Bonjour à tous. Comme vous le savez peut-être, j'avais l'habitude d' écrire et de parler davantage du stockage, de Vertica, du stockage de Big Data et d'autres choses analytiques. Désormais, toutes les autres bases de données, non seulement analytiques, mais aussi OLTP (PostgreSQL) et NOSQL (MongoDB, Redis, Tarantool) sont également tombées dans mon domaine de responsabilité.
Cette situation m'a permis de considérer une organisation qui a plusieurs bases de données comme une organisation qui a une base de données hétérogène (hétérogène) distribuée. Une seule base de données hétérogène distribuée, constituée d'un tas de PostgreSQL, Redis et Mong ... Et, éventuellement, d'une ou deux bases de données Vertica.
Le travail de cette base distribuée unique génère un tas de tâches intéressantes. Tout d'abord, du point de vue des affaires, il est important que tout soit normal avec des données se déplaçant le long d'une telle base. Je n'utilise pas spécifiquement le terme intégrité, cohérence, car le terme est complexe, et dans différentes nuances de considérer un SGBD (théorème A C ID et C AP), il a une signification différente.
La situation avec une base distribuée est aggravée si une entreprise essaie de passer à une architecture de microservice. Sous le chat, je parle de la façon d'assurer l'intégrité des données dans une architecture de microservice sans transactions distribuées et connectivité étroite. (Et à la fin j'explique pourquoi j'ai choisi cette illustration pour l'article).

Selon Chris Richardson (l'un des évangélistes les plus célèbres de l'architecture de microservices), cette architecture a deux approches pour travailler avec des bases de données: base de données partagée et base de données par service.

La base de données partagée est une bonne première étape, une excellente solution pour une petite entreprise sans plans de croissance ambitieux. De plus, ce modèle est en soi un anti-modèle du point de vue de l'architecture de microservices, comme deux services partageant une base commune ne peuvent pas être testés et mis à l'échelle indépendamment. C'est-à-dire ces services sont plutôt un service qui tend à devenir un monolithe.
Le modèle de base de données par service suppose que chaque service possède sa propre base de données. Un service ne peut accéder aux données d'un autre service que via l'API (au sens large), sans connexion directe à sa base de données.
Le modèle de base de données par service permet aux équipes des services correspondants de sélectionner les bases de données à leur guise. Quelqu'un est capable dans MongoDB, quelqu'un croit en PostgreSQL, quelqu'un a besoin de Redis (le risque de perte de données lors de l'arrêt est acceptable pour ce service), et quelqu'un stocke généralement les données dans des fichiers CSV sur disque (et pourquoi, en fait , et non?).
Travailler avec un tel «zoo» de bases de données soulève la tâche de restaurer l'ordre dans les données à un tout nouveau niveau de complexité.
Architecture ACID et microservice
Examinons la tâche de mettre les choses en ordre à travers le prisme de l'ensemble d'exigences ACID basé sur un SGBD classique: nous allons développer l'essence de chaque lettre de l'abréviation et illustrer les difficultés de cette lettre dans l'architecture de microservices.
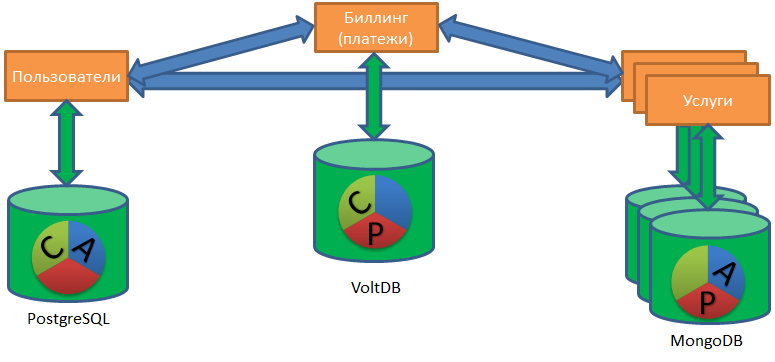
(A) CID - Atomicité. Atomicité - tout ou rien.
Selon l'exigence d'atomicité, il est impératif de terminer toutes les étapes (avec des répétitions possibles), si une étape importante échoue, annuler les étapes terminées.
L'illustration ci-dessus illustre le processus de test d'achat d'un service VIP: l'argent est réservé dans la facturation (1), un service bonus est activé pour un utilisateur (2), le type d'utilisateur est changé en Pro (3), l'argent réservé dans la facturation est débité (4). Les quatre étapes doivent être terminées ou non.
Dans ce cas, vous ne pouvez pas bloquer au milieu du processus, par conséquent, l'asynchronie est préférable, dans les cas extrêmes, le synchronisme avec le délai d'expiration intégré.
A (C) ID - Cohérence. Cohérence - chaque étape ne doit pas contredire les conditions aux limites.
Exemples classiques de conditions pour, par exemple, envoyer de l'argent du client A dans le service 1 au client B dans le service 2: à la suite d'un tel envoi d'argent ne devrait pas devenir moins (l'argent ne devrait pas être perdu pendant le transfert) ou plus (il est inacceptable d'envoyer le même argent à deux utilisateurs en même temps). Pour se conformer à cette exigence, vous devez coder les conditions quelque part et vérifier les données pour les conditions (idéalement, sans appels supplémentaires).

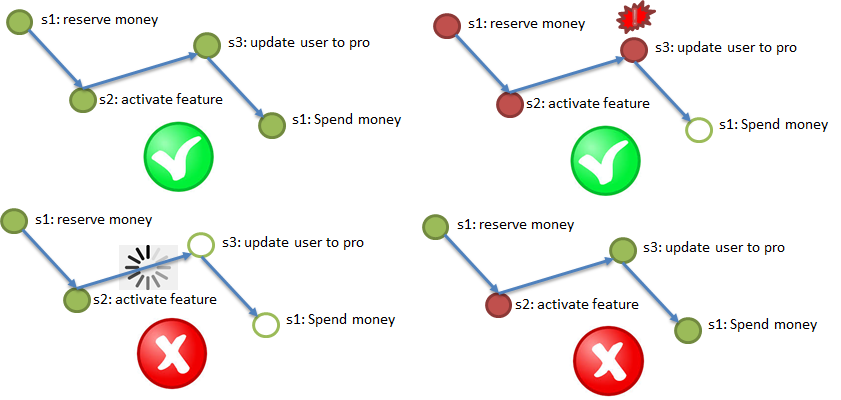
ACI (D) - Durabilité. L'exigence de durabilité signifie que les effets des opérations ne disparaissent pas.
Dans les conditions de persistance de Polyglot, un service peut fonctionner sur une base de données qui peut régulièrement «perdre» les données qui y sont enregistrées. Une astuce similaire peut être obtenue même à partir de bases de données solides comme PostgreSQL, si la réplication asynchrone y est activée. L'illustration montre comment les modifications enregistrées dans Master, mais qui n'ont pas atteint Slave via la réplication asynchrone, peuvent être détruites en brûlant le serveur Master. Pour garantir les exigences de durabilité, il est nécessaire de pouvoir diagnostiquer et récupérer correctement ces pertes.
Et où suis-je, demandez-vous?
Et nulle part. L'isolement dans un environnement de plusieurs services asynchrones indépendants est une exigence technique. La recherche moderne a montré que de vrais processus commerciaux peuvent être mis en œuvre sans isolement. L'isolement simplifie la réflexion en minimisant la concurrence (le développement de l'informatique parallèle est plus difficile pour un programmeur), mais l'architecture des microservices est intrinsèquement massive-parallèle, l'isolement dans un tel environnement est redondant.
Il existe de nombreuses approches pour se conformer aux exigences ci-dessus. L'algorithme de transactions distribuées le plus connu fourni par ce que l'on appelle la validation en deux phases (2PC). Malheureusement, la mise en œuvre de validations en deux phases nécessite la réécriture de tous les services impliqués. Et le plus grave: cet algorithme n'est pas très productif. Les illustrations issues d'études récentes montrent que cet algorithme montre une certaine performance sur une base distribuée de deux serveurs, mais avec une augmentation du nombre de serveurs, la productivité ne croît pas linéairement ... Ou plutôt, elle ne croît pas du tout.

L'un des principaux avantages de l'architecture de microservices est la possibilité d'augmenter linéairement les performances en ajoutant simplement de plus en plus de serveurs. Il s'avère que si nous utilisons un commit en deux phases pour garantir l'intégrité distribuée, ce processus deviendra un goulot d'étranglement, un frein à la croissance de la productivité, malgré l'augmentation du nombre de serveurs.
Comment garantir l'intégrité distribuée (exigences ACiD) sans commits en deux phases, avec la possibilité d'évoluer de manière linéaire dans les performances?
La recherche moderne (par exemple, An Evaluation of Distributed Concurrency Control. VLDB 2017 ) soutient que la soi-disant «approche optimiste» peut aider. La différence entre l'engagement en deux phases et «l'approche optimiste» généralisée peut être illustrée par la différence entre l'ancien magasin soviétique (avec un comptoir) et un supermarché moderne comme Auchan. Dans un magasin avec un comptoir, chaque client est considéré comme suspect et reçoit un contrôle maximal. D'où les lignes et les conflits. Et au supermarché, l'acheteur est considéré comme honnête par défaut, ils lui donnent la possibilité de s'approcher des étagères et de remplir les chariots. Bien sûr, il existe des outils de surveillance pour attraper les escrocs (caméras, sécurité), mais la plupart des acheteurs n'ont jamais à s'en occuper.
Par conséquent, le supermarché peut être agrandi, agrandi, simplement en plaçant plus de caisses. Il en va de même avec l'architecture de microservices: si l'intégrité distribuée est assurée par une «approche optimiste», lorsque seuls les processus où quelque chose s'est mal passé sont en outre chargés de vérifications. Et les processus normaux passent sans vérifications supplémentaires.
C'est important. L '«approche optimiste» comprend plusieurs algorithmes. Je voudrais vous parler de la saga - l'algorithme pour maintenir l'intégrité distribuée, recommandé par Chris Richardson.
Sagas - éléments de l'algorithme
L'algorithme d'affaissement a deux options. Par conséquent, dans un premier temps, je voudrais décrire universellement les éléments requis de l'algorithme afin que la description soit adaptée aux deux options.
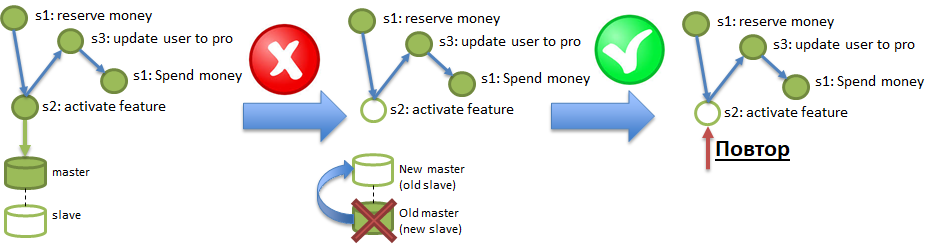
Élément 1. Canal fiable et persistant de livraison d'événements entre les services, garantissant "au moins une livraison". C'est-à-dire si l'étape 2 du processus s'est terminée avec succès, une notification (événement) à ce sujet doit atteindre l'étape 3 au moins une fois, les livraisons répétées sont acceptables, mais rien ne doit être perdu. "Persistant" signifie que le canal doit stocker les notifications pendant un certain temps (2-3 jours, une semaine) afin qu'un service qui a perdu les dernières modifications en raison de la perte de la base de données (voir l'exemple de durabilité, dans l'illustration c'est l'étape 2), puisse restaurer ces changements en rejouant les événements de la chaîne.
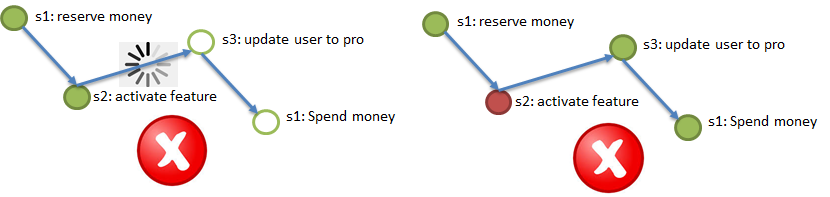
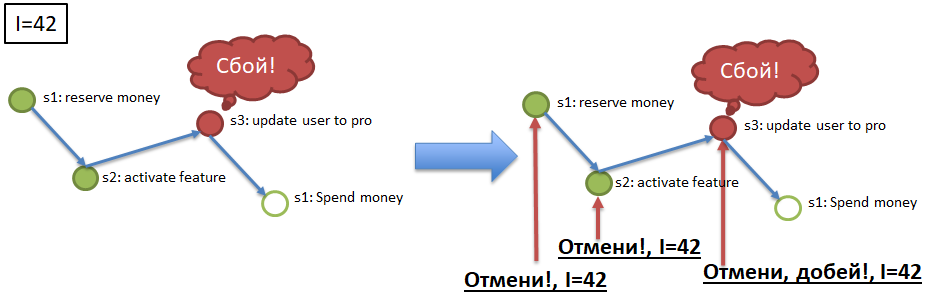
Élément 2. Idempotence des appels de service grâce à l'utilisation d'une clé d'idempotence unique. Imaginez que moi (l'utilisateur) lance le processus d'achat d'un package VIP (voir l'exemple pour Atomicity). Au début du processus, on me donne une clé unique, la clé d'idempotence, par exemple, 42. Ensuite, l'appel à chacune des étapes (1 → 2 → 3 → 4) doit être effectué avec la clé d'idempotence indiquée. Dans le paragraphe ci-dessus, la possibilité de l'arrivée répétée du même message au service (à l'étape) est évoquée. Le service (étape) doit automatiquement pouvoir ignorer l'arrivée répétée de l'événement traité, en vérifiant la répétition par la clé idempotency. Autrement dit, si tous les services (étapes de processus) sont idempotents, afin de répondre aux exigences d'atomicité et de durabilité, il suffit de rediriger vers les étapes correspondant aux événements des canaux. Les étapes qui ont ignoré les événements les exécuteront et les étapes qui ont déjà terminé les événements les ignoreront en raison de l'idempotency.

Élément 3. Annulation des appels de service (étapes) par clé idempotency.
Pour garantir l'atomicité (voir l'exemple), si le processus avec la clé idempotency 42, par exemple, s'est arrêté / est tombé à l'étape 3, il est alors nécessaire d'annuler l'exécution réussie des étapes 1 et 2 pour la clé 42. Pour cela, chaque étape de processus obligatoire doit avoir une étape de «compensation» , Une méthode API qui annule l'exécution de l'étape requise pour la clé d'idempotence spécifiée (42). L'implémentation des appels compensatoires est un élément difficile mais nécessaire au raffinement des services dans le cadre de l'implémentation de l'algorithme d'affaissement.
Les trois éléments énumérés ci-dessus sont pertinents pour les deux versions de la mise en œuvre de la «sag»: orchestrée et chorégraphique.
Sagas orchestrées
L'algorithme plus simple et plus évident pour les sagas orchestrées est plus facile à comprendre et à mettre en œuvre. Dans un excellent article, kevteev a décrit l'algorithme et le processus de mise en œuvre du mécanisme des sagas orchestrées dans Avito. Leur algorithme suppose l'existence d'un service de contrôle, "orchestrant" les appels de service dans le cadre de processus métier desservis. Le même service de surveillance peut avoir sa propre base de données (par exemple, PostgreSQL), qui agit comme un canal fiable de livraison d'événements persistants (élément 1).
Sagas chorégraphiques
La saga chorégraphique est plus délicate. Ici, un bus de données qui met en œuvre les exigences suivantes doit agir comme un canal persistant fiable: publication de type "ignorer", livraison d'événements de publication-abonnement, au moins une fois de livraison. C'est-à-dire chaque étape de chaque processus doit recevoir une commande pour fonctionner à partir du bus et y envoyer le message de réussite, sur le début de l'étape suivante, afin qu'il le lise également sur le bus et poursuive le processus. De plus, pour chaque message, il peut y avoir plusieurs abonnés.
La saga chorégraphique devrait également avoir un service de contrôle, un service de sagas, mais beaucoup plus «léger». Le service doit connaître les processus métier enregistrés dans le système, la composition des étapes incluses dans chaque processus. Il doit également écouter le bus, surveiller l'exécution de chaque processus (chaque clé d'idempotence), et seulement si quelque chose s'est mal passé, soit lancer des «répétitions» d'étapes spécifiques, soit lancer des «annulations», des «compensations» pour les étapes suivies.
Nuances
L'une des nuances les plus importantes des sagas qui les distinguent des transactions classiques est un écart par rapport à la linéarité, la séquence et l'obligation de chaque étape. Une saga n'est pas nécessairement une chaîne linéaire d'événements, elle peut être un graphique dirigé: un nouvel événement d'enregistrement d'utilisateur peut engendrer plusieurs étapes en parallèle (envoi de SMS, enregistrement d'une connexion, génération d'un mot de passe, envoi d'un e-mail), dont certaines peuvent être facultatives. Dans une première approximation, il semble que dans une telle saga "ramifiée" avec des étapes facultatives, il est difficile de déterminer l'achèvement de la saga (processus), mais, en fait, tout est simple: la saga (processus) est terminée lorsque toutes les étapes requises sont terminées, dans n'importe quel ordre.

La deuxième nuance, plus typique des sagas chorégraphiques, mais également possible pour les sagas orchestrées, est de choisir une approche pour l'enregistrement des processus métier, types de sagas dans le service sagas. L'exemple d'atomicité décrit un processus de quatre étapes obligatoires consécutives.
Qui a enregistré ce processus, indiqué toutes les étapes, placé les dépendances et les étapes obligatoires? La réponse évidente mais démodée est que l'enregistrement du processus doit être effectué de manière centralisée dans le service d'affaissement. Mais cette réponse n'est pas très cohérente avec l'architecture de microservices. Dans l'architecture de microservices, il est plus prometteur, plus productif et plus rapide d'enregistrer des processus ascendants. C'est-à-dire de ne pas noter toutes les nuances du processus dans le service sag, mais de permettre aux services individuels de «s'intégrer» dans les processus existants par eux-mêmes, en indiquant leur nature contraignante / facultative et leurs prédécesseurs obligatoires.
C'est-à-dire le processus d'enregistrement d'un utilisateur dans le service d'affaissement peut initialement comprendre trois étapes, puis, pendant le développement du système, sept autres étapes y seront intégrées, et une étape sera écrite, et il y en aura neuf. Un tel schéma «anarchiste» et «décentralisé» est difficile à tester, à mettre en œuvre un processus strict et coordonné, mais il est beaucoup plus pratique pour les équipes Agiles, pour une évolution produit multidirectionnelle continue.
En fait, ici. Avec une présentation sérieuse, je pense qu'il vaut la peine de terminer, sinon l'article s'est avéré trop volumineux.
Voici un lien vers la présentation de ce matériel, j'ai fait un reportage sur ce sujet à Highload Siberia 2018.
UPD - et vidéo de la conférence:
Épilogue
En fin de compte, je voudrais essayer d'expliquer tout ce qui précède dans un langage plus figuratif.
Après tout, qu'est-ce qu'une saga depuis le début? Cette intrigue, cette aventure du Moyen Âge ... Ou du Game of Thrones. Un événement a lieu (une bataille, un mariage, quelqu'un meurt), la nouvelle s'envole à travers le monde à travers des messagers, des pigeons voyageurs, des marchands. Lorsque les informations parviennent aux intéressés (dans une semaine, un mois, un an), ils réagissent: ils envoient des armées, déclarent la guerre, exécutent quelqu'un et de nouveaux messages volent.
Aucun organisme de réglementation ne surveille la séquence des actions. Aucune transaction, aucun retour en arrière, dans le sens d'annuler l'action, comme si elle n'avait jamais été. De manière adulte, chaque action se déroule pour toujours. Il peut être indemnisé, mais c'est précisément l'action (meurtre) et l'indemnisation (salaire pour la tête, vira), et non l'abolition de la mort.
Les événements prennent beaucoup de temps, proviennent de différentes sources, les actions se déroulent en parallèle et pas strictement séquentiellement. Et assez souvent, de nouveaux participants apparaissent soudainement dans l'intrigue, qui décident de participer (les dragons arrivent;)) ... et certains des anciens participants meurent soudainement.
De telles choses. Cela semble être un gâchis et un chaos, mais tout fonctionne, la coordination interne du monde n'est pas rompue, l'intrigue se développe et est cohérente ... Bien que parfois imprévisible.