Qu'est-ce qui attire autant les développeurs vers les microservices? Il n'y a pas de technologie révolutionnaire derrière eux, les avantages par rapport au monolithe sont assez controversés. Seule la facilité avec laquelle les outils de développement et de déploiement modernes vous permettent de créer des systèmes pour fonctionner sur des milliers de serveurs. Nous proposons de tracer le chemin vers le moment présent, où le développement et le déploiement d'un tel système distribué est possible par un seul développeur. Alexander Trekhlebov, holonavt , architecte d'entreprise de Promsvyazbank, est engagé depuis plus de 15 ans dans le développement de logiciels sur l'évolution des technologies de virtualisation, le rôle des conteneurs Linux, Docker et Kubernetes. A commencé avec C ++, puis est passé à Java. Récemment, il a développé un backend bancaire sur la plateforme Spring Cloud.

Si nous rappelons les premières implémentations de l'exécution de script (Java Script, VB Script) dans le cadre de l'affichage de pages dans un navigateur, il s'agissait alors de séquences d'instructions à un seul thread. Le même JavaScript - c'est une tâche unique. Si JS est exécuté dans le cadre d'une page Web et qu'une des instructions exécutables échoue ou tarde, alors tout ce qui se passe sur la page, tout le code est gelé. Et vous ne pouvez rien faire, il suffit de fermer ou de recharger la page, et parfois le navigateur ou l'ensemble du système d'exploitation.
De toute évidence, ce n'était pas très pratique. Surtout quand on considère le fait que le multitâche / multithread était déjà partout: processeurs, systèmes d'exploitation, applications (à moins que le premier OS pour les appareils mobiles ne soit à une seule tâche), et JS était toujours à un seul thread. Que s'est-il passé alors? Divers cadres ont commencé à apparaître l'un après l'autre, d'une manière ou d'une autre, résolvant ce problème. Facebook a fait réagir, Google a publié Angular.
Frontend et backend de tempête multitâche
Comment faites-vous du multitâche à partir d'un système monotâche? Prenez des instructions et dispersez-vous sur différents flux, et surveillez bien sûr ces flux. Vous vous souvenez sûrement comment dans l'une des versions de FB est apparue soudainement la possibilité d'écrire simultanément un message et de surveiller les changements dans la bande. Et si soudain la bande tombait, alors les messages continuaient de fonctionner. C'est alors que la première interface utilisateur est apparue sur l'interface modulaire React. Avec l'aide du framework, le multitâche a commencé à fonctionner dès le départ.
Qu'est-ce que tout cela a à voir avec les microservices? Lorsque l'interface utilisateur des banques Internet a commencé à fournir une fonctionnalité assez large, le gel, et plus encore la chute de l'application, est devenu un événement choquant pour les utilisateurs. Après tout, c'est une chose lorsque Facebook s'est enlisé, et une autre chose - lorsque vous venez de faire un paiement hypothécaire et que les fonds sur votre compte n'apparaissent pas, car il y a eu un échec sur la forme des soldes de compte.
Une idée simple est venue: des éléments d'interface utilisateur indépendants qui permettent d'attacher Angular et React à des éléments backend également indépendants. Chaque élément backend indépendant est un microservice qui peut évoluer, augmenter après une panne, etc.
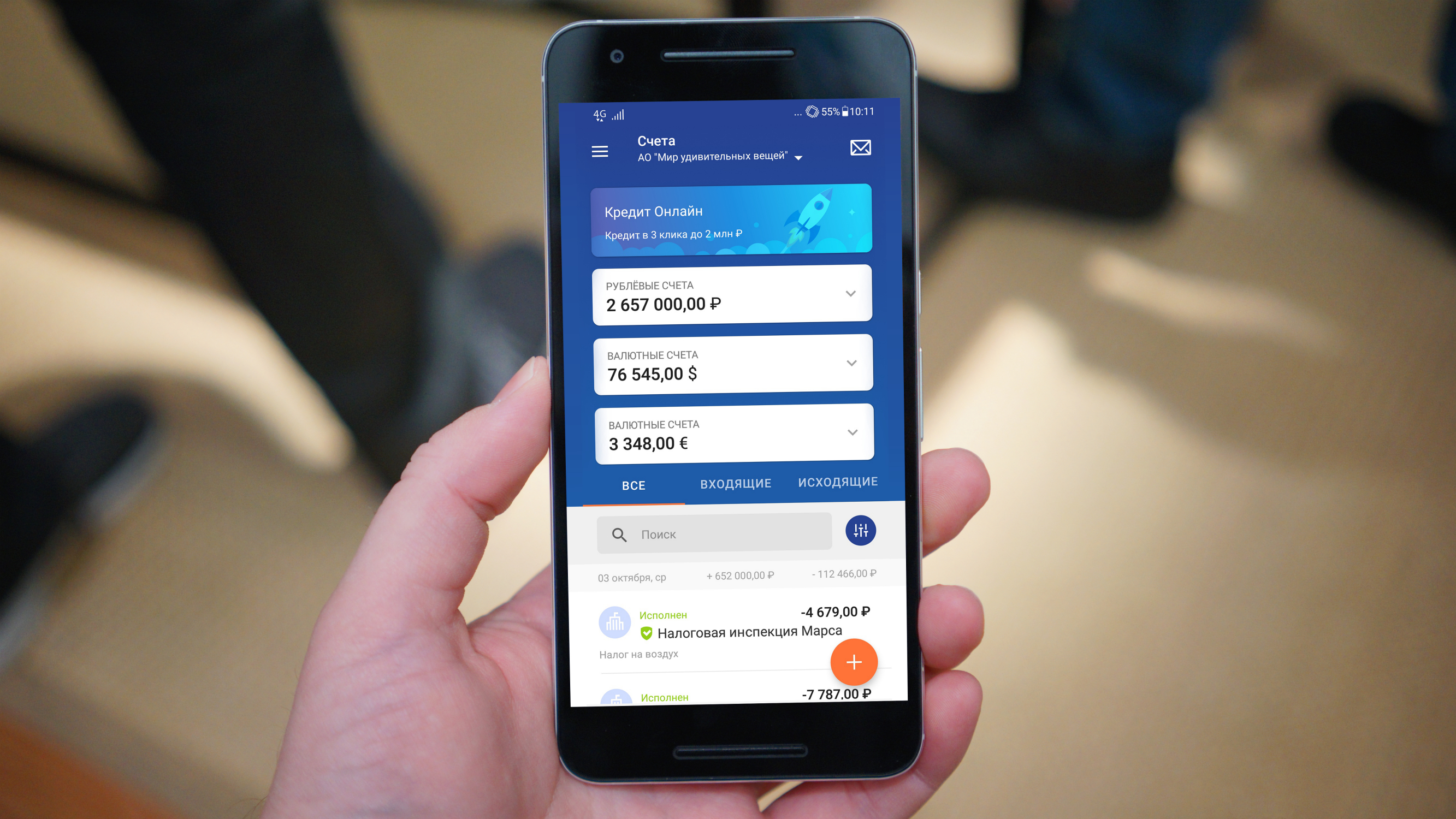
Il est important de créer correctement l'interface utilisateur afin qu'elle soit modifiée en fonction des composants backend disponibles. Si quelque chose ne fonctionne pas pour vous sur le backend, alors vous n'affichez pas la fonctionnalité correspondante sur l'interface utilisateur, ou vous l'affichez d'une manière par défaut - vous pouvez changer la couleur de la police en gris ou afficher une plaque vide avec l'inscription "Les informations de compte ne sont pas disponibles. Rappelle demain ". En fait, une telle combinaison d'éléments d'interface utilisateur avec des microservices contribue à augmenter la fiabilité et l'évolutivité globales d'une application bancaire.
Du Titanic à Docker
À mon avis, la décomposition est la principale raison pour laquelle les microservices sont devenus si populaires, malgré la consommation de mémoire importante et la surcharge de puissance de calcul. Le reste, dans l'ensemble, les microservices n'ont pas de gros avantages par rapport à un monolithe. La décomposition, à ma connaissance, est lorsque la fonctionnalité est divisée en certains blocs indépendants pour le lancement et le déploiement. Cela signifie que pendant que les autres blocs fonctionnent, l'un peut être mis à jour, souvent sans arrêter son travail (bleu, vert - déploiement), et déclencher une instance supplémentaire.
Tous ces technologues ne sont pas apparus hier et pas avant-hier. Les solutions informatiques distribuées ont été développées à l'époque des mainframes car le manque de ressources informatiques est apparu presque immédiatement dès l'apparition de ces ressources.
Ils ont commencé à comprendre comment répartir rationnellement tout cela, par exemple, les calculs graphiques dans les stations Silicon Graphix. Tout cela était cher et ces solutions n'étaient disponibles que pour les grandes organisations, sans parler des développeurs individuels. Les stations elles-mêmes et le logiciel serveur pour eux étaient très chers, donc les capacités correspondantes ont été développées pour le noyau Linux. Par exemple, le calcul de l'infographie pour les scènes du film "Titanic", sorti en 1997, a été effectué sur des serveurs équipés de processeurs Alpha fonctionnant sous Linux. La plupart des solutions nécessaires au fonctionnement des systèmes distribués étaient déjà développées et testées à l'époque. Mais il était encore difficile pour un spécialiste d'utiliser toutes ces technologies, l'assemblage, la livraison et le support d'un tel système nécessitaient de sérieux coûts de main-d'œuvre.
Au début, il n'y avait que des serveurs physiques qui devaient être acheminés d'une manière ou d'une autre, puis l'ère de la virtualisation a commencé, les machines virtuelles sont apparues, le travail est devenu plus amusant, mais le démarrage et l'arrêt de la machine virtuelle sont restés une action gourmande en ressources. Et je voulais que cela se produise aussi rapidement que le démarrage d'un processus à l'intérieur du système d'exploitation. Un grand pas vers la sortie de la technologie "dans le peuple" a été associé à l'avènement des conteneurs Linux.
Un conteneur Linux est presque un processus système, mais il a sa propre interface réseau et bien plus encore, ce qui en fait presque comme une machine virtuelle. Pourquoi presque? Parce que la machine virtuelle monte dans un environnement assez isolé. Le conteneur Linux utilise le système d'exploitation parent, chaque conteneur a sa propre version du système d'exploitation Linux, mais les appels système sont diffusés vers le noyau du système d'exploitation parent.

Cela a ses avantages - lors de la création d'un conteneur LXC, vous n'avez pas besoin de relancer le noyau. Cependant, travailler avec des conteneurs LXC dans leur forme d'origine était très long et peu pratique. En fait, à un moment donné, Docker est apparu. Cette décision a pris tout le soin de déployer et de gérer des conteneurs Linux, exposant une interface plus pratique.
L'avènement de Docker a été le moteur d'une large diffusion de l'architecture des microservices. Oui, les technologies ont été inventées depuis longtemps, mais la possibilité de leur utilisation pratique n'est apparue qu'à ce moment. Désormais, à l'aide de Docker, un développeur peut littéralement coupler plusieurs machines virtuelles et organiser un système informatique distribué, puis le mettre à jour et le mettre à l'échelle dynamiquement à l'aide de quelques commandes.

Ainsi, les capacités de décomposition ont permis à un large cercle de développeurs de transformer un monolithe en un ensemble de microservices à l'intérieur des conteneurs. Cependant, de nouvelles difficultés sont apparues ici. Lorsqu'il existe plusieurs dizaines de conteneurs et qu'ils sont dispersés sur plusieurs serveurs, vous devez en quelque sorte les gérer, les accompagner, effectuer leur orchestration. Des solutions comme Docker Swarm et Kubernetes sont déjà apparues ici. Le développeur individuel a reçu un nouvel outil puissant.
Microservices dans les banques
Quelle est la situation des microservices dans le secteur bancaire? Combien, par exemple, sont nécessaires pour prendre en charge les services bancaires en ligne? Il y a un bon exemple: au Royaume-Uni, il y a une banque entièrement numérique - Monzo, il n'y a pas de back-office, pas de succursales, pas de site Web, tout est essentiellement dans une application mobile. Tout a commencé avec 40 microservices, puis leur nombre est passé à 300, maintenant plus.
Si vous regardez l'implémentation dans Promsvyazbank, nous avons des systèmes avec jusqu'à 40 microservices déployés.
Parallèlement, des systèmes de développement sont en cours de développement qui permettent d'utiliser les quelques lignes de code pour développer les principaux composants du système de microservices, qui peuvent être mis à l'échelle et mis à jour très simplement. Toutes ces fonctionnalités sont très appréciées dans la construction de systèmes d'apprentissage automatique, l'analyse de grandes quantités de données en temps réel (Cloud Streaming, etc.).
Alexander Trekhlebov parlera de son expérience de développement basée sur l'architecture de microservices dans le rapport «Microservices - tolérance aux pannes basée sur la modularité de bout en bout» au 404 Internet Workers Festival , qui se tiendra du 6 au 7 octobre 2018 à Samara.