Parmi les réseaux sociaux, Twitter est plus adapté que d'autres à l'extraction de données textuelles en raison de la stricte restriction de la longueur du message dans laquelle les utilisateurs sont obligés de placer tous les éléments les plus essentiels.
Je suggère de deviner quelle technologie ce cadre de nuage de mots?
En utilisant l'API Twitter, vous pouvez extraire et analyser une grande variété d'informations. Un article sur la façon de le faire avec le langage de programmation R.
L'écriture du code ne prend pas autant de temps, des difficultés peuvent survenir en raison des changements et du resserrement de l' API Twitter, apparemment la société était sérieusement préoccupée par les problèmes de sécurité après avoir été traînée au Congrès américain à la suite de l'enquête sur l'influence des «pirates russes» sur les élections américaines de 2016.
API d'accès
Pourquoi quelqu'un aurait-il besoin de récupérer des données industrielles sur Twitter? Eh bien, par exemple, cela aide à faire des prédictions plus précises concernant le résultat des événements sportifs. Mais je suis sûr qu'il existe d'autres scénarios utilisateur.
Pour commencer, il est clair que vous devez avoir un compte Twitter avec un numéro de téléphone. C'est nécessaire pour créer l'application, c'est cette étape qui donne accès à l'API.
Nous allons à la page du développeur et cliquez sur le bouton Créer une application . Vient ensuite la page sur laquelle vous devez remplir les informations sur l'application. Actuellement, la page comprend les champs suivants.
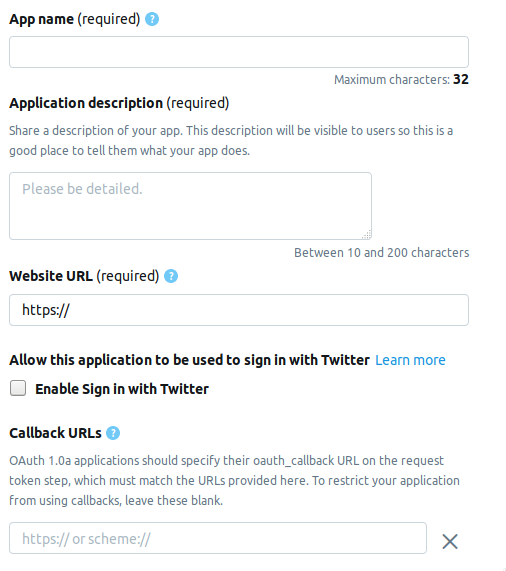
- AppName - nom de l'application (obligatoire).
- Description de l' application - description de l' application (obligatoire).
- URL du site Web - page du site Web de l'application (obligatoire), vous pouvez saisir tout ce qui ressemble à une URL.
- Activer la connexion avec Twitter (case à cocher) - La connexion à partir de la page de l'application sur Twitter peut être omise.
- URL de rappel - Rappel de l' application lors de l'authentification (obligatoire) et nécessaire , vous pouvez quitter
http://127.0.0.1:1410 .
Les champs suivants sont facultatifs: l'adresse de la page pour les conditions de service, le nom de l'organisation, etc.
Lors de la création d'un compte développeur, choisissez l'une des trois options possibles.
- Standard - La version de base, vous pouvez rechercher des enregistrements jusqu'à une profondeur de ≤ 7 jours, gratuitement.
- Premium - Une option plus avancée, vous pouvez rechercher des enregistrements à une profondeur de ≤ 30 jours et depuis 2006. Gratuit, mais ils ne donnent pas tout de suite lors de l'examen d'une demande.
- Entreprise - Tarif classe affaires, payant et fiable.
J'ai choisi Premium , il a fallu environ une semaine pour attendre l'approbation. Je ne peux pas dire à tout le monde s’ils me le donnent de suite, mais ça vaut quand même le coup d’essayer, et Standard n’ira nulle part.
Connexion Twitter
Après avoir créé l'application, un ensemble contenant les éléments suivants apparaîtra dans l'onglet Clés et jetons . Voici les noms et les variables correspondantes de R.
Clés API grand public
- Clé API -
api_key - Clé secrète API -
api_secret
Jeton d'accès et secret de jeton d'accès
- Jeton d'accès -
access_token - Secret du jeton d'accès -
access_token_secret
Installez les packages nécessaires.
install.packages("rtweet") install.packages("tm") install.packages("wordcloud")
Ce morceau de code ressemblera à ceci.
library("rtweet") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret)
Après l'authentification, R vous invite à enregistrer les codes OAuth sur le disque pour une utilisation ultérieure.
[1] "Using direct authentication" Use a local file to cache OAuth access credentials between R sessions? 1: Yes 2: No
Les deux options sont acceptables, j'ai choisi la 1ère.
Rechercher et filtrer les résultats
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600)
La clé include_rts vous permet de contrôler si les retweets sont inclus ou exclus de la recherche. À la sortie, nous obtenons une table avec de nombreux champs dans lesquels il y a des détails et des détails de chaque enregistrement. Voici les 20 premiers.
> head(names(tweets), n=20) [1] "user_id" "status_id" "created_at" [4] "screen_name" "text" "source" [7] "display_text_width" "reply_to_status_id" "reply_to_user_id" [10] "reply_to_screen_name" "is_quote" "is_retweet" [13] "favorite_count" "retweet_count" "hashtags" [16] "symbols" "urls_url" "urls_t.co" [19] "urls_expanded_url" "media_url"
Vous pouvez composer une chaîne de recherche plus complexe.
search_string <- paste0(c("data mining","#bigdata"),collapse = "+") search_tweets(search_string, include_rts=FALSE, n=100)
Les résultats de la recherche peuvent être enregistrés dans un fichier texte.
write.table(tweets$text, file="datamine.txt")
Nous fusionnons dans le corps des textes, nous filtrons les mots de service, les signes de ponctuation et traduisons tout en minuscules.
Il existe une autre fonction de recherche - searchTwitter , qui nécessite la bibliothèque twitteR . À certains égards, c'est plus pratique que search_tweets , mais à certains égards inférieur à celui-ci.
Plus - la présence d'un filtre par le temps.
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500) text = sapply(tweets, function(x) x$getText())
Moins - la sortie n'est pas une table, mais un objet de type status . Pour l'utiliser dans notre exemple, nous devons extraire un champ de texte de la sortie. Cela rend sapply dans la deuxième ligne.
corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "hadoop", stopwords("english")), removeNumbers = TRUE, tolower = TRUE))
Dans la deuxième ligne, la fonction tm_map nécessaire pour convertir toutes sortes de caractères emoji en minuscules, sinon la conversion en minuscules en utilisant tolower échouera.
Construire un nuage de mots
Les nuages de mots sont apparus pour la première fois sur l'hébergement de photos Flickr , pour autant que je sache, et ont depuis gagné en popularité. Pour cette tâche, nous avons besoin de la bibliothèque wordcloud .
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
La fonction search_string vous permet de définir la langue comme paramètre.
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru")
Cependant, en raison du fait que le package NLP pour R est mal russifié, en particulier, il n'y a pas de liste de services ou de mots vides, je n'ai pas réussi à construire un nuage de mots avec une recherche en russe. Je serai heureux si vous trouvez une meilleure solution dans les commentaires.
Eh bien, en fait ...
script entier library("rtweet") library("tm") library("wordcloud") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) oauth_callback <- "http://127.0.0.1:1410" setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret) appname="my_app" twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret) tweets <- search_tweets("devops", include_rts=FALSE, n=600) corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "drupal", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Matériaux utilisés.
Liens courts:
Liens originaux:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
PS Hint, le mot-clé cloud sur le KDPV n'est pas utilisé dans le programme, il est associé à mon article précédent .