Bonjour à tous! Dans le cadre de notre cours de
développeur Python, nous avons organisé une autre leçon ouverte sur le sujet «Comment ne pas écrire en Python». La leçon a été
donnée par l'enseignant et créateur du cours,
Stanislav Stupnikov , qui possède une vaste expérience en développement industriel et scientifique. Les antipatterns de la programmation, des mauvaises pratiques et d'autres maux, que vous devez connaître et qui devraient être évités lors de l'écriture de code, ont été examinés.
Voir la vidéo et le résumé pour plus de détails. Attention: certains exemples de code ne sont pas recommandés pour être exécutés sur votre ordinateur!
Pendant la leçon ouverte, l'enseignant a montré des diapositives générées avec le cahier Jupyter.
Commençons donc!
Alors pourquoi ne pas écrire en Python?
Pour faciliter la soumission du matériel, une liste de techniques a été préparée et ne devrait pas être utilisée dans le processus de programmation. Chaque exemple était accompagné d'un exemple de code clair (disponible pour une visualisation gratuite en vidéo). Nous décrivons brièvement les principaux antipatterns:
- Modèle de couches. Il s'agissait du soi-disant motif de «couches», ce qui signifie généralement un essai trop large, sauf. Par exemple, vous appelez une fonction qui est un wrapper pour quelque chose, par exemple, elle encapsule une bibliothèque client pour une base de données. Dans un bon cas (le système est petit), tout ira bien dans 99% des cas, mais si le système est grand, alors les probabilités d'un problème ne sont pas multipliées de la meilleure façon. En conséquence, quelque chose tombe ou se brise constamment.
- Antiglobalisme. Tout le monde sait que les variables globales sont inefficaces, sauf dans certains cas exceptionnels. Il est préférable de tout transmettre sous forme d'attributs à des fonctions, etc., etc., pour obtenir les résultats souhaités. Cependant, certains proposent une «excellente idée» - utiliser des objets mutables. Il consiste à transmettre non pas des variables globales, mais des objets mutables en fonctions, puis de les modifier à l'intérieur et de ne rien renvoyer. C'est tellement cool!) En fait, un morceau d'un modèle de programmation du langage C, transféré dans le monde Python.
- Escalier vers le ciel. Comme vous l'avez peut-être deviné, il s'agit d'un «escalier vers le ciel». Ce problème est mieux caractérisé par une image simple:
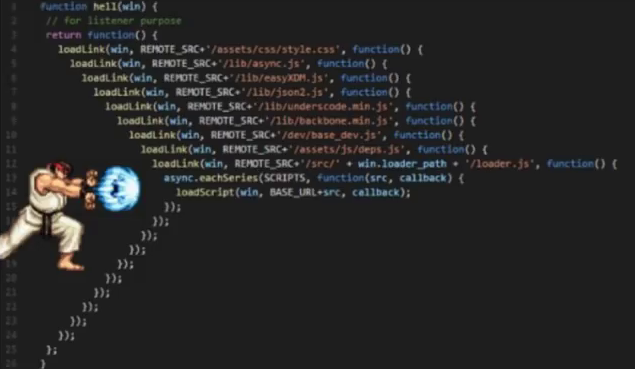
- Javatar. Les erreurs de ce plan sont souvent commises par les programmeurs qui, pour une raison ou une autre, sont passés de Java à Python. Naturellement, ils viennent avec leur propre charte, donc ils violent en masse les règles de développement de Python. C'est l'apparition de l'indentation insensée, et de CamelCase, et le désir de créer plus de classes ... En conséquence, la structure du code devient plus compliquée. Lorsqu'un script d'une taille de 300 lignes pourrait être supprimé, nous voyons 10 à 20 fichiers.
- Suringénierie. Très souvent, la deuxième itération d'un projet ne se termine jamais ou est implémentée de manière trop compliquée. Cela se produit si vous souhaitez réécrire un code existant mais imparfait, ce qui le rend idéal. En même temps, vous oubliez que le meilleur est l'ennemi du bien. En conséquence, le programmeur tombe dans le piège standard de la réingénierie, lorsque la mise en œuvre devient plus coûteuse, lourde et encombrante que nécessaire pour résoudre les tâches. Et en fait: les berlines familiales devraient-elles atteindre des vitesses allant jusqu'à 350 km / h, et les smartphones, dont la mode change chaque année, devraient-ils fonctionner pendant 100 ans?
- Oneliner Un autre problème urgent est la «ligne unique». Il s'agit de programmeurs qui essaient avec un zèle enviable de tout mettre sur une seule ligne, cinq étages de publicités)). En raison de la complexité excessive du code et des particularités de la mise en œuvre des expressions régulières de la machine en Python, ces scripts «collent» parfois à l'analyse, vous devez donc utiliser un module spécial pour résoudre le problème.
- Copie sur lecture. Ce n'est pas tant une erreur qu'une caractéristique de la programmation Python. Beaucoup connaissent l’approche Copie sur écriture. Son idée est que lors de la lecture d'une zone de données, une copie partagée est utilisée, et lorsqu'une modification est effectuée, une nouvelle copie est créée, c'est-à-dire que nous parlons d'optimiser les processus de performance. Si nous parlons de Python, dans certains cas, nous ne nous contentons pas de lire un tableau d'éléments, mais nous faisons référence à toutes les structures sous-jacentes qui sont en mémoire, c'est-à-dire que nous «réécrivons» la mémoire en la modifiant. Ainsi, au lieu de Copy-On-Write, nous obtenons Copy-on-Read lorsque nous semblons lire la mémoire, mais en fait, nous devons copier ces informations de l'espace parent vers nous en tant que processus enfant, ce qui est triste, car l'approche l'optimisation ne fonctionne pas et la consommation augmente.
- Il n'y a pas de fourchette. Fork - clonage l'émergence d'un nouveau processus. Le problème est lié aux spécificités du travail avec les systèmes Unix et à la non-évidence de certaines structures de données qui sont cachées dans l'implémentation. Un processus «bifurqué» est un processus qui démarre au moment où le thread a capturé le journal dans la file d'attente afin d'y mettre quelque chose. Autrement dit, le nouveau processus qui a vu le jour veut également écrire quelque chose, mais pour cela, il doit récupérer le journal de cette file d'attente lui-même, mais il ne peut pas le faire, car le journal est déjà capturé. En conséquence, nous obtenons un verrou. Tout cela confirme une fois de plus que cela ne vaut pas la peine d'être programmé, de ne pas connaître les caractéristiques de la mise en œuvre de l'environnement dans lequel vous travaillez et les outils que vous utilisez.
Il y avait encore beaucoup de choses intéressantes, alors mieux vaut regarder la vidéo, car le récit est encore court.
Comme toujours, nous attendons des questions, des commentaires et des suggestions ici ou à
la porte ouverte .