Je n'aime pas ça quand il n'y a pas d'instructions simples étape par étape sur le réseau sans mots intelligents montrant comment ne pas faire les choses les plus évidentes. Par conséquent, sans introduction inutile aujourd'hui, je vais vous expliquer comment sauvegarder correctement un cluster SQL de basculement. Oui, c'est un cluster, pas un serveur SQL autonome. Beaucoup a été écrit à leur sujet, mais pour une raison quelconque, les clusters sont évités.
Et sans une longue introduction, nous considérerons notre laboratoire:
- Cluster Windows avec Windows Server 2012 r2 sous le capot et un certain nombre de nœuds. Pour plus de commodité, il n'y en a que deux dans mon laboratoire. Une question légitime se pose: pourquoi mettre un cluster sur un cluster? Je vais vous expliquer un peu plus bas.
- Trois disques sont connectés au cluster via iSCSI: un quorum, un disque avec une ou des bases, un disque pour les journaux. Vous pouvez faire plus, vous pouvez moins, ici comme vous le souhaitez. Parfois, vous l'aimez: deux disques locaux (un pour le système, un pour l'installation de SQL lui-même), un disque de quorum, un disque combiné pour la base de données racine et système, un disque pour la base, un disque pour les journaux, un disque pour TempDB et un disque pour les sauvegardes. Les ingénieurs système disent que c'est également correct. Mais je pense que le nombre de disques dont vous disposez ne jouera absolument aucun rôle. Si cela fonctionne pour vous, alors vous avez raison et bien fait.
- Chaque nœud a une instance SQL installée, ce qui comprend qu'il fait partie du cluster SQL, et le cluster Windows voit le rôle de SQL Server.
Maintenant - avant de commencer - convenons de deux choses importantes:
- Prenez une décision et arrêtez de douter (je voulais insérer ici une blague sur les bains publics, une croix et un slip, mais
censuré décidé de s'en passer). Une infrastructure ne doit être gérée que par une seule solution. Si vous utilisez la solution A pour la sauvegarde SQL et la solution B pour la sauvegarde de cluster, alors B ne doit en aucun cas toucher SQL. Ou il vaut mieux ne pas utiliser la solution A du tout, si B peut effectuer des sauvegardes granulaires des machines au niveau de l'application. Pourquoi? Imaginons que les deux applications puissent trankeytit les journaux SQL et le faire avec succès. SQL fonctionnera bien sûr, mais dans la prochaine sauvegarde, vous recevrez un message sur l'état incohérent du serveur dans le meilleur des cas, et dans le pire des cas, vous ne pourrez pas récupérer à partir du journal des transactions. - Je sais qu'il existe des "millénaires et mille" options pour les logiciels de sauvegarde, toutes sont sans aucun doute meilleures parce que input_reason_here , mais excusez-moi, je n'en écrirai qu'une seule qui ne peut pas faire cela pire que les autres, et peut-être même mieux.
C'est parti!
Ainsi, comme cela est déjà clair, nous allons sauvegarder l'intégralité des nœuds. La première question se pose immédiatement: pourquoi, si le cluster Microsoft SQL prêt à l'emploi nous offre un niveau de protection très, très décent contre les chutes? Par exemple, vous pouvez toujours retirer le rôle de SQL et des ressources à un autre nœud.
Ce raisonnement est vrai, mais l'option est manquée selon laquelle les nœuds eux-mêmes sont vulnérables. En bref: le cluster au niveau du système d'exploitation ferme les risques associés au fonctionnement du système d'exploitation d'une machine particulière, et le cluster SQL ferme les risques associés spécifiquement aux bases de données. Oui, et sauvegarder cette configuration est plus intéressant.
Imaginons qu'un malware crypto nous arrive et commence à poser les nœuds de cluster un par un. Ici, nous ne pourrons pas restaurer rapidement uniquement les fichiers de base de données. Et il y a aussi des mises à jour du système d'exploitation infructueuses, du matériel en train de mourir, etc.
Par conséquent, je propose de considérer que nous nous sommes mis d'accord sur la nécessité d'une sauvegarde de l'ensemble du serveur, et maintenant nous nous tournons vers les outils. Je vais écrire comment atteindre vos objectifs et être incroyable avec Veeam Backup & Replication 9.5 Il y a une autre version, Veeam était capable de sauvegarder uniquement les machines virtuelles de manière centralisée, mais maintenant il a reçu un support complet pour les sauvegardes des serveurs physiques, et c'est un péché de ne pas le comprendre.
Groupes de protection
Pour la sauvegarde, nous utiliserons le groupe de protection . Il s'agit en fait d'une simple entité logique - un conteneur où sont regroupées les machines à sauvegarder. Par exemple, vous pouvez regrouper plusieurs objets de AD et ne vous inquiétez pas que les nouvelles machines n'entreront pas en sauvegarde. Le groupe de protection analyse automatiquement les modifications et effectue les actions nécessaires restantes selon le calendrier spécifié. En un mot, une chose très pratique, surtout dans les grandes infrastructures mixtes.
Mais on passe des mots à l'action: on lance Veeam Backup & Replication , on va dans l'onglet Inventaire et on lance l'assistant de création de Protection Group

À la première étape, vous devez spécifier le nom du groupe et une description si nécessaire, tout est clair ici.
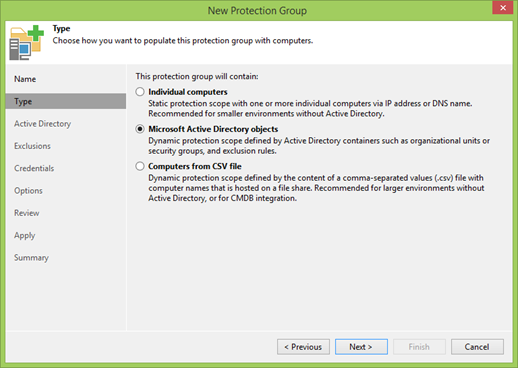
Mais à l'étape suivante, vous devez déjà choisir où le groupe de protection recevra les informations sur les machines protégées. Vous pouvez les ajouter à l'ancienne manuellement par des noms DNS ou IP, vous pouvez fournir une liste sous la forme d'un fichier CSV, comme le font les vrais Jedi, mais nous sommes des gens plus simples et nous utiliserons des objets Active Directory. Dans notre cas, cela signifie également que tous les nœuds du cluster seront détectés automatiquement, y compris les nouveaux.
À l'étape suivante, il vous sera d'abord demandé d'indiquer l'adresse du contrôleur de domaine, le port et les données utilisateur pour la connexion.
Si tout va bien, cliquez sur Ajouter et sélectionnez l'unité d'organisation dont vous avez besoin.
Un point important: il suffit d'ajouter un cluster! Il n'est pas nécessaire d'ajouter des nœuds séparés.
Mon cluster s'appelle WINCLU et je vais l'ajouter.
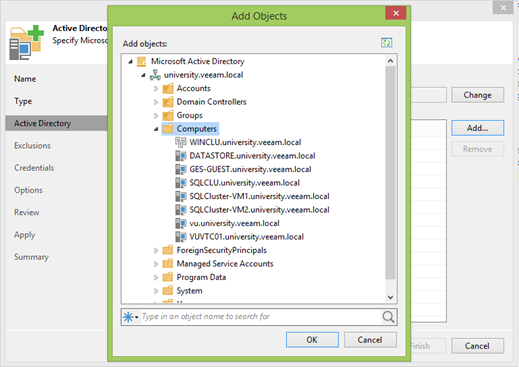
À l'étape suivante, des règles sont définies pour exclure les machines de l'analyse. Dans le monde moderne, les unités d'organisation contiennent souvent des machines virtuelles et physiques, et dans certains cas, elles sont sauvegardées dans différents scénarios. En fait, il existe même des clusters mixtes où des machines physiques et virtuelles sont utilisées. Une sorte de troisième niveau de protection.
Par défaut, les deux premières cases à cocher sont sélectionnées, et vous n'aurez peut-être pas besoin de les supprimer, mais mon laboratoire est complètement virtuel, et au début, nous avons convenu d'examiner la fonctionnalité de sauvegarde des machines physiques.
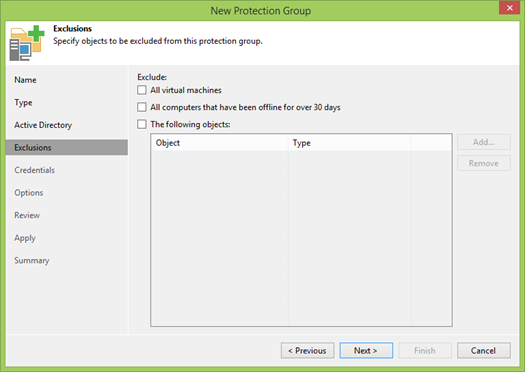
Nous devons maintenant spécifier quel utilisateur nous utiliserons. Dans certains cas idéaux, nous avons créé un utilisateur spécial dans AD qui a des droits d'administrateur local sur toutes les machines. Si ce n'est pas le cas, Veeam vous permet d'affecter un utilisateur distinct à chaque objet.
Pourquoi ai-je besoin d'un administrateur local?
- Tout d'abord, pour installer Veeam Agent sur chaque machine, qui gérera le processus de sauvegarde locale.
- Deuxièmement, pour que Veeam Agent effectue cette sauvegarde, il a besoin des droits d'administrateur local pour travailler avec VSS. Voilà comment fonctionne Windows, et il n'y a rien à faire à ce sujet.
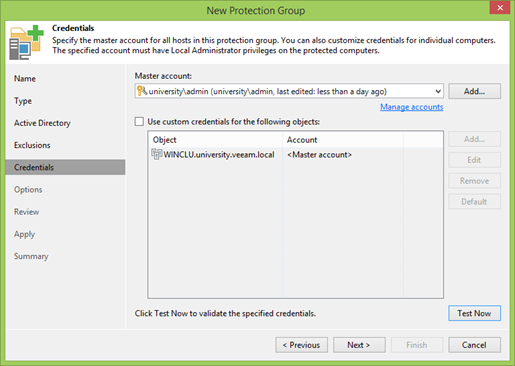
Séparément, vous devez vous concentrer sur le bouton Tester maintenant . Une grande chose qui vous permet de vérifier rapidement que tous les comptes sont entrés correctement et, dans le cas d'un cluster, assurez-vous à l'avance que tous les nœuds sont visibles et accessibles.
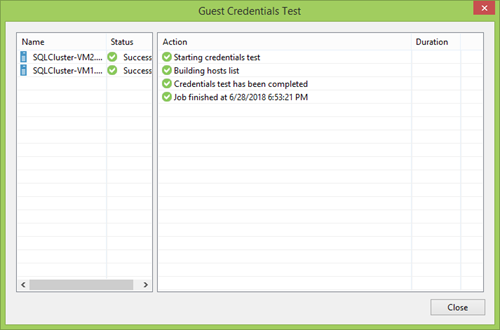
Ensuite, vous devez définir l'intervalle et l'heure de numérisation des participants PG. Vous pouvez le faire au moins une fois par semaine, mais vous pouvez configurer une mise à jour continue. Cela dépend de vous, mais généralement une excellente option consiste à répéter la fréquence de sauvegarde afin que tous les nouveaux participants puissent se rendre au point de récupération le plus proche.
Voici les options moins évidentes mais importantes.
Le serveur de distribution est la machine avec laquelle les agents Veeam seront installés. En général, il suffit d'utiliser le serveur Veeam Backup, mais dans les infrastructures géographiquement distribuées avec une mauvaise connexion, il est logique de spécifier une option plus proche. Dans tous les autres cas, changer n'a pas de sens.
Plus loin. Je ne connais pas les raisons pour lesquelles les agents ne devraient pas être installés ni mis à jour automatiquement, mais si vous ne faites pas confiance à l'automatisation, vous pouvez refuser en toute sécurité. Mais gardez à l'esprit qu'en raison de la différence de versions, vous pouvez vous retrouver sans autre point de sauvegarde.
Vous pouvez également accepter d'installer notre pilote CBT, qui suivra le changement de disques au niveau du système de fichiers. Cela vous permettra d'envoyer à la sauvegarde uniquement les secteurs réellement modifiés, ce qui signifie que le point de restauration est inférieur, la sauvegarde est plus rapide, la charge sur le serveur est moindre. Mais si vous ne faites pas confiance, le trafic n'est pas important pour vous, vos disques sont volumineux et la connexion est excellente, vous ne pouvez donc pas le configurer.
Il y a une nuance avec le redémarrage automatique: il est utilisé non seulement lors de la première installation, mais également lors des mises à jour. N'oubliez donc pas de décocher si vous ne pouvez pas vous permettre un tel luxe.
À l'étape suivante, nous serons informés de la nécessité de réinstaller les composants sur le serveur de distribution. Même s'ils ne sont pas là, dans une minute, ils seront là en cliquant sur le bouton Appliquer .
Lors de la dernière étape, nous serons informés que le groupe de protection (PG) a été créé avec succès et nous proposerons de lancer la découverte, c'est-à-dire le groupe selon les conditions spécifiées fera une liste de machines et selon les paramètres démarrera l'installation des agents. Pendant que toutes les opérations nécessaires auront lieu, vous pouvez aller vous verser du café.
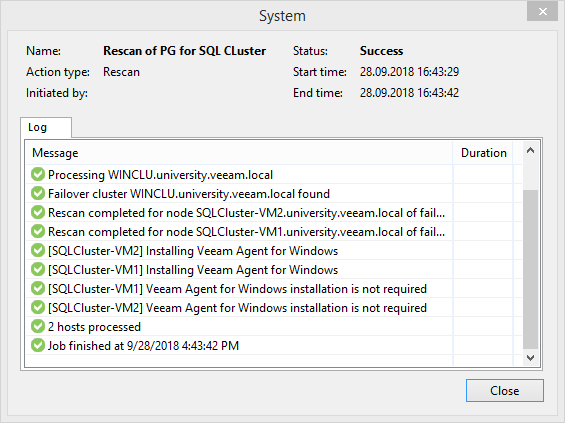
En vidant une tasse de café, vous pouvez constater qu'un agent n'a pas pu être installé sur l'un des nœuds en raison d'une erreur d'accès au réseau. Si un tel chagrin vous est arrivé, déconnectez simplement le disque de quorum de ce nœud. Pas souvent, mais ça arrive. Ou peut-être que ce n'est qu'une caractéristique de mon laboratoire. N'a donc pas eu la persévérance pour faire face à ce problème jusqu'à la fin.
Créer une sauvegarde
Donc, si à l'étape précédente tout s'est terminé avec succès, votre groupe de protection dispose désormais d'un cluster et d'une liste de ses nœuds avec des agents installés avec succès. Par conséquent, nous nous tournons vers le plus intéressant: nous créons une sauvegarde en mode cluster de basculement afin que tous les nœuds et tous les disques attachés y entrent.
Quelle est la principale différence et pourquoi vous ne pouvez pas simplement les enregistrer en tant que machines distinctes? Techniquement, vous pouvez le faire avec tous les nœuds sauf un - le détenteur actuel du rôle de cluster. Si vous commencez à le sauvegarder directement sur le front, les autres nœuds peuvent perdre contact avec lui et commencer à tirer la couverture sur eux-mêmes, ce qui entraînera finalement l'effondrement et l'arrêt de l'ensemble du cluster. Cela se produit très souvent sur des systèmes occupés.

En utilisant le bouton droit de la souris (RMB), en cliquant sur PG, nous lançons l'assistant de création de tâche de sauvegarde et sélectionnons immédiatement le mode de cluster de basculement . Ces tâches ne peuvent être créées que sur le serveur de sauvegarde central, contrairement aux sauvegardes d'agent local. Mais cela est logique: comme vous vous en souvenez, nous voulions sauvegarder SQL intégralement en même temps, ce qui signifie que les journaux seront régulièrement tranchés - pour lesquels, en tout cas, vous aurez besoin d'une communication entre les serveurs.
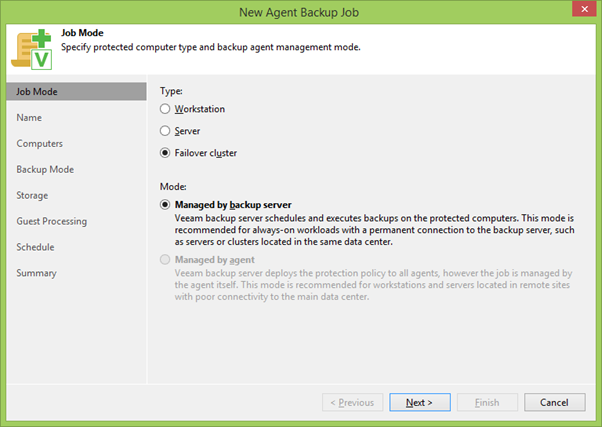
Sélectionnez ensuite le nom du travail et la liste des participants de sauvegarde. Par défaut, il n'y aura que la PG sélectionnée, mais ici vous pouvez également ajouter quelque chose de plus.
À l'étape suivante, vous devez choisir entre la sauvegarde de disques individuels ou la machine entière. En général, si vous pouvez sauvegarder l'intégralité de la machine, vous devez sauvegarder l'intégralité de la machine. Dans notre cas, cela est vrai, car nous devons sauvegarder tous les disques du cluster qui peuvent apparaître sur n'importe quel nœud de notre cluster.
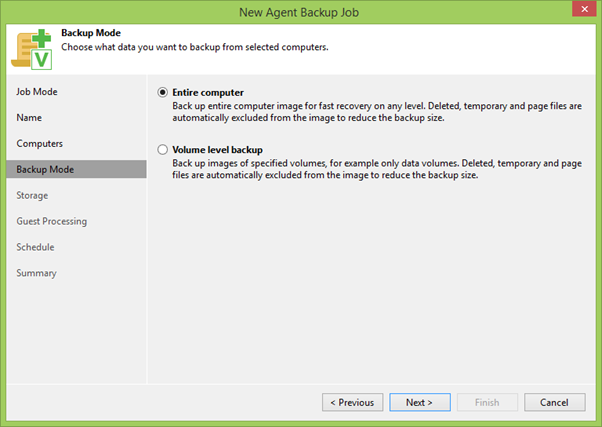
Ensuite, nous sélectionnons un référentiel pour les sauvegardes et spécifions le nombre de points de récupération que nous aurons. En utilisant le bouton Avancé , vous pouvez appeler le menu de réglage fin, où vous pouvez choisir comment créer une chaîne de sauvegarde, activer des vérifications d'intégrité de fichier supplémentaires et bien plus encore, ce que nous ne perdrons pas de temps maintenant, car la section la plus intéressante est la section Traitement invité .

Cela dépend des paramètres de cet onglet si nous pouvons obtenir la sauvegarde dite cohérente des applications (qui est parfois traduite comme une sauvegarde intégrale ou comme une sauvegarde tenant compte de l'état des applications, ou si nous ne comprenons pas encore comment et, surtout, pourquoi). Par conséquent, allez dans Applications , sélectionnez notre PG et cliquez sur Modifier .

Assurez-vous que le premier onglet inclut le traitement adapté aux applications . Dans ce cas, le sous-système VSS sera impliqué, dont le travail devrait se passer sans erreur. Au contraire, cela peut fonctionner avec des erreurs, mais dans ce cas, la sauvegarde ne sera pas créée et vous devrez comprendre les causes de l'échec. Ici, vous devez également déterminer le sort des journaux de transactions: Veeam peut les ignorer, simplement copier pour sauvegarder ou recadrer.
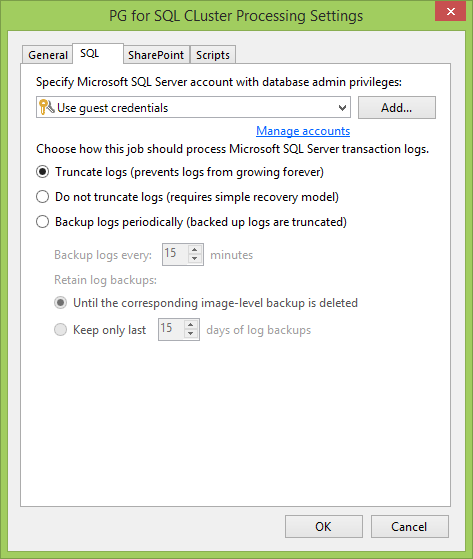
Allez maintenant dans l'onglet SQL . La première chose à faire est de définir le compte d'utilisateur pour l'interaction avec le serveur SQL et ses bases de données. Dans un monde idéal, il correspond à l'administrateur local que nous avons spécifié lors de la création de la PG. Sinon, l'essentiel est que cet utilisateur doit disposer des droits de propriétaire de bases de données .
Ensuite, nous choisissons comment nous allons interagir avec les journaux. Par exemple, si vous avez une base de données en mode de récupération complète , il est très pratique de triturer les journaux. Vous pouvez également sauvegarder les journaux de transactions selon une planification distincte afin de pouvoir restaurer rapidement la base de données au bon moment et ne pas perdre tout ce qui se trouvait entre les sauvegardes. Bien sûr, vous ne pouvez rien faire avec les journaux.
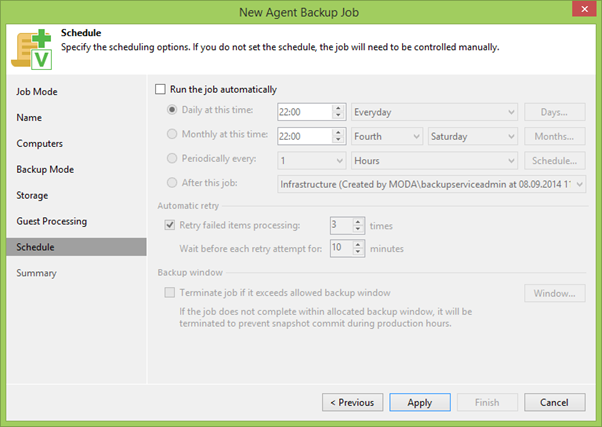
Nous passons à l'avant-dernier point du calendrier , où nous définissons le calendrier en fonction de vos besoins. C'est assez pour quelqu'un une fois par jour, quelqu'un une fois par heure, c'est à vous.
Nous terminons la tâche en cliquant sur Appliquer plusieurs fois et apprécions le résultat.
Dans un monde idéal, si vous n'avez aucune astuce pour installer des agents qui fonctionnent comme un lien entre le cluster et Veeam Server, ou si vous avez soudainement oublié de charger la licence nécessaire pour les agents, le travail fonctionnera parfaitement et vous verrez l'image suivante.
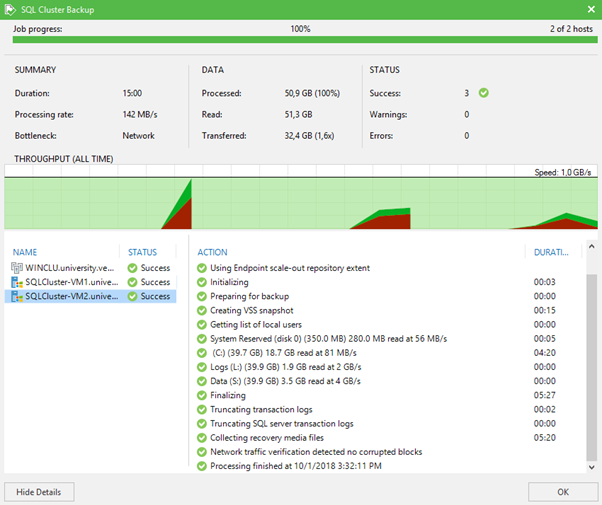
C’est tout. Il s'avère que les clusters de sauvegarde ne sont pas aussi effrayants que d'habitude. Même s'il s'agit d'un cluster à l'intérieur d'un autre cluster.
Si vous souhaitez en savoir plus sur un autre scénario de sauvegarde / restauration, écrivez-le dans les commentaires et nous vous dirons tout de la meilleure façon possible.