"Certaines personnes nous appellent" Plyushkins "- j'aime dire que nous sommes des archivistes."
Le directeur de Wayback Machine, Mark Graham, décrit l'échelle des archives préférées de tous
 Regardez Wayback Machine à Online News Association 2018Austin, Texas.
Regardez Wayback Machine à Online News Association 2018Austin, Texas. Peu importe à quel point les services d'abonnés ne veulent pas vous convaincre de cela, mais tout ne peut pas être trouvé sur Amazon ou Netflix. Vous voulez, par exemple,
lire le livre du juge Brett Cavanaugh (ou même leur
fameux annuel )? Curieux de voir un tas d'
affiches publicitaires vintage pour fumer ? Que diriez-vous de voir
la plus grande collection de littérature bouddhiste tibétaine au monde ? Aujourd'hui, il y a un endroit où vous pouvez faire tout cela, et ce n'est pas Google ou certains sites pirates que vous visitez (souvent).
«J'ai une vidéo du gouvernement sur la façon de se laver les mains ou de se préparer à une guerre nucléaire », explique Mark Graham, directeur de Wayback Machine aux Archives Internet. "Nous pourrions facilement faire une liste de fichiers .ppt sur tous les sites avec le domaine .mil, Military Industrial PowerPoint Complex."
Graham a récemment parlé avec plusieurs petits groupes de participants à la conférence 2018 de la Online News Association et Ars Technica a eu la chance d'être là. Il a ensuite fait une présentation complète de la conférence, qui est maintenant
disponible en format audio . Et l'idée de base est que l'échelle des archives Internet d'aujourd'hui peut être aussi difficile à comprendre que l'échelle d'Internet elle-même.
L'espace physique à but non lucratif est toujours facile à comprendre, du moins c'est ce que Graham voulait qu'il soit. Aujourd'hui, toutes les activités d'Internet Archive sont réalisées dans une ancienne église (même les bancs n'ont pas été retirés) à San Francisco par environ deux cents personnes. L'archive contient également l'entrepôt le plus proche pour stocker des supports physiques, non seulement des livres, mais aussi des choses telles que des disques vinyle. Graham plaisante en disant que l'unité de mesure principale est le «conteneur pour la livraison». Les archives reçoivent cette quantité de matériel toutes les deux semaines.
La société est actuellement le deuxième plus grand scanner de livres au monde, après Google. Graham a veillé à ce que le nombre actuel d'analyses atteigne plus de quatre millions. L'archive a même une liste de souhaits pour ses 1,5 million de scans suivants, y compris tout ce qui est cité sur Wikipedia. La Wayback Machine essaie de vous protéger contre l'apparition d'une
erreur 404 en cliquant sur les liens de Wikipédia (Graham a récemment déclaré à la BBC que les robots Wayback ont récupéré près de six millions de pages perdues en raison de l'échec des liens pour cela). Aujourd'hui, les livres publiés avant 1923 peuvent être téléchargés gratuitement via Internet Archive, et vous pouvez plus tard emprunter une copie numérique de bon nombre de ces livres.
Traduction de Tweet:
Archive Internet: plus de 9 millions de liens incorrects sur Wikipédia corrigés
WikiResearch: Si reconnaissants pour le travail extraordinaire que nos amis de @internetarchive font pour traiter l'erreur 404 et enregistrer numériquement des millions de liens vers des sites et des sources cités par les Wikipédiens alors qu'ils créent la plus grande encyclopédie du monde.
Bien sûr, de nos jours, Internet Archive offre bien plus que du texte. Sa collection d'actualités couvre plus de 1,6 million de programmes d'actualités avec des outils tels que la possibilité de rechercher des mots dans les sous-titres et d'accéder aux dernières nouvelles (les émissions sont disponibles après 24 heures, puis fournies aux visiteurs sous la forme de passages consultables de deux minutes). La partie croissante de l'audio et de la musique des archives Internet couvre les actualités radio, la baladodiffusion et les médias physiques (par exemple, une collection de
200 000 exemplaires des 78 récemment donnés par la bibliothèque de Boston). Et, comme l'écrit Ars, l'organisation dispose d'
une vaste collection classique de jeux vidéo que n'importe qui peut télécharger sur un émulateur basé sur un navigateur pour la recherche ou les loisirs. Officiellement, cette section comprend environ 300 000 titres et plus, «afin que vous puissiez jouer à Oregon Trail sur votre ancien ordinateur Apple C dans votre navigateur dès maintenant - pas de publicité, pas de suivi des utilisateurs», explique Graham.
«Certains peuvent nous appeler Plyushkins», dit-il. "J'aime dire que nous sommes archivistes."
En général, Graham dit que quatre pétaoctets d'informations par an sont ajoutés aux archives Internet (soit quatre millions de gigaoctets pour le contexte). Les données actuelles de l'organisation sont de 22 pétaoctets, mais Internet Archive possède en fait 44 pétaoctets. «Parce que nous sommes paranoïaques», explique Graham. «Les voitures peuvent échouer et nous avons une réputation.» Ce credo inspiré de la
NASA a aidé une organisation à but non lucratif à survivre aux dommages causés par un incendie, qui a
coûté près de 600 000 $ - le tout sans perdre de données d'archives.
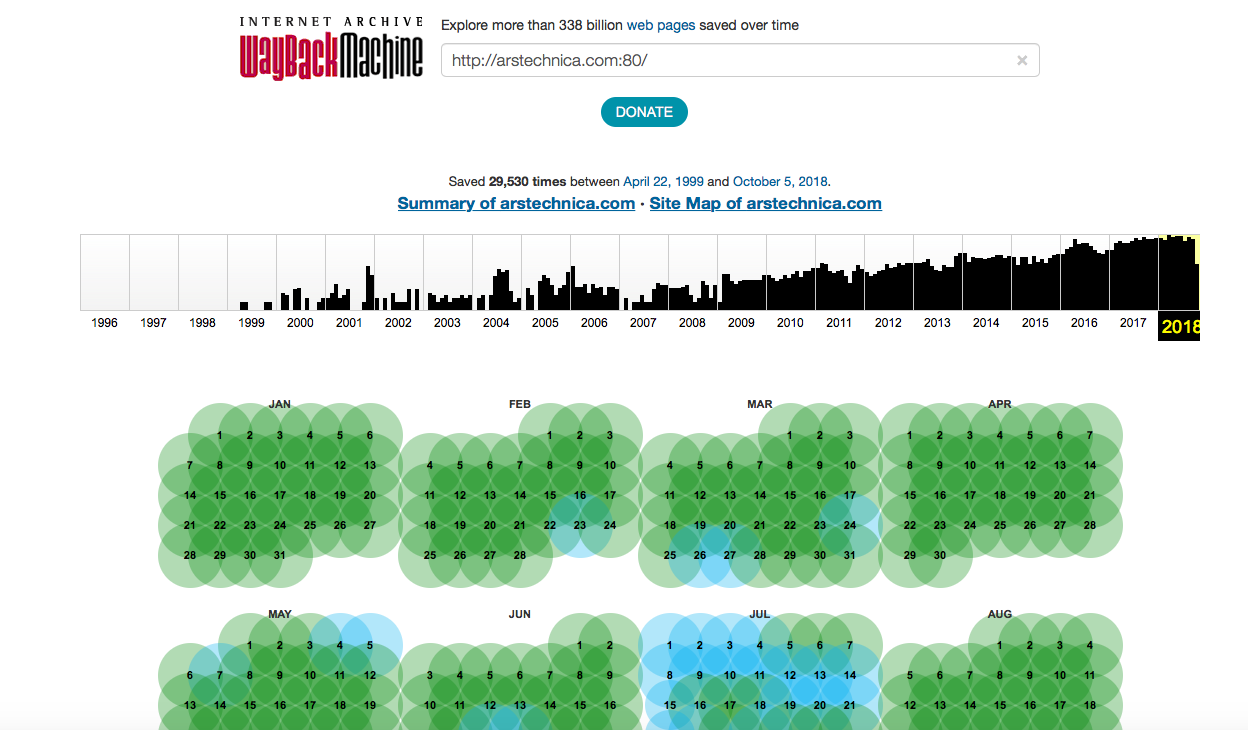 30 000 entrées? Pas mal, et il semble que les robots Wayback Machine ont certainement accru leur affection pour Ars.
30 000 entrées? Pas mal, et il semble que les robots Wayback Machine ont certainement accru leur affection pour Ars.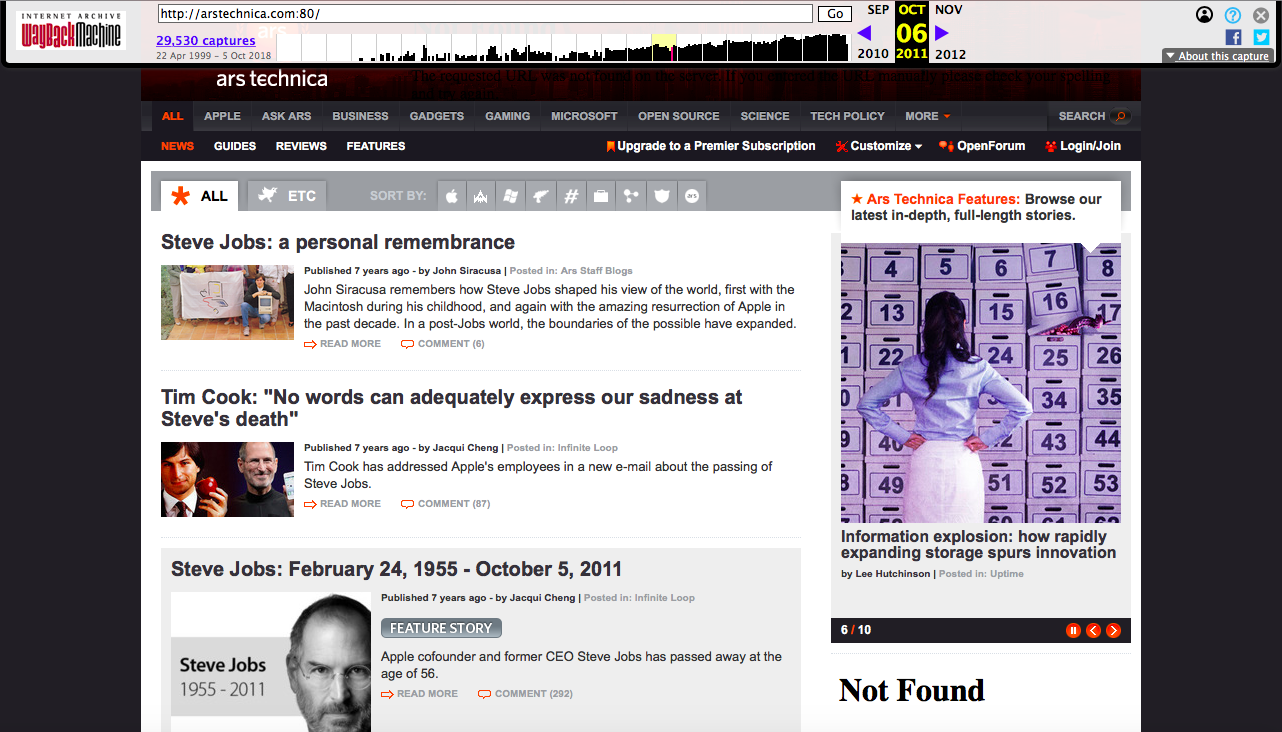 Avec la Wayback Machine, vous pouvez vous souvenir et réfléchir à la façon dont Ars a caché la mort de Steve Jobs en octobre 2011.
Avec la Wayback Machine, vous pouvez vous souvenir et réfléchir à la façon dont Ars a caché la mort de Steve Jobs en octobre 2011. Hmm ... j'ai peut-être encore une chance de devenir un Arsien / Arsien pour télécharger le 1000e PDF capturé par Internet Archive.
Hmm ... j'ai peut-être encore une chance de devenir un Arsien / Arsien pour télécharger le 1000e PDF capturé par Internet Archive.Accès universel aux connaissances (et aux faits, à un grand nombre de faits)
Le concept général des archives Internet au cours des 22 dernières années a été simple:
«l'accès universel à toutes les connaissances» . À l'ère d'Internet, cela signifie, bien sûr, l'introduction d'une petite armée de robots, et Graham note qu'Internet Archive a toujours un logiciel qui recueille le contenu. Environ 7 000 processus simultanés s'étendent sur l'ensemble du réseau pour finalement recevoir 1,5 milliard d'articles différents par semaine. Certaines choses, comme la page d'accueil de Google ou le New York Times, peuvent être consultées plusieurs fois par jour; d'autres peuvent être consultés moins fréquemment.
«Nous essayons de tout obtenir, mais c'est difficile», note Graham. «Intégrations, javascripts, applications interactives - nous ne pouvons pas obtenir certains de ces documents, mais nous y travaillons.»
Le cache des choses sur lesquelles nous travaillons comprend des médias éphémères tels que Snapchat ou des groupes publics Telegram, et la Wayback Machine maintient des contacts locaux dans des endroits où certaines archives ou serveurs multimédias peuvent être en danger (Graham note récemment des partenaires dans Egypte, par exemple).
Le résultat de tout cela est que la Wayback Machine est devenue quelque chose de beaucoup plus utile que les amusants voyages passés à LiveJournals. Ars l'a utilisé à plusieurs reprises à des fins diverses, allant de la
capture des changements dans la neutralité nette de Comcast au fait que la description organisationnelle de Defence Distributed a évolué. Et Graham souligne une récente
controverse en 2018 lorsque le président Trump a tweeté que Google ne promeut pas de bonnes relations avec les États-Unis d'Amérique sur sa page d'accueil (comme c'était le cas par le passé). Avant que Google ne puisse répondre à cette question, la société s'est tournée vers Internet Archive avec une question simple - en existe-t-il une copie?
"J'adore Google, mais leur travail n'est pas de faire des copies de la page d'accueil toutes les 10 minutes", explique Graham. "C'est notre travail."
Graham a indiqué que Wayback Machine avait en fait saisi 835 copies de la page d'accueil de Google en janvier 2018. «De cette façon, nous avons pu aider à ramasser les records. Nous ne prenons pas parti, mais nous sommes pour la vérité. »
Le site a joué un rôle similaire lorsque la Maison Blanche a récemment
supprimé toutes les archives de ses newsletters , et un certain nombre d'organisations (non seulement des organisations de presse, mais aussi des organisations environnementales ou des ACLU) en avaient besoin. Et le matériel obtenu de Wayback Machine a
été utilisé comme preuve devant le tribunal . «Il y a de nombreux événements qui se produisent en termes de temps», ajoute-t-il. En tant qu'ancien vice-président de NBC News (d'où son désir d'assister à l'ONA, peut-être), Graham souligne également avec fierté que le site est référencé environ cinq fois par jour par les médias.
Graham dit que Wayback Machine travaille dur pour améliorer ses outils utilisateur afin d'améliorer le site. En bas à gauche de la page d'accueil de Wayback Machine, vous trouverez, par exemple,
des API publiques . Graham souligne que les gens les utilisent pour créer des choses comme un
différenciateur , où vous pouvez prendre deux numérisations, les placer côte à côte et voir les changements. Un autre outil créé par l'utilisateur, qui a attiré son attention, vous permet de regarder le site et de faire un
arbre radial pour voir comment sa structure évolue dans le temps .
Bien que l'outil le plus simple et le plus efficace pour tout le monde soit la technologie directement issue de Wayback Machine - le site permet à quelqu'un d'envoyer manuellement un lien vers les archives Internet pour l'archivage directement depuis sa page d'accueil. «Si je promène mon chat dans le jardin et que je vois une histoire sur Google Actualités, vous pouvez l'imprimer. Mais aujourd'hui, vous pouvez également l'envoyer aux archives Internet », explique Graham. Selon ses estimations, le résultat pourrait être d'environ un million de tirs par semaine.
«Nous recherchons des informations sur un très grand réseau sans tricher», dit-il. Et peu importe que quelque chose soit trouvé par des robots ou un utilisateur amateur dédié des archives, tout le monde peut simplement apprécier la capacité de trouver du contenu, ce qui est d'ailleurs la
mission originale d'Ars Technica . (Heureusement, après 20 ans, personne ne nous a encore informés de "
très mauvaises choses comme le contenu NT, Linux et BeOS sous un même toit.")
Traduction: Diana Sheremyova

À propos de #philtechLes #philtech (technologies + philanthropie) sont des technologies ouvertes et décrites publiquement qui alignent le niveau de vie du plus grand nombre possible de personnes en créant des plateformes transparentes pour l'interaction et l'accès aux données et aux connaissances. Et satisfaisant les principes de la filtech:
1. Ouvert et répliqué, non concurrentiel.
2. Construit sur les principes d'auto-organisation et d'interaction horizontale.
3. Durable et orienté vers la perspective, plutôt que de rechercher des avantages locaux.
4. Construit sur des données [ouvertes], pas sur les traditions et les croyances
5. Non violent et non manipulateur.
6. Inclusif et ne travaillant pas pour un groupe de personnes au détriment des autres.
PhilTech Accelerator of Social Technology Startups est un programme de développement intensif pour des projets en phase initiale visant à égaliser l'accès à l'information, aux ressources et aux opportunités. Le deuxième volet: mars - juin 2018.
Chat en télégrammeUne communauté de personnes développant des projets filtech ou simplement intéressés par le thème de la technologie pour le secteur social.
#philtech newsChaîne télégramme avec des nouvelles sur des projets dans l'idéologie #philtech et des liens vers des documents utiles.
Abonnez-vous à la newsletter hebdomadaire