Je continue de télécharger des rapports avec Pixonic DevGAMM Talks, notre réunion de septembre pour les développeurs de systèmes hautement chargés. Ils ont partagé beaucoup d'expériences et de cas, et aujourd'hui je publie une transcription du discours du développeur backend de Saber Interactive Roman Rogozin. Il a évoqué la pratique de l'application du modèle de l'acteur à partir de l'exemple de la gestion des joueurs et de leurs états (d'autres rapports se trouvent en fin d'article, la liste est complétée).
Notre équipe travaille sur un backend pour le jeu Quake Champions, et je vais parler de ce qu'est le modèle d'acteur et comment il est utilisé dans le projet.
Un peu sur la pile technologique. Nous écrivons du code en C #, respectivement, toutes les technologies y sont liées. Je veux noter qu'il y aura certaines choses spécifiques que je montrerai sur l'exemple de ce langage, mais les principes généraux resteront inchangés.

Pour le moment, nous hébergeons nos services dans Azure. Il y a des primitives très intéressantes que nous ne voulons pas abandonner, comme le stockage de table et Cosmos DB (mais nous essayons de ne pas trop les serrer pour le projet multi-plateforme).
Maintenant, je voudrais parler un peu de ce qu'est un modèle d'acteur. Et pour commencer, il est apparu comme principe il y a plus de 40 ans.
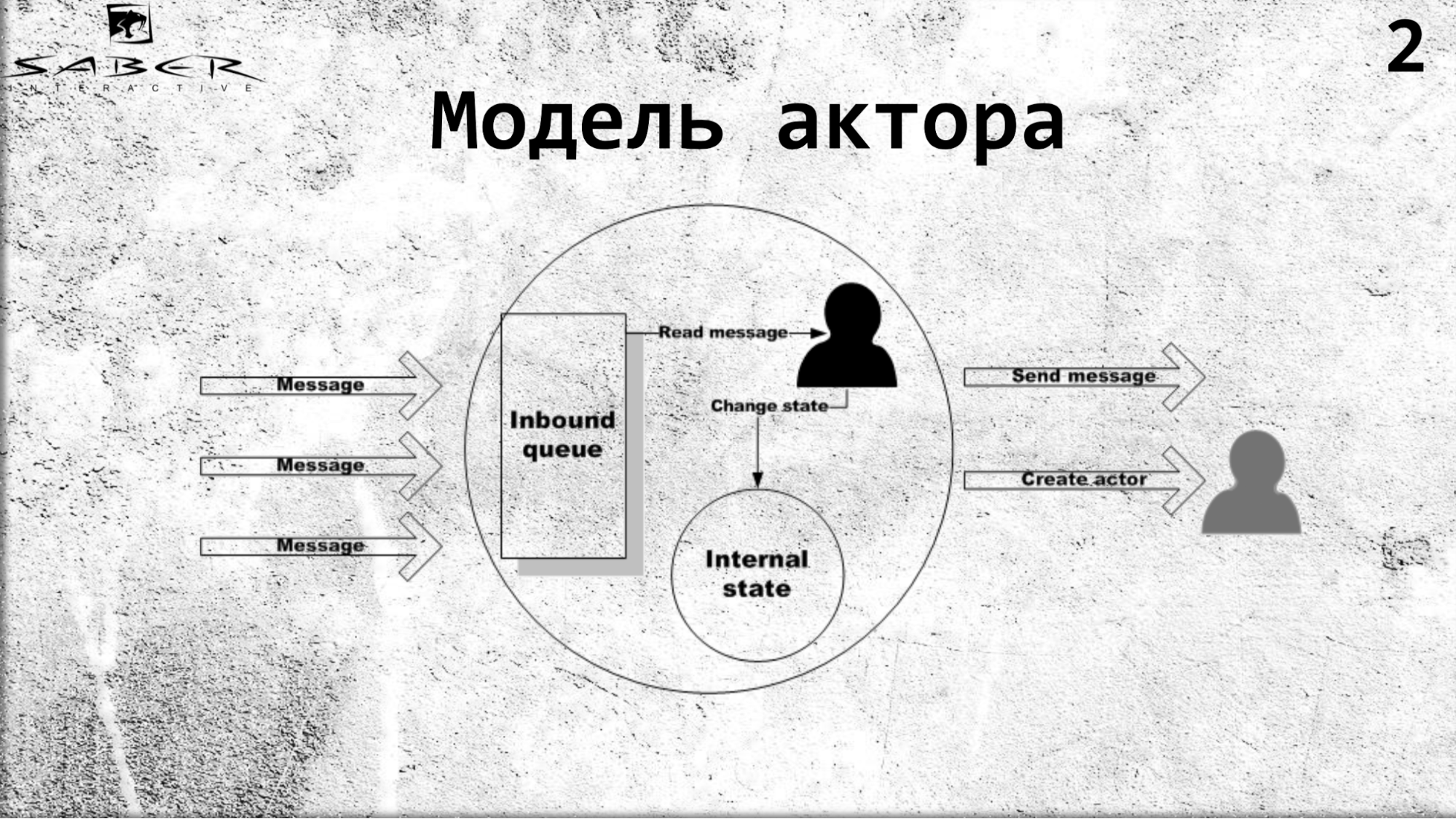
Un acteur est un modèle de calcul parallèle qui déclare qu'il existe un certain objet isolé qui a son propre état interne et un accès exclusif pour changer cet état. Un acteur peut lire des messages et, en outre, séquentiellement, exécuter une sorte de logique métier, s'il veut changer son état interne, et envoyer des messages à des services externes, y compris à d'autres acteurs. Et il sait créer d'autres acteurs.
Les acteurs communiquent entre eux de manière asynchrone, ce qui vous permet de créer des systèmes cloud distribués très chargés. À cet égard, le modèle d'acteur a été largement utilisé récemment.
Pour résumer un peu, imaginons que nous avons un cloud où il y a une sorte de cluster de serveurs, et nos acteurs tournent sur ce cluster.
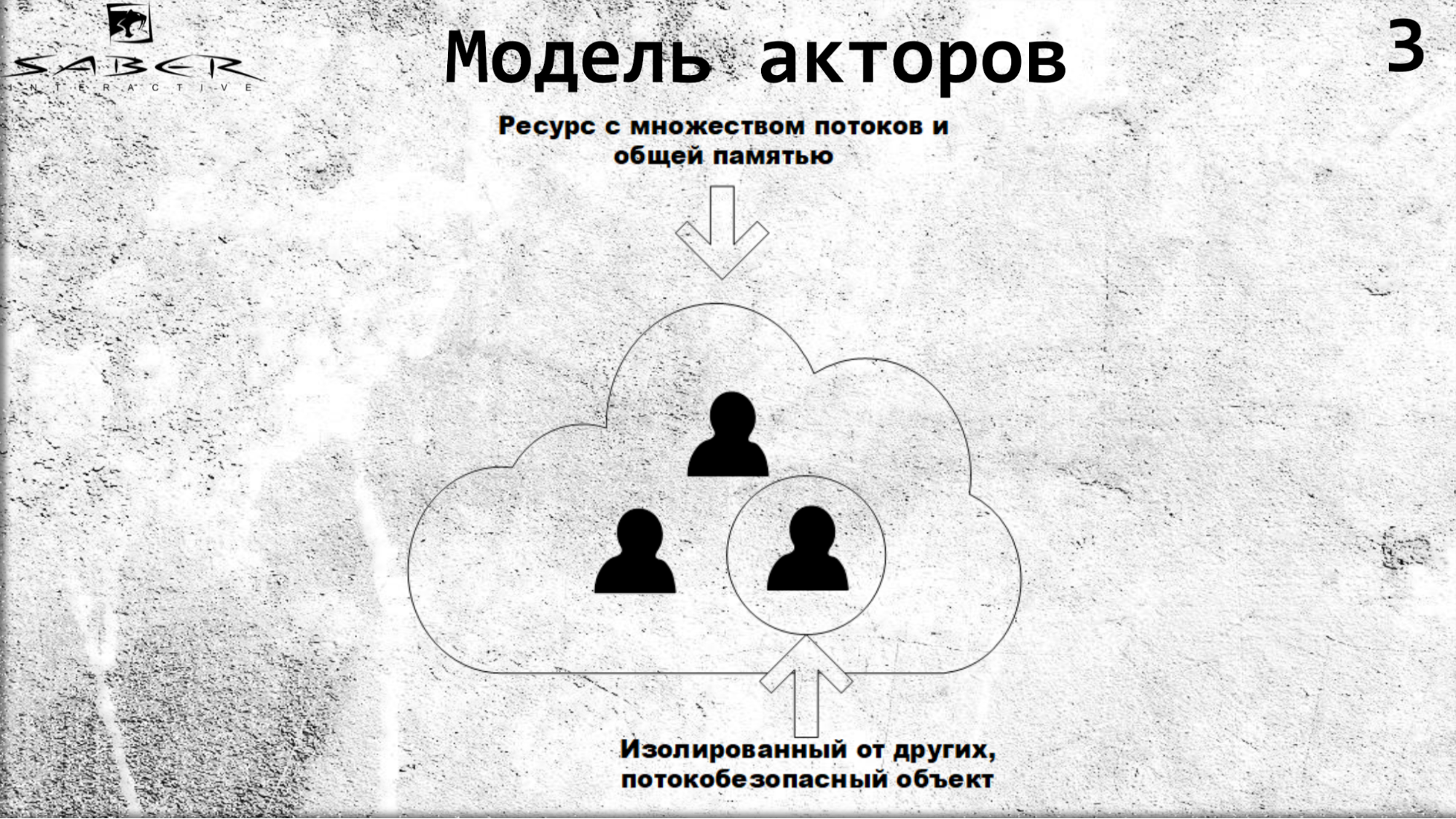
Les acteurs sont isolés les uns des autres, communiquent par le biais d'appels asynchrones et, à l'intérieur d'eux-mêmes, les acteurs sont protégés contre les threads.
À quoi cela pourrait ressembler. Supposons que nous ayons plusieurs utilisateurs (pas une très grosse charge), et à un moment donné, nous comprenons qu'il y a un afflux de joueurs, et nous devons d'urgence faire une montée en gamme.
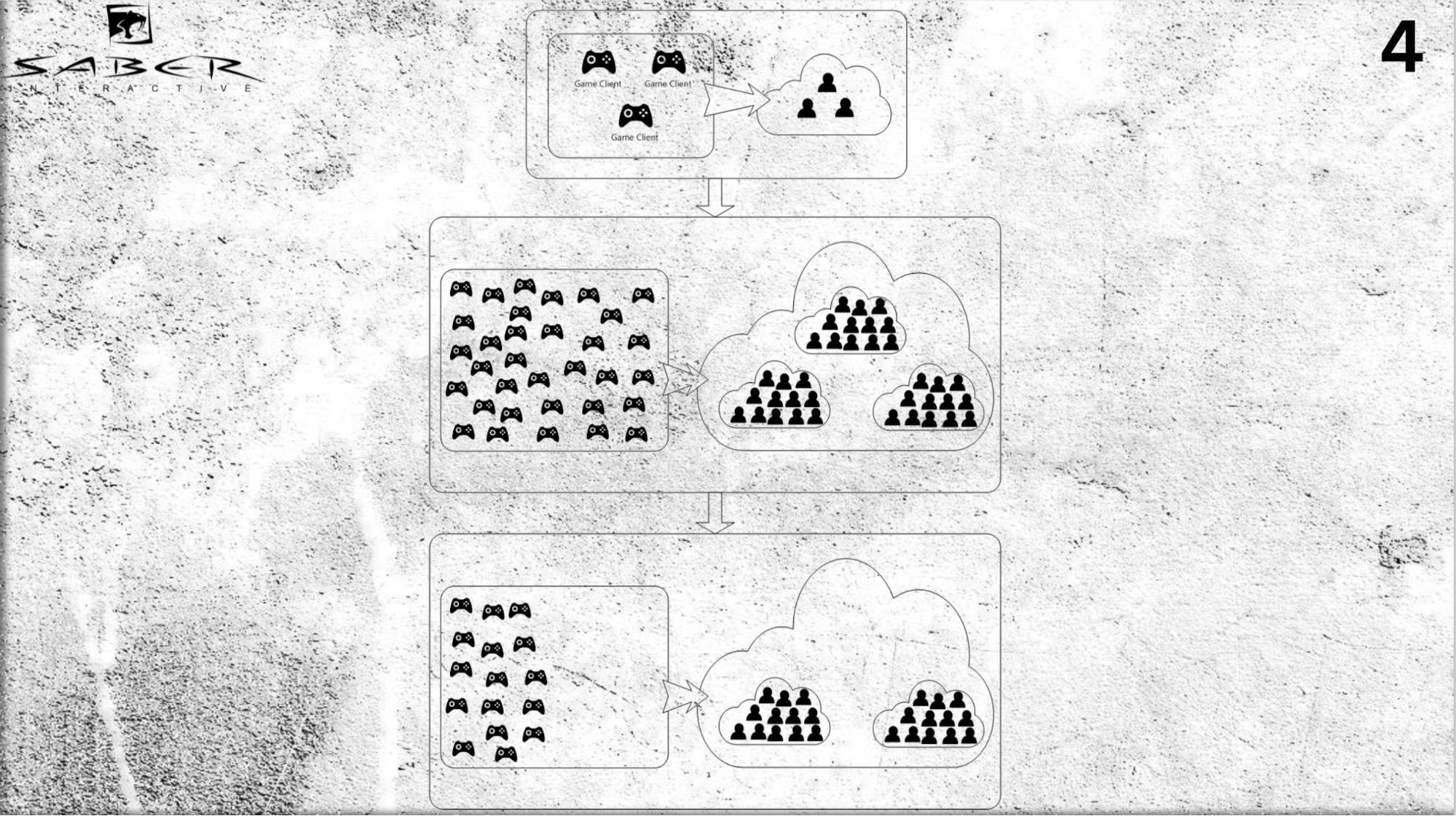
Nous pouvons ajouter des serveurs à notre cloud et, en utilisant le modèle d'acteur, pousser des utilisateurs individuels - affecter chaque acteur individuel et allouer de l'espace pour la mémoire et le temps processeur pour cet acteur dans le cloud.
Ainsi, l'acteur, d'une part, joue le rôle d'un cache, et d'autre part, c'est un «cache intelligent», qui peut traiter certains messages et exécuter la logique métier. Encore une fois, si vous devez faire une réduction d'échelle (par exemple, les joueurs sont partis) - il n'y a pas de problème non plus à retirer ces acteurs du système.
Dans le backend, nous n'utilisons pas le modèle d'acteur classique, mais basé sur le cadre d'Orléans. Quelle est la différence - je vais essayer de vous le dire maintenant.

D'abord, Orléans introduit le concept d'acteur virtuel ou, comme on l'appelle aussi, de grain. Contrairement au modèle d'acteur classique, où un service est chargé de créer cet acteur et de le placer sur certains serveurs, Orléans reprend le travail. C'est-à-dire si un certain service utilisateur demande une certaine note, Orléans comprendra lequel des serveurs est maintenant le moins chargé, il y placera l'acteur et retournera le résultat au service utilisateur.
Un exemple. Pour les céréales, il est important de connaître uniquement le type d'acteur, par exemple, les états des utilisateurs et l'ID. Supposons que l'ID utilisateur 777, nous obtenons la graine de cet utilisateur et ne réfléchissons pas à la façon de stocker cette graine, nous ne contrôlons pas le cycle de vie de la graine. Orléans, en elle-même, stocke en elle-même les chemins de tous les acteurs d'une manière très astucieuse. S'il n'y a pas d'acteur, il les crée, si l'acteur est vivant, il le renvoie, et pour les services aux utilisateurs, tout a l'air pour que tous les acteurs soient toujours vivants.
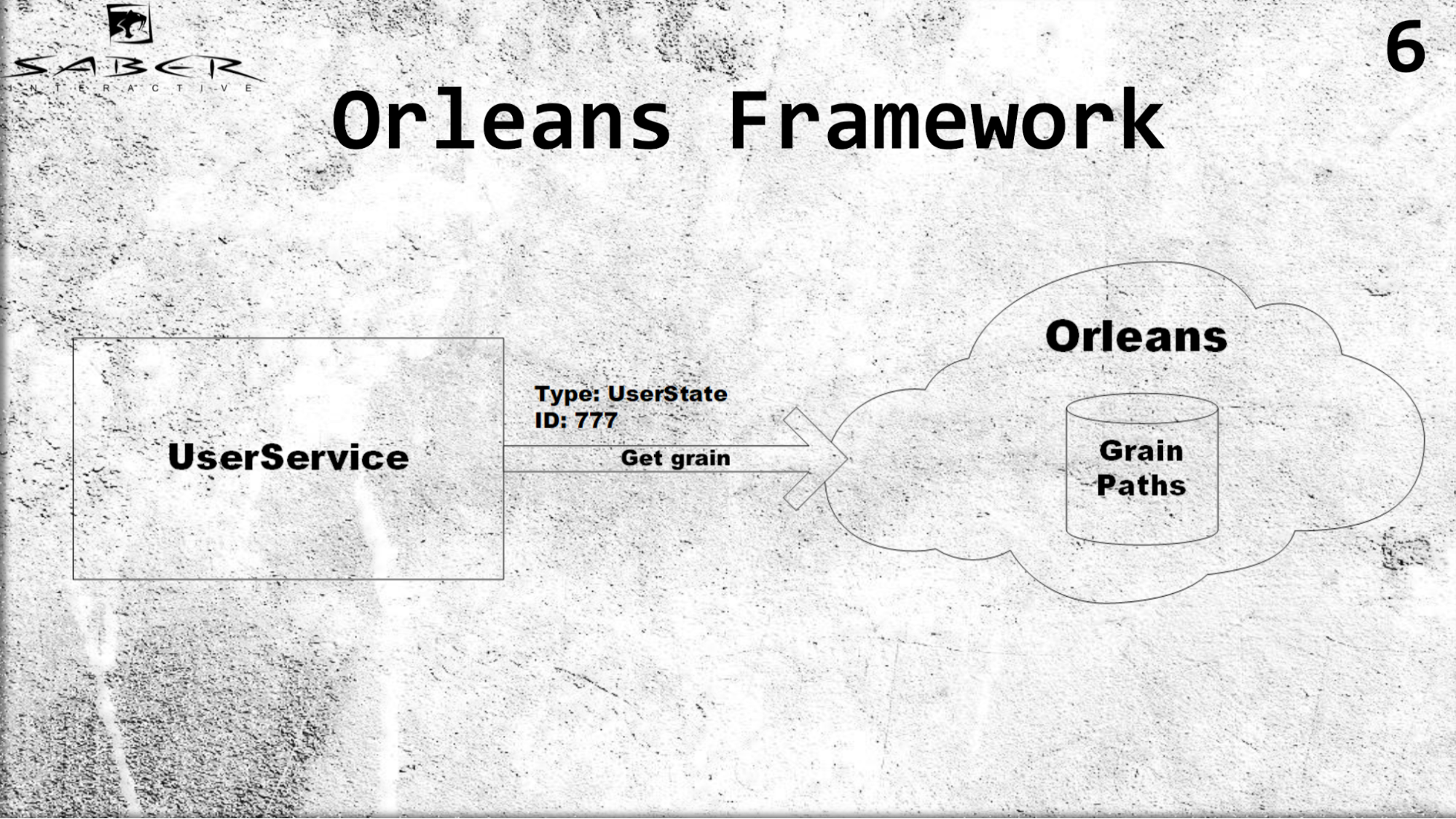
Quels avantages cela nous apporte-t-il? Tout d'abord, un équilibrage de charge transparent car le programmeur n'a pas besoin de gérer lui-même l'emplacement de l'acteur. Il dit simplement Orléans, qui est déployé sur plusieurs serveurs: donnez-moi un tel acteur depuis vos serveurs.
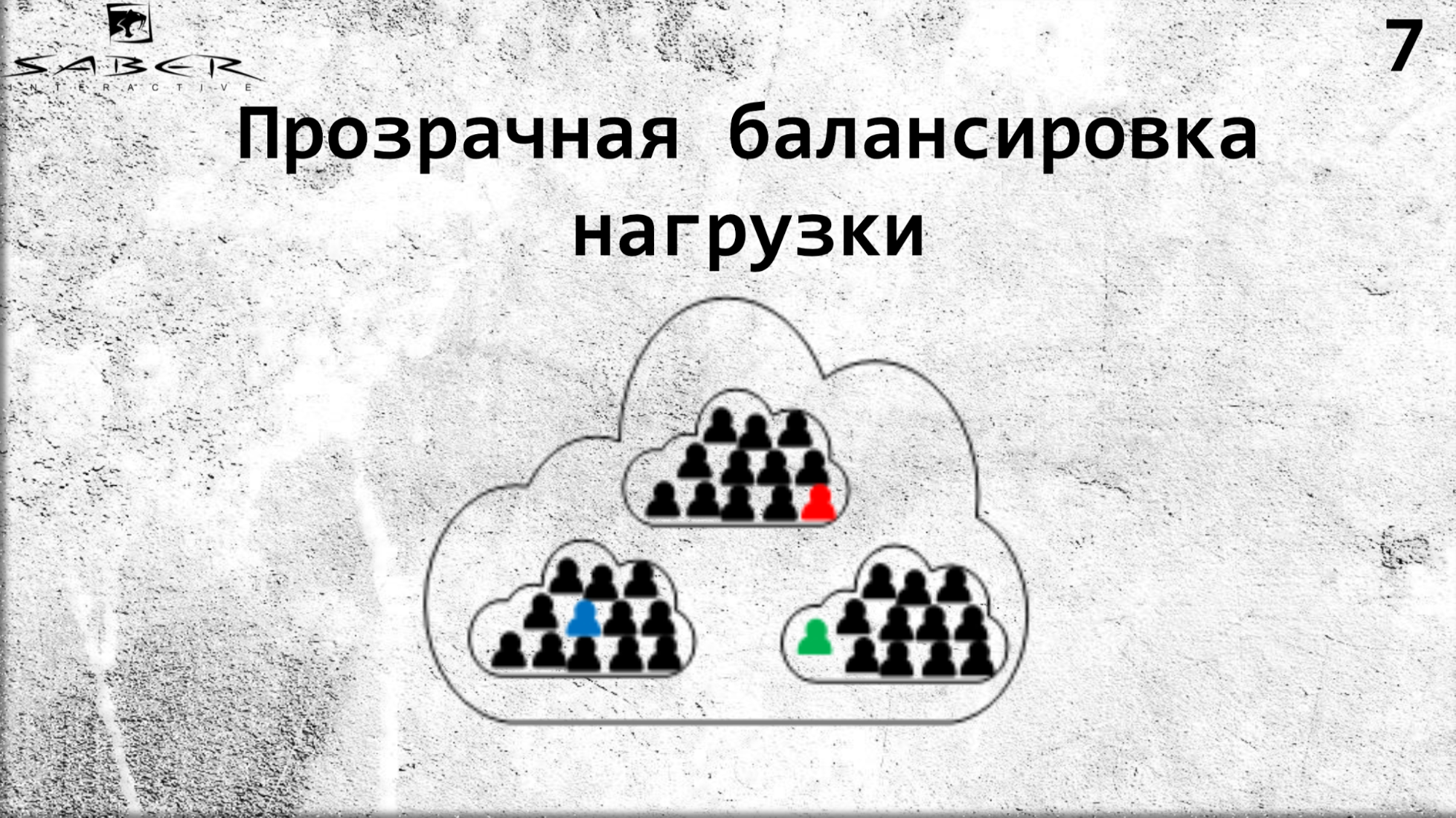
Si vous le souhaitez, vous pouvez réduire l'échelle si la charge sur le processeur et la mémoire est faible. Encore une fois, vous pouvez faire le haut de gamme dans la direction opposée. Mais le service n'en sait rien, il demande la graine, et Orléans lui donne cette graine. Ainsi, Orléans prend en charge les infrastructures pour le cycle de vie des grains.
Deuxièmement, Orléans gère les pannes de serveur.

Cela signifie que si dans le modèle classique le programmeur est responsable de gérer un tel cas par lui-même (ils ont placé l'acteur sur un serveur, mais ce serveur est tombé en panne, et nous devons nous-mêmes élever cet acteur sur l'un des serveurs en direct), ce qui ajoute plus de mécanique ou un travail de réseau complexe pour un programmeur, puis à Orléans, il semble transparent. Nous demandons une graine, Orléans voit qu'elle n'est pas disponible, la récupère (la place sur certains serveurs en direct) et la retourne au service.
Pour être plus clair, analysons un petit exemple de la façon dont un utilisateur lit une partie de son état.
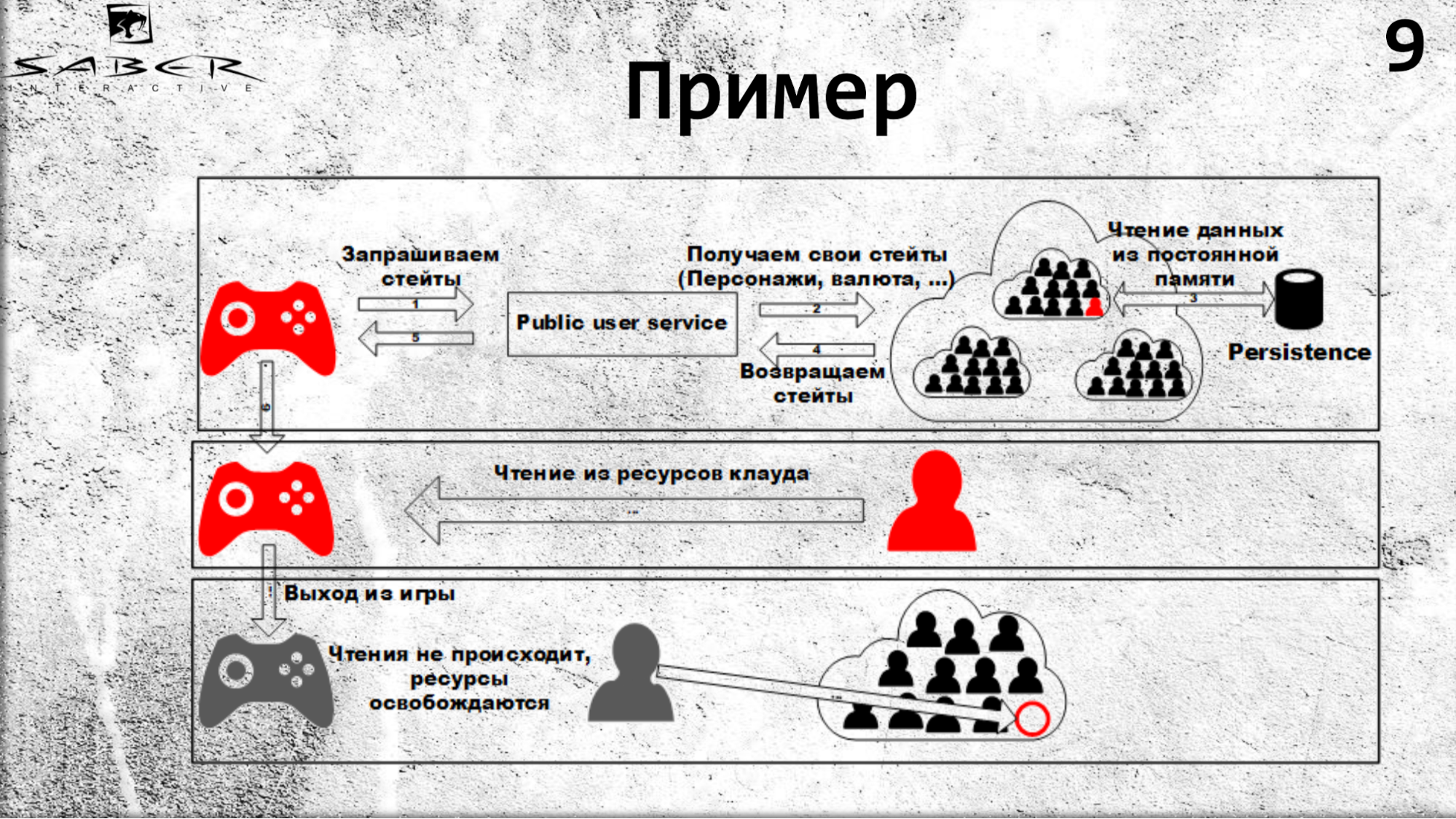
Un état peut être sa condition économique, qui stocke l'armure, les armes, la monnaie ou les champions de cet utilisateur. Afin d'obtenir ces états, il appelle le PublicUserService, qui se tourne vers Orléans pour l'état. Ce qui se passe: Orléans voit qu'il n'y a pas encore un tel acteur (c'est-à-dire, le grain), il le crée sur un serveur gratuit, et le grain lit son état dans un magasin Persistence.
Ainsi, la prochaine fois que vous lirez des ressources dans le cloud, comme indiqué dans la diapositive, toutes les lectures proviendront du cache cache. Dans le cas où l'utilisateur quitte le jeu, les ressources de lecture ne se produisent pas, donc Orléans comprend que le grain n'est plus utilisé par personne et peut être désactivé.
Si nous avons plusieurs clients (client de jeu, serveur de jeu), ils peuvent demander des états d'utilisateur, et l'un d'eux lèvera ce grain. Plus précisément, cela obligera Orléans à décrocher, puis tous les appels, comme nous le savons déjà, se produisent dans celui-ci de manière séquentielle. Tout d'abord, le client recevra l'état, puis le serveur de jeu.
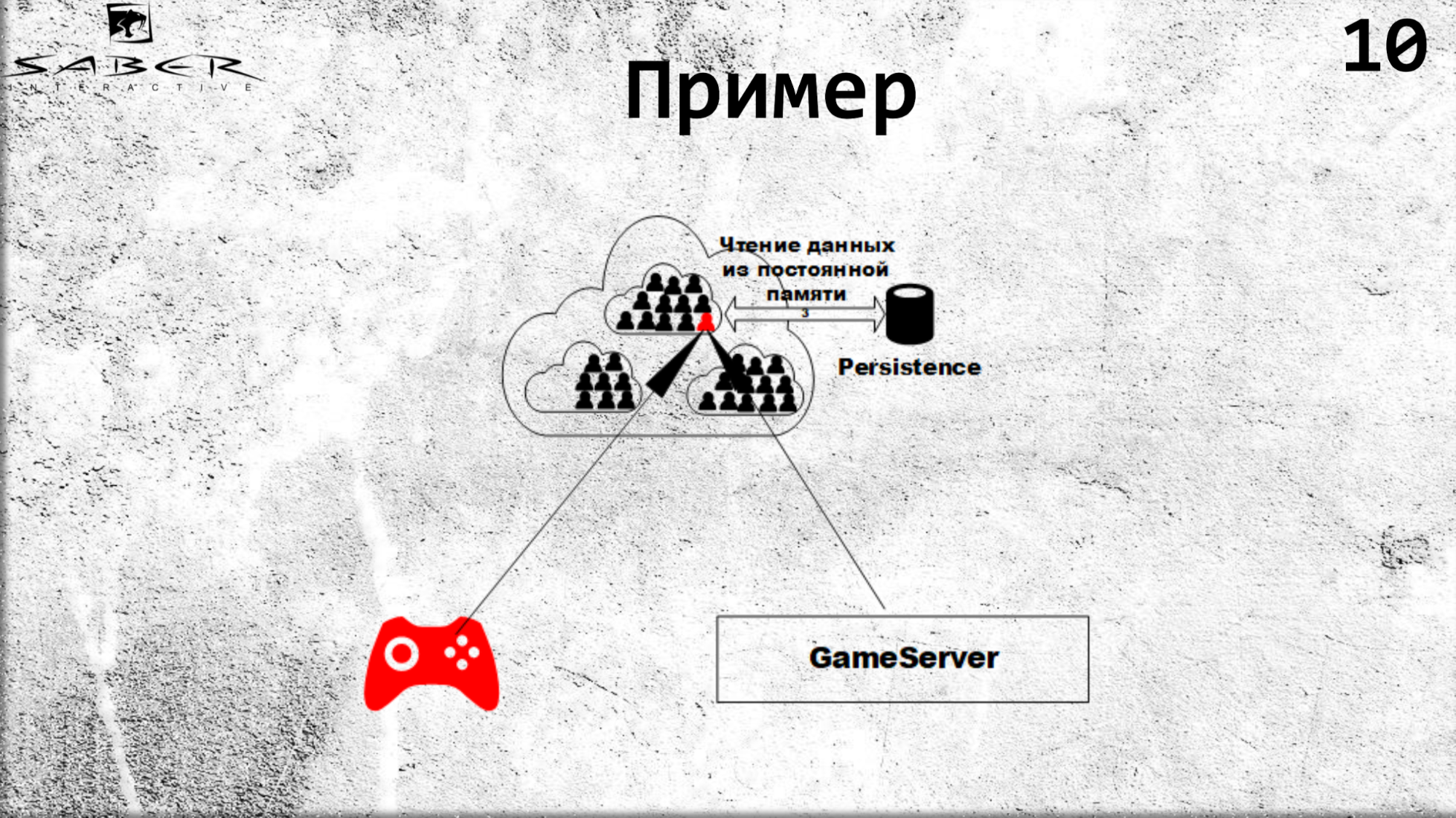
Le même flux sur la mise à jour. Lorsqu'un client souhaite mettre à jour un état, il transfère cette responsabilité au grain, c'est-à-dire lui dira: "donnez à cet utilisateur 10 pièces d'or", et le grain monte, il traite cet état avec une sorte de logique commerciale à l'intérieur du grain. Et puis vient la mise à jour du cache cache et, si vous le souhaitez, la persistance dans Persistence.

Pourquoi la persévérance est-elle requise ici? Ceci est un sujet distinct et il réside dans le fait que, parfois, il n'est pas particulièrement important pour nous que le Grain maintienne constamment ses états dans la Persistance. Si tel est l'état du joueur en ligne, nous sommes prêts à risquer de le perdre pour des raisons de productivité, s'il concerne l'économie, alors il faut être sûr que ses états sont préservés.
Le cas le plus simple: pour chaque appel d'état de sauvegarde, écrivez cette mise à jour dans Persistence. Ainsi, si le grayn tombe soudainement de manière inattendue, la prochaine élévation du grain sur certains des autres serveurs provoquera une mise à jour du cache avec les données actuelles.
Un petit exemple de son apparence.

Comme je l'ai dit précédemment, un grain se compose d'un type et d'une clé (dans ce cas, le type est IPlayerState, la clé est IGrainWithGuidKey, ce qui signifie qu'il s'agit de Guid). Et nous avons une interface que nous implémentons, c'est-à-dire GetStates retourne une liste d'états et ApplyState, lequel certains états s'appliquent. Les méthodes d'Orléans renvoient Task. Ce que cela signifie: la tâche est une promesse qui nous dit que lorsque l'État reviendra, la promesse sera en état résolu. Nous avons également certains PlayerState que nous obtenons avec GrainFactory. C'est-à-dire ici nous obtenons un lien, et nous ne savons rien de l'emplacement physique de ce grain. Lors de l'appel à GetStates, Orléans lèvera notre grain, lira l'état du magasin de persistance dans sa mémoire, et lorsque ApplyState appliquera un nouvel état, il mettra également à jour cet état à la fois dans sa mémoire et dans Persistance.
Je voudrais faire un exemple un peu plus complexe sur l'architecture de haut niveau de notre service UserStates.
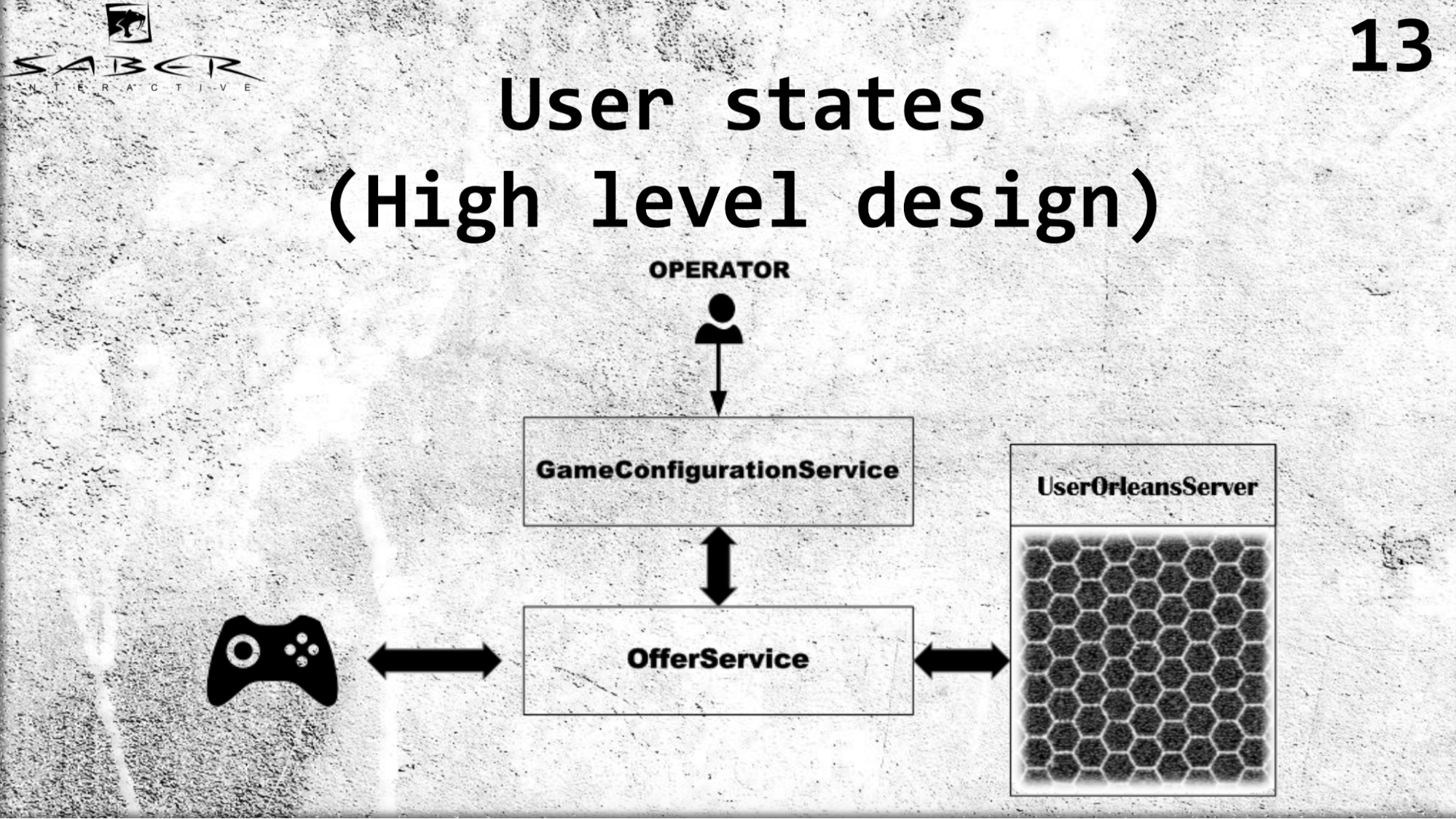
Nous avons une sorte de client de jeu qui obtient ses états via OfferSevice. Nous avons un GameConfigurationService, responsable du modèle économique d'un groupe d'utilisateurs, dans ce cas, notre utilisateur. Et nous avons un opérateur qui change ce modèle économique. Conformément à cela, l'utilisateur demande un OfferSevice pour recevoir ses états. Et OfferSevice accède déjà au service UserOrleans, qui se compose de ces grains, il soulève cet état de l'utilisateur dans sa mémoire, exécute éventuellement une sorte de logique métier et renvoie les données à l'utilisateur via OfferService.
En général, je voudrais attirer l'attention sur le fait qu'Orléans est bon pour sa grande capacité de parallélisme, car les grains sont indépendants les uns des autres. Et d'autre part, à l'intérieur de la graine, nous n'avons pas besoin d'utiliser des primitives de synchronisation, car nous savons que chaque appel à cette graine sera en quelque sorte cohérent.
Ici, je voudrais faire ressortir certains des pièges de ce modèle.

Le premier est trop grainé. Étant donné que tous les appels dans le greine sont thread-safe, l'un après l'autre, et si nous avons une logique grasse sur le greine, nous devrons attendre trop longtemps. Encore une fois, trop de mémoire est allouée pour un tel grain. Il n'y a pas d'algorithme exact pour déterminer la taille du grain, car un grain trop petit est également mauvais. Ici, il est plutôt nécessaire de partir de la valeur optimale. Je ne dirai pas exactement lequel, c'est au programmeur de décider.
Le deuxième problème n'est pas aussi évident - c'est la soi-disant réaction en chaîne. Lorsqu'un utilisateur lève des grains, et lui, à son tour, peut implicitement lever d'autres grains dans le système. Comment cela se produit: l'utilisateur reçoit ses statuts, l'utilisateur a des amis et il reçoit le statut de ses amis. Ainsi, l'ensemble du système garde tous ses grains en mémoire, et si nous avons 1000 utilisateurs, et chacun a 100 amis, alors 100 000 grains peuvent être actifs comme ça. Ce cas doit également être évité - en quelque sorte stocker les états des amis dans une sorte de mémoire partagée.

Eh bien, quelles technologies existent pour mettre en œuvre le modèle d'acteur. Peut-être le plus célèbre est Akka, qui nous est venu avec Java. Il existe un fork appelé Akka.NET pour .NET. Il y a Orléans, qui est open-source et qui est dans d'autres langues, comme implémentation. Il existe des primitives Azure telles que Service Fabric Actor - il existe de nombreuses technologies.
Questions du public
- Comment résolvez-vous des problèmes classiques comme le CICD, la mise à jour de ces acteurs, utilisez-vous Docker et est-ce vraiment nécessaire?- Nous n'utilisons pas encore Docker. En général, DevOps est engagé dans le déploiement; ils déploient nos services dans le service cloud Azure.
- Mise à jour continue, sans temps d'arrêt, comment ça se passe? Orléans décide lui-même sur quel serveur le serveur ira, sur quel serveur la requête ira et comment mettre à jour ce service. C'est-à-dire une nouvelle logique métier est apparue, une mise à jour du même acteur est apparue - comment se déroulent ces mises à jour?- Si nous parlons de mettre à jour l'ensemble du service, et si nous avons mis à jour une logique commerciale de l'acteur, nous pouvons déployer un service à la Nouvelle-Orléans pour cela. Habituellement, cela est résolu avec nos primitives appelées topologie. Nous avons déployé un service de la Nouvelle-Orléans, qui est pour l'instant vide, et sans acteur, afficher l'ancien service et le remplacer par un nouveau. Il n'y aura aucun acteur dans le système, mais à la prochaine demande de l'utilisateur, ces acteurs seront déjà créés. Il y aura probablement une sorte de pic au début. Dans de tels cas, la mise à jour a généralement lieu le matin, car le matin, nous avons le plus petit nombre de joueurs.
"Comment Orléans comprend-il que le serveur est tombé en panne?" Vous avez dit qu'il jetait rapidement les acteurs sur un autre serveur ...- Il a un pingator qui comprend périodiquement quels serveurs sont vivants.
- Ping-t-il spécifiquement un acteur ou un serveur?- Plus précisément, le serveur.
- Une telle question: une erreur s'est produite à l'intérieur de l'acteur, vous dites qu'il va pas à pas, à chaque instruction. Mais une erreur s'est produite et qu'arrive-t-il à l'acteur? Supposons une erreur non traitée. L'acteur est-il en train de mourir?- Non, Orleans lève une exception dans le schéma .NET standard.
- Écoutez, nous n'avons pas géré l'exception, l'acteur est apparemment décédé. Le joueur, je ne sais pas à quoi il ressemblera, mais alors que se passe-t-il? Essayez-vous de redémarrer cet acteur ou de faire quelque chose comme ça?- Cela dépend de quel cas cela dépend de quel cas. Par exemple récupérable ou non récupérable.
- C'est-à-dire Est-ce que tout est configurable?- Plutôt programmé. Nous gérons quelques exceptions. C'est-à-dire nous voyons clairement qu'un tel code d'erreur, et certains, comme les exceptions non gérées, sont déjà poussés plus loin.
- Avez-vous plusieurs Persistences - est-ce comme une base de données?- Persistance, oui, une base de données avec stockage persistant.
- Disons qu'une base de données a défini dans lequel (conditionnellement) l'argent du jeu. Que se passe-t-il si un acteur ne peut pas l'atteindre? Comment gérez-vous cela?- Tout d'abord, c'est le stockage. Pour le moment, nous utilisons Azure Table Storage, et de tels problèmes se produisent réellement - Le stockage se bloque. Dans ce cas, vous devez généralement le reconfigurer.
- Si l'acteur n'a pas pu obtenir quelque chose dans le stockage, à quoi ressemble le joueur? Il n'a tout simplement pas cet argent ou ferme-t-il immédiatement la partie?- Ce sont des changements critiques pour l'utilisateur. Étant donné que chaque service a sa propre gravité, dans ce cas, le service utilisateur est un état terminal et le client se bloque simplement.
- Il m'a semblé que les messages des acteurs passent par des files d'attente asynchrones. Comment est cette solution optimisée? Ça ne gonfle pas, ça ne fait pas raccrocher le joueur? N'est-il pas préférable d'utiliser une approche réactive?- Le problème des files d'attente dans les acteurs est assez bien connu, car nous ne pouvons clairement pas contrôler la taille de la file d'attente, vous avez raison. Mais Orléans, d'une part, assume une sorte de travail de gestion et, d'autre part, je pense que, simplement par timeout, l'accès à l'acteur tombera, c'est-à-dire nous ne pouvons pas atteindre l'acteur, par exemple.
- Et comment cela affectera-t-il le joueur?- Étant donné que le service utilisateur contacte l'acteur, il lèvera une exception de délai d'expiration et, s'il s'agit d'un service «critique», le client lèvera une erreur et fermera. Et si c'est moins critique, cela attendra.
- C'est-à-dire Avez-vous une menace DDoS? Un grand nombre de petites actions peuvent mettre un joueur? Disons que quelqu'un commence rapidement à inviter des amis, etc.- Non, il existe un limiteur de requêtes qui ne vous permettra pas d'accéder trop souvent aux services.
- Comment gérez-vous la cohérence des données? Supposons que nous ayons deux utilisateurs, nous devons prendre quelque chose de l'un et facturer quelque chose à l'autre, afin qu'il soit transactionnel.- Bonne question. Tout d'abord, Orleans 2.0 prend en charge la transaction d'acteur distribué - il s'agit de la première version. Plus précisément, il est déjà nécessaire de parler de l'économie. Et comme moyen le plus simple - dans la dernière Orléans, les transactions entre les acteurs sont mises en œuvre sans problème.
- C'est-à-dire Sait-elle déjà comment garantir la pérennité des données?- Oui.
Plus d'entretiens avec Pixonic DevGAMM Talks