Essence
Il s'avère que pour cela, il suffit d'exécuter un tel ensemble de commandes:
git clone https://github.com/attardi/wikiextractor.git cd wikiextractor wget http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 python3 WikiExtractor.py -o ../data/wiki/ --no-templates --processes 8 ../data/ruwiki-latest-pages-articles.xml.bz2
puis polir un peu avec un script pour le post-traitement
python3 process_wikipedia.py
Le résultat est un fichier .csv terminé avec votre corps.
Il est clair que:
http://dumps.wikimedia.org/ruwiki/latest/ruwiki-latest-pages-articles.xml.bz2 peut être modifié dans la langue dont vous avez besoin, plus de détails ici [4] ;- Toutes les informations sur les paramètres de
wikiextractor se trouvent dans le manuel (il semble que même le dock officiel n'a pas été mis à jour, contrairement au mana);
Un script de post-traitement convertit les fichiers wiki en une table comme celle-ci:
| idx | article_uuid | phrase | phrase nettoyée | durée de la phrase nettoyée |
|---|
| 0 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean I de Chatillon (Comte de Pentevre) Jean I de ... | jean i de châtillon comte de pentevre jean i de cha ... | 38 |
| 1 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Était sous la protection de Robert de Vera, comte O ... | a été gardé par robert de vera graph oxford ... | 18 |
| 2 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Cependant, Henry de Gromont, gr ... | cependant, Henry de Gromon gras s'y est opposé ... | 14 |
| 3 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Le roi lui a offert une autre caractéristique importante en tant qu'épouse ... | le roi a offert à sa femme une autre personne importante de fili ... | 48 |
| 4 | 74fb822b-54bb-4bfb-95ef-4eac9465c7d7 | Jean a été libéré et rentré en France en 138 ... | jean libéré retour france année mariage m ... | 52 |
article_uuid - une clé pseudo-unique, l'ordre des idées doit être conservé après un tel prétraitement.
Pourquoi
Peut-être, pour le moment, le développement des outils ML a atteint un tel niveau [8] que littéralement quelques jours suffisent pour construire un modèle / pipeline NLP fonctionnel. Les problèmes ne surviennent qu'en l'absence d'ensembles de données fiables / intégrations prêtes / modèles de langage prêts. Le but de cet article est de soulager un peu votre douleur en montrant que quelques heures suffisent pour traiter l'ensemble de Wikipédia (en théorie le corpus le plus populaire pour la formation des incorporations de mots en PNL). Après tout, si quelques jours suffisent pour construire un modèle simple, pourquoi passer beaucoup plus de temps à obtenir des données pour ce modèle?
Le principe du script
wikiExtractor enregistre les articles Wiki sous forme de texte séparé par des blocs <doc> . En fait, le script est basé sur la logique suivante:
- Prenez une liste de tous les fichiers dans la sortie;
- Nous divisons les fichiers en articles;
- Supprimez toutes les balises HTML et caractères spéciaux restants;
- En utilisant
nltk.sent_tokenize divisons en phrases; - Pour que le code n'atteigne pas une taille énorme et reste lisible, chaque article se voit attribuer son propre uuid;
En tant que prétraitement de texte, c'est simple (vous pouvez facilement le couper par vous-même):
- Supprimer les caractères autres que des lettres;
- Supprimer les mots vides;
Le jeu de données est, et maintenant?
Application principale
Le plus souvent, dans la pratique, en PNL, vous devez gérer la tâche de construire des plongements.
Pour le résoudre, utilisez généralement l'un des outils suivants:
- Vecteurs / incorporations de mots prêts à l'emploi [6];
- Les états internes de CNN se sont entraînés sur des tâches telles que la définition de fausses phrases / modélisation / classification du langage [7];
- Une combinaison des méthodes ci-dessus;
De plus, il a été démontré à maintes reprises [9] que comme bonne base de référence pour l'incorporation de phrases, on peut également prendre des vecteurs de mots simplement moyennés (avec quelques détails mineurs, que nous omettons maintenant).
Autres cas d'utilisation
- Nous utilisons des phrases aléatoires de Wiki comme exemples négatifs de perte de triplet;
- Nous formons des encodeurs pour les phrases en utilisant la définition de fausses phrases [10];
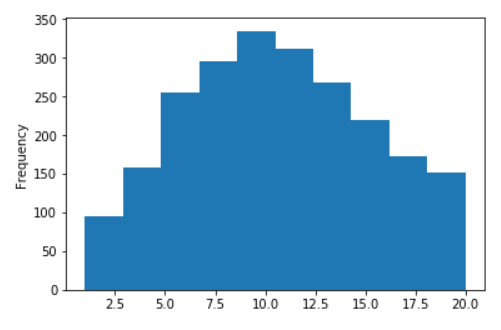
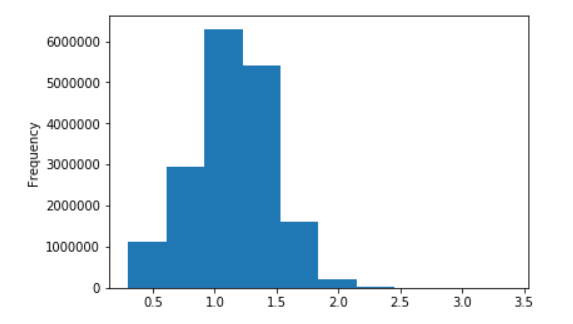
Quelques graphiques pour le wiki russe
Distribution de la longueur des phrases pour Wikipedia russe
Pas de logarithmes (sur l'axe X, les valeurs sont limitées à 20)
En logarithmes décimaux
Les références
- Des vecteurs de mots à texte rapide formés sur un wiki;
- Modèles de texte rapide et Word2Vec pour la langue russe;
- Bibliothèque impressionnante d'extraction de wiki pour python;
- La page officielle avec des liens pour Wiki;
- Notre script pour le post-traitement;
- Articles principaux sur l'intégration de mots: Word2Vec , Fast-Text , optimisation ;
- Plusieurs approches SOTA actuelles:
- InferSent ;
- CNN pré-formation générative;
- ULMFiT ;
- Approches contextuelles pour la représentation des mots (Elmo);
- Moment Imagenet en PNL ?
- Bases de référence pour l'intégration des propositions 1 , 2 , 3 , 4 ;
- Définition de fausses phrases pour l'encodeur d'offre;