 Présentation complète de l'apprentissage automatique en Python: troisième partie
Présentation complète de l'apprentissage automatique en Python: troisième partieBeaucoup de gens n'aiment pas que les modèles d'apprentissage automatique soient
des boîtes noires : nous y mettons des données et sans aucune explication, nous obtenons des réponses - souvent des réponses très précises. Dans cet article, nous allons essayer de comprendre comment le modèle que nous avons créé fait des prévisions et ce qu'il peut dire sur le problème que nous résolvons. Et nous concluons par une discussion sur la partie la plus importante du projet d'apprentissage automatique: nous documentons ce que nous avons fait et présentons les résultats.
Dans la
première partie, nous avons examiné le nettoyage des données, l'analyse exploratoire, la conception et la sélection des fonctionnalités. Dans la
deuxième partie, nous avons étudié le remplissage des données manquantes, la mise en place et la comparaison de modèles d'apprentissage automatique, le réglage hyperparamétrique par recherche aléatoire avec validation croisée et, enfin, l'évaluation du modèle résultant.
Tout le
code du projet est sur GitHub. Et le troisième cahier Jupyter lié à cet article se trouve
ici . Vous pouvez l'utiliser pour vos projets!
Donc, nous travaillons sur une solution au problème en utilisant l'apprentissage automatique, ou plutôt, en utilisant la régression supervisée. Sur la base
des données énergétiques des bâtiments de New York, nous avons créé un modèle qui prédit le score Energy Star. Nous avons obtenu le modèle de «
régression basée sur l'augmentation du gradient », capable de prédire dans la plage de 9,1 points (dans la plage de 1 à 100) sur la base des données de test.
Interprétation du modèle
La régression de renforcement du gradient se situe approximativement au milieu de
l'échelle d'interprétabilité du modèle : le modèle lui-même est complexe, mais se compose de centaines d'
arbres de décision assez simples. Il existe trois façons de comprendre le fonctionnement de notre modèle:
- Évaluez l' importance des symptômes .
- Visualisez l'un des arbres de décision.
- Appliquer la méthode LIME - Explications locales interprétables du modèle-agnostique, explications locales indépendantes du modèle interprétées.
Les deux premières méthodes sont caractéristiques des ensembles d'arbres et la troisième, comme vous pouvez le comprendre d'après son nom, peut être appliquée à n'importe quel modèle d'apprentissage automatique. LIME est une approche relativement nouvelle, c'est un pas en avant significatif dans une tentative d'
expliquer le fonctionnement de l'apprentissage automatique .
L'importance des symptômes
L'importance des signes vous permet de voir la relation de chaque signe dans le but de prévoir. Les détails techniques de cette méthode sont complexes (la diminution moyenne d'impureté ou la
diminution de l'erreur due à l'inclusion d'un trait est mesurée ), mais nous pouvons utiliser des valeurs relatives pour comprendre quels traits sont les plus pertinents. Dans Scikit-Learn, vous pouvez
extraire l'importance des attributs de n'importe quel ensemble «étudiant» basé sur un arbre.
Dans le code ci-dessous, le
model est notre modèle formé, et en utilisant
model.feature_importances_ vous pouvez déterminer l'importance des attributs. Ensuite, nous les envoyons au bloc de données Pandas et affichons les 10 attributs les plus importants:
import pandas as pd
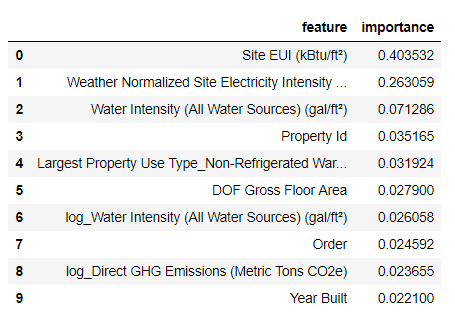
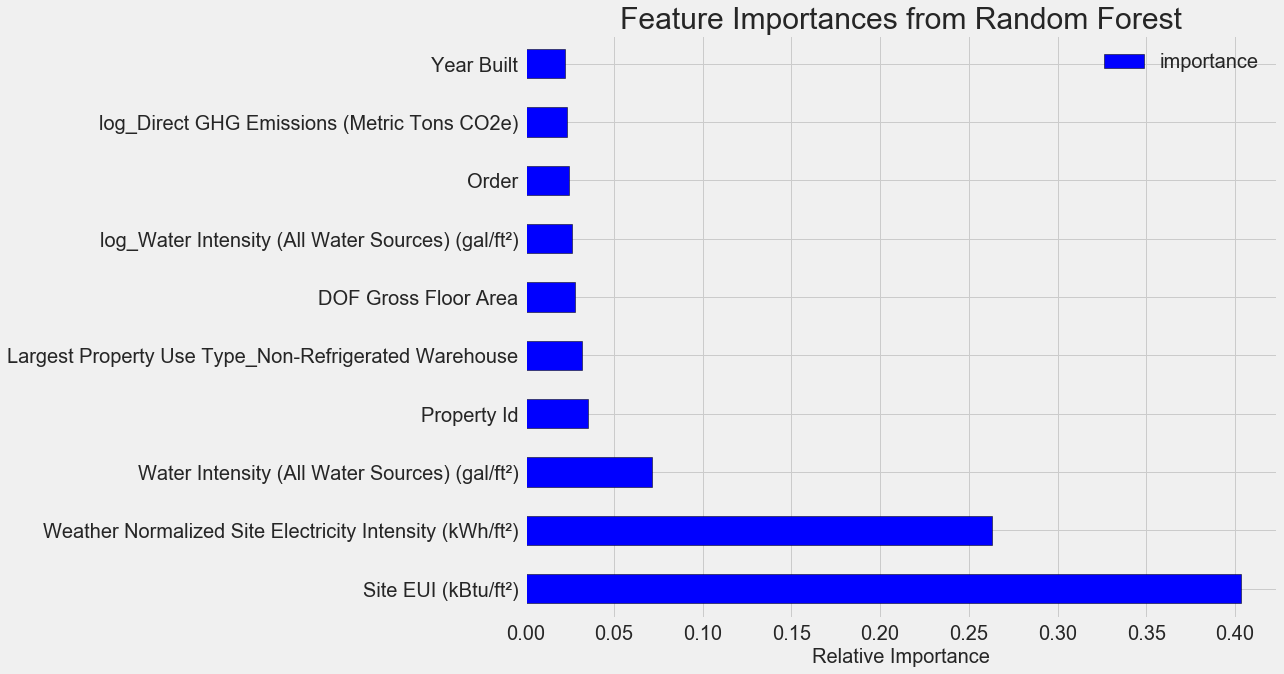
Les caractéristiques les plus importantes sont le
Site EUI (
Energy Consumption Intensity ) et
Weather Normalized Site Electricity Intensity , représentant plus de 66% de l'importance totale. Déjà dans la troisième fonctionnalité, l'importance diminue considérablement, cela
suggère que nous n'avons pas besoin d'utiliser les 64 fonctionnalités pour atteindre une précision de prévision élevée (dans le
cahier Jupyter, cette théorie est testée en utilisant uniquement les 10 fonctionnalités les plus importantes, et le modèle n'était pas très précis).
Sur la base de ces résultats, une des premières questions peut enfin être résolue: les indicateurs les plus importants du score Energy Star sont l'EUI du site et l'intensité électrique normalisée du site météorologique. Nous n'entrerons pas
trop profondément dans la jungle de l'importance des attributs , nous dirons seulement qu'avec eux, vous pouvez commencer à comprendre le mécanisme de prévision par le modèle.
Visualisation d'un seul arbre de décision
Il est difficile de comprendre l'ensemble du modèle de régression basé sur l'augmentation du gradient, ce qui ne peut pas être dit au sujet des arbres de décision individuels. Vous pouvez visualiser n'importe quel arbre à l'aide de la fonction
Scikit-Learn- export_graphviz . Tout d'abord, extrayez l'arbre de l'ensemble, puis enregistrez-le sous forme de fichier à points:
from sklearn import tree
À l'aide du
visualiseur Graphviz, convertissez le fichier dot en png en tapant:
dot -Tpng images/tree.dot -o images/tree.pngVous avez un arbre de décision complet:

Un peu encombrant! Bien que cet arbre n’ait que 6 couches de profondeur, il est difficile de suivre toutes les transitions.
export_graphviz l'
export_graphviz fonction
export_graphviz et
export_graphviz la profondeur de l'arborescence à deux couches:
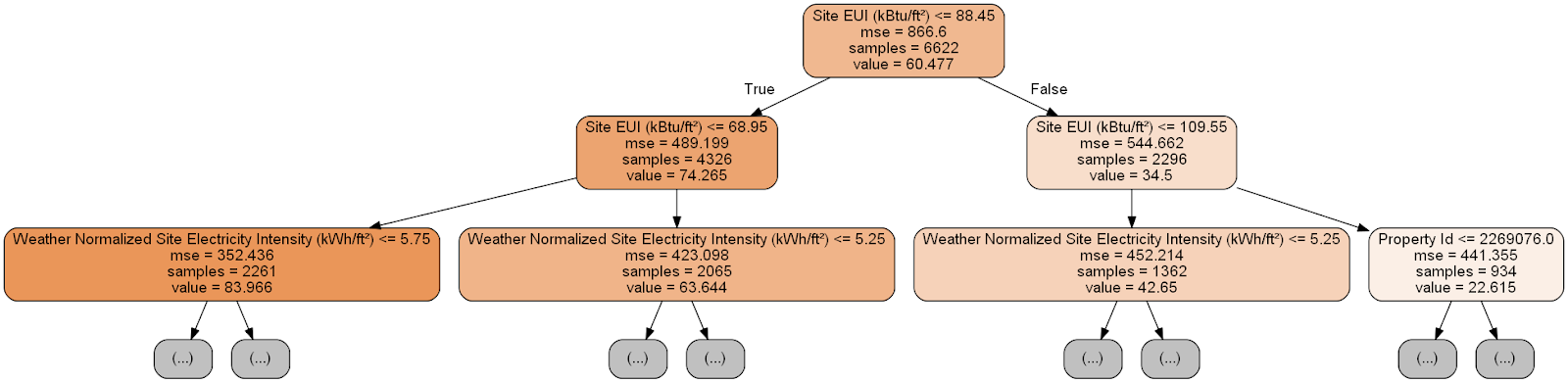
Chaque nœud (rectangle) de l'arbre contient quatre lignes:
- Question posée sur la valeur d'un des signes d'une dimension particulière: cela dépend de la direction dans laquelle nous sortirons de ce nœud.
Mse est une mesure d'erreur dans un nœud.Samples - le nombre d'échantillons de données (mesures) dans le nœud.- Évaluation de l'objectif de
Value pour tous les échantillons de données dans le nœud.
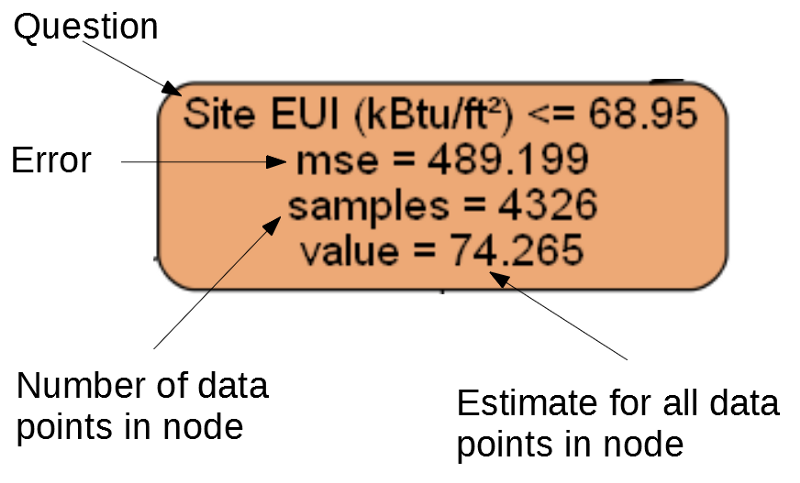 Noeud séparé.
Noeud séparé.(Les feuilles ne contiennent que 2. –4., Parce qu'elles représentent le score final et n'ont pas de nœuds enfants).
La prévision d'une mesure donnée dans l'arbre de décision commence à partir du nœud supérieur - la racine, puis descend dans l'arbre. Dans chaque nœud, vous devez répondre à la question posée «oui» ou «non». Par exemple, l'illustration précédente demande: «Le site EUI building est-il inférieur ou égal à 68,95?» Si oui, l'algorithme va au nœud enfant droit, sinon, à gauche.
Cette procédure est répétée sur chaque couche de l'arbre jusqu'à ce que l'algorithme atteigne le nœud feuille sur la dernière couche (ces nœuds ne sont pas représentés dans l'illustration avec l'arbre réduit). La prévision pour n'importe quelle dimension dans la feuille de calcul est une
value . Si plusieurs mesures viennent sur la feuille, chacune d'elles recevra la même prévision. À mesure que la profondeur de l'arbre augmente, l'erreur sur les données d'apprentissage diminue, car il y aura plus de feuilles et les échantillons seront divisés plus soigneusement. Cependant, un arbre trop profond entraînera un
recyclage des données de formation et ne sera pas en mesure de généraliser les données de test.
Dans le
deuxième article, nous avons défini le nombre d'hyperparamètres de modèle qui contrôlent chaque arbre, par exemple, la profondeur maximale de l'arbre et le nombre minimum d'échantillons nécessaires pour chaque feuille. Ces deux paramètres affectent fortement l'équilibre entre le sur et le sous-apprentissage, et la visualisation de l'arbre de décision nous permettra de comprendre comment ces paramètres fonctionnent.
Bien que nous ne puissions pas étudier tous les arbres du modèle, l'analyse de l'un d'eux aidera à comprendre comment chaque «élève» prédit. Cette méthode basée sur un organigramme est très similaire à la façon dont une personne prend une décision.
Les ensembles d'arbres de décision combinent les prévisions de nombreux arbres individuels, ce qui vous permet de créer des modèles plus précis avec moins de variabilité. Ces ensembles sont
très précis et faciles à expliquer.
Explications dépendantes du modèle interprétable local (LIME)
Le dernier outil avec lequel vous pouvez essayer de comprendre comment notre modèle «pense». LIME vous permet d'expliquer
comment une seule prévision est générée pour n'importe quel modèle d'apprentissage automatique . Pour ce faire, localement, à côté de certaines mesures, un modèle simplifié est créé sur la base d'un modèle simple tel que la régression linéaire (les détails sont décrits dans cet ouvrage:
https://arxiv.org/pdf/1602.04938.pdf ).
Nous utiliserons la méthode LIME pour étudier la prévision complètement erronée de notre modèle et comprendre pourquoi il se trompe.
Nous trouvons d'abord cette prévision incorrecte. Pour ce faire, nous allons former le modèle, générer une prévision et sélectionner la valeur avec l'erreur la plus importante:
from sklearn.ensemble import GradientBoostingRegressor
Prédiction: 12.8615
Valeur réelle: 100,0000Ensuite, nous créons un explicateur et nous lui donnons les données d'entraînement, les informations de mode, les étiquettes pour les données d'entraînement et les noms des attributs. Il est maintenant possible de transmettre les données d'observation et la fonction de prévision à l'explicateur, puis de leur demander d'expliquer la raison de l'erreur de prévision.
import lime
Tableau d'explication des prévisions:
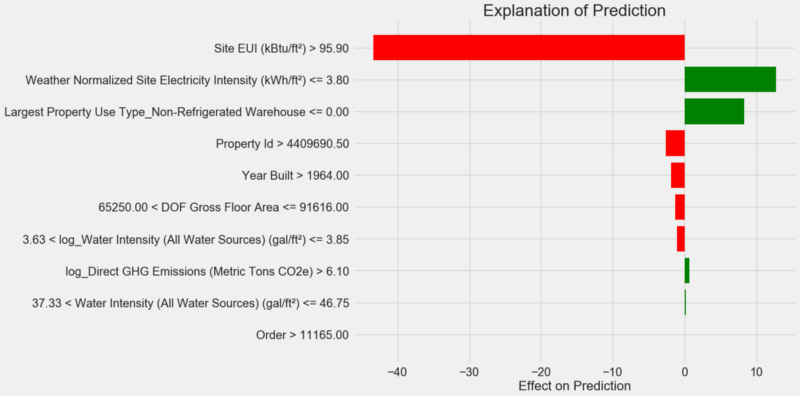
Comment interpréter le diagramme: chaque enregistrement le long de l'axe Y indique une valeur de la variable, et les barres rouges et vertes reflètent l'influence de cette valeur sur la prévision. Par exemple, selon l'enregistrement supérieur, l'influence du
Site EUI supérieure à 95,90, par conséquent, environ 40 points sont soustraits de la prévision. Selon le deuxième enregistrement, l'influence de l'
Weather Normalized Site Electricity Intensity inférieure à 3,80, et donc environ 10 points sont ajoutés aux prévisions. La prévision finale est la somme de l'ordonnée à l'origine et des effets de chacune des valeurs énumérées.
Regardons-le dans l'autre sens et appelons la méthode
.show_in_notebook() :

Le processus de prise de décision par le modèle est illustré à gauche: l'effet sur la prévision de chaque variable est affiché visuellement. Le tableau de droite montre les valeurs réelles des variables pour une mesure donnée.
Dans ce cas, le modèle prédit environ 12 points, mais en fait c'était 100. Au début, vous vous demandez peut-être pourquoi cela s'est produit, mais si vous analysez l'explication, il s'avère que ce n'est pas une hypothèse extrêmement audacieuse, mais le résultat du calcul basé sur des valeurs spécifiques.
Site EUI était relativement élevé et on pouvait s'attendre à un score Energy Star faible (car il est fortement influencé par l'EUI), ce que notre modèle a fait. Mais dans ce cas, cette logique s'est avérée erronée, car en fait, le bâtiment a reçu le score Energy Star le plus élevé - 100.
Les erreurs de modèle peuvent vous déranger, mais ces explications vous aideront à comprendre pourquoi le modèle était incorrect. De plus, grâce aux explications, vous pouvez commencer à découvrir pourquoi le bâtiment a obtenu le score le plus élevé malgré le site EUI élevé. Peut-être que nous apprendrons quelque chose de nouveau sur notre tâche qui échapperait à notre attention si nous ne commencions pas à analyser les erreurs de modèle. De tels outils ne sont pas idéaux, mais ils peuvent grandement faciliter la compréhension du modèle et prendre de
meilleures décisions .
Documentation des travaux et présentation des résultats
De nombreux projets accordent peu d'attention à la documentation et aux rapports. Vous pouvez faire la meilleure analyse au monde, mais si vous ne
présentez pas
correctement les résultats , ils n'auront pas d'importance!
En documentant un projet d'analyse de données, nous emballons toutes les versions des données et du code afin que d'autres personnes puissent reproduire ou collecter le projet. N'oubliez pas que le code est lu plus souvent qu'écrit, donc notre travail devrait être clair pour les autres et pour nous, si nous y revenons dans quelques mois. Par conséquent, insérez des commentaires utiles dans le code et expliquez vos décisions.
Les cahiers Jupyter sont un excellent outil de documentation; ils vous permettent d'abord d'expliquer les solutions, puis d'afficher le code.
De plus, Jupyter Notebook est une bonne plate-forme pour interagir avec d'autres spécialistes. En utilisant les
extensions pour les blocs-notes, vous pouvez
masquer le code du rapport final , car peu importe à quel point c'est difficile à croire, tout le monde ne veut pas voir un tas de code dans le document!
Vous ne voudrez peut-être pas faire de compression, mais montrez tous les détails. Cependant, il est important
de comprendre votre public lors de la présentation de votre projet et de
préparer un rapport en conséquence . Voici un exemple de résumé de l'essence de notre projet:
- À l'aide de données sur la consommation d'énergie des bâtiments à New York, vous pouvez créer un modèle qui prédit le nombre de points Energy Star avec une erreur de 9,1 points.
- L'IUE du site et l'intensité électrique normalisée par les conditions météorologiques sont les principaux facteurs qui influencent les prévisions.
Nous avons écrit une description détaillée et des conclusions dans le bloc-notes Jupyter, mais au lieu de PDF, nous avons converti le fichier .tex en
Latex , que nous avons ensuite édité dans
texStudio , et la
version résultante a été convertie en PDF. Le fait est que le résultat d'exportation par défaut de Jupyter vers PDF semble assez décent, mais il peut être considérablement amélioré en quelques minutes d'édition. De plus, Latex est un puissant système de préparation de documents utile à posséder.
En fin de compte, la valeur de notre travail est déterminée par les décisions qu’il aide à prendre, et il est très important de pouvoir «livrer la marchandise en personne». En documentant correctement, nous aidons d'autres personnes à reproduire nos résultats et nous donnons des commentaires, ce qui nous permettra de devenir plus expérimentés et de compter sur les résultats obtenus à l'avenir.
Conclusions
Dans notre série de publications, nous avons couvert un didacticiel d'apprentissage automatique du début à la fin. Nous avons commencé par effacer les données, puis créé un modèle, et finalement nous avons appris à l'interpréter. Rappelons la structure générale du projet d'apprentissage automatique:
- Nettoyage et formatage des données.
- Analyse exploratoire des données.
- Conception et sélection de fonctionnalités.
- Comparaison des métriques de plusieurs modèles d'apprentissage automatique.
- Réglage hyperparamétrique du meilleur modèle.
- Évaluation du meilleur modèle sur un ensemble de données de test.
- Interprétation des résultats du modèle.
- Conclusions et rapport bien documenté.
L'ensemble des étapes peut varier selon le projet et l'apprentissage automatique est souvent itératif plutôt que linéaire, donc ce guide vous aidera à l'avenir. Nous espérons que vous pouvez désormais réaliser vos projets en toute confiance, mais n'oubliez pas: personne n'agit seul! Si vous avez besoin d'aide, il existe de nombreuses communautés très utiles où vous recevrez des conseils.
Ces sources peuvent vous aider: