Bonjour à tous.
Il a écrit une bibliothèque pour former un réseau de neurones. Peu importe, s'il vous plaît.
J'ai longtemps voulu me faire un instrument de ce niveau. C été, il se mit aux affaires. Voici ce qui s'est passé:
- la bibliothèque est écrite à partir de zéro en C ++ (uniquement STL + OpenBLAS pour le calcul), C-interface, win / linux;
- la structure du réseau est spécifiée dans JSON;
- couches de base: entièrement connectées, convolutives, regroupées. Supplémentaire: redimensionner, recadrer ..;
- fonctionnalités de base: batchNorm, dropout, optimiseurs de poids - adam, adagrad ..;
- OpenBLAS est utilisé pour calculer le CPU, CUDA / cuDNN pour la carte vidéo. Il a également posé la mise en œuvre d'OpenCL, pour l'avenir;
- pour chaque couche, il est possible de définir séparément ce qu'il faut considérer - CPU ou GPU (et lequel);
- la taille des données d'entrée n'est pas fixée de manière rigide, elle peut changer pendant le travail / la formation;
- fait des interfaces pour C ++ et Python. C # viendra aussi plus tard.
La bibliothèque s'appelait SkyNet. (Tout est compliqué avec des noms, d'autres étaient des options, mais quelque chose ne va pas ..)
Comparaison avec PyTorch en utilisant l'exemple MNIST:
PyTorch: Précision: 98%, Temps: 140 sec
SkyNet: Précision: 95%, Temps: 150 sec
Machine: i5-2300, GF1060. Code de test.
Architecture logicielle
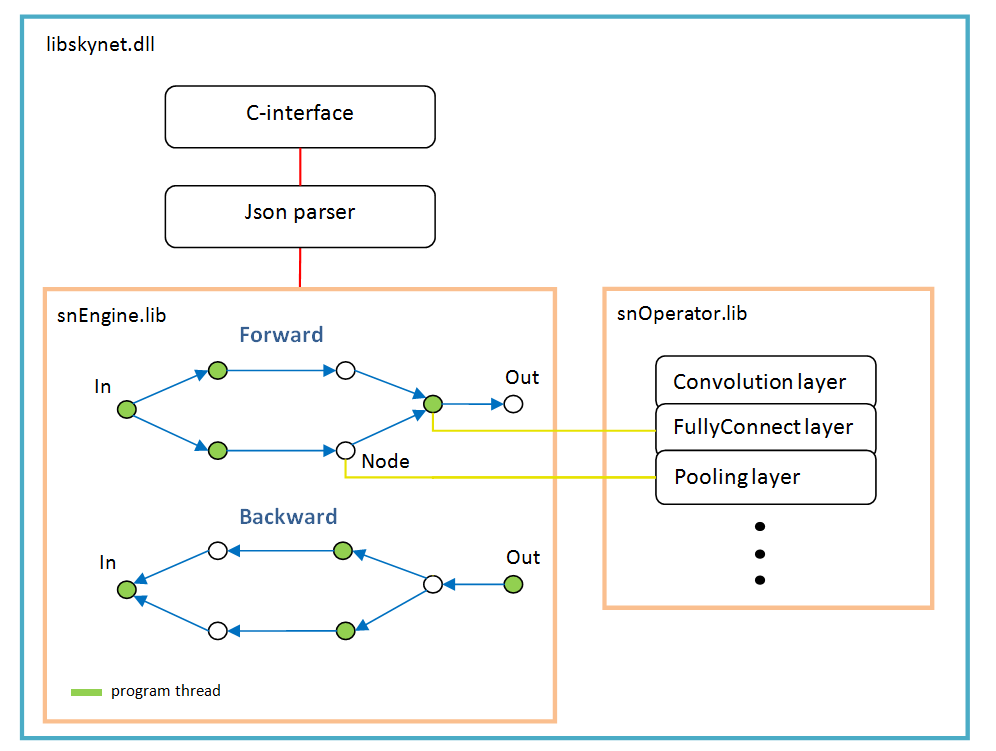
Il est basé sur un graphe d'opérations qui est créé dynamiquement une fois après l'analyse de la structure du réseau.
Pour chaque branche, un nouveau thread. Chaque nœud du réseau (Node) est une couche de calcul.
Il y a des caractéristiques du travail:
- fonction d'activation, normalisation par lot, abandon - ils sont tous implémentés en tant que paramètres de couches spécifiques, en d'autres termes, ces fonctions n'existent pas en tant que couches distinctes. Peut-être que batchNorm devrait être sélectionné dans une couche distincte à l'avenir;
- softMax n'est pas non plus une couche séparée, il appartient à la couche spéciale LossFunction. Dans lequel il est utilisé lors du choix d'un type spécifique de calcul d'erreur;
- la couche «LossFunction» est utilisée pour calculer automatiquement l'erreur, vous ne pouvez évidemment pas utiliser les étapes avant / arrière (ci-dessous est un exemple de travail avec cette couche);
- il n'y a pas de couche «Aplatir», ce n'est pas nécessaire puisque la couche «FullyConnect» elle-même dessine le tableau d'entrée;
- l'optimiseur de poids doit être défini pour chaque couche de poids; par défaut, 'adam' est utilisé par tout le monde.
Des exemples
Mnist

Le code C ++ ressemble à ceci: Le code complet est disponible
ici . Ajout de quelques images au référentiel, situé à côté de l'exemple. J'ai utilisé l'opencv pour lire les images, je ne l'ai pas inclus dans le kit.
Un autre réseau du même plan, plus compliqué.

Code pour créer un tel réseau: Dans les exemples, ce n'est pas le cas, vous pouvez copier à partir d'ici.
En Python, le code ressemble également // snet = snNet.Net() snet.addNode("Input", Input(), "C1 C2 C3") \ .addNode("C1", Convolution(15, 0, calcMode.CUDA), "P1") \ .addNode("P1", Pooling(calcMode.CUDA), "FC1") \ .addNode("C2", Convolution(12, 0, calcMode.CUDA), "P2") \ .addNode("P2", Pooling(calcMode.CUDA), "FC3") \ .addNode("C3", Convolution(12, 0, calcMode.CUDA), "P3") \ .addNode("P3", Pooling(calcMode.CUDA), "FC5") \ \ .addNode("FC1", FullyConnected(128, calcMode.CUDA), "FC2") \ .addNode("FC2", FullyConnected(10, calcMode.CUDA), "LS1") \ .addNode("LS1", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC3", FullyConnected(128, calcMode.CUDA), "FC4") \ .addNode("FC4", FullyConnected(10, calcMode.CUDA), "LS2") \ .addNode("LS2", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("FC5", FullyConnected(128, calcMode.CUDA), "FC6") \ .addNode("FC6", FullyConnected(10, calcMode.CUDA), "LS3") \ .addNode("LS3", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \ \ .addNode("Summ", LossFunction(lossType.softMaxToCrossEntropy), "Output") .............
CIFAR-10

Ici, je devais déjà activer batchNorm. Cette grille apprend jusqu'à 50% de précision sur 1000 itérations, lot 100.
Ce code s'est avéré sn::Net snet; snet.addNode("Input", sn::Input(), "C1") .addNode("C1", sn::Convolution(15, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C2") .addNode("C2", sn::Convolution(15, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(25, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C4") .addNode("C4", sn::Convolution(25, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(40, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C6") .addNode("C6", sn::Convolution(40, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P3") .addNode("P3", sn::Pooling(sn::calcMode::CUDA), "FC1") .addNode("FC1", sn::FullyConnected(2048, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC2") .addNode("FC2", sn::FullyConnected(128, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC3") .addNode("FC3", sn::FullyConnected(10, sn::calcMode::CUDA), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
Je pense qu'il est clair que toutes les classes d'images peuvent être remplacées.
U-net tyni
Dernier exemple. U-Net natif simplifié pour démonstration.

Je m'explique un peu: couches DC1 ... - convolution inverse, couches Concat1 ... - couches d'addition de canaux,
Rsz1 ... - sont utilisés pour convenir du nombre de canaux dans l'étape opposée, car l'erreur de la somme des canaux remonte de la couche Concat.
Code C ++. sn::Net snet; snet.addNode("In", sn::Input(), "C1") .addNode("C1", sn::Convolution(10, -1, sn::calcMode::CUDA), "C2") .addNode("C2", sn::Convolution(10, 0, sn::calcMode::CUDA), "P1 Crop1") .addNode("Crop1", sn::Crop(sn::rect(0, 0, 487, 487)), "Rsz1") .addNode("Rsz1", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc1") .addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3") .addNode("C3", sn::Convolution(10, -1, sn::calcMode::CUDA), "C4") .addNode("C4", sn::Convolution(10, 0, sn::calcMode::CUDA), "P2 Crop2") .addNode("Crop2", sn::Crop(sn::rect(0, 0, 247, 247)), "Rsz2") .addNode("Rsz2", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc2") .addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5") .addNode("C5", sn::Convolution(10, 0, sn::calcMode::CUDA), "C6") .addNode("C6", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC1") .addNode("DC1", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz3") .addNode("Rsz3", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc2") .addNode("Conc2", sn::Concat("Rsz2 Rsz3"), "C7") .addNode("C7", sn::Convolution(10, 0, sn::calcMode::CUDA), "C8") .addNode("C8", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC2") .addNode("DC2", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz4") .addNode("Rsz4", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc1") .addNode("Conc1", sn::Concat("Rsz1 Rsz4"), "C9") .addNode("C9", sn::Convolution(10, 0, sn::calcMode::CUDA), "C10"); sn::Convolution convOut(1, 0, sn::calcMode::CUDA); convOut.act = sn::active::sigmoid; snet.addNode("C10", convOut, "Output");
Le code complet et les images sont
ici .
Des mathématiques open source comme celle-ci .
J'ai testé toutes les couches sur MNIST; TF a servi de standard pour l'évaluation des erreurs.
Et ensuite
La bibliothèque n'augmentera pas en largeur, c'est-à-dire sans ouverture, sockets, etc., afin de ne pas se gonfler.
L'interface de la bibliothèque ne changera pas / ne s'agrandira pas, je ne le dirai pas du tout et jamais, mais enfin et surtout.
Seulement en profondeur: je ferai le calcul sur OpenCL, l'interface pour C #, le réseau RNN peut être ...
MKL Je pense que cela n'a aucun sens à ajouter, car le réseau est un peu plus profond - il est de toute façon plus rapide sur la carte vidéo, et la carte de performance moyenne ne manque pas du tout.
Importation / exportation de poids avec d'autres frameworks - via Python (pas encore implémenté). La feuille de route sera si l'intérêt des gens se fait sentir.
Qui peut prendre en charge le code, s'il vous plaît. Mais il y a des limites pour que l'architecture actuelle ne casse pas.
Vous pouvez étendre l'interface pour python à l'impossibilité, tout comme des quais et des exemples sont nécessaires.
Pour installer à partir de Python:
* pip install libskynet - CPU
* pip install libskynet-cu - CUDA9.2 + cuDNN7.3.1
Guide d'utilisation du wiki.
Le logiciel est distribué gratuitement, licence MIT.
Je vous remercie