Les différentes exceptions dans .NET ont leurs propres caractéristiques, et il peut être très utile de les connaître. Comment tromper le CLR? Comment rester en vie lors de l'exécution en interceptant une StackOverflowException? Quelles exceptions il semble impossible de saisir, mais si vous le voulez vraiment, pouvez-vous?

Sous la coupe, la transcription du rapport d'Eugene (
epeshk ) Peshkov de notre conférence
DotNext 2018 Piter , où il a parlé de ces et d'autres caractéristiques des exceptions.
Salut Je m'appelle Eugene. Je travaille pour SKB Kontur et développe un système d'hébergement et déploie des applications pour Windows. L'essentiel est que nous avons de nombreuses équipes de produits qui écrivent leurs propres services et les hébergent chez nous. Nous leur fournissons une solution facile et simple à une variété de tâches d'infrastructure. Par exemple, pour surveiller la consommation des ressources système ou terminer les répliques du service.
Parfois, il s'avère que les applications hébergées sur notre système s'effondrent. Nous avons vu de nombreuses façons comment une application peut se bloquer lors de l'exécution. L'une de ces méthodes consiste à lever une exception inattendue et enchanteresse.
Aujourd'hui, je vais parler des fonctionnalités des exceptions dans .NET. Nous avons rencontré certaines de ces caractéristiques en production, et certaines au cours d'expériences.
Plan
- Comportement des exceptions .NET
- Gestion des exceptions et hacks Windows
Tout ce qui suit est vrai pour Windows. Tous les exemples ont été testés sur la dernière version du framework .NET 4.7.1 complet. Il y aura également quelques références à .NET Core.
Violation d'accès
Cette exception se produit lors d'opérations de mémoire incorrectes. Par exemple, si une application tente d'accéder à une zone mémoire à laquelle elle n'a pas accès. L'exception est de bas niveau et généralement, si cela se produit, un débogage très long sera nécessaire.
Essayons d'obtenir cette exception en utilisant C #. Pour ce faire, nous écrivons l'octet 42 à l'adresse 1000 (nous supposons que 1000 est une adresse assez aléatoire et notre application n'y a probablement pas accès).
try { Marshal.WriteByte((IntPtr) 1000, 42); } catch (AccessViolationException) { ... }
WriteByte fait exactement ce dont nous avons besoin: il écrit un octet à l'adresse donnée. Nous nous attendons à ce que cet appel lève une AccessViolationException. Ce code lèvera en effet cette exception, il pourra le gérer et l'application continuera à fonctionner. Maintenant, changeons un peu le code:
try { var bytes = new byte[] {42}; Marshal.Copy(bytes, 0, (IntPtr) 1000, bytes.Length); } catch (AccessViolationException) { ... }
Si au lieu de WriteByte vous utilisez la méthode Copy et copiez l'octet 42 à l'adresse 1000, puis en utilisant try-catch, AccessViolation ne peut pas être intercepté. Dans le même temps, un message s'affiche sur la console indiquant que l'application a été arrêtée en raison d'une exception AccessViolationException non gérée.
Marshal.Copy(bytes, 0, (IntPtr) 1000, bytes.Length); Marshal.WriteByte((IntPtr) 1000, 42);
Il s'avère que nous avons deux lignes de code, tandis que la première plante toute l'application avec AccessViolation, et la seconde lève une exception traitée du même type. Pour comprendre pourquoi cela se produit, nous verrons comment ces méthodes sont organisées de l'intérieur.
Commençons par la méthode Copy.
static void Copy(...) { Marshal.CopyToNative((object) source, startIndex, destination, length); } [MethodImpl(MethodImplOptions.InternalCall)] static extern void CopyToNative(object source, int startIndex, IntPtr destination, int length);
La seule chose que la méthode Copy fait est d'appeler la méthode CopyToNative, implémentée dans .NET. Si notre application plante toujours et qu'une exception se produit quelque part, cela ne peut se produire qu'à l'intérieur de CopyToNative. D'ici, nous pouvons faire la première observation: si le code .NET appelé le code natif et AccessViolation se sont produits à l'intérieur, le code .NET ne peut pas gérer cette exception pour une raison quelconque.
Nous allons maintenant comprendre pourquoi il était possible de traiter AccessViolation à l'aide de la méthode WriteByte. Regardons le code de cette méthode:
unsafe static void WriteByte(IntPtr ptr, byte val) { try { *(byte*) ptr = val; } catch (NullReferenceException) {
Cette méthode est entièrement implémentée dans le code managé. Il utilise un pointeur C # pour écrire des données à l'adresse souhaitée et intercepte également une exception NullReferenceException. Si le NRE est intercepté, une AccessViolationException est levée. Il est donc nécessaire en raison de la
spécification . Dans ce cas, toutes les exceptions levées par la construction throw sont gérées. Par conséquent, si une exception NullReferenceException se produit pendant l'exécution de code dans WriteByte, nous pouvons intercepter AccessViolation. Un NRE pourrait-il se produire, dans notre cas, lors de l'accès à l'adresse 1000 plutôt qu'à l'adresse zéro?
Nous réécrivons le code à l'aide de pointeurs C # directement, et voyons que lors de l'accès à une adresse non nulle, une NullReferenceException est en fait levée:
*(byte*) 1000 = 42;
Pour comprendre pourquoi cela se produit, nous devons nous rappeler comment fonctionne la mémoire du processus. Dans la mémoire de processus, toutes les adresses sont virtuelles. Cela signifie que l'application dispose d'un grand espace d'adressage et que seules certaines pages de celle-ci sont affichées dans la mémoire physique réelle. Mais il y a une particularité: les 64 premiers Ko d'adresses ne sont jamais mappés à la mémoire physique et ne sont pas donnés à l'application. Rantime .NET le sait et l'utilise. Si AccessViolation s'est produite dans le code managé, le runtime vérifie à quelle adresse en mémoire l'accès a été généré et génère une exception appropriée. Pour les adresses de 0 à 2 ^ 16 - NullReference, pour tous les autres - AccessViolation.
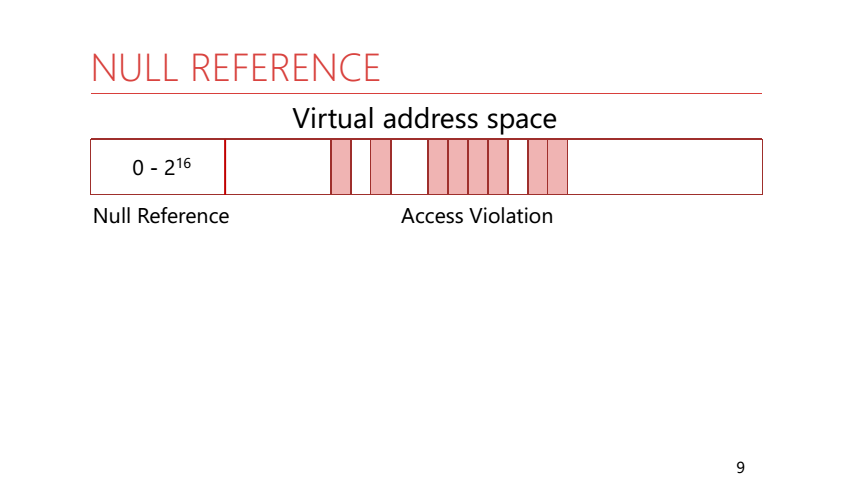
Voyons pourquoi la NullReference est levée non seulement lors de l'accès à l'adresse zéro. Imaginez que vous accédez à un champ d'un objet d'un type de référence, et la référence à cet objet est nulle:

Dans cette situation, nous nous attendons à obtenir une exception NullReferenceException. L'accès au champ de l'objet se fait à un décalage par rapport à l'adresse de cet objet. Il s'avère que nous allons nous tourner vers une adresse suffisamment proche de zéro (rappelez-vous que le lien vers notre objet d'origine est zéro). Avec ce comportement d'exécution, nous obtenons l'exception attendue sans vérification supplémentaire de l'adresse de l'objet lui-même.
Mais que se passe-t-il si nous nous tournons vers le champ d'un objet et que cet objet lui-même occupe plus de 64 Ko?

Pouvons-nous obtenir AccessViolation dans ce cas? Faisons une expérience. Créons un très grand objet et nous nous référons à ses champs. Un champ au début de l'objet, le second à la fin:

Les deux méthodes lèveront une exception NullReferenceException. Aucune exception AccessViolationException ne se produira.
Regardons les instructions qui seront générées pour ces méthodes. Dans le deuxième cas, le compilateur JIT a ajouté une instruction cmp supplémentaire qui accède à l'adresse de l'objet lui-même, appelant ainsi AccessViolation avec une adresse nulle, qui sera convertie par le runtime en NullReferenceException.
Il convient de noter que pour cette expérience, il ne suffit pas d'utiliser un tableau comme un grand objet. Pourquoi? Laissez cette question au lecteur, écrivez des idées dans les commentaires :)
Résumons les expériences avec AccessViolation.

AccessViolationException se comporte différemment selon l'endroit où l'exception s'est produite (en code managé ou en natif). De plus, si une exception s'est produite dans le code managé, l'adresse de l'objet sera vérifiée.
La question est: pouvons-nous gérer une AccessViolationException qui s'est produite dans du code natif ou dans du code managé, mais qui n'a pas été convertie en NullReference et qui n'a pas été levée à l'aide de throw? Il s'agit parfois d'une fonctionnalité utile, en particulier lorsque vous travaillez avec du code non sécurisé. La réponse à cette question dépend de la version de .NET.

Dans .NET 1.0, il n'y avait aucune exception AccessViolationException. Tous les liens ont été considérés comme valides ou nuls. Au moment de .NET 2.0, il est devenu clair que sans travail direct avec la mémoire - aucun moyen, et AccessViolation est apparu, alors qu'il était traitable. Dans la version 4.0 et supérieure, il restait toujours réalisable, mais le traitement n'est pas si simple. Pour intercepter cette exception, vous devez maintenant marquer la méthode dans laquelle se trouve le bloc catch avec l'attribut HandleProcessCorruptedStateException. Apparemment, les développeurs l'ont fait parce qu'ils pensaient que AccessViolationException n'était pas l'exception qui devrait être interceptée dans une application standard.
De plus, pour des raisons de compatibilité descendante, il est possible d'utiliser les paramètres d'exécution:
- legacyNullReferenceExceptionPolicy renvoie un comportement .NET 1.0 - tous les AV se transforment en NRE
- legacyCorruptedStateExceptionsPolicy renvoie un comportement .NET 2.0 - tous les AV sont interceptés
Dans .NET, Core AccessViolation n'est pas du tout géré.
Dans notre production, il y avait une telle situation:

Une application construite sous .NET 4.7.1 a utilisé une bibliothèque de code partagée construite sous .NET 3.5. Il y avait un assistant dans cette bibliothèque pour exécuter une action périodique:
while (isRunning) { try { action(); } catch (Exception e) { log.Error(e); } WaitForNextExecution(... ); }
Nous avons transmis l'action de notre application à cet assistant. Il se trouve qu'il s'est écrasé avec AccessViolation. En conséquence, notre application a constamment connecté AccessViolation, au lieu de se bloquer parce que le code dans la bibliothèque sous 3.5 pourrait l'attraper. Il convient de noter que l'interception ne dépend pas de la version du runtime sur lequel l'application s'exécute, mais du TargetFramework, sous lequel l'application a été créée, et de ses dépendances.
Pour résumer. Le traitement AccessVilolation dépend de son origine - en code natif ou géré - ainsi que des paramètres TargetFramework et d'exécution.
Abandon du fil
Parfois, dans le code, vous devez arrêter l'exécution de l'un des threads. Pour ce faire, vous pouvez utiliser le thread.Abort ();
var thread = new Thread(() => { try { ... } catch (ThreadAbortException e) { ... Thread.ResetAbort(); } }); ... thread.Abort();
Lorsque la méthode Abort est appelée dans un thread arrêté, une ThreadAbortException est levée. Analysons ses caractéristiques. Par exemple, un code comme celui-ci:
var thread = new Thread(() => { try { … } catch (ThreadAbortException e) { … } }); ... thread.Abort();
Absolument équivalent à ceci:
var thread = new Thread(() => { try { ... } catch (ThreadAbortException e) { ... throw; } }); ... thread.Abort();
Si vous devez toujours traiter ThreadAbort et effectuer d'autres actions dans le thread arrêté, vous pouvez utiliser la méthode Thread.ResetAbort (); Il arrête le processus d'arrêt du flux et l'exception cesse de lancer plus haut dans la pile. Il est important de comprendre que la méthode thread.Abort () elle-même ne garantit rien - le code dans le thread arrêté peut l'empêcher de s'arrêter.
Une autre caractéristique de thread.Abort () est qu'il ne pourra pas interrompre le code s'il est dans le catch et enfin les blocs.
Dans le code du framework, vous pouvez souvent trouver des méthodes où le bloc try est vide et toute la logique est enfin à l'intérieur. Cela est fait juste pour empêcher ce code d'être levé par une ThreadAbortException.
En outre, un appel à la méthode thread.Abort () attend qu'une exception ThreadAbortException soit levée. Combinez ces deux faits et obtenez que la méthode thread.Abort () puisse bloquer le thread appelant.
var thread = new Thread(() => { try { } catch { }
En réalité, cela peut être rencontré lors de l'utilisation de l'utilisation. Elle est déployée dans try / finally, à l'intérieur de la méthode finalement, la méthode Dispose est appelée. Il peut être arbitrairement complexe, contenir des gestionnaires d'événements, utiliser des verrous. Et si thread.Abort a été appelé au moment de l'exécution, Dispose - thread.Abort () l'attendra. Nous obtenons donc un verrou presque à partir de zéro.
Dans .NET Core, la méthode thread.Abort () lève une exception PlatformNotSupportedException. Et je pense que c'est très bien, car cela me motive à utiliser non pas thread.Abort (), mais des méthodes non invasives pour arrêter l'exécution de code, par exemple en utilisant le CancellationToken.
HORS MÉMOIRE
Cette exception peut être obtenue si la mémoire de la machine est inférieure à celle requise. Ou quand nous avons rencontré les limites d'un processus 32 bits. Mais vous pouvez l'obtenir même si l'ordinateur a beaucoup de mémoire libre et que le processus est de 64 bits.
var arr4gb = new int[int.MaxValue/2];
Le code ci-dessus lancera OutOfMemory. Le fait est que, par défaut, les objets supérieurs à 2 Go ne sont pas autorisés. Cela peut être résolu en définissant gcAllowVeryLargeObjects dans App.config. Dans ce cas, une baie de 4 Go est créée.
Essayons maintenant de créer un tableau encore plus.
var largeArr = new int[int.MaxValue];
Maintenant, même gcAllowVeryLargeObjects n'aidera pas. Cela est dû au fait que .NET a une
limite sur l'index maximum dans un tableau . Cette restriction est inférieure à int.MaxValue.
Index de tableau max:
- tableaux d'octets - 0x7FFFFFC7
- autres tableaux - 0X7F E FFFFF
Dans ce cas, une OutOfMemoryException se produira, bien qu'en fait nous ayons rencontré une restriction de type de données, pas un manque de mémoire.
Parfois, OutOfMemory est explicitement jeté par le code managé à l'intérieur du framework .NET:

Il s'agit d'une implémentation de la méthode string.Concat. Si la longueur de la chaîne de résultat est supérieure à int.MaxValue, une OutOfMemoryException est immédiatement levée.
Passons à la situation où OutOfMemory apparaît dans le cas où la mémoire est réellement épuisée.
LimitMemory(64.Mb()); try { while (true) list.Add(new byte[size]); } catch (OutOfMemoryException e) { Console.WriteLine(e); }
Tout d'abord, nous limitons la mémoire de notre processus à 64 Mo. Ensuite, à l'intérieur de la boucle, sélectionnez de nouveaux tableaux d'octets, enregistrez-les sur une feuille afin que le GC ne les collecte pas et essayez d'attraper OutOfMemory.
Dans ce cas, tout peut arriver:
- Exception gérée
- Le processus va tomber
- Allons en prise, mais l'exception se bloque à nouveau
- Entrons dans la capture, mais StackOverflow plantera
Dans ce cas, le programme sera totalement non déterministe. Analysons toutes les options:
- Une exception peut être gérée. Dans .NET, rien ne vous empêche de gérer une OutOfMemoryException.
- Le processus peut tomber. N'oubliez pas que nous avons une application gérée. Cela signifie qu'à l'intérieur, il est exécuté non seulement notre code, mais aussi le code d'exécution. Par exemple, GC. Ainsi, une situation peut se produire lorsque le runtime veut allouer de la mémoire pour lui-même, mais ne peut pas le faire, alors nous ne pourrons pas intercepter l'exception.
- Entrons dans le piège, mais l'exception se bloque à nouveau. À l'intérieur de catch, nous faisons également le travail où nous avons besoin de mémoire (nous imprimons une exception sur la console), ce qui peut provoquer une nouvelle exception.
- Entrons dans la capture, mais StackOverflow plantera. StackOverflow lui-même se produit lorsque la méthode WriteLine est appelée, mais il n'y a pas de débordement de pile ici, mais une situation différente se produit. Analysons-le plus en détail.
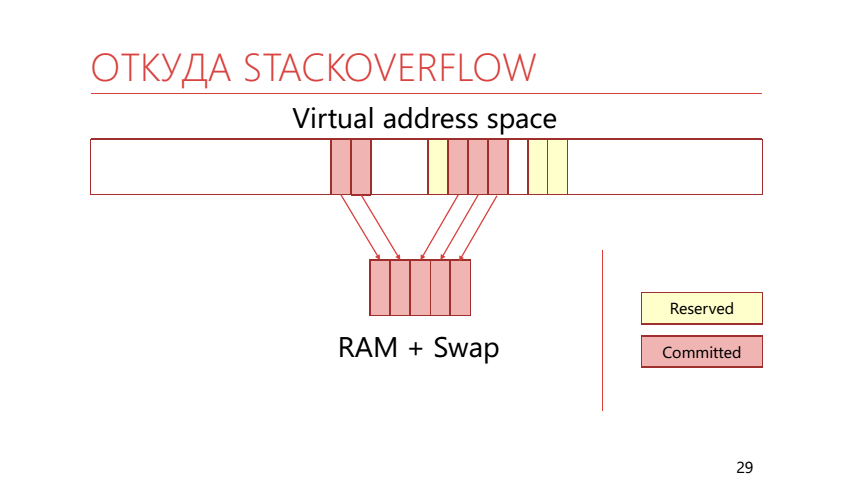
Dans la mémoire virtuelle, les pages peuvent non seulement être mappées à la mémoire physique, mais peuvent également être réservées. Si la page est réservée, l'application a alors indiqué qu'elle allait l'utiliser. Si la page est déjà mappée à la mémoire réelle ou à l'échange, elle est alors appelée «validée» (validée). La pile utilise cette capacité pour diviser la mémoire en réservée et validée. Cela ressemble à ceci:

Il s'avère que nous appelons la méthode WriteLine, qui prend une certaine place sur la pile. Il s'avère que toute la mémoire validée est déjà terminée, ce qui signifie que le système d'exploitation devrait à ce moment prendre une autre page réservée sur la pile et la mapper à la mémoire physique réelle, qui est déjà remplie de tableaux d'octets. Cela conduit à l'exception de StackOverflow.
Le code suivant vous permettra de valider immédiatement toute la mémoire dans la pile au début du flux.
new Thread(() => F(), 4*1024*1024).Start();
Vous pouvez également utiliser le paramètre d'
exécution disableCommitThreadStack. Il doit être désactivé pour que la pile de threads soit validée à l'avance. Il est à noter que le comportement par défaut décrit dans la documentation et observé en réalité est différent.

Débordement de pile
Examinons de plus près StackOverflowException. Regardons deux exemples de code. Dans l'un d'eux, nous exécutons une récursion infinie, ce qui conduit à un débordement de pile, dans le second, nous lançons simplement cette exception avec throw.
try { InfiniteRecursion(); } catch (Exception) { ... }
try { throw new StackOverflowException(); } catch (Exception) { ... }
Puisque toutes les exceptions levées avec throw sont gérées, dans le deuxième cas, nous intercepterons l'exception. Et avec le premier cas, tout est plus intéressant. Tournez-vous vers
MSDN :
"Vous ne pouvez pas intercepter les exceptions de dépassement de pile, car le code de gestion des exceptions peut nécessiter la pile."
MSDN
Il indique ici que nous ne pourrons pas intercepter une StackOverflowException, car l'interception elle-même peut nécessiter un espace de pile supplémentaire qui est déjà terminé.
Afin de nous protéger contre cette exception, nous pouvons procéder comme suit. Tout d'abord, vous pouvez limiter la profondeur de la récursivité. Deuxièmement, vous pouvez utiliser les méthodes de la classe RuntimeHelpers:
RuntimeHelpers.EnsureSufficientExecutionStack ();
- "Garantit que l'espace de pile restant est suffisamment grand pour exécuter la fonction .NET Framework moyenne." - MSDN
- InsufficientExecutionStackException
- 512 Ko - x86, AnyCPU, 2 Mo - x64 (moitié de la taille de la pile)
- 64/128 Ko - .NET Core
- Vérifier uniquement l'espace d'adressage de la pile
La documentation de cette méthode indique qu'elle vérifie qu'il y a suffisamment d'espace sur la pile pour exécuter la fonction .NET
moyenne . Mais quelle est la fonction
moyenne ? En fait, dans le .NET Framework, cette méthode vérifie qu'au moins la moitié de sa taille est libre sur la pile. Dans .NET Core, il vérifie la disponibilité de 64 Ko.
Un analogue est également apparu dans .NET Core: RuntimeHelpers.TryEnsureSufficientExecutionStack () qui renvoie un booléen, plutôt que de lever une exception.
C # 7.2 a introduit la possibilité d'utiliser Span et stackallock ensemble sans utiliser de code dangereux. Peut-être à cause de cela, stackalloc sera utilisé plus souvent dans le code et il sera utile d'avoir un moyen de se protéger de StackOverflow lors de son utilisation, en choisissant où allouer de la mémoire. En tant que telle méthode, une méthode est proposée
qui vérifie la possibilité d'allocation sur la pile et la construction
trystackalloc .
Span<byte> span; if (CanAllocateOnStack(size)) span = stackalloc byte[size]; else span = new byte[size];
Retour à la documentation de StackOverflow sur MSDN
Au lieu de cela, lorsqu'un débordement de pile se produit dans une application normale , le Common Language Runtime (CLR) met fin au processus. »
MSDN
S'il y a une application «normale» qui tombe pendant StackOverflow, alors il y a des applications non normales qui ne tombent pas? Pour répondre à cette question, vous devrez descendre d'un niveau du niveau de l'application gérée au niveau CLR.

"Une application qui héberge le CLR peut modifier le comportement par défaut et spécifier que le CLR décharge le domaine d'application où l'exception se produit, mais laisse le processus se poursuivre." - MSDN
StackOverflowException -> AppDomainUnloadedException
Une application qui héberge le CLR peut redéfinir le comportement du débordement de pile afin qu'au lieu de terminer l'intégralité du processus, le domaine d'application soit déchargé, dans le flux duquel ce débordement s'est produit. Nous pouvons donc transformer une StackOverflowException en AppDomainUnloadedException.
Lorsqu'une application gérée est lancée, le runtime .NET démarre automatiquement. Mais vous pouvez aller dans l'autre sens. Par exemple, écrivez une application non managée (en C ++ ou dans un autre langage) qui utilisera une API spéciale afin d'augmenter le CLR et de lancer notre application. Une application qui exécute le CLR en interne sera appelée hôte CLR. En l'écrivant, nous pouvons configurer beaucoup de choses en runtime. Par exemple, remplacez le gestionnaire de mémoire et le gestionnaire de threads. En production, nous utilisons l'hôte CLR pour éviter d'échanger des pages de mémoire.
Le code suivant configure l'hôte CLR afin que AppDomain (C ++) soit déchargé pendant StackOverflow:
ICLRPolicyManager *policyMgr; pCLRControl->GetCLRManager(IID_ICLRPolicyManager, (void**) (&policyMgr)); policyMgr->SetActionOnFailure(FAIL_StackOverflow, eRudeUnloadAppDomain);
Est-ce un bon moyen d'échapper à StackOverflow? Probablement pas très. Tout d'abord, nous avons dû écrire du code C ++, ce que nous ne voudrions pas faire. Deuxièmement, nous devons changer notre code C # afin que la fonction qui peut lever une StackOverflowException soit exécutée dans un AppDomain distinct et dans un thread séparé. Notre code se transformera immédiatement en de telles nouilles:
try { var appDomain = AppDomain.CreateDomain("..."); appDomain.DoCallBack(() => { var thread = new Thread(() => InfiniteRecursion()); thread.Start(); thread.Join(); }); AppDomain.Unload(appDomain); } catch (AppDomainUnloadedException) { }
Afin d'appeler la méthode InfiniteRecursion, nous avons écrit un tas de lignes. Troisièmement, nous avons commencé à utiliser AppDomain. Et cela garantit presque un tas de nouveaux problèmes. Y compris avec des exceptions. Prenons un exemple:
public class CustomException : Exception {} var appDomain = AppDomain.CreateDomain( "..."); appDomain.DoCallBack(() => throw new CustomException()); System.Runtime.Serialization.SerializationException: Type 'CustomException' is not marked as serializable. at System.AppDomain.DoCallBack(CrossAppDomainDelegate callBackDelegate)
Étant donné que notre exception n'est pas marquée comme sérialisable, notre code tombera avec une exception SerializationException. Et pour résoudre ce problème, il ne nous suffit pas de marquer notre exception avec l'attribut Serializable, nous devons toujours implémenter un constructeur supplémentaire pour la sérialisation.
[Serializable] public class CustomException : Exception { public CustomException(){} public CustomException(SerializationInfo info, StreamingContext ctx) : base(info, context){} } var appDomain = AppDomain.CreateDomain("..."); appDomain.DoCallBack(() => throw new CustomException());
Tout cela n'est pas très beau, alors nous allons plus loin - au niveau du système d'exploitation et des hacks, qui ne devraient pas être utilisés en production.
Seh / veh

Notez que tandis que les exceptions gérées volaient entre Managed et le CLR, les exceptions SEH volent entre le CLR et Windows.
SEH - Gestion structurée des exceptions
- Moteur de gestion des exceptions Windows
- Gestion uniforme des exceptions logicielles et matérielles
- Exceptions C # implémentées au-dessus de SEH
SEH est un mécanisme de gestion des exceptions dans Windows, il vous permet de gérer de manière uniforme toutes les exceptions provenant, par exemple, du niveau du processeur ou associées à la logique de l'application elle-même.
Rantime .NET connaît les exceptions SEH et peut les convertir en exceptions gérées:
- EXCEPTION_STACK_OVERFLOW -> Crash
- EXCEPTION_ACCESS_VIOLATION -> AccessViolationException
- EXCEPTION_ACCESS_VIOLATION -> NullReferenceException
- EXCEPTION_INT_DIVIDE_BY_ZERO -> DivideByZeroException
- Exceptions SEH inconnues -> SEHException
Nous pouvons interagir avec SEH via WinApi.
[DllImport("kernel32.dll")] static extern void RaiseException(uint dwExceptionCode, uint dwExceptionFlags, uint nNumberOfArguments,IntPtr lpArguments);
En fait, la construction throw fonctionne également via SEH. throw -> RaiseException(0xe0434f4d, ...)
Il convient de noter ici que le code d'exception CLR est toujours le même, donc quel que soit le type d'exception que nous lançons, il sera toujours traité.VEH est une gestion d'exceptions vectorielles, une extension de SEH, mais fonctionnant au niveau du processus, et non au niveau d'un seul thread. Si SEH est sémantiquement similaire à try-catch, alors VEH est sémantiquement similaire à un gestionnaire d'interruption. Nous définissons simplement notre gestionnaire et pouvons recevoir des informations sur toutes les exceptions qui se produisent dans notre processus. Une caractéristique intéressante de VEH est qu'elle vous permet de modifier l'exception SEH avant qu'elle ne parvienne au gestionnaire. Nous pouvons mettre notre propre gestionnaire vectoriel entre le système d'exploitation et le runtime, qui gérera les exceptions SEH et, lorsqu'il rencontrera EXCEPTION_STACK_OVERFLOW, le changera afin que le runtime .NET ne plante pas le processus.Vous pouvez interagir avec VEH via WinApi:
Nous pouvons mettre notre propre gestionnaire vectoriel entre le système d'exploitation et le runtime, qui gérera les exceptions SEH et, lorsqu'il rencontrera EXCEPTION_STACK_OVERFLOW, le changera afin que le runtime .NET ne plante pas le processus.Vous pouvez interagir avec VEH via WinApi: [DllImport("kernel32.dll", SetLastError = true)] static extern IntPtr AddVectoredExceptionHandler(IntPtr FirstHandler, VECTORED_EXCEPTION_HANDLER VectoredHandler); delegate VEH PVECTORED_EXCEPTION_HANDLER(ref EXCEPTION_POINTERS exceptionPointers); public enum VEH : long { EXCEPTION_CONTINUE_SEARCH = 0, EXCEPTION_EXECUTE_HANDLER = 1, EXCEPTION_CONTINUE_EXECUTION = -1 } delegate VEH PVECTORED_EXCEPTION_HANDLER(ref EXCEPTION_POINTERS exceptionPointers); [StructLayout(LayoutKind.Sequential)] unsafe struct EXCEPTION_POINTERS { public EXCEPTION_RECORD* ExceptionRecord; public IntPtr Context; } delegate VEH PVECTORED_EXCEPTION_HANDLER(ref EXCEPTION_POINTERS exceptionPointers); [StructLayout(LayoutKind.Sequential)] unsafe struct EXCEPTION_RECORD { public uint ExceptionCode; ... }
Le contexte contient des informations sur l'état de tous les registres de processeur au moment de l'exception. Nous serons intéressés par EXCEPTION_RECORD et le champ ExceptionCode qu'il contient. Nous pouvons le remplacer par notre propre code d'exception, dont le CLR ne sait rien. Le gestionnaire de vecteurs ressemble à ceci: static unsafe VEH Handler(ref EXCEPTION_POINTERS e) { if (e.ExceptionRecord == null) return VEH. EXCEPTION_CONTINUE_SEARCH; var record = e. ExceptionRecord; if (record->ExceptionCode != ExceptionStackOverflow) return VEH. EXCEPTION_CONTINUE_SEARCH; record->ExceptionCode = 0x01234567; return VEH. EXCEPTION_EXECUTE_HANDLER; }
Nous allons maintenant créer un wrapper qui installe un gestionnaire vectoriel sous la forme de la méthode HandleSO, qui accepte un délégué qui pourrait potentiellement tomber d'une StackOverflowException (pour plus de clarté, le code ne gère pas les erreurs de fonction WinApi et supprime le gestionnaire vectoriel). HandleSO(() => InfiniteRecursion()) ; static T HandleSO<T>(Func<T> action) { Kernel32. AddVectoredExceptionHandler(IntPtr.Zero, Handler); Kernel32.SetThreadStackGuarantee(ref size); try { return action(); } catch (Exception e) when ((uint) Marshal. GetExceptionCode() == 0x01234567) {} return default(T); } HandleSO(() => InfiniteRecursion());
À l'intérieur, la méthode SetThreadStackGuarantee est également utilisée. Cette méthode réserve un espace de pile pour le traitement StackOverflow.De cette façon, nous pouvons survivre à l'invocation d'une méthode à récursion infinie. Notre flux continuera de fonctionner comme si rien ne s'était passé, comme si aucun débordement ne s'était produit.Mais que se passe-t-il si vous appelez HandleSO deux fois dans le même thread? HandleSO(() => InfiniteRecursion()); HandleSO(() => InfiniteRecursion());
Et il y aura une exception AccessViolationException. Retour au périphérique de pile. Le système d'exploitation peut détecter les débordements de pile. Tout en haut de la pile se trouve une page spéciale marquée du drapeau de page Garde. Lors du premier accès à cette page, une autre exception se produira - STATUS_GUARD_PAGE_VIOLATION, et l'indicateur de page de garde sera supprimé de la page. Si vous interceptez simplement ce débordement, cette page ne sera plus sur la pile - au prochain débordement, le système d'exploitation ne pourra pas le comprendre et le pointeur de pile ira au-delà de la mémoire allouée à la pile. Par conséquent, une exception AccessViolationException se produira. Vous devez donc restaurer les indicateurs de page après le traitement de StackOverflow - la façon la plus simple de le faire est d'utiliser la méthode _resetstkoflw de la bibliothèque d'exécution C (msvcrt.dll).
Le système d'exploitation peut détecter les débordements de pile. Tout en haut de la pile se trouve une page spéciale marquée du drapeau de page Garde. Lors du premier accès à cette page, une autre exception se produira - STATUS_GUARD_PAGE_VIOLATION, et l'indicateur de page de garde sera supprimé de la page. Si vous interceptez simplement ce débordement, cette page ne sera plus sur la pile - au prochain débordement, le système d'exploitation ne pourra pas le comprendre et le pointeur de pile ira au-delà de la mémoire allouée à la pile. Par conséquent, une exception AccessViolationException se produira. Vous devez donc restaurer les indicateurs de page après le traitement de StackOverflow - la façon la plus simple de le faire est d'utiliser la méthode _resetstkoflw de la bibliothèque d'exécution C (msvcrt.dll). [DllImport("msvcrt.dll")] static extern int _resetstkoflw();
De la même manière, vous pouvez intercepter une AccessViolationException dans .NET Core sous Windows, ce qui provoque le blocage du processus. Dans ce cas, vous devez prendre en compte l'ordre dans lequel les gestionnaires vectoriels sont appelés et définir votre gestionnaire au début de la chaîne, car .NET Core utilise également VEH lors du traitement d'AccessViolation. Le premier paramètre de la fonction AddVectoredExceptionHandler est responsable de l'ordre dans lequel les gestionnaires sont appelés: Kernel32.AddVectoredExceptionHandler(FirstHandler: (IntPtr) 1, handler);
Après avoir étudié des questions pratiques, nous résumons les résultats généraux:- Les exceptions ne sont pas aussi simples qu'elles le paraissent;
- Toutes les exceptions ne sont pas gérées de la même manière;
- La gestion des exceptions se produit à différents niveaux d'abstraction;
- Vous pouvez intervenir dans le processus de gestion des exceptions et faire fonctionner le runtime .NET différemment de celui initialement prévu.
Les références
→ Référentiel avec des exemples du rapport→ Dotnext 2016 Moscou - Adam Sitnik - Exceptions exceptionnelles dans .NET→ DotNetBook: Exceptions→ .NET Inside Out Partie 8 - Gérer l'exception de dépassement de pile en C # avec VEH est une autre façon d'intercepter StackOverflow.Les 22 et 23 novembre, Eugene prononcera une allocution à DotNext 2018 Moscou avec un rapport "System Metrics: Collecting Pitfalls" . Jeffrey Richter, Greg Young, Pavel Yosifovich et d'autres conférenciers tout aussi intéressants viendront à Moscou. Les sujets des rapports peuvent être consultés ici et acheter des billets ici . Rejoignez-nous maintenant!