 Traduction d' une visite guidée complète d'un projet d'apprentissage automatique en Python: première partie .
Traduction d' une visite guidée complète d'un projet d'apprentissage automatique en Python: première partie .Lorsque vous lisez un livre ou écoutez un cours de formation sur l'analyse des données, vous avez souvent l'impression que vous êtes face à des parties distinctes d'une image qui ne peuvent pas être assemblées. Vous pouvez être effrayé par la perspective de passer à l'étape suivante et de résoudre complètement un problème à l'aide de l'apprentissage automatique, mais avec l'aide de cette série d'articles, vous gagnerez en confiance dans la capacité de résoudre tout problème dans le domaine de la science des données.
Afin que vous ayez enfin une image complète dans votre tête, nous vous suggérons d'analyser du début à la fin le projet d'utilisation du machine learning en utilisant des données réelles.
Suivez successivement les étapes:
- Nettoyage et formatage des données.
- Analyse exploratoire des données.
- Conception et sélection de fonctionnalités.
- Comparaison des métriques de plusieurs modèles d'apprentissage automatique.
- Réglage hyperparamétrique du meilleur modèle.
- Évaluation du meilleur modèle sur un ensemble de données de test.
- Interprétation des résultats du modèle.
- Conclusions et travail avec des documents.
Vous apprendrez comment les étapes s'enchaînent et comment les implémenter en Python.
L'ensemble du projet est disponible sur GitHub, la première partie se trouve
ici. Dans cet article, nous considérerons les trois premières étapes.
Description de la tâche
Avant d'écrire du code, vous devez comprendre le problème résolu et les données disponibles. Dans ce projet, nous travaillerons avec
des données d'efficacité énergétique accessibles au public
pour les bâtiments de New York.
Notre objectif: utiliser les données disponibles pour construire un modèle qui prédit le nombre de Energy Star Score pour un bâtiment particulier, et interpréter les résultats pour trouver des facteurs qui influencent le score final.
Les données incluent déjà le score Energy Star attribué, notre tâche est donc l'apprentissage automatique avec régression contrôlée:
- Supervisé: Nous connaissons les signes et le but, et notre tâche est de former un modèle qui peut comparer le premier avec le second.
- Régression: le score Energy Star est une variable continue.
Notre modèle doit être précis - afin qu'il puisse prédire la valeur du score Energy Star proche de la vérité - et interprétable - afin que nous puissions comprendre ses prédictions. Connaissant les données cibles, nous pouvons les utiliser pour prendre des décisions à mesure que nous approfondissons les données et créons le modèle.
Nettoyage des données
Tous les ensembles de données ne sont pas un ensemble d'observations parfaitement assorties, sans anomalies et valeurs manquantes (un indice des
jeux de données mtcars et
iris ). Dans les données réelles, il y a peu d'ordre, donc avant de commencer l'analyse, vous devez l'
effacer et la mettre dans un format acceptable. Le nettoyage des données est une procédure désagréable mais obligatoire pour résoudre la plupart des tâches d'analyse des données.
Tout d'abord, vous pouvez charger les données sous la forme d'une trame de données Pandas et les examiner:
import pandas as pd import numpy as np # Read in data into a dataframe data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv') # Display top of dataframe data.head()
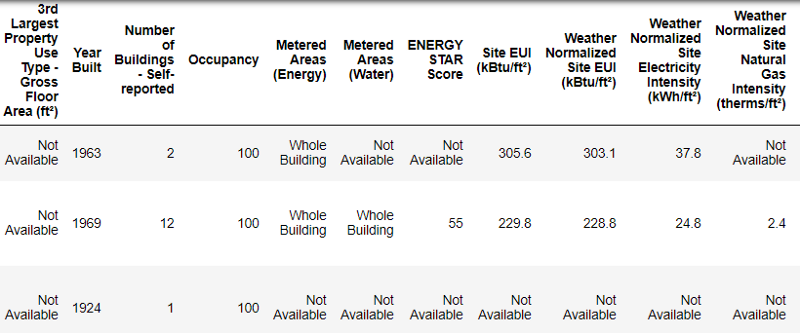 Voilà à quoi ressemblent les vraies données.
Voilà à quoi ressemblent les vraies données.Ceci est un fragment d'un tableau de 60 colonnes. Même ici, plusieurs problèmes sont visibles: nous devons prédire le
Energy Star Score , mais nous ne savons pas ce que signifient toutes ces colonnes. Bien que ce ne soit pas nécessairement un problème, car vous pouvez souvent créer un modèle précis sans rien savoir des variables. Mais l'interprétabilité est importante pour nous, nous devons donc trouver la signification d'au moins quelques colonnes.
Lorsque nous avons reçu ces données, nous n'avons pas posé de questions sur les valeurs, mais nous avons examiné le nom du fichier:
et a décidé de rechercher «Local Law 84». Nous avons trouvé
cette page , qui disait que nous parlons de la loi en vigueur à New York, selon laquelle les propriétaires de tous les bâtiments d'une certaine taille devraient rendre compte de la consommation d'énergie. Une recherche supplémentaire a permis de trouver
toutes les valeurs de colonne . Ne négligez donc pas les noms de fichiers, ils peuvent être un bon point de départ. De plus, c'est un rappel que vous ne vous précipitez pas et ne manquez pas quelque chose d'important!
Nous n'étudierons pas toutes les colonnes, mais nous traiterons certainement du score Energy Star, qui est décrit comme suit:
Le rang centile est compris entre 1 et 100, qui est calculé sur la base des rapports annuels sur la consommation d'énergie par les propriétaires de bâtiments eux-mêmes. Le Energy Star Score est une mesure relative utilisée pour comparer la performance énergétique des bâtiments.
Le premier problème a été résolu, mais le second est resté - des valeurs manquantes, marquées comme «Non disponible». Il s'agit d'une valeur de chaîne en Python, ce qui signifie que même les chaînes avec des nombres seront stockées en tant que types de données d'
object , car s'il y a une chaîne dans la colonne, Pandas la convertit en une colonne entièrement constituée de chaîne. Les types de données de colonne peuvent être trouvés en utilisant la méthode
dataframe.info() :
# See the column data types and non-missing values data.info()
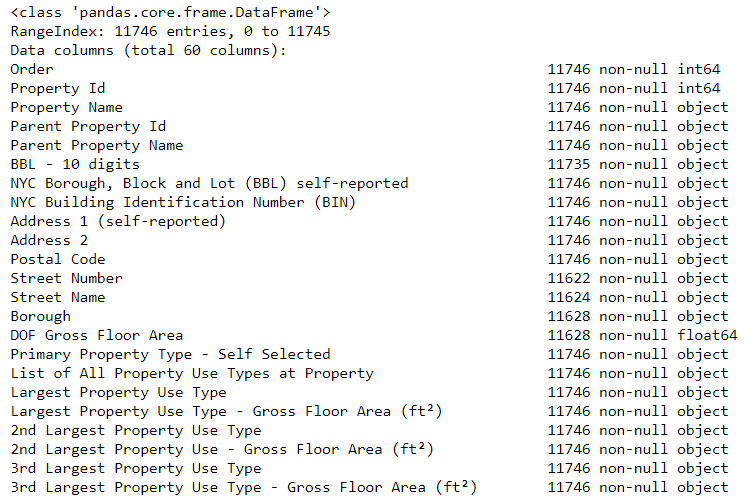
Certes, certaines colonnes qui contiennent explicitement des nombres (comme ft²) sont stockées en tant qu'objets. Nous ne pouvons pas appliquer l'analyse numérique aux valeurs de chaîne, nous les convertissons donc en types de données numériques (en particulier
float )!
Ce code remplace d'abord tous les «Non disponibles» par
pas un nombre (
np.nan ), qui peut être interprété comme des nombres, puis convertit le contenu de certaines colonnes en un type
float :
# Replace all occurrences of Not Available with numpy not a number data = data.replace({'Not Available': np.nan}) # Iterate through the columns for col in list(data.columns): # Select columns that should be numeric if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in col or 'therms' in col or 'gal' in col or 'Score' in col): # Convert the data type to float data[col] = data[col].astype(float)
Lorsque les valeurs dans les colonnes correspondantes avec nous deviennent des nombres, nous pouvons commencer à examiner les données.
Données manquantes et anormales
Outre les types de données incorrects, l'un des problèmes les plus courants est l'absence de valeurs. Ils peuvent être absents pour diverses raisons et avant de former le modèle, ces valeurs doivent être remplies ou supprimées. Tout d'abord, découvrons combien de valeurs nous avons dans chaque colonne (le
code est ici ).
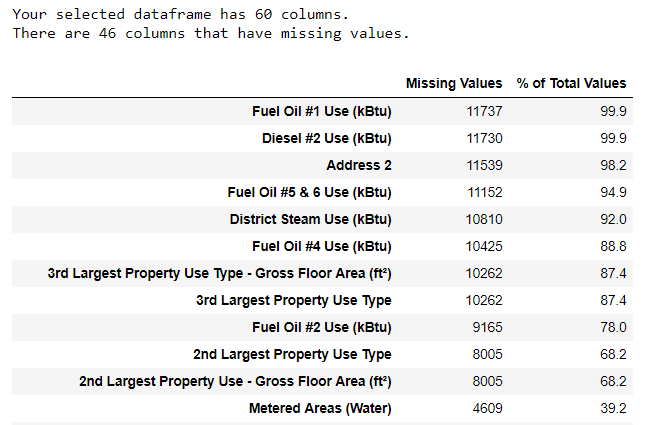 Pour créer une table, une fonction d'une branche sur StackOverflow a été utilisée .
Pour créer une table, une fonction d'une branche sur StackOverflow a été utilisée .Les informations doivent toujours être supprimées avec prudence, et s'il existe de nombreuses valeurs dans la colonne, cela ne profitera probablement pas à notre modèle. Le seuil après lequel il est préférable de jeter les colonnes dépend de votre tâche (
voici une discussion ), et dans notre projet, nous supprimerons les colonnes qui sont plus de la moitié vides.
À ce stade également, il est préférable de supprimer les valeurs anormales. Ils peuvent se produire en raison de fautes de frappe lors de la saisie de données ou en raison d'erreurs dans les unités de mesure, ou ils peuvent être corrects, mais des valeurs extrêmes. Dans ce cas, nous supprimerons les valeurs "extra", guidées par la
définition des anomalies extrêmes :
- Sous le premier quartile se trouve une plage interquartile de 3 ∗.
- Au-dessus du troisième quartile + 3 ∗ intervalle interquartile.
Le code qui supprime les colonnes et les anomalies est répertorié sur le Bloc-notes sur Github. À la fin du processus de nettoyage des données et de la suppression des anomalies, nous avons plus de 11 000 bâtiments et 49 panneaux.
Analyse exploratoire des données
L'étape ennuyeuse mais nécessaire du nettoyage des données est terminée, vous pouvez aller à l'étude!
L'analyse des données exploratoires (RAD) est un processus à durée illimitée au cours duquel nous calculons des statistiques et recherchons des tendances, des anomalies, des modèles ou des relations dans les données.
En bref, RAD est une tentative de comprendre ce que les données peuvent nous dire. Habituellement, l'analyse commence par une revue superficielle, puis nous trouvons des fragments intéressants et les analysons plus en détail. Les résultats peuvent être intéressants en soi, ou ils peuvent contribuer au choix du modèle, aidant à décider quelles fonctionnalités nous utiliserons.
Graphes à variable unique
Notre objectif est de prédire la valeur du score Energy Star (renommé notre
score dans nos données), il est donc logique de commencer par examiner la distribution de cette variable. Un histogramme est un moyen simple mais efficace de visualiser la distribution d'une seule variable, et il peut être facilement construit à l'aide de
matplotlib .
import matplotlib.pyplot as plt # Histogram of the Energy Star Score plt.style.use('fivethirtyeight') plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k'); plt.xlabel('Score'); plt.ylabel('Number of Buildings'); plt.title('Energy Star Score Distribution');
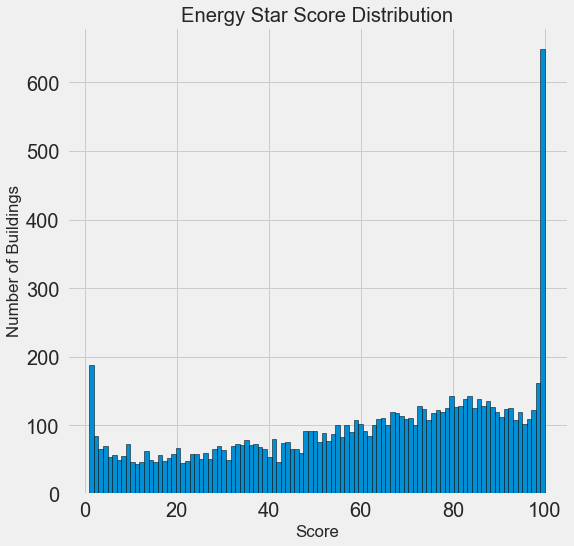
Ça a l'air suspect! Le score Energy Star est un centile, vous devez donc vous attendre à une distribution uniforme lorsque chaque point est attribué au même nombre de bâtiments. Cependant, un nombre disproportionnellement élevé de bâtiments a obtenu les résultats les plus élevés et les plus bas (pour le Energy Star Score, le plus grand est le mieux).
Si nous regardons à nouveau la définition de ce score, nous verrons qu'il est calculé sur la base de «rapports remplis indépendamment par les propriétaires d'immeubles», ce qui peut expliquer l'excès de très grandes valeurs. Demander aux propriétaires de bâtiments de déclarer leur consommation d'énergie, c'est comme demander aux étudiants de déclarer leurs notes aux examens. Ce n'est donc peut-être pas le critère le plus objectif pour évaluer l'efficacité énergétique d'un bien immobilier.
Si nous avions une quantité illimitée de temps, nous pourrions découvrir pourquoi tant de bâtiments ont obtenu des points très élevés et très bas. Pour ce faire, il faudrait choisir les bâtiments appropriés et les analyser soigneusement. Mais nous devons seulement apprendre à prédire les scores et ne pas développer une méthode d'évaluation plus précise. Vous pouvez noter que les points ont une distribution suspecte, mais nous nous concentrerons sur les prévisions.
Recherche de relation
La partie principale de l'AHFR est la recherche de la relation entre les signes et notre objectif. Les variables en corrélation avec lui sont utiles pour une utilisation dans le modèle, car elles peuvent être utilisées pour la prévision. Une façon d'étudier l'effet d'une variable catégorielle (qui ne prend qu'un ensemble limité de valeurs) sur l'objectif est de tracer la densité à l'aide de la bibliothèque Seaborn.
Le graphique de densité peut être considéré comme un histogramme lissé car il montre la distribution d'une seule variable. Vous pouvez coloriser des classes individuelles sur le graphique pour voir comment une variable catégorielle modifie la distribution. Ce code trace le graphique de densité Energy Star Score, coloré selon le type de bâtiment (pour une liste de bâtiments de plus de 100 dimensions):
# Create a list of buildings with more than 100 measurements types = data.dropna(subset=['score']) types = types['Largest Property Use Type'].value_counts() types = list(types[types.values > 100].index) # Plot of distribution of scores for building categories figsize(12, 10) # Plot each building for b_type in types: # Select the building type subset = data[data['Largest Property Use Type'] == b_type] # Density plot of Energy Star Scores sns.kdeplot(subset['score'].dropna(), label = b_type, shade = False, alpha = 0.8); # label the plot plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20); plt.title('Density Plot of Energy Star Scores by Building Type', size = 28);
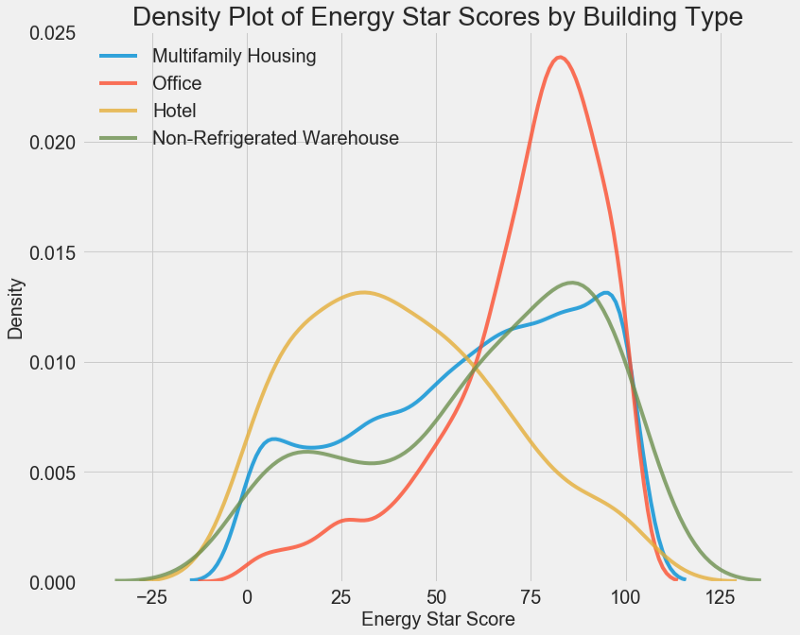
Comme vous pouvez le voir, le type de bâtiment affecte considérablement le nombre de points. Les immeubles de bureaux ont généralement un score plus élevé et les hôtels plus bas. Vous devez donc inclure le type de bâtiment dans le modèle, car ce signe affecte notre objectif. En tant que variable catégorielle, nous devons effectuer un codage à chaud du type de bâtiment.
Un graphique similaire peut être utilisé pour estimer le score Energy Star par quartier de ville:
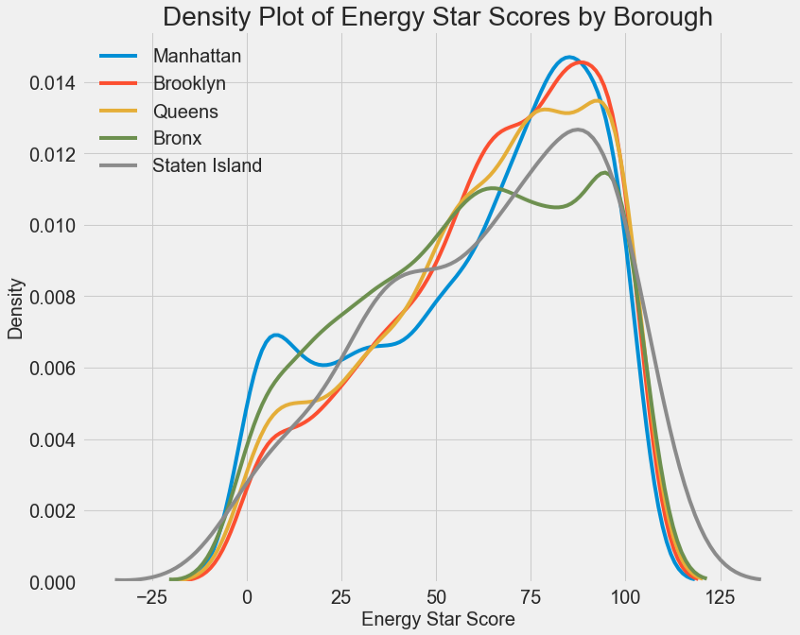
La zone n'affecte pas autant le score que le type de bâtiment. Néanmoins, nous l'inclurons dans le modèle, car il existe une légère différence entre les régions.
Pour calculer la relation entre les variables, vous pouvez utiliser
le coefficient de corrélation de Pearson . Il s'agit d'une mesure de l'intensité et de la direction d'une relation linéaire entre deux variables. Une valeur de +1 signifie une relation positive parfaitement linéaire et -1 signifie une relation négative parfaitement linéaire. Voici quelques exemples de valeurs de
coefficient de corrélation de
Pearson :

Bien que ce coefficient ne puisse pas refléter les dépendances non linéaires, il est possible de commencer par lui pour évaluer les relations des variables. Dans Pandas, vous pouvez facilement calculer les corrélations entre toutes les colonnes d'une trame de données:
# Find all correlations with the score and sort correlations_data = data.corr()['score'].sort_values()
Les corrélations les plus négatives avec l'objectif:

et le plus positif:

Il existe plusieurs fortes corrélations négatives entre les attributs et l'objectif, et les plus importants d'entre eux appartiennent à différentes catégories d'IUE (les méthodes de calcul de ces indicateurs diffèrent légèrement).
EUI (Energy Use Intensity ) est la quantité d'énergie consommée par un bâtiment divisée par un pied carré de surface. Cette valeur spécifique est utilisée pour évaluer l'efficacité énergétique, et plus elle est petite, mieux c'est. La logique suggère que ces corrélations sont justifiées: si l'EUI augmente, alors le Energy Star Score devrait diminuer.
Graphiques à deux variables
Nous utilisons des nuages de points pour visualiser les relations entre deux variables continues. Vous pouvez ajouter des informations supplémentaires aux couleurs des points, par exemple une variable catégorielle. La relation entre l'Energy Star Score et l'IUE est illustrée ci-dessous, les couleurs indiquent différents types de bâtiments:
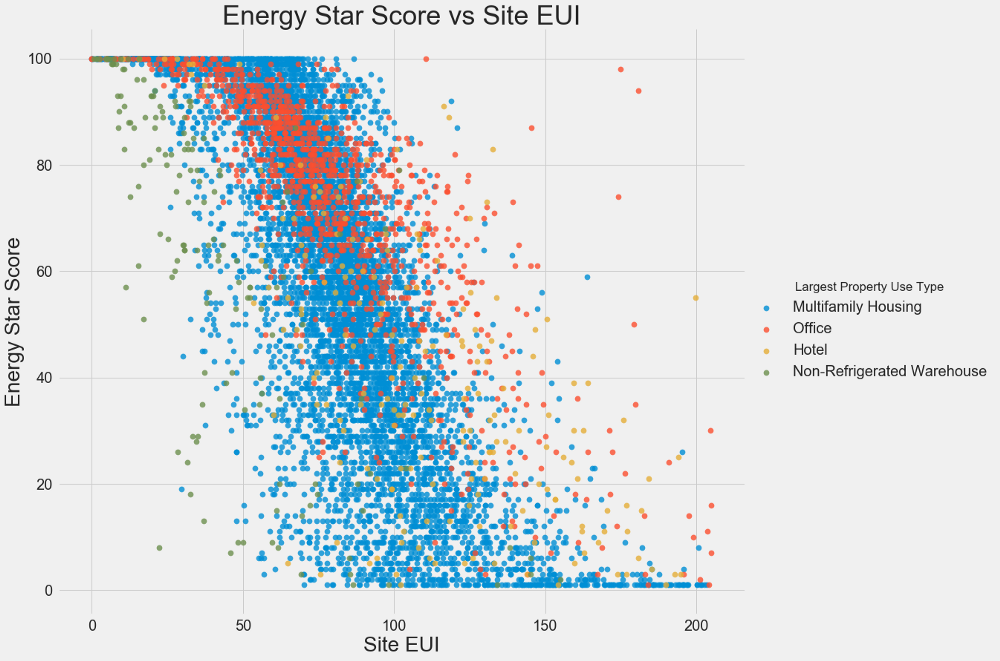
Ce graphique vous permet de visualiser un coefficient de corrélation de -0,7. À mesure que l'IUE diminue, le score Energy Star augmente, cette relation est observée dans différents types de bâtiments.
Notre dernier tableau de recherche s'appelle le
tracé des paires . C'est un excellent outil pour voir les relations entre différentes paires de variables et la distribution de variables uniques. Nous utiliserons la bibliothèque Seaborn et la fonction PairGrid pour créer un diagramme de paires avec un diagramme de dispersion dans le triangle supérieur, avec un histogramme diagonal, un diagramme de densité de noyau bidimensionnel et des coefficients de corrélation dans le triangle inférieur.
# Extract the columns to plot plot_data = features[['score', 'Site EUI (kBtu/ft²)', 'Weather Normalized Source EUI (kBtu/ft²)', 'log_Total GHG Emissions (Metric Tons CO2e)']] # Replace the inf with nan plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan}) # Rename columns plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI', 'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI', 'log_Total GHG Emissions (Metric Tons CO2e)': 'log GHG Emissions'}) # Drop na values plot_data = plot_data.dropna() # Function to calculate correlation coefficient between two columns def corr_func(x, y, **kwargs): r = np.corrcoef(x, y)[0][1] ax = plt.gca() ax.annotate("r = {:.2f}".format(r), xy=(.2, .8), xycoords=ax.transAxes, size = 20) # Create the pairgrid object grid = sns.PairGrid(data = plot_data, size = 3) # Upper is a scatter plot grid.map_upper(plt.scatter, color = 'red', alpha = 0.6) # Diagonal is a histogram grid.map_diag(plt.hist, color = 'red', edgecolor = 'black') # Bottom is correlation and density plot grid.map_lower(corr_func); grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds) # Title for entire plot plt.suptitle('Pairs Plot of Energy Data', size = 36, y = 1.02);
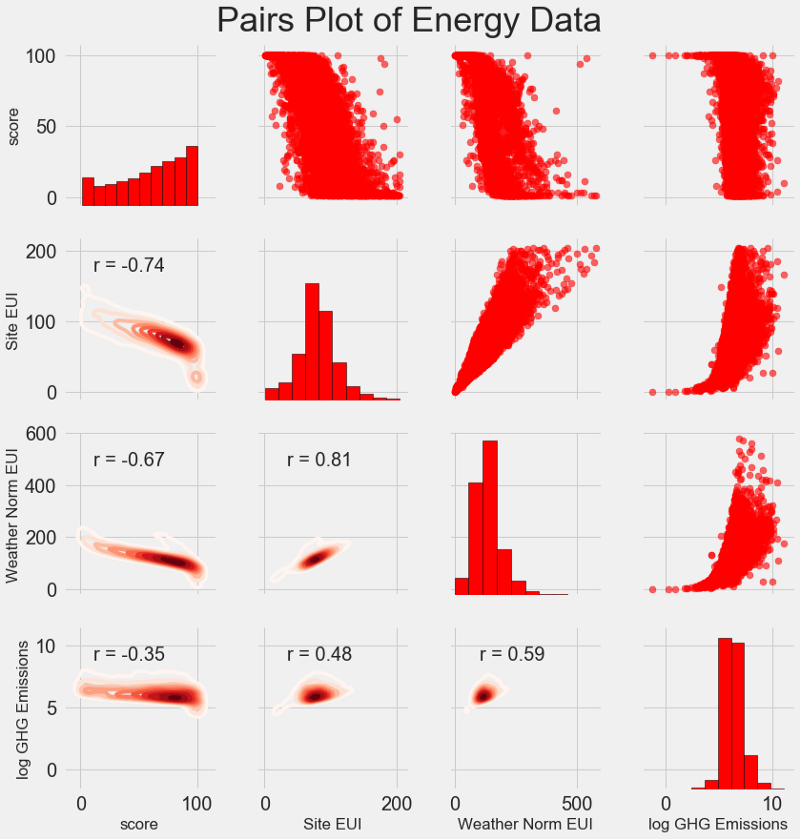
Pour voir la relation des variables, recherchez l'intersection des lignes et des colonnes. Supposons que vous vouliez regarder la corrélation entre la
Weather Norm EUI et le
score , alors nous recherchons la série
Weather Norm EUI et la colonne de
score , à l'intersection de laquelle il existe un coefficient de corrélation de -0,67. Ces graphiques ont non seulement l'air cool, mais aident également à choisir les variables pour le modèle.
Conception et sélection de fonctionnalités
La conception et la sélection de fonctionnalités apportent souvent le meilleur rendement en termes de temps consacré à l'apprentissage automatique. Nous donnons d'abord les définitions:
- Construction de caractéristiques: processus d'extraction ou de création de nouvelles caractéristiques à partir de données brutes. Pour utiliser des variables dans le modèle, vous devrez peut-être les transformer, par exemple, prendre le logarithme naturel, ou extraire la racine carrée, ou appliquer un codage à chaud des variables catégorielles. La conception caractéristique peut être considérée comme créant des fonctionnalités supplémentaires à partir de données brutes.
- Sélection des fonctionnalités: processus de sélection des fonctionnalités les plus pertinentes à partir des données, au cours duquel nous supprimons certaines fonctionnalités pour aider le modèle à mieux généraliser les nouvelles données afin d'obtenir un modèle plus interprétable. Le choix des signes peut être considéré comme la suppression du «superflu» afin qu'il ne reste que les plus importants.
Le modèle d'apprentissage automatique ne peut apprendre que des données que nous fournissons, il est donc extrêmement important de s'assurer que nous incluons toutes les informations pertinentes pour notre tâche. Si vous ne fournissez pas au modèle les données correctes, il ne pourra pas apprendre et ne produira pas de prévisions précises!
Nous ferons ce qui suit:
- Applicable aux variables catégorielles (trimestre et type de propriété) codage unique.
- Ajoutez le logarithme naturel de toutes les variables numériques.
Un codage à chaud est nécessaire pour inclure des variables catégorielles dans le modèle. L'algorithme d'apprentissage automatique ne pourra pas comprendre le type de "bureau", donc si le bâtiment est un bureau, on lui attribuera un signe de 1, et sinon un bureau, alors 0.
L'ajout d'entités transformées aidera le modèle à en savoir plus sur les relations non linéaires au sein des données. Dans l'analyse des données, il est normal
d'extraire des racines carrées, de prendre des logarithmes naturels ou de transformer les signes d'une manière ou d'une autre , cela dépend de la tâche spécifique ou de votre connaissance des meilleures techniques. Dans ce cas, nous ajouterons le logarithme naturel de tous les signes numériques.
Ce code sélectionne les signes numériques, calcule leurs logarithmes, sélectionne deux signes catégoriels, leur applique un codage à chaud et combine les deux ensembles en un seul. À en juger par la description, beaucoup de travail reste à faire, mais dans Pandas, tout est assez simple!
# Copy the original data features = data.copy() # Select the numeric columns numeric_subset = data.select_dtypes('number') # Create columns with log of numeric columns for col in numeric_subset.columns: # Skip the Energy Star Score column if col == 'score': next else: numeric_subset['log_' + col] = np.log(numeric_subset[col]) # Select the categorical columns categorical_subset = data[['Borough', 'Largest Property Use Type']] # One hot encode categorical_subset = pd.get_dummies(categorical_subset) # Join the two dataframes using concat # Make sure to use axis = 1 to perform a column bind features = pd.concat([numeric_subset, categorical_subset], axis = 1)
Nous avons maintenant plus de 11 000 observations (bâtiments) avec 110 colonnes (balises). Tous les signes ne seront pas utiles pour prédire le score Energy Star, nous allons donc reprendre la sélection des signes et supprimer certaines des variables.
Sélection des fonctionnalités
Bon nombre des 110 panneaux disponibles sont redondants car ils sont fortement corrélés les uns aux autres. Par exemple, voici un graphique de l'IUE et du site normalisé par temps EUI, avec un coefficient de corrélation de 0,997.
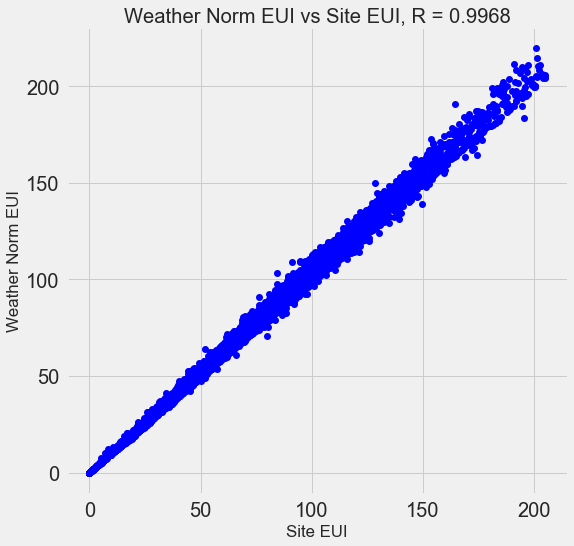
Les signes fortement corrélés sont appelés
colinéaires . La suppression d'une variable dans de telles paires d'attributs aide souvent le
modèle à se généraliser et à être plus interprétable . Veuillez noter que nous parlons de la corrélation de certains signes avec d'autres, et non de la corrélation avec l'objectif, ce qui n'aiderait que notre modèle!
Il existe un certain nombre de méthodes pour calculer la colinéarité des caractéristiques, et l'une des plus populaires est le
facteur d'inflation de la
variance . Nous utiliserons le coefficient de corrélation pour rechercher et supprimer des entités colinéaires. Nous rejetons une paire de signes si le coefficient de corrélation entre eux est supérieur à 0,6. Le code est dans le bloc-notes (et en réponse à
Stack Overflow ).
Cette valeur semble arbitraire, mais en fait j'ai essayé différents seuils, et ce qui précède m'a permis de créer le meilleur modèle. L'apprentissage automatique est
empirique et doit souvent expérimenter pour trouver la meilleure solution. Après la sélection, nous avons 64 attributs et un objectif.
# Remove any columns with all na values features = features.dropna(axis=1, how = 'all') print(features.shape) (11319, 65)
Choisissez un niveau de base
Nous avons effacé les données, effectué une analyse exploratoire et construit les panneaux. Et avant de procéder à la création du modèle, vous devez sélectionner le niveau de base initial (base naïve) - une sorte d'hypothèse avec laquelle nous comparerons les résultats des modèles. S'ils tombent en dessous du niveau de base, nous supposerons que l'apprentissage automatique n'est pas applicable pour cette tâche, ou qu'une approche différente doit être essayée.
Pour les tâches de régression, en tant que niveau de base, il est raisonnable de deviner la valeur médiane de l'objectif sur l'ensemble d'entraînement pour tous les exemples de l'ensemble de test. Ces kits définissent une barrière relativement faible pour tous les modèles.
En tant que mesure, nous prenons l'
erreur absolue moyenne (mae) dans les prévisions. Il existe de nombreuses autres métriques pour les régressions, mais j'aime les
conseils pour choisir une métrique et l'utiliser pour évaluer les modèles. Et l'erreur absolue moyenne est facile à calculer et à interpréter.
Avant de calculer le niveau de base, vous devez diviser les données en ensembles de formation et de test:
- Un ensemble d'attributs de formation est ce que nous fournissons à notre modèle avec les réponses pendant la formation. Le modèle doit apprendre à correspondre aux caractéristiques de l'objectif.
- Un ensemble de fonctionnalités de test est utilisé pour évaluer le modèle formé. Lorsqu'elle traite la suite de tests, elle ne voit pas les bonnes réponses et doit prévoir uniquement en fonction des fonctionnalités disponibles. Nous connaissons les réponses pour les données de test et pouvons comparer les résultats des prévisions avec eux.
Pour la formation, nous utilisons 70% des données et pour les tests - 30%:
# Split into 70% training and 30% testing set X, X_test, y, y_test = train_test_split(features, targets, test_size = 0.3, random_state = 42)
Maintenant, nous calculons l'indicateur pour le niveau de base initial:
# Function to calculate mean absolute error def mae(y_true, y_pred): return np.mean(abs(y_true - y_pred)) baseline_guess = np.median(y) print('The baseline guess is a score of %0.2f' % baseline_guess) print("Baseline Performance on the test set: MAE = %0.4f" % mae(y_test, baseline_guess))
La supposition de base est un score de 66,00
Performances de base sur l'ensemble de test: MAE = 24,5164L'erreur absolue moyenne sur l'ensemble de test était d'environ 25 points. Puisque nous évaluons dans la plage de 1 à 100, l'erreur est de 25% - une barrière plutôt faible pour le modèle!
Conclusion
Dans cet article, vous êtes passés par les trois premières étapes de la résolution d'un problème à l'aide de l'apprentissage automatique. Après avoir défini la tâche, nous:
- Données brutes effacées et formatées.
- Réalisation d'une analyse exploratoire pour étudier les données disponibles.
- Nous avons développé un ensemble de fonctionnalités que nous utiliserons pour nos modèles.
, , .
Scikit-Learn , .