Il y a quelques jours, Splunk a publié une nouvelle version de sa plate-forme Splunk 7.2, qui a introduit de nombreuses innovations pour optimiser les performances, y compris un nouveau schéma de stockage de données, l'administration des performances utilisées, et bien plus encore. Voir les détails sous la coupe.
Smartstore
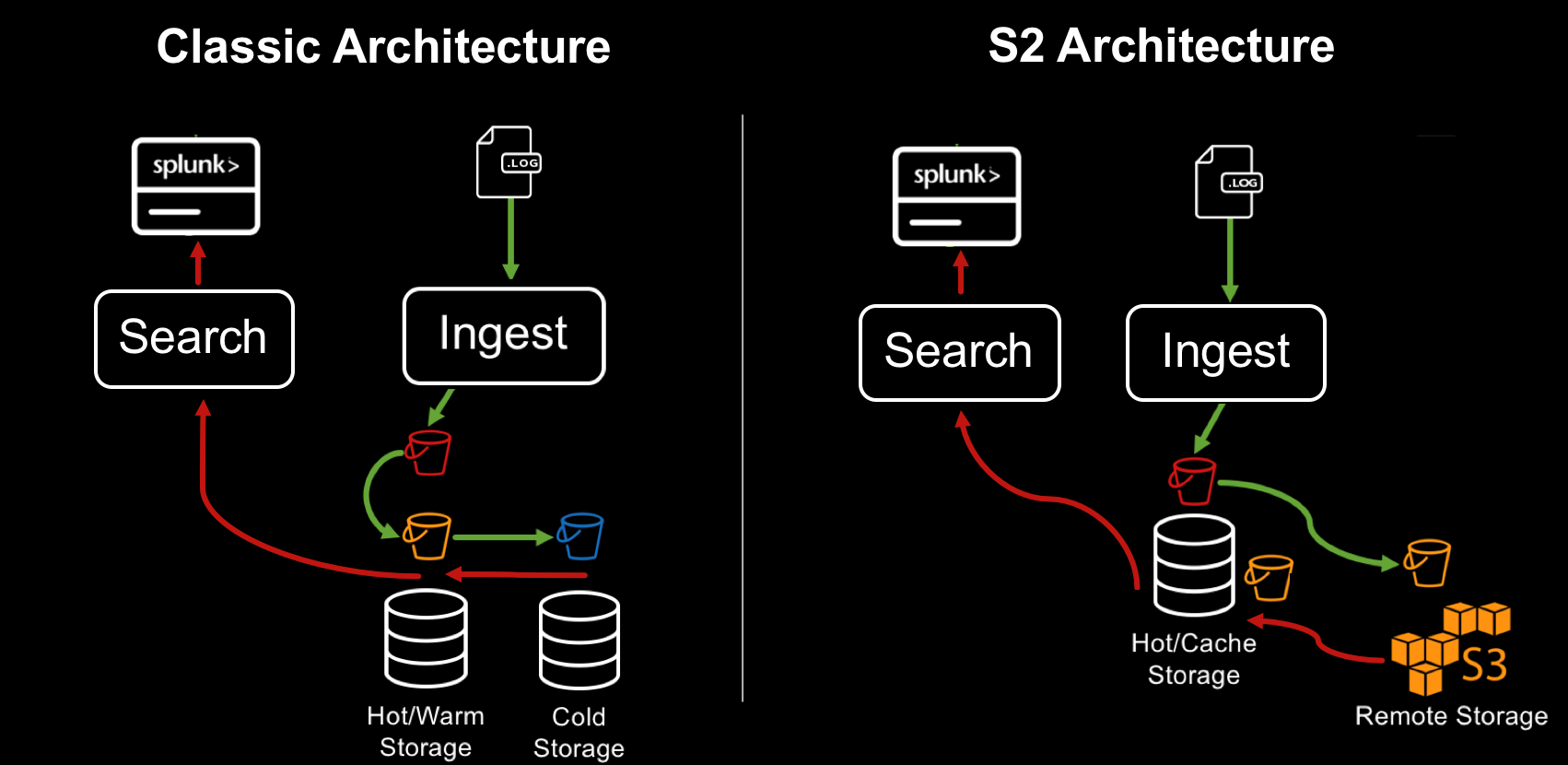
SmartStore est une nouvelle façon de gérer les entrepôts de données dans Splunk. Auparavant, toutes les données étaient stockées dans des indexeurs, ce qui permettait aux données d'être facilement accessibles pour le traitement. S'il est nécessaire d'étendre le volume, un nouvel indexeur a été ajouté au cluster. Ce modèle est idéal pour les volumes de données faibles à moyens. Lorsque vous ajoutez plus de données, vous avez besoin non seulement de plus d'espace, mais également de plus de puissance de traitement. Cependant, avec des volumes de données en croissance exponentielle, la demande de stockage dépasse la demande en informatique rapide. SmartStore vous permet d'héberger des données localement sur des indexeurs ou sur des référentiels distants. Le mouvement des données entre les indexeurs et le stockage distant est contrôlé par le gestionnaire de cache situé sur les indexeurs.
Avec SmartStore, vous pouvez réduire au minimum la taille du stockage de l'indexeur et sélectionner les ressources informatiques optimales pour les E / S. La plupart des données sont stockées sur un stockage distant, tandis que l'indexeur contient un cache local qui contient un minimum de données: données chaudes, copies des données chaudes récemment impliquées dans les recherches.
 Quand est-il préférable d'utiliser SmartStore?
Quand est-il préférable d'utiliser SmartStore?- Les coûts d'infrastructure ralentissent l'évolutivité et limitent le temps de stockage.
- L'archivage des données n'est pas une solution abordable, car les anciennes données (~ 1 an) doivent être consultables.
- Large déploiement de Splunk, généralement plus de ~ 10 indexeurs.
- La plupart (plus de 95%) des demandes concernent les dernières données (moins de 90 jours).
- Les recherches de données plus anciennes (> 90 jours) sont rares et les performances de recherche lentes sont acceptables.
Gestion de la charge de travail
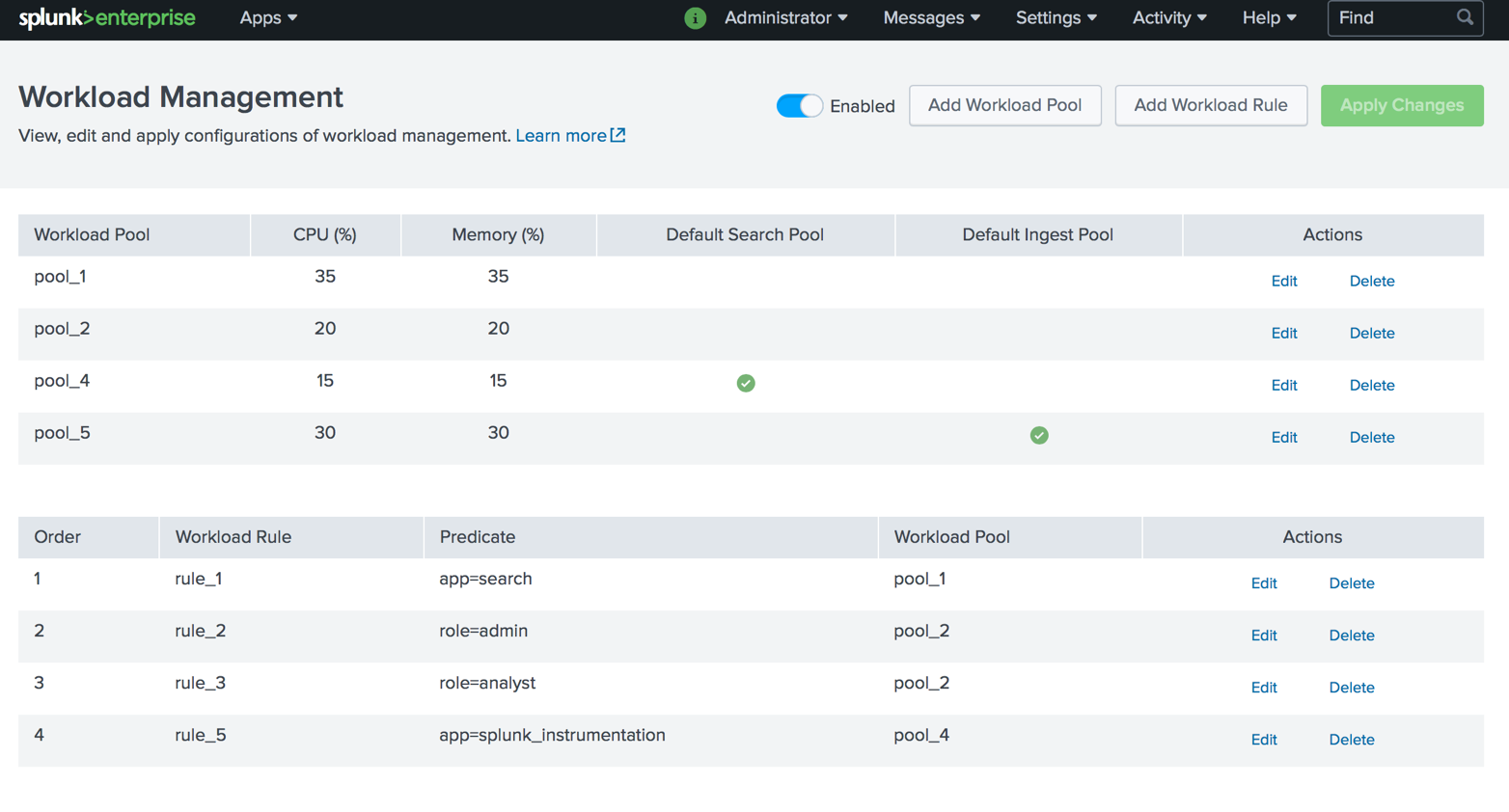
La gestion de la charge de travail est un mécanisme basé sur une politique de réservation de ressources système (CPU, mémoire) pour télécharger des données et effectuer des requêtes de recherche conformément aux priorités de l'entreprise. Cela permet aux administrateurs de classer les charges de travail en différents groupes et de réserver des parties des ressources système (CPU, mémoire) par groupe de charges de travail, quelle que soit la charge totale du système.
Quand est-il préférable de l'utiliser?- Indiquer la priorité des demandes et tâches clés;
- Pour limiter l'impact global sur les performances des requêtes de recherche lourdes;
- Pour éviter les retards dans le chargement des données en raison des ressources de recherche dépensées.
Surveillance de la santé Splunk en temps réel
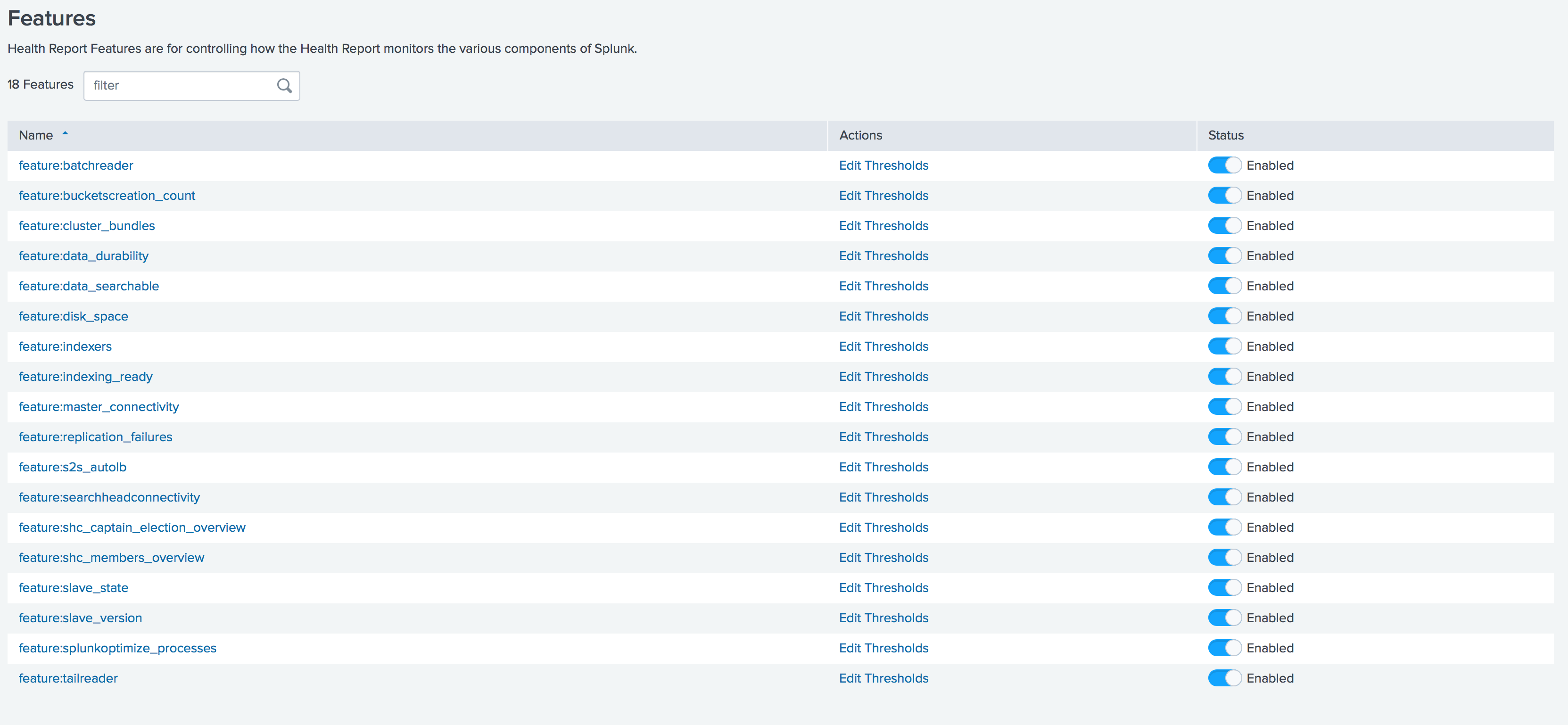
La version 7.2 a considérablement étendu l'outil de surveillance de la santé Splunk. Le gestionnaire de rapports d'intégrité est désormais disponible grâce auquel vous pouvez activer / désactiver des fonctions et définir des valeurs de seuil pour des fonctions individuelles directement via l'interface graphique.
Vous pouvez également configurer des alertes de santé Splunk par e-mail, télégramme, Slack, etc.

Mesures
De plus, les fonctions de travail avec les métriques ont atteint un nouveau niveau. Premièrement, un tout nouvel outil pour analyser et surveiller les métriques sans utiliser de requêtes de recherche est apparu -
Splunk Metrics Workspace . Il fournit une interface d'analyse visuelle facile à utiliser. Vous pouvez créer des visualisations interactives dans l'espace de travail, effectuer diverses fonctions analytiques pour avoir une idée des indicateurs.
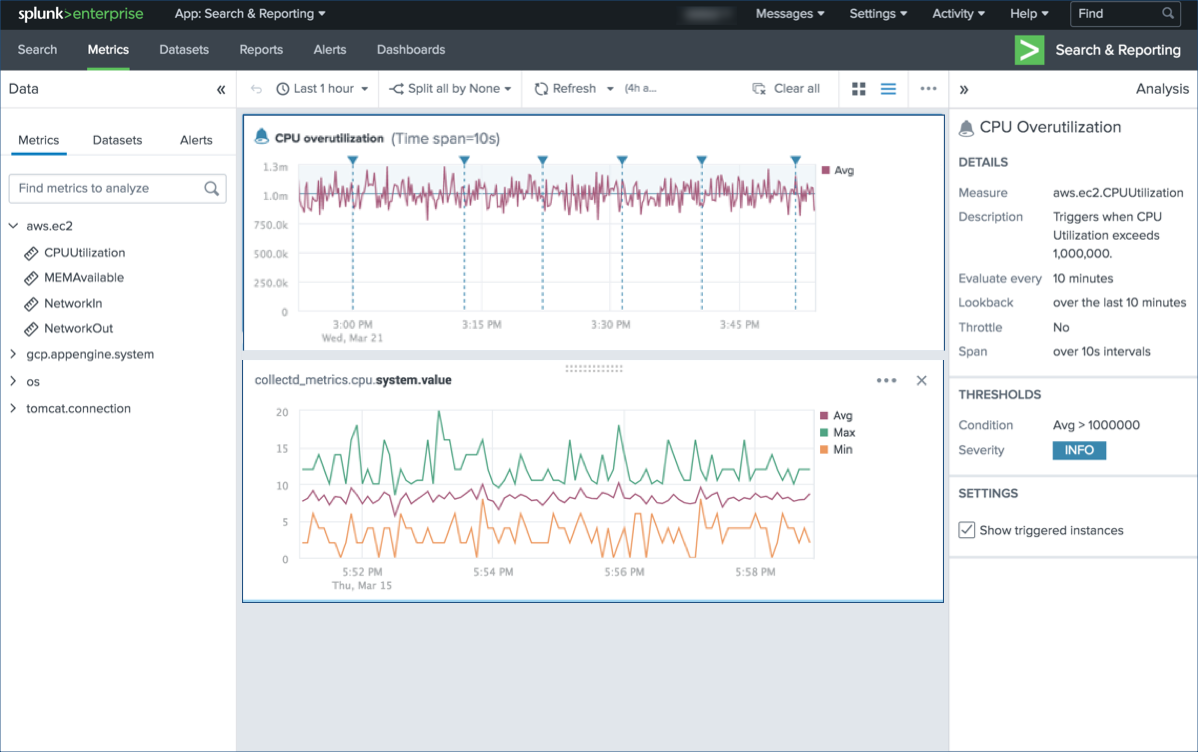 Opérations et fonctions analytiques:
Opérations et fonctions analytiques:- Agrégation
- Comparaison de temps - superposer le graphique précédent sur le graphique actuel.
- Séparation - affiche les résultats d'une mesure spécifique.
- Filtres - l'inclusion ou l'exclusion de certains résultats.
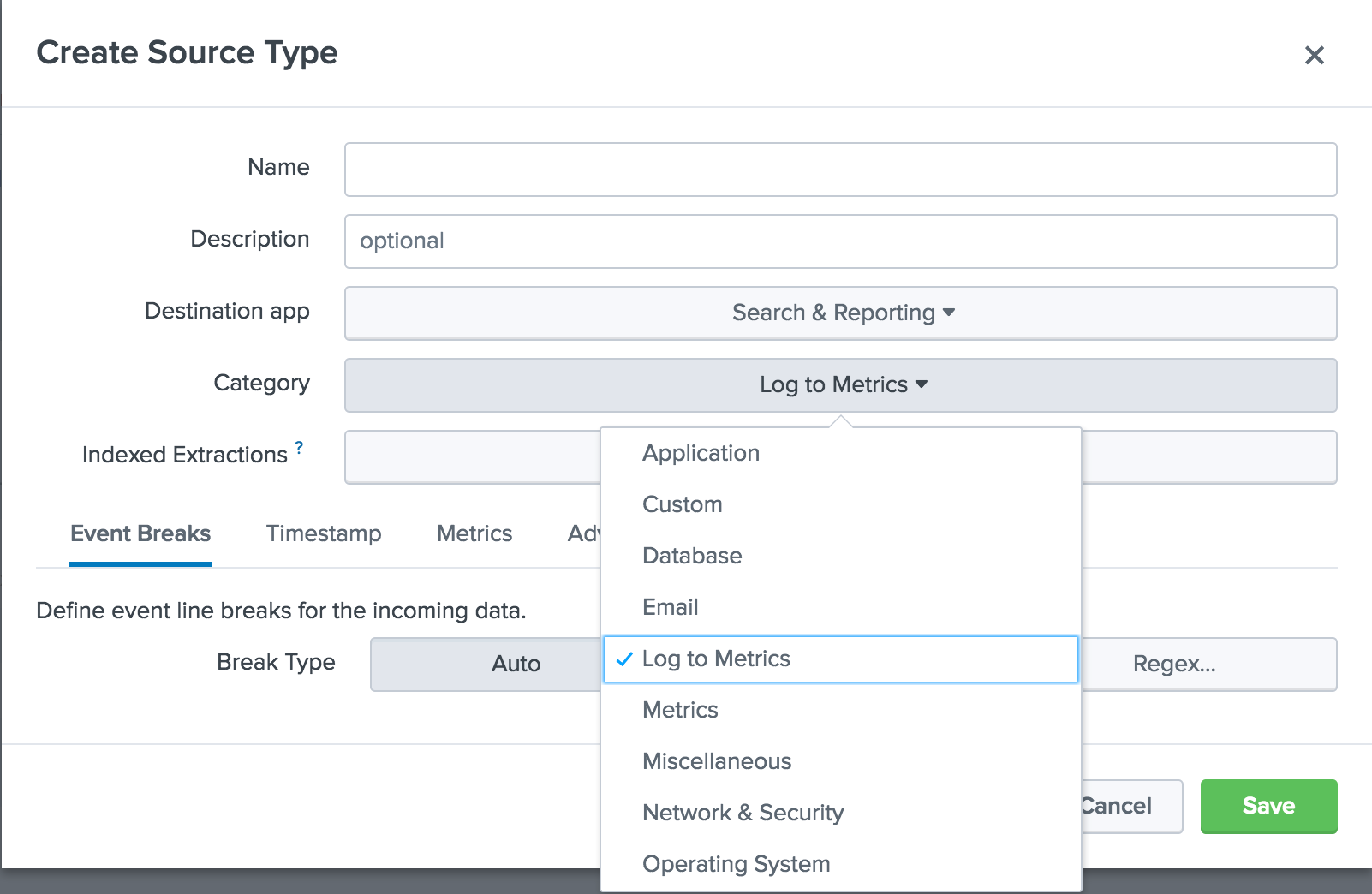
Deuxièmement, il est devenu possible de convertir des journaux structurés et non structurés en métriques. Auparavant, il y avait deux méthodes principales pour recevoir des métriques dans Splunk: en utilisant des agents tels que statsd et collectd, et également en créant et en stockant des données à l'aide de mcollect. La nouvelle fonctionnalité
Log to Metrics permet à la plateforme Splunk de convertir des journaux contenant des données métriques en points de données métriques discrets. Vous pouvez également définir des mesures qui doivent être extraites en tant que mesures et créer une liste noire de champs qui ne doivent pas être affichés dans les données de mesures
MTLK 4.0
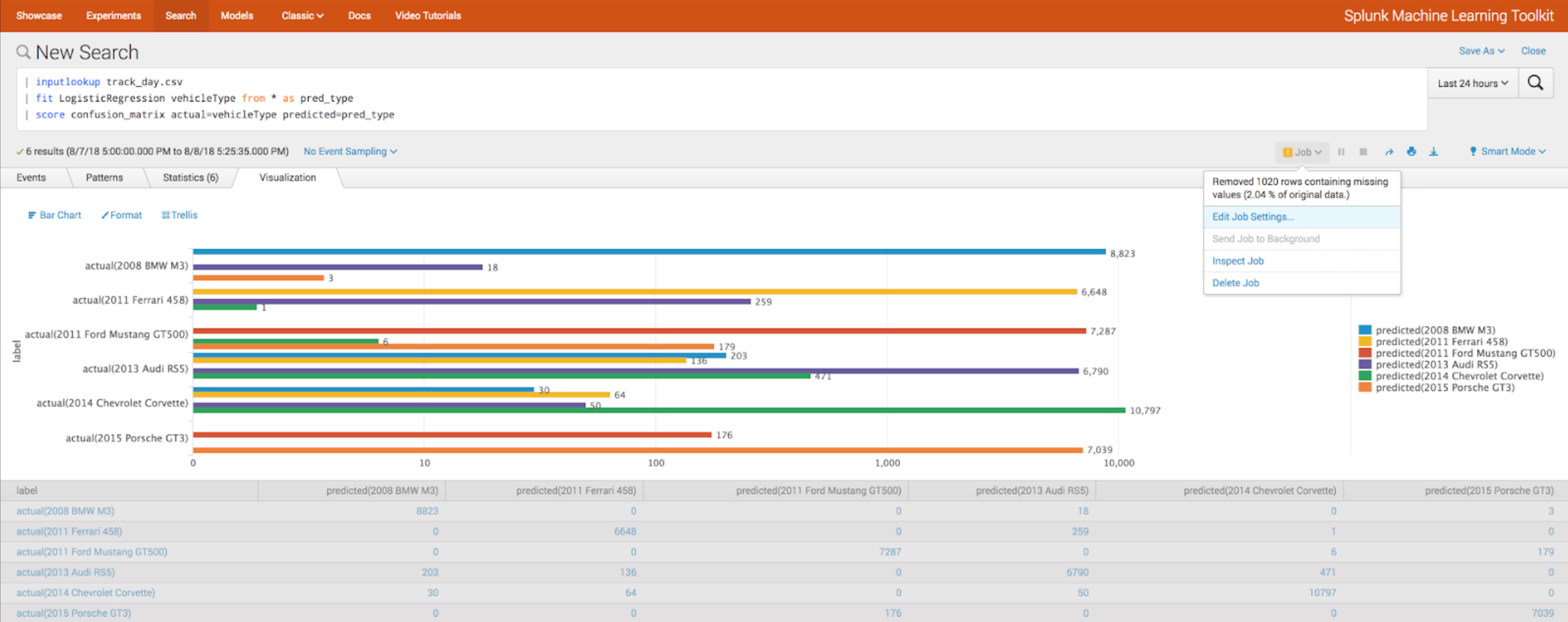
Avec la nouvelle version de Splunk, une nouvelle version de Splunk Machine Learning Toolkit est également disponible. Nous avons écrit
plus tôt sur les versions précédentes de MTLK, et voyons maintenant quelles nouveautés sont apparues.
Intégration:- Tensorflow
- Étincelle Apache
- Github
Nouveaux algorithmes:- LocalOutlierFactor
- Classificateur MLP
Évaluation d'algorithme- Fonction Score
- Validation croisée (paramètre kfold_cv)
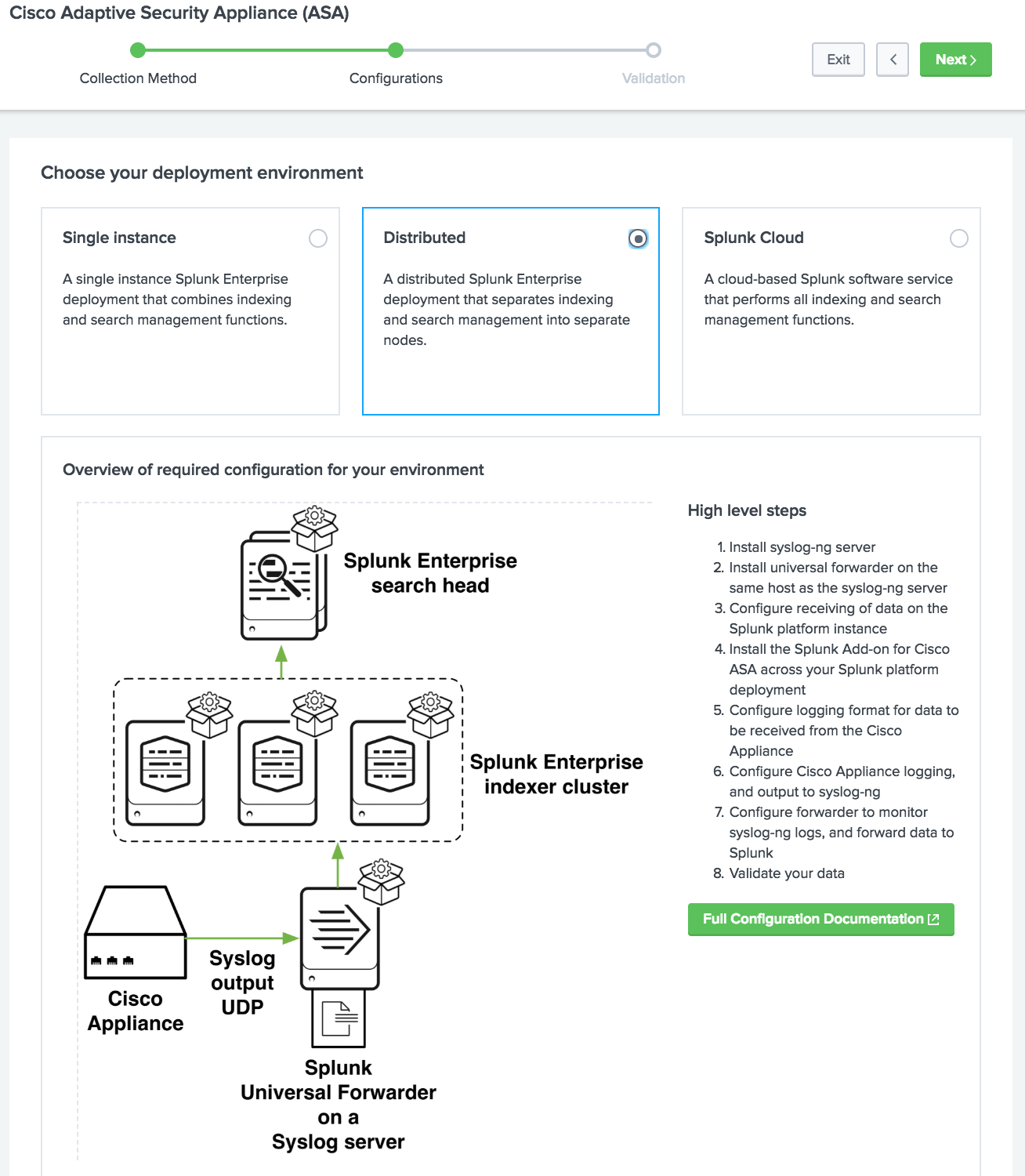
Intégration des données gérées
Nouvelle interface utilisateur graphique avec guide de chargement des données pour aider les utilisateurs de Splunk à comprendre les concepts essentiels pour obtenir des données à partir de diverses sources dans Splunk.
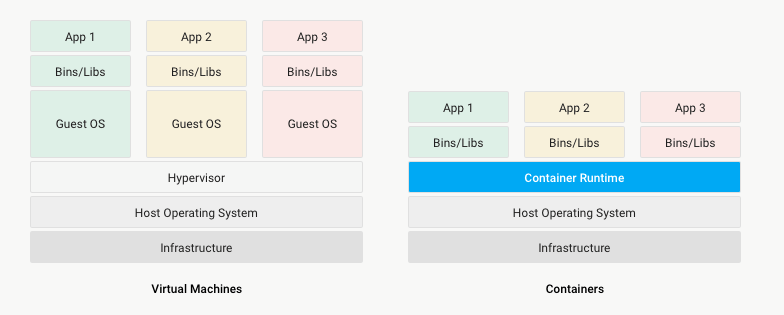
Prise en charge de Docker
Avec la sortie d'Enterprise 7.2, les utilisateurs Splunk ont désormais la possibilité de déployer Splunk dans un conteneur Docker. Un conteneur est un progiciel léger qui combine le code d'application avec le runtime, les outils, les bibliothèques système et les paramètres d'environnement nécessaires à son exécution. Cela vous permet d'abstraire les applications de l'environnement dans lequel elles s'exécutent, de les isoler des autres applications et de simplifier la mise à l'échelle.
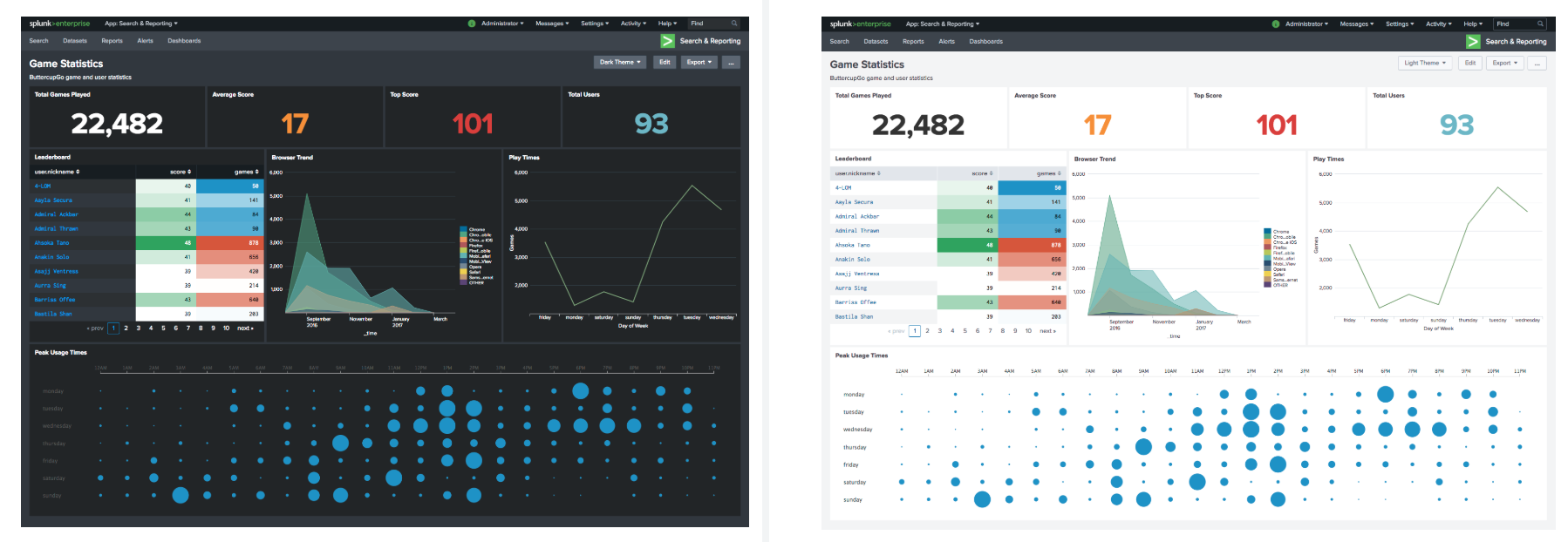
Interface sombre
Oui oui! Vous pouvez maintenant utiliser le thème sombre développé par les designers Splunk dans vos tableaux de bord. Bien sûr, auparavant, il était également possible d'ajuster l'arrière-plan sombre du tableau de bord à l'aide de CSS, mais pour que le thème semble normal, il était toujours nécessaire de sélectionner et d'ajouter une palette de couleurs pour tous les éléments, ce qui est plutôt morne. Maintenant, ce problème est résolu en cliquant sur un bouton.
Pour l'étude la plus approfondie de toutes les nouvelles fonctionnalités, vous devez installer l'application
Splunk Enterprise 7.2 Overview , et également regarder la
vidéo officielle de sortie.
