Le sujet de la conversation d'aujourd'hui est ce que Python a appris au fil des années de son existence en travaillant avec des images. En effet, en plus des anciens de 1990 ImageMagick et GraphicsMagick, il existe des bibliothèques efficaces modernes. Par exemple, Pillow et Pillow-SIMD plus productif. Leur développeur actif Alexander Karpinsky (
homm ) chez MoscowPython a comparé différentes bibliothèques pour travailler avec des images en Python, a présenté des repères et a parlé de fonctionnalités non évidentes qui sont toujours suffisantes. Dans cet article, une transcription du rapport vous aidera à choisir une bibliothèque pour votre application et à la faire fonctionner le plus efficacement possible.
À propos du conférencier: Alexander Karpinsky travaille chez
Uploadcare et est engagé au service de la modification rapide d'images à la volée. Il est impliqué dans le développement de
Pillow , une bibliothèque populaire pour travailler avec des images en Python, et développe son propre fork de cette bibliothèque,
Pillow-SIMD , qui utilise des instructions de processeur modernes pour des performances maximales.
Contexte
Le service de modification d'image de Uploadcare est un serveur qui reçoit une requête HTTP avec un identifiant d'image et certaines opérations qu'un client doit effectuer. Le serveur doit terminer les opérations et répondre le plus rapidement possible. Le client agit le plus souvent comme un navigateur.
L'ensemble du service peut être décrit comme un wrapper autour de la bibliothèque graphique. La qualité de l'ensemble du projet dépend de la qualité, des performances et de la convivialité de la bibliothèque graphique. Il est facile de deviner que Uploadcare utilise Pillow comme bibliothèque graphique.
Bibliothèques
Nous allons brièvement examiner le type de bibliothèques graphiques en général en Python pour mieux comprendre ce qui sera discuté plus tard.
Oreiller
Oreiller - fork de PIL (Python Imaging Library). Il s'agit d'un projet très ancien, sorti en 1995 pour Python 1.2. Vous pouvez imaginer son âge! À un moment donné, la bibliothèque d'imagerie Python a été abandonnée et son développement s'est arrêté. Un fork de Pillow a été créé pour installer et construire la bibliothèque d'imagerie Python sur des systèmes modernes. Peu à peu, le nombre de modifications nécessaires aux utilisateurs de la bibliothèque d'imagerie Python a augmenté et Pillow 2.0 est sorti, ce qui a ajouté la prise en charge de Python 3. Cela peut être considéré comme le début d'une vie distincte du projet Pillow.
Pillow est un module natif pour Python, la moitié du code est écrit en C, l'autre moitié en Python. Les versions les plus diverses de Python sont prises en charge: 2.7, 3.3+, PP, .
Oreiller-SIMD
Voici ma fourchette de Pillow, qui sort en mai 2016. SIMD signifie Single Instruction, Multiple Data
- Une approche dans laquelle le processeur peut effectuer un plus grand nombre d'actions par cycle en utilisant des instructions modernes.
Pillow-SIMD n'est pas une fourchette au sens classique lorsqu'un projet commence à vivre sa propre vie. Il s'agit d'un remplacement pour Pillow, c'est-à-dire que vous installez une bibliothèque au lieu d'une autre, ne modifiez pas une ligne dans votre code source et obtenez plus de performances.
Pillow-SIMD peut être assemblé avec les instructions SSE4 (par défaut). Il s'agit d'un ensemble d'instructions que l'on trouve dans presque tous les processeurs x86 modernes. Pillow-SIMD peut également être assemblé avec le jeu d'instructions AVX2. Cet ensemble d'instructions est, à commencer par l'architecture Haswell, c'est-à-dire approximativement à partir de 2013.
Opencv
OpenCV (Open Computer Vision) est une autre bibliothèque pour travailler avec des images en Python dont vous avez probablement entendu parler. Il fonctionne depuis 2000. La liaison Python est incluse. Cela signifie que la liaison est constamment pertinente, il n'y a pas de synchronicité entre la bibliothèque elle-même et la liaison.
Malheureusement, cette bibliothèque n'est pas encore prise en charge dans PyPy, car OpenCV est basé sur numpy, et numpy a récemment commencé à fonctionner sous PyPy, et PyC ne prend pas encore en charge OpenCV.
VIPS
Une autre bibliothèque à laquelle il faut prêter attention est VIPS. L'idée principale de
VIPS est que vous n'avez pas besoin de charger toute l'image en mémoire pour travailler avec l'image. La bibliothèque peut charger de petits morceaux, les traiter et les enregistrer. Ainsi, pour traiter des images gigapixels, vous n'avez pas besoin de dépenser des gigaoctets de mémoire.
C'est une bibliothèque assez ancienne - 1993, mais elle a dépassé son temps. Pendant longtemps, on en a peu entendu parler, mais récemment, des liants VIPS pour diverses langues ont commencé à apparaître, y compris pour Go, Node.js, Ruby.
Pendant longtemps j'ai voulu essayer cette bibliothèque, la ressentir, mais je n'ai pas réussi pour une raison très stupide. Je n'ai pas pu comprendre comment installer VIPS, car la liaison était très compliquée. Mais maintenant (en 2017), la liaison pyvips a été libérée par l'auteur du VIPS lui-même, avec lequel il n'y a plus de problème. L'installation et l'utilisation de VIPS sont désormais très faciles. Pris en charge: Python 2.7, 3.3+, RuPu, RuPuZ.
ImageMagick & GraphicsMagick
Si nous parlons de travailler avec des graphiques, nous ne pouvons pas nous empêcher de mentionner les personnes âgées - les bibliothèques
ImageMagick et
GraphicsMagick . Ce dernier était à l'origine un fork d'ImageMagick avec de meilleures performances, mais maintenant leurs performances semblent être égales. Pour autant que je sache, il n'y a pas d'autres différences fondamentales entre eux. Par conséquent, vous pouvez utiliser n'importe lequel, plus précisément, celui que vous préférez utiliser.
Ce sont les plus anciennes bibliothèques que j'ai mentionnées aujourd'hui (1990). Pendant tout ce temps, il y avait plusieurs liants pour Python, et presque tous sont morts en toute sécurité. Parmi ceux qui peuvent être utilisés, il y a:
- La liaison de baguette, qui est construite sur des types de ct, mais n'est plus mise à jour.
- La liaison pgmagick utilise Boost.Python, donc elle se compile très longtemps et ne fonctionne pas dans PyPy. Mais, néanmoins, vous pouvez l'utiliser, je dirais qu'il est préférable à Wand.
Performances
Lorsque nous parlons de travailler avec des images, la première chose qui nous intéresse (au moins pour moi) est la performance, car sinon nous pourrions écrire quelque chose en Python avec nos mains.
La performance n'est pas si simple. Vous ne pouvez pas simplement dire qu’une bibliothèque est plus rapide qu’une autre. Chaque bibliothèque possède un ensemble de fonctions, et chaque fonction fonctionne à une vitesse différente.
En conséquence, il est juste de dire que les performances d'une fonction sont supérieures ou inférieures dans une bibliothèque particulière. Ou vous avez une application qui a besoin d'un certain ensemble de fonctionnalités, et vous faites une référence spécifiquement pour cette fonctionnalité, et dites que telle ou telle bibliothèque fonctionne plus rapidement (plus lentement) pour votre application.
Il est important de vérifier le résultat.
Lorsque vous faites des repères, il est très important de regarder le résultat obtenu. Même si à première vue vous avez écrit le même code, cela ne veut pas dire que c'est la même chose.
Récemment, dans un article comparant les performances de Pillow et d'OpenCV, je suis tombé sur ce code:
from PIL import Image, ImageFilter.BoxBlur im.filter(ImageFilter.BoxBlur(3)) ... import cv2 cv2.blur(im, ksize=(3, 3)) ...
Il semble être là, et là, BoxBlur, et là, et là, argument 3, mais en fait le résultat est différent. Parce que dans Pillow (3), c'est le rayon de flou, et dans OpenCV ksize = (3, 3) est la taille du noyau, c'est-à-dire, grosso modo, le diamètre. Dans ce cas, la valeur correcte pour OpenCV serait 3 * 2 + 1, c'est-à-dire (7, 7).
Quel est le problème?
Pourquoi les performances sont-elles généralement un problème lorsque vous travaillez avec des graphiques? Parce que la complexité de toute opération dépend de plusieurs paramètres, et le plus souvent, la complexité croît linéairement avec chacun d'eux. Et si, par exemple, il y a trois de ces facteurs, et que la complexité dépend linéairement de chacun, alors la complexité dans le cube est obtenue.
Exemple: flou gaussien dans OpenCV.

A gauche, un rayon de 3, à droite, 30. Comme vous pouvez le voir, la différence de vitesse est plus de 10 fois.
Lorsque j'ai été confronté à la tâche d'ajouter un flou gaussien à mon application, je n'étais pas heureux que, hypothétiquement, 900 ms puissent être dépensés en une seule opération. Il y a des milliers de telles opérations par minute dans l'application, et passer autant de temps sur une seule n'est pas pratique. Par conséquent, j'ai étudié le problème et mis en œuvre le flou gaussien dans Pillow, qui fonctionne en temps constant par rapport au rayon. Autrement dit, seule la taille de l'image affecte les performances du flou gaussien.
Mais l'essentiel ici n'est pas que quelque chose fonctionne plus vite ou plus lentement.
Je veux dire que lorsque vous construisez une sorte de système, il est important de comprendre de quels paramètres dépend la complexité de la sortie. Ensuite, vous pouvez limiter ces paramètres ou par d'autres moyens pour faire face à cette complexité.
L'opération la plus courante que nous effectuons avec les images après leur ouverture est probablement le redimensionnement.
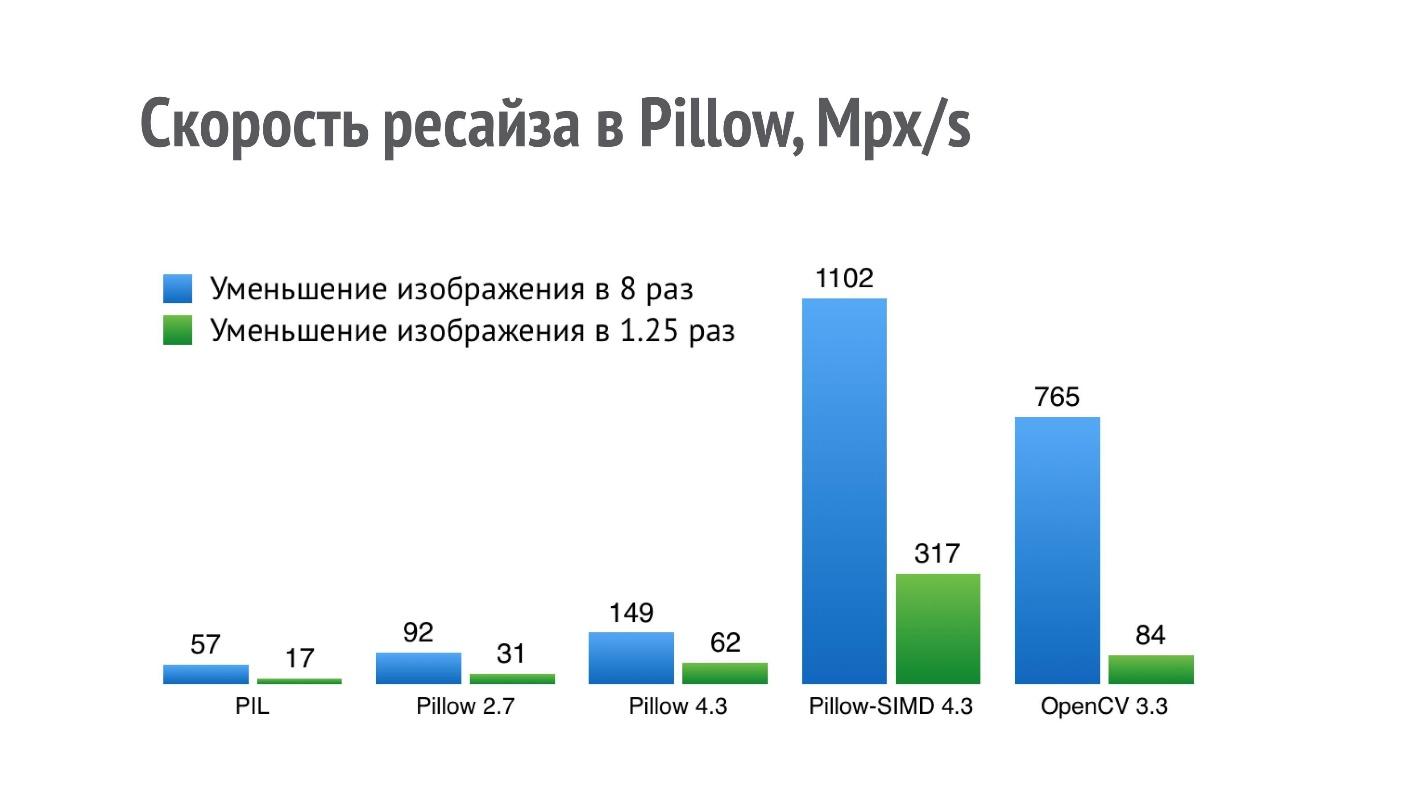
Le graphique montre les performances (plus c'est mieux) de différentes bibliothèques pour l'opération de réduction de l'image de 8 et 1,25 fois.
Pour PIL, un résultat de 17 Mpx / s signifie que la photo d'un iPhone (12 Mpx) peut être réduite de 1,25 fois un peu en moins d'une seconde. De telles performances ne sont pas suffisantes pour une application sérieuse qui effectue un grand nombre de ces opérations.
J'ai commencé à optimiser les performances du redimensionnement, et dans Pillow 2.7, j'ai réussi à doubler la productivité et dans Pillow 4.3 - triple (la version de Pillow 5.3 est actuellement pertinente, mais les performances de redimensionnement sont les mêmes).
Mais l'opération de redimensionnement est une chose qui s'intègre très bien sur SIMD. Il approche une instruction unique, plusieurs données et, par conséquent, dans la version actuelle de Pillow-SIMD, j'ai réussi
à augmenter la vitesse de redimensionnement de 19 fois par rapport à la bibliothèque d'imagerie Python d'origine en utilisant les mêmes ressources.
Ceci est nettement supérieur aux performances de redimensionnement d'OpenCV. Mais la comparaison n'est pas entièrement correcte, car OpenCV utilise une méthode de redimensionnement légèrement moins de haute qualité avec un filtre de boîte, et dans Pillow-SIMD, le redimensionnement est implémenté à l'aide de convolutions.
Ceci est une liste incomplète de ces opérations qui sont accélérées dans Pillow-SIMD par rapport à Pillow ordinaire.
- Redimensionner: 4 à 7 fois.
- Flou: 2,8 fois.
- Application du noyau 3 × 3 ou 5 × 5: 11 fois.
- Multiplication et division par canal alpha: 4 et 10 fois.
- Composition alpha: 5 fois.
J'ai déjà dit que l'on ne peut pas dire que certaines bibliothèques fonctionnent plus rapidement qu'une autre, mais vous pouvez créer un ensemble d'opérations qui vous intéressent. J'ai choisi un ensemble d'opérations qui sont intéressantes dans ma candidature, j'ai fait un benchmark et obtenu de tels résultats.

Il s'est avéré que Pillow-SIMD sur cet ensemble fonctionne 2 fois plus rapidement que Pillow. Tout à la fin est Wand (rappelez-vous que c'est ImageMagick).
Mais je m'intéressais à autre chose - pourquoi OpenCV et VIPS sont-ils si pauvres en résultats, car ce sont des bibliothèques qui sont également conçues en vue de performances? Il s'est avéré que dans le cas d'OpenCV, l'assembly binaire OpenCV qui est installé à l'aide de pip a été assemblé avec un codec JPEG lent (l'auteur de l'assembly a été informé, ce problème a déjà été résolu pour 2018). Il est construit avec libjpeg, tandis que la plupart des systèmes, au moins basés sur Debian, utilisent libjpeg-turbo, qui est plusieurs fois plus rapide. Si vous créez vous-même OpenCV à partir de la source, les performances seront meilleures.
Dans le cas de VIPS, la situation est différente. J'ai contacté l'auteur du VIPS, je lui ai montré cette référence, et nous avons correspondu longtemps et fructueusement. Après cela, l'auteur de VIPS a trouvé plusieurs endroits dans le VIPS lui-même, où l'exécution n'était pas sur la route optimale, et les a corrigés.
C'est ce qui arrivera aux performances si vous construisez OpenCV à partir des sources de la version actuelle et VIPS à partir du maître, qui est déjà là.
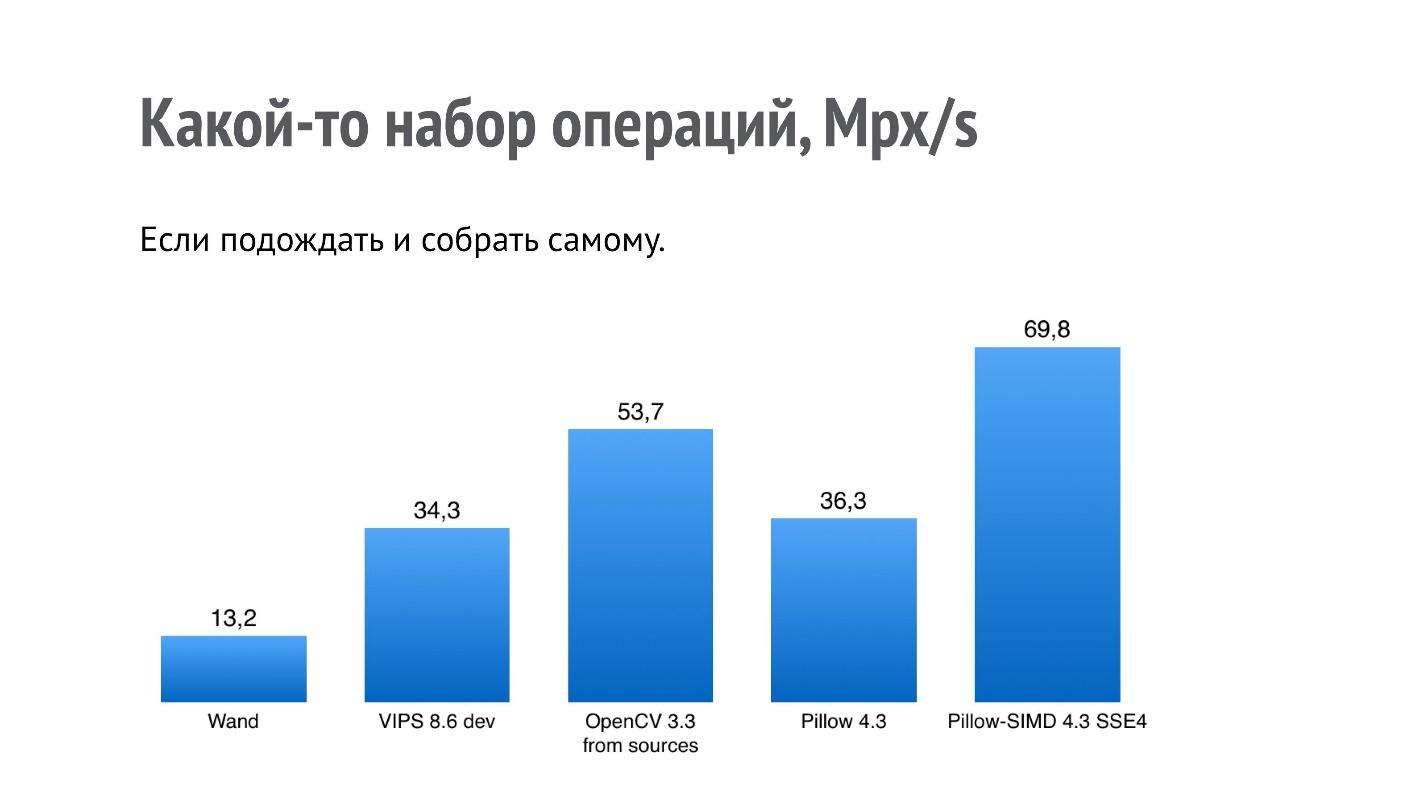
Même si vous trouvez une sorte de référence, ce n'est pas un fait que tout fonctionnera avec cette vitesse exactement sur votre machine.
Ensemble de repères
Tous les benchmarks dont j'ai parlé se trouvent sur
la page des résultats . Il s'agit d'un mini-projet distinct où j'écris des repères dont j'ai moi-même besoin pour développer Pillow-SIMD, les exécuter et publier les résultats.
GitHub a un
projet avec des frameworks de test où chacun peut proposer ses propres benchmarks ou corriger ceux qui existent déjà.
Travail parallèle
Jusqu'à présent, j'ai parlé de performances pures, c'est-à-dire sur un seul cœur de processeur. Mais nous avons tous depuis longtemps accès à des systèmes avec plus de cœurs, et je voudrais en disposer. Ici, je dois dire qu'en fait, Pillow est la seule bibliothèque de toutes celles qui n'utilise pas la parallélisation des tâches. Je vais essayer d'expliquer pourquoi cela se produit. Toutes les autres bibliothèques sous une forme ou une autre l'utilisent.
Mesures de performance
En termes de performances, nous nous intéressons à 2 paramètres:
- Exécution en temps réel d'une opération. Il y a une opération (ou une séquence d'opérations), et vous vous demandez à quelle heure (horloge murale) cette séquence sera exécutée. Ce paramètre est important sur le bureau, où un utilisateur a donné la commande et attend le résultat.
- Débit de l'ensemble du système (workflow). Lorsque vous avez un ensemble d'opérations en cours, ou de nombreuses opérations indépendantes, et la vitesse de traitement de ces opérations sur votre matériel est importante pour vous. Cette métrique est plus importante sur un serveur où il y a de nombreux clients et que vous devez tous les servir. Le temps qu'il faut pour servir un client est certes important, mais légèrement inférieur à la bande passante totale.
Sur la base de ces deux mesures, nous considérons différentes manières de fonctionner en parallèle.
Méthodes de travail parallèles
1.
Au niveau de l'application , lorsque vous décidez au niveau de l'application que les opérations sont traitées dans différents threads. Dans le même temps, le temps d'exécution réel d'une opération ne change pas, car comme auparavant, un cœur est engagé dans une séquence d'opérations. Le débit du système augmente proportionnellement au nombre de cœurs, c'est-à-dire très bon.
2.
Au niveau des opérations graphiques - c'est exactement ce que l'on trouve dans la plupart des bibliothèques graphiques. Lorsqu'une bibliothèque graphique reçoit une sorte d'opération, elle crée le nombre nécessaire de threads en elle-même, divise une opération en plusieurs plus petites et les exécute. Dans le même temps, le temps d'exécution réel est réduit - une opération est plus rapide. Mais le
débit ne croît pas linéairement avec le nombre de cœurs. Il existe des opérations qui ne sont pas parallèles, et un exemple frappant est le décodage des fichiers PNG - il ne peut en aucun cas être parallélisé. En outre, il existe des frais généraux pour la création de threads, le fractionnement des tâches, qui ne permettent pas non plus à la bande passante d'augmenter de manière linéaire.
3.
Au niveau des commandes et des données du processeur . Nous préparons les données d'une manière spéciale et utilisons des commandes spéciales pour rendre le processeur plus rapide avec elles. Il s'agit de l'approche SIMD, qui, en fait, est utilisée dans Pillow-SIMD. Le temps d'exécution en temps réel diminue, le débit augmente - c'est
une option gagnant-gagnant .
Comment combiner le travail parallèle
Si nous voulons combiner en quelque sorte le travail parallèle, alors SIMD fonctionne bien avec la parallélisation à l'intérieur d'une opération, et SIMD fonctionne bien avec la parallélisation à l'intérieur d'une application.

Mais la parallélisation à l'intérieur de l'application et à l'intérieur de l'opération n'est pas compatible entre elles. Si vous essayez de le faire, vous obtiendrez des inconvénients des deux approches. Le temps réel de l'opération sera le même que sur un cœur et le débit du système augmentera, mais pas linéairement par rapport au nombre de cœurs.
Multithreading
Si nous parlons de threads, nous écrivons tous en Python et savons qu'il a un GIL qui empêche deux threads de fonctionner en même temps. Python est un langage strictement monothread.
Bien sûr, ce n'est pas vrai, car le GIL empêche en fait l'exécution de deux threads en Python, et si le code est écrit dans un autre langage et n'utilise pas les structures internes de Python pendant son fonctionnement, ce code peut libérer le GIL et ainsi libérer l'interpréteur pour d'autres tâches.
De nombreuses bibliothèques graphiques publient GIL pendant leur travail, notamment Pillow, OpenCV, pyvips, Wand. Un seul pgmagick ne libère pas. Autrement dit, vous pouvez créer des threads en toute sécurité pour effectuer certaines opérations, et cela fonctionnera en parallèle avec le reste du code.
Mais la question se pose:
combien de threads créer?Si nous créons un nombre infini de threads pour chaque tâche que nous avons, alors ils prennent simplement toute la mémoire et le processeur entier - nous n'obtiendrons aucun travail efficace. J'ai formulé une règle spéciale.
Règle N + 1
Pour un travail productif, vous ne devez pas créer plus de N + 1 travailleurs, où N est le nombre de cœurs ou de threads de processeur sur la machine, et le travailleur est le processus ou le thread impliqué dans le traitement.
Les processus sont mieux utilisés, car même au sein du même interprète, il existe des goulots d'étranglement et des frais généraux.
Par exemple, dans notre application, on utilise l'instance N + 1 Tornado, dont l'équilibre est effectué par ngnix. Si Tornado est mentionné, parlons alors du fonctionnement asynchrone.
Fonctionnement asynchrone
Le temps pendant lequel la bibliothèque graphique effectue un travail réellement utile - traitement d'image - peut et doit être utilisé pour les entrées / sorties, si vous les avez dans l'application. Les cadres asynchrones sont très pertinents ici.
Mais il y a un problème - lorsque nous appelons une sorte de traitement, il est appelé de manière synchrone. Même si la bibliothèque publie le GIL à ce moment, la boucle d'événement est toujours bloquée.
@gen.coroutine def get(self, *args, **kwargs): im = process_image(...) ...
Heureusement, ce problème est très facile à résoudre en créant un ThreadPoolExecutor avec un seul thread sur lequel le traitement d'image démarre. Cet appel se produit déjà de manière asynchrone.
@run_on_executor(executor=ThreadPoolExecutor(1)) def process_image(self, ... @gen.coroutine def get(self, *args, **kwargs): im = yield process_image(...) ...
En substance, une file d'attente avec un travailleur est créée ici qui effectue des opérations graphiques, et la boucle d'événements n'est pas bloquée et s'exécute silencieusement en parallèle dans un autre thread.
Entrée / sortie
Un autre sujet que j'aimerais aborder dans la discussion des opérations graphiques est l'entrée / sortie. Le fait est que nous créons rarement n'importe quel type d'image en utilisant une bibliothèque graphique. Le plus souvent, nous ouvrons des images qui nous sont parvenues d'utilisateurs sous forme de fichiers encodés (JPEG, PNG, BMP, TIFF, etc.).
En conséquence, la bibliothèque graphique pour la construction d'une bonne application devrait avoir quelques avantages pour l'entrée / sortie des fichiers.
Chargement paresseux
Le premier de ces chignons est le chargement paresseux. Si, par exemple, dans Pillow vous ouvrez une image, à ce moment-là, le décodage de l'image ne se produit pas. Vous êtes renvoyé avec un objet qui semble que l'image est déjà chargée et fonctionne. Vous pouvez consulter ses propriétés et décider, sur la base des propriétés de cette image, si vous êtes prêt à continuer à travailler avec elle, si l'utilisateur a téléchargé, par exemple, une image gigapixel afin de rompre votre service.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345))
Si vous décidez quoi faire ensuite, puis en utilisant l'appel explicite ou implicite à charger, cette image est décodée. Déjà à ce moment, la quantité de mémoire nécessaire est allouée.
>>> from PIL import Image >>> %time im = Image.open() Wall time: 1.2 ms >>> im.mode, im.size ('RGB', (2152, 1345)) >>> %time im.load() Wall time: 73.6 ms
Mode d'image interrompue
Le deuxième chignon nécessaire pour travailler avec du contenu généré par l'utilisateur est le mode d'image interrompue. Les fichiers que nous recevons des utilisateurs contiennent très souvent des incohérences avec le format dans lequel ils sont encodés.
Ces écarts se produisent pour diverses raisons. Parfois, c'est une erreur de transmission sur le réseau, parfois ce n'est qu'une sorte de codecs tordus qui ont codé l'image. Par défaut, Pillow, lorsqu'il voit des images qui ne correspondent pas au format à la fin, lève simplement une exception.
from PIL import Image Image.open('trucated.jpg').save('trucated.out.jpg') IOError: image file is truncated (143 bytes not processed)
Mais l'utilisateur n'est pas à blâmer pour le fait que sa photo soit cassée, il veut quand même obtenir le résultat. Heureusement, Pillow a un mode d'image cassé. Nous modifions un paramètre et Pillow essaie d'ignorer au maximum toutes les erreurs de décodage présentes dans l'image. En conséquence, l'utilisateur voit au moins quelque chose.
from PIL import Image, ImageFile ImageFile.LOAD_TRUNCATED_IMAGES = True Image.open('trucated.jpg').save('trucated.out.jpg')

Même une image recadrée est toujours meilleure que rien - juste une page avec une erreur.
Tableau récapitulatif
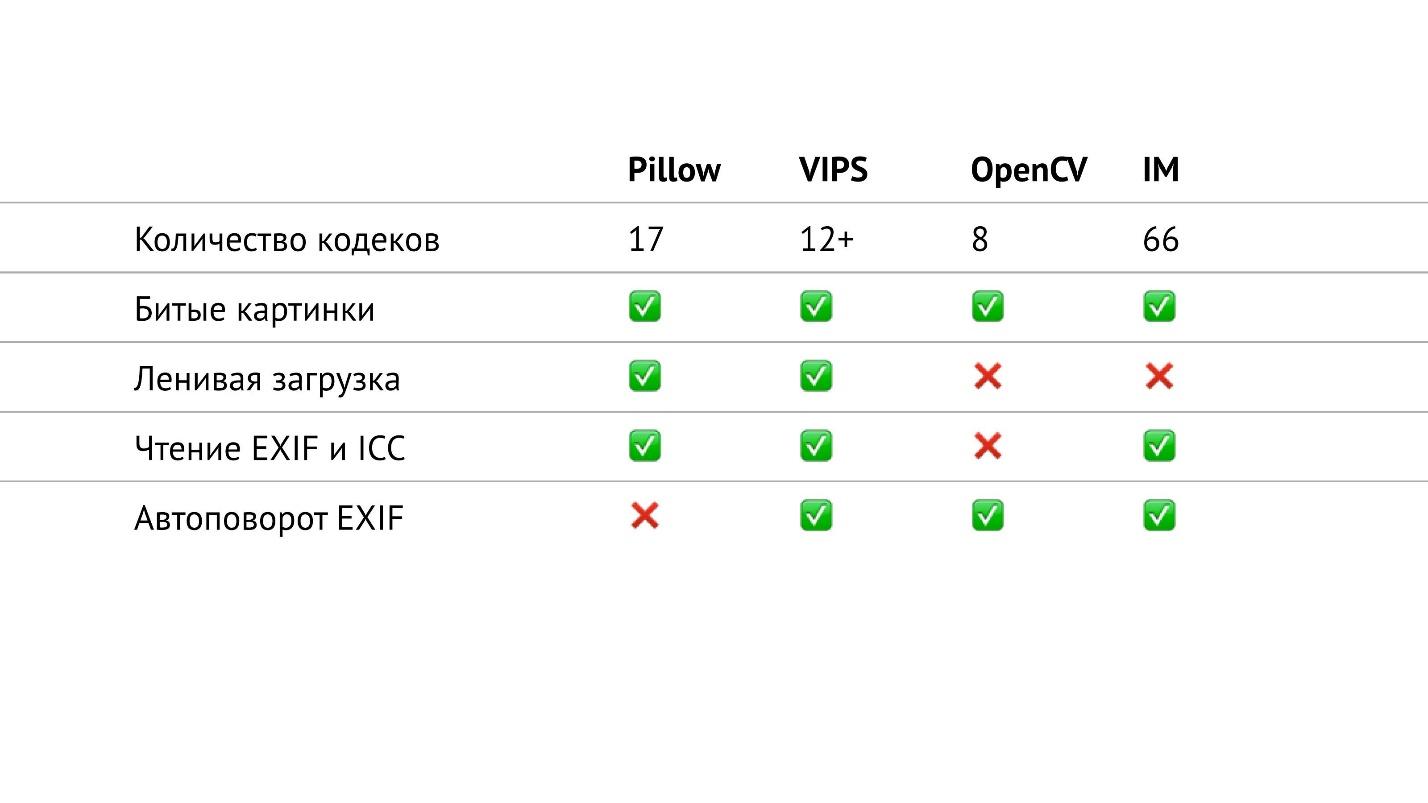
Dans le tableau ci-dessus, j'ai rassemblé tout ce qui concerne les entrées / sorties dans les bibliothèques dont je parle. En particulier, j'ai compté le nombre de codecs de différents formats qui se trouvent dans les bibliothèques. Il s'est avéré que dans OpenCV, ils sont les moins, dans ImageMagick - le plus. Il semble que dans ImageMagick, vous pouvez ouvrir n'importe quelle image que vous rencontrez. VIPS possède 12 codecs natifs, mais VIPS peut utiliser ImageMagick comme intermédiaire. Je n'ai pas testé comment cela fonctionne, j'espère que c'est transparent.
L'oreiller a 17 codecs. C'est maintenant la seule bibliothèque dans laquelle il n'y a pas de rotation automatique EXIF. Mais maintenant, c'est un petit problème, car vous pouvez lire EXIF vous-même et faire pivoter l'image en conséquence. Il s'agit d'un petit extrait, qui est facilement google et prend un maximum de 20 lignes.
Caractéristiques d'OpenCV
Si vous regardez attentivement ce tableau, vous pouvez voir que dans OpenCV, en fait, tout n'est pas si bon avec les entrées / sorties. Il a le moins de codecs, pas de chargement paresseux et vous ne pouvez pas lire EXIF et le profil de couleur.
Mais ce n'est pas tout. En fait, OpenCV a plus de fonctionnalités. Lorsque nous ouvrons simplement une image, l'
cv2.imread(filename) fait tourner les fichiers JPEG conformément à EXIF (voir le tableau), mais ignore le canal alpha des fichiers PNG - un comportement plutôt étrange!
Heureusement, OpenCV a un indicateur:
cv2.imread(filename, flags=cv2.IMREAD_UNCHANGED) .
Si vous spécifiez l'indicateur IMREAD_UNCHANGED, OpenCV quitte le canal alpha pour les fichiers PNG, mais arrête de transformer les fichiers JPEG conformément à EXIF. Autrement dit, le même indicateur affecte deux propriétés complètement différentes. Comme le montre le tableau, OpenCV n'a pas la capacité de lire EXIF, et il s'avère que dans le cas de ce drapeau, il est impossible de faire pivoter JPEG du tout.
Que faire si vous ne savez pas à l'avance le format de votre image et que vous avez besoin à la fois du canal alpha pour PNG et de la rotation automatique pour JPEG? Rien à faire - OpenCV ne fonctionne pas comme ça.
La raison pour laquelle OpenCV a de tels problèmes réside dans le nom de cette bibliothèque. Il possède de nombreuses fonctionnalités pour la vision par ordinateur et l'analyse d'images. En fait, OpenCV est conçu pour fonctionner avec des sources vérifiées. Il s'agit, par exemple, d'une caméra de surveillance extérieure qui prend des images une fois par seconde et le fait pendant 5 ans dans le même format et la même résolution. Il n'y a pas besoin de variabilité en entrée / sortie.
Les personnes qui ont besoin de la fonctionnalité OpenCV n'ont pas vraiment besoin de la fonctionnalité de contenu utilisateur.
Mais que se passe-t-il si votre application a encore besoin de fonctionnalités pour travailler avec le contenu utilisateur, et en même temps vous avez besoin de toute la puissance d'OpenCV pour le traitement et les statistiques?

La solution est de combiner des bibliothèques. Le fait est que OpenCV est construit sur la base de numpy, et Pillow a tous les moyens d'exporter des images de Pillow vers un tableau numpy. Autrement dit, nous exportons le tableau numpy, et OpenCV peut continuer à travailler avec cette image, comme avec la sienne. Cela se fait très facilement:
import numpy from PIL import Image ... pillow_image = Image.open(filename) cv_image = numpy.array(pillow_image)
De plus, lorsque nous faisons de la magie en utilisant OpenCV (traitement), nous appelons une autre méthode Pillow et réimportons l'image d'OpenCV au format Pillow. Par conséquent, les E / S peuvent à nouveau être utilisées.
import numpy from PIL import Image ... pillow_image = Image.fromarray(cv_image, "RGB") pillow_image.save(filename)
Ainsi, il s'avère que nous utilisons les entrées / sorties de Pillow et le traitement à partir d'OpenCV, c'est-à-dire que nous prenons le meilleur des deux mondes.
J'espère que cela vous aidera à créer une application graphique chargée.
Vous pouvez apprendre d'autres secrets de développement en Python, tirer parti d'une expérience inestimable et parfois inattendue, et surtout, vous pouvez discuter de vos tâches très prochainement à Moscou Python Conf ++ . Par exemple, faites attention à ces noms et sujets dans le programme.
- Donald Whyte avec une histoire sur la façon de rendre les mathématiques 10 fois plus rapides à l'aide de bibliothèques, astuces et astuces populaires, et le code est compréhensible et pris en charge.
- Andrei Popov consiste à collecter une énorme quantité de données et à les analyser pour détecter les menaces.
- Ephraim Matosyan dans son rapport «Rendez Python plus rapide» vous expliquera comment augmenter les performances du démon qui traite les messages du bus.
Une liste complète de ce qui sera discuté pour les 22 et 23 octobre ici , a le temps de se joindre.