La vérification d'un serveur n'est pas un problème. Vous prenez la liste de contrôle et vérifiez dans l'ordre: processeur, mémoire, disques. Mais avec une centaine de serveurs, il est peu probable que cette méthode fonctionne bien. Pour exclure le facteur humain, pour rendre les contrôles plus fiables et plus rapides, il est nécessaire d'automatiser le processus. Qui a besoin de savoir comment faire mieux qu'un fournisseur d'hébergement? Artyom Artemyev sur HighLoad ++ Siberia a expliqué quelles méthodes peuvent être utilisées, ce qui est préférable d'exécuter avec vos mains et ce qui fonctionne bien pour automatiser. En outre, une version texte du rapport avec des conseils que toute personne qui travaille avec du fer et doit vérifier régulièrement ses performances peut répéter.
 A propos du conférencier:
A propos du conférencier: Artyom Artemyev (
artemirk ) directeur technique d'un grand hébergeur FirstVDS, il travaille avec le fer.
FirstVDS dispose de deux centres de données. Le premier est le leur, ils ont construit leur propre bâtiment, apporté et installé leurs racks, ils entretiennent eux-mêmes, s'inquiètent du courant et du refroidissement du datacenter. Le deuxième centre de données est une grande salle dans un grand centre de données loué, tout est plus facile avec lui, mais il existe aussi. Au total, c'est 60 racks et environ 3000 serveurs de fer. Il y avait quelque chose pour se former et tester différentes approches, ce qui signifie que nous attendons des recommandations pratiquement confirmées. Commençons par consulter ou lire le rapport.
Il y a environ 6 à 7 ans, nous avons réalisé que le simple fait de mettre le système d'exploitation sur le serveur ne suffisait pas. L'OS est allumé, le serveur est réveillé et prêt pour la bataille. Nous le lançons en production - des redémarrages et des gels incompréhensibles commencent. Que faire, ce n'est pas clair - le processus est en cours, le transfert de l'ensemble du projet de travail vers une nouvelle pièce de métal est difficile, coûteux et douloureux. Où courir?
Les méthodes de déploiement modernes nous permettent d'éviter cela et de transporter le serveur en 5 secondes, mais nos clients (surtout il y a 6 ans) ne volaient tout simplement pas dans les nuages, marchaient au sol et utilisaient des morceaux de fer ordinaires.

Dans cet article, je vais vous dire quelles méthodes nous avons essayées, lesquelles nous avons pris racine, lesquelles n'ont pas pris racine, lesquelles sont bonnes à exécuter avec vos mains et comment automatiser tout cela. Je vais vous donner des conseils, et vous pouvez le répéter dans votre entreprise si vous travaillez avec du fer et que vous avez un tel besoin.
Quel est le problème?
En théorie, la vérification du serveur n'est pas un problème. Au départ, nous avions un processus, comme dans l'image ci-dessous. Un homme s'assoit, prend une liste de contrôle, vérifie: processeur, mémoire, disques, se froisse le front, prend une décision.
Ensuite, 3 serveurs ont été installés par mois. Mais, quand il y a de plus en plus de serveurs, cette personne commence à pleurer et à se plaindre de sa mort au travail. Une personne se trompe de plus en plus, car la vérification est devenue une routine.
Nous avons pris une décision: nous automatisons! Une personne fera des choses plus utiles.
Petite excursion
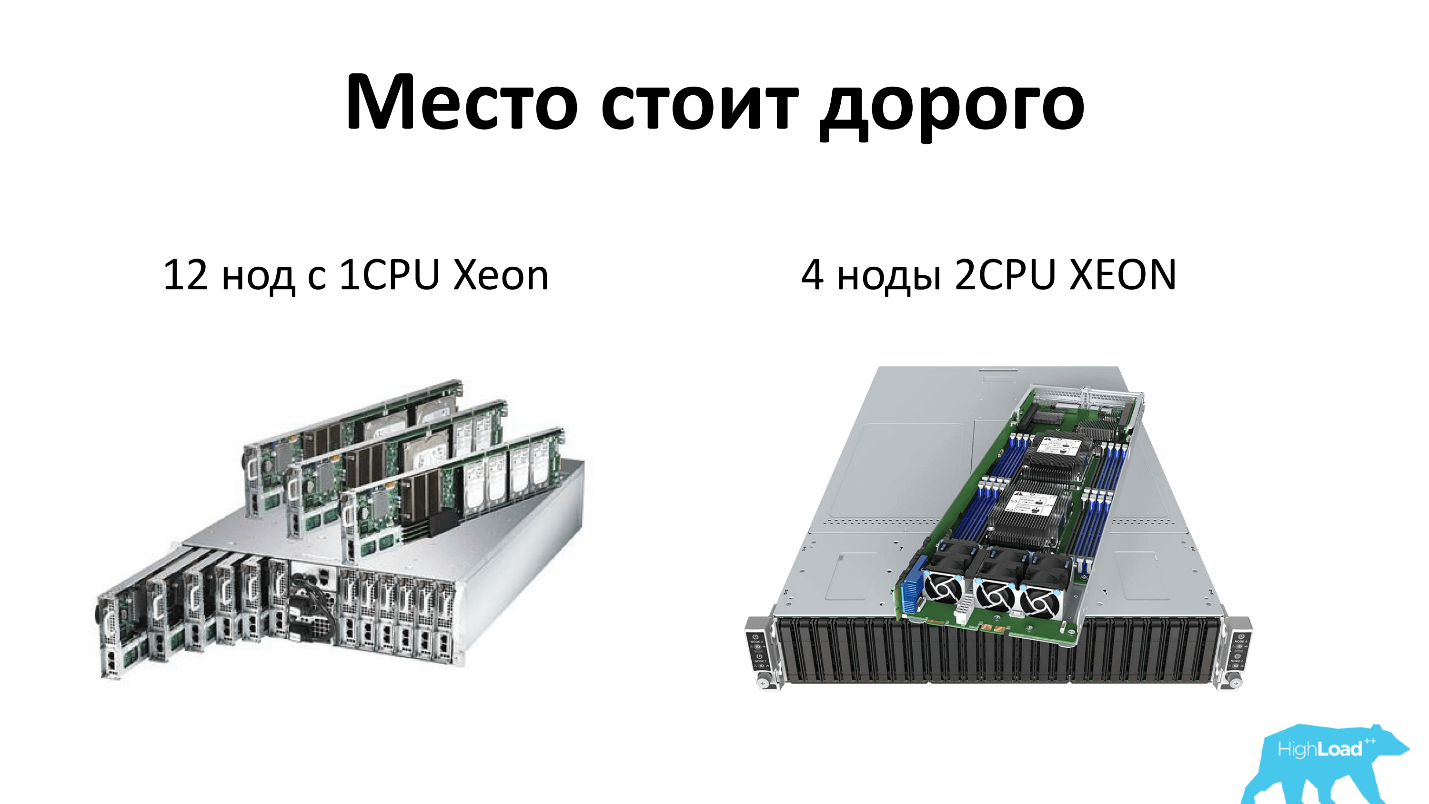
Je vais clarifier ce que je veux dire quand je parle du serveur aujourd'hui. Nous, comme tout le monde, économisons de l'espace en rack et utilisons des serveurs haute densité. Aujourd'hui, il s'agit de 2 unités, qui peuvent accueillir soit 12 nœuds de serveurs à processeur unique, soit 4 nœuds de serveurs à double processeur. Autrement dit, chaque serveur reçoit 4 disques - tout honnêtement. De plus, il y a deux alimentations dans le rack, c'est-à-dire que tout est redondant et que tout le monde l'aime.
D'où vient le fer?
Le fer est apporté à notre centre de données par nos fournisseurs - généralement Supermicro et Intel. Dans le centre de données, nos gars-opérateurs installent les serveurs dans un espace vide dans le rack et connectent deux câbles, un réseau et l'alimentation. Il est également de la responsabilité des opérateurs de configurer le BIOS sur le serveur. Autrement dit, connectez le clavier, le moniteur et configurez deux paramètres:
Restore on AC/Power Loss — [Power On] , de sorte que le serveur s'allume toujours dès que l'alimentation apparaît. Cela devrait fonctionner sans arrêt. Le deuxième
First boot device — [PXE] , c'est-à-dire que nous avons mis le premier périphérique de démarrage sur le réseau, sinon nous ne pourrons pas atteindre le serveur, car ce n'est pas un fait qu'il dispose de disques immédiatement, etc.

Après cela, l'opérateur ouvre le panneau de comptabilité des serveurs de fer, dans lequel vous devez enregistrer le fait d'installer le serveur, pour lequel il est indiqué:
- rack;
- autocollant
- ports réseau
- ports d'alimentation
- numéro d'unité.
Après cela, le port réseau sur lequel l'opérateur a installé le nouveau serveur, pour des raisons de sécurité, va vers un VLAN de quarantaine spécial, qui contient également DHCP, Pxe, TFtp. Ensuite, le serveur charge notre Linux préféré, qui possède tous les utilitaires nécessaires, et le processus de diagnostic démarre.
Étant donné que le serveur possède toujours le premier périphérique de démarrage sur le réseau, pour les serveurs qui entrent en production, le port bascule vers un autre VLAN. Il n'y a pas de DHCP dans un autre VLAN, et nous n'avons pas peur de réinstaller accidentellement notre serveur de production. Pour cela, nous avons un VLAN séparé.
Il arrive que le serveur ait été installé, tout va bien, mais il n'a pas démarré dans le système de diagnostic. Cela se produit, en règle générale, du fait qu'avec un retard dans la commutation des VLAN, tous les commutateurs réseau ne commutent pas rapidement les VLAN, etc.

Ensuite, l'opérateur reçoit la tâche de redémarrer le serveur avec ses mains. Auparavant, il n'y avait pas d'IPMI, nous avons configuré des sockets distants et fixé sur quel port les sockets du serveur, tiré la socket sur le réseau et le serveur a redémarré.
Mais les points de vente gérés ne fonctionnent pas toujours bien, nous gérons donc désormais l'alimentation du serveur via IPMI. Mais lorsque le serveur est nouveau, IPMI n'est pas configuré, il ne peut être redémarré qu'en montant et en appuyant sur le bouton. Par conséquent, un homme s'assoit, attend - la lumière s'allume - court et appuie sur le bouton. Tel est son travail.
Si après cela, le serveur n'a pas démarré, il est inscrit dans une liste spéciale pour réparation. Cette liste comprend les serveurs sur lesquels les diagnostics n'ont pas démarré ou ses résultats n'étaient pas satisfaisants. Une personne individuelle - qui aime le fer - s'assoit et se désassemble tous les jours - recueille, regarde, pourquoi ne fonctionne pas.
CPU
Tout va bien, le serveur a démarré, nous commençons à tester. Nous testons d'abord le processeur comme l'un des éléments les plus importants.

La première impulsion a été d'utiliser l'application du fournisseur. Nous avons presque tous les processeurs Intel - ils sont allés sur le site, ont téléchargé l'outil de diagnostic du processeur Intel - tout va bien, il montre beaucoup d'informations intéressantes, y compris les heures de fonctionnement du serveur en heures et le graphique de la consommation d'énergie.
Mais le problème est qu'Intel PTD fonctionne sous Windows, ce que nous n'aimions plus. Pour commencer un test, il vous suffit de déplacer la souris, d'appuyer sur le bouton "START" et le test commencera. Le résultat est affiché à l'écran, mais il n'y a aucun moyen de l'exporter n'importe où. Cela ne nous convient pas, car le processus n'est pas automatisé.

Nous sommes allés lire les forums et avons trouvé les deux moyens les plus simples.
- La boucle éternelle cat / dev / zero> / dev / null . Vous pouvez vous enregistrer en haut - 100% d'un cœur est consommé. Nous comptons le nombre de cœurs, exécutons le nombre requis de cat / dev / zéro, multiplié par le nombre de cœurs souhaité. Tout fonctionne très bien!
- Utilitaire / bac / stress . Elle construit des matrices en mémoire et commence à les retourner constamment. Tout va bien aussi - le processeur chauffe, il y a une charge.
Nous donnons les serveurs en production, les utilisateurs reviennent et disent que le processeur est instable. Vérifié - le processeur est instable. Ils ont commencé à enquêter, ont pris un serveur qui réussit les vérifications, mais il se bloque lors d'une bataille, a activé le noyau de débogage sous Linux et collecté le vidage de mémoire. Le serveur avant le redémarrage vide dans le fichier tout ce qui était en mémoire avant le crash.

Diverses optimisations sont intégrées dans les processeurs pour les opérations fréquentes. Nous pouvons voir des indicateurs reflétant les optimisations prises en charge par le processeur, par exemple, les optimisations pour travailler avec des nombres à virgule flottante, les optimisations multimédias, etc. Mais notre / bin / stress et le cycle éternel ne font que graver le processeur en une seule opération et n'utilisent pas de fonctionnalités supplémentaires. L'enquête a montré que le processeur se bloque lors de l'utilisation de la fonctionnalité de l'un des drapeaux intégrés.
La première impulsion a été de laisser / bin / stress - laisser le processeur se réchauffer. Ensuite, dans un cycle, nous parcourons tous les drapeaux, les tirons. En réfléchissant à la façon de mettre en œuvre ceci, qui commande d'appeler afin d'appeler les fonctions de chaque indicateur, nous lisons les forums.
Au forum des overclockers, nous sommes tombés sur un projet intéressant de recherche de nombres premiers
Great Internet Mersenne Prime Search . Les scientifiques ont créé un réseau distribué auquel tout le monde peut se connecter et aider à trouver un nombre premier. Les scientifiques ne croient personne, donc le programme fonctionne très intelligemment: d'abord vous l'exécutez, il calcule les nombres premiers qu'il connaît déjà et compare le résultat avec ce qu'il sait. Si le résultat ne correspond pas, le processeur ne fonctionne pas correctement. Nous avons vraiment aimé cette propriété: avec n'importe quel non-sens, elle est sujette à tomber.
De plus, le but du projet est de trouver autant de nombres premiers que possible, donc le programme est constamment optimisé pour les propriétés des nouveaux processeurs, en conséquence il tire beaucoup de drapeaux.
Mprime n'a pas de limite de temps, s'il n'est pas arrêté, il fonctionne pour toujours. Nous l'exécutons pendant 30 minutes.
/usr/bin/timeout 30m /opt/mprime -t /bin/grep -i error /root/result.txt
Après avoir terminé le travail, nous vérifions qu'il n'y a pas d'erreurs dans result.txt, et regardons les journaux du noyau, en particulier, dans le fichier / proc / kmsg, nous recherchons des erreurs.
Une autre excursion

Le 3 janvier 2018, ils ont trouvé le 50e nombre premier de Mersenne (2
p -1). De ce nombre, seulement 23 millions de chiffres. Vous pouvez le télécharger pour le voir -
il s'agit d'
une archive zip de 12 Mo.Pourquoi avons-nous besoin de nombres premiers? Tout d'abord, tout chiffrement RSA utilise des nombres premiers. Plus nous en savons, plus votre clé SSH est fiable. Deuxièmement, les scientifiques testent leurs hypothèses et leurs théorèmes mathématiques, et cela ne nous dérange pas d'aider les scientifiques - cela ne nous coûte rien. Il se révèle une histoire gagnant-gagnant.

Donc, le processeur fonctionne, tout va bien. Reste à savoir de quel type de processeur il s'agit. Nous utilisons le processeur dmidecode -t et voyons tous les emplacements qui se trouvent sur la carte mère, et quels processeurs se trouvent dans ces emplacements. Ces informations entrent dans notre système comptable, nous les interpréterons plus tard.
Attraper
Ainsi, étonnamment, des jambes cassées peuvent être trouvées. / bin / stress et le cycle perpétuel ont fonctionné, et Mprime est tombé. Ils ont roulé longtemps, cherché, découvert - le résultat dans l'image ci-dessous - tout est clair ici.

Un tel processeur n'a tout simplement pas démarré. L'opérateur était très fort, a pris le mauvais processeur - mais a pu livrer.

Encore une belle affaire. La rangée noire sur la photo ci-dessous représente les fans, la flèche montre comment l'air souffle. Nous voyons: le radiateur se trouve à travers le ruisseau. Bien sûr, tout a surchauffé et s'est éteint.

La mémoire
Avec la mémoire, tout est assez simple. Ce sont des cellules dans lesquelles nous écrivons des informations, et après un certain temps nous les relisons. S'il reste le même que nous avons noté, alors cette cellule fonctionne.

Tout le monde connaît le bon programme, directement classique,
Memtest86 + , qui s'exécute à partir de n'importe quel support, sur le réseau, ou même à partir d'une disquette. Elle est réalisée afin de vérifier autant de cellules mémoire que possible. Les cellules occupées ne peuvent plus être vérifiées. Memtest86 + a donc une taille minimale pour ne pas occuper de mémoire. Malheureusement,
memtest86 + n'affiche que ses statistiques à l'écran . Nous avons essayé de l'étendre d'une manière ou d'une autre, mais tout cela est dû au fait qu'à l'intérieur du programme, il n'y avait même pas de pile réseau. Pour l'étendre, il faudrait apporter le noyau Linux et tout le reste.
Il existe une version payante de ce programme qui sait déjà comment déposer des informations sur le disque. Mais nos serveurs n'ont pas toujours de disque, et il n'y a pas toujours de système de fichiers sur ces disques. Mais le lecteur réseau, comme nous l'avons déjà découvert, ne peut pas être connecté.
Nous avons commencé à creuser plus loin et avons trouvé un programme
Memtester similaire. Ce programme fonctionne à partir du niveau OS de Linux. Son plus gros inconvénient est que le système d'exploitation lui-même et Memtester occupent certaines cellules de mémoire, et ces cellules ne seront pas vérifiées.
Memtester est démarré avec la commande: memtester `cat / proc / meminfo | grep MemFree | awk '{print $ 2-1024}' 'k 5
Ici, nous transférons la quantité de mémoire libre moins 1 Mo. Cela est fait, car sinon le Memtester prend toute la mémoire et le tueur de duvet la tue. Nous effectuons ce test pendant 5 cycles, à la sortie, nous avons une plaque avec OK ou échec.
| Adresse bloquée | ok |
| Valeur aléatoire | ok |
| Comparez XOR | ok |
| Comparez SUB | ok |
| Comparez MUL | ok |
| Comparez DIV | ok |
| Comparer OU | ok |
| Comparer ET | ok |
Nous enregistrons le résultat final et analysons davantage les échecs.

Pour comprendre l'étendue du problème - notre plus petit serveur a 32 Go de mémoire, notre image Linux avec Memtester prend 60 Mo,
nous ne vérifions pas 2% de la mémoire . Mais selon les statistiques des 6 dernières années, il n'y a rien eu de tel que la mémoire franchement battue soit entrée en production. C'est le compromis que nous acceptons, et qu'il nous coûte cher de fixer, et nous vivons avec.
En cours de route, nous collectons également la mémoire dmidecode -t, qui donne toutes les banques de mémoire que nous avons sur la carte mère (généralement jusqu'à 24 pièces), et quels dés se trouvent dans chaque banque. Ces informations sont utiles si nous voulons mettre à niveau le serveur - nous saurons où ajouter quoi, combien de bandes à prendre et à quel serveur aller.
Périphériques de stockage
Il y a 6 ans, tous les disques étaient avec des crêpes qui tournaient. Une autre histoire consistait à dresser une liste de tous les disques. Il y avait plusieurs approches différentes, car on ne pensait pas que vous pouviez simplement regarder ls / dev / sd. Mais à la fin, nous avons cessé de regarder ls / dev / sd * et ls / dev / cciss / c0d *. Dans le premier cas, il s'agit d'un périphérique SATA, dans le second - SCSI et SAS.

Littéralement cette année, ils ont commencé à vendre des disques nvme et ont ajouté la liste nvme ici.
Une fois la liste des disques compilée, nous essayons de lire 0 octet pour comprendre qu'il s'agit d'un périphérique bloc et que tout va bien. Si vous ne pouviez pas le lire, alors nous pensons que c'est une sorte de fantôme, et nous n'avons pas et n'avons jamais eu un tel disque.
La première approche de la vérification des disques était évidente: «
dd -o nocache -o direct if=/dev/urandom of=${disk} des données aléatoires sur le disque et voyons la vitesse» -
dd -o nocache -o direct if=/dev/urandom of=${disk} . En règle générale, les disques à crêpes fournissent 130-150 Mb / s. Nous avons plissé les yeux et décidé pour nous-mêmes que 90 Mo / s est le nombre après lequel il y a des disques réparables, tout ce qui est plus petit est défectueux.
Mais encore une fois, les utilisateurs ont commencé à revenir et à dire que les lecteurs étaient mauvais. Il s'est avéré que la physique insidieuse plaisantait à nouveau avec nous.
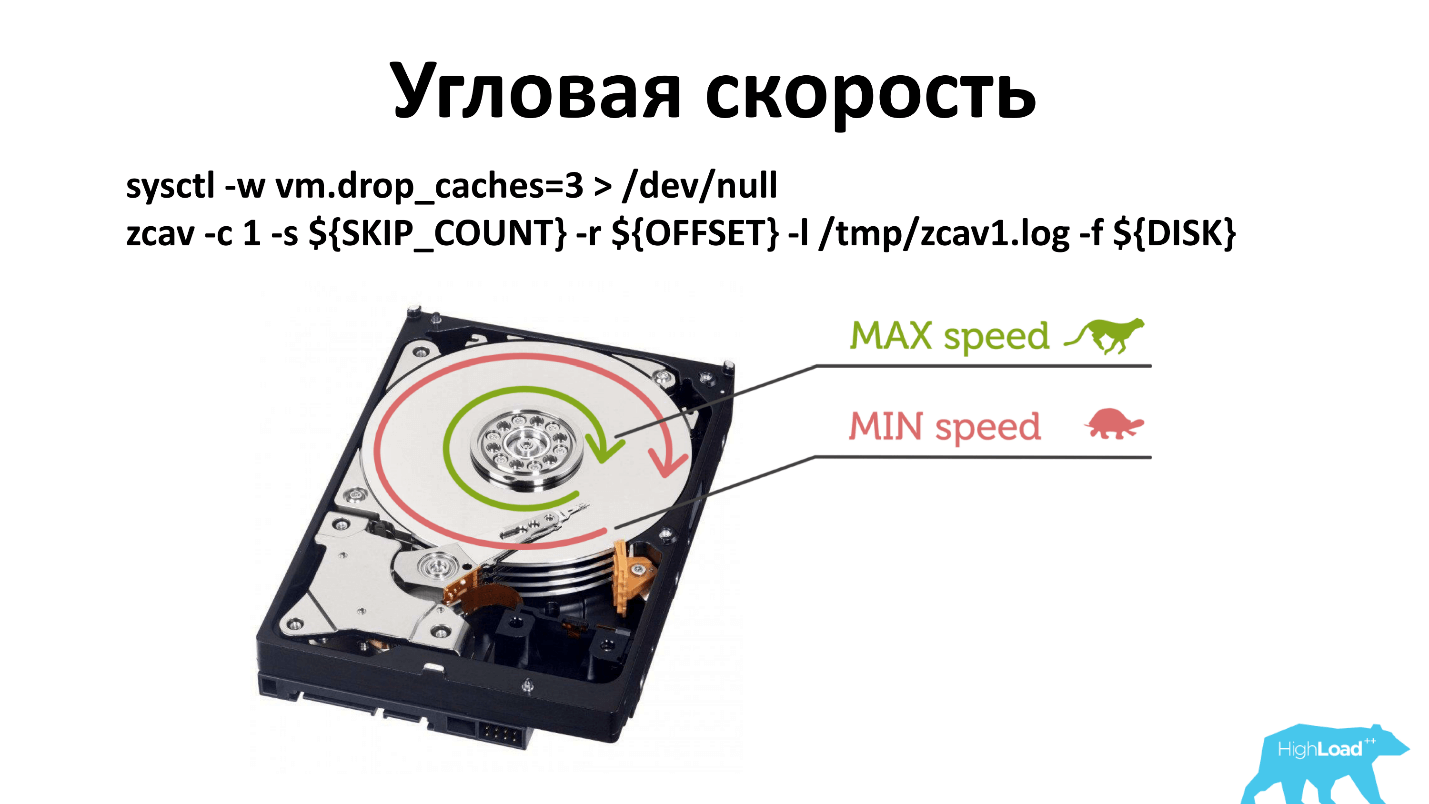
Il y a une vitesse angulaire et, en règle générale, lorsque vous exécutez -dd, il écrit près de la broche. Si, pour une raison quelconque, la vitesse de rotation de la broche s'est dégradée, cela est moins visible que si vous écrivez à partir du bord du disque.
J'ai dû changer le principe de la vérification. Maintenant, nous vérifions à trois endroits: près de la broche, au milieu et à l'extérieur. Probablement, il ne peut être vérifié que de l'extérieur, mais c'est ainsi que cela s'est produit historiquement. Et ce qui fonctionne, ne touchez pas.
Vous pouvez utiliser
smartctl pour demander au disque comment il fonctionne. Nous pensons qu'une bonne conduite:
- Il n'y a pas de secteurs réalloués (nombre de secteurs réalloués = 0) , c'est-à-dire tous les secteurs qui ont quitté l'usine.
- Nous n'utilisons pas de disques de plus de 4 ans , bien qu'ils fonctionnent assez bien. Avant d'introduire cette pratique, nous avions des disques depuis 7 ans. Nous pensons maintenant qu'après 4 ans, le disque a payé, et nous ne sommes pas prêts à accepter le risque d'usure.
- Aucun secteur ne va être réaffecté ( Current_Pending_Sector = 0 ).
- Nombre d'erreurs UltraDMA CRC = 0 - ce sont des erreurs sur le câble SATA. S'il y a une erreur, il vous suffit de changer le fil, vous n'avez pas besoin de changer le disque.

Les SSD distribués sont généralement d'excellents disques, ils fonctionnent rapidement, ne font pas de bruit, ne chauffent pas. Nous pensons qu'un bon SSD a une vitesse d'écriture de plus de 200 Mo / s. Nos clients adorent les prix bas, et les modèles de serveurs qui émettent 320-350 Mo / s ne nous parviennent pas toujours.
Pour les SSD, nous recherchons également smartctl. Les mêmes réaffectés, Power_On_Hours, Current_Pending_Sector. Tous les SSD sont capables d'afficher le degré d'usure, il affiche le paramètre Media_Wearout_Indicator. Nous essuyons les disques jusqu'à 5% de leur durée de vie, puis nous les retirons. Ces disques trouvent parfois une seconde vie dans les besoins personnels des employés. Par exemple, j'ai récemment découvert qu'en 2 ans, un tel disque s'était épuisé de 1% supplémentaire dans l'ordinateur portable d'un employé, bien que dans notre pays, le cache SSD épuise 95% en environ 10 mois.
Mais le problème est que tous les fabricants de disques n'étaient pas d'accord sur les noms de paramètres, et ce Media_Wearout_Indicator, par exemple, s'appelle Percent_Lifetime_Used pour Toshiba, autre Wear Leveling Count, Percent Lifetime Remaining pour d'autres fabricants, ou tout simplement. * Wear. *.
Crucial n'a pas du tout cette option. Ensuite, nous considérons simplement la quantité de réécriture du disque - «octet écrit» - combien d'octets nous avons déjà écrit sur ce disque. De plus, selon les spécifications, nous essayons de savoir combien de réécritures ce disque est calculé par le fabricant. Par les mathématiques élémentaires, nous déterminons combien il vivra de plus. S'il est temps de changer - changez.
RAID
Je ne sais pas pourquoi dans le monde moderne nos clients veulent toujours des RAID. Les gens achètent du RAID, y mettent 4 SSD, qui sont beaucoup plus rapides que ce RAID (6 Go). Ils ont une sorte d'instruction, et ils la collectent. Je pense que c'est une chose presque inutile.
Il y avait auparavant 3 fabricants: Adaptec; 3ware; Intel Nous avions 3 utilitaires, nous dérangeons, mais nous avons exécuté des diagnostics pour tout le monde. Maintenant, LSI a acheté tout le monde - il n'y a plus qu'un seul utilitaire.
Lorsque notre système de diagnostic détecte le RAID, il analyse le volume logique sur des disques séparés afin que vous puissiez mesurer la vitesse de chaque disque et lire son Smart. Après cela, il reste au RAID de vérifier la batterie. Qui ne sait pas - il y a suffisamment de batteries sur le RAID pour faire tourner tous les disques pendant encore 2 heures. Autrement dit, vous éteignez le serveur, le retirez et il fait tourner le disque pendant 2 heures supplémentaires pour terminer tous les enregistrements.
Réseau
Avec le réseau, tout est assez simple - il devrait y avoir moins de 300 Mbit à l'intérieur du centre de données. Si moins, vous devez le réparer. Nous examinons également les erreurs sur l'interface.
Les erreurs sur l'interface réseau ne devraient pas être du tout , et si elles le sont, alors tout est mauvais.
Nous essayons de mettre à jour le BIOS et le firmware IPMI en cours de route. Il s'est avéré que nous n'aimons pas tous les BIOS. Nous avons encore des BIOS qui ne savent pas comment utiliser UEFI et d'autres fonctionnalités que nous utilisons. Nous essayons de le mettre à jour automatiquement, mais cela ne fonctionne pas toujours, tout n'est pas très simple là-bas. Si cela ne fonctionne pas, la personne se met à jour avec ses mains.
Nous ne donnons pas IPMI Supermicro au monde, nous l'avons sur des adresses grises via OpenVPN. Néanmoins, nous craignons qu'un jour une autre vulnérabilité ne se manifeste et que nous en souffrions. Par conséquent, nous essayons de garder le firmware IPMI toujours le dernier. Si ce n'est pas le cas, mettez à jour.
D'une chose étrange, il est récemment ressorti qu'Intel sur les cartes réseau 10 et 40 gigabits n'inclut pas le démarrage PXE. Il s'avère que si le serveur est dans un rack dans lequel il n'y a qu'une carte de 40 gigabits, il est impossible de démarrer sur le réseau, car vous devez démarrer sur une carte gigabit. Nous flashons séparément les cartes réseau sur 40G afin qu'elles aient PXE et puissent continuer à vivre.
Une fois tout vérifié, le serveur est immédiatement mis en vente . Son prix est calculé, auquel il est mis sur le site et vendu.

Au total, nous effectuons environ 350 vérifications par mois, 69% des serveurs sont réparables, 31% ne le sont pas. Cela est dû au fait que nous avons une histoire riche, certains serveurs existent depuis 10 ans. La plupart des serveurs qui n'ont pas réussi le test, nous venons de jeter.
Pour les curieux: nous avons 3 clients qui vivent toujours sur le Pentium IV et qui ne veulent partir nulle part. Ils ont 512 Mo de RAM.
L'avenir est venu! Si je devais clôturer ce système aujourd'hui ...

Un merveilleux utilitaire,
Hardware Lister (lshw), a été publié, qui peut communiquer avec le noyau, afficher magnifiquement quel type de matériel se trouve dans le noyau, ce que le noyau pourrait détecter. Toutes ces danses ne sont pas nécessaires. Si vous répétez - je vous conseille fortement de regarder cet utilitaire et de l'utiliser. Tout deviendra beaucoup plus simple.
Résumé:
- Le compromis n'est pas mauvais, c'est juste une question de prix. Si la solution est très coûteuse, vous devez rechercher un niveau où la fiabilité et le prix sont acceptables.
- Les programmes non essentiels sont parfois intéressants à tester. Il ne reste plus qu'à les trouver.
- Testez tout ce que vous atteignez!
Le prochain grand HighLoad ++ aura déjà lieu les 8 et 9 novembre à Moscou. Le programme comprend des spécialistes célèbres et de nouveaux noms, des tâches traditionnelles et nouvelles. Dans la section DevOps, par exemple, les éléments suivants sont déjà acceptés:
Étudiez la liste des rapports et dépêchez-vous de vous joindre. Ou abonnez-vous à notre newsletter et vous recevrez des critiques régulières des rapports, des rapports sur les nouveaux articles et vidéos.