Que se passe-t-il lorsque votre produit commence à être vendu dans un autre pays avec ses propres caractéristiques linguistiques et culturelles? Très probablement, la localisation l'attend. Dans la plupart des cas, il vous suffit de traduire les fichiers de ressources pour que les menus et les éléments d'interface soient dans la langue familière à l'utilisateur. Mais que faire si la base de ce que vous vendez est des données, dont il y a beaucoup, elles arrivent constamment, en gros volumes et nécessitent une traduction régulière. Et pas seulement une langue, mais plusieurs langues à la fois.
Sous la coupe, vous trouverez une histoire sur la façon dont ce problème a été résolu dans 2GIS. Je vais vous donner l'exemple du dernier cas à Dubaï, mais les pratiques sont applicables pour toutes les langues.
A propos de l'arabe
Toute cette histoire a commencé avec le lancement de 2GIS à Dubaï, où deux langues sont utilisées: l'arabe et l'anglais.
La haute précision des données est la valeur la plus importante de l'entreprise. Elle est réalisée par le travail manuel de cartographes et de spécialistes sur le terrain. À Dubaï, où les spécialistes locaux et les utilisateurs finaux connaissent l'anglais, les données n'étaient initialement entrées que dans celui-ci. En voie de croissance, ils ont décidé de ne pas s'arrêter là et d'ajouter la langue arabe.
Fidji
Pour le travail des cartographes, nous avons notre propre logiciel. Cette chose s'appelle Fidji et sert de système maître pour la collecte de données cartographiques.
Nous avons déjà écrit comment les Fidji aident les cartographes à éditer des maisons et à tracer des routes. Les données téléchargées des Fidji après traitement et préparation vont au produit final pour plaire aux utilisateurs. Dans l'article, je parle exactement de ce que nous avons mis en place aux Fidji pour éditer / stocker / afficher des données multilingues.
Termes
Dans l'équipe, nous utilisons un vocabulaire spécifique. Voici quatre exemples ↓
Le système prend en charge le travail avec deux types de langues:
Langue des
métadonnées - la langue dans laquelle tous les contrôles utilisateur sont affichés: interface utilisateur, métadonnées.
Langage de
données - un langage dans lequel les valeurs des attributs des géo-objets, certains répertoires et classificateurs sont affichés.
Les langues sont liées aux territoires. Un territoire peut avoir deux types de langues:
La langue principale du territoire est la langue officiellement adoptée sur ce territoire.
La langue supplémentaire du territoire est la langue dans laquelle nous voulons publier le produit. Il vient en plus du principal.
Langues et dialectes
Les dialectes adoptés dans différentes régions du pays peuvent varier considérablement. Par conséquent, dans certains systèmes, le noyau de la langue (= la version de base) et les dialectes sont stockés séparément, puis lors du déchargement de leurs merjats. Cette approche nous a semblé très compliquée, nous avons donc décidé de considérer chaque dialecte comme une langue indépendante.
Nuance liée aux langues et dialectes arabes. Pour chaque langue, vous devez entrer un indicateur de direction de chariot avec deux valeurs: de gauche à droite et de droite à gauche. Par défaut, le chariot doit se déplacer de gauche à droite. Si la valeur est définie de droite à gauche, vous devez modifier la direction du chariot pour tous les champs multilingues modifiables. Comment cela a été fait dans les produits finaux a été écrit
ici . Nous devions faire à peu près la même chose.
Accrocher aux territoires
Notre monde entier est divisé en certains territoires - ce peuvent être des pays, des régions, des régions. Pour chaque territoire, nous spécifions plusieurs langues, dont l'une est considérée comme principale et les autres - supplémentaires. La traduction a lieu de la langue principale vers la langue supplémentaire.
Par exemple, dans le cas de Dubaï, nous avons laissé l'anglais comme langue principale, car il y avait beaucoup de données. L'arabe a été rendu facultatif.
Entrez et changez la langue
Pour que les cartographes travaillent confortablement, nous avons repensé notre interface dans les endroits où la saisie multilingue est destinée.

Dans cette image, vous pouvez voir que nous avons divisé les langues en onglets, où la plus à gauche est la langue principale, puis il y en a d'autres.
Dans les onglets des langues supplémentaires, seuls les champs disponibles pour l'édition qui ont un indicateur pour le besoin de traduction dans la base de données. Cela sert de mesure de protection et aide à concentrer l'attention de l'utilisateur sur la traduction des données nécessaires. Tout le reste est édité dans la langue principale.

En fait, la modification des données dans une langue supplémentaire peut être nécessaire uniquement si le cartographe lui-même connaît plusieurs langues et ne souhaite pas recourir à l'aide d'un traducteur. Pour tout le monde, il y a CrowdIn.
Crowdin, ou transfert de flux
Nous avons donc permis à nos cartographes de remplir des données dans différentes langues. Mais il est préférable de confier la tâche de traduction à des professionnels.
La première chose qui vient à l'esprit lors de la traduction de l'application est de remettre les fichiers de ressources aux traducteurs et, après le transfert, de les télécharger.
À cet égard, la plateforme CrowdIn nous a beaucoup aidés. Il vous permet de rediriger vos fichiers vers des traducteurs professionnels. Il ne restait plus qu'à intégrer les données traduites dans notre système.
La situation est compliquée par le fait que les données nous parviennent dans un flux continu, c'est pourquoi nous aimerions recevoir des traductions en continu.
Nous avons optimisé le système comme suit: si des modifications sont apportées dans la langue principale du territoire, nous téléchargeons les modifications pour les traduire dans toutes les autres langues de ce territoire. Nous faisons des exceptions pour les cas où le cartographe lui-même a fait la traduction. Ici, nous pensons qu'il comprend ce qu'il fait et qu'il n'est pas nécessaire de connecter un interprète.
Pour chaque répertoire ou objet de carte, nous avons une version de bout en bout, qui est incrémentée à chaque mise à jour des données. Nous pouvons donc obtenir rapidement toutes les modifications d'une version spécifique.
Le système de gestion des versions est très simple et efficace, mais présente un inconvénient important: en fait, nous avons une seule file d'attente et nous ne pouvons pas la gérer de quelque manière que ce soit. Notre maximum est de sauter la version. Il est nécessaire de basculer vers une file d'attente normale, par exemple, vers RabitMQ ou Kafka, mais les mains n'ont pas encore atteint.
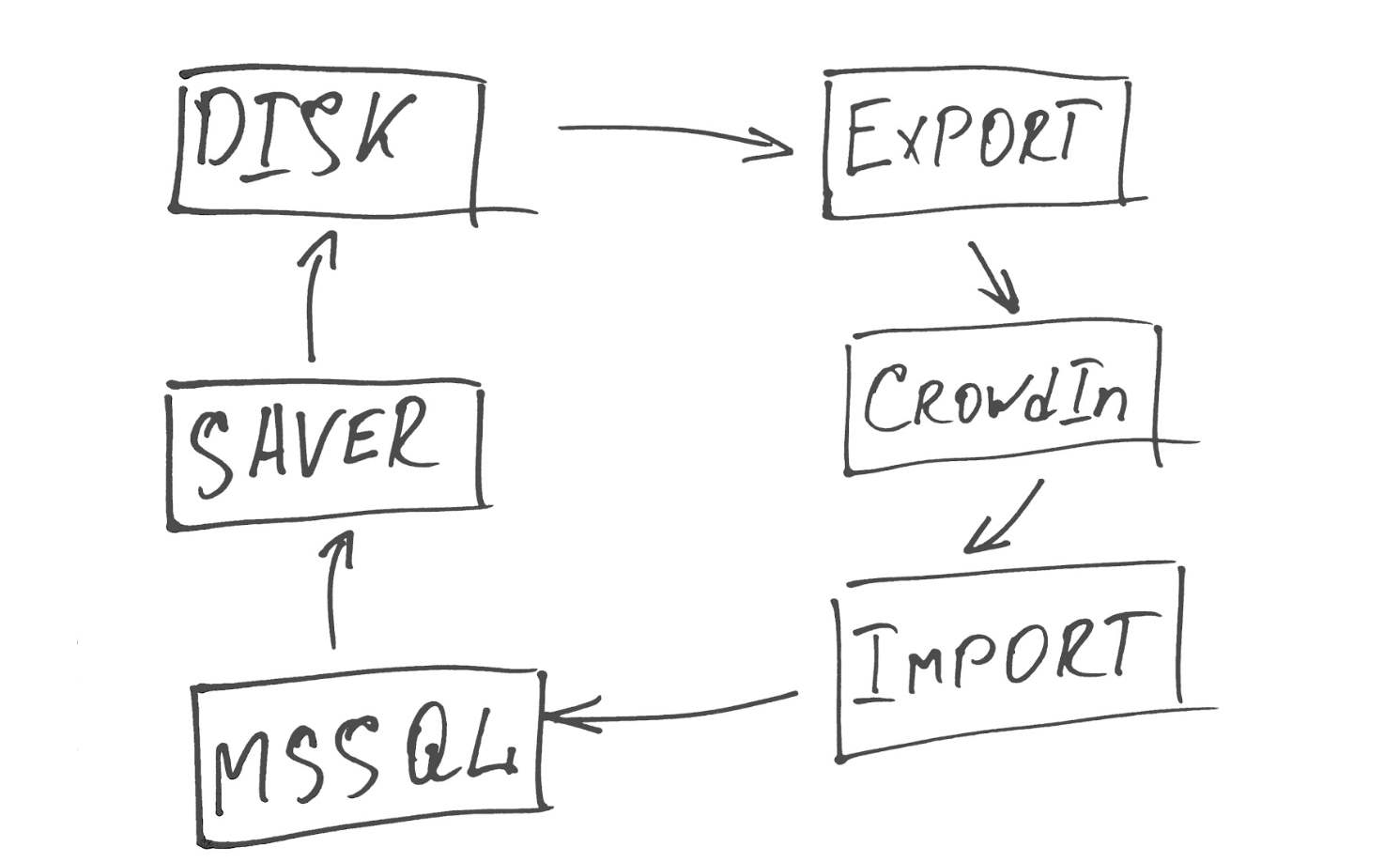
Pour mettre à jour rapidement le contenu, nous avons écrit un petit service qui fonctionne en trois volets.
Le premier flux (Saver) extrait toutes les données qui nécessitent une traduction et génère des fichiers xml à partir de celles-ci.
Le second (Export) les envoie à CrowdIn et les place dans le projet souhaité, qui indique la langue principale à partir de laquelle nous traduisons et une liste de langues dans lesquelles traduire.
Le troisième (Import) interroge périodiquement l'API CrowdIn pour les fichiers dont la traduction a été effectuée et installée à 100%, et importe les fichiers finis dans notre base de données.
Sans râteau ne pouvait pas faire. Nous sommes tombés sur notre système de gestion des versions de données.
Lorsque nous avons téléchargé la traduction du mot, la version des données a été mise à jour et le mot est à nouveau tombé dans la traduction.
Pour éviter une boucle de traduction sans fin, nous avons commencé à enregistrer des données. Chaque mot traduit est marqué, ce qui élimine son envoi répété à CrowdIn.
Tutoriel
Je vais maintenant vous expliquer comment se déroule le travail avec CrowdIn. Il existe plusieurs façons de travailler avec la plate-forme, par exemple, vous pouvez télécharger des fichiers vers le référentiel Git et CrowdIn lui-même les aspire. Mais nous pensions que travailler via l'API semble plus pratique.
CrowdIn a un
tutoriel assez détaillé, mais ci-dessous j'écrirai comment nous l'avons fait.
Nous devons obtenir une clé API, que nous joindrons à chacune de nos demandes, afin que le système nous vérifie. Nous allons dans l'onglet API dans les paramètres du projet et regardons ce qui est écrit dans la colonne clé API.

Cette clé doit être ajoutée à la fin de chacune de vos demandes de plateforme. Par exemple, comme ceci:
OBTENIR:
https://api.crowdin.com/api/project/{myLitleProject}/download/all.zip?key={project-key}2. Créez un dossier dans lequel nous téléchargerons des fichiers à l'intérieur du projet.
var uri = $"project/{_projectName}/add-directory?key={apiKey}"; var content = new MultipartFormDataContent { { new StringContent(crowdInDirectoryPath), "name" } }; return PostAsync(uri, content);
Il y a un petit moment maladroit. Nous écrivons un service, ce serait bien s'il vérifie d'abord si le dossier dont nous avons besoin est présent avant d'essayer de le créer. CrowdIn ne dispose pas d'un moyen normal de rechercher un dossier, nous envoyons donc une demande de création. S'il n'est pas là, CrowdIn le créera et renverra le code 200. S'il y avait un dossier, il ne créera rien et renverra le code 500.
3. Exportez des fichiers. La fonction add-file a beaucoup d'options et de paramètres, comment lire et où. Voici un exemple de la façon dont nous chargeons les données avec des fichiers xml.
ExempleNous mettons toutes les données que nous allons traduire dans des fichiers xml avec la structure suivante.
<LocalizableDocument> <LocalizableValues> <LocalizableValue> … <Attributes> <LocalizableAttributeValue> <AttributeName/> <Value/> </LocalizableAttributeValue> </Attributes> </LocalizableValue> </LocalizableValues> </LocalizableDocument>
Pour que CrowdIn puisse analyser quelles données du fichier doivent être traduites, il faut les spécifier. Pour ce faire, vous devez écrire un tableau de paramètres translatable_elements avec les chemins d'accès aux éléments nécessaires du document dans le contenu. Dans notre cas, cela ressemblait à ceci:
var uri = $"project/{_projectName}/add-file?key={apiKey}"; var content = new MultipartFormDataContent { { new StringContent("/LocalizableDocument/LocalizableValues/LocalizableValue/Attributes/LocalizableAttributeValue/Value"), "translatable_elements[0]" } }; foreach (var filePath in filePaths) { var fileName = Path.GetFileName(filePath); var fileStream = File.OpenRead(filePath); var fileContent = new StreamContent(fileStream); content.Add(fileContent, $"files[{_crowdInDirectoryPath}/{fileName}]", fileName); } return PostAsync(uri, content);
Remarque: la documentation indique que CrowdIn peut mâcher un maximum de 20 fichiers à la fois, tandis que la taille d'un fichier ne doit pas dépasser 100 Mo.
4. Nous découvrons quels fichiers nous avons entièrement traduits. Nous le faisons en utilisant une commande pour une langue spécifique.
var uri = $"project/{_projectName}/language-status?key={apiKey}"; var content = new MultipartFormDataContent {{ new StringContent(langCode), "language" } }; return PostAsync(uri, content);
La plateforme nous renverra quelque chose comme ceci:
<item> <node_type>directory</node_type> <id>29812</id> <name>Version 1.0</name> <files> <item> <node_type>file</node_type> <id>29827</id> <name>strings.xml</name> <node_type>file</node_type> <phrases>7</phrases> <translated>0</translated> <approved>0</approved> <words>32</words> <words_translated>0</words_translated> <words_approved>0</words_approved> </item> </files> </item>
Ici, nous nous intéressons aux valeurs <traduit /> et <approuvé />. Le premier indique le pourcentage de lignes traduites dans ce fichier, le second indique le pourcentage de valeurs approuvées si, en plus du traducteur, un réviseur participe également au workflow. En fonction de notre flux de travail, par exemple, à 100, nous considérons le document traduit et approuvé. Maintenant, ce fichier peut nous être réimporté.
5. Réimportez le fichier dans notre système.
Cela se fait avec une simple requête GET.
https://api.crowdin.com/api/project/{_projectName}/export-file?file={_crowdInDirectoryPath}/{fileName}&language={langCode}&key={project-key}
Le fichier résultant est désérialisé et les données sont importées dans notre système.
Au lieu d'une conclusion
En termes généraux, c'est tout. Bien sûr, nous devions encore affiner l'affichage des signatures sur la carte des Fidji afin qu'elles soient affichées dans la bonne langue, en fonction du territoire sur lequel le cartographe règne désormais. Il était nécessaire de convenir avec d'autres systèmes de la manière dont nous leur fournirons des données multilingues, mais c'est une autre histoire.
En conséquence, nous avons reçu le service dans un esprit «allumé et oublié». Les cartographes saisissent les données, les traducteurs traduisent, le cheikh est satisfait, le service télécharge les données si nécessaire et nous résolvons les problèmes les plus urgents sans penser au fonctionnement de notre système en plusieurs langues.