Je poste le deuxième rapport de notre
premier mitap , qui s'est tenu en septembre. La dernière fois que vous avez pu lire (et voir) comment
utiliser Consul pour faire évoluer les services avec état d'Ivan Bubnov de BIT.GAMES, et aujourd'hui nous parlerons de CICD. Plus précisément, notre administrateur système Egor Panov en parlera, qui est responsable de la disponibilité des infrastructures et des services dans Pixonic. Sous la coupe - décodage de la performance.
Pour commencer, l'industrie du jeu est plus risquée - vous ne savez jamais exactement ce qui va sombrer dans le cœur du joueur. Et donc nous créons de nombreux prototypes. Bien sûr, nous créons des prototypes sur le genou de bâtons, cordes et autres matériaux improvisés.
Il semblerait qu'avec cette approche, faire quelque chose qui peut ensuite être soutenu est généralement impossible. Mais même à ce stade, nous tenons bon. Nous nous appuyons sur trois piliers:
- excellente expertise des testeurs;
- interaction étroite avec eux;
- le temps que nous donnons pour les tests.
En conséquence, si nous ne construisons pas nos processus, par exemple, le déploiement ou l'IC (intégration continue), nous arriverons tôt ou tard à la conclusion que la durée des tests augmentera et augmentera tout le temps. Et nous allons soit tout faire lentement et perdre le marché, soit nous exploserons simplement à chaque déploiement.
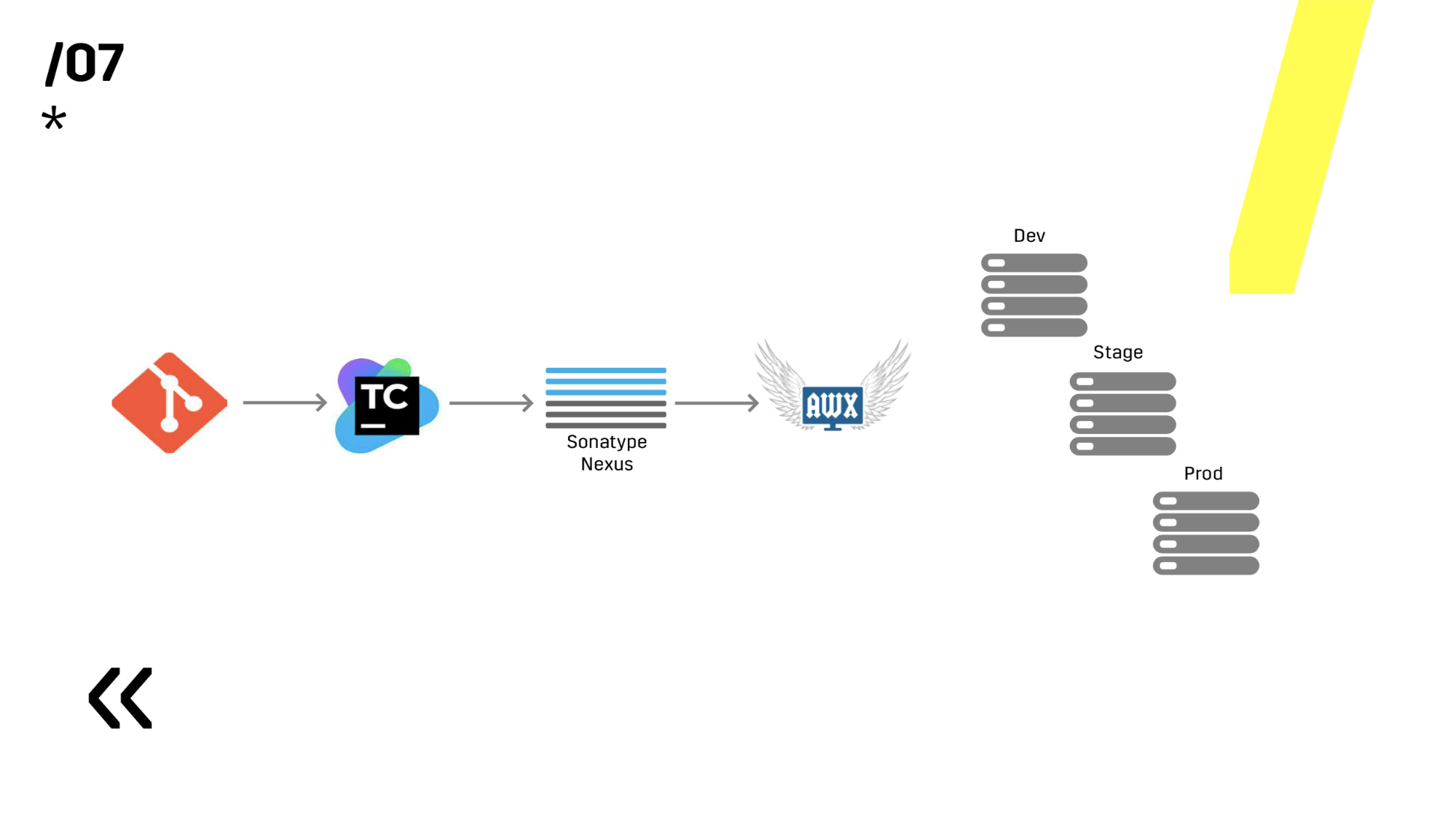
Mais construire un processus CICD n'est pas si simple. Certains diront, eh bien, oui, je vais mettre Jenkins, je vais appeler rapidement quelque chose, maintenant je suis prêt CICD. Non, ce n'est pas seulement un outil, c'est aussi une pratique. Commençons dans l'ordre.

Le premier. De nombreux articles écrivent que tout doit être conservé dans un référentiel: le code, les tests, le déploiement et même le schéma de base de données et les paramètres IDE communs à tous. Nous avons suivi notre propre chemin.
Nous avons alloué différents référentiels: déploiement dans notre référentiel, tests dans un autre. Ça marche plus vite. Cela ne vous convient peut-être pas, mais pour nous, c'est beaucoup plus pratique. Parce qu'il y a un point important à ce stade - vous devez créer un simple et transparent pour tous les hitflows. Bien sûr, vous pouvez télécharger le fichier fini quelque part, mais dans tous les cas, vous devez le régler vous-même, l'améliorer. Pour nous, par exemple, un déploiement vit sur son propre gitflow, qui ressemble plus à un flux GitHub, et le développement de serveur vit sur son propre gitflow.
Le paragraphe suivant. Vous devez configurer une version entièrement automatique. Il est clair qu'à la première étape, le développeur lui-même recueille personnellement le projet, puis il le déploie personnellement avec l'aide de SCP, le lance lui-même, l'envoie à celui qui en a besoin. Cette option n'a pas duré longtemps, un script bash est apparu. Eh bien, comme l'environnement des développeurs est en constante évolution, un serveur de construction dédié spécial est apparu. Il a vécu très longtemps, pendant ce temps, nous avons réussi à augmenter jusqu'à 500 serveurs, à configurer les configurations de serveur sur Puppet, à accumuler l'héritage sur Puppet, à refuser Puppet, à passer à Ansible, et ce buildserver a continué à vivre.
Ils ont décidé de tout changer après deux appels, ils n'ont pas attendu un troisième. L'histoire est claire: le buildserver est un point de défaillance unique et, bien sûr, lorsque nous devions déployer quelque chose, le centre de données est complètement tombé avec notre buildserver. Et le deuxième appel: nous devions mettre à jour la version Java - nous l'avons mise à jour sur le buildserver, l'avons installée sur la scène, tout est cool, tout est super et là nous avons dû commencer un petit bugfix sur le prod. Bien sûr, nous avons oublié de reculer et tout s'est effondré.
Après cela, ils ont tout réécrit pour que la construction entière puisse se produire sur absolument n'importe quel agent TeamCity et l'ont réécrit sur Ansible, car il a été configuré sur Ansible, pourquoi ne pas utiliser le même outil pour le déploiement aussi.
La règle suivante: plus vous vous engagez souvent, mieux c'est. Pourquoi? Parce qu'il y en a un quatrième: chaque commit est collecté. Et en fait, encore plus que chaque commit. J'ai déjà dit que nous avons TeamCity, et cela vous permet d'exécuter un commit à partir de votre IDE préféré (vous devinez ce que je veux dire). En fait, une rétroaction rapide, tout est super.
Une construction cassée est réparée immédiatement. Dès que vous configurez le déploiement automatique, vous devez configurer la notification automatique dans Slack. Nous savons tous très bien qu'un développeur ne sait comment son code fonctionne qu'au moment où il l'écrit. Par conséquent: la personne a découvert - immédiatement réparée.
Nous testons l'environnement en répétant prod. C'est simple, nous avons choisi Ansible et AWX. Quelqu'un pourrait demander, mais qu'en est-il de Docker, Kubernetes, OpenShift, où tous les problèmes hors de la boîte ont été résolus depuis longtemps? J'ai oublié de dire que nous avons des composants à la fois Linux et Windows. Et, par exemple, le serveur Photon, qui est sous Windows, nous n'avons que récemment pu emballer plus ou moins normalement dans un conteneur Docker de 10 Go. En conséquence, nous avons une application Windows qui ne s’emballe pas bien dans un conteneur; Il existe une application sous Linux (qui est en Java), qui est parfaitement packagée, mais il n'y a aucune raison de le faire, elle fonctionne bien partout où vous l'exécutez. C'est Java.
Ensuite, nous avons choisi entre Ansible et Chef. Ils fonctionnent tous les deux correctement avec Windows, mais Ansible s'est avéré beaucoup plus facile pour nous. Lorsque nous avons déjà installé AWX - en général, tous les incendies sont devenus. AWX a des secrets, des graphismes, de l'histoire. Vous pouvez montrer à une personne loin de tout cela, il verra immédiatement tout et tout deviendra clair.
Et vous devez toujours garder la construction rapide. Je ne sais pas pourquoi, mais chaque fois que vous lancez un nouveau projet, vous oubliez complètement le serveur de build, les agents et sélectionnez un ordinateur qui traînait - voici notre serveur de build. Il n'est pas souhaitable de répéter cette erreur, car tout ce dont je parle (commentaires rapides, avantages) - tout ne sera pas si pertinent si l'assemblage démarre sur votre propre ordinateur portable beaucoup plus rapidement que sur une sorte de batterie de serveurs.

7 points - et nous avons déjà construit une sorte de processus CI. Super Le diagramme suivant n'est pas visible, mais il y a toujours Graylog sur le côté. Qui lit nos articles sur Habré, qui a déjà vu
comment nous avons choisi Graylog et
comment installer . Dans tous les cas, cela aide à dévier si un problème persiste.
Maintenant, sur cette base, il est déjà possible de procéder au déploiement.

Mais j'ai déjà parlé du déploiement dans le deuxième paragraphe, je ne m'attarderai donc pas là-dessus. Je dirai une chose à propos de la vie: si vous utilisez Ansible, assurez-vous d'ajouter cette série, qui est sur la diapositive. Il est arrivé plus d'une fois que vous démarriez quelque chose, puis vous comprenez, mais je l'ai démarré à tort, ou à tort, ou à tort, et vous voyez que ce n'est qu'un serveur. Et nous pouvons facilement perdre un serveur et vous venez de le télécharger à nouveau, personne ne l'a remarqué.
De plus, ils ont installé le référentiel d'artefacts sur Nexus - c'est un point d'entrée unique pour absolument tout le monde, pas seulement CI.
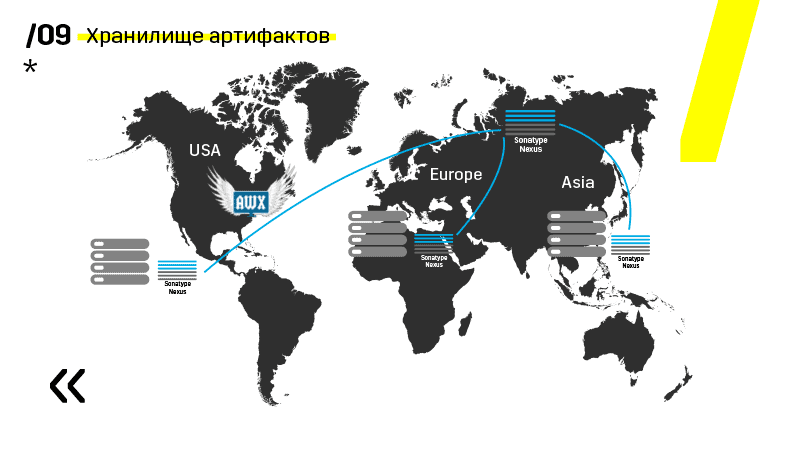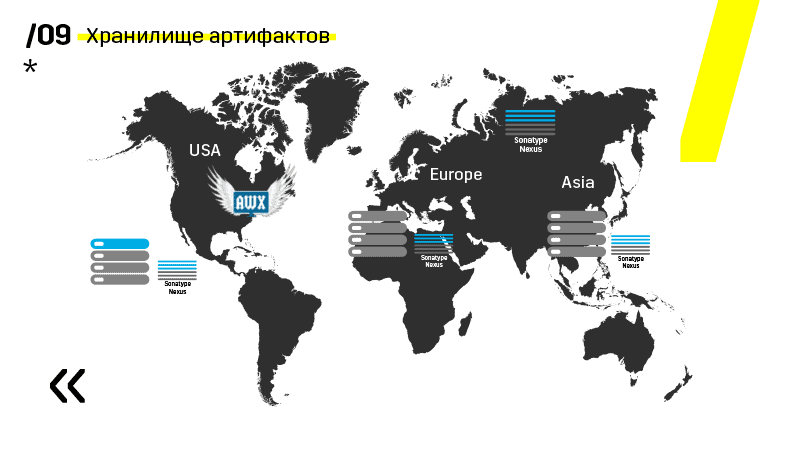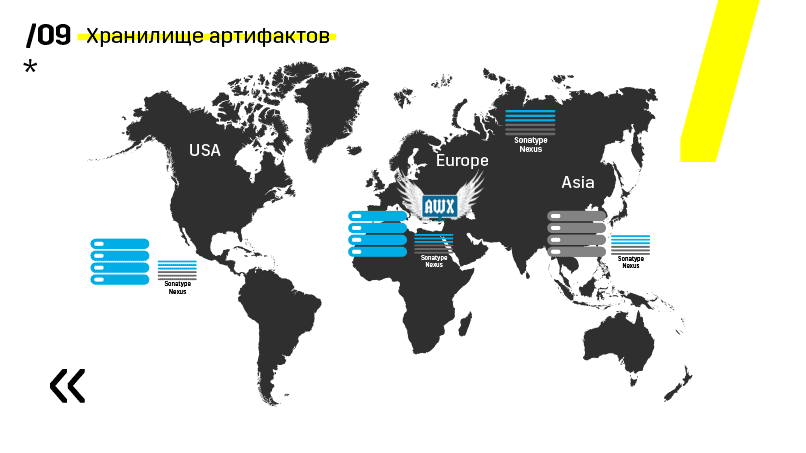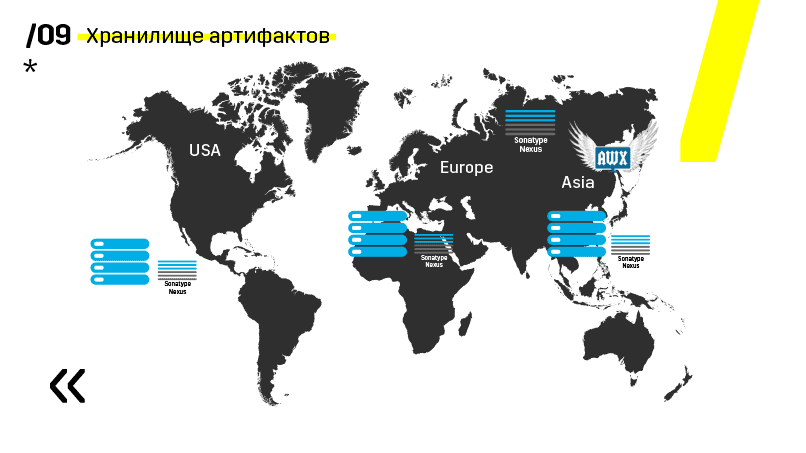
Et cela nous aide beaucoup à assurer la répétabilité. Eh bien, comme Nexus peut fonctionner en tant que services proxy dans différentes régions, ils accélèrent le déploiement, l'installation de packages rpm, les images de docker, etc.
Lorsque vous déposez un nouveau projet, il est conseillé de choisir des composants faciles à automatiser. Par exemple, nous n'avons pas réussi avec le serveur Photon. En tout cas, c'était la meilleure solution à d'autres égards. Mais Cassandra, par exemple, est très facilement mise à jour et automatisée.
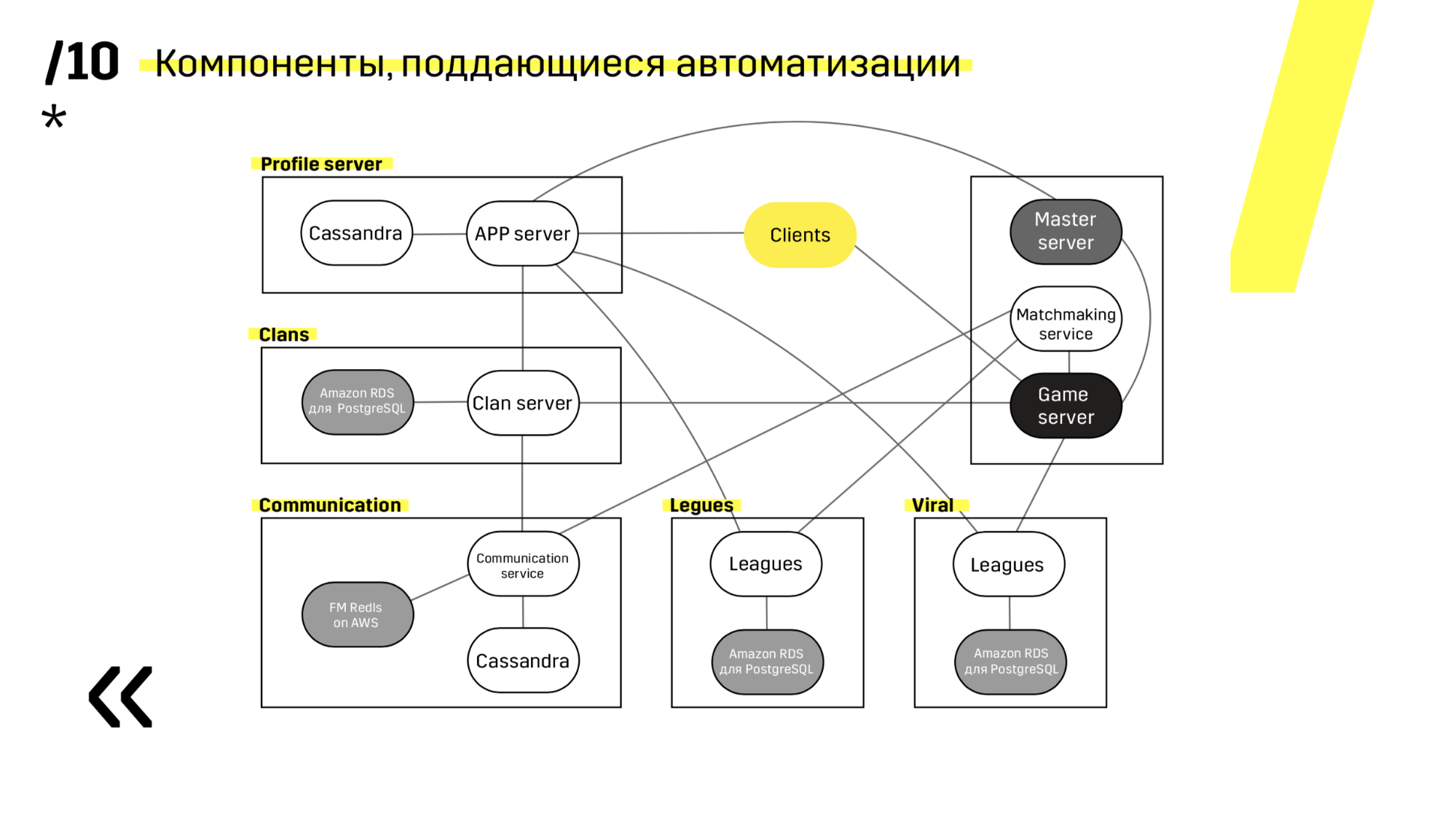
Voici un exemple de l'un de nos projets. Le client arrive sur le serveur APP, où il a un profil dans la base de données Cassandra, puis se rend sur le serveur maître, qui, avec l'aide du matchmaking, lui donne un serveur de jeu avec une sorte d'espace. Tous les autres services sont réalisés sous la forme d'une «application - base de données» et sont mis à jour exactement de la même manière.
Deuxième point: vous devez fournir une architecture de déploiement simple et faiblement couplée. Nous avons réussi.
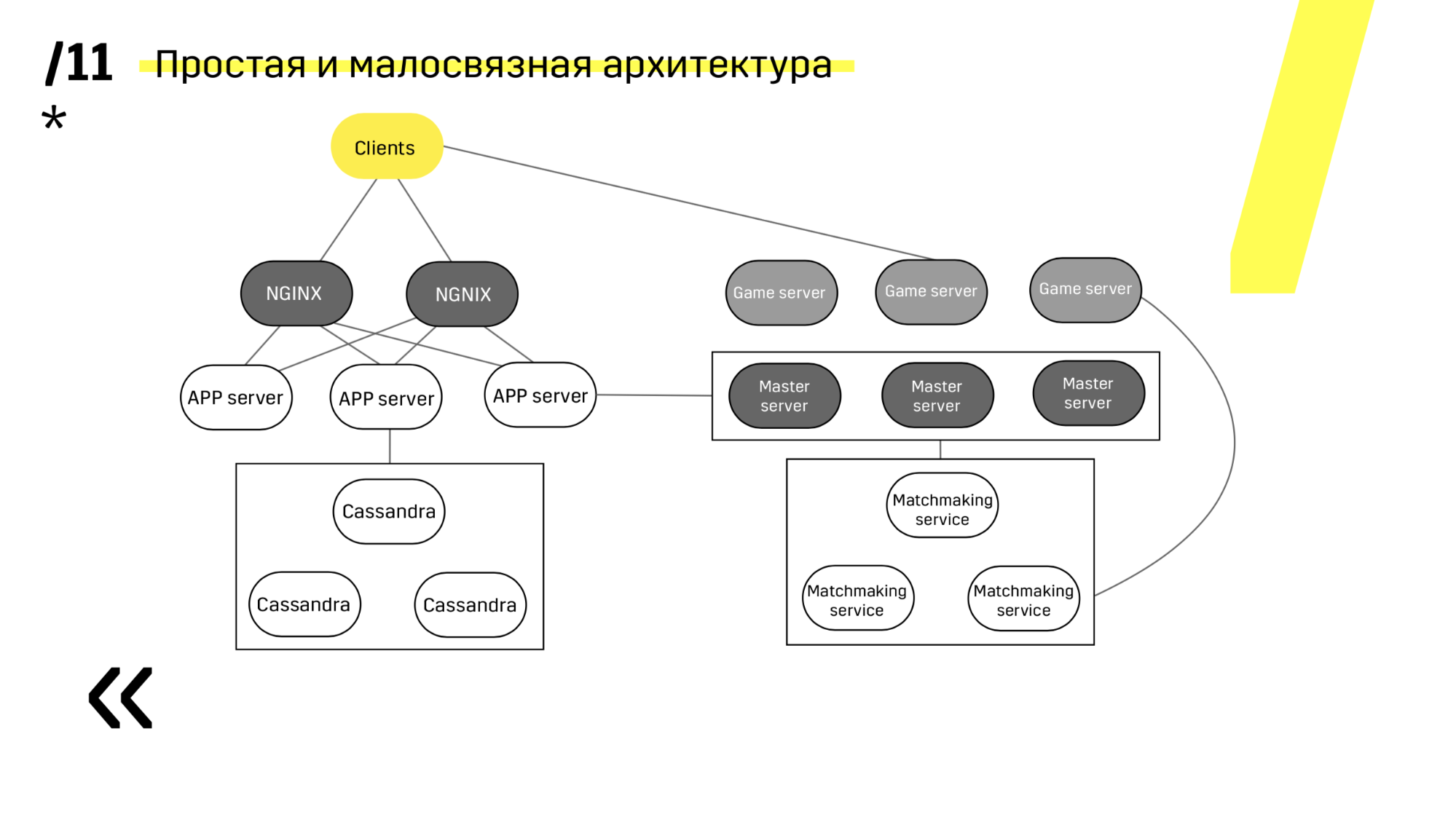
Voir, mettre à jour par exemple le serveur d'applications. Nous avons des services de découverte dédiés qui reconfigurent l'équilibreur, nous allons donc simplement sur le serveur d'applications, l'extinction, il se bloque de l'équilibrage, nous mettons à jour tout. Et donc avec chacun individuellement.
Les serveurs maîtres sont mis à jour presque à l'identique. Le client envoie un ping à chaque serveur maître de la région et passe à celui sur lequel le ping est le meilleur. En conséquence, si nous mettons à jour le serveur maître, alors le jeu ira peut-être un peu plus lentement, mais il est mis à jour facilement et simplement.
Les serveurs de jeux sont mis à jour un peu différemment car il y a toujours un jeu en cours. Nous allons au matchmaking, lui demandons de mettre un certain serveur hors service, de venir sur le serveur de jeu, d'attendre que les jeux deviennent exactement zéro et de mettre à jour. Ensuite, nous revenons à l'équilibre.
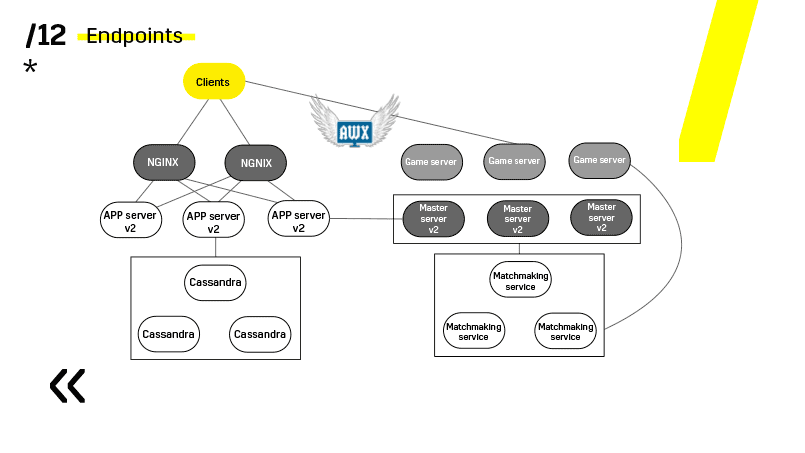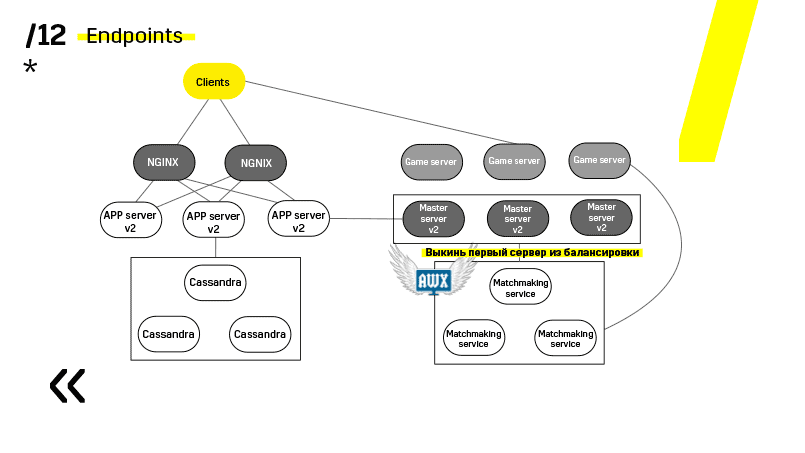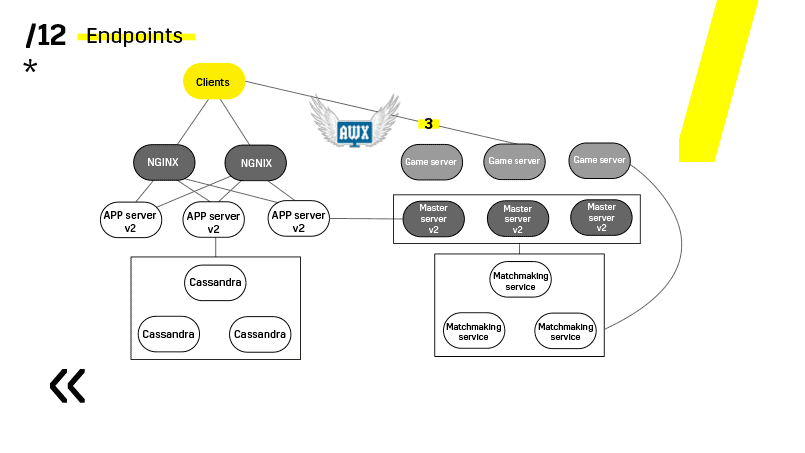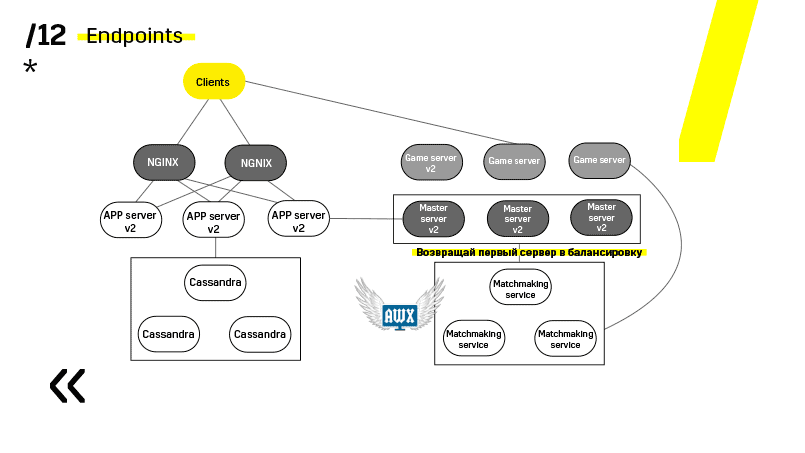
Le point clé ici est les points d'extrémité que possède chacun des composants et avec lesquels il est facile et simple de communiquer. Si vous avez besoin d'un exemple, il existe un cluster Elasticsearch. En utilisant des requêtes http régulières dans JSON, vous pouvez facilement communiquer avec lui. Et il donne immédiatement dans le même JSON toutes sortes de métriques différentes et des informations de haut niveau sur le cluster: vert, jaune, rouge.
Après avoir terminé ces 12 étapes, nous avons augmenté le nombre d'environnements, commencé à tester davantage, le déploiement a été accéléré, les gens ont commencé à recevoir des commentaires rapides.

Ce qui est très important, nous avons obtenu la simplicité et la rapidité des expériences. Et cela est très important, car lorsqu'il y a beaucoup d'expériences, nous pouvons facilement filtrer les idées erronées et nous concentrer sur les bonnes. Et non sur la base d’évaluations subjectives, mais sur la base d’indicateurs objectifs.
En fait, je ne suis plus lorsque nous avons un déploiement là-bas, lors de la sortie. Il n'y a pas de «oh, relâchez!» Sentiment, tout est réuni et la chair de poule. Maintenant, c'est une telle opération de routine, je vois périodiquement dans une salle de chat que quelque chose s'est produit, d'accord. C'est vraiment cool. Vos administrateurs système rugiront de joie lorsque vous le ferez.
Mais le monde ne reste pas immobile, il rebondit parfois. Nous avons quelque chose à améliorer. Par exemple, je voudrais également mettre les journaux de la construction dans Graylog. Cela nécessitera un raffinement supplémentaire de la journalisation afin qu'il n'y ait pas d'histoire distincte, mais clairement: c'est ainsi que la construction a été assemblée, donc elle a été testée, elle a été déployée, et donc elle se comporte sur la prod. Et une surveillance continue - c'est une histoire plus compliquée.

Nous utilisons Zabbix, et il n'est pas du tout prêt pour de telles approches. La 4e version sortira bientôt, nous découvrirons ce qui s'y trouve et si tout va mal, nous trouverons une solution différente. Je vais vous dire comment cela se passera lors de la prochaine réunion.
Questions du public
Et que se passe-t-il lorsque vous jetez des ordures en production? Par exemple, vous n'avez pas calculé quelque chose en fonction des performances et tout va bien pour l'intégration, mais en production, regardez - vos serveurs commencent à planter. Comment recule-t-on? Y a-t-il un bouton de sauvegarde?Nous avons essayé de faire l'automatisation de la restauration. Vous pouvez ensuite parler de rapports sur la façon dont cela fonctionne, à quel point tout est merveilleux. Mais d'abord, nous concevons pour que les versions soient rétrocompatibles et testons cela. Et quand nous avons fait cette chose entièrement automatique, qui vérifie quelque chose et la fait reculer, puis a commencé à vivre avec, nous avons réalisé que nous y mettions beaucoup plus d'efforts que si nous prenions simplement l'ancienne version avec la même pédale .
Concernant la mise à jour automatique du déploiement: pourquoi apportez-vous des modifications au serveur actuel, sans en ajouter un nouveau et simplement l'ajouter au groupe cible ou à l'équilibreur?Si vite.
Par exemple, si vous devez mettre à jour la version Java, vous changez l'état de l'instance sur Amazon, la mise à jour de la version Java ou autre chose, alors comment voulez-vous revenir dans ce cas? Apportez-vous des modifications sur le serveur de production?Oui, chaque composant fonctionne bien avec la nouvelle version et l'ancienne. Oui, vous devrez peut-être recharger le serveur.
Il y a des changements d'état quand de gros problèmes sont possibles ...Alors explosez.
Il me semble simplement ajouter un nouveau serveur et simplement le mettre sur le groupe cible dans le groupe cible - une petite tâche de complexité et une assez bonne pratique.Nous sommes hébergés sur du matériel, pas dans les nuages. Nous pouvons ajouter un serveur - c'est possible, mais un peu plus longtemps qu'un simple clic dans le cloud. Par conséquent, nous prenons notre serveur actuel (nous n'avons pas une telle charge pour ne pas pouvoir retirer certaines machines) - nous retirons certaines machines, les mettons à jour, y mettons le trafic de vente, voyons comment cela fonctionne, si tout va bien, alors nous continuerons à tout faire d'autres voitures.
Vous dites que si chaque commit est collecté et si tout est mauvais - le développeur règle tout tout de suite. Comprenez-vous que tout va mal? Quels sont les commits?Naturellement, au début c'était une sorte de test manuel, le feedback est lent. Ensuite, avec une sorte de tests automatiques sur Appium, tout cela est couvert, cela fonctionne et donne une sorte de rétroaction sur la chute ou non des tests.
C'est-à-dire Tout d'abord, chaque commit est déployé et les testeurs le regardent-ils?Eh bien, pas tout le monde, c'est de la pratique. Nous avons fait une pratique sur ces 12 points - accélérée. En fait, c'est un travail long et difficile, peut-être au cours de l'année. Mais idéalement, vous arrivez à cela et tout fonctionne. Oui, nous avons besoin d'une sorte d'autotests, au moins un ensemble minimal, pour que tout fonctionne pour vous.
Et la question est plus petite: il y a un serveur d'application dans l'image et ainsi de suite, est-ce ce qui m'intéresse là-bas? Vous avez dit que vous ne semblez pas avoir Docker, qu'est-ce qu'un serveur? Java nu ou quoi?Quelque part, c'est Photon sur Windows (un serveur de jeux), le serveur d'applications est une application Java sur Tomcat.
C'est-à-dire pas de virtualoks, pas de conteneurs, rien?Eh bien, Java est, pourrait-on dire, un conteneur.
Et tout se déroule-t-il avec Ansible?Oui C'est-à-dire à un certain moment, nous n'avons tout simplement pas investi dans l'orchestration, car pourquoi? Si dans tous les cas, Windows devra être géré séparément de la même manière, et ici absolument tout est couvert par un seul outil.
Et comment la base de données est-elle déployée? Dépendance à l'égard d'un composant ou d'un service?Il existe un schéma dans le service lui-même qui se déploiera lorsqu'il apparaîtra et doit être développé pour que rien ne soit supprimé, mais juste quelque chose soit ajouté et il soit rétrocompatible.
Votre base est-elle également en fer ou est-elle quelque part dans le cloud d'Amazon?La plus grande base est le fer, mais il y en a d'autres. Il y en a de petits, RDS n'est plus du fer, du virtuel. Ces petits services que j'ai montrés: chats, ligues, bavarder avec Facebook, clans, l'un d'eux est RDS.
Serveur maître - à quoi ressemble-t-il?En fait, c'est le même serveur de jeu, seulement avec un signe du maître et c'est un équilibreur. C'est-à-dire le client envoie un ping à tous les maîtres, puis il reçoit celui auquel le ping est le moins, et déjà le serveur maître utilisant le matchmaking recueille les salles sur les serveurs de jeu et envoie le joueur.
Je comprends bien que pour chaque déploiement, vous écrivez (si des fonctionnalités apparaissent) une migration pour mettre à jour les données? Vous avez dit que vous prenez d'anciens artefacts et que vous les remplissez - qu'advient-il des données? Ecrivez-vous une migration pour restaurer la base?Il s'agit d'une opération de restauration très rare. Oui, vous écrivez la migration des plumes et quoi faire.
Comment une mise à jour du serveur se synchronise-t-elle avec les mises à jour du client? C'est-à-dire vous devez sortir une nouvelle version du jeu - allez-vous d'abord mettre à jour tous les serveurs, puis les clients seront mis à jour? Le serveur prend-il en charge à la fois l'ancienne et la nouvelle version?Oui, nous développons le basculement et la gradation des fonctionnalités c. C'est-à-dire Il s'agit d'une poignée spéciale, un levier qui vous permet d'activer certaines fonctionnalités plus tard. Vous pouvez absolument mettre à niveau calmement, voir que tout fonctionne pour vous, mais n'incluez pas cette fonctionnalité. Et lorsque vous avez déjà dispersé le client, vous pouvez resserrer de 10% en fiddning, voir que tout va bien, puis au maximum.
Vous dites que vous avez stocké séparément des parties du projet dans différents référentiels, c'est-à-dire avez-vous une sorte de processus de développement? Si vous modifiez le projet lui-même, vos tests devraient tomber car vous avez modifié le projet. Les tests qui se trouvent séparément doivent donc être corrigés le plus rapidement possible.Je vous ai parlé de la baleine "interaction étroite avec les testeurs." Ce schéma avec différents référentiels ne fonctionne très bien que s'il existe une communication très dense. Ce n'est pas un problème pour nous, tout le monde communique facilement les uns avec les autres, il y a une bonne communication.
C'est-à-dire les testeurs prennent-ils en charge le référentiel de tests de votre équipe? Et les autotests se trouvent séparément?Oui Vous avez créé une fonctionnalité et vous pouvez collecter exactement les autotests dont vous avez besoin dans le référentiel des testeurs, et ne pas tout vérifier.
Une telle approche, lorsque tout se déroule rapidement - vous pouvez vous permettre d'aller immédiatement au prod pour chaque commit. Suivez-vous de telles tactiques ou composez-vous des versions? C'est-à-dire une fois par semaine, pas le vendredi, pas le week-end, avez-vous des tactiques de sortie ou la fonctionnalité est-elle prête, puis-je la sortir? Parce que si vous faites une petite version à partir de petites fonctionnalités, vous avez moins de chances que tout se brise, et si quelque chose se brise, vous savez certainement quoi.Forcer les utilisateurs clients à télécharger une nouvelle version toutes les cinq minutes ou tous les jours n'est pas une bonne idée. Dans tous les cas, vous serez attaché au client. C'est formidable lorsque vous avez un projet Web dans lequel vous pouvez mettre à jour au moins tous les jours et n'avez rien à faire. L'histoire est plus compliquée avec le client, nous avons une sorte de tactique de libération et nous nous y tenons.
Vous avez parlé de déployer l'automatisation sur les serveurs de produits et (si je comprends bien), il y a également le déploiement de l'automatisation pour un test - qu'en est-il des environnements de développement? Y a-t-il une sorte d'automatisation déployée par les développeurs?Presque la même chose. La seule chose n'est pas les serveurs de fer, mais dans la machine virtuelle, mais l'essence est à peu près la même. En même temps, sur le même Ansible, nous avons écrit (nous avons Ovirt) la création de cette machine virtuelle et son moletage.
Avez-vous toute l'histoire stockée dans un projet avec les prods Ansible et les configurations de test, ou est-ce qu'elle vit et se développe séparément?On peut dire que ce sont des projets séparés. Dev (nous l'appelons devbox) est une histoire quand tout est dans un seul pack, et sur la prod c'est une histoire distribuée.
Plus d'entretiens avec Pixonic DevGAMM Talks