
Je veux partager une autre construction à long terme du soir, qui montre que vous pouvez faire des jeux même sur du matériel faible.
À propos de ce que vous deviez faire, comment cela a été décidé et comment faire quelque chose de plus qu'un simple clone de Pong - bienvenue chez Cat.
Attention: grand article, trafic et insertions de code multiples!
En bref sur le jeu
Shoot`em up! - maintenant sur AVR.
En fait, c'est un autre shmap, donc une fois de plus, le personnage principal
Shepard doit sauver la galaxie d'une attaque soudaine de personnes inconnues, se frayant un chemin dans l'espace à travers les étoiles et les champs d'astéroïdes nettoyant simultanément chaque système stellaire.
L'ensemble du jeu est écrit en C et C ++ sans utiliser la bibliothèque Wire d'Arduino.
Le jeu propose 4 navires (ce dernier est disponible après le passage), chacun avec ses propres caractéristiques:
- maniabilité;
- durabilité;
- puissance des armes à feu.
Également implémenté:
- Graphiques couleur 2D;
- puissance pour les armes;
- les patrons à la fin des niveaux;
- niveaux avec astéroïdes (et leur animation de rotation);
- changement de couleur d'arrière-plan aux niveaux (et pas seulement l'espace noir);
- le mouvement des étoiles en arrière-plan à différentes vitesses (pour l'effet de la profondeur);
- notation et sauvegarde en EEPROM;
- les mêmes sons (coups de feu, explosions, etc.);
- une mer d'adversaires identiques.
Plateforme
Le retour du fantôme.
Je préciserai à l'avance que cette plateforme doit être perçue comme l'ancienne console de jeu de la première troisième génération (80s, shiru8bit ).
De plus, les modifications matérielles par rapport au matériel d'origine sont interdites, ce qui garantit le lancement sur toute autre carte identique dès la sortie de la boîte.
Ce jeu a été écrit pour la carte Arduino Esplora, mais le transfert vers GBA ou toute autre plate-forme, je pense, ne sera pas difficile.
Néanmoins, même sur cette ressource, ce forum n'a été couvert que quelques fois, et d'autres conseils ne valaient pas la peine d'être mentionnés, malgré la communauté assez large de chacun:
- GameBuino META:
- Pokitto;
- makerBuino;
- Arduboy;
- UzeBox / FuzeBox;
- et bien d'autres.
Pour commencer, ce qui n'est pas sur Esplora:
- beaucoup de mémoire (ROM 28kb, RAM 2,5kb);
- puissance (CPU 8 bits à 16 MHz);
- DMA
- générateur de caractères;
- des zones de mémoire allouées ou des registres spéciaux. destination (palette, tuiles, fond, etc.);
- contrôler la luminosité de l'écran (oh, tant d'effets à la poubelle);
- extenseurs d'espace d'adressage (mappeurs);
- débogueur (
mais qui en a besoin quand il y a un écran entier! ).
Je vais continuer avec le fait qu'il y a:
- SPI matériel (peut fonctionner à la vitesse F_CPU / 2);
- écran basé sur ST7735 160x128 1,44 ";
- une pincée de minuteries (seulement 4 pièces);
- une pincée de GPIO;
- une poignée de boutons (5pcs. + joystick à deux axes);
- peu de capteurs (éclairage, accéléromètre, thermomètre);
- émetteur d'
irritation piezo buzzer.
Apparemment, il n'y a presque rien. Il n'est pas surprenant que personne ne veuille faire quoi que ce soit avec elle, sauf le clone de Pong et deux ou trois matchs pour tout ce temps!
Le fait est peut-être que l'écriture sous le contrôleur ATmega32u4 (et similaires) est similaire à la programmation pour Intel 8051 (qui a presque 40 ans au moment de la publication), où vous devez observer un grand nombre de conditions et recourir à diverses astuces et astuces.
Traitement périphérique
Un pour tout!
Après avoir examiné le circuit, il a été clairement vu que tous les périphériques sont connectés via l'expandeur GPIO (multiplexeur 74HC4067D plus MUX) et sont commutés à l'aide du GPIO PF4, PF5, PF6, PF7 ou du grignotage PORTF senior, et la sortie MUX est lue sur GPIO - PF1.
Il est très pratique de commuter l'entrée en attribuant simplement des valeurs au port PORTF par masque et en n'oubliant en aucun cas le quartet mineur:
uint16_t getAnalogMux(uint8_t chMux) { MUX_PORTX = ((MUX_PORTX & 0x0F) | ((chMux<<4)&0xF0)); return readADC(); }
Sondage de clic sur le bouton:
#define SW_BTN_MIN_LVL 800 bool readSwitchButton(uint8_t btn) { bool state = true; if(getAnalogMux(btn) > SW_BTN_MIN_LVL) {
Voici les valeurs du port F:
#define SW_BTN_1_MUX 0 #define SW_BTN_2_MUX 8 #define SW_BTN_3_MUX 4 #define SW_BTN_4_MUX 12
En ajoutant un peu plus:
#define BUTTON_A SW_BTN_4_MUX #define BUTTON_B SW_BTN_1_MUX #define BUTTON_X SW_BTN_2_MUX #define BUTTON_Y SW_BTN_3_MUX #define buttonIsPressed(a) readSwitchButton(a)
Vous pouvez interroger en toute sécurité la bonne croix:
void updateBtnStates(void) { if(buttonIsPressed(BUTTON_A)) btnStates.aBtn = true; if(buttonIsPressed(BUTTON_B)) btnStates.bBtn = true; if(buttonIsPressed(BUTTON_X)) btnStates.xBtn = true; if(buttonIsPressed(BUTTON_Y)) btnStates.yBtn = true; }
Veuillez noter que l'état précédent n'est pas réinitialisé, sinon vous pouvez manquer le fait d'appuyer sur la touche (cela fonctionne également comme une protection supplémentaire contre le bavardage).
Sfx
Un bourdonnement.
Que faire s'il n'y a pas de DAC, pas de puce de Yamaha et qu'il n'y a qu'un rectangle PWM 1 bit pour le son?
Au début, cela ne semble pas tellement, mais, malgré cela, le PWM rusé est utilisé ici pour recréer la technique «audio PDM» et avec son aide, vous pouvez le faire
.Quelque chose de similaire est fourni par la bibliothèque de Gamebuino et tout ce qui est nécessaire est de transférer le générateur de popping vers un autre GPIO et le temporisateur vers Esplora (sortie timer4 et OCR4D). Pour un fonctionnement correct, timer1 est également utilisé pour générer des interruptions et recharger le registre OCR4D avec de nouvelles données.
Le moteur Gamebuino utilise des modèles sonores (comme dans la musique de tracker), ce qui économise beaucoup d'espace, mais vous devez faire tous les échantillons vous-même, il n'y a pas de bibliothèques avec celles prêtes à l'emploi.
Il convient de mentionner que ce moteur est lié à une période de mise à jour d'environ 1/50 s ou 20 images / s.
Pour lire les modèles sonores, après avoir lu le wiki sur le format audio, j'ai esquissé une interface graphique simple sur Qt. Il n'émet pas de son de la même manière, mais donne une idée approximative de la façon dont le motif sonnera et vous permet de le charger, de l'enregistrer et de le modifier.
Graphisme
Immortal Pixelart.
L'affichage code les couleurs sur deux octets (RGB565), mais comme les images dans ce format prendront beaucoup, elles ont toutes été indexées par la palette pour économiser de l'espace, ce que j'ai déjà décrit plus d'une fois dans mes articles précédents.
Contrairement à Famicom / NES, il n'y a pas de limites de couleur pour l'image et il y a plus de couleurs disponibles dans la palette.
Chaque image du jeu est un tableau d'octets dans lequel les données suivantes sont stockées:
- largeur, hauteur;
- marqueur de début de données;
- dictionnaire (le cas échéant, mais plus à ce sujet plus tard);
- charge utile;
- marqueur de fin de données.
Par exemple, une telle image (agrandie 10 fois):

dans le code, cela ressemblera à ceci:
pic_t weaponLaserPic1[] PROGMEM = { 0x0f,0x07, 0x02, 0x8f,0x32,0xa2,0x05,0x8f,0x06,0x22,0x41,0xad,0x03,0x41,0x22,0x8f,0x06,0xa2,0x05, 0x8f,0x23,0xff, };
Où sans navire dans ce genre? Après des centaines de croquis de test avec une différence de pixels, seuls ces navires restaient pour le joueur:

Il est à noter que les navires n'ont pas de flamme dans les carreaux (ici c'est pour plus de clarté), il est appliqué séparément pour créer une animation de l'échappement du moteur.
N'oubliez pas les pilotes de chaque navire:

La variation des navires ennemis n'est pas trop grande, mais permettez-moi de vous rappeler qu'il n'y a pas trop d'espace, alors voici trois navires:

Sans bonus canoniques sous forme d'amélioration des armes et de restauration de la santé, le joueur ne durera pas longtemps:

Bien sûr, avec l'augmentation de la puissance des canons, le type d'obus émis change:

Comme il était écrit au début, le jeu a un niveau avec des astéroïdes, il vient après chaque deuxième boss. Il est intéressant de noter qu'il existe de nombreux objets mobiles et rotatifs de différentes tailles. De plus, lorsqu'un joueur les frappe, ils s'effondrent partiellement, devenant plus petits.
Astuce: les gros astéroïdes gagnent plus de points.



Pour créer cette animation simple, 12 petites images suffisent:

Ils sont divisés en trois pour chaque taille (grande, moyenne et petite) et pour chaque angle de rotation, vous avez besoin de 4 autres degrés de rotation de 0, 90, 180 et 270 degrés. Dans le jeu, il suffit de remplacer le pointeur du tableau par l'image à un intervalle égal créant ainsi l'illusion de rotation.
void rotateAsteroid(asteroid_t &asteroid) { if(RN & 1) { asteroid.sprite.pPic = getAsteroidPic(asteroid); ++asteroid.angle; } } void moveAsteroids(void) { for(auto &asteroid : asteroids) { if(asteroid.onUse) { updateSprite(&asteroid.sprite); rotateAsteroid(asteroid); ...
Cela se fait uniquement en raison du manque de capacités matérielles, et une implémentation logicielle comme la transformation Affine prendra plus que les images elles-mêmes et sera très lente.
Un morceau de satin pour ceux qui sont intéressés.
Vous pouvez remarquer une partie des prototypes et ce qui n'apparaît qu'au générique après avoir passé le jeu.
En plus des graphiques simples, pour économiser de l'espace et ajouter un effet rétro, les glyphes minuscules et tous les glyphes jusqu'à 30 et après 127 octets d'ASCII ont été supprimés de la police.
Important!
N'oubliez pas que const et constexpr sur AVR ne signifient pas du tout que les données seront dans la mémoire du programme, ici, pour cela, vous devez également utiliser PROGMEM.
Cela est dû au fait que le noyau AVR est basé sur l'architecture Harvard, donc des codes d'accès spéciaux pour le CPU sont nécessaires pour accéder aux données.
Serrer la galaxie
Le moyen le plus simple d'emballer est le RLE.
Après avoir étudié les données compressées, vous pouvez remarquer que le bit le plus significatif de l'octet de charge utile dans la plage de 0x00 à 0x50 n'est pas utilisé. Cela vous permet d'ajouter les données et le marqueur de début pour le début de répétition (0x80), et l'octet suivant pour indiquer le nombre de répétitions, ce qui vous permet de compresser une série de 257 (+2 du fait que RLE de deux octets est stupide) d'octets identiques en seulement deux.
Implémentation et affichage du décompresseur:
void drawPico_RLE_P(uint8_t x, uint8_t y, pic_t *pPic) { uint16_t repeatColor; uint8_t tmpInd, repeatTimes; alphaReplaceColorId = getAlphaReplaceColorId(); auto tmpData = getPicSize(pPic, 0); tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2); ++pPic;
L'essentiel est de ne pas afficher l'image en dehors de l'écran, sinon ce sera des ordures, car il n'y a pas de contrôle de bordure ici.
L'image de test est décompressée en ~ 39 ms. en même temps, occupant 3040 octets, alors que sans compression, il faudrait 11 200 octets ou 22 400 octets sans indexation.
Image test (agrandie 2 fois):

Dans l'image ci-dessus, vous pouvez voir entrelacé, mais à l'écran, il est lissé par le matériel, créant un effet similaire à CRT et en même temps augmentant considérablement le taux de compression.
Le RLE n'est pas une panacée
Nous sommes traités pour le déjà-vu.
Comme vous le savez, RLE va bien avec les conditionneurs de type LZ. WiKi est venu à la rescousse avec une liste de méthodes de compression. L'impulsion était la vidéo de "GameHut" sur l'analyse de l'
intro impossible
dans Sonic 3D Blast.Après avoir étudié de nombreux emballeurs (LZ77, LZW, LZSS, LZO, RNC, etc.), je suis arrivé à la conclusion que leurs déballeurs:
- nécessitent beaucoup de RAM pour les données décompressées (au moins 64 Ko et plus);
- volumineux et lent (certains ont besoin de construire des arbres Huffman pour chaque sous-unité);
- avoir un faible taux de compression avec une petite fenêtre (exigences de RAM très strictes);
- avoir des ambiguïtés avec l'octroi de licences.
Après des mois d'adaptations futiles, il a été décidé de modifier le packer existant.
Par analogie avec les compresseurs de type LZ, pour obtenir une compression maximale, l'accès au dictionnaire a été utilisé, mais au niveau des octets - les paires d'octets les plus fréquemment répétées sont remplacées par un pointeur d'un octet dans le dictionnaire.
Mais il y a un hic: comment distinguer un octet de «combien de répétitions» d'un «marqueur de dictionnaire»?
Après une longue séance avec un morceau de papier et un jeu magique avec des chauves-souris, cela est apparu:
- «Marqueur de dictionnaire» est un marqueur RLE (0x80) + octet de données (0x50) + numéro de position dans le dictionnaire;
- limiter l'octet «combien de répétitions» à la taille du marqueur de dictionnaire - 1 (0xCF);
- le dictionnaire ne peut pas utiliser la valeur 0xff (c'est pour le marqueur de fin d'image).
En appliquant tout cela, nous obtenons une taille de dictionnaire fixe: pas plus de 46 paires d'octets et une réduction RLE à 209 octets. Évidemment, toutes les images ne peuvent pas être empaquetées comme ceci, mais elles ne le seront plus.
Dans les deux algorithmes, la structure de l'image compressée sera la suivante:
- 1 octet par largeur et hauteur;
- 1 octet pour la taille du dictionnaire, c'est un pointeur marqueur vers le début des données compressées;
- de 0 à 92 octets du dictionnaire;
- 1 à N octets de données compressées.
L'utilitaire packer résultant sur D (pickoPacker) est suffisant pour mettre dans un dossier avec des fichiers * .png indexés et exécuter à partir du terminal (ou cmd). Si vous avez besoin d'aide, exécutez l'option "-h" ou "--help".
Après l'exécution de l'utilitaire, nous obtenons des fichiers * .h, dont le contenu est pratique à transférer au bon endroit dans le projet (il n'y a donc pas de protection).
Avant le déballage, l'écran, le dictionnaire et les données initiales sont préparés:
void drawPico_DIC_P(uint8_t x, uint8_t y, pic_t *pPic) { auto tmpData = getPicSize(pPic, 0); tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2); uint8_t tmpByte, unfoldPos, dictMarker; alphaReplaceColorId = getAlphaReplaceColorId(); auto pDict = &pPic[3];
Un morceau de données lu peut être emballé dans un dictionnaire, nous le vérifions et le déballons donc:
inline uint8_t findPackedMark(uint8_t *ptr) { do { if(*ptr >= DICT_MARK) { return 1; } } while(*(++ptr) != PIC_DATA_END); return 0; } inline uint8_t *unpackBuf_DIC(const uint8_t *pDict) { bool swap = false; bool dictMarker = true; auto getBufferPtr = [&](uint8_t a[], uint8_t b[]) { return swap ? &a[0] : &b[0]; }; auto ptrP = getBufferPtr(buf_unpacked, buf_packed); auto ptrU = getBufferPtr(buf_packed, buf_unpacked); while(dictMarker) { if(*ptrP >= DICT_MARK) { setPicWData(ptrU) = getPicWData(pDict, *ptrP); ++ptrU; } else { *ptrU = *ptrP; } ++ptrU; ++ptrP; if(*ptrP == PIC_DATA_END) { *ptrU = *ptrP;
Maintenant, à partir du tampon reçu, nous décompressons le RLE de manière familière et l'afficher à l'écran:
inline void printBuf_RLE(uint8_t *pData) { uint16_t repeatColor; uint8_t repeatTimes, tmpByte; while((tmpByte = *pData) != PIC_DATA_END) {
Étonnamment, le remplacement de l'algorithme n'a pas affecté de manière significative le temps de déballage et est d'environ 47 ms. C'est presque 8 ms. plus longtemps, mais l'image de test ne prend que 1650 octets!
Jusqu'à la dernière mesure
Presque tout peut être fait plus rapidement!
Malgré la présence de matériel SPI, le noyau AVR offre beaucoup de maux de tête lors de son utilisation.
On sait depuis longtemps que SPI sur AVR, en plus de fonctionner à la vitesse F_CPU / 2, possède également un registre de données de seulement 1 octet (il n'est pas possible de charger 2 octets à la fois).
De plus, presque tout le code SPI sur AVR que j'ai rencontré fonctionne selon ce schéma:
- Télécharger les données SPDR
- interroger le bit SPIF dans le SPSR en boucle.
Comme vous pouvez le voir, la fourniture continue de données, comme cela se fait sur le STM32, ne sent pas ici. Mais, même ici, vous pouvez accélérer la sortie des deux déballeurs de ~ 3 ms!
En ouvrant la fiche technique et en consultant la section «Horloges du jeu d'instructions», vous pouvez calculer les coûts du processeur lors de la transmission d'un octet via SPI:
- 1 cycle pour le chargement du registre avec de nouvelles données;
- 2 temps par bit (ou 16 temps par octet);
- 1 barre par magie de ligne d'horloge (un peu plus tard sur «NOP»);
- 1 horloge pour vérifier le bit d'état dans SPSR (ou 2 horloge sur la branche);
Au total, pour transmettre un pixel (deux octets), 38 cycles d'horloge ou ~ 425600 cycles d'horloge pour l'image de test (11 200 octets) doivent être dépensés.
Sachant que F_CPU == 16 MHz, nous obtenons
0,0000000625 62,5 nanosecondes par cycle d'horloge (
Process0169 ), en multipliant les valeurs, nous obtenons ~ 26 millisecondes. La question se pose: «D'où ai-je écrit plus tôt que le temps de déballage est de 39 ms. et 47 ms. "? Tout est simple - logique de déballage + gestion des interruptions.
Voici un exemple de sortie d'interruption:
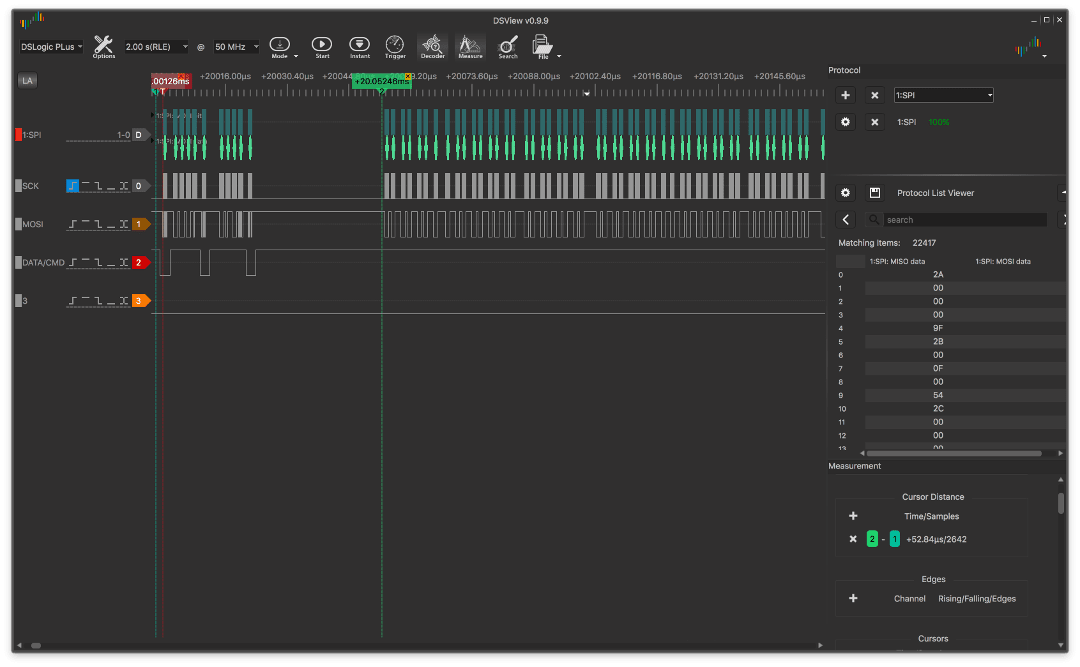
et sans interruption:

Les graphiques montrent que le temps entre le réglage de la fenêtre d'adresse dans l'écran VRAM et le début du transfert de données dans la version sans interruption est moindre et qu'il n'y a presque pas d'écart entre les octets pendant la transmission (le graphique est uniforme).
Malheureusement, vous ne pouvez pas désactiver les interruptions pour chaque sortie d'image, sinon le son et le cœur de tout le jeu se briseront (plus à ce sujet plus tard).
Il a été écrit ci-dessus à propos d'un certain "NOP magique" pour une ligne d'horloge. Le fait est que pour stabiliser le CLK et définir le drapeau SPIF, exactement 1 cycle d'horloge est nécessaire et au moment où ce drapeau est lu, il est déjà défini, ce qui évite de se ramifier en 2 barres sur l'instruction BREQ.
Voici un exemple sans NOP:
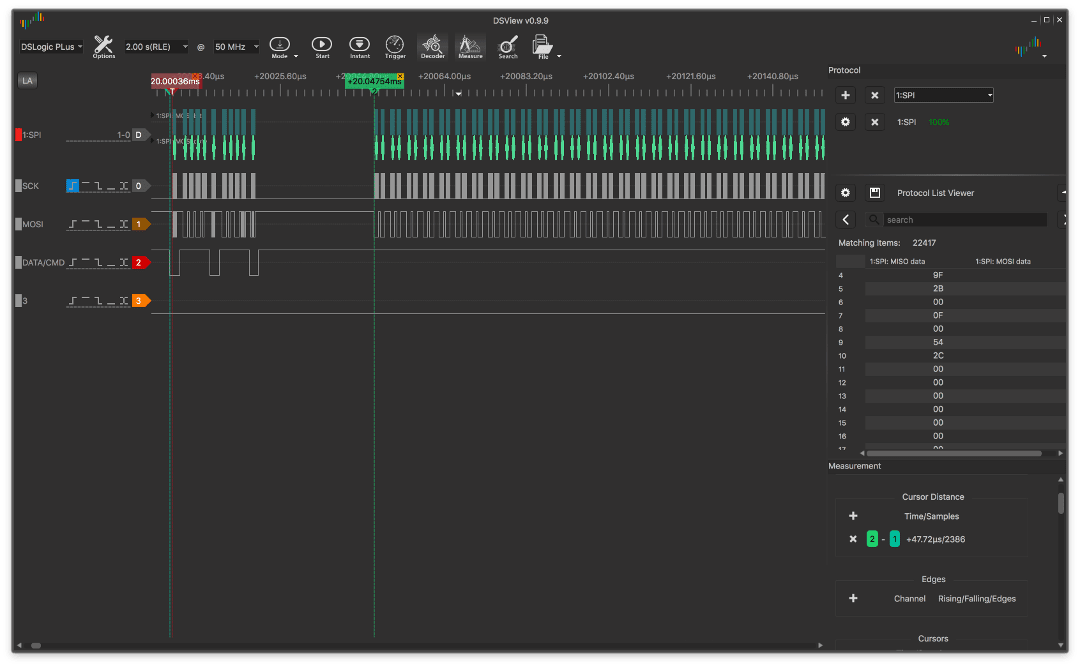
et avec lui:

La différence semble insignifiante, juste quelques microsecondes, mais si vous prenez une échelle différente:
Grand NOP:
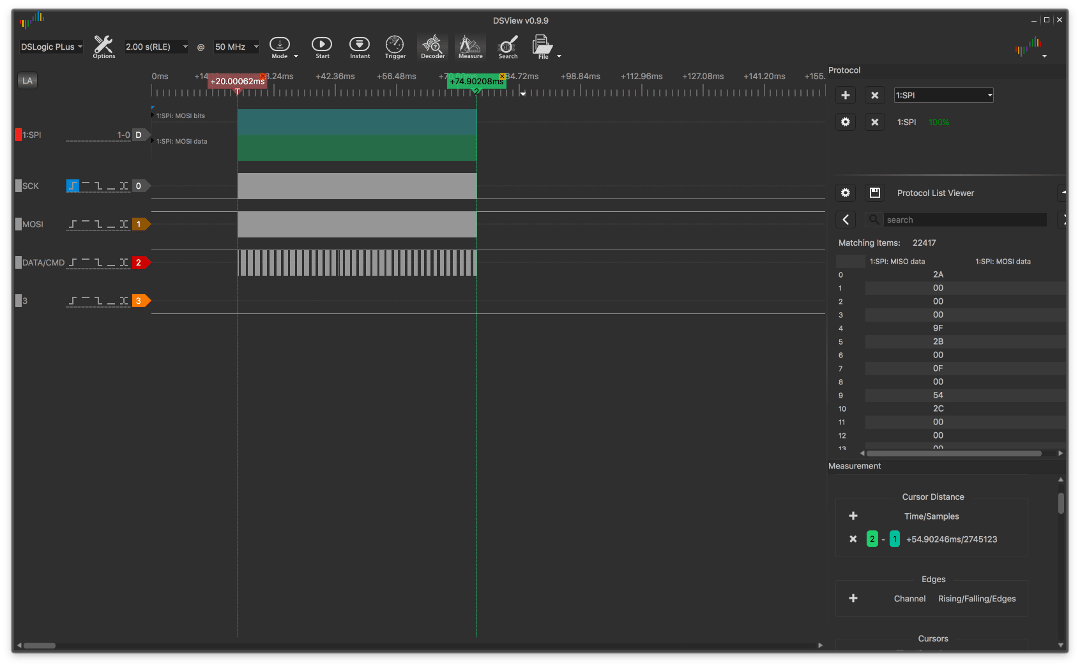
et avec elle trop grande:

alors la différence devient beaucoup plus sensible, atteignant ~ 4,3 ms.
Faisons maintenant le sale tour suivant:
Nous échangeons l'ordre de chargement et de lecture des registres et vous ne pouvez pas attendre chaque deuxième octet du drapeau SPIF, mais vérifiez-le uniquement avant de charger le premier octet du pixel suivant.
Nous appliquons les connaissances et déployons la fonction "pushColorFast (repeatColor);":
#define SPDR_TX_WAIT(a) asm volatile(a); while((SPSR & (1<<SPIF)) == 0); typedef union { uint16_t val; struct { uint8_t lsb; uint8_t msb; }; } SPDR_t; ... do { #ifdef ESPLORA_OPTIMIZE SPDR_t in = {.val = repeatColor}; SPDR_TX_WAIT(""); SPDR = in.msb; SPDR_TX_WAIT("nop"); SPDR = in.lsb; #else pushColorFast(repeatColor); #endif } while(--repeatTimes); } #ifdef ESPLORA_OPTIMIZE SPDR_TX_WAIT("");
Malgré l'interruption de la minuterie, l'utilisation de l'astuce ci-dessus donne un gain de près de 6 ms.:

C'est ainsi que la simple connaissance du fer vous permet d'en tirer un peu plus et de produire quelque chose de similaire:

Collisions au Colisée
La bataille des boîtes.
Pour commencer, l'ensemble des objets (navires, coquillages, astéroïdes, bonus) sont des structures (sprites) avec les paramètres suivants:
- coordonnées X, Y actuelles;
- nouvelles coordonnées X, Y;
- pointeur sur l'image.
Étant donné que l'image stocke la largeur et la hauteur, il n'est pas nécessaire de dupliquer ces paramètres, de plus, une telle organisation simplifie la logique à bien des égards.
Le calcul lui-même est rendu simple au banal - basé sur l'intersection des rectangles. Bien qu'il ne soit pas suffisamment précis et ne calcule pas les conflits futurs, c'est plus que suffisant.
La vérification s'effectue alternativement sur les axes X et Y. De ce fait, l'absence d'intersection sur l'axe X réduit le calcul de la collision.
Tout d'abord, le côté droit du premier rectangle avec le côté gauche du deuxième rectangle est vérifié pour la partie commune de l'axe X. En cas de succès, une vérification similaire est effectuée pour le côté gauche du premier et le côté droit du deuxième rectangle.
Après avoir détecté avec succès les intersections le long de l'axe X, une vérification est effectuée de la même manière pour les côtés supérieur et inférieur des rectangles le long de l'axe Y.
Ce qui précède semble beaucoup plus facile qu'il n'y paraît:
bool checkSpriteCollision(sprite_t *pSprOne, sprite_t *pSprTwo) { auto tmpDataOne = getPicSize(pSprOne->pPic, 0); auto tmpDataTwo = getPicSize(pSprTwo->pPic, 0); uint8_t objOnePosEndX = (pSprOne->pos.Old.x + tmpDataOne.u8Data1); if(objOnePosEndX >= pSprTwo->pos.Old.x) { uint8_t objTwoPosEndX = (pSprTwo->pos.Old.x + tmpDataTwo.u8Data1); if(pSprOne->pos.Old.x >= objTwoPosEndX) { return false;
Reste à ajouter ceci au jeu:
void checkInVadersCollision(void) { decltype(aliens[0].weapon.ray) gopher; for(auto &alien : aliens) { if(alien.alive) { if(checkSpriteCollision(&ship.sprite, &alien.sprite)) { gopher.sprite.pos.Old = alien.sprite.pos.Old; rocketEpxlosion(&gopher);
Courbe de Bézier
Rails spatiaux.
Comme dans tout autre jeu de ce genre, les navires ennemis doivent se déplacer le long des courbes.
Il a été décidé de mettre en œuvre des courbes quadratiques comme la plus simple pour le contrôleur et cette tâche. Trois points leur suffisent: l'initiale (P0), la finale (P2) et l'imaginaire (P1). Les deux premiers spécifient le début et la fin de la ligne, le dernier point décrit le type de courbure.
Excellent article sur les courbes.Comme il s'agit d'une courbe paramétrique de Bézier, elle a également besoin d'un paramètre supplémentaire - le nombre de points intermédiaires entre les points de début et de fin.
Au total, nous obtenons ici une telle structure:
typedef struct {
Dans ce document, position_t est une structure de deux octets de coordonnées X et Y.
La recherche d'un point pour chaque coordonnée est calculée à l'aide de cette formule (thx Wiki):
B = ((1.0 - t) ^ 2) P0 + 2t (1.0 - t) P1 + (t ^ 2) P2,
t [> = 0 && <= 1]
Pendant longtemps, sa mise en œuvre a été résolue de front sans calcul à virgule fixe:
... float t = ((float)pItemLine->step)/((float)pLine->totalSteps); pPos->x = (1.0 - t)*(1.0 - t)*pLine->P0.x + 2*t*(1.0 - t)*pLine->P1.x + t*t*pLine->P2.x; pPos->y = (1.0 - t)*(1.0 - t)*pLine->P0.y + 2*t*(1.0 - t)*pLine->P1.y + t*t*pLine->P2.y; ...
Bien sûr, cela ne peut pas être laissé. Après tout, se débarrasser du flotteur pourrait non seulement améliorer la vitesse, mais aussi libérer la ROM, de sorte que les implémentations suivantes ont été trouvées:
- avrfix;
- stdfix;
- libfixmath;
- fixedptc.
Le premier reste un cheval noir, car il s'agit d'une bibliothèque compilée et ne voulait pas jouer avec le désassembleur.
Le deuxième candidat du bundle GCC n'a pas non plus fonctionné, car le avr-gcc utilisé n'était pas corrigé et le type "short _Accum" n'était pas disponible.
La troisième option, malgré le fait qu'il dispose d'un grand nombre de tapis. fonctions, a des opérations binaires codées en dur sur des bits spécifiques sous le format Q16.16, ce qui rend impossible le contrôle des valeurs de Q et I.
Ce dernier peut être considéré comme une version simplifiée de "fixedmath", mais le principal avantage est la possibilité de contrôler non seulement la taille de la variable, qui par défaut est de 32 bits avec le format Q24.8, mais aussi les valeurs de Q et I.
Résultats des tests à différents paramètres:
| Tapez | QI | Drapeaux supplémentaires | Octet ROM | Tms. * |
|---|
| flotter | - | - | 4236 | 35 |
| fixedmath | 16.16 | - | 4796 | 119 |
| fixedmath | 16.16 | FIXMATH_NO_OVERFLOW | 4664 | 89 |
| fixedmath | 16.16 | FIXMATH_OPTIMIZE_8BIT | 5036 | 92 |
| fixedmath | 16.16 | _NO_OVERFLOW + _8BIT | 4916 | 89 |
| fixedptc | 24,8 | FIXEDPT_BITS 32 | 4420 | 64 |
| fixedptc | 9.7 | FIXEDPT_BITS 16 | 3490 | 31 |
* La vérification a été effectuée sur le patron: "195,175,145,110,170,70,170" et la clé "-Os".
Le tableau montre que les deux bibliothèques ont utilisé plus de ROM et se sont révélées pires que le code compilé de GCC lors de l'utilisation de float.
On voit également qu'une petite révision du format Q9.7 et une diminution de la variable à 16 bits ont donné une accélération de 4 ms. et libérer la ROM à ~ 50 octets.
L'effet attendu était une diminution de la précision et une augmentation du nombre d'erreurs:

qui dans ce cas n'est pas critique.
Allouer des ressources
Les mardis et jeudis ne fonctionnent qu'une heure.
Dans la plupart des cas, tous les calculs sont effectués à chaque image, ce qui n'est pas toujours justifié, car il peut ne pas y avoir assez de temps dans l'image pour calculer quelque chose et vous devrez tromper en alternant, en comptant les images ou en les sautant. Je suis donc allé plus loin - j'ai complètement abandonné le personnel.
Après avoir tout divisé en petites tâches, que ce soit: calculer les collisions, traiter le son, les boutons et afficher les graphiques, il suffit de les exécuter à un certain intervalle, et l'inertie de l'œil et la possibilité de mettre à jour seulement une partie de l'écran feront l'affaire.Nous gérons tout cela non pas une fois avec le système d'exploitation, mais avec la machine d'état que j'ai créée il y a quelques années, ou, plus simplement, pas le gestionnaire de tâches tinySM.Je répète les raisons de l'utiliser à la place de n'importe quel RTOS:- exigences ROM plus faibles (~ 250 octets de base);
- exigences de RAM plus faibles (~ 9 octets par tâche);
- principe de travail simple et compréhensible;
- déterminisme du comportement;
- moins de temps processeur perdu;
- laisse l'accès au fer;
- indépendant de la plateforme;
- écrit en C et facile à encapsuler en C ++;
avait besoin de mon propre vélo.
Comme je l'ai déjà décrit, les tâches sont organisées en un tableau de pointeurs vers des structures, où un pointeur vers une fonction et son intervalle d'appel sont stockés. Ce regroupement simplifie la description du jeu en plusieurs étapes, ce qui vous permet également de réduire le nombre de branches et de basculer dynamiquement l'ensemble des tâches.Par exemple, pendant l'écran de démarrage, 7 tâches sont effectuées et pendant le jeu, il y a déjà 20 tâches (toutes les tâches sont décrites dans le fichier gameTasks.c).Vous devez d'abord définir certaines macros pour votre commodité: #define T(a) a##Task #define TASK_N(a) const taskParams_t T(a) #define TASK(a,b) TASK_N(a) PROGMEM = {.pFunc=a, .timeOut=b} #define TASK_P(a) (taskParams_t*)&T(a) #define TASK_ARR_N(a) const tasksArr_t a##TasksArr[] #define TASK_ARR(a) TASK_ARR_N(a) PROGMEM #define TASK_END NULL
La déclaration de tâche crée en fait une structure, initialise ses champs et la place dans la ROM: TASK(updateBtnStates, 25);
Chacune de ces structures occupe 4 octets de ROM (deux par pointeur et deux par intervalle).Un bon avantage des macros est que cela ne fonctionne pas pour créer plus d'une structure unique pour chaque fonction.Après avoir déclaré les tâches nécessaires, nous les ajoutons au tableau et les mettons également en ROM: TASK_ARR( game ) = { TASK_P(updateBtnStates), TASK_P(playMusic), TASK_P(drawStars), TASK_P(moveShip), TASK_P(drawShip), TASK_P(checkFireButton), TASK_P(pauseMenu), TASK_P(drawPlayerWeapon), TASK_P(checkShipHealth), TASK_P(drawSomeGUI), TASK_P(checkInVaders), TASK_P(drawInVaders), TASK_P(moveInVaders), TASK_P(checkInVadersRespawn), TASK_P(checkInVadersRay), TASK_P(checkInVadersCollision), TASK_P(dropWeaponGift), TASK_END };
Lorsque vous définissez l'indicateur USE_DYNAMIC_MEM sur 0 pour la mémoire statique, la principale chose à retenir est d'initialiser les pointeurs vers le magasin de tâches en RAM et de définir le nombre maximal d'entre eux qui seront exécutés: ... tasksContainer_t tasksContainer; taskFunc_t tasksArr[MAX_GAME_TASKS]; ... initTasksArr(&tasksContainer, &tasksArr[0], MAX_GAME_TASKS); …
Définition des tâches à exécuter: ... addTasksArray_P(gameTasksArr); …
La protection contre les débordements est contrôlée par l'indicateur USE_MEM_PANIC, si vous êtes sûr du nombre de tâches, vous pouvez le désactiver pour enregistrer la ROM.Il ne reste plus qu'à exécuter le gestionnaire: ... runTasks(); ...
À l'intérieur se trouve une boucle infinie qui contient la logique de base. Une fois à l'intérieur, la pile est également restaurée grâce à "__attribute__ ((noreturn))".Dans la boucle, les éléments du tableau sont analysés en alternance pour la nécessité d'appeler la tâche après l'expiration de l'intervalle.Le comptage des intervalles a été effectué sur la base de timer0 en tant que système avec un quantum de 1 ms ...Malgré la répartition réussie des tâches dans le temps, elles se chevauchaient parfois (gigue), ce qui provoquait une décoloration à court terme de tout et de tout dans le jeu.Il fallait définitivement décider, mais comment? À propos de la façon dont tout a été profilé la prochaine fois, mais pour l'instant, essayez de trouver l'œuf de Pâques dans la source.La fin
Donc, en utilisant beaucoup d'astuces (et beaucoup d'autres dont je n'ai pas décrit), tout s'est avéré tenir dans une ROM de 24 Ko et 1500 octets de RAM. Si vous avez des questions, je me ferai un plaisir d'y répondre.Pour ceux qui n'ont pas trouvé ou n'ont pas cherché d'oeuf de Pâques:creuser sur le côté: void invadersMagicRespawn(void) { for(auto &alien : aliens) { if(!alien.alive) { alien.respawnTime = 1; } } }
Rien de remarquable, non?Raaaaazvorachivaem macro envahisseursMagicRespawn: void action() { tftSetTextSize(1); for(;;) { tftSetCP437(RN & 1); tftSetTextColorBG((((RN % 192 + 64) & 0xFC) << 3), COLOR_BLACK); tftDrawCharInt(((RN % 26) * 6), ((RN & 15) * 8), (RN % 255)); tftPrintAt_P(32, 58, (const char *)creditP0); } } a(void) { for(auto &alien : aliens) { if(!alien.alive) { alien.respawnTime = 1; } } }
«(void)» , «action()» 10 , «disablePause();». «Matrix Falling code» . 130 ROM.
Pour construire et exécuter il suffit de mettre le dossier (ou lien) "esploraAPI" dans "/ arduino / bibliothèques /".Références:
PS Vous pouvez voir et entendre à quoi cela ressemble un peu plus tard lorsque je fais une vidéo acceptable.