Bonjour, Habr! Je vous présente la traduction de l'article "Former votre premier réseau neuronal: classification de base" .

Ceci est un guide de formation de modèle de réseau de neurones pour classer des images de vêtements tels que des baskets et des chemises. Pour créer un réseau de neurones, nous utilisons python et la bibliothèque TensorFlow.
Installer TensorFlow
Pour le travail, nous avons besoin des bibliothèques suivantes:
- numpy (sur la ligne de commande, nous écrivons: pip install numpy)
- matplotlib (sur la ligne de commande, nous écrivons: pip install matplotlib)
- keras (sur la ligne de commande, nous écrivons: pip install keras)
- jupyter (sur la ligne de commande, nous écrivons: pip install jupyter)
Utilisation de pip: sur la ligne de commande, écrivez pip install tensorflow
Si vous obtenez une erreur, vous pouvez télécharger le fichier .whl et l'installer à l'aide de pip: pip install file_path \ file_name.whl
Guide d'installation officiel de TensorFlow
Lancez Jupyter. Pour commencer à la ligne de commande, écrivez le cahier jupyter.
Pour commencer
Ce guide utilise le jeu de données Fashion MNIST, qui contient 70 000 images en niveaux de gris dans 10 catégories. Les images montrent des vêtements individuels à faible résolution (28 par 28 pixels):

Nous utiliserons 60 000 images pour former le réseau et 10 000 images pour évaluer la précision avec laquelle le réseau a appris à classer les images. Vous pouvez accéder à Fashion MNIST directement depuis TensorFlow en important et en téléchargeant simplement les données:
fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Le chargement d'un jeu de données renvoie quatre tableaux NumPy:
- Les tableaux train_images et train_labels sont les données que le modèle utilise pour la formation
- Les tableaux test_images et test_labels sont utilisés pour tester le modèle.
Les images sont des tableaux NumPy 28x28 dont les valeurs de pixels vont de 0 à 255. Les étiquettes sont un tableau d'entiers de 0 à 9. Ils correspondent à la classe de vêtements:
| Étiquette | Classe |
| 0 | T-shirt (T-shirt) |
| 1 | Pantalon (pantalon) |
| 2 | Pull (Pull) |
| 3 | Robe |
| 4 | Manteau (Manteau) |
| 5 | Sandale |
| 6 | Chemise |
| 7 | Sneaker (Baskets) |
| 8 | Sac |
| 9 | Bottines (Bottines) |
Les noms de classe ne sont pas inclus dans l'ensemble de données, nous le prescrivons donc nous-mêmes:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Exploration des données
Tenez compte du format de l'ensemble de données avant d'entraîner le modèle.
train_images.shape
Prétraitement des données
Avant de préparer le modèle, les données doivent être prétraitées. Si vous cochez la première image de l'ensemble d'entraînement, vous verrez que les valeurs des pixels sont comprises entre 0 et 255:
plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False)

Nous adaptons ces valeurs à une plage de 0 à 1:
train_images = train_images / 255.0 test_images = test_images / 255.0
Nous affichons les 25 premières images de l'ensemble de formation et affichons le nom de la classe sous chaque image. Assurez-vous que les données sont au format correct.
plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]])

Construction de modèles
La construction d'un réseau de neurones nécessite des couches de réglage du modèle.
Le bloc de construction principal du réseau neuronal est la couche. La majeure partie du deep learning consiste à combiner des couches simples. La plupart des couches, telles que tf.keras.layers.Dense, ont des paramètres qui sont appris pendant la formation.
model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation=tf.nn.relu), keras.layers.Dense(10, activation=tf.nn.softmax) ])
La première couche du réseau tf.keras.layers.Flatten convertit le format d'image d'un tableau 2d (28 par 28 pixels) en un tableau 1d de 28 * 28 = 784 pixels. Cette couche n'a pas de paramètres à étudier, elle ne fait que reformater les données.
Les deux couches suivantes sont tf.keras.layers.Dense. Ce sont des couches neuronales étroitement connectées ou entièrement connectées. La première couche dense contient 128 nœuds (ou neurones). Le deuxième (et dernier) niveau est une couche à 10 nœuds tf.nn.softmax, qui renvoie un tableau de dix estimations de probabilité, dont la somme est 1. Chaque nœud contient une estimation qui indique la probabilité que l'image actuelle appartient à l'une des 10 classes.
Compiler un modèle
Avant que le modèle ne soit prêt pour la formation, il aura besoin de quelques réglages supplémentaires. Ils sont ajoutés lors de la phase de compilation du modèle:
- Fonction de perte - mesure la précision du modèle pendant l'entraînement
- L'optimiseur est la façon dont le modèle est mis à jour en fonction des données qu'il voit et de la fonction de perte.
- Métriques (métriques) - utilisées pour contrôler les étapes de la formation et des tests
model.compile(optimizer=tf.train.AdamOptimizer(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Formation modèle
L'apprentissage d'un modèle de réseau neuronal nécessite les étapes suivantes:
- Soumission des données de formation du modèle (dans cet exemple, les tableaux train_images et train_labels)
- Un modèle apprend à associer des images et des balises.
- Nous demandons au modèle de faire des prédictions sur la suite de tests (dans cet exemple, le tableau test_images). Nous vérifions la conformité des prévisions d'étiquettes du tableau d'étiquettes (dans cet exemple, le tableau test_labels)
Pour commencer la formation, appelez la méthode model.fit:
model.fit(train_images, train_labels, epochs=5)
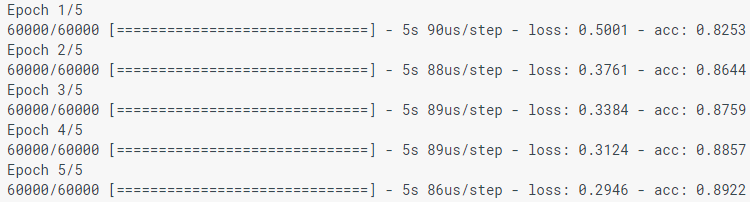
Lors de la modélisation du modèle, les indicateurs de perte (perte) et de précision (acc) sont affichés. Ce modèle atteint une précision d'environ 0,88 (ou 88%) selon les données d'entraînement.
Indice de précision
Comparez le fonctionnement du modèle dans un jeu de données de test:
test_loss, test_acc = model.evaluate(test_images, test_labels) print('Test accuracy:', test_acc)

Il s'avère que la précision dans l'ensemble de données de test est légèrement inférieure à la précision dans l'ensemble de données d'apprentissage. Cet écart entre la précision de la formation et la précision des tests est un exemple de recyclage. La reconversion est lorsqu'un modèle d'apprentissage automatique fonctionne moins bien avec de nouvelles données qu'avec des données de formation.
Prévision
Nous utilisons le modèle pour prédire certaines images.
predictions = model.predict(test_images)
Ici, le modèle a prédit l'étiquette pour chaque image dans le cas de test. Regardons la première prédiction:
predictions[0]

La prédiction est un tableau de 10 nombres. Ils décrivent la «confiance» du modèle que l'image correspond à chacun des 10 vêtements différents. Nous pouvons voir quelle étiquette a la valeur de confiance la plus élevée:
np.argmax(predictions[0])
Ainsi, le modèle est plus confiant que cette image est Bottine (Bottines), ou class_names [9]. Et nous pouvons vérifier l'étiquette de test pour nous assurer que c'est correct:
test_labels[0]
Nous allons écrire des fonctions pour visualiser ces prédictions.
def plot_image(i, predictions_array, true_label, img): predictions_array, true_label, img = predictions_array[i], true_label[i], img[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
Regardons la 0ème image, les prédictions et un tableau de prédictions.
i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)

Construisons quelques images avec leurs prévisions. Les étiquettes de prévision correctes sont bleues et les étiquettes de prévision incorrectes sont rouges. Veuillez noter que cela peut être faux même s'il est très confiant.
num_rows = 5 num_cols = 3 num_images = num_rows*num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i+1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i+2) plot_value_array(i, predictions, test_labels)

Enfin, nous utilisons un modèle entraîné pour faire une prédiction sur une seule image.
Les modèles Tf.keras sont optimisés pour faire des prédictions pour les packages (batch) ou les collections (collection). Par conséquent, bien que nous utilisions une seule image, nous devons l'ajouter à la liste:
Prévisions pour l'image:
predictions_single = model.predict(img) print(predictions_single)

plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)

np.argmax(predictions_single[0])
Comme précédemment, le modèle prédit l'étiquette 9.
Si vous avez des questions, écrivez dans les commentaires ou dans des messages privés.