
Les vues, ou vues, est l'un des concepts de la plateforme CUBA, pas le plus courant dans le monde des frameworks web. Comprendre cela signifie vous éviter des erreurs stupides lorsque, en raison d'un chargement de données incomplet, l'application cesse soudainement de fonctionner. Voyons quelles sont les représentations (jeu de mots) et pourquoi elles sont réellement pratiques.
Le problème des données déchargées
Prenons un sujet plus simple et considérons le problème en utilisant son exemple. Supposons que nous ayons une entité Client qui se réfère à une entité CustomerType dans une relation plusieurs-à-un, en d'autres termes, l'acheteur a un lien vers un certain type qui le décrit: par exemple, "vache à lait", "vivaneau", etc. L'entité CustomerType a un attribut de nom dans lequel le nom de type est stocké.
Et, probablement, tous les nouveaux arrivants (ou même les utilisateurs avancés) de CUBA ont tôt ou tard reçu cette erreur:
IllegalStateException: Cannot get unfetched attribute [type] from detached object com.rtcab.cev.entity.Customer-e703700d-c977-bd8e-1a40-74afd88915af [detached].
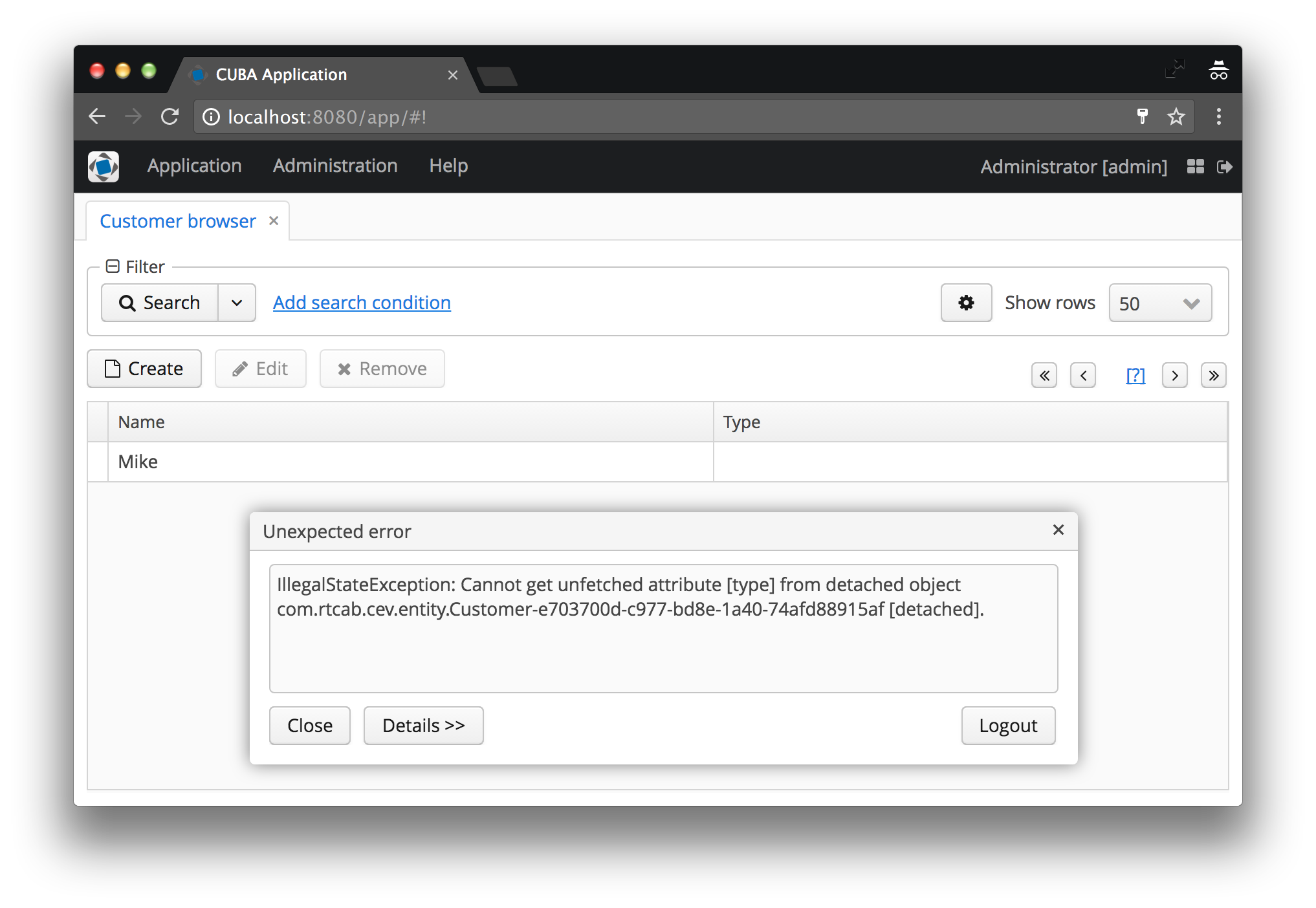
Avouez-le, vous l'avez aussi vu de vos propres yeux? Je - oui, dans une centaine de situations différentes. Dans cet article, nous examinerons la cause de ce problème, pourquoi il existe et comment le résoudre.
Pour commencer, une petite introduction au concept de vues.
Qu'est-ce qu'une vue?
Une vue dans CUBA est essentiellement une collection de colonnes dans une base de données qui doivent être chargées ensemble dans une seule requête.
Supposons que nous voulons créer une interface utilisateur avec une table client, où la première colonne est le nom du client et la seconde est le nom du type de l'attribut customerType (comme dans la capture d'écran ci-dessus). Il est logique de supposer que dans ce modèle de données, nous aurons deux tables distinctes dans la base de données, une pour l'entité Customer , l'autre pour CustomerType . La SELECT * from CEV_CUSTOMER nous renverra les données d'une seule table ( name attribut, etc.). Évidemment, pour obtenir également des données d'autres tables, nous utiliserons JOINs.
Dans le cas de l'utilisation de requêtes SQL classiques à l'aide de JOIN, la hiérarchie des associations (attributs de référence) se développe à partir du graphique dans une liste plate.
Note du traducteur: en d' autres termes, les relations entre les tables sont effacées et le résultat est présenté dans un seul tableau de données représentant l'union des tables.
Dans le cas de CUBA, ORM est utilisé, qui ne perd pas d'informations sur les relations entre les entités et présente le résultat des requêtes sous la forme d'un graphique intégral des données demandées. Dans ce cas, JPQL, un objet analogique de SQL, est utilisé comme langage de requête.
Néanmoins, les données doivent encore être déchargées d'une manière ou d'une autre de la base de données et transformées en un graphique d'entité. Pour cela, le mécanisme de mappage objet-relationnel (qui est JPA) a deux approches principales pour les requêtes vers la base de données.
Chargement paresseux vs. désireux d'aller chercher
Le chargement paresseux et le chargement gourmand sont deux stratégies possibles pour obtenir des données de la base de données. La différence fondamentale entre les deux réside dans le chargement des données des tables liées. Un petit exemple pour une meilleure compréhension:
Vous vous souvenez de la scène du livre "Le Hobbit ou aller-retour", où un groupe de gnomes en compagnie de Gandalf et Bilbo essaient de demander à passer la nuit dans la maison de Beorn? Gandalf a ordonné aux nains d'apparaître strictement à son tour et seulement après avoir soigneusement convenu avec Beorn et a commencé à les présenter un à la fois afin de ne pas choquer le propriétaire par la nécessité d'accueillir 15 invités à la fois.

Donc, Gandalf et les gnomes dans la maison de Beorn ... Ce n'est probablement pas la première chose qui me vient à l'esprit en pensant aux téléchargements paresseux et gourmands, mais il y a certainement des similitudes. Gandalf a agi sagement ici, car il était conscient des limites. On peut dire qu'il a consciemment choisi le chargement paresseux des gnomes, car il a compris que le téléchargement de toutes les données à la fois serait une opération trop lourde pour cette base de données. Cependant, après le 8e gnome, Gandalf est passé au chargement gourmand et a chargé un tas des gnomes restants, car il a remarqué que des appels trop fréquents à la base de données commençaient à le rendre moins énervant.
La morale est que le chargement paresseux et gourmand a ses avantages et ses inconvénients. Quoi appliquer dans chaque situation spécifique, vous décidez.
Problème de demande N + 1
Le problème de requête N + 1 se pose souvent si vous utilisez inconsidérément le chargement paresseux où que vous alliez. Pour illustrer, regardons un morceau de code Grails. Cela ne signifie pas que dans Grails, tout se charge paresseusement (en fait, vous choisissez vous-même la méthode de démarrage). Dans Grails, une requête vers la base de données par défaut renvoie des instances d'entité avec tous les attributs de sa table. Essentiellement, SELECT * FROM Pet est exécuté.
Si vous voulez approfondir les relations entre les entités, vous devez le faire post factum. Voici un exemple:
function getPetOwnerNamesForPets(String nameOfPet) { def pets = Pet.findAll(sort:"name") { name == nameOfPet } def ownerNames = [] pets.each { ownerNames << it.owner.name } return ownerNames.join(", ") }
Le graphique est it.owner.name ici par une seule ligne: it.owner.name . Le propriétaire est une relation qui n'a pas été chargée dans la demande d'origine ( Pet.findAll ). Ainsi, à chaque appel de cette ligne, GORM fera quelque chose comme SELECT * FROM Person WHERE id='…' . Chargement paresseux à l'eau pure.
Si vous calculez le nombre total de requêtes SQL, vous obtenez N (un propriétaire pour chaque appel it.owner ) + 1 (pour le Pet.findAll origine). Si vous souhaitez approfondir le graphique des entités liées, il est probable que votre base de données trouvera rapidement ses limites.
En tant que développeur, vous ne le remarquerez probablement pas, car de votre point de vue, vous ne faites que parcourir le graphique des objets. Cette imbrication cachée dans une courte ligne cause une réelle douleur à la base de données et rend le chargement paresseux parfois dangereux.
En développant une analogie hobby, le problème de N + 1 pourrait se manifester comme suit: imaginez que Gandalf n'est pas capable de stocker les noms des gnomes dans sa mémoire. Par conséquent, introduisant les nains un par un, il est obligé de se retirer dans son groupe et de demander son nom au nain. Avec ces informations, il retourne à Beorn et représente Thorin. Il répète ensuite cette manœuvre pour Bifur, Bofur, Fili, Kili, Dori, Nori, Ori, Oin, Gloyn, Balin, Dvalin et Bombur.

Il est facile d'imaginer qu'un tel scénario serait peu susceptible de naître: quel destinataire voudrait attendre si longtemps les informations demandées? Par conséquent, vous ne devez pas utiliser cette approche sans réfléchir et vous fier aveuglément aux paramètres par défaut de votre mappeur de persistance.
Résolution du problème des requêtes N + 1 à l'aide des vues CUBA
Dans CUBA, vous ne rencontrerez probablement jamais le problème de requête N + 1, car la plate-forme a décidé de ne pas utiliser du tout le chargement paresseux caché. Au lieu de cela, CUBA a introduit le concept de représentations. Les vues sont une description des attributs qui doivent être sélectionnés et chargés avec les instances d'entité. Quelque chose comme
SELECT pet.name, person.name FROM Pet pet JOIN Person person ON pet.owner == person.id
D'une part, la vue décrit les colonnes qui doivent être chargées à partir de la table principale ( Pet ) (au lieu de charger tous les attributs via *), d'autre part, elle décrit les colonnes qui doivent être chargées à partir des tables c-JOIN.
Vous pouvez imaginer la vue CUBA comme vue SQL pour OR-Mapper: le principe de fonctionnement est à peu près le même.
Dans la plate-forme CUBA, vous ne pouvez pas appeler une requête via le DataManager sans utiliser la vue. La documentation fournit un exemple:
@Inject private DataManager dataManager; private Book loadBookById(UUID bookId) { LoadContext<Book> loadContext = LoadContext.create(Book.class) .setId(bookId).setView("book.edit"); return dataManager.load(loadContext); }
Ici, nous voulons télécharger le livre par son ID. La setView("book.edit") , lors de la création d'un contexte de chargement, indique avec quelle vue le livre doit être chargé à partir de la base de données. Si vous ne transmettez aucune vue, le gestionnaire de données utilise l'une des trois vues standard de chaque entité: la vue _local . Local fait ici référence à des attributs qui ne font pas référence à d'autres tables, tout est simple.
Résolution du problème avec IllegalStateException via des vues
Maintenant que nous comprenons un peu le concept de représentation, revenons au premier exemple du début de l'article et essayons d'éviter de lever une exception.
Le message IllegalStateException: impossible d'obtenir l'attribut non récupéré [] de l'objet détaché signifie simplement que vous essayez d'afficher un attribut qui n'est pas inclus dans la vue avec laquelle l'entité est chargée.
Comme vous pouvez le voir, dans le descripteur de l'écran de navigation, j'ai utilisé la vue _local , et c'est tout le problème:
<dsContext> <groupDatasource id="customersDs" class="com.rtcab.cev.entity.Customer" view="_local"> <query> <![CDATA[select e from cev$Customer e]]> </query> </groupDatasource> </dsContext>
Pour supprimer l'erreur, vous devez d'abord inclure le type de client dans la vue. Comme nous ne pouvons pas changer la vue par défaut de _local , nous pouvons créer la nôtre. Dans Studio, cela peut être fait, par exemple, comme suit (clic droit sur les entités> créer une vue):
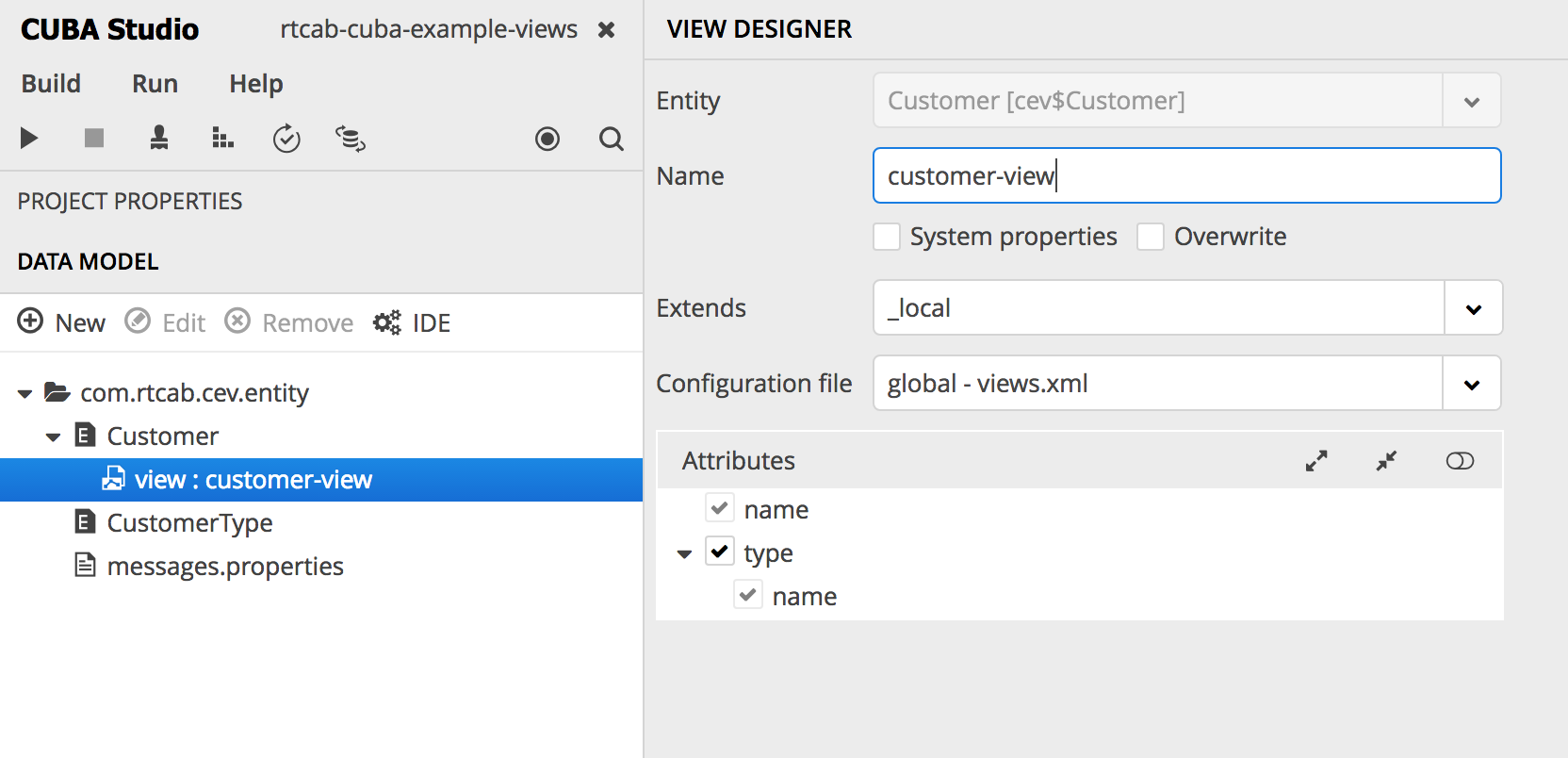
soit directement dans le descripteur views.xml de notre application:
<view class="com.rtcab.cev.entity.Customer" extends="_local" name="customer-view"> <property name="type" view="_minimal"/> </view>
Après cela, nous modifions le lien vers la vue dans l'écran de navigation, comme ceci:
<groupDatasource id="customersDs" class="com.rtcab.cev.entity.Customer" view="customer-view"> <query> <![CDATA[select e from cev$Customer e]]> </query> </groupDatasource>
Cela résout complètement le problème, et maintenant les données du lien sont affichées dans l'écran de visualisation du client.
_Minimal view and instance name
Ce qui mérite d'être mentionné dans le contexte des vues, c'est la vue _minimal . La vue locale a une définition très claire: elle inclut tous les attributs de l'entité, qui sont des attributs directs de la table (qui ne sont pas des clés étrangères).
La définition d'une représentation minimale n'est pas si évidente, mais aussi assez claire.
CUBA a le concept d'un nom d'instance d'entité - nom d'instance. Le nom de l'instance est l'équivalent de la toString() dans le bon vieux Java. Il s'agit d'une représentation sous forme de chaîne d'une entité à afficher sur une interface utilisateur et à utiliser dans les liens. Le nom de l'instance est défini à l'aide de l'annotation de l'entité NamePattern .
Il est utilisé comme ceci: @NamePattern("%s (%s)|name,code") . Nous avons deux résultats:
Le nom d'instance définit le mappage de l'entité avec l'interface utilisateur
Tout d'abord, le nom de l'instance détermine quoi et dans quel ordre sera affiché dans l'interface utilisateur si une entité fait référence à une autre entité (comme Client fait référence à CustomerType ).
Dans notre cas, le type de client sera affiché comme le nom de l'instance CustomerType , à laquelle le code est ajouté aux crochets. Si le nom d'instance n'est pas défini, le nom de la classe d'entité et l'ID de l'instance spécifique seront affichés - convenez que ce n'est pas du tout ce que l'utilisateur aimerait voir. Voir les captures d'écran avant et après ci-dessous pour des exemples des deux cas.
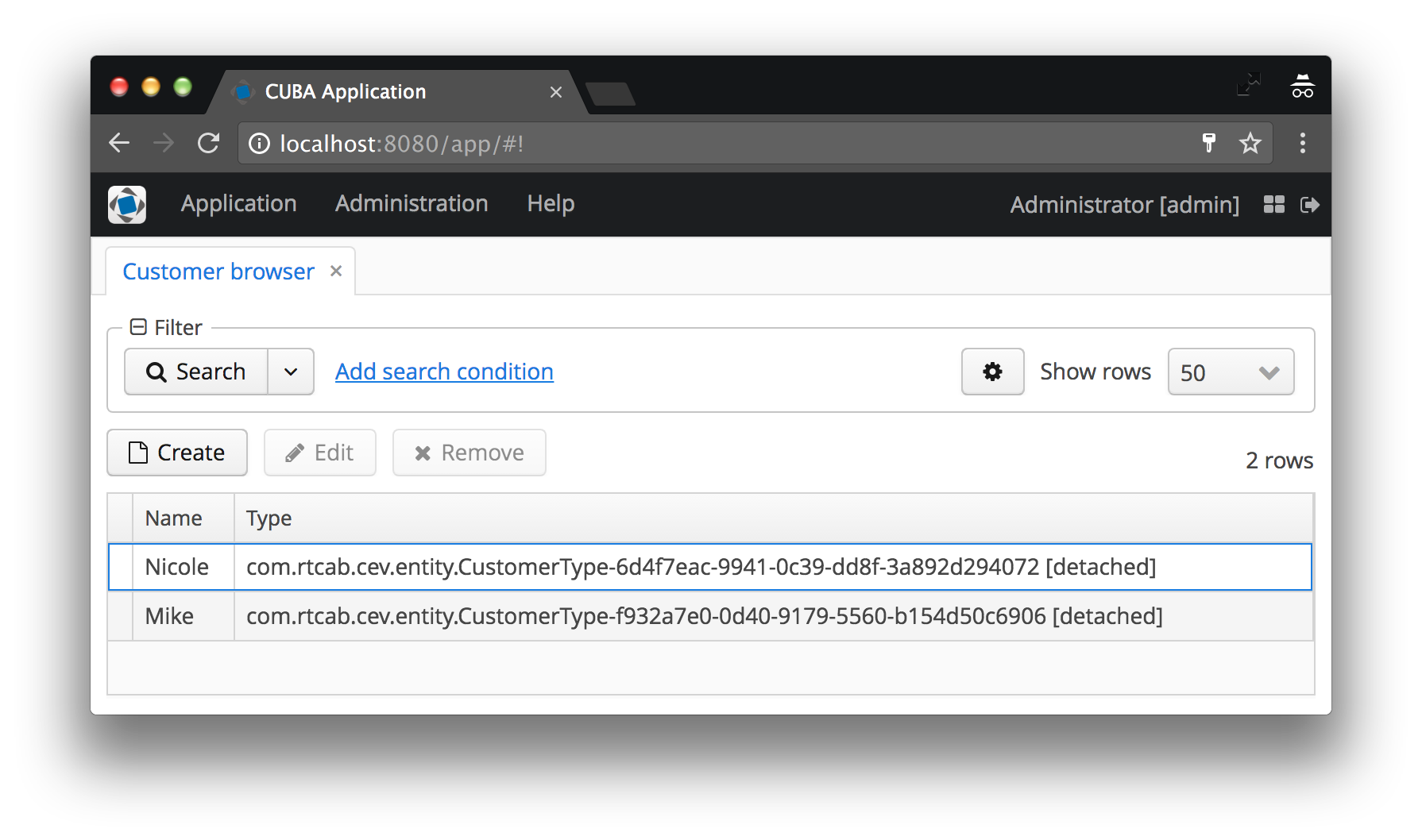
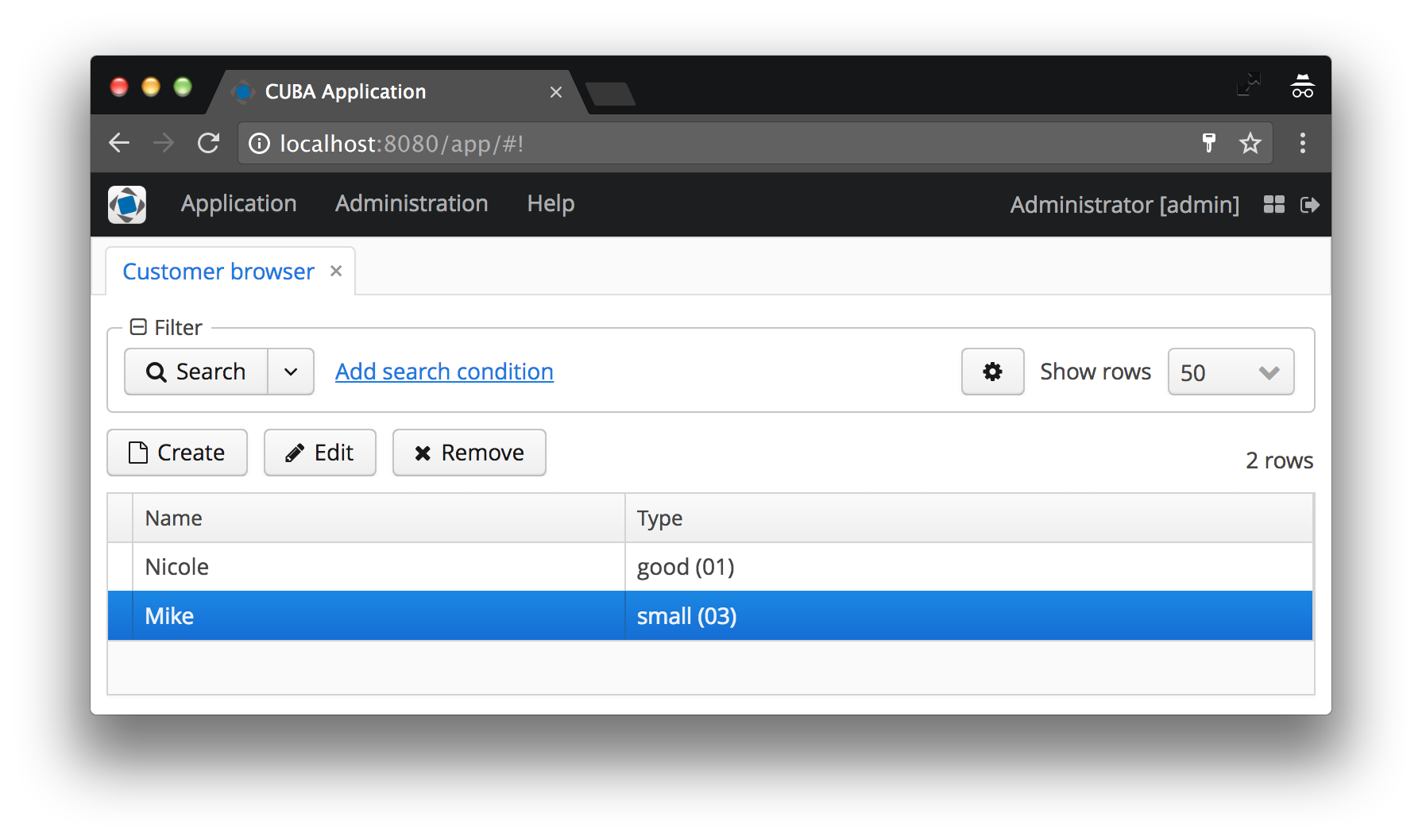
Le nom de l'instance définit les attributs de vue minimum
La deuxième chose que l'annotation NamePattern affecte est: tous les attributs spécifiés après la barre verticale forment automatiquement une vue _minimal . À première vue, cela semble évident, car les données sous une forme ou une autre doivent être affichées dans l'interface utilisateur, ce qui signifie que vous devez d'abord les télécharger à partir de la base de données. Bien que, pour être honnête, je pense rarement à ce fait.
Il est important de noter ici que la représentation minimale, si elle est comparée à la représentation locale, peut contenir des références à d'autres entités. Par exemple, pour l'acheteur de l'exemple ci-dessus, j'ai défini un nom d'instance, qui comprend un attribut local de l'entité Client ( name ) et un attribut de référence ( type ):
@NamePattern("%s - %s|name,type")
La représentation minimale peut être utilisée récursivement: (Client [Nom de l'instance] -> Type de client [Nom de l'instance])
Note du traducteur: depuis la publication de l'article, une autre vue système est apparue: la vue _base , qui inclut tous les attributs locaux non système et les attributs spécifiés dans l'annotation @NamePattern (c'est-à-dire en fait _minimal + _local ).
Conclusion
En conclusion, nous résumons le sujet le plus important. Grâce aux vues, dans CUBA, nous pouvons indiquer explicitement ce qui doit être chargé à partir de la base de données. Les vues déterminent ce qui sera chargé avec gourmandise, tandis que la plupart des autres frameworks effectuent secrètement un chargement paresseux.
Les représentations peuvent sembler être un mécanisme lourd, mais à long terme elles se justifient.
J'espère avoir réussi à expliquer de manière accessible ce que sont réellement ces vues mystérieuses. Bien sûr, il existe des scénarios plus avancés pour leur utilisation, ainsi que des pièges dans le travail avec les représentations en général et avec des représentations minimales en particulier, mais j'écrirai à ce sujet dans un article séparé d'une manière ou d'une autre.