Nous présentons à votre attention la technique de création de programmes d'assembleur avec des instructions qui se chevauchent - pour protéger le bytecode compilé du démontage. Cette technique est capable de résister à l'analyse de bytecode statique et dynamique. L'idée est de sélectionner un flux d'octets qui, lorsqu'il est désassemblé de deux décalages différents, entraîne deux chaînes d'instructions différentes, c'est-à-dire deux façons différentes d'exécuter le programme. Pour ce faire, nous prenons des instructions d'assembleur multi-octets et masquons le code protégé dans les parties variables du bytecode de ces instructions. Afin de tromper le démonteur en le mettant sur une fausse piste (selon une chaîne d'instructions de masquage), et de protéger de ses yeux une chaîne d'instructions cachée.

Trois conditions préalables pour créer un «chevauchement» efficace
Afin de tromper le désassembleur, le code qui se chevauche doit satisfaire aux trois conditions suivantes: 1) Les instructions de la chaîne de masquage et la chaîne cachée doivent toujours se croiser, c'est-à-dire ne doivent pas être alignés les uns par rapport aux autres (leurs premier et dernier octets ne doivent pas coïncider). Sinon, une partie du code caché sera visible dans la chaîne de masquage. 2) Les deux chaînes doivent être constituées d'instructions de montage plausibles. Sinon, le masquage sera déjà détecté au stade de l'analyse statique (après être tombé sur un code inapproprié pour l'exécution, le désassembleur corrigera le pointeur de commande et exposera le masquage). 3) Toutes les instructions des deux chaînes doivent être non seulement plausibles, mais également correctement exécutées (pour éviter que cela ne se produise, le programme s'est écrasé lorsque vous essayez de les exécuter). Sinon, lors de l'analyse dynamique, les échecs attireront l'attention du revers, et le masque sera révélé.
Description de la technique des instructions d'assembleur "à chevauchement"
Afin de rendre le processus de création de code se chevauchant aussi flexible que possible, il est nécessaire de sélectionner uniquement ces instructions multioctets, pour lesquelles autant d'octets que possible peuvent prendre n'importe quelle valeur. Ces instructions multi-octets constitueront une chaîne d'instructions de masquage.
Dans le but de créer un code qui se chevauchent et qui satisfera aux trois conditions ci-dessus, nous considérons chaque instruction de masquage comme une séquence d'octets de la forme: XX YY ZZ.
Ici XX est le préfixe d'instruction (code d'instruction et autres octets statiques - qui ne peuvent pas être modifiés).
YY sont des octets qui peuvent être modifiés arbitrairement (en règle générale, ces octets stockent la valeur numérique directe transmise à l'instruction; ou l'adresse de l'opérande stockée en mémoire). Il doit y avoir autant d'octets YY que possible afin que plus d'instructions cachées puissent y entrer.
ZZ - ce sont également des octets qui peuvent être modifiés arbitrairement, à la seule différence que la combinaison d'octets ZZ avec les octets suivants XX (ZZ XX) doit former une instruction valide qui remplit les trois conditions formulées au début de l'article. Idéalement, ZZ ne devrait occuper qu'un seul octet, de sorte que sur YY (c'est essentiellement la partie la plus importante - notre code caché est placé ici), il devrait y avoir autant d'octets que possible. La dernière instruction cachée devrait se terminer en ZZ, - créant un point de convergence pour les deux chaînes d'exécution.
Instructions de collage
La combinaison ZZ XX - nous appellerons l'instruction de collage. Une instruction de collage est nécessaire, d'une part, pour joindre des instructions cachées situées dans des instructions de masquage adjacentes et, d'autre part, pour remplir la première condition nécessaire énoncée au début de l'article: les instructions des deux chaînes doivent toujours se croiser (par conséquent, l'instruction de collage est toujours situé à l'intersection de deux instructions de masquage).
L'instruction de collage est exécutée dans une chaîne de commandes cachée et doit donc être sélectionnée de manière à imposer le moins de restrictions possible au code caché. Supposons que lors de son exécution, les registres à usage général et le registre EFLAGS soient modifiés, le code caché ne pourra pas utiliser efficacement les registres et commandes conditionnelles correspondants (par exemple, si l'instruction de collage est précédée par l'opérateur de comparaison et que l'instruction de collage elle-même modifie la valeur du registre EFLAGS, puis la transition conditionnelle, qui se trouve après les instructions de collage ne fonctionnera pas correctement).
La description ci-dessus de la technique de chevauchement est illustrée dans la figure suivante. Si l'exécution commence par les octets de début (XX), alors une chaîne d'instructions de masquage est activée. Et si à partir des octets YY, une chaîne d'instructions cachée est activée.

Instructions d'assembleur adaptées au rôle d '"instructions de masquage"
La plus longue des instructions, qui à première vue nous convient le mieux, est une version de 10 octets de MOV, où le décalage spécifié par le registre et l'adresse 32 bits est transféré comme premier opérande, et le nombre 32 bits comme deuxième opérande. Cette instruction contient le plus d'octets pouvant être modifiés arbitrairement (jusqu'à 8 pièces).

Cependant, bien que cette instruction semble plausible (théoriquement, elle peut être exécutée correctement), elle ne nous convient toujours pas, car son premier opérande, en règle générale, pointera vers une adresse inaccessible, et donc, lorsque vous essayez d'exécuter un tel MOV, le programme va s'effondrer. T.O. ce MOV de 10 octets ne remplit pas la troisième condition nécessaire: toutes les instructions des deux chaînes doivent être correctement exécutées.
Par conséquent, nous choisirons pour le rôle d'instructions de masquage uniquement les candidats qui ne présentent pas de risque d'effondrement du programme. Cette condition réduit considérablement la gamme d'instructions appropriées pour créer du code qui se chevauchent, mais il en existe encore. En voici quatre. Chacune de ces quatre instructions contient cinq octets, qui peuvent être modifiés arbitrairement, sans risque de plantage du programme.
- LEA. Cette instruction calcule l'adresse mémoire spécifiée par l'expression dans le deuxième opérande et stocke le résultat dans le premier opérande. Étant donné que nous pouvons nous référer à la mémoire sans y avoir réellement accès (et, par conséquent, sans risque de plantage du programme), les cinq derniers octets de cette instruction peuvent prendre des valeurs arbitraires.

- CMOVcc. Cette instruction effectue l'opération MOV si la condition «cc» est remplie. Pour que cette instruction satisfasse à la troisième exigence, la condition doit être sélectionnée de telle sorte qu'en toutes circonstances, elle ait la valeur FAUX. Sinon, cette instruction peut essayer d'accéder à une adresse mémoire inaccessible, etc. faire baisser le programme.

- SETcc Il fonctionne sur le même principe que CMOVcc: met l'octet à un si la condition "cc" est remplie. Cette instruction a le même problème que CMOVcc: l'accès à une adresse non valide entraînera le plantage du programme. Par conséquent, le choix de la condition «cc» doit être abordé très attentivement.

- Non. Les NOP peuvent être de longueurs différentes (de 2 à 15 octets), selon les opérandes qui y sont indiqués. Dans ce cas, il n'y aura aucun risque de planter le programme (en raison de l'accès à une adresse mémoire invalide). Parce que la seule chose que les NOP font est d'augmenter le compteur d'instructions (ils n'effectuent aucune opération sur les opérandes). Par conséquent, les octets NOP dans lesquels les opérandes sont spécifiés peuvent prendre une valeur arbitraire. Pour nos besoins, un NOP de 9 octets est le mieux adapté.

Pour référence, voici quelques autres options NOP.
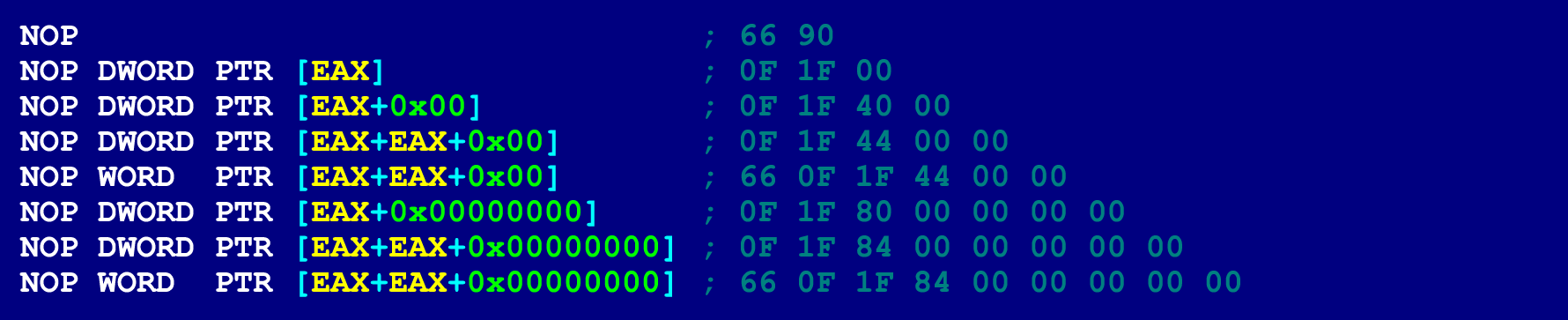
Instructions d'assembleur adaptées au rôle d '«instructions de collage»
La liste des instructions adaptées au rôle d'une instruction de collage est unique pour chaque instruction de masquage spécifique. Vous trouverez ci-dessous une liste (générée par l'algorithme illustré dans la figure suivante) utilisant un NOP de 9 octets comme exemple.

Pour former cette liste, nous avons pris en compte uniquement les options dans lesquelles ZZ prend 1 octet (sinon il y aura peu d'espace pour le code caché). Voici une liste d'instructions collantes appropriées pour un NOP de 9 octets.

Parmi cette liste d'instructions, aucune n'est exempte d'effets secondaires. Chacun d'eux modifie soit les EFLAGS, soit les registres à usage général, soit les deux à la fois. Cette liste est divisée en 4 catégories, selon l'effet secondaire de l'instruction.
La première catégorie comprend des instructions qui modifient le registre EFLAGS, mais ne modifient pas les registres à usage général. Les instructions de cette catégorie peuvent être utilisées en l'absence de sauts conditionnels ou d'instructions dans la chaîne d'instructions masquées basées sur l'évaluation des informations du registre EFLAGS. Dans ce cas, dans ce cas (pour un NOP à 9 octets), il n'y a que deux instructions: TEST et CMP.

Voici un exemple simple de code caché qui utilise TEST comme instruction de collage. Cet exemple effectue un appel système de sortie, qui renvoie une valeur de 1 pour n'importe quelle version de Linux. Afin de former correctement l'instruction TEST pour nos besoins, nous devrons définir le dernier octet du premier NOP sur 0xA9. Cet octet, lorsqu'il est couplé aux quatre premiers octets du prochain NOP (66 0F 1F 84), se transformera en une instruction TEST EAX, 0x841F0F66. Les deux figures suivantes montrent le code assembleur correspondant (pour la chaîne de masquage et la chaîne cachée). La chaîne cachée est activée lorsque le contrôle est transféré sur le 4ème octet du premier NOP.


La deuxième catégorie comprend des instructions qui modifient les valeurs des registres généraux ou de la mémoire disponible (pile, par exemple), mais ne modifient pas le registre EFLAGS. Lors de l'exécution d'une instruction PUSH ou de toute variante MOV, où une valeur immédiate est spécifiée comme deuxième opérande, le registre EFLAGS reste inchangé. T.O. des instructions de collage de la deuxième catégorie peuvent même être placées entre l'instruction de comparaison (TEST par exemple) et l'instruction d'évaluation du registre EFLAGS. Cependant, les instructions de cette catégorie limitent l'utilisation du registre qui apparaît dans les instructions de collage correspondantes. Par exemple, si MOV EBP, 0x841F0F66 est utilisé comme instruction de collage, les possibilités d'utilisation du registre EBP (du reste du code masqué) sont considérablement limitées.
La troisième catégorie comprend des instructions qui modifient le registre EFLAGS et les registres à usage général (ou mémoire) changent. Ces instructions n'ont pas d'avantages évidents par rapport aux instructions des deux premières catégories. Cependant, ils peuvent également être utilisés, car ils ne contredisent pas les trois conditions formulées au début de l'article. La quatrième catégorie comprend les instructions, dont la mise en œuvre ne garantit pas que le programme ne se bloquera pas - il existe un risque d'accès illégal à la mémoire. Il est extrêmement indésirable de les utiliser, car ils ne remplissent pas la troisième condition.
Instructions d'assembleur pouvant être utilisées dans une chaîne cachée
Dans notre cas (lorsque des NOP de 9 octets sont utilisés comme instructions de masquage), la longueur de chaque instruction de la chaîne cachée ne doit pas dépasser quatre octets (cette restriction ne s'applique pas aux instructions persistantes qui occupent 5 octets). Cependant, ce n'est pas une limitation très critique, car la plupart des instructions de plus de quatre octets peuvent être décomposées en plusieurs instructions plus courtes. Ce qui suit est un exemple d'un MOV de 5 octets qui est trop grand pour tenir dans une chaîne cachée.
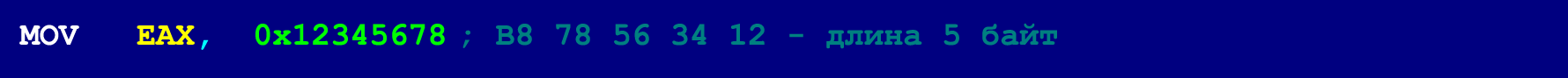
Cependant, ce MOV de cinq octets peut être décomposé en trois instructions, dont la longueur ne dépasse pas quatre octets.

Amélioration du masquage en dispersant les NOP de masquage tout au long du programme
Un grand nombre de NOP consécutifs semble, du point de vue inverse, très suspect. En concentrant son intérêt sur ces NOP suspects, un inverseur expérimenté peut accéder au bas du code qui s'y cache. Pour éviter cette exposition, des NOP masqués peuvent être dispersés tout au long du programme.
La chaîne correcte d'exécution du code caché dans ce cas peut être prise en charge par des instructions à deux octets de saut inconditionnel. Dans ce cas, les deux derniers octets de chaque NOP occuperont un JMP de 2 octets.
Cette astuce vous permet de diviser une longue séquence de NOP en plusieurs courtes (ou même d'utiliser un NOP chacun). Dans le dernier NOP d'une séquence aussi courte, seuls 3 octets de la charge utile peuvent être alloués (le 4ème octet sera pris par l'instruction de saut inconditionnel). T.O. ici, il y a une restriction supplémentaire sur la taille des instructions valides. Cependant, comme mentionné ci-dessus, des instructions longues peuvent être présentées sur une chaîne d'instructions plus courtes. Ci-dessous est un exemple du même MOV de 5 octets, que nous avons déjà présenté pour s'adapter à la limite de 4 octets. Cependant, maintenant nous décomposons ce MOV de manière à tenir dans la limite de 3 octets.
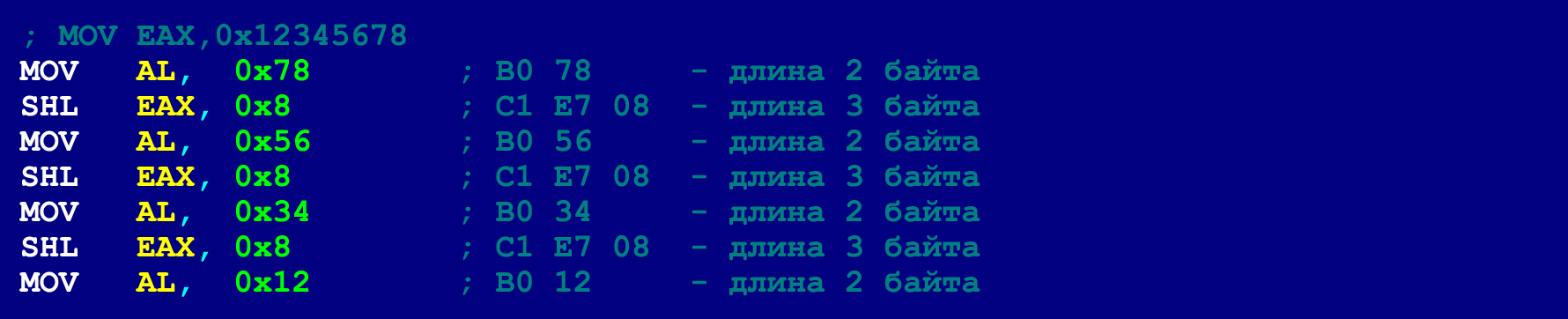
Après avoir décomposé toutes les instructions longues en instructions plus courtes selon le même principe, nous pouvons, pour en masquer davantage, utiliser généralement des NOP uniques dispersés tout au long du programme. Les instructions JMP à deux octets peuvent sauter en avant et en arrière de 127 octets, ce qui signifie que deux NOP consécutifs (consécutifs, en termes de chaîne d'instructions masquées) doivent se trouver dans les 127 octets.
Cette astuce a un autre avantage important (en plus du masquage amélioré): avec son aide, vous pouvez placer du code caché dans les NOP existants du fichier binaire compilé (c'est-à-dire insérer une charge utile dans le binaire après l'avoir compilé). Dans ce cas, il n'est pas nécessaire que ces NOP orphelins aient 9 octets. Par exemple, s'il y a plusieurs NOP à un octet consécutifs dans le binaire, ils peuvent être convertis en NOP à plusieurs octets, sans perturber la fonctionnalité du programme. Vous trouverez ci-dessous un exemple de technique de dispersion des NOP (ce code est fonctionnellement équivalent à l'exemple décrit ci-dessus).

Un tel code caché, caché dans NOP dispersé dans le programme, est déjà beaucoup plus difficile à détecter.
Un lecteur attentif doit avoir remarqué que le premier NOP n'a pas de dernier octet. Cependant, il n'y a rien à craindre. Parce que cet octet non réclamé est précédé d'un saut inconditionnel. T.O. le contrôle ne lui sera jamais transféré. Donc, tout est en ordre.
Voici une technique pour créer du code qui se chevauchent. Utilisation sur la santé. Cachez votre précieux code aux regards indiscrets. Mais adoptez simplement une autre instruction, pas un NOP de 9 octets. Parce que les inverseurs liront probablement aussi cet article.