pas là, vous devez en quelque sorte compléter, mettre à jour les cas de test.
Par conséquent, nous réduisons tous les paramètres de qualité en une seule évaluation des évaluateurs, ce qui affecte leur carrière et leur sort dans notre système. Plus la note d’une personne est élevée, plus elle reçoit des tâches difficiles et réclame des prix. Plus la cote de l'évaluateur est faible, plus il est probable qu'elle soit renvoyée. Quand une personne travaille de façon stable avec une cote basse, nous nous séparons finalement de lui.
4. Délégation
Le tout dernier pilier de notre système pyramidal évolutif dont je veux parler concerne les tâches de délégation.
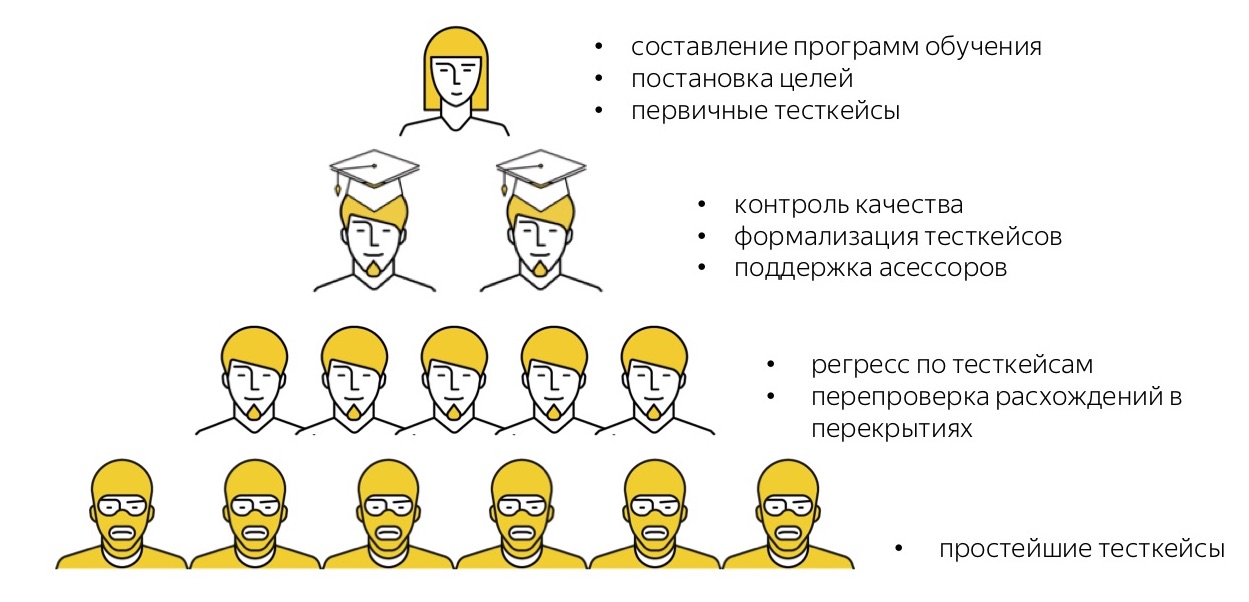
Je rappellerai à nouveau à quoi ressemble notre pyramide pour les tâches de test manuelles. Nous avons des personnes «de haut niveau» - ce sont des testeurs à plein temps, des représentants de l'équipe de service qui composent des programmes de formation pour le service dont ils ont besoin pour tester, forment une stratégie pour ce qui doit être testé, écrivent des cas de test principaux sous forme gratuite.
De plus, nous avons les évaluateurs les plus talentueux qui transfèrent les cas de test de forme libre à ceux formalisés, aident d'autres évaluateurs, les soutiennent dans les salles de chat et effectuent des recoupements et un contrôle qualité sélectif.
De plus, il y a un nuage de nos nombreux interprètes qui effectuent la régression étape par étape.
Ensuite, nous avons Toloka, dont nous n'avons pas oublié. Nous sommes maintenant au stade des expériences: nous comprenons que les cas les plus simples peuvent être donnés pour des tests à une foule impersonnelle à Toloka.
Ce sera beaucoup moins cher et plus rapide, car il y a encore plus d'artistes là-bas. Mais pendant que nous sommes en train de construire ce système. Maintenant, nous ne donnons que le plus simple, mais j'espère que dans quelques mois nous arriverons au fait que nous y déléguerons davantage. Il est très important de surveiller le bon développement de cette pyramide. Premièrement (de telles questions me sont souvent posées, je souhaite donc y répondre de manière proactive), le crowdsourcing n'est pas un rejet du travail de spécialistes de haut niveau en faveur des foules, mais un outil de scaling. Nous ne pouvons pas refuser le sommet de cette pyramide, notre «tête», nous ne pouvons utiliser le crowdsourcing que pour ajouter plus de mains à ce système, il est donc très facile de le faire évoluer gratuitement.Deuxièmement, ce n'est pas sorcier, mais vous devez constamment vous en souvenir: toute l'histoire fonctionne bien et correctement si les tâches les plus difficiles pour ce niveau sont résolues à chaque niveau. En gros, si la même chose peut être faite à plusieurs niveaux de la pyramide, cela doit être fait à son niveau le plus bas. Ce n'est pas une histoire statique, mais dynamique. Nous commençons par le fait que seules les personnes "de haut niveau" peuvent effectuer certaines tâches, affiner progressivement le processus et réduire ces tâches ci-dessous, en adaptant et en réduisant le coût de l'ensemble du processus.Et j'entends assez souvent une telle remarque: "Pourquoi s'embêter avec ce jardin, il vaut mieux tout automatiser et y dépenser de l'énergie." Mais le crowdsourcing ne remplace pas l'automatisation, c'est une chose parallèle. Nous ne le faisons pas au lieu de l'automatisation, mais en plus. Un tel système nous permet simplement de libérer des travailleurs qui pourraient être engagés dans l'automatisation, d'une part, et, d'autre part, formaliser assez bien le processus, qui sera alors beaucoup plus facile à automatiser.
Il est très important de surveiller le bon développement de cette pyramide. Premièrement (de telles questions me sont souvent posées, je souhaite donc y répondre de manière proactive), le crowdsourcing n'est pas un rejet du travail de spécialistes de haut niveau en faveur des foules, mais un outil de scaling. Nous ne pouvons pas refuser le sommet de cette pyramide, notre «tête», nous ne pouvons utiliser le crowdsourcing que pour ajouter plus de mains à ce système, il est donc très facile de le faire évoluer gratuitement.Deuxièmement, ce n'est pas sorcier, mais vous devez constamment vous en souvenir: toute l'histoire fonctionne bien et correctement si les tâches les plus difficiles pour ce niveau sont résolues à chaque niveau. En gros, si la même chose peut être faite à plusieurs niveaux de la pyramide, cela doit être fait à son niveau le plus bas. Ce n'est pas une histoire statique, mais dynamique. Nous commençons par le fait que seules les personnes "de haut niveau" peuvent effectuer certaines tâches, affiner progressivement le processus et réduire ces tâches ci-dessous, en adaptant et en réduisant le coût de l'ensemble du processus.Et j'entends assez souvent une telle remarque: "Pourquoi s'embêter avec ce jardin, il vaut mieux tout automatiser et y dépenser de l'énergie." Mais le crowdsourcing ne remplace pas l'automatisation, c'est une chose parallèle. Nous ne le faisons pas au lieu de l'automatisation, mais en plus. Un tel système nous permet simplement de libérer des travailleurs qui pourraient être engagés dans l'automatisation, d'une part, et, d'autre part, formaliser assez bien le processus, qui sera alors beaucoup plus facile à automatiser.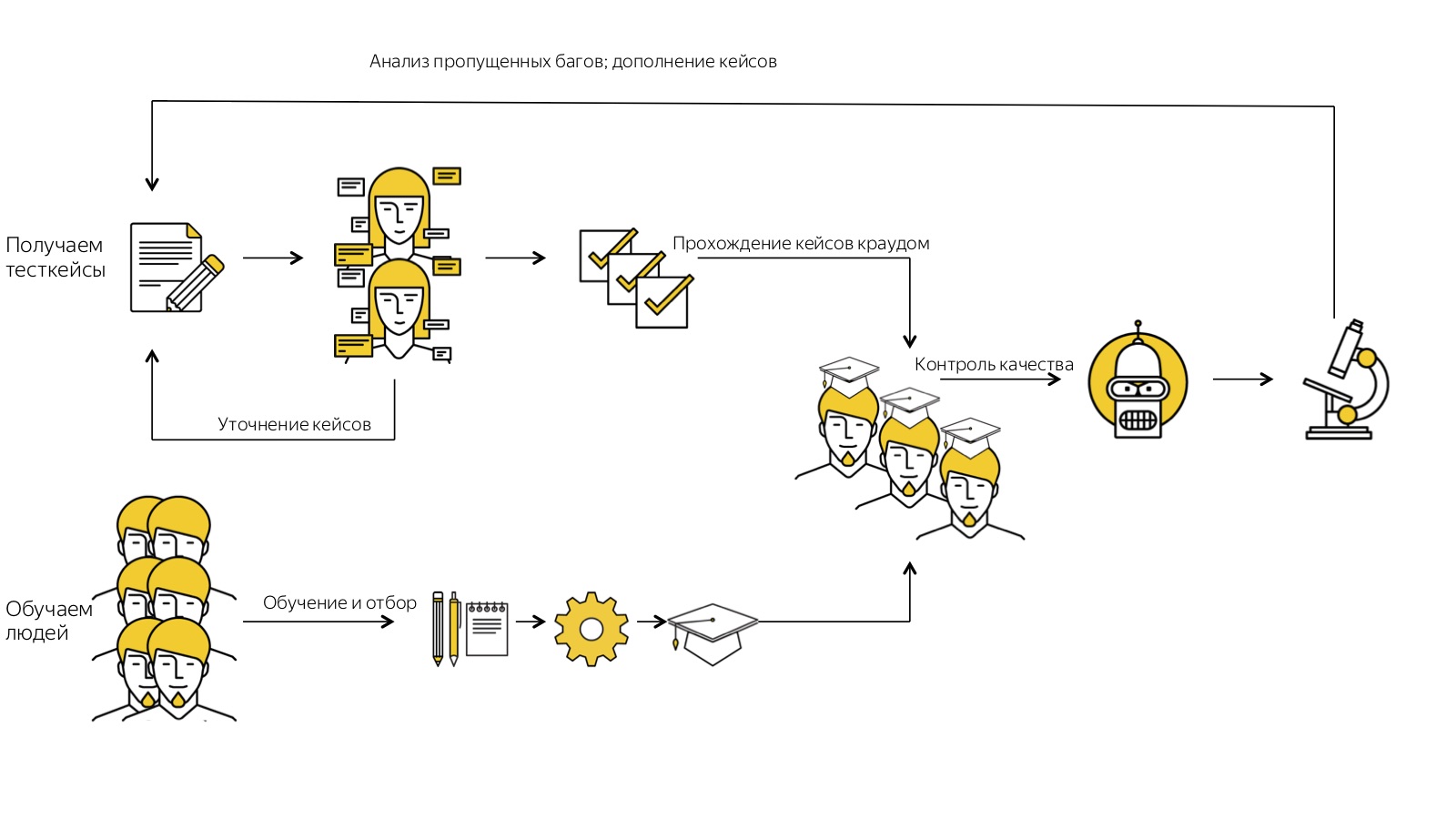 Au final, je rappellerai encore une fois à quoi ressemble toute notre histoire. Nous commençons par obtenir des cas de test sous forme gratuite. Nous les exécutons plusieurs fois par le biais d'évaluateurs, collectons des commentaires, précisons-les. Après cela, nous obtenons des cas de test cool, déjà léchés. Parallèlement à cela, nous recrutons beaucoup, beaucoup de gens, les soumettons au système de formation automatique et à la sortie, nous n'obtenons que ceux qui ont pu faire face à toutes les étapes par eux-mêmes et ont réalisé ce que nous voulions de lui. Nous obtenons une foule formée. Il travaille pour nous avec des cas de test formalisés, et nous contrôlons sa qualité: nous le vérifions en permanence, analysons les cas avec des bugs manqués afin d'améliorer nos processus.Et un tel système fonctionne pour nous, vole. Je ne sais pas si mon histoire sera utile en ce moment à quelqu'un d'un point de vue pratique, mais j'espère que cela nous permettra de réfléchir un peu plus largement et de supposer que certaines tâches peuvent être résolues de cette façon. Parce que - et nous rencontrons souvent cela - l'un de vous pourrait déjà se surprendre à penser: «Eh bien, peut-être que cela fonctionne quelque part, mais certainement pas pour moi. J'ai des tâches tellement difficiles que ça ne me concerne pas du tout. » Mais notre expérience suggère que pratiquement toutes les tâches de presque tous les domaines, si elles sont correctement décomposées, formalisées et intégrées dans un processus clair, peuvent être mises à l'échelle au moins partiellement avec l'aide de la foule.
Au final, je rappellerai encore une fois à quoi ressemble toute notre histoire. Nous commençons par obtenir des cas de test sous forme gratuite. Nous les exécutons plusieurs fois par le biais d'évaluateurs, collectons des commentaires, précisons-les. Après cela, nous obtenons des cas de test cool, déjà léchés. Parallèlement à cela, nous recrutons beaucoup, beaucoup de gens, les soumettons au système de formation automatique et à la sortie, nous n'obtenons que ceux qui ont pu faire face à toutes les étapes par eux-mêmes et ont réalisé ce que nous voulions de lui. Nous obtenons une foule formée. Il travaille pour nous avec des cas de test formalisés, et nous contrôlons sa qualité: nous le vérifions en permanence, analysons les cas avec des bugs manqués afin d'améliorer nos processus.Et un tel système fonctionne pour nous, vole. Je ne sais pas si mon histoire sera utile en ce moment à quelqu'un d'un point de vue pratique, mais j'espère que cela nous permettra de réfléchir un peu plus largement et de supposer que certaines tâches peuvent être résolues de cette façon. Parce que - et nous rencontrons souvent cela - l'un de vous pourrait déjà se surprendre à penser: «Eh bien, peut-être que cela fonctionne quelque part, mais certainement pas pour moi. J'ai des tâches tellement difficiles que ça ne me concerne pas du tout. » Mais notre expérience suggère que pratiquement toutes les tâches de presque tous les domaines, si elles sont correctement décomposées, formalisées et intégrées dans un processus clair, peuvent être mises à l'échelle au moins partiellement avec l'aide de la foule.Heisenbug 2018 Piter , : 6-7 Heisenbug , , .