Bonjour à tous!
Pendant que
Leonid se prépare pour sa première
leçon ouverte dans notre cours
Administrateur Linux , nous continuons à parler du chargement du noyau Linux.
C'est parti!
Comprendre comment un système fonctionne sans échecs - Se préparer à corriger les pannes inévitables
La blague la plus ancienne dans le domaine open source est l'affirmation selon laquelle «le code se documente lui-même». L'expérience a montré que lire le code source, c'est comme écouter les prévisions météorologiques: les gens intelligents iront toujours dehors et regarderont le ciel. Vous trouverez ci-dessous des conseils pour vérifier et examiner le démarrage du système Linux à l'aide d'outils de débogage familiers. Une analyse du processus de démarrage d'un système qui fonctionne bien prépare les utilisateurs et les développeurs à résoudre les plantages inévitables.
D'une part, le processus de téléchargement est étonnamment simple. Le noyau du système d'exploitation (noyau) fonctionne sur un seul thread et de manière synchrone sur un noyau (noyau), ce qui peut sembler compréhensible même pour un esprit humain pathétique. Mais comment démarre le noyau de l'OS? Quelles fonctions font initrd (
un disque RAM pour l'initialisation initiale ) et les chargeurs de démarrage? Et attendez, pourquoi le voyant du port Ethernet est-il toujours allumé?

Lisez la suite pour obtenir des réponses à ces questions et à d'autres; Le code des démos et exercices décrits est également disponible sur
GitHub .
Début de démarrage: statut OFFWake-on-LANUn état OFF signifie que le système n'est pas alimenté, non? La simplicité apparente est trompeuse. Par exemple, le voyant Ethernet est allumé même dans cet état, car le réveil sur réseau local (WOL, réveil sur [le signal du] réseau local) est activé sur votre système. Assurez-vous en écrivant:
$# sudo ethtool <interface name>
À la place, il peut être, par exemple, eth0 (ethtool est dans les packages Linux du même nom). Si le «Wake-on» dans la sortie affiche g, les hôtes distants peuvent démarrer le système en envoyant
MagicPacket . Si vous ne souhaitez pas allumer votre système à distance vous-même et donner cette opportunité aux autres, désactivez WOL dans le menu BIOS du système ou utilisez:
$# sudo ethtool -s <interface name> wol d
Un processeur répondant à MagicPacket peut être un
contrôleur de gestion de la carte mère (BMC) ou une partie d'une interface réseau.
Intel Management Engine, Platform Controller Hub et MinixLe BMC n'est pas le seul microcontrôleur (MCU) qui peut «écouter» un système nominalement éteint. Les systèmes X86_64 disposent du progiciel Intel Management Engine (IME) pour la gestion à distance des systèmes. Une large gamme de périphériques, des serveurs aux ordinateurs portables, dispose d'une technologie
dotée de fonctionnalités telles que le contrôle à distance KVM ou le service de licence de capacité Intel. Selon le
propre outil d'
Inte ,
IME a des vulnérabilités non corrigées. La mauvaise nouvelle est qu'il est difficile de désactiver IME. Trammell Hudson a créé
le projet me_cleaner, qui efface certains des composants IME les plus flagrants, tels que le serveur Web intégré, mais en même temps, il est possible que l'utilisation du projet transforme le système sur lequel il s'exécute en brique.
Le micrologiciel IME et le programme System Management Mode (SMM) qui le suit au démarrage sont basés sur
le système d'exploitation Minix et s'exécutent sur un processeur Platform Controller Hub distinct, et non sur le processeur principal du système. SMM lance ensuite le programme UEFI (Universal Extensible Firmware Interface) sur le processeur principal, qui a été
écrit plus d'une fois . Le groupe Coreboot a lancé un projet
NERF (Non-Extensible Reduced Firmware) spectaculairement ambitieux chez Google, qui vise à remplacer non seulement UEFI, mais aussi les premiers composants de l'espace utilisateur Linux, tels que systemd. En attendant, nous attendons les résultats, les utilisateurs de Linux peuvent acheter des ordinateurs portables auprès de Purism, System76 ou Dell, sur lesquels
IME est désactivé , et nous pouvons espérer des ordinateurs portables avec un
processeur ARM 64 bits .
Chargeurs
Que fait le firmware amorçable en plus du lancement du logiciel espion suspect? La tâche du chargeur de démarrage est de fournir au processeur qui vient d'être allumé les ressources nécessaires pour exécuter un système d'exploitation à usage général comme Linux. Lors de la mise sous tension, il n'y a pas seulement de la mémoire virtuelle, mais aussi de la DRAM jusqu'au moment d'élever son contrôleur. Le chargeur de démarrage allume ensuite les blocs d'alimentation et analyse les bus et les interfaces pour trouver l'image du noyau et le système de fichiers racine. Les chargeurs de démarrage populaires, tels que U-Boot et GRUB, prennent en charge à la fois les interfaces courantes comme USB, PCI et NFS, ainsi que d'autres périphériques intégrés plus spécialisés, tels que les flashs NOR et NAND. Les chargeurs interagissent également avec les périphériques matériels de sécurité, tels que le
module de plateforme sécurisée (TPM) , pour établir une chaîne de confiance dès le début du téléchargement.
 Exécution du chargeur U-boot dans le bac à sable sur le serveur de génération.
Exécution du chargeur U-boot dans le bac à sable sur le serveur de génération.Le chargeur de démarrage
U-Boot open source populaire est pris en charge par les systèmes du Raspberry Pi aux appareils Nintendo, aux cartes de voiture et aux Chromebooks. Il n'y a pas de journal système et en cas de problème, il se peut même qu'il n'y ait pas de sortie de console. Pour faciliter le débogage, l'équipe U-Boot fournit un bac à sable pour tester les correctifs sur l'hôte de génération ou même dans le système d'intégration continue. Sur un système avec des outils de développement communs tels que Git et la collection de compilateurs GNU (GCC) installés, il est facile de comprendre le sandbox U-Boot.
$# git clone git://git.denx.de/u-boot; cd u-boot $# make ARCH=sandbox defconfig $# make; ./u-boot => printenv => help
C'est tout: vous avez lancé U-Boot sur x86_64 et vous pouvez tester des fonctionnalités délicates, par exemple, la répartition des
périphériques de stockage fictifs , la manipulation des clés secrètes basée sur TPM et le branchement à chaud des périphériques USB. Le sandbox U-Boot peut être en une étape dans le débogueur GDB. Le développement utilisant le bac à sable est 10 fois plus rapide que le test en écrasant le chargeur de démarrage sur la carte, de plus, le bac à sable «brique» peut être restauré en appuyant sur Ctrl + C.
Lancement du noyauDémarrage de l'approvisionnement du noyauÀ la fin de ses tâches, le chargeur de démarrage passera au code du noyau qu'il a chargé dans la mémoire principale et commencera à l'exécuter, en passant tous les paramètres de ligne de commande que l'utilisateur a spécifiés. Quel programme est le noyau? file / boot / vmlinuz montre qu'il s'agit de bzImage. L'arborescence des sources Linux possède
un outil extract-vmlinux que vous pouvez utiliser pour extraire le fichier:
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux $# file vmlinux vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, stripped
Le noyau est un fichier binaire
ELF (Executable and Linking Format) , comme les programmes d'espace utilisateur Linux. Cela signifie que nous pouvons utiliser des commandes binutils comme readelf pour l'apprendre. Comparez, par exemple, les conclusions suivantes:
$# readelf -S /bin/date $# readelf -S vmlinux
La liste des partitions dans les fichiers binaires est pour la plupart similaire.
Donc, le noyau devrait lancer d'autres binaires ELF Linux ... Mais comment fonctionnent les programmes d'espace utilisateur? Dans la fonction
main() , non? Pas vraiment.
Avant d'exécuter la fonction
main() , les programmes ont besoin d'un contexte d'exécution, y compris de la mémoire tas (tas) et pile (pile), ainsi que des descripteurs de fichiers pour
stdio ,
stdout et
stderr . Les programmes de l'espace utilisateur obtiennent ces ressources de la bibliothèque standard (
glibc pour la plupart des systèmes Linux). Tenez compte des éléments suivants:
$# file /bin/date /bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a, stripped
Les binaires ELF ont un interpréteur, tout comme les scripts Bash et Python. Mais il n'a pas besoin d'être spécifié via
#! comme dans les scripts, car ELF est un format Linux natif. L'interpréteur ELF fournit au fichier binaire toutes les ressources nécessaires en appelant
_start() , une fonction disponible dans le paquet source
glibc , qui peut être apprise via
GDB . Le noyau, évidemment, n'a pas d'interprète, et il devrait se fournir indépendamment, mais comment?
Une étude sur le démarrage d'un noyau avec GDB fournit une réponse à cette question. Pour commencer, installez le package de débogage du noyau, qui contient la version non coupée de
vmlinux , par exemple,
apt-get install linux-image-amd64-dbg . Ou compilez et installez votre propre noyau à partir d'une source, par exemple, en suivant les instructions de l'excellent
manuel du noyau Debian .
gdb vmlinux suivi des
info files montre la section ELF
init.text . Indiquez le début de l'exécution du programme dans
init.text avec
l *(address) , où adresse est le début hexadécimal de
init.text . GDB indiquera que le noyau x86_64 est lancé dans le
arch/x86/kernel/head_64.S , où nous trouvons la fonction de construction
start_cpu0() et le code qui crée explicitement la pile et décompresse zImage avant d'appeler
x86_64 start_kernel() . Les cœurs ARM 32 bits ont un
arch/arm/kernel/head.S. start_kernel() arch/arm/kernel/head.S. start_kernel() est indépendant de l'architecture, donc la fonction est située dans le noyau
init/main.c On peut dire que
start_kernel() est une vraie fonction Linux
main() .
De start_kernel () à PID 1Manifeste matériel du noyau: tables ACPI et arborescences de périphériquesLors du démarrage, le noyau a besoin d'informations sur le matériel en plus du type de processeur pour lequel il a été compilé. Les instructions du code sont complétées par des données de configuration, qui sont stockées séparément. Il existe deux méthodes principales de stockage des données: les
arborescences de périphériques et les
tables ACPI . À partir de ces fichiers, le noyau découvre quel équipement doit être exécuté à chaque démarrage.
Pour les périphériques intégrés, l'arborescence des périphériques (DU) est un manifeste de l'équipement installé. DU est un fichier qui se compile en même temps que la source du noyau et se trouve généralement dans / boot avec
vmlinux . Pour voir ce qui se trouve dans l'arborescence des périphériques binaires sur le périphérique ARM, utilisez simplement la commande
strings du package binutils dans le fichier dont le nom correspond à
/boot/*.dtb , car
dtb signifie le fichier binaire de l'arborescence des périphériques (Device-Tree Binary). Vous pouvez modifier la télécommande en modifiant les fichiers de type JSON qui la composent et en redémarrant le compilateur spécial dtc fourni avec la source du noyau. DU est un fichier statique dont le chemin est généralement transmis au noyau par les chargeurs de démarrage sur la ligne de commande, mais ces dernières années, une
superposition d'arborescence de périphériques a été ajoutée où le noyau peut charger dynamiquement des fragments supplémentaires en réponse aux événements de connexion à chaud après le chargement.
La famille x86 et de nombreux appareils de niveau professionnel ARM64 utilisent le mécanisme alternatif de configuration avancée et d'interface d'alimentation (
ACPI) . Contrairement à la télécommande, les informations ACPI sont stockées dans le système de fichiers virtuel
/sys/firmware/acpi/tables , qui est créé par le noyau au démarrage en accédant à la ROM interne. Pour lire les tables ACPI, utilisez la commande
acpica-tools package
acpica-tools . Voici un exemple:
 Les tableaux ACPI sur les ordinateurs portables Lenovo sont prêts pour Windows 2001.
Les tableaux ACPI sur les ordinateurs portables Lenovo sont prêts pour Windows 2001.Oui, votre système Linux est prêt pour Windows 2001 si vous souhaitez l'installer. ACPI a à la fois des méthodes et des données, contrairement à la télécommande, qui ressemble plus à un langage de description matérielle. Les méthodes ACPI restent actives après le démarrage. Par exemple, si vous exécutez la commande acpi_listen (à partir du package apcid), puis fermez et ouvrez le couvercle de l'ordinateur portable, vous verrez que la fonctionnalité ACPI a continué à fonctionner pendant tout ce temps. Une
réécriture temporaire et dynamique
des tables ACPI est possible, mais une modification permanente nécessitera une interaction avec le menu du BIOS au démarrage ou le flashage de la ROM. Au lieu de telles complexités, vous devriez peut-être simplement
installer coreboot , un remplacement pour le firmware open source.
De start_kernel () à l'espace utilisateur
Le code dans
init/main.c est étonnamment facile à lire et, curieusement, porte toujours le copyright original de Linus Torvalds de 1991-1992. Lignes trouvées à
dmesg | head dmesg | head système en cours d'exécution provient essentiellement de ce fichier source. Le premier CPU est enregistré par le système, les structures de données globales sont initialisées, le planificateur, les gestionnaires d'interruption (IRQ), les temporisateurs et la console sont levés les uns après les autres. Tous les horodatages avant d'exécuter
timekeeping_init() sont nuls. Cette partie de l'initialisation du noyau est synchrone, c'est-à-dire que l'exécution se produit dans un seul thread. Les fonctions ne sont exécutées que lorsque la dernière d'entre elles est terminée et renvoyée. En conséquence, la sortie
dmesg sera entièrement reproductible même entre les deux systèmes, tant qu'ils ont la même télécommande ou les mêmes tables ACPI. Linux se comporte également comme un système d'exploitation en temps réel (RTOS) fonctionnant sur un MCU, tel que QNX ou VxWorks. Cette situation est stockée dans la fonction
rest_init() , qui est appelée par
start_kernel() au moment de son achèvement.
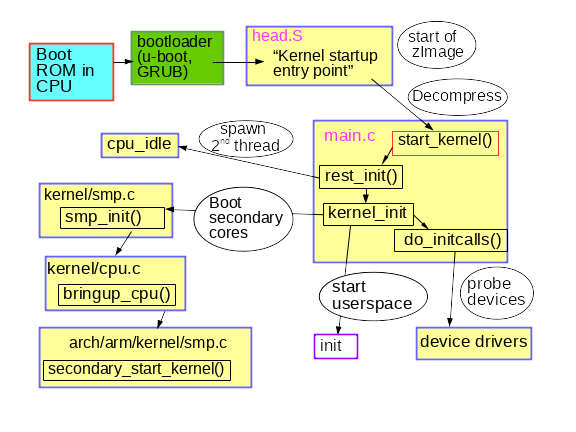 Une brève description du processus de démarrage précoce du noyau
Une brève description du processus de démarrage précoce du noyau
Le modestement nommé
rest_init() crée un nouveau thread qui exécute
kernel_init() , qui à son tour appelle
do_initcalls() . Les utilisateurs peuvent surveiller le fonctionnement des
initcalls en ajoutant
initcalls_debug à la ligne de commande du noyau. Par conséquent, vous obtiendrez l'entité
dmesg chaque fois que vous exécutez la fonction
initcall .
initcalls passe par sept niveaux consécutifs: early, core, postcore, arch, subsys, fs, device et late. La partie la plus notable des
initcalls pour les utilisateurs est l'identification et l'installation des périphériques du processeur: bus, réseau, stockage, écrans, etc., accompagnés du chargement de leurs modules du noyau.
rest_init() crée également un deuxième thread dans le processeur de démarrage, qui commence par exécuter
cpu_idle() pendant que le planificateur distribue son travail.
kernel_init() configure également le
multitraitement symétrique (SMP). Dans les noyaux modernes, vous pouvez trouver ce moment dans la sortie dmesg par la ligne "Bringing up secondary CPUs ...". SMP fabrique ensuite le CPU à chaud, ce qui signifie qu'il gère son cycle de vie à l'aide d'une machine d'état conditionnellement similaire à celles utilisées dans des appareils tels que les clés USB à détection automatique. Le système de gestion de l'alimentation du noyau arrête souvent les cœurs individuels (cœurs) et les réveille selon les besoins afin que le même code CPU hotplug soit appelé à plusieurs reprises sur une machine inoccupée. Jetez un œil à la façon dont un système de gestion de l'alimentation appelle un hotplug CPU à l'aide d'
un outil BCC appelé
offcputime.py .
Notez que le code dans
init/main.c presque terminé son exécution lorsque
smp_init() exécuté. Le processeur de démarrage a terminé la plupart de l'initialisation unique, que les autres noyaux n'ont pas besoin de répéter. Cependant, des threads doivent être créés pour chaque cœur afin de contrôler les interruptions (IRQ), la file d'attente de travail, les temporisateurs et les événements d'alimentation sur chacun d'eux. Par exemple, regardez les threads du processeur qui servent les softirqs et les files d'attente de travail avec la commande
ps -o psr. $\
où le champ PSR signifie «processeur». Chaque cœur doit avoir ses propres temporisateurs et gestionnaires de hotplug cpuhp.
Et enfin, comment est lancé l'espace utilisateur? Vers la fin,
kernel_init() recherche un
initrd qui peut démarrer le processus
init en son nom. Sinon, le noyau exécute
init lui-même. Pourquoi alors
initrd peut être nécessaire?
Espace utilisateur précoce: qui a commandé initrd?En plus de l'arborescence des périphériques, un autre chemin d'initialisation du fichier, éventuellement fourni par le noyau au démarrage, appartient à
initrd .
initrd souvent dans / boot avec le fichier bzImage vmlinuz sur x86, ou avec une uImage similaire et une arborescence de périphériques pour ARM. Une liste du contenu
intrd peut être consultée à l'aide de l'outil
lsinitramfs , qui fait partie du package
initramfs-tools-core . L'image de distribution initrd contient les répertoires minimum
/bin ,
/sbin et
/etc , ainsi que les modules et fichiers du noyau dans
/scripts . Tout devrait être plus ou moins familier, car
initrd pour la plupart similaire au système de fichiers racine Linux simplifié. Cette similitude est un peu trompeuse, car presque tous les exécutables dans
/bin et
/sbin intérieur du ramdisk sont des liens symboliques vers le
binaire BusyBox , ce qui rend les répertoires / bin et / sbin 10 fois plus petits que dans la
glibc .
Pourquoi essayer de créer un
initrd si la seule chose qu'il fait est de charger certains modules et d'exécuter
init sur un système de fichiers racine normal? Prenons un système de fichiers racine chiffré. Le déchiffrement peut dépendre du chargement du module du noyau stocké dans
/lib/modules système de fichiers racine ... et, comme prévu, dans
initrd . Le module crypto peut être compilé statiquement dans le noyau, et non chargé à partir d'un fichier, mais il y a plusieurs raisons de le refuser. Par exemple, la compilation statique d'un noyau avec des modules peut le rendre trop volumineux pour tenir dans le stockage disponible, ou la compilation statique peut violer les termes de la licence du logiciel. Sans surprise, les pilotes de stockage, les réseaux et les HID (périphériques d'entrée humains) peuvent également être représentés dans
initrd - essentiellement tout code qui n'est pas une partie requise du noyau nécessaire pour monter le système de fichiers racine. Toujours dans initrd, les utilisateurs peuvent stocker
leur propre code ACPI pour les tables .
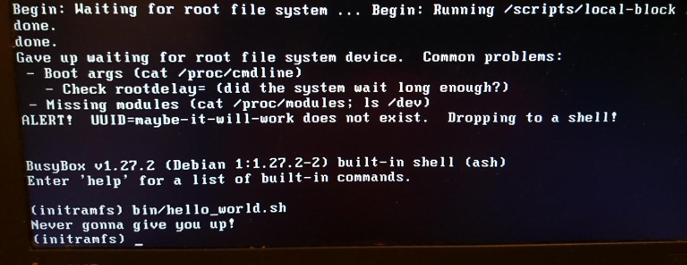 Amusez-vous avec la coquille de sauvetage et l'initrd personnalisé.
Amusez-vous avec la coquille de sauvetage et l'initrd personnalisé.initrd également idéal pour tester les systèmes de fichiers et les périphériques de stockage. Placez les outils de test dans
initrd et exécutez les tests à partir de la mémoire, pas à partir de l'objet de test.
Enfin, lorsque
init cours d'exécution, le système fonctionne! Comme les processeurs secondaires sont déjà en cours d'exécution, la machine est devenue une créature asynchrone, paginée, imprévisible et performante que nous connaissons et aimons tous. En effet,
ps -o pid,psr,comm -p indique que le processus d'
init espace utilisateur ne s'exécute plus sur le processeur de démarrage.
RésuméLe processus de démarrage Linux semble interdit, compte tenu de la quantité de logiciels affectés, même sur un simple périphérique intégré. D'un autre côté, le processus de démarrage est assez simple, car il n'y a pas de complexité excessive causée par l'éviction du multitâche, du RCU et des conditions de course. En faisant attention uniquement au noyau et au PID 1, on peut ignorer l'excellent travail accompli par les chargeurs de démarrage et les processeurs auxiliaires pour préparer la plate-forme au lancement du noyau. Le noyau est certainement différent des autres programmes Linux, mais l'utilisation d'outils pour travailler avec d'autres binaires ELF aidera à mieux comprendre sa structure. L'étude d'un processus de démarrage réalisable préparera de futurs plantages.
LA FIN
Nous attendons vos commentaires et questions, comme d'habitude, ici ou à notre
leçon ouverte où Leonid sera époustouflé.