La commande de vitesse Yandex optimise manuellement les résultats de la recherche. Le faire à l'aveuglette est difficile et souvent tout simplement inutile. Par conséquent, la société a construit une infrastructure pour collecter des métriques, tester la vitesse et analyser les données.
À propos des mesures à utiliser et de la façon d'optimiser tout, le développeur des interfaces Yandex
Andrei Prokopyuk (
Andre_487 ) le
sait .

Le matériel est basé sur le discours d'Andrey lors de la conférence
HolyJS . Sous la coupe - et la vidéo, et une version texte du rapport.
En plus de ce rapport sur les mesures en ligne, il y a un rapport d'Alexei Kalmakov (également de Yandex) sur les mesures hors ligne, dans son cas il n'y a pas de version texte, mais une vidéo est disponible.
Les résultats de recherche Yandex se composent de nombreux blocs différents, de classes de réponses aux requêtes des utilisateurs. Plus de 50 personnes y travaillent dans l'entreprise, et pour que le taux d'émission ne baisse pas, nous veillons en permanence au développement.
Personne ne dira que les utilisateurs préfèrent l'interface rapide à l'interface lente. Mais avant de commencer l'optimisation, il est important de comprendre comment cela affectera votre entreprise. Les développeurs doivent-ils passer du temps à accélérer l'interface si cela n'affecte pas les mesures commerciales?
Pour répondre à cette question, je vais vous raconter deux histoires.
Historique de l'introduction d'une police web spécifique sur l'émission
Après avoir établi une expérience avec les polices, nous avons constaté que le temps moyen de rendu du contenu s'est détérioré de 3%, de 62 millisecondes. Pas tellement si vous le prenez pour un delta dans le vide. Le retard perceptible à l'œil nu commence avec seulement 100 millisecondes - et pourtant le temps jusqu'au premier clic a immédiatement augmenté d'un pour cent et demi.

Les utilisateurs ont commencé à interagir plus tard avec la page. Le nombre de pages cliquées a diminué de près d'un demi pour cent. Le temps de présence sur le service a été réduit et le temps d'absence a été augmenté.

Nous n'avons pas commencé à déployer la fonctionnalité avec les polices. Après tout, ces chiffres semblent petits jusqu'à ce que vous vous souveniez de l'ampleur du service. En réalité, un et demi pour cent - des centaines de milliers de personnes.
De plus, la vitesse a un effet cumulatif. Pour une mise à jour avec une part de non réclamés - 0,4% suivra de plus en plus. Dans Yandex, ces fonctionnalités sont déployées par dizaines par jour, et si vous ne vous battez pas pour chaque part, cela ne durera pas longtemps et atteindra 10%.
Historique de la mise en cache LS
Cette histoire est liée au fait que nous insérons beaucoup de contenu statique dans la page.
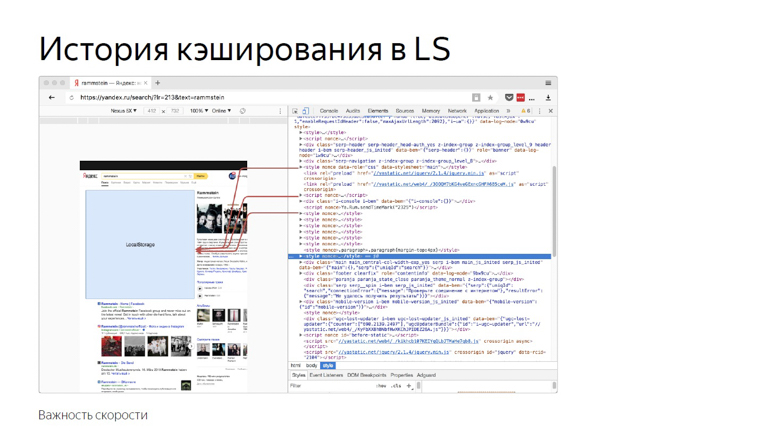
En raison de sa grande variabilité, nous ne pouvons pas le compiler en un seul paquet ou le livrer avec des ressources externes. La pratique a montré qu'avec la livraison en ligne, le rendu et l'initialisation de JavaScript sont les plus rapides.
Une fois que nous avons décidé que l'utilisation d'un référentiel de navigateur serait une bonne idée. Mettez tout dans localStorage et, lors des entrées suivantes sur la page, chargez-le à partir de là et ne le transmettez pas sur le réseau.
Ensuite, nous nous sommes concentrés principalement sur les métriques «taille HTML» et «délai de livraison HTML» et avons obtenu de bons résultats sur celles-ci. Au fil du temps, nous avons inventé de nouvelles méthodes de mesure de la vitesse, acquis de l'expérience et décidé de revérifier, de mener une expérience inverse, de désactiver l'optimisation.

Le délai de livraison HTML moyen (la métrique clé au moment du développement de l'optimisation) a augmenté de 12%, ce qui est beaucoup. Mais en même temps, le temps jusqu'à ce que l'en-tête soit dessiné, avant le début de l'analyse du contenu et avant l'initialisation de JavaScript. Réduit également le temps au premier clic. Le pourcentage est petit - 0,6, mais si vous vous souvenez de l'échelle ...

En désactivant l'optimisation, nous avons obtenu une détérioration de la métrique, visible uniquement pour les spécialistes, et en même temps, une amélioration notable pour l'utilisateur.
On peut en tirer les conclusions suivantes:
Premièrement, la vitesse affecte vraiment les affaires et les mesures commerciales.
Deuxièmement, les optimisations doivent être précédées de mesures. Si vous implémentez quelque chose, après avoir fait de mauvaises mesures, il est probable que vous ne ferez rien d'utile. La composition de l'audience, la flotte d'appareils, les scénarios d'interaction et les réseaux sont différents partout, et vous devez vérifier ce qui fonctionnera exactement pour vous.
Une fois, Ash nous a appris des morts sinistres d'abord à tirer, puis à penser ou à ne pas penser du tout. En vitesse, vous n'avez pas à le faire.
Et le troisième point: les mesures doivent refléter l'expérience utilisateur. Par exemple, la taille HTML et le délai de livraison sont des mesures de vitesse médiocres car l'utilisateur ne s'assoit pas avec devTools et ne sélectionne pas un service avec moins de retard. Mais quelles mesures sont bonnes et correctes - nous le dirons plus loin.
Quoi et comment mesurer?
Les mesures doivent commencer par quelques mesures clés qui, contrairement, par exemple, à la taille HTML, sont proches de l'expérience utilisateur.

Si TTFCP (temps avant la première peinture complète) et TTFMP (temps avant la première peinture significative) indiquent le temps jusqu'au premier rendu du contenu et le temps avant le rendu du contenu significatif, alors le troisième est le temps jusqu'à ce que le cadre soit initialisé, cela vaut la peine d'être expliqué.
C'est le moment où le framework a déjà traversé la page, collecté toutes les données nécessaires et bloqué les gestionnaires. Si l'utilisateur clique quelque part à ce moment, il recevra une réponse dynamique.
Et la dernière, quatrième métrique, le temps jusqu'à la première interactivité, est généralement appelée temps à interactif (TTI).
Ces métriques, contrairement à la taille html ou au délai de livraison, sont proches de l'expérience utilisateur.
Il est temps de peindre le premier contenu
Pour mesurer le moment où l'utilisateur a vu le premier contenu de la page, il existe une API de synchronisation de peinture, disponible jusqu'à présent uniquement en chrome. Les données peuvent être obtenues de la manière suivante.

Avec cet appel, nous obtenons un ensemble d'événements de rendu. Jusqu'à présent, deux types d'événements sont pris en charge: la première peinture - tout rendu et la première peinture de contenu - tout rendu de contenu autre que le fond blanc de l'onglet vide et le contenu d'arrière-plan de la page.
Nous obtenons donc un tableau d'événements, filtrons la peinture en premier contenu et envoyons avec un certain ID.
Temps de première peinture significative
Il n'y a aucun événement dans l'API Paint Timing signalant qu'un contenu significatif a été rendu sur la page. Cela est dû au fait que ce contenu sur chaque page est différent. Si nous parlons de service vidéo, l'essentiel est le joueur, dans les résultats de recherche - le premier résultat non publicitaire. Il existe de nombreux services et une API universelle n'a pas encore été développée. Mais ici, de bonnes béquilles éprouvées entrent en jeu.
Il y a deux écoles de béquilles dans Yandex pour mesurer cette métrique: en utilisant RequestAnimationFrame et en mesurant avec InterceptionObserver.
Dans RequestAnimationFrame, le rendu est mesuré à l'aide d'un intervalle.

Supposons qu'il existe un contenu significatif. Voici une div avec le contenu principal de la classe. Un script est placé devant, où RequestAnimationFrame est appelé deux fois.
Dans le rappel du premier appel, écrivez la limite inférieure de l'intervalle. Dans le rappel de la seconde - le haut. Cela est dû à la structure de trame que le navigateur rend.

Le premier est l'exécution de JavaScript, puis l'analyse des styles, puis le calcul de la mise en page, du rendu et de la composition.
Le rappel, appelant RequestAnimationFrame, est activé au même stade que JavaScript et le contenu est rendu dans la dernière section du cadre lors de la composition. Par conséquent, lors du premier appel, nous n'obtenons que la limite inférieure, sensiblement supprimée dans le temps de la sortie des pixels à l'écran.
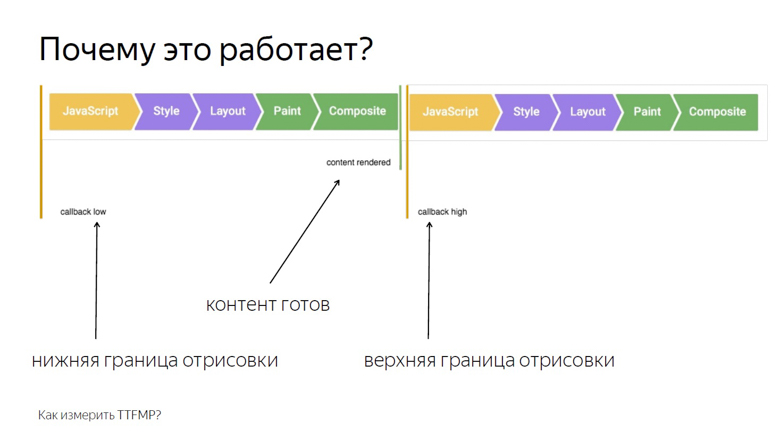
Placez deux cadres côte à côte. On peut voir qu'à la fin du premier d'entre eux le contenu a été rendu. Nous écrivons la bordure inférieure de RequestAnimationFrame, appelée à l'intérieur du premier rappel, et rappelons dans la deuxième trame. Ainsi, nous obtenons l'intervalle de JavaScript appelé dans le cadre où le contenu a été rendu en JavaScript dans le deuxième cadre.
InterceptionObserver
Notre deuxième béquille avec le même contenu fonctionne différemment. Cette fois, le script est placé ci-dessous. Nous y créons InterceptionObserver et souscrivons à domNode.

Nous ne transmettons pas de paramètres supplémentaires, nous mesurons donc son intersection avec la fenêtre. Cette heure est enregistrée comme l'heure exacte du rendu.
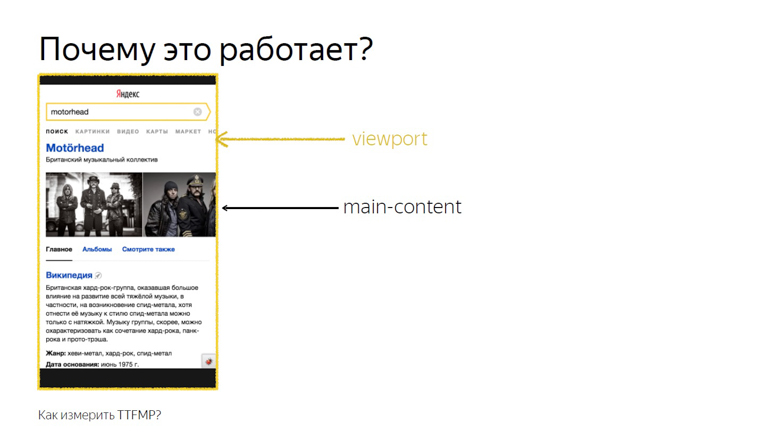
Cela fonctionne parce que l'intersection du contenu principal et de la fenêtre est l'intersection exacte que l'utilisateur voit. Cette API a été conçue pour savoir exactement quand un utilisateur a vu une annonce, mais nos recherches ont montré que cela fonctionne également sur des blocs non publicitaires.
De ces deux méthodes, il est toujours préférable d'utiliser RequestAnimationFrame: son support est plus large, et il est mieux testé par nous en pratique.
Js inited
Imaginez un framework qui a une sorte d'événement «init» auquel vous pouvez vous abonner, mais rappelez-vous qu'en pratique, JS Inited est à la fois une métrique simple et complexe.

Simple - car il vous suffit de trouver le moment où le framework a terminé l'organisation des événements. Complexe - car vous devez rechercher ce point par vous-même pour chaque framework.
Temps d'interactivité
TTI est souvent confondu avec la métrique précédente, mais en fait c'est un indicateur du moment où le flux principal du navigateur est libéré. Pendant le chargement de la page, de nombreuses tâches sont effectuées: du rendu de divers éléments à l'initialisation du framework. Ce n'est que lorsqu'il est déchargé que vient le temps de la première interactivité.
Le concept de tâches longues et l'API Long Task aident à mesurer cela.
Tout d'abord sur les longues tâches.

Entre les courtes tâches indiquées par des flèches, le navigateur peut facilement entasser le traitement d'un événement utilisateur, par exemple une entrée, car il a une priorité élevée. Mais avec les longues tâches indiquées par les flèches rouges, cela ne fonctionnera pas.
L'utilisateur devra attendre jusqu'à épuisement, et seulement après que le navigateur aura procédé au traitement de sa saisie. Dans le même temps, le framework peut déjà être initialisé, et les boutons fonctionneront, mais lentement. Une telle réponse différée est une expérience utilisateur plutôt désagréable. Au moment où la dernière tâche longue est terminée et le thread est vide depuis longtemps, l'illustration arrive à 7 secondes et 300 millisecondes.
Comment mesurer cet intervalle à l'intérieur de JavaScript?

La première étape est conditionnellement désignée comme la balise d'ouverture du corps, après quoi vient le script. Cela crée un PerformanceObserver qui s'abonne à l'événement de tâche longue. Dans le PerformanceObserver de rappel, les informations sur les événements sont collectées dans un tableau.

Après avoir collecté les données, le moment est venu pour la deuxième étape. Il est désigné sous forme de balise de fermeture. Nous prenons le dernier élément du tableau, la dernière longue tâche, regardons le moment de son achèvement et vérifions si suffisamment de temps s'est écoulé.
Dans le travail original sur cette métrique, 5 secondes ont été prises comme constante, mais le choix n'a été aucunement étayé. Cela s'est avéré suffisant pour 3 secondes. Si 3 secondes s'écoulent, nous comptons le temps jusqu'à la première interactivité; sinon, nous réglons Timeout et vérifions à nouveau cette constante.
Comment traiter les données?
Les données doivent être reçues des clients, traitées et présentées de manière pratique. Notre concept d'envoi de données est assez simple. Cela s'appelle un compteur.
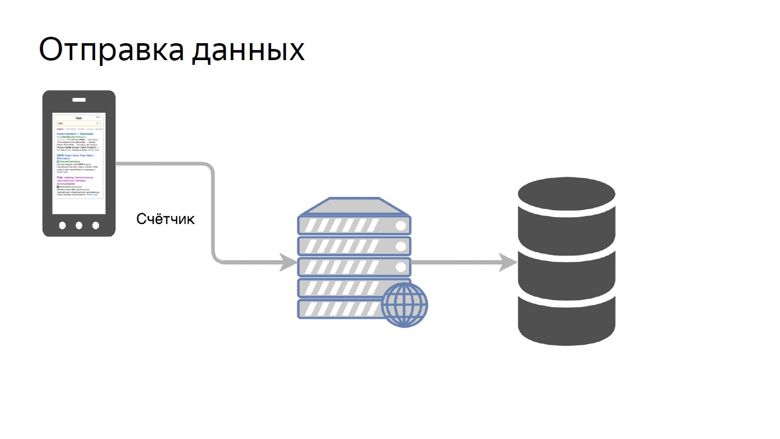
Nous transférons les données d'une certaine métrique vers un stylo spécial sur le backend et les collectons dans le référentiel.

Ici, l'agrégation de données est classiquement désignée comme une requête SQL. Voici les principales agrégations que nous considérons généralement en fonction des métriques de vitesse: moyenne arithmétique et groupe centile (50e, 75e, 95e, 99e).

La moyenne arithmétique dans notre série numérique est presque 1900. Elle est sensiblement plus grande que la plupart des éléments de l'ensemble, car cette agrégation est très sensible aux valeurs aberrantes. Cette propriété nous est toujours utile.

Afin de calculer les centiles pour le même ensemble, triez-le et placez le pointeur sur l'index des centiles. Disons le 50e, qui est aussi appelé la médiane. Nous tombons entre les éléments. Dans ce cas, vous pouvez sortir de la situation de différentes manières, nous calculons la moyenne entre elles. Nous obtenons 150. Par rapport à la moyenne arithmétique, on voit clairement que les centiles sont insensibles aux valeurs aberrantes.
Nous prenons en compte et utilisons ces fonctionnalités d'agrégation. La sensibilité arithmétique des émissions est un inconvénient si vous essayez d'évaluer l'expérience utilisateur avec. En effet, un utilisateur peut toujours se connecter au réseau, par exemple depuis un train, et gâcher la sélection.
Mais la même sensibilité est un avantage en matière de monitoring. Afin de ne pas rater un problème important, nous utilisons la moyenne arithmétique. Il se déplace facilement, mais le risque de faux positifs dans ce cas n'est pas un gros problème. Mieux vaut négliger que négliger.

De plus, nous considérons la médiane (si nous l'attachons aux métriques de temps, la médiane est un indicateur de l'heure à laquelle 50% des demandes correspondent) et le 75e centile. 75% des demandes correspondent à ce moment, nous considérons cela comme une estimation de la vitesse globale. Les 95e et 99e centiles sont considérés comme mesurant la longue queue lente. Ce sont de très grands nombres. Le 95e est considéré comme la demande la plus lente. Le 99e centile est anormal.
Il ne sert à rien de compter le maximum. C'est le chemin de la folie. Après avoir calculé le maximum, il peut s'avérer que l'utilisateur attend le chargement de la page depuis 20 ans.
Après avoir considéré les agrégations, il ne reste plus qu'à appliquer ces nombres, et la chose la plus évidente qui puisse être faite avec eux est de les présenter sous forme de graphiques.
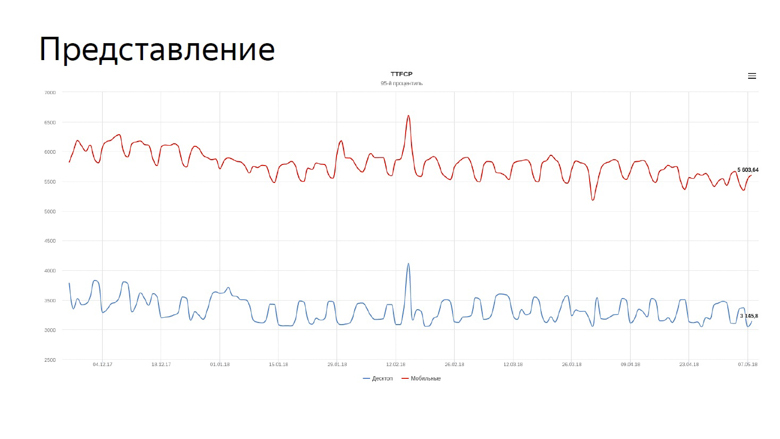
Sur le graphique, notre temps réel pour les premières mesures de peinture de contenu pour la recherche. La ligne bleue reflète la dynamique des ordinateurs de bureau, la rouge - pour les appareils mobiles.
Nous devons constamment surveiller les graphiques de vitesse et nous avons confié cette tâche au robot.
Suivi
Étant donné que les mesures de vitesse sont volatiles et fluctuent constamment avec différentes périodes, la surveillance doit être affinée. Pour cela, nous utilisons le concept de frustrations.
Le débogage est le moment où un processus aléatoire modifie ses caractéristiques, telles que la variance ou l'attente mathématique. Dans notre cas, il s'agit de l'échantillon moyen. Comme mentionné, la moyenne est sensible aux émissions et bien adaptée à la surveillance.
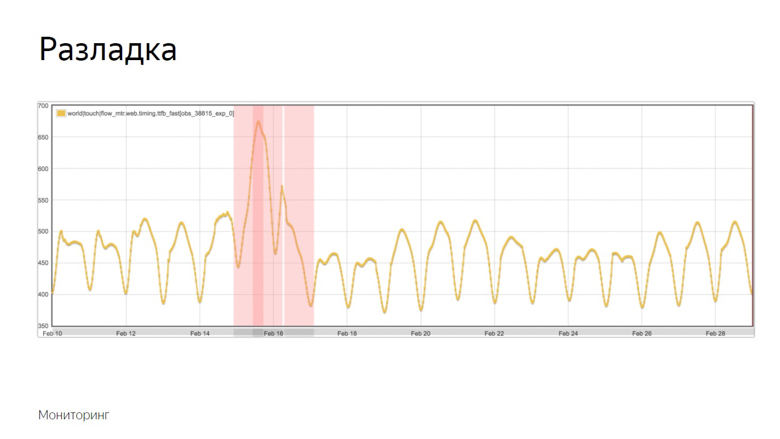
Voici un exemple de graphique où l'alignement s'est produit et où le robot a enregistré l'incident. Comment a-t-il isolé ce moment de plusieurs autres hésitations? Pour comprendre cela, nous imposons des données supplémentaires.

Le graphique jaune est un indicateur métrique, et le graphique bleu est une moyenne mobile avec une période suffisamment longue. Le rouge est la moyenne plus trois écarts-types. Le vert est le même, seulement avec un signe moins.
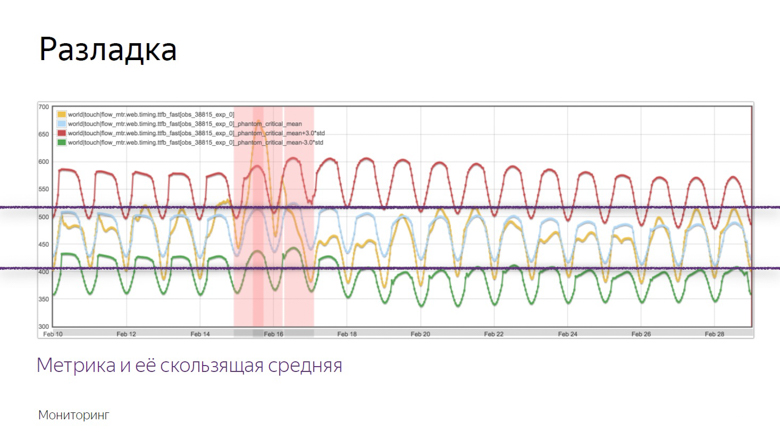
Les indicateurs rouges et verts forment un couloir sûr. Alors que la métrique et la moyenne mobile fluctuent entre elles - tout est normal, ce sont des fluctuations ordinaires. Mais s'ils quittent la zone de sécurité, la surveillance est déclenchée.
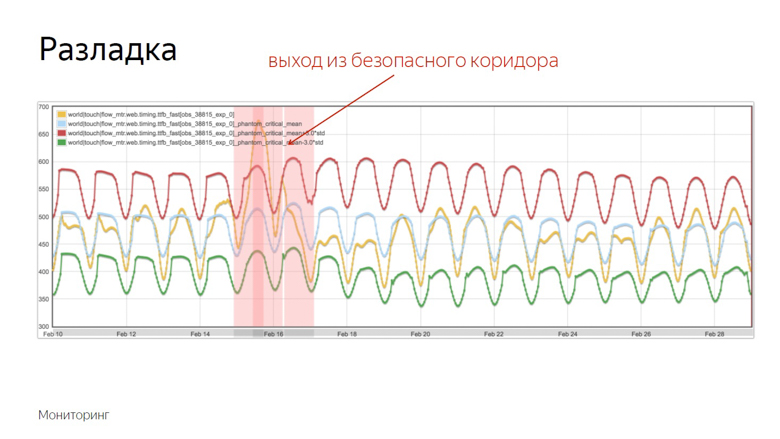
Vérification des fonctionnalités pour la vitesse
Tout ce qui a été discuté était de travailler avec les données de vitesse d'un projet déjà lancé, mais je veux mesurer la vitesse des fonctionnalités individuelles avant de les envoyer à une grande production. Pour ce faire, nous utilisons les tests A / B - une comparaison des métriques pour les groupes de contrôle et expérimentaux.
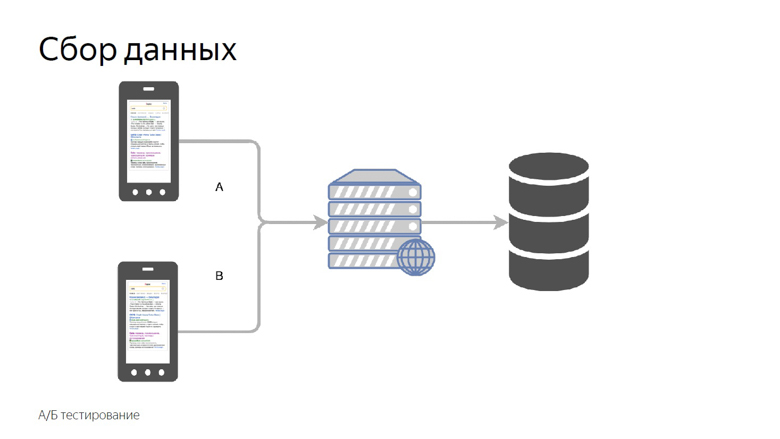
Nous divisons les utilisateurs en groupes de contrôle et expérimentaux. Les lectures de chaque créneau sont collectées séparément, agrégées et tabulées.
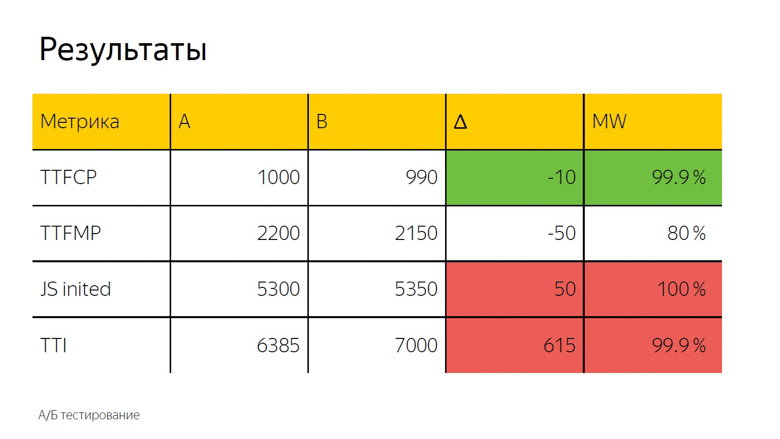
Dans les tests A / B, en règle générale, la moyenne arithmétique est également utilisée. Nous voyons ici un delta et, afin de déterminer avec précision s'il s'agit d'un accident ou d'un résultat significatif, un test statistique est appliqué.

Il est désigné comme «MW» car le test de Mann-Whitney est utilisé dans le calcul. Avec son aide, le soi-disant "pourcentage d'exactitude" est calculé. Cet indicateur a un seuil, après lequel nous considérons le delta comme vrai. Ici, il est fixé à 99,9%.
Lorsque le test atteint cette valeur, le delta est mis en surbrillance dans l'interface. Nous l'appelons coloration. Ici, nous voyons le vert, c'est-à-dire une bonne coloration à temps pour la première peinture pleine de contenu. Le temps de la première peinture significative n'atteint pas cette valeur, c'est-à-dire que le delta est également bon, mais pas 99,9%. Il est totalement impossible de lui faire confiance. Lors de l'initialisation du cadre et du temps d'interactivité, une coloration rouge confiante est observée. On peut en tirer la même conclusion que dans le cas des polices.

Comment le faire soi-même?
Vous pouvez implémenter des mesures de vitesse de deux manières. La première consiste à tout faire vous-même.

Une poignée pour recevoir des données des clients, un backend, qui met tout cela dans une base de données, MongoDB, PostgreSQL, MySQL, n'importe quel SGBD (ils ont des agrégations hors de la boîte), plus l'une des nombreuses solutions open source - afin de dessiner des graphiques et d'organiser la surveillance.
La deuxième solution consiste à utiliser les systèmes d'analyse Yandex Metric ou Google Analytics. Sur l'exemple de Yandex Metrics, cela ressemble à ceci.
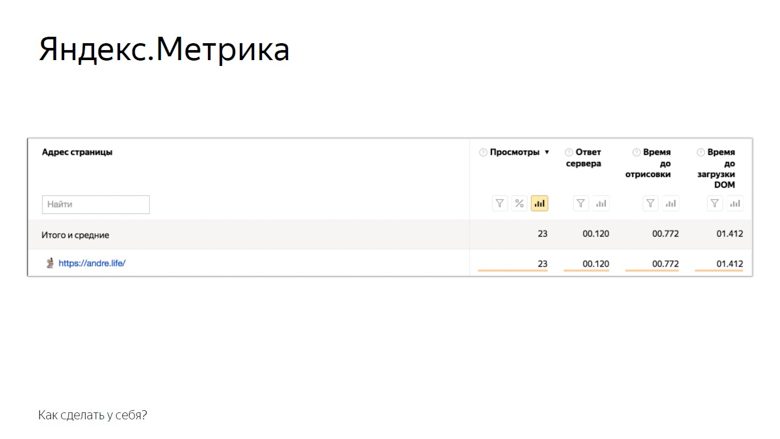
Voici les mesures que la mesure fournit à l'utilisateur hors de la boîte. Bien sûr, ce n'est pas tout ce qui précède, mais déjà quelque chose. Le reste peut être ajouté manuellement via les paramètres utilisateur. Des tests et une surveillance A / B sont également disponibles.
Conclusion
Le concept de mesure de vitesse en ligne dont nous avons parlé est connu sous le nom de RUM - Real User Monitoring. Nous l'aimons tellement que nous avons même dessiné un logo avec un tréma rock and roll cool.

Cette approche est bonne car elle est basée sur des chiffres du monde réel, ces indicateurs dont dispose l'audience de votre service. À l'aide de mesures, vous semblez obtenir des commentaires de chaque utilisateur. Alors commencez à optimiser et ne vous arrêtez pas.
L'annonce à la fin. Si vous avez aimé cette conversation avec HolyJS 2018 Piter , vous serez probablement intéressé par le prochain HolyJS 2018 Moscou , qui se tiendra du 24 au 25 novembre . Là, vous pouvez non seulement voir de nombreux autres rapports JS, mais aussi demander à n'importe quel orateur dans la zone de discussion après le rapport. Et demain, à partir du 1er novembre, le prix des billets augmentera jusqu'à la finale, c'est donc aujourd'hui la dernière occasion de les acheter à prix réduit!