
Chacun de nous perçoit les textes à sa manière, qu'il s'agisse d'actualités sur Internet, de poésie ou de romans classiques. Il en va de même pour les algorithmes et les méthodes d'apprentissage automatique, qui, en règle générale, perçoivent les textes sous forme mathématique, sous la forme d'un espace vectoriel multidimensionnel.
L'article est consacré à la visualisation à l'aide de t-SNE calculé par des représentations vectorielles multidimensionnelles Word2Vec de mots. La visualisation permettra une meilleure compréhension du principe de Word2Vec et de la façon d'interpréter la relation entre les vecteurs de mots avant une utilisation ultérieure dans les réseaux de neurones et d'autres algorithmes d'apprentissage automatique. L'article se concentre sur la visualisation, la recherche et l'analyse des données ne sont pas prises en compte. En tant que source de données, nous utilisons des articles de Google Actualités et des œuvres classiques de L.N. Tolstoï. Nous allons écrire le code en Python dans le cahier Jupyter.
Intégration de voisin stochastique distribué en T
T-SNE est un algorithme d'apprentissage automatique pour la visualisation de données basé sur la méthode de réduction dimensionnelle non linéaire, qui est décrite en détail dans l'article original [1] et sur
Habré . Le principe de base du fonctionnement du t-SNE est de réduire les distances par paire entre les points tout en conservant leur position relative. En d'autres termes, l'algorithme mappe des données multidimensionnelles sur un espace de dimension inférieure, tout en conservant la structure du voisinage des points.
Représentations vectorielles des mots et Word2Vec
Tout d'abord, nous devons présenter les mots sous forme vectorielle. Pour cette tâche, j'ai choisi l'utilitaire de sémantique de distribution Word2Vec, qui est conçu pour afficher la signification sémantique des mots dans l'espace vectoriel. Word2Vec trouve des relations entre les mots en supposant que les mots sémantiquement liés se trouvent dans des contextes similaires. Vous pouvez en savoir plus sur Word2Vec dans l'article d'origine [2], ainsi
qu'ici et
ici .
En entrée, nous prenons des articles de Google Actualités et des romans de L.N. Tolstoï. Dans le premier cas, nous utiliserons les vecteurs pré-formés sur l'ensemble de données Google Actualités (environ 100 milliards de mots) publié par Google
sur la page du projet .
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
En plus des vecteurs pré-formés utilisant la bibliothèque Gensim [3], nous formerons un autre modèle dans les textes de L.N. Tolstoï. Étant donné que Word2Vec accepte un tableau de phrases en entrée, nous utilisons le modèle de jeton de phrase Punkt pré-formé du package NLTK pour diviser automatiquement le texte en phrases. Le modèle pour la langue russe peut être téléchargé
ici .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
Ensuite, en utilisant la bibliothèque Gensim, nous formerons le modèle Word2Vec avec les paramètres suivants:
- taille = 200 - dimension de l'espace attributaire;
- window = 5 - le nombre de mots du contexte que l'algorithme analyse;
- min_count = 5 - le mot doit apparaître au moins cinq fois pour que le modèle en tienne compte.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualisation des représentations vectorielles de mots à l'aide de t-SNE
T-SNE est extrêmement utile pour visualiser les similitudes entre les objets dans un espace multidimensionnel. À mesure que la quantité de données augmente, il devient de plus en plus difficile de construire un graphique visuel, donc dans la pratique, les mots associés sont combinés en groupes pour une visualisation plus approfondie. Prenons par exemple quelques mots d'un dictionnaire du modèle Word2Vec précédemment formé sur Google Actualités.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
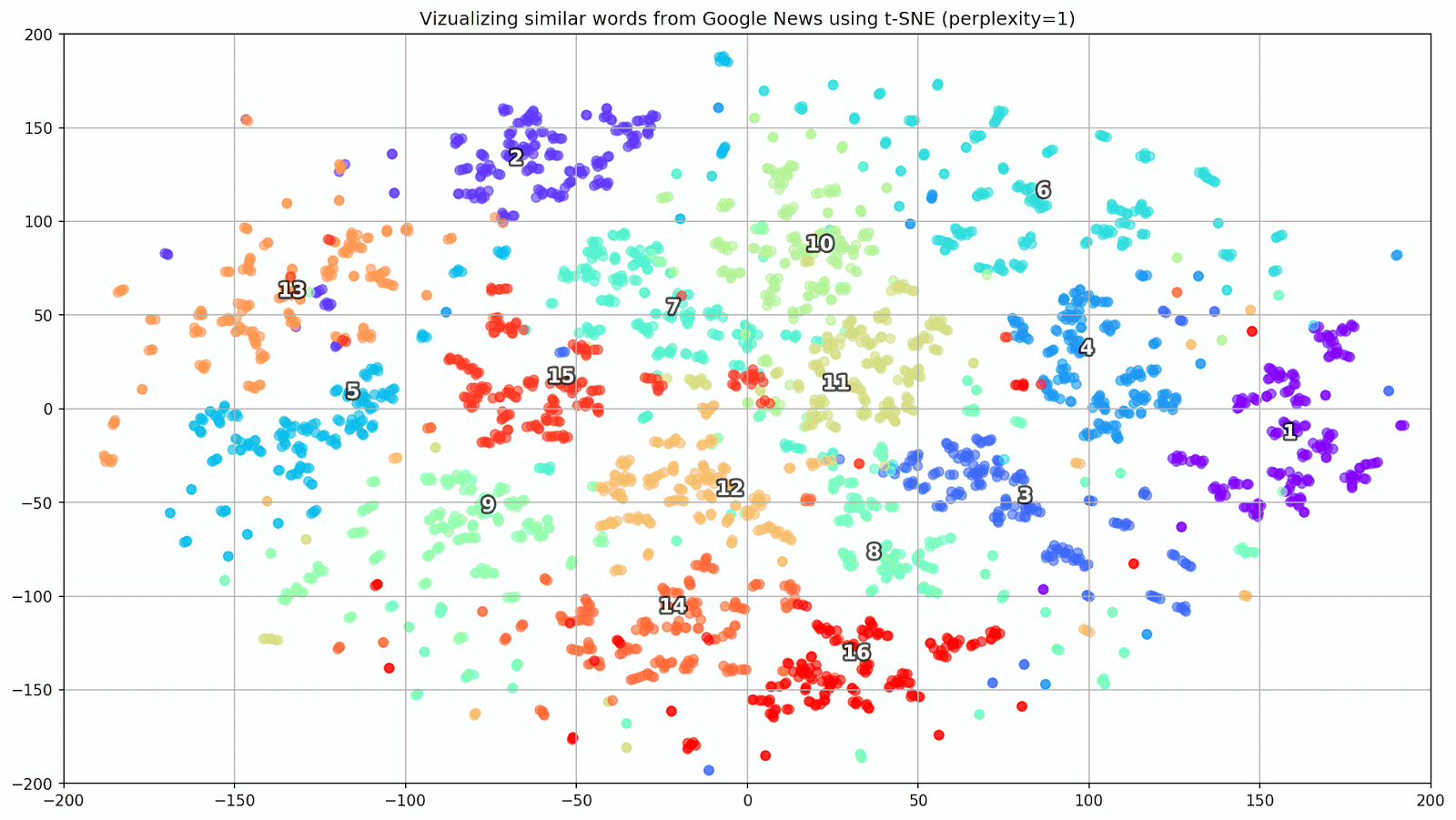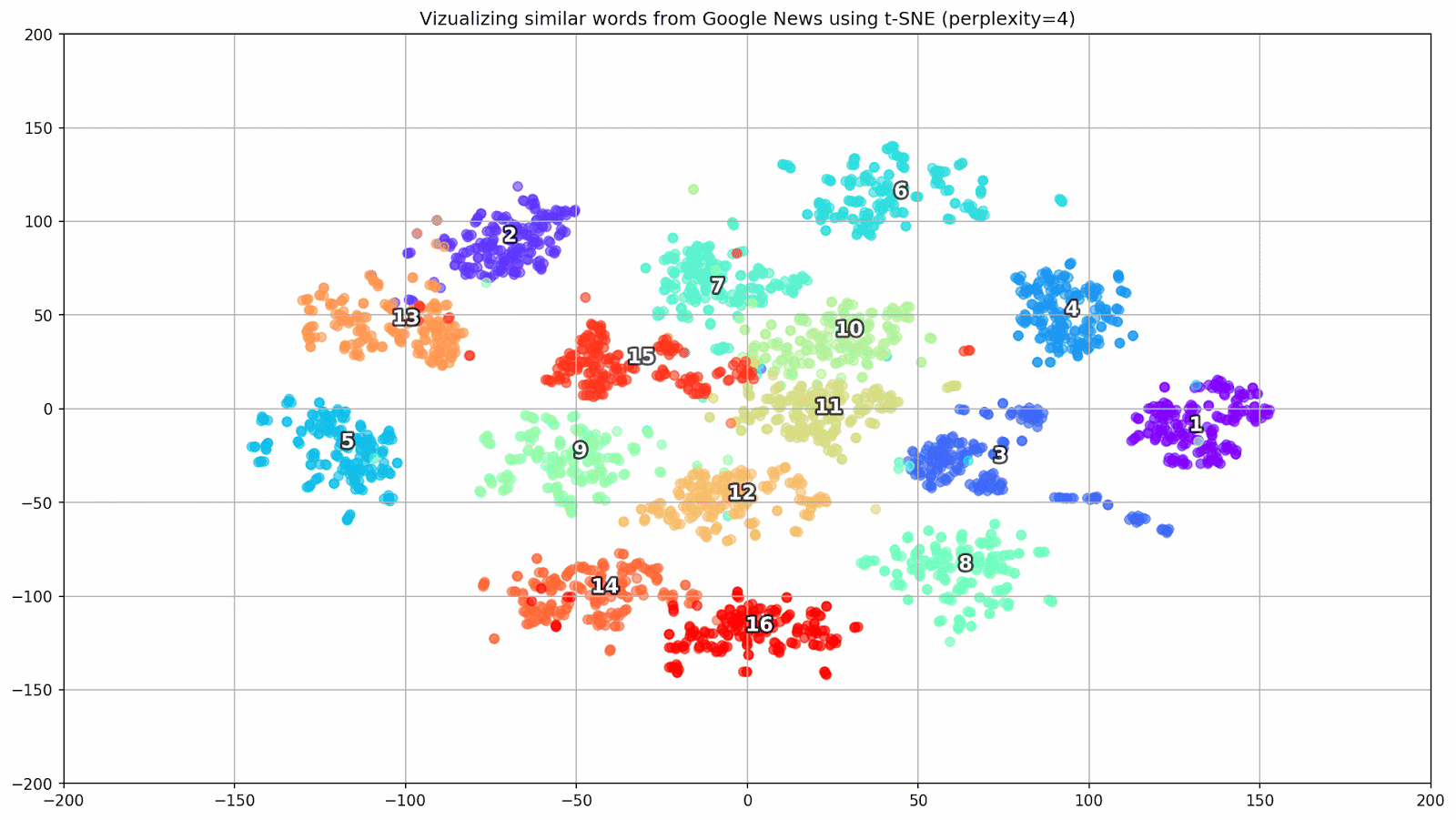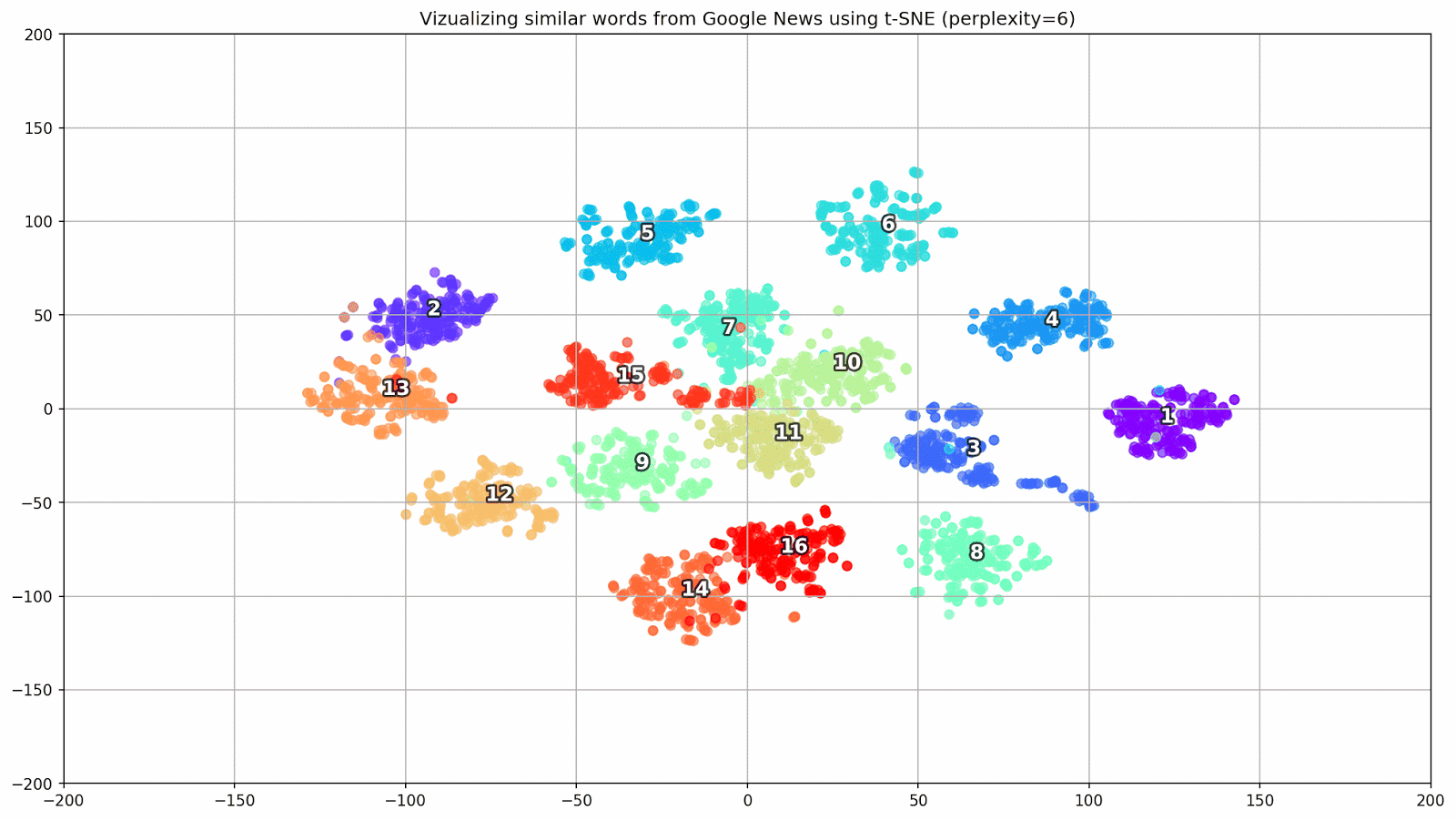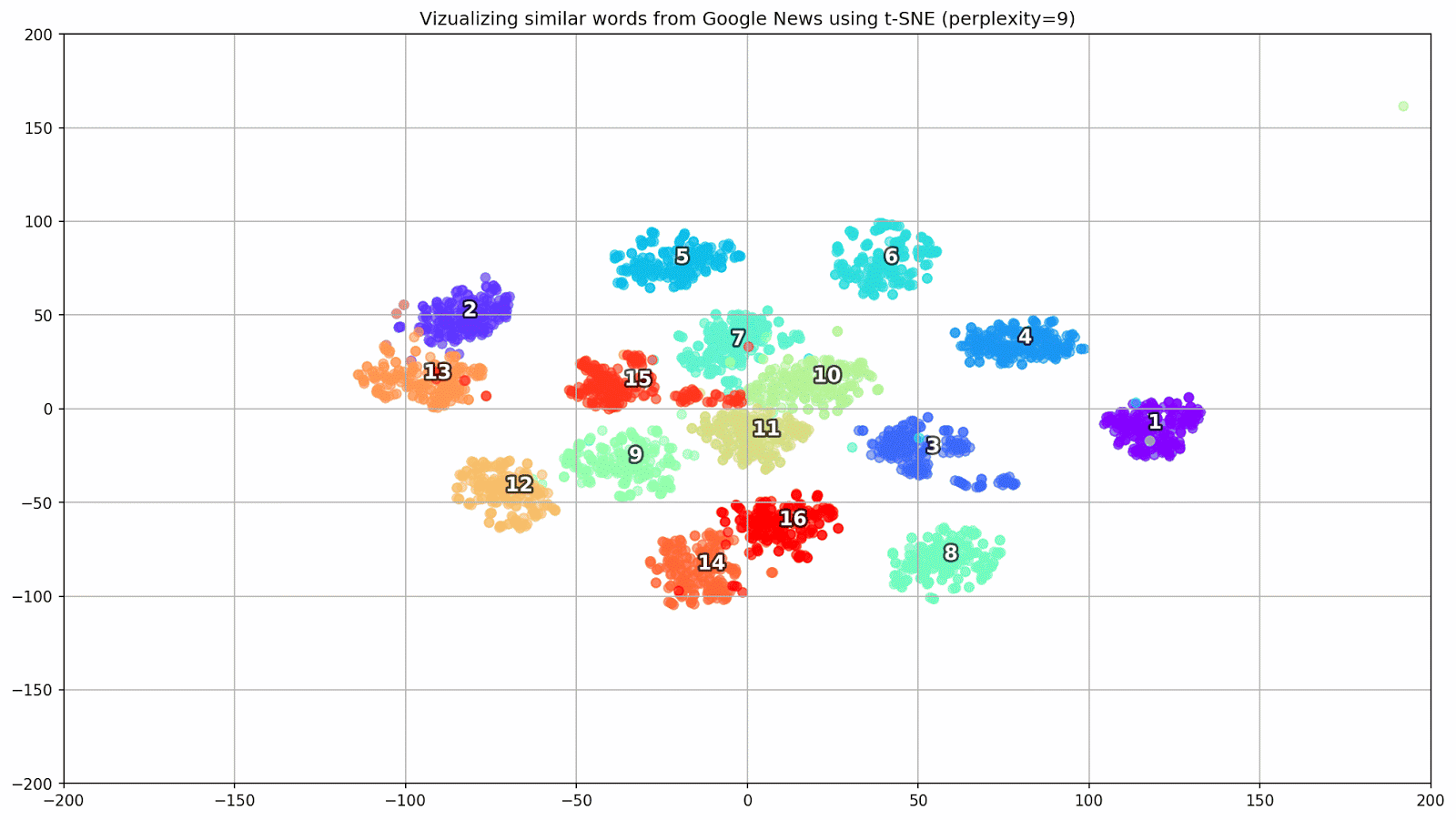 Figure 1. Groupes de mots similaires de Google Actualités avec différentes valeurs de préplexité.
Figure 1. Groupes de mots similaires de Google Actualités avec différentes valeurs de préplexité.Ensuite, nous passons au fragment le plus remarquable de l'article, la configuration t-SNE. Ici, vous devez tout d'abord faire attention aux hyperparamètres suivants:
- n_components - le nombre de composants, c'est-à-dire la dimension de l'espace des valeurs;
- perplexité - perplexité, dont la valeur en t-SNE peut être assimilée au nombre effectif de voisins. Il est lié au nombre de voisins les plus proches, qui est utilisé dans d'autres modèles d'apprentissage sur la base des variétés (voir l'image ci-dessus). Sa valeur est recommandée [1] pour être réglée dans la plage de 5-50;
- init - type d'initialisation initiale des vecteurs.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
Vous trouverez ci-dessous un script pour créer un graphique bidimensionnel à l'aide de Matplotlib, l'une des bibliothèques les plus populaires pour visualiser des données en Python.
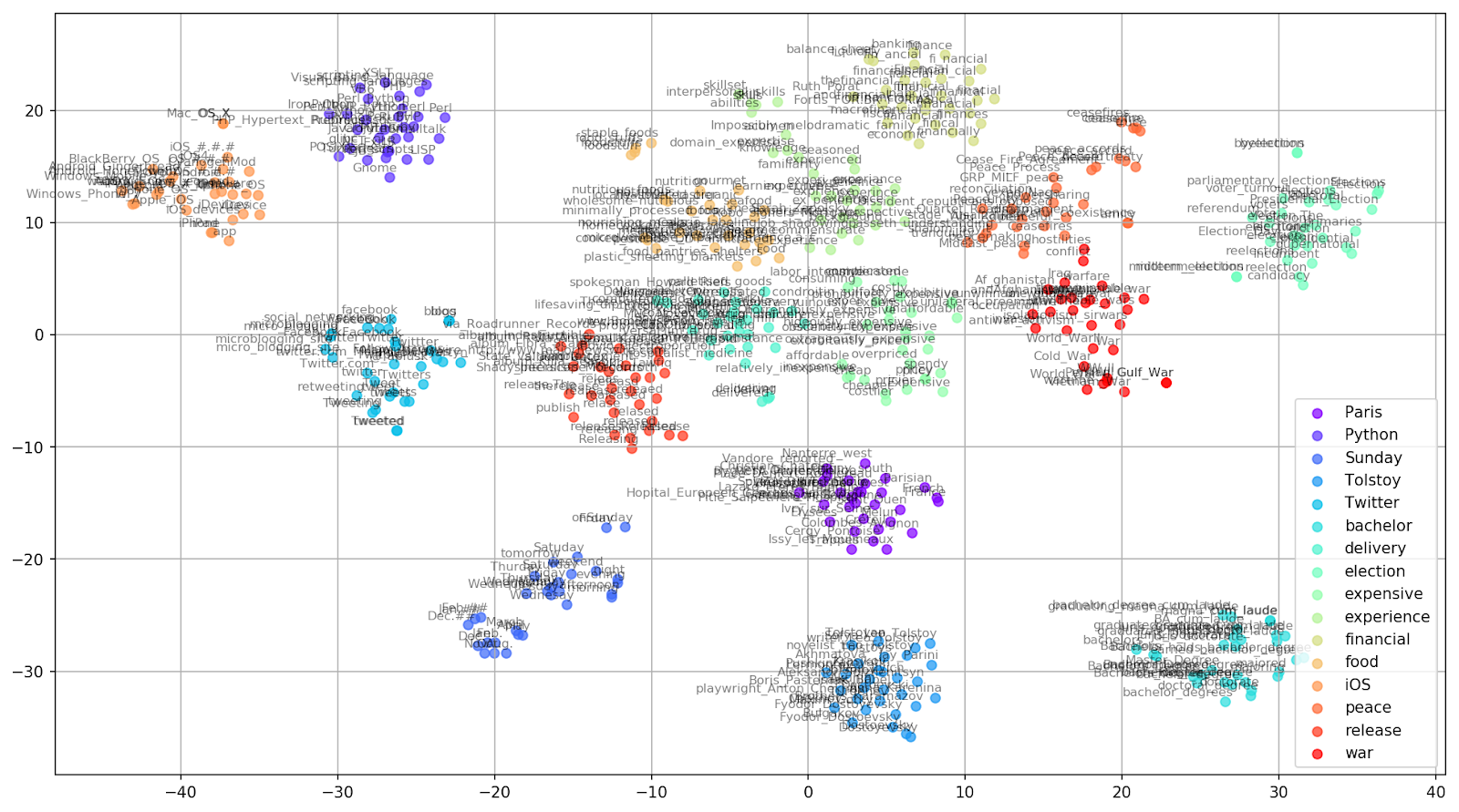 Figure 2. Groupes de mots similaires de Google Actualités (préplexité = 15).
Figure 2. Groupes de mots similaires de Google Actualités (préplexité = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
Parfois, il est nécessaire de construire non pas des groupes de mots séparés, mais l'ensemble du dictionnaire. À cette fin, analysons Anna Karenina, la grande histoire de la passion, de la trahison, de la tragédie et de l'expiation.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
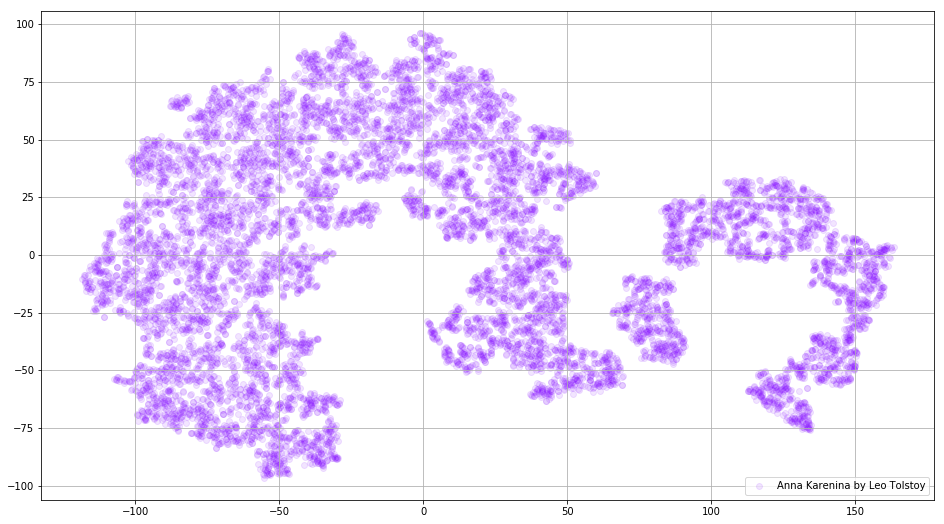
 Figure 3. Visualisation du dictionnaire du modèle Word2Vec, formé sur le roman "Anna Karenina".
Figure 3. Visualisation du dictionnaire du modèle Word2Vec, formé sur le roman "Anna Karenina".L'image peut devenir encore plus informative si nous utilisons l'espace tridimensionnel. Jetez un œil à War and Peace, l'un des principaux romans de la littérature mondiale.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
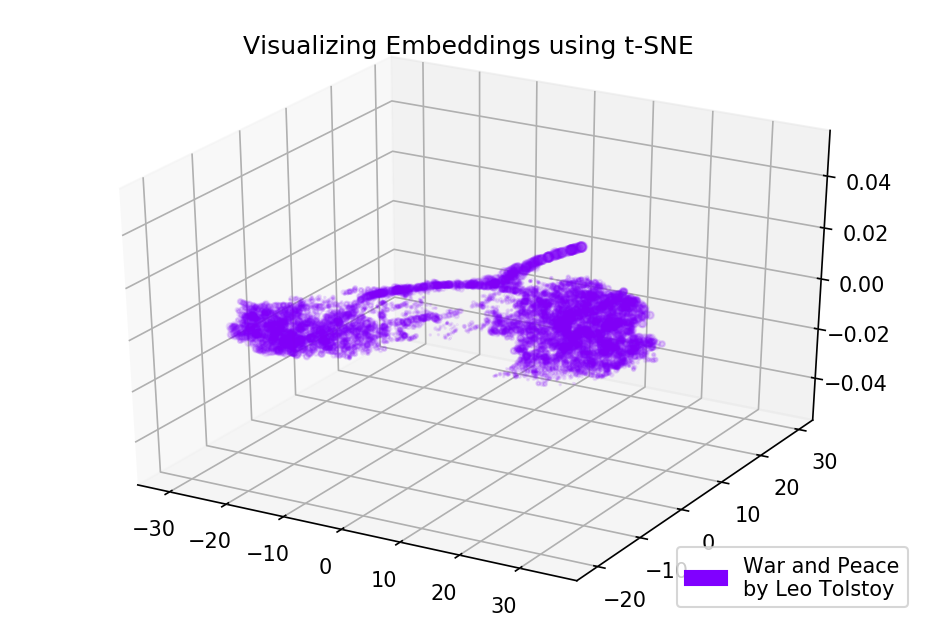 Figure 4. Visualisation du dictionnaire du modèle Word2Vec, formé sur le roman "Guerre et paix".
Figure 4. Visualisation du dictionnaire du modèle Word2Vec, formé sur le roman "Guerre et paix".Code source
Le code est disponible sur
GitHub . Vous y trouverez le code de rendu des animations.
Les sources
- Maaten L., Hinton G. Visualisation des données à l'aide de t-SNE // Journal of machine learning research. - 2008. - T. 9. - S. 2579-2605.
- Représentations distribuées des mots et des phrases et leur compositionnalité // Avancées dans les systèmes de traitement de l'information neuronale . - 2013 .-- S. 3111-3119.
- Rehurek R., Sojka P. Cadre logiciel pour la modélisation de sujets avec de grands corpus // Dans les actes de l'atelier LREC 2010 sur les nouveaux défis pour les cadres PNL. - 2010.