La théorie des jeux est une discipline mathématique qui considère la modélisation des actions des joueurs qui ont un objectif, qui est de choisir les stratégies optimales de comportement dans un conflit. Sur Habré, ce sujet a déjà été
abordé , mais aujourd'hui nous allons parler de certains de ses aspects plus en détail et considérer des exemples sur Kotlin.
Ainsi, une stratégie est un ensemble de règles qui déterminent le choix d'une ligne de conduite pour chaque mouvement personnel, selon la situation. La stratégie optimale du joueur est la stratégie qui garantit la meilleure position dans un jeu donné, c'est-à-dire gain maximum. Si le jeu est répété plusieurs fois et contient, en plus des mouvements personnels et aléatoires, la stratégie optimale fournit le gain moyen maximum.
La tâche de la théorie des jeux est d'identifier les stratégies optimales pour les joueurs. L'hypothèse principale, basée sur les stratégies optimales trouvées, est que l'adversaire (ou les adversaires) n'est pas moins intelligent que le joueur lui-même et fait tout pour atteindre son objectif. Le calcul d'un adversaire raisonnable n'est qu'une des positions potentielles du conflit, mais dans la théorie des jeux c'est lui qui est posé dans les fondements.
Il existe des jeux avec la nature dans lesquels un seul participant maximise ses profits. Les jeux avec la nature sont des modèles mathématiques dans lesquels le choix de la solution dépend de la réalité objective. Par exemple, la demande des consommateurs, l'état de la nature, etc. La «nature» est un concept généralisé d'un adversaire qui ne poursuit pas ses propres objectifs. Dans ce cas, plusieurs critères sont utilisés pour sélectionner la stratégie optimale.
Il existe deux types de tâches dans les jeux avec la nature:
- la tâche de prendre des décisions dans des conditions de risque lorsque les probabilités avec lesquelles la nature accepte chacun des états possibles sont connues;
- tâches de décision dans des conditions d'incertitude, lorsqu'il n'est pas possible d'obtenir des informations sur les probabilités d'occurrence d'états de la nature.
Brièvement sur ces critères est décrit
ici .
Nous allons maintenant considérer les critères de décision dans les stratégies pures, et à la fin de l'article, nous allons résoudre le jeu dans les stratégies mixtes par la méthode analytique.
RéservationJe ne suis pas un spécialiste de la théorie des jeux, mais dans ce travail, j'ai utilisé Kotlin pour la première fois. Cependant, j'ai décidé de partager mes résultats. Si vous remarquez des erreurs dans l'article ou si vous souhaitez donner des conseils, veuillez en PM.
Énoncé du problème
Nous analyserons tous les critères de prise de décision à l'aide d'un exemple traversant. La tâche est la suivante: l'agriculteur doit déterminer dans quelles proportions semer son champ avec trois cultures, si le rendement de ces cultures et, par conséquent, le profit, dépendent de la façon dont l'été sera: frais et pluvieux, normal ou chaud et sec. L'agriculteur a calculé le bénéfice net de 1 hectare de différentes cultures en fonction de la météo. Le jeu est déterminé par la matrice suivante:

Nous présenterons ensuite cette matrice sous forme de stratégies:
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1)
La stratégie optimale souhaitée est indiquée par
uopt . Nous allons résoudre le jeu en utilisant les critères Wald, l'optimisme, le pessimisme, Savage et Hurwitz face à l'incertitude et les critères Bayes et Laplace en risque.
Comme mentionné ci-dessus, les exemples seront sur Kotlin. Je note qu'en général, il existe des solutions telles que Gambit (écrit en C), Axelrod et PyNFG (écrit en Python), mais nous roulerons sur notre propre vélo, assemblé sur le genou, juste afin de pousser un peu élégant, à la mode et langage de programmation pour les jeunes.
Pour implémenter par programmation la solution du jeu, nous allons introduire plusieurs classes. Tout d'abord, nous avons besoin d'une classe qui nous permet de décrire une ligne ou une colonne d'une matrice de jeu. La classe est extrêmement simple et contient une liste de valeurs possibles (alternatives ou états de la nature) et leur nom correspondant. Le champ
key sera utilisé pour l'identification, ainsi que pour la comparaison, et la comparaison sera nécessaire dans la mise en œuvre de la domination.
Ligne ou colonne de matrice de jeu import java.text.DecimalFormat import java.text.NumberFormat open class GameVector(name: String, values: List<Double>, key: Int = -1) : Comparable<GameVector> { val name: String val values: List<Double> val key: Int private val formatter:NumberFormat = DecimalFormat("#0.00") init { this.name = name; this.values = values; this.key = key; } public fun max(): Double? { return values.max(); } public fun min(): Double? { return values.min(); } override fun toString(): String{ return name + ": " + values .map { v -> formatter.format(v) } .reduce( {f1: String, f2: String -> "$f1 $f2"}) } override fun compareTo(other: GameVector): Int { var compare = 0 if (this.key == other.key){ return compare } var great = true for (i in 0..this.values.lastIndex){ great = great && this.values[i] >= other.values[i] } if (great){ compare = 1 }else{ var less = true for (i in 0..this.values.lastIndex){ less = less && this.values[i] <= other.values[i] } if (less){ compare = -1 } } return compare } }
La matrice du jeu contient des informations sur les alternatives et les états de la nature. De plus, il implémente certaines méthodes, par exemple, trouver l'ensemble dominant et le prix net du jeu.
Matrice de jeu open class GameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>, natureStateNames: List<String>) { val matrix: List<List<Double>> val alternativeNames: List<String> val natureStateNames: List<String> val alternatives: List<GameVector> val natureStates: List<GameVector> init { this.matrix = matrix; this.alternativeNames = alternativeNames this.natureStateNames = natureStateNames var alts: MutableList<GameVector> = mutableListOf() for (i in 0..matrix.lastIndex) { val currAlternative = alternativeNames[i] val gameVector = GameVector(currAlternative, matrix[i], i) alts.add(gameVector) } alternatives = alts.toList() var nss: MutableList<GameVector> = mutableListOf() val lastIndex = matrix[0].lastIndex // , for (j in 0..lastIndex) { val currState = natureStateNames[j] var states: MutableList<Double> = mutableListOf() for (i in 0..matrix.lastIndex) { states.add(matrix[i][j]) } val gameVector = GameVector(currState, states.toList(), j) nss.add(gameVector) } natureStates = nss.toList() } open fun change (i : Int, j : Int, value : Double) : GameMatrix{ var mml = this.matrix.toMutableList() var rowi = mml[i].toMutableList() rowi.set(j, value) mml.set(i, rowi) return GameMatrix(mml.toList(), alternativeNames, natureStateNames) } open fun changeAlternativeName (i : Int, value : String) : GameMatrix{ var list = alternativeNames.toMutableList() list.set(i, value) return GameMatrix(matrix, list.toList(), natureStateNames) } open fun changeNatureStateName (j : Int, value : String) : GameMatrix{ var list = natureStateNames.toMutableList() list.set(j, value) return GameMatrix(matrix, alternativeNames, list.toList()) } fun size() : Pair<Int, Int>{ return Pair(alternatives.size, natureStates.size) } override fun toString(): String { return " :\n" + natureStateNames.reduce { n1: String, n2: String -> "$n1;\n$n2" } + "\n :\n" + alternatives .map { a: GameVector -> a.toString() } .reduce { a1: String, a2: String -> "$a1;\n$a2" } } protected fun dominateSet(gvl: List<GameVector>, list: MutableList<String>, dvv: Int) : MutableSet<GameVector>{ var dSet: MutableSet<GameVector> = mutableSetOf() for (gv in gvl){ for (gvv in gvl){ if (!dSet.contains(gv) && !dSet.contains(gvv)) { if (gv.compareTo(gvv) == dvv) { dSet.add(gv) list.add("[$gvv] [$gv]") } } } } return dSet } open fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>) : GameMatrix{ var result: MutableList<MutableList<Double>> = mutableListOf() var ralternativeNames: MutableList<String> = mutableListOf() var rnatureStateNames: MutableList<String> = mutableListOf() val dIndex = dCol.map { c -> c.key }.toList() for (i in 0 .. natureStateNames.lastIndex){ if (!dIndex.contains(i)){ rnatureStateNames.add(natureStateNames[i]) } } for (gv in this.alternatives){ if (!dRow.contains(gv)){ var nr: MutableList<Double> = mutableListOf() for (i in 0 .. gv.values.lastIndex){ if (!dIndex.contains(i)){ nr.add(gv.values[i]) } } result.add(nr) ralternativeNames.add(gv.name) } } val rlist = result.map { r -> r.toList() }.toList() return GameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList()) } fun dominateMatrix(): Pair<GameMatrix, List<String>>{ var list: MutableList<String> = mutableListOf() var dCol: MutableSet<GameVector> = dominateSet(this.natureStates, list, 1) var dRow: MutableSet<GameVector> = dominateSet(this.alternatives, list, -1) val newMatrix = newMatrix(dCol, dRow) var ddgm = Pair(newMatrix, list.toList()) val ret = iterate(ddgm, list) return ret; } protected fun iterate(ddgm: Pair<GameMatrix, List<String>>, list: MutableList<String>) : Pair<GameMatrix, List<String>>{ var dgm = this var lddgm = ddgm while (dgm.size() != lddgm.first.size()){ dgm = lddgm.first list.addAll(lddgm.second) lddgm = dgm.dominateMatrix() } return Pair(dgm,list.toList().distinct()) } fun minClearPrice(): Double{ val map: List<Double> = this.alternatives.map { a -> a?.min() ?: 0.0 } return map?.max() ?: 0.0 } fun maxClearPrice(): Double{ val map: List<Double> = this.natureStates.map { a -> a?.max() ?: 0.0 } return map?.min() ?: 0.0 } fun existsClearStrategy() : Boolean{ return minClearPrice() >= maxClearPrice() } }
Nous décrivons l'interface qui répond aux critères
Critère interface ICriteria { fun optimum(): List<GameVector> }
Prise de décision dans l'incertitude
Prendre des décisions face à l'incertitude suggère que le joueur n'est pas opposé à un adversaire raisonnable.
Critère de Wald
Le critère de Wald maximise le pire résultat possible:
uopt=maximinj[U]
L'utilisation du critère assure contre le pire résultat, mais le prix d'une telle stratégie est la perte de l'opportunité d'obtenir le meilleur résultat possible.
Prenons un exemple. Pour les stratégies
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) trouver les bas et obtenir les trois prochains
S=(0,1,−1) . Le maximum pour le triple indiqué sera la valeur 1, donc, selon le critère de Wald, la stratégie gagnante est la stratégie
U2=(2,3,1) correspondant à Plantation Culture 2.
L'implémentation logicielle du critère Wald est simple:
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == max!!.second } .map { m -> m.first } } }
Par souci de clarté, pour la première fois, je montrerai à quoi ressemblerait la solution comme un test:
Test private fun matrix(): GameMatrix { val alternativeNames: List<String> = listOf(" 1", " 2", " 3") val natureStateNames: List<String> = listOf(" ", "", " ") val matrix: List<List<Double>> = listOf( listOf(0.0, 2.0, 5.0), listOf(2.0, 3.0, 1.0), listOf(4.0, 3.0, -1.0) ) val gm = GameMatrix(matrix, alternativeNames, natureStateNames) return gm; } } private fun testCriteria(gameMatrix: GameMatrix, criteria: ICriteria, name: String){ println(gameMatrix.toString()) val optimum = criteria.optimum() println("$name. : ") optimum.forEach { o -> println(o.toString()) } } @Test fun testWaldCriteria() { val matrix = matrix(); val criteria = WaldCriteria(matrix) testCriteria(matrix, criteria, " ") }
Il est facile de deviner que pour d'autres critères, la différence ne sera que dans la création de l'objet
criteria .
Critère d'optimisme
Lorsqu'il utilise le critère d'un optimiste, le joueur choisit une solution qui donne le meilleur résultat, tandis que l'optimiste suppose que les conditions de jeu lui seront les plus favorables:
uopt=maximaxj[U]
La stratégie d’un optimiste peut entraîner des conséquences négatives lorsque l’offre maximale coïncide avec la demande minimale - l’entreprise peut subir des pertes lors de la radiation de produits invendus. Dans le même temps, la stratégie de l'optimiste a une certaine signification, par exemple, vous n'avez pas besoin de prendre soin des clients insatisfaits, car toute demande possible est toujours satisfaite, il n'est donc pas nécessaire de maintenir l'emplacement des clients. Si la demande maximale est réalisée, la stratégie de l'optimiste vous permet d'obtenir une utilité maximale tandis que d'autres stratégies entraîneront une perte de profits. Cela donne certains avantages concurrentiels.
Prenons un exemple. Pour les stratégies
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) trouver, trouver le maximum et obtenir les trois prochains
S=(5,3,4) . Le maximum pour le triple indiqué sera la valeur 5, donc, selon le critère d'optimisme, la stratégie gagnante est la stratégie
U1=(0,2,5) correspondant à Plantation Culture 1.
La mise en œuvre du critère d'optimisme n'est pratiquement pas différente du critère de Wald:
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == max!!.second } .map { m -> m.first } } }
Critère de pessimisme
Ce critère est destiné à sélectionner le plus petit élément de la matrice de jeu parmi ses éléments minimum possibles:
uopt=miniminj[U]
Le critère du pessimisme suggère que l'évolution des événements sera défavorable au décideur. En utilisant ce critère, le décideur est guidé par la possible perte de contrôle de la situation, il essaie donc d'exclure les risques potentiels en choisissant l'option avec une rentabilité minimale.
Prenons un exemple. Pour les stratégies
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) trouver, trouver le minimum et obtenir les trois prochains
S=(0,1,−1) . Le minimum pour le triple indiqué sera la valeur -1, donc, selon le critère du pessimisme, la stratégie gagnante est la stratégie
U3=(4.3,−1) correspondant à Plantation Culture 3.
Après avoir pris connaissance des critères et de l'optimisme de Wald, il est facile de deviner à quoi ressemblera la classe du critère de pessimisme:
class PessimismCriteria(gameMatrix : GameMatrix) : ICriteria { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } override fun optimum(): List<GameVector> { val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) } val min = mins.minWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)}) return mins .filter { m -> m.second == min!!.second } .map { m -> m.first } } }
Critère sauvage
Le critère Savage (critère d'un pessimiste pessimiste) implique de minimiser les plus grands profits perdus, en d'autres termes, le plus grand regret pour les profits perdus est minimisé:
uopt=minimaxj[S]si,j=(max beginbmatrixu1,ju2,j...un,j endbmatrix−ui,j)
Dans ce cas, S est la matrice des regrets.
La solution optimale selon le critère Savage devrait donner le moins de regrets aux regrets trouvés à l'étape précédente. La solution correspondant à l'utilitaire trouvé sera optimale.
Les caractéristiques de la solution obtenue incluent une absence garantie des plus grandes déceptions et une diminution garantie des gains maximums possibles des autres joueurs.
Prenons un exemple. Pour les stratégies
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) faire une matrice de regrets:
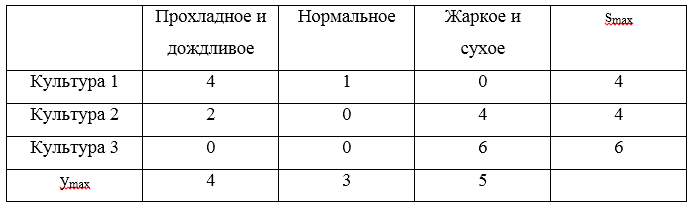
Trois regrets maximum
S=(4,4,6) . La valeur minimale de ces risques sera une valeur de 4, ce qui correspond aux stratégies
U1 et
U2 .
La programmation du test Savage est un peu plus difficile:
class SavageCriteria(gameMatrix: GameMatrix) : ICriteria { val gameMatrix: GameMatrix init { this.gameMatrix = gameMatrix } fun GameMatrix.risk(): List<Pair<GameVector, Double?>> { val maxStates = this.natureStates.map { n -> Pair(n, n.values.max()) } .map { n -> n.first.key to n.second }.toMap() var am: MutableList<Pair<GameVector, List<Double>>> = mutableListOf() for (a in this.alternatives) { var v: MutableList<Double> = mutableListOf() for (i in 0..a.values.lastIndex) { val mn = maxStates.get(i) v.add(mn!! - a.values[i]) } am.add(Pair(a, v.toList())) } return am.map { m -> Pair(m.first, m.second.max()) } } override fun optimum(): List<GameVector> { val risk = gameMatrix.risk() val minRisk = risk.minWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) }) return risk .filter { r -> r.second == minRisk!!.second } .map { m -> m.first } } }
Critère de Hurwitz
Le critère de Hurwitz est un compromis régulé entre pessimisme extrême et optimisme complet:
uopt=max( gamma×A(k)+A(0)×(1− gamma))
A (0) est la stratégie de l'extrême pessimiste, A (k) est la stratégie de l'optimiste complet,
gamma=1 - valeur de consigne du coefficient de poids:
0 leq gamma leq1 ;
gamma=0 - pessimisme extrême,
gamma=1 - optimisme total.
Avec un petit nombre de stratégies discrètes, définir la valeur souhaitée du coefficient de poids
gamma , puis arrondissez le résultat à la valeur la plus proche possible, en tenant compte de la discrétisation effectuée.
Prenons un exemple. Pour les stratégies
U1=(0,2,5),U2=(2,3,1),U3=(4,3,−1) . Nous supposons que le coefficient d'optimisme
gamma=0,6 . Faites maintenant un tableau:
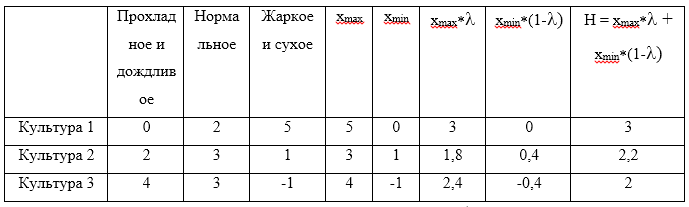
La valeur maximale à partir du H calculé sera la valeur 3, ce qui correspond à la stratégie
U1 .
La mise en œuvre du critère Hurwitz est déjà plus volumineuse:
class HurwitzCriteria(gameMatrix: GameMatrix, optimisticKoef: Double) : ICriteria { val gameMatrix: GameMatrix val optimisticKoef: Double init { this.gameMatrix = gameMatrix this.optimisticKoef = optimisticKoef } inner class HurwitzParam(xmax: Double, xmin: Double, optXmax: Double){ val xmax: Double val xmin: Double val optXmax: Double val value: Double init{ this.xmax = xmax this.xmin = xmin this.optXmax = optXmax value = xmax * optXmax + xmin * (1 - optXmax) } } fun GameMatrix.getHurwitzParams(): List<Pair<GameVector, HurwitzParam>> { return this.alternatives.map { a -> Pair(a, HurwitzParam(a.max()!!, a.min()!!, optimisticKoef)) } } override fun optimum(): List<GameVector> { val hpar = gameMatrix.getHurwitzParams() val maxHurw = hpar.maxWith(Comparator { o1, o2 -> o1.second.value.compareTo(o2.second.value) }) return hpar .filter { r -> r.second == maxHurw!!.second } .map { m -> m.first } } }
Prise de décision à risque
Les méthodes de prise de décision peuvent s'appuyer sur des critères de décision dans des conditions de risque, sous réserve des conditions suivantes:
- manque d'informations fiables sur les conséquences possibles;
- la présence de distributions de probabilité;
- connaissance de la probabilité de résultats ou de conséquences pour chaque décision.
Si une décision est prise dans des conditions de risque, les coûts des décisions alternatives sont décrits par des distributions de probabilité. À cet égard, la décision est basée sur l'utilisation du critère de la valeur attendue, selon lequel les solutions alternatives sont comparées en termes de maximisation des bénéfices attendus ou de minimisation des coûts attendus.
Le critère de la valeur attendue peut être réduit soit pour maximiser le profit attendu (moyen), soit pour minimiser les coûts attendus. Dans ce cas, on suppose que le profit (coûts) associé à chaque solution alternative est une variable aléatoire.
La formulation de ces tâches est généralement la suivante: une personne choisit n'importe quelle action dans une situation où des événements aléatoires influencent le résultat de l'action. Mais le joueur a une certaine connaissance des probabilités de ces événements et peut calculer la combinaison et la séquence les plus rentables de ses actions.
Afin de continuer à donner des exemples, nous complétons la matrice de jeu avec des probabilités:
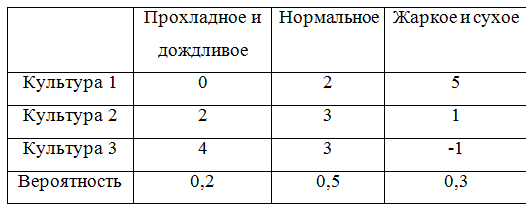
Afin de prendre en compte les probabilités, une classe décrivant la matrice de jeu devra être refaite un peu. Il s'est avéré, en vérité, pas très élégant, mais bon.
Matrice de jeu avec probabilités open class ProbabilityGameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>, natureStateNames: List<String>, probabilities: List<Double>) : GameMatrix(matrix, alternativeNames, natureStateNames) { val probabilities: List<Double> init { this.probabilities = probabilities; } override fun change (i : Int, j : Int, value : Double) : GameMatrix{ val cm = super.change(i, j, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } override fun changeAlternativeName (i : Int, value : String) : GameMatrix{ val cm = super.changeAlternativeName(i, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } override fun changeNatureStateName (j : Int, value : String) : GameMatrix{ val cm = super.changeNatureStateName(j, value) return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities) } fun changeProbability (j : Int, value : Double) : GameMatrix{ var list = probabilities.toMutableList() list.set(j, value) return ProbabilityGameMatrix(matrix, alternativeNames, natureStateNames, list.toList()) } override fun toString(): String { var s = "" val formatter: NumberFormat = DecimalFormat("#0.00") for (i in 0 .. natureStateNames.lastIndex){ s += natureStateNames[i] + " = " + formatter.format(probabilities[i]) + "\n" } return " :\n" + s + " :\n" + alternatives .map { a: GameVector -> a.toString() } .reduce { a1: String, a2: String -> "$a1;\n$a2" } } override fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>) : GameMatrix{ var result: MutableList<MutableList<Double>> = mutableListOf() var ralternativeNames: MutableList<String> = mutableListOf() var rnatureStateNames: MutableList<String> = mutableListOf() var rprobailities: MutableList<Double> = mutableListOf() val dIndex = dCol.map { c -> c.key }.toList() for (i in 0 .. natureStateNames.lastIndex){ if (!dIndex.contains(i)){ rnatureStateNames.add(natureStateNames[i]) } } for (i in 0 .. probabilities.lastIndex){ if (!dIndex.contains(i)){ rprobailities.add(probabilities[i]) } } for (gv in this.alternatives){ if (!dRow.contains(gv)){ var nr: MutableList<Double> = mutableListOf() for (i in 0 .. gv.values.lastIndex){ if (!dIndex.contains(i)){ nr.add(gv.values[i]) } } result.add(nr) ralternativeNames.add(gv.name) } } val rlist = result.map { r -> r.toList() }.toList() return ProbabilityGameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList(), rprobailities.toList()) } } }
Critère de Bayes
Le critère de Bayes (critère d'attente) est utilisé dans les problèmes de prise de décision dans les conditions de risque comme une évaluation de la stratégie
ui l'attente mathématique de la variable aléatoire correspondante apparaît. Selon cette règle, la stratégie optimale du joueur
uopt se trouve à partir de la condition:
uopt=max1 leqi leqnM(ui)M(ui)=max1 leqi leqn summj=1ui,j cdoty0j
En d'autres termes, un indicateur d'inefficacité de la stratégie
ui par critère de Bayes concernant les risques est la valeur moyenne (attente) des risques de la i-ème ligne de la matrice
U dont les probabilités coïncident avec les probabilités de la nature. Ensuite, la stratégie optimale parmi les stratégies pures selon le critère de Bayes concernant les risques est la stratégie
uopt ayant une inefficacité minimale, c'est-à-dire un risque moyen minimal. Le critère bayésien est équivalent en termes de gains et de risques, c'est-à-dire si la stratégie
uopt est optimal par le critère de Bayes en ce qui concerne les victoires, puis il est optimal par le critère de Bayes en ce qui concerne les risques, et vice versa.
Passons à l'exemple et calculons les attentes mathématiques:
M1=0 cdot0.2+2 cdot0.5+5 cdot0.3=2.5;M2=2 cdot0.2+3 cdot0.5+1 cdot0.3=2.2;M4=0 cdot0.2+3 cdot0.5+(−1) cdot0.3=2.0;
L'espérance mathématique maximale est
M1 par conséquent, une stratégie gagnante est une stratégie
U1 .
Implémentation logicielle du critère de Bayes:
class BayesCriteria(gameMatrix: ProbabilityGameMatrix) : ICriteria { val gameMatrix: ProbabilityGameMatrix init { this.gameMatrix = gameMatrix } fun ProbabilityGameMatrix.bayesProbability(): List<Pair<GameVector, Double?>> { var am: MutableList<Pair<GameVector, Double>> = mutableListOf() for (a in this.alternatives) { var alprob: Double = 0.0 for (i in 0..a.values.lastIndex) { alprob += a.values[i] * this.probabilities[i] } am.add(Pair(a, alprob)) } return am.toList(); } override fun optimum(): List<GameVector> { val risk = gameMatrix.bayesProbability() val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) }) return risk .filter { r -> r.second == maxBayes!!.second } .map { m -> m.first } } }
Critère de Laplace
Le critère de Laplace présente une maximisation simplifiée de l'attente mathématique d'utilité lorsque l'hypothèse d'une probabilité égale de niveaux de demande est valide, ce qui élimine la nécessité de collecter des statistiques réelles.
Dans le cas général, lors de l'utilisation du critère de Laplace, la matrice des utilités attendues et le critère optimal sont déterminés comme suit:
uopt=max[ overlineU] overlineU= beginbmatrix overlineu1 overlineu2... overlineun endbmatrix, overlineui= frac1n sumnj=1ui,j
Prenons l'exemple de la prise de décision selon le critère de Laplace. Nous calculons la moyenne arithmétique pour chaque stratégie:
overlineu1= frac13 cdot(0+2+5)=2.3 overlineu2= frac13 cdot(2+3+1)=2.0 o v e r l i n e u 3 = f r a c 1 3 c d o t ( 4 + 3 - 1 ) = 2 $ .
La stratégie gagnante est donc la stratégie
U 1 .
Implémentation logicielle du critère de Laplace:
class LaplaceCriteria(gameMatrix: GameMatrix) : ICriteria { val gameMatrix: GameMatrix init { this.gameMatrix = gameMatrix } fun GameMatrix.arithemicMean(): List<Pair<GameVector, Double>> { return this.alternatives.map { m -> Pair(m, m.values.average()) } } override fun optimum(): List<GameVector> { val risk = gameMatrix.arithemicMean() val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second.compareTo(o2.second) }) return risk .filter { r -> r.second == maxBayes!!.second } .map { m -> m.first } } }
Stratégies mixtes. Méthode analytique
La méthode analytique vous permet de résoudre le jeu dans des stratégies mixtes.
Afin de formuler un algorithme pour trouver une solution à un jeu par une méthode analytique, nous considérons quelques concepts supplémentaires.La stratégieU i domine la stratégieU i - 1 , si toutu 1 .. n ∈ U i ≥ u 1 .. n ∈ U i - 1 .
En d'autres termes, si dans une ligne d'une matrice de paiement tous les éléments sont supérieurs ou égaux aux éléments correspondants d'une autre ligne, la première ligne domine la seconde et est appelée la ligne dominante. Et aussi si dans une colonne de la matrice de paiement tous les éléments sont inférieurs ou égaux aux éléments correspondants d'une autre colonne, alors la première colonne domine la seconde et est appelée la colonne dominante.Le prix le plus bas du jeu est appeléα = m a x i m i n j u i j .
Le prix le plus élevé du jeu est appelé β = m i n j m a x i u i j .
Vous pouvez maintenant formuler un algorithme pour résoudre le jeu par la méthode analytique:- Calculer le fond α et supérieurPrix du jeu β . Si α = β , puis écrivez la réponse en stratégies pures; sinon, continuez la solution plus loin
- Supprimer les lignes dominantes des colonnes dominantes. Il peut y en avoir plusieurs. À leur place dans la stratégie optimale, les composantes correspondantes seront 0
- Résolvez le jeu matriciel par programmation linéaire.
Pour donner un exemple, vous devez donner une classe qui décrit la solutionRésoudre class Solve(gamePriceObr: Double, solutions: List<Double>, names: List<String>) { val gamePrice: Double val gamePriceObr: Double val solutions: List<Double> val names: List<String> private val formatter: NumberFormat = DecimalFormat("#0.00") init{ this.gamePrice = 1 / gamePriceObr this.gamePriceObr = gamePriceObr; this.solutions = solutions this.names = names } override fun toString(): String{ var s = " : " + formatter.format(gamePrice) + "\n" for (i in 0..solutions.lastIndex){ s += "$i) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "\n" } return s } fun itersect(matrix: GameMatrix): String{ var s = " : " + formatter.format(gamePrice) + "\n" for (j in 0..matrix.alternativeNames.lastIndex) { var f = false val a = matrix.alternativeNames[j] for (i in 0..solutions.lastIndex) { if (a.equals(names[i])) { s += "$j) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "\n" f = true break } } if (!f){ s += "$j) " + a + " = 0\n" } } return s } }
Et la classe qui exécute la solution par la méthode simplex. Comme je ne comprends pas les mathématiques, j'ai utilisé l'implémentation prête à l'emploi d' Apache Commons MathSolveur open class Solver (gameMatrix: GameMatrix) { val gameMatrix: GameMatrix init{ this.gameMatrix = gameMatrix } fun solve(): Solve{ val goalf: List<Double> = gameMatrix.alternatives.map { a -> 1.0 } val f = LinearObjectiveFunction(goalf.toDoubleArray(), 0.0) val constraints = ArrayList<LinearConstraint>() for (alt in gameMatrix.alternatives){ constraints.add(LinearConstraint(alt.values.toDoubleArray(), Relationship.LEQ, 1.0)) } val solution = SimplexSolver().optimize(f, LinearConstraintSet(constraints), GoalType.MAXIMIZE, NonNegativeConstraint(true)) val sl: List<Double> = solution.getPoint().toList() val solve = Solve(solution.getValue(), sl, gameMatrix.alternativeNames) return solve } }
Maintenant, nous exécutons la solution par la méthode analytique. Pour plus de clarté, nous prenons une autre matrice de jeu:( 2 4 8 5 6 2 4 6 3 2 5 4 )
Il y a un ensemble dominant dans cette matrice:( 2 4 6 2 )
Solution val alternativeNames: List<String> = listOf(" 1", " 2", " 3") val natureStateNames: List<String> = listOf(" ", "", " ", "") val matrix: List<List<Double>> = listOf( listOf(2.0, 4.0, 8.0, 5.0), listOf(6.0, 2.0, 4.0, 6.0), listOf(3.0, 2.0, 5.0, 4.0) ) val gm = GameMatrix(matrix, alternativeNames, natureStateNames) val (dgm, list) = gm.dominateMatrix() println(dgm.toString()) println(list.reduce({s1, s2 -> s1 + "\n" + s2})) println() val s: Solver = Solver(dgm) val solve = s.solve() println(solve)
Solution de jeu ( 0 , 33 ; 0 , 67 ; 0 ) avec le prix du jeu égal à 3,33Au lieu d'une conclusion
J'espère que cet article sera utile à ceux qui ont besoin d'une première approximation avec la solution des jeux avec la nature. Au lieu de conclusions, un lien vers GitHub .Je serais reconnaissant pour la rétroaction constructive!