
Bonjour à nouveau, Alexey Pristavko est en contact, et ceci est la deuxième partie de mon histoire sur le DataLine de stockage d'objets S3 basé sur Cloudian HyperStore.
Aujourd'hui, je parlerai en détail de la façon dont notre stockage S3 est organisé et des difficultés que nous avons rencontrées lors de sa création. Assurez-vous d'aborder le sujet «de fer» et d'analyser l'équipement sur lequel nous avons fini par rester.
C'est parti!
Si en lecture vous avez envie de vous familiariser avec l'architecture applicative de la solution Cloudian, vous trouverez son analyse détaillée dans l'
article précédent . Nous y avons discuté en détail du dispositif interne Cloudian, de la tolérance aux pannes et de la logique du SDS intégré.
Le schéma final de l'équipement physique
Puisque plus tard nous parlerons de notre "tourment de choix", je donnerai immédiatement la liste définitive du fer auquel nous sommes arrivés. Petit avertissement: le choix de l'équipement réseau était en grande partie dû à sa présence dans notre entrepôt (soit dit en passant, très solide).
Donc, au niveau physique du stockage, nous avons les équipements suivants:
Nom
| Fonction
| La configuration
| Qté
|
Serveur Lenovo System x3650 M5
| Noeud de travail
| 1x Xeon E5-2630v4 2,2 GHz,
4x 16 Go DDR4,
14x 10 To 7,2 K 6 Gbit / s SATA 3,5 ",
2 disques SSD de 480 Go,
Intel x520 double port 10 GbE SFP +,
2x750W HS PSU
| 4
|
Serveur HP ProLiant DL360 G9
| Noeud d'équilibrage de charge
| 2 E5-2620 v3,
128 Go de RAM,
2 disques SSD de 600 Go,
4 disques durs SAS,
Intel x520 double port 10 GbE SFP +
| 2
|
Commutateur Cisco C4500
| Passerelle frontalière
| Catalyst WS-C4500X-16SFP +
| 2
|
Commutateur Cisco C3750
| Prolongateur de port
| Catalyseur WS-C3750X-24T avec C3KX-NM-10G
| 2
|
Commutateur Cisco C2960
| avion de contrôle
| Catalyseur WS-C2960 + 48PST-L
| 1
|
Pour une meilleure compréhension de l'architecture, nous allons examiner tour à tour tous les éléments et parler de leurs fonctionnalités et tâches.
Commençons par les serveurs. Les serveurs Lenovo ont une configuration spéciale qui est implémentée conjointement et en pleine conformité avec les recommandations et spécifications Cloudian. Par exemple, ils utilisent un contrôleur avec un accès direct au disque. Étant donné que dans notre cas, le RAID est organisé au niveau du logiciel d'application, ce mode augmente la fiabilité et accélère le sous-système de disque. Exactement, les mêmes serveurs peuvent être achetés en tant qu'appliance Cloudian avec toutes les licences.
Les serveurs d'équilibrage de charge avec Nginx pour CentOS garantissent une répartition uniforme de la charge sur les nœuds de travail et soustraient l'utilisateur à l'organisation du trafic interne. Et comme bonus agréable - si nécessaire, vous pouvez organiser un cache sur eux.
La paire Cisco 4500X seize 10 Go SFP + sert de noyau et de frontière à notre petit mais fier réseau de stockage. Bien sûr, le fer est un peu démodé, mais il n'est pas inférieur au «nouveau» en termes de fiabilité, il a une redondance interne et sa fonctionnalité répond à toutes nos exigences. Le C3750 joue le rôle d'extendeur d'usine, il n'est pas nécessaire d'insérer des émetteurs-récepteurs 1G dans des emplacements 10G. Et passer complètement à des liens de 10 Go n'a pas encore beaucoup de sens. Comme les tests l'ont montré, nous avons rencontré le processeur et les disques plus tôt.
Le diagramme ci-dessous illustre suffisamment en détail l'organisation physique que j'ai décrite:
 1. Schéma d'organisation du stockage physique
1. Schéma d'organisation du stockage physiquePassons en revue le schéma. Comme vous pouvez le voir, la tolérance aux pannes au niveau physique est réalisée en dupliquant et en connectant chacun des appareils avec au moins deux liaisons optiques, une pour chaque appareil dans une paire. Cela nous donne une garantie de maintenir la connectivité physique dans le circuit lors d'un accident de tout périphérique réseau ou de deux périphériques de paires différentes simultanément.
Nous allons en dessous du schéma. Les deux paires Cisco (4500/4500, 3750/3750) sont combinées en un seul périphérique logique utilisant la pile et VSS. La pile est assemblée avec deux câbles de pile, VSS via trois liaisons optiques 10G. Cela vous permet de vous assurer que les deux appareils de chaque paire interagissent dans leur ensemble. Un tel clustering nous permet de travailler dans le cadre d'un segment L2 transparent à travers les deux appareils d'une paire et de faire une agrégation de liens générale à l'aide de LACP, car cette technologie est prise en charge de manière native par le système d'exploitation du serveur et Cisco IOS. Du côté du serveur, il semble qu'il fonctionne avec un commutateur au lieu de deux, et au-dessus de l'application, il y a un canal agrégé de double capacité.
Tout l'équipement réseau passant entre lui-même et les canaux entrants se fait à l'aide de liaisons optiques 10G, l'équipement serveur est connecté à l'aide de câbles Cisco Twinax 10G et de cuivre 1G.
BGP est utilisé pour la tolérance aux pannes sur le canal entrant, et Round Robin DNS est utilisé pour équilibrer les adresses IP externes. Les adresses externes elles-mêmes sont parquées sur des serveurs d'équilibrage de charge et, si nécessaire, migrent entre les nœuds à l'aide du paquet Pacemaker / Corosync.
La surveillance et le contrôle via IPMI sont effectués via une liaison interne directe. Toutes les interfaces de gestion (serveurs et Cisco) sont connectées via des commutateurs de plan de contrôle séparés. Ils sont à leur tour inclus dans le réseau de contrôle du centre de données. Cela nous garantit l'impossibilité de perdre la communication avec les équipements pendant le travail ou à la suite d'un accident sur un réseau externe. Pour le cas le plus extrême, il y a des préposés avec KVM.
Réseau logique
Pour comprendre le fonctionnement du réseau logique S3 du stockage DataLine, tournons-nous vers un autre schéma:
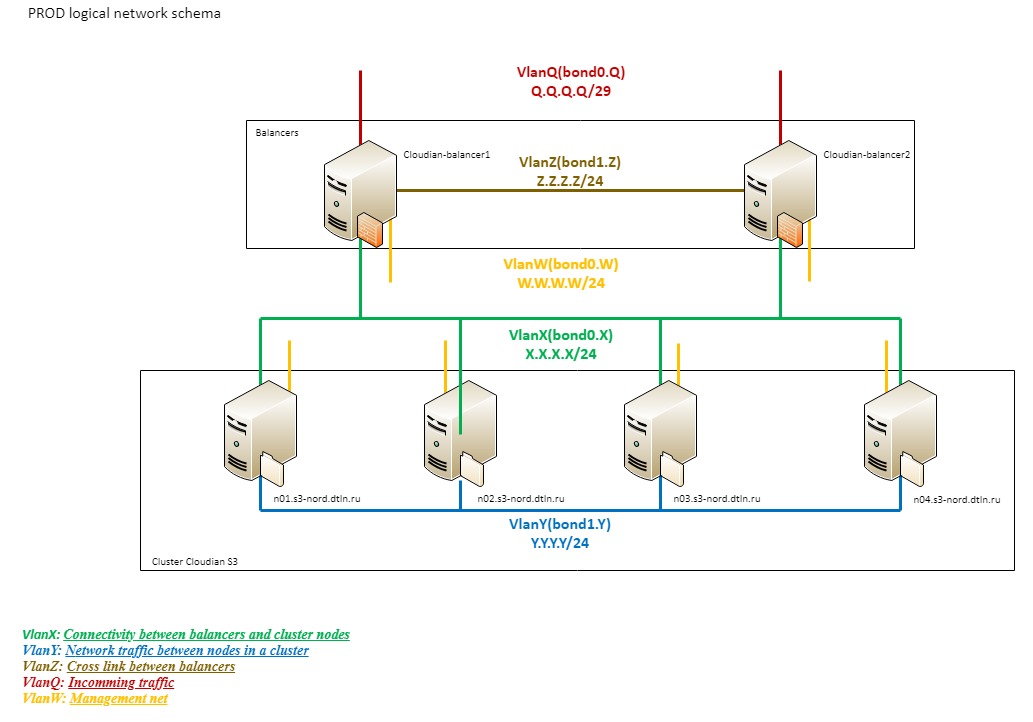 2. Schéma du réseau logique de stockage
2. Schéma du réseau logique de stockageComme vous pouvez le voir, la logique du réseau se compose de plusieurs segments.
Un réseau externe (Q) d'une capacité totale de 20G est connecté directement à Provider Edge. Viennent ensuite le Cisco 4500 et les équilibreurs.
Le bloc logique suivant (X) est le VLAN entre les équilibreurs et les nœuds de travail. Les équilibreurs utilisent la même connexion que pour le trafic entrant. Les nœuds de travail sont connectés via la pile 3750 avec 4 liaisons 1G (deux pour chaque 3750). Toutes les liaisons physiques sont assemblées en une seule liaison logique utilisant également LACP. Ce réseau est utilisé uniquement pour le traitement du trafic client.
Toutes les connexions au sein du cluster Cloudian (Y) passent par un troisième segment logique construit au-dessus de 10G. Une telle organisation permet d'éviter les problèmes sur le canal externe dus au trafic interne et vice versa. Il s'agit d'un segment extrêmement chargé et important pour le fonctionnement du cluster. C'est à travers lui que les données et les métadonnées sont répliquées, elles sont utilisées par toutes les procédures de rééquilibrage, etc., nous avons donc distingué son «insubmersibilité» comme une tâche distincte.
Un peu de beauté
Voici à quoi tout ressemble:
 3. Équipement réseau et équilibreurs complets
3. Équipement réseau et équilibreurs complets 4. La même vue arrière
4. La même vue arrièreFaites attention au changement. Dans des articles précédents, mes collègues ont écrit sur l'importance des câbles de marquage de couleur, mais il ne sera pas hors de propos de toucher à ce sujet ici.
Nous utilisons la commutation des couleurs non seulement pour le réseau, mais aussi pour l'alimentation. Cela permet à nos ingénieurs de naviguer rapidement dans le rack et réduit l'influence du facteur humain lors de la commutation.
 5. Noeuds de travail
5. Noeuds de travail 6. Vue arrière
6. Vue arrièreSur cette photo, vous pouvez clairement voir à quel point les serveurs qui fonctionnent sont remplis de disques - il n'y a pratiquement aucun emplacement vide même à l'arrière. Soit dit en passant, une telle organisation des câbles en faisceaux compacts remplit non seulement une fonction esthétique, mais évite également le chevauchement des ventilateurs des alimentations, ce qui évite au fer de surchauffer.
Liste blanche
Dans les commentaires sur le dernier article, j'ai promis de parler davantage de l'appareil de liste blanche.
Si, pour une raison quelconque, nous avons convenu avec le client d'exclure des comptes tous les travaux avec le stockage de l'intérieur du centre de données ou via des canaux directs vers son équipement, alors nous devons organiser une connexion privée au stockage.
Rappelez-vous, dans le premier diagramme, il y avait une branche sur DIST et Cloud? En plus du canal Internet principal de 20 Go, nous utilisons un canal agrégé pour les commutateurs, auquel nous connectons tous les clients au niveau du centre de données. Si le client veut un lien direct vers le stockage, nous pouvons configurer le VLAN du client vers notre 4500X avec la construction d'une route séparée (ou sans) et démarrer L3. Après cela, la liaison au plan tarifaire est configurée sur les adresses du client déjà dans Cloudian lui-même. Ensuite, pour tous ceux qui sont connectés à ce plan tarifaire, l'utilisation de S3 à partir d'adresses en liste blanche ne sera pas prise en compte.
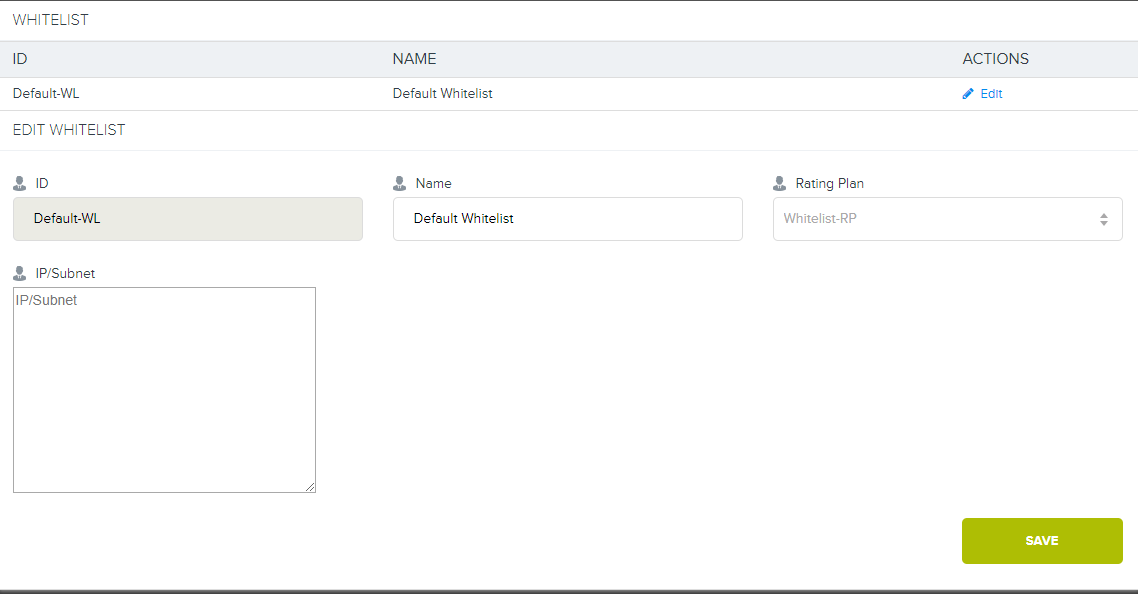 7. Et voici une interface spéciale dans Cloudian.
7. Et voici une interface spéciale dans Cloudian.Maintenant, nous n'avons pas un tel tarif dans le réseau, mais si vous le voulez vraiment, nous pouvons le fournir.
Histoire de la construction
Nous abordons progressivement la partie la plus intéressante de l'histoire - la construction d'une installation de stockage. Il y aura de nombreuses photos, jusqu'à trois tentatives pour organiser l'équilibrage du trafic et quelques mauvais conseils. J'espère que l'analyse des problèmes rencontrés sur le chemin sera utile à ceux qui se préparent à travailler avec des vitesses 10Gb + sur le web.
Expérimenter avec 10G
Avant de passer directement à l'essentiel de cette section, je me permets de faire un autre petit avertissement.
Selon une tradition établie, avant d'acheter de nouveaux équipements auxiliaires, nous nous rendons à l'entrepôt et sélectionnons des composants plus ou moins adaptés. Cela vous permet d'effectuer rapidement des tests et de décider d'une future liste de courses. Bien sûr, bien que nous n'atteignions pas un résultat fiable à 100%, rien n'est dépensé pour la productivité.
C'était donc cette fois. Et si Cisco n'a pas lancé de surprise, alors avec les équilibreurs de charge, la «cupidité» nous a presque ruinés.
La première expérience. Serveurs Supermicro
Ici, nous avons été déçus par le désir de réaliser un test rapide à moindre coût. Dans l'entrepôt, nous avons trouvé des serveurs Supermicro qui avaient tout bien sauf le manque d'interfaces SFP. Nous avons décidé d'y installer notre bien-aimé Intel 520DA2 et avons immédiatement fait face au premier problème: les machines sont monobloc, mais il n'y a pas de contremarches. En même temps, pour une raison quelconque, notre corps n'était pas dans les listes de compatibilité, mais il y avait beaucoup de contremarches indigènes.
Sur les conseils de la directrice du développement innovant, Misha Solovyov, nous avons tout connecté avec des colonnes montantes flexibles pour les exploitations minières. Le résultat était un tel "cadavre":
 8. Prototype n ° 1
8. Prototype n ° 1J'ai dû utiliser le fameux ruban électrique bleu à certains endroits, pour que, Dieu m'en garde, fais quoi que ce soit de court. Oui, la ferme collective. Oui, honteux. Mais une telle «configuration» est tout à fait acceptable pour la période de l'expérience.
 9. Vue arrière
9. Vue arrièreCe qui en est ressorti est clairement visible sur la capture d'écran de l'iperf:
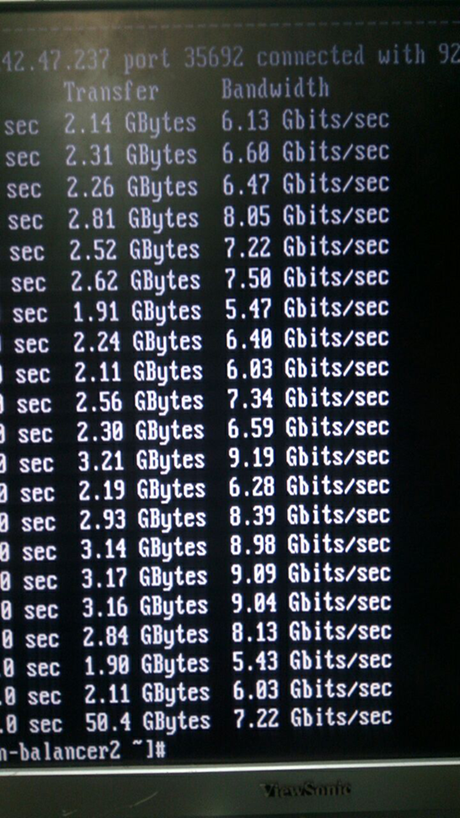 10. En fait, ce n'est pas une capture d'écran :)
10. En fait, ce n'est pas une capture d'écran :)Les métriques sont très intéressantes, non? Nous étions donc tristes. Au début, nous pensions aux puces d'espionnage, nous démontions et redressions tout.
 11. À première vue, il n'y a pas de jetons d'espionnage ici
11. À première vue, il n'y a pas de jetons d'espionnage iciIls ont rappelé le cours de physique: interférences électromagnétiques, signaux haute fréquence, etc ... Bien sûr, poursuivre l'expérience avec une telle quantité et qualité de la "ferme collective" n'avait pas de sens. Nous avons donc finalement démonté le système et remis les serveurs en place.
La deuxième expérience. Citrix Netscaler MPX8005
Dans le processus de retour des serveurs à l'endroit, nous avons trouvé de nouveaux héros: Citrix Netscaler MPX8005. C'est un merveilleux fer de marque, d'ailleurs, presque jamais utilisé. Ils ressemblent à ceci:
 12. La glissière du rack ne tenait pas en longueur, mais nous, visionnaires, avons décidé de la reporter à plus tard
12. La glissière du rack ne tenait pas en longueur, mais nous, visionnaires, avons décidé de la reporter à plus tardÉquipement placé dans un rack, commuté et configuré. Ce sont vraiment d'excellents morceaux de fer «adultes», 2 emplacements SFP pour 10 Go chacun, HA, des algorithmes avancés, il y a même L7. Certes, jusqu'à 5 gigabits sous licence, mais nous avons toujours utilisé L3, mais il n'y a pas de telles limites.
Croise les doigts, test. Il n'y a pas de vitesse. Sur les interfaces - erreurs solides sur les émetteurs-récepteurs inappropriés, vitesse d'environ 5 gigabits, chutes constantes. Ils se souvenaient des élévateurs flexibles, étaient encore tristes. Même là, la vitesse était plus élevée et moins d'erreurs. Nous commençons à comprendre:
show channel LA/1 1) Interface LA/1 (802.3ad Link Aggregate) #10 flags=0x4100c020 <ENABLED, UP, AGGREGATE, UP, HAMON, HEARTBEAT, 802.1q> MTU=9000, native vlan=1, MAC=XXX, uptime 0h03m23s Requested: media NONE, speed AUTO, duplex NONE, fctl NONE, throughput 160000 Link Redundancy Throughput 80000 Actual: throughput 20000 LLDP Mode: NONE RX: Pkts(9388) Bytes(557582) Errs(0) Drops(1225) Stalls(0) TX: Pkts(10514) Bytes(574232) Errs(0) Drops(0) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) bandwidthHigh: 160000 Mbits/sec, bandwidthNormal: 160000 Mbits/sec. LA mode: AUTO > show interface 10/1 1) Interface 10/1 (10G Ethernet, unsupported fiber SFP+, 10 Gbit) #1 flags=0x400c020 <ENABLED, UP, BOUND to LA/1, UP, autoneg, 802.1q> LACP <Active, Long timeout, key 1, priority 32768> MTU=9000, MAC=XXX, uptime 0h05m44s Requested: media AUTO, speed AUTO, duplex AUTO, fctl OFF, throughput 0 Actual: media FIBER, speed 10000, duplex FULL, fctl OFF, throughput 10000 LLDP Mode: TRANSCEIVER, LR Priority: 1024 RX: Pkts(8921) Bytes(517626) Errs(0) Drops(585) Stalls(0) TX: Pkts(9884) Bytes(545408) Errs(0) Drops(3) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) Bandwidth thresholds are not set. > show interface 10/2 1) Interface 10/2 (10G Ethernet, unsupported fiber SFP+, 10 Gbit) #0 flags=0x400c020 <ENABLED, UP, BOUND to LA/1, UP, autoneg, 802.1q> LACP <Active, Long timeout, key 1, priority 32768> MTU=9000, MAC=XXX, uptime 0h05m58s Requested: media AUTO, speed AUTO, duplex AUTO, fctl OFF, throughput 0 Actual: media FIBER, speed 10000, duplex FULL, fctl OFF, throughput 10000 LLDP Mode: TRANSCEIVER, LR Priority: 1024 RX: Pkts(8944) Bytes(530975) Errs(0) Drops(911) Stalls(0) TX: Pkts(10819) Bytes(785347) Errs(0) Drops(3) Stalls(0) NIC: InDisc(0) OutDisc(0) Fctls(0) Stalls(0) Hangs(0) Muted(0) Bandwidth thresholds are not set.
Nous avons utilisé des émetteurs-récepteurs Cisco natifs avec lesquels, en théorie, aucun problème ne devrait survenir. Ils ont même vérifié l'optique et, au cas où, ont changé les émetteurs-récepteurs - la même image. Notre voiture ne marche pas, et c'est tout! Nous regardons de plus près.
"Beaux" émetteurs-récepteurs Cisco:
ix1: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe000-0xe01f mem 0xf7800000-0xf781ffff,0xf7840000-0xf7843fff irq 17 at device 0.1 on pci1 ix1: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CISCO-AVAGO , part number XXX , 10G 0x10 1G 0x00 CT 0x00 *** Unsupported SFP+/SFP type!
Les émetteurs-récepteurs ne sont pas détectés normalement, non pris en charge!
J'ai dû trouver les plus "parents" les plus:
 13. Les émetteurs-récepteurs les plus natifs de l'ouest sauvage
13. Les émetteurs-récepteurs les plus natifs de l'ouest sauvage ix0: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe020-0xe03f mem 0xf7820000-0xf783ffff,0xf7844000-0xf7847fff irq 16 at device 0.0 on pci1 platform: Manufacturer Citrix Inc. platform: NSMPX-8000-10G 4*CPU+6*E1K+2*IX+1*E1K+4*CVM 1620 675320 (28), manufactured at 8/10/2015 platform: serial 4NP602H7H0 platform: sysid 675320 - NSMPX-8000-10G 4*CPU+6*E1K+2*IX+1*E1K+4*CVM 1620 ix0: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CITRIX , part number XXX , 10G 0x10 1G 0x01 CT 0x00 ix0: [ITHREAD] 10/2: Ethernet address: 00:e0:ed:45:39:f8 ix1: <Intel(R) PRO/10GbE PCI-Express Network Driver, Version - 2.7.4> port 0xe000-0xe01f mem 0xf7800000-0xf781ffff,0xf7840000-0xf7843fff irq 17 at device 0.1 on pci1 ix1: ixgbe bus speed = 5.0Gbps and PCIe lane width = 8 SFP+/SFP, vendor CITRIX , part number XXX , 10G 0x10 1G 0x01 CT 0x00
Ces émetteurs-récepteurs ont été déterminés sans aucun problème, mais cela n'a pas sauvé la situation. Firmware mis à jour - même chose. Le support Citrix a décidé de garder le silence avec tact (non, pas à cause du pedigree de l'émetteur-récepteur).
Nous avons pris une profonde inspiration et nous sommes enfouis dans les spécifications matérielles. Il s'est avéré que la réponse pendant tout ce temps était sous nos yeux:
vitesse du bus ixgbe = 5,0 Gbps et largeur de voie PCIe = 8. C'est un problème avec la carte. Elle-même manque de vitesse PCIe. Notre Citrix a les performances maximales de l'emplacement PCI-e pour une carte avec des émetteurs-récepteurs de
5,0 Gbit / s, ce qu'il nous a crié tout ce temps. Comme Citrix sur MPX8015 (c'est exactement la même chose en matériel!) Ils voulaient distribuer 15 gigabits, ce n'est pas clair. Mais nous avons compris pourquoi de tels équilibreurs "cool" se trouvaient tout le temps dans un entrepôt. Ils ne peuvent pas fonctionner correctement avec les liaisons 10G en principe.
La dernière expérience. Nous utilisons le bon fer et le rendons beau
Ici, notre patience s'est terminée avec notre foi en l'humanité, et nous avons dû utiliser la technologie "de rechange" pour obtenir le matériel normal sous la forme du HP ProLiant DL360 G9 à partir des photos ci-dessus. Ils n'ont pas commencé à nous réserver des surprises, ils téléchargent la 10G et ne se plaignent pas. :)
Test de charge
Comme nous n'acceptons pas l'approche hujak-hujak-et-production, et nous savons par expérience qu'un système non testé après assemblage avec une garantie de presque 100% sera inutilisable, nous avons décidé de procéder à des tests de charge. De plus, avec son aide, vous pouvez effectuer certains réglages pour l'avenir.
Pour générer la charge, l'outil habituel a été choisi - Apache Jmetr. À lui seul, c'est assez bon, comme je l'ai
écrit quelques articles en arrière, et c'est l'une des solutions les plus flexibles sur le marché, même si Java aime manger. Pour travailler avec S3, nous avons utilisé un module auto-écrit utilisant le kit AWS SDK, également en Java. Lors des tests, nous avons pu atteindre une vitesse de 12,5 Gbit / s pour l'écriture de fichiers de plus de 250 mégaoctets avec chargement parallèle par blocs de 5 mégaoctets, et pour des fichiers de moins de 5 mégaoctets - traitant environ 3000 requêtes HTTP par seconde. Lors de l'exécution des deux tests en parallèle, il s'est avéré environ 11 Gigabits et 2200 requêtes par seconde. Dans le même temps, il est possible d'améliorer le travail avec une charge mixte et avec de petits objets. Nous avons "enterré" dans le CPU, et le deuxième socket est libre. Sur le générateur de charge, des fichiers de test ont été extraits de la RAM afin d'exclure l'influence sur les résultats du sous-système disque du générateur lui-même. Pour les tests, rappelant l'amour de Java pour la RAM et la nécessité de travailler avec un grand nombre de threads lors du chargement parallèle, nous avons utilisé le serveur HP DL980 g7 comme générateur. Il s'agit d'un serveur de huit unités avec 8 processeurs Intel E7-4870 et 512 Go de RAM à bord.
À l'intérieur de l'équipe, le surnom affectueux Behemoth lui collait.
 14. Notre hippopotame. C'est vrai, quelque chose de similaire?
14. Notre hippopotame. C'est vrai, quelque chose de similaire? 15. Vue arrière. Les câbles effrayants en bas au centre sont une interconnexion du bus de pont interne
15. Vue arrière. Les câbles effrayants en bas au centre sont une interconnexion du bus de pont interne 16. C'est l'un des deux objectifs du serveur. Chacun a 4 processeurs et 16 emplacements de 16 gigaoctets de RAM
16. C'est l'un des deux objectifs du serveur. Chacun a 4 processeurs et 16 emplacements de 16 gigaoctets de RAM 17. Pour utiliser confortablement Htop dans la console d'un tel serveur, vous avez besoin d'un grand moniteur :)
17. Pour utiliser confortablement Htop dans la console d'un tel serveur, vous avez besoin d'un grand moniteur :)En pratique, un test mixte a sensiblement chargé même un serveur aussi puissant.
Pour arriver aux résultats de performance obtenus, nous avons dû transférer le réseau interne du cluster sur des trames jumbo 9k et régler légèrement la pile réseau des équilibreurs et des nœuds de travail (nous utilisons CentOS Linux), ainsi qu'optimiser un certain nombre d'autres paramètres du noyau sur les nœuds de travail:
cat /etc/sysctl.conf … kernel.printk = 3 4 1 7 read_ahead_kb = 1024 write_expire = 250 read_expire = 250 fifo_batch = 128 front_merges = 0 net.core.wmem_default = 16777216 net.core.wmem_max = 16777216 net.core.rmem_default = 16777216 net.core.rmem_max = 16777216 net.core.somaxconn = 5120 net.core.netdev_max_backlog = 50000 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 net.ipv4.tcp_slow_start_after_idle = 0 net.ipv4.tcp_max_syn_backlog = 30000 net.ipv4.tcp_max_tw_buckets = 2000000 fs.file-max = 196608 vm.overcommit_memory = 1 vm.overcommit_ratio = 100 vm.max_map_count = 65536 vm.dirty_ratio = 40 vm.dirty_background_ratio = 5 vm.dirty_expire_centisecs = 100 vm.dirty_writeback_centisecs = 100 net.ipv4.tcp_fin_timeout=10 net.ipv4.tcp_congestion_control=htcp net.ipv4.netfilter.ip_conntrack_max=1048576 net.core.rmem_default=65536 net.core.wmem_default=65536 net.core.rmem_max=16777216 net.core.wmem_max=16777216 net.ipv4.ip_local_port_range=1024 65535
Les principaux paramètres qui ont subi un réglage sont la taille des tampons, le nombre de connexions réseau, le nombre de connexions au port et les connexions surveillées par les pare-feu, ainsi que les délais d'expiration.
Cisco C3750 + LACP = douleurUn autre écueil dans les performances du réseau est l'équilibrage de charge lors de l'utilisation de LACP / LAGp. Malheureusement, les Cisco 3750 ne peuvent pas équilibrer la charge entre les ports, uniquement aux adresses source et de destination. Pour obtenir un équilibrage du trafic correct, j'ai dû suspendre 12 adresses IP sur les interfaces de liaison des nœuds de travail, en "regardant" vers les clients. Conditionnellement, 3 pour chaque lien physique. Avec cette configuration, il était possible de se passer de LACP sur les interfaces "externes" des nœuds de travail, puisque toutes les adresses sont spécifiées dans la configuration Nginx, mais alors si le lien était perdu, nous réduirions automatiquement le poids du nœud dans l'équilibrage. Avec le «dump», le lien LACP vous permet de maintenir une accessibilité totale à toutes les adresses.
bond0.10 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 RX packets:2390824140 errors:0 dropped:0 overruns:0 frame:0 TX packets:947068357 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:18794424755066 (17.0 TiB) TX bytes:246433289523 (229.5 GiB) bond0.10:0 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:1 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:2 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:3 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:4 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:5 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:6 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:7 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:8 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:9 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XXMask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1 bond0.10:10 Link encap:Ethernet HWaddr XXX inet addr:192.168.XX Bcast:192.168.XX Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1
Test fonctionnel
Après avoir terminé le travail sur le référentiel, nous avons rencontré le service flexify.io. Ils aident à faciliter la migration entre différents magasins d'objets. Mais pour devenir partenaire Flexify, vous devez passer des tests sérieux. "Pourquoi pas?" - nous avons pensé. Les tests tiers sont toujours une expérience enrichissante.
La tâche principale des tests est de vérifier le fonctionnement des méthodes du protocole S3 à travers leurs proxys par rapport à diverses configurations, parmi lesquelles il peut y avoir n'importe quel ensemble de compartiments compatibles S3 pris en charge par le fournisseur de services.
Tout d'abord, les méthodes qui fonctionnent avec des objets dans le compartiment sont vérifiées. Notre stockage a été testé en utilisant un large éventail de données de test, le comportement des méthodes a été testé pour des objets de différentes tailles et contenus, pour des clés contenant toutes sortes de combinaisons de caractères Unicode.
Lors de tests négatifs, ils ont essayé de transférer des données invalides dans la mesure du possible. Une attention particulière a été accordée à la sécurité des données dans le processus.
Des méthodes de travail avec des godets ont également été testées, mais principalement dans des scénarios positifs. L'objectif de ces tests était de vérifier que l'utilisation de méthodes via un proxy n'entraîne pas de problèmes graves, par exemple une corruption des données ou des plantages.
L'étendue de la couverture peut être jugée par les tests qui ont été utilisés à la fois par le biais de procurations et directement. La plupart des tests, en particulier ceux qui fonctionnent avec des objets, sont paramétrés et testent un grand nombre d'objets, de plages, etc. différents.
Tests implémentés pour les objetsDemande d'objet GET sans paramètres facultatifs
GET Objet multithread de demande
Demande d'objet GET à un objet chiffré avec les paramètres sse fournis
Demande d'objet GET à un objet chiffré sans paramètres sse fournis
Demande d'objet GET avec une plage qui coupe la plage d'octets du fichier
GET Requête d'objet avec plage hors plage de plage d'octets du fichier
Demande d'objet GET avec un paramètre de plage de suffixe
Demande d'objet GET avec un paramètre de plage de suffixe hors de la plage d'octets du fichier
GET Object request with invalid range parameter
Demande d'objet principal à un objet existant
Demande d'objet principal à un objet récemment supprimé
Demande d'objet principal avec une clé qui n'a jamais existé dans un compartiment
Demande d'objet principal à un objet chiffré avec les paramètres sse fournis
Demande d'objet principal à un objet chiffré sans paramètres sse fournis
Liste des demandes d'objets
Liste des objets v2
Liste des requêtes d'objets avec le paramètre Marker fourni
Liste des objets avec le paramètre Prefix fourni
Lister la demande d'objets avec les paramètres de marqueur et de préfixe fournis
Recevez tous les objets sur le noeud final avec List Objects avec les paramètres Marker et Prefix fournis
Lister la demande d'objets avec le paramètre Delimiter ignoré
Lister la demande d'objets avec le paramètre Marker passé, mais avec le paramètre Delimiter ignoré
Liste des objets avec le préfixe non existant transmis
Lister la demande d'objets avec un marqueur inexistant passé
Téléchargement en plusieurs parties avec la méthode native upload_file ()
Téléchargement en plusieurs parties avec la méthode native upload_fileobj ()
Téléchargement en plusieurs parties avec méthode personnalisée
Arrêt du téléchargement en plusieurs parties avec la méthode abort_multipart_upload ()
Exécution de la méthode abort_multipart_upload () avec uploadId incorrect
Exécution de la méthode abort_multipart_upload () avec une clé et un uploadId incorrects
Téléchargement en plusieurs parties de 2 fichiers avec la même clé simultanément. 2e fichier téléchargé avant le 1er
Téléchargement en plusieurs parties de 2 fichiers avec la même clé simultanément. 1er fichier téléchargé avant le 2ème
Téléchargement en plusieurs parties de 2 fichiers avec des clés différentes simultanément. 1er fichier téléchargé avant le 2ème
Téléchargement en plusieurs parties avec une taille de pièce de 512 Ko
Téléchargement en plusieurs parties avec une taille de pièce supérieure à la taille maximale autorisée
Téléchargement en plusieurs parties d'un fichier avec des pièces de tailles différentes
Répertorier la demande de téléchargement en plusieurs parties
PUT Object ACL request to an object with provided grantee id
GET Object ACL request à un objet avec des autorisations d'accès supplémentaires accordées
Méthode d'étiquetage d'objets PUT
Méthode de marquage d'objet GET
DELETE Object Tagging, méthode
PUT demande d'objet sans paramètres facultatifs
PUT Object demande un multithread
PUT Object demandes avec des paramètres de chiffrement facultatifs passés
PUT Object demandes avec paramètre Body vide passé
GET Object avec la méthode native download_file ()
GET Object avec la méthode native download_fileobj ()
GET Object avec une méthode personnalisée utilisant des plages
GET Object avec préfixe avec la méthode native download_file ()
GET Object avec préfixe avec la méthode native download_fileobj ()
GET Object avec préfixe avec méthode personnalisée utilisant des plages
SUPPRIMER Demande d'objet à un objet existant
SUPPRIMER Demande d'objet à un objet non existant
SUPPRIMER Demande d'objets à un groupe avec des objets existants
Tests réalisés pour le godetMettez le chiffrement du compartiment
GET Bucket Encryption
DELETE Bucket Encryption
PUT Bucket Policy request
GET Bucket Policy request to a bucket with Policy
DELETE Bucket Policy request to a bucket with Policy
GET Bucket Policy request to a bucket with no Policy
DELETE Bucket Policy request to a bucket with no Policy
Mettre le marquage du godet
Obtenir le balisage du compartiment
DELETE Bucket Tagging
Créer une demande de compartiment avec le nom de compartiment existant
Créer une demande de compartiment avec un nom de compartiment unique
Supprimer la demande de compartiment avec le nom de compartiment existant
Supprimer la demande de compartiment avec un nom de compartiment unique
PUT Bucket ACL request to a bucket with provided grantee id
GET Object ACL request à un objet avec des autorisations d'accès supplémentaires accordées
Comme vous pouvez le deviner, il s'agit d'un test assez difficile, mais nous l'avons généralement réussi de manière positive. Certains problèmes sont survenus en raison du manque de prise en charge de l'ESS et des petites écoles avec prise en charge Unicode à l'époque:
Échec du téléchargement avec des clés contenant:
- U + 0000-U + 001F - les 32 premiers caractères de contrôle illisibles. Sur Amazon, par exemple, seul le premier U + 0000 n'est pas versé directement.
- Et aussi U + 18D7C, U + 18DA8, U + 18DB4, U + 18DBA, U + 18DC4, U + 18DCE. Ce sont également des caractères illisibles, mais Amazon les accepte comme clés. Il n'y a eu aucun problème avec tous les autres personnages.
Lors de la lecture du contenu du compartiment, il y a un problème sur la clé 66 675, qui contient le symbole U + FFFE. Il n'est pas possible d'obtenir une liste complète de clés dans un compartiment contenant un objet avec une telle clé.
Sinon, les tests ont réussi, et fin septembre nous sommes apparus dans la liste des fournisseurs disponibles!
Une courte postface et un bonus pour les lecteurs
Plus tôt, j'ai écrit que Cloudian HyperStore, malgré ses nombreux avantages, n'est pratiquement pas couvert dans le segment russophone d'Internet.
Le premier article portait sur les bases du travail avec Cloudian. Nous avons démonté sa structure interne, ses nuances architecturales et lu la traduction de la documentation officielle.
Aujourd'hui, j'ai raconté comment nous avons construit notre propre stockage et quelles nuances et pièges nous avons rencontrés.
Ceux d'entre vous qui veulent toucher avec des stylos ce dont nous parlons 2 articles d'affilée peuvent utiliser le formulaire de rétroaction
sur cette page et découvrir personnellement ce qu'est le sel. En standard, nous donnons 15 Go pendant 2 semaines gratuitement, bien sûr, avec un accès utilisateur. Si vous souhaitez partager vos impressions de travailler avec le référentiel, écrivez-moi en PM. :)
Et pour ceux qui n'ont pas assez de 15 Go pendant 2 semaines, nous avons une
petite quête! Dans les photographies de l'article, nous avons placé trois hippopotames. Les 50 premières personnes qui les trouveront recevront 30 Go pendant 4 semaines. Pour obtenir un test agrandi, écrivez dans les commentaires les numéros des photos où les hippopotames se sont cachés et demandez le lien ci-dessus. N'oubliez pas d'inclure un lien vers votre commentaire dans l'application.
Par tradition, si vous avez des questions, posez-les dans les commentaires.
Je serai ravi d'y répondre.