Presque tous les nouveaux employés de Yandex sont étonnés de l'ampleur des contraintes que subissent nos produits. Des milliers d'hôtes avec des centaines de milliers de requêtes par seconde. Et ce n'est là qu'un des services. Dans ce cas, nous devons répondre aux demandes en une fraction de seconde. Même un léger changement dans le produit peut avoir un impact significatif sur les performances, il est donc important de tester et d'évaluer l'impact de votre code sur le service.
Au sein de notre service des technologies publicitaires, les tests fonctionnent dans le cadre de la méthodologie d'intégration continue, dont nous discuterons plus en détail de l'organisation du 25 octobre lors de l'événement Yandex de l'intérieur , et aujourd'hui nous partagerons avec les lecteurs Habr l'expérience de l'automatisation de l'évaluation des métriques de produits importantes liées à la performance du service. Vous apprendrez à confier l'analyse à une machine, et non à les suivre sur des graphiques. C'est parti!

Il ne s'agit pas de tester le site. Il existe de nombreux outils en ligne pour cela. Aujourd'hui, nous allons parler d'un service backend interne très chargé, qui fait partie d'un grand système et prépare les informations pour un service externe. Dans notre cas, pour les pages de résultats de recherche et les sites partenaires. Si notre composant n'a pas le temps de répondre, les informations qu'il contient ne seront tout simplement pas transmises à l'utilisateur. Ainsi, l'entreprise perdra de l'argent. Par conséquent, il est très important de répondre à temps.
Quelles mesures de serveur importantes peuvent être mises en évidence?
- Demande par seconde (RPS) . Le bonheur d'un utilisateur est bien sûr important pour nous. Mais si ce n'est pas un, mais des milliers d'utilisateurs sont venus vers vous. Combien de requêtes par seconde votre serveur peut-il supporter et ne pas tomber?
- Temps par demande . Le contenu du site doit être rendu le plus rapidement possible afin que l'utilisateur ne se lasse pas d'attendre et qu'il n'aille pas au magasin pour du pop-corn. Dans notre cas, il ne verra pas une partie importante des informations sur la page.
- Taille de l'ensemble résident (RSS) . Assurez-vous de surveiller la quantité de mémoire utilisée par votre programme. Si le service mange toute la mémoire, il n'est guère possible de parler de tolérance aux pannes.
- Erreurs HTTP .
Alors mettons-le dans l'ordre.
Demande par seconde
Notre développeur, qui s'occupe de tests de charge depuis longtemps, aime parler de la ressource critique du système. Voyons voir ce que c'est.
Chaque système a ses propres caractéristiques de configuration qui déterminent le fonctionnement. Par exemple, la longueur de la file d'attente, le délai de réponse, le pool de threads, etc. Il peut donc arriver que la capacité de votre service repose sur l'une de ces ressources. Vous pouvez mener une expérience. Augmentez tour à tour chaque ressource. Une ressource, dont l'augmentation augmentera la capacité de votre service, sera critique pour vous. Dans un système bien configuré, pour augmenter la capacité, vous devrez augmenter non pas une ressource, mais plusieurs. Mais cela peut encore être "ressenti". Ce sera formidable si vous pouvez configurer votre système de sorte que toutes les ressources fonctionnent à pleine puissance et que le service s’adapte dans les délais qui lui sont impartis.
Pour estimer le nombre de requêtes par seconde que votre serveur supportera, vous devez lui diriger un flux de requêtes. Étant donné que ce processus est intégré au système CI, nous utilisons un «pistolet» très simple avec des fonctionnalités limitées. Mais à partir d'un logiciel open source, Yandex.Tank est parfait pour cette tâche. Il a une documentation détaillée. Un cadeau à Tank est un service permettant de visualiser les résultats.
Un petit dessus. Yandex.Tank a une fonctionnalité assez riche, non limitée à l'automatisation des demandes de décorticage. Il vous aidera également à collecter des métriques de votre service, à créer des graphiques et à fixer le module avec la logique dont vous avez besoin. En général, nous vous recommandons fortement de le connaître.
Vous devez maintenant envoyer des requêtes au tank afin qu'il puisse tirer à notre service. Les requêtes avec lesquelles vous shellerez le serveur peuvent être du même type, créées et propagées artificiellement. Cependant, les mesures seront beaucoup plus précises si vous pouvez collecter un véritable pool de demandes d'utilisateurs pendant une certaine période de temps.
La capacité peut être mesurée de deux manières.
Modèle de charge ouverte (stress test)
Créez des "utilisateurs", c'est-à-dire plusieurs threads qui enverront une demande à votre système. La charge que nous ne donnerons pas est constante, mais l'accumule ou la nourrit même par vagues. Ensuite, cela nous rapprochera de la vie réelle. Nous augmentons le RPS et saisissons le point auquel le service bombardé «franchit» le SLA. Ainsi, vous pouvez trouver les limites du système.
Pour calculer le nombre d'utilisateurs, vous pouvez utiliser la petite formule (vous pouvez la lire ici ). En omettant la théorie, la formule ressemble à ceci:
RPS = 1000 / T * travailleurs, où
• T - temps moyen de traitement des demandes (en millisecondes);
• travailleurs - le nombre de fils;
• 1000 / T requêtes par seconde - cette valeur sera générée par un générateur à thread unique.
Modèle de charge fermée (test de charge)
Nous prenons un nombre fixe d '«utilisateurs». Vous devez le configurer pour que la file d'attente d'entrée correspondant à la configuration de votre service soit toujours obstruée. Dans le même temps, cela n'a aucun sens de faire un nombre de threads supérieur à la limite de file d'attente, car nous nous reposerons sur ce nombre, et les demandes restantes seront rejetées par le serveur avec une erreur 5xx. Nous regardons combien de requêtes par seconde le design pourra émettre. Un tel schéma dans le cas général n'est pas similaire au flux réel de requêtes, mais il aidera à montrer le comportement du système à la charge maximale et à évaluer son débit actuel.
Pour la grande majorité des systèmes (où la ressource critique n'est pas liée au traitement des connexions), le résultat sera le même. Dans le même temps, le modèle fermé a moins de bruit, car le système est dans la zone de charge qui nous intéresse tout le temps du test.
Lors du test de notre service, nous utilisons un modèle fermé. Après le tir, le pistolet nous indique le nombre de demandes par seconde que notre service a pu émettre. Yandex.Tank cet indicateur est également facile à dire.
Temps par demande
Si nous revenons au paragraphe précédent, il devient évident qu'avec un tel schéma, cela n'a aucun sens d'évaluer le temps de réponse à une requête. Plus le système est chargé, plus il se dégrade et plus il répond. Par conséquent, pour tester le temps de réponse, l'approche doit être différente.
Pour obtenir le temps de réponse moyen, nous utiliserons le même Yandex.Tank. Ce n'est que maintenant que nous fixerons le RPS correspondant à l'indicateur moyen de votre système en production. Après le bombardement, nous obtenons des temps de réponse pour chaque demande. Sur la base des données collectées, des centiles de temps de réponse peuvent être calculés.
Ensuite, vous devez comprendre quel centile nous considérons important. Par exemple, nous misons sur la production. Nous pouvons laisser 1% des demandes d'erreurs, des non-réponses, des demandes de débogage qui fonctionnent longtemps, des problèmes avec le réseau, etc. Par conséquent, nous considérons comme important le temps de réponse, qui prend en charge 99% des demandes.
Taille de l'ensemble résident
Notre serveur fonctionne directement avec les fichiers via mmap . En mesurant l'index RSS, nous voulons savoir combien de mémoire le programme a pris au système d'exploitation pendant le fonctionnement.
Sous Linux, le fichier / proc / PID / smaps est écrit - il s'agit d'une extension basée sur une carte qui montre la consommation de mémoire pour chacun des mappages de processus. Si votre processus utilise tmpfs, la mémoire anonyme et non anonyme sera mise en smaps. La mémoire non anonyme comprend, par exemple, les fichiers chargés en mémoire. Voici un exemple d'entrée dans smaps. Un fichier spécifique est spécifié et son paramètre Anonymous = 0kB.
7fea65a60000-7fea65a61000 r--s 00000000 09:03 79169191 /place/home/.../some.yabs Size: 4 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 4 kB Private_Dirty: 0 kB Referenced: 4 kB Anonymous: 0 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd mr me ms
Et ceci est un exemple d'allocation de mémoire anonyme. Lorsqu'un processus (le même mmap) demande au système d'exploitation d'allouer une certaine taille de mémoire, une adresse lui est allouée. Alors que le processus ne prend que de la mémoire virtuelle. À ce stade, nous ne savons pas encore quel morceau de mémoire physique sera alloué. Nous voyons un record sans nom. Ceci est un exemple d'allocation de mémoire anonyme. Le système a été demandé la taille de 24572 kB, mais ils ne l'ont pas utilisé et en fait seulement RSS = 4 kB a été pris.
7fea67264000-7fea68a63000 rw-p 00000000 00:00 0 Size: 24572 kB Rss: 4 kB Pss: 4 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 4 kB Referenced: 4 kB Anonymous: 4 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Locked: 0 kB VmFlags: rd wr mr mw me ac
Étant donné que la mémoire non anonyme allouée n'ira nulle part après l'arrêt du processus, le fichier ne sera pas supprimé, nous ne sommes pas intéressés par ce RSS.
Avant de commencer à tirer sur le serveur, nous résumons le flux RSS de / proc / PID / smaps, alloué à la mémoire anonyme, et nous nous en souvenons. Nous procédons au décorticage, similaire au temps de test par demande. Après avoir terminé, pensez à nouveau à RSS. La différence entre l'état initial et l'état final sera la quantité de mémoire utilisée par votre processus pendant le fonctionnement.
Erreurs HTTP
N'oubliez pas de suivre les codes de réponse que le service renvoie lors des tests. Si quelque chose s'est mal passé lors de la configuration d'un test ou d'un environnement et que le serveur a renvoyé des erreurs 5xx et 4xx pour toutes vos demandes, il n'y avait pas grand intérêt à un tel test. Nous surveillons la proportion de mauvaises réponses. S'il y a beaucoup d'erreurs, le test est considéré comme invalide.
Un peu sur la précision des mesures
Et maintenant, la chose la plus importante. Revenons aux paragraphes précédents. Il se trouve que les valeurs absolues des métriques calculées par nous ne sont pas si importantes pour nous. Non, bien sûr, vous pouvez atteindre la stabilité des indicateurs, en tenant compte de tous les facteurs, erreurs et fluctuations. En parallèle, écrivez un travail scientifique sur ce sujet (au fait, si quelqu'un en recherche un, cela pourrait être une bonne option). Mais ce n'est pas cela qui nous intéresse.
Il est important pour nous d'influencer la validation spécifique sur le code par rapport à l'état précédent du système. C'est-à-dire que la différence entre les métriques de validation en validation est importante. Et ici, il est nécessaire de mettre en place un processus qui comparera cette différence et garantira en même temps la stabilité de la valeur absolue dans cet intervalle.
L'environnement, les demandes, les données, l'état du service - tous les facteurs à notre disposition doivent être fixes. C'est ce système qui fonctionne pour nous dans le cadre de l'intégration continue, nous fournissant des informations sur toutes sortes de changements survenus au sein de chaque commit. Malgré cela, il ne sera pas possible de tout réparer, il y aura du bruit. On peut réduire le bruit, évidemment, en augmentant l'échantillon, c'est-à-dire faire plusieurs itérations de la prise de vue. De plus, après avoir tourné, disons, 15 itérations, nous pouvons calculer la médiane de l'échantillon résultant. De plus, il est nécessaire de trouver un équilibre entre le bruit et la durée de la prise de vue. Par exemple, nous avons retenu une erreur de 1%. Si vous souhaitez choisir une méthode statistique plus complexe et précise en fonction de vos besoins, nous vous recommandons un livre qui répertorie les options avec une description de quand et laquelle est utilisée.
Que peut-on faire d'autre avec le bruit?
Notez que l'environnement dans lequel vous effectuez des tests joue un rôle important dans ces tests. Le banc de test doit être fiable, il ne doit pas exécuter d'autres programmes, car ils peuvent conduire à la dégradation de votre service. De plus, les résultats peuvent et dépendront du profil de charge, de l'environnement, de la base de données et de divers «orages magnétiques».
Dans le cadre d'un test de validation unique, nous effectuons plusieurs itérations sur différents hôtes. Premièrement, si vous utilisez le cloud, tout peut y arriver. Même si le cloud est spécialisé, comme le nôtre, les processus de service y fonctionnent toujours. Par conséquent, vous ne pouvez pas compter sur le résultat d'un hôte. Et si vous avez un hôte de fer, où il n'y a pas, comme dans le cloud, de mécanisme standard pour élever l'environnement, vous pouvez même le casser une fois et le laisser ainsi. Et il vous mentira toujours. Par conséquent, nous effectuons nos tests dans le cloud.
Certes, une autre question en découle. Si vos mesures sont effectuées à chaque fois sur des hôtes différents, les résultats peuvent faire un peu de bruit et à cause de cela. Ensuite, vous pouvez normaliser les lectures sur l'hôte. Autrement dit, selon les données historiques, collecter le «coefficient hôte» et en tenir compte lors de l'analyse des résultats.
L'analyse des données historiques montre que le matériel est différent. Le mot «matériel» inclut ici la version du noyau et les conséquences de la disponibilité (apparemment, les objets du noyau non mobiles en mémoire).
Ainsi, à chaque "hôte" (au redémarrage, l'hôte "meurt" et un "nouveau" apparaît) nous associons l'amendement par lequel nous multiplions le RPS avant agrégation.
Nous considérons et mettons à jour les amendements d'une manière extrêmement maladroite, rappelant étrangement une option de formation de renforcement.
Pour un vecteur donné de corrections postérieures, nous considérons la fonction objectif:
- dans chaque test, nous considérons l'écart type des résultats RPS «corrigés» obtenus
- prendre la moyenne d'eux avec des poids égaux ,
- nous avons tau = 1 semaine.
Ensuite, nous fixons une correction (pour l'hôte avec la plus grande somme de ces poids) à 1,0 et recherchons les valeurs de toutes les autres corrections qui donnent un minimum de la fonction objectif.
Afin de valider les résultats sur les données historiques, nous considérons les corrections sur les anciennes données, nous considérons le résultat corrigé sur le frais, comparons avec le non corrigé.
Une autre option pour ajuster les résultats et réduire le bruit est la normalisation des «synthétiques». Avant de démarrer le service à tester, exécutez un «programme synthétique» sur l'hôte, à partir duquel vous pouvez évaluer l'état de l'hôte et calculer le facteur de correction. Mais dans notre cas, nous utilisons des corrections basées sur l'hôte, et cette idée est restée une idée. Peut-être que l'un d'entre vous l'aimera.
Malgré l'automatisation et tous ses avantages, n'oubliez pas la dynamique de vos indicateurs. Il est important de s'assurer que le service ne se dégrade pas avec le temps. Vous ne remarquerez peut-être pas de petits rabattements, ils peuvent s'accumuler et, sur une longue période, vos indicateurs peuvent s'affaisser. Voici un exemple de nos graphiques que nous examinons à RPS. Il montre la valeur relative de chaque validation vérifiée, son numéro et la possibilité de voir d'où la version a été allouée.
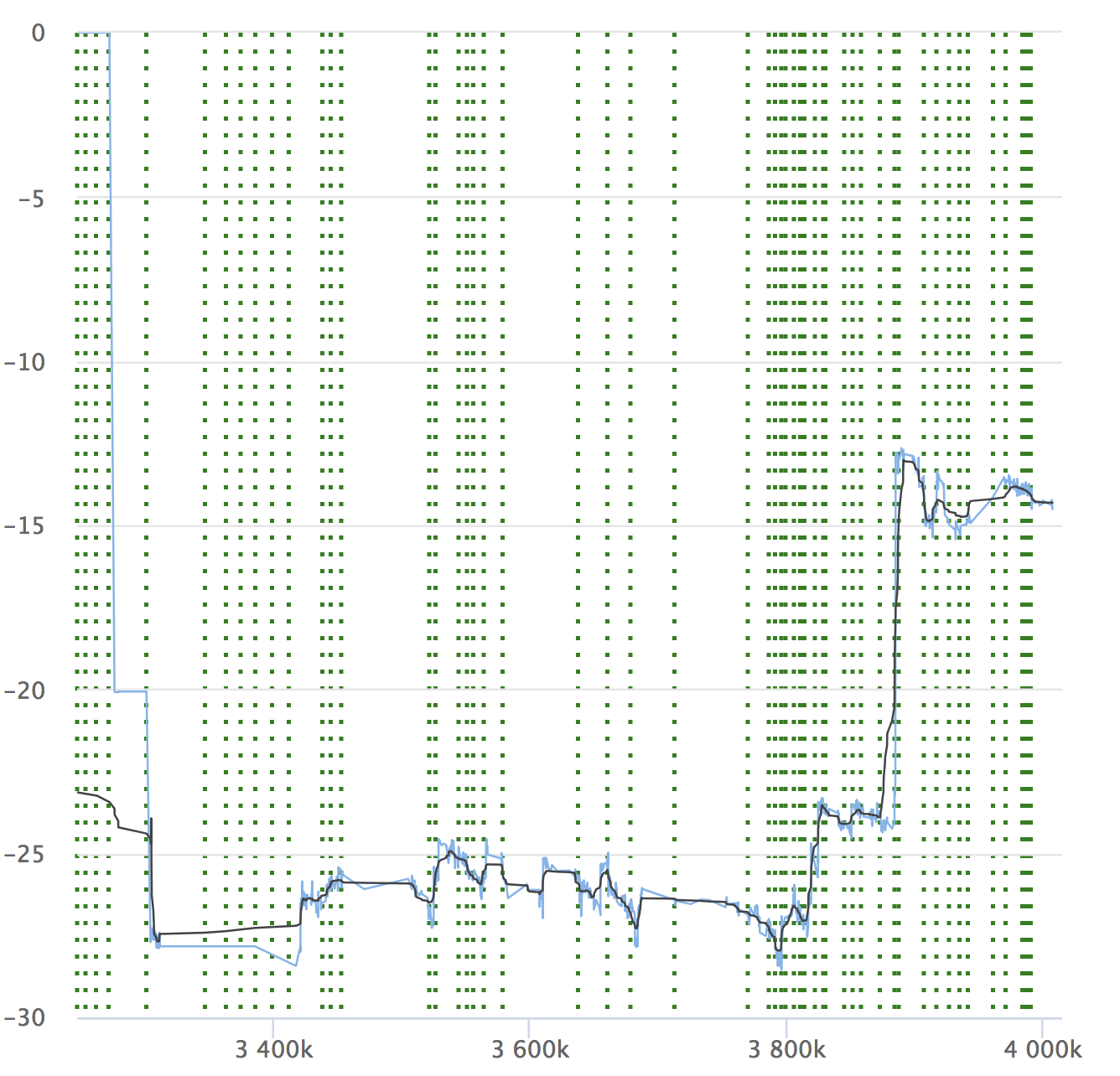
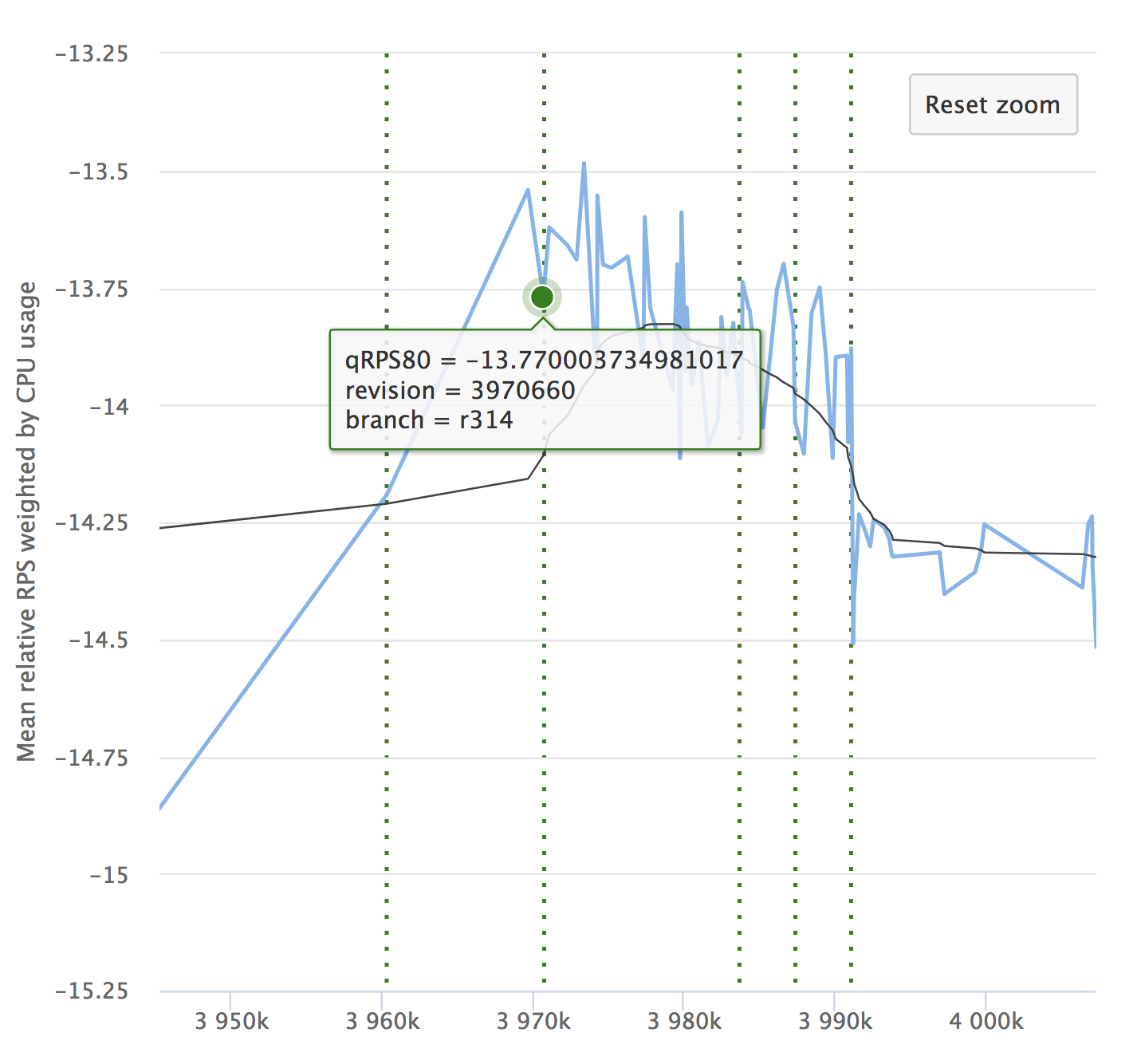
Si vous lisez l'article, il sera certainement intéressant pour vous de voir un rapport sur Yandex.Tank et une analyse des résultats des tests de charge.
Nous vous rappelons également que plus en détail sur l'organisation de l'intégration continue nous parlerons du 25 octobre lors de l'événement Yandex de l'intérieur . Venez visiter!