Le développement de réseaux de neurones profonds pour la reconnaissance d'images insuffle une nouvelle vie dans les domaines de recherche déjà connus en apprentissage automatique. L'un de ces domaines est l'adaptation du domaine. L'essence de cette adaptation est de former le modèle sur les données du domaine source (domaine source) afin qu'il montre une qualité comparable sur le domaine cible (domaine cible). Par exemple, un domaine source peut être des données synthétiques qui peuvent être générées à moindre coût, et un domaine cible peut être des photos d'utilisateurs. Ensuite, la tâche de l'adaptation du domaine est de former le modèle sur des données synthétiques, qui fonctionneront bien avec des objets "réels".
Au sein du groupe de vision industrielle Vision.BIZ.Ru, nous travaillons sur divers problèmes appliqués, et parmi eux il y a souvent ceux pour lesquels il y a peu de données de formation. Dans ces cas, la génération de données synthétiques et l'adaptation du modèle formé sur celles-ci peuvent grandement aider. Un bon exemple appliqué de cette approche est la tâche de détecter et de reconnaître les marchandises sur les étagères d'un magasin. Obtenir des photos de telles étagères et les marquer est assez laborieux, mais elles peuvent être générées tout simplement. Par conséquent, nous avons décidé d'approfondir le sujet de l'adaptation de domaine.

Les études en adaptation de domaine affectent l'utilisation de l'expérience acquise par un réseau de neurones dans une nouvelle tâche. Le réseau pourra-t-il extraire certaines fonctionnalités du domaine source et les utiliser dans le domaine cible? Bien qu'un réseau de neurones dans l'apprentissage automatique ne soit que de loin lié aux réseaux de neurones dans le cerveau humain, néanmoins, le Saint Graal des chercheurs en intelligence artificielle est d'enseigner aux réseaux de neurones les capacités d'une personne. Et les gens peuvent utiliser leur expérience antérieure et leurs connaissances accumulées pour comprendre de nouveaux concepts.
De plus, l'adaptation de domaine peut aider à résoudre l'un des problèmes fondamentaux de l'apprentissage en profondeur: pour former de grands réseaux avec une qualité de reconnaissance élevée, une très grande quantité de données est nécessaire, ce qui en pratique n'est pas toujours disponible. Une solution peut être d'utiliser des méthodes d'adaptation de domaine sur des données synthétiques qui peuvent être générées en quantités pratiquement illimitées.
Très souvent, dans les problèmes appliqués, il existe un cas où les données d'un seul domaine sont disponibles pour la formation, et le modèle doit être appliqué sur un autre domaine. Par exemple, le réseau qui détermine la qualité esthétique de la photographie peut être formé sur une base de données disponible sur le réseau, collectée sur le site amateur. Et il est prévu d'utiliser ce réseau dans des photographies ordinaires, dont le niveau de qualité diffère en moyenne du niveau d'une photo d'un site photo spécialisé. Comme solution, nous pouvons envisager d'adapter le modèle aux photographies ordinaires sans étiquette.
Ces questions théoriques et appliquées relèvent du domaine de l'adaptation. Dans cet article, je parlerai des principales recherches dans ce domaine, basées sur l'apprentissage en profondeur, et des ensembles de données pour comparer différentes méthodes. L'idée principale de l'adaptation du domaine profond est de former un réseau neuronal profond sur le domaine source, ce qui traduira l'image en une telle intégration (généralement la dernière couche du réseau) que lorsqu'elle est utilisée sur le domaine cible, une haute qualité sera obtenue.
Repères de base
Comme dans n'importe quel domaine de l'apprentissage automatique, une certaine quantité de recherche est accumulée dans l'adaptation du domaine au fil du temps, qui doit être comparée les unes aux autres. Pour cela, la communauté développe des jeux de données, sur la partie formation dont les modèles sont formés, et sur la partie test ils sont comparés. Malgré le fait que le domaine de recherche de l'adaptation en domaine profond soit encore relativement jeune, il existe déjà un nombre assez important d'articles et de bases de données qui sont utilisés dans ces articles. Je vais énumérer les principaux, en me concentrant sur l'adaptation du domaine des données synthétiques au «réel».
Les chiffres
Apparemment, selon la tradition instituée par Yann LeCun (l'un des pionniers de l'apprentissage en profondeur, directeur de Facebook AI Research), en vision par ordinateur, les ensembles de données les plus simples sont associés à des chiffres ou des lettres manuscrites. Il existe plusieurs ensembles de données avec des nombres qui sont apparus à l'origine pour expérimenter avec des modèles de reconnaissance d'image. Dans les articles sur l'adaptation de domaine, on peut trouver une variété de leurs combinaisons dans des paires de domaine source-cible. Parmi ces ensembles de données:
- MNIST - numéros manuscrits, n'a pas besoin de présentation supplémentaire;
- USPS - nombres manuscrits en basse résolution;
- SVHN - numéros de maison avec Google Street View;
- Les nombres synthétiques sont des nombres synthétiques, comme son nom l'indique.
Du point de vue de la tâche de formation sur les données synthétiques utilisables dans le monde "réel", les plus intéressantes sont les paires:
- Source: MNIST, cible: SVHN;
- Source: USPS, cible: MNIST;
- Source: Synth Numbers, cible: SVHN.

La plupart des méthodes ont des références sur des ensembles de données "numériques". Mais les autres types de domaines sont loin d'être retrouvés dans tous les articles.
Bureau
Cet ensemble de données contient 31 catégories de divers éléments, chacun étant représenté dans 3 domaines: une image d'Amazon, une photo d'une webcam et une photo d'un appareil photo numérique.

Il est utile pour vérifier comment le modèle répondra à l'ajout d'arrière-plan et de qualité au domaine cible.
Panneaux de signalisation
Une autre paire de jeux de données pour former le modèle sur des données synthétiques et l'appliquer à des données "réelles":
- Source: Synth Signs - images de panneaux de signalisation générés de manière à ressembler à de vrais panneaux de signalisation dans la rue;
- Cible: GTSRB est une base de reconnaissance assez bien connue contenant des panneaux provenant des routes allemandes.

Une caractéristique de cette paire de bases de données est que les données de Synth Signs sont assez similaires aux données «réelles», donc les domaines sont assez proches.
De la fenêtre de la voiture
Ensembles de données pour la segmentation. Un couple assez intéressant, le plus proche des conditions réelles. Les données sources sont obtenues à l'aide du moteur de jeu (GTA 5) et les données cibles proviennent de la vie réelle. Des approches similaires sont utilisées pour former des modèles utilisés dans les voitures autonomes.
- Moteur SYNTHIA ou GTA 5 - images d'une vue de la ville depuis une fenêtre de voiture générées à l'aide d'un moteur de jeu;
- Paysages urbains - Photos d'une voiture prise dans 50 villes différentes.

VisDA
Cet ensemble de données est utilisé dans le cadre du défi d'adaptation du domaine visuel , qui fait partie d'un atelier sur l'ECCV et l'ICCV. Le domaine source contient 12 catégories d'objets étiquetés générés à l'aide de la CAO, tels qu'un avion, un cheval, une personne, etc. Le domaine cible contient des images non étiquetées des 12 mêmes catégories prises sur ImageNet. Dans la compétition, qui s'est tenue en 2018, la 13e catégorie a été ajoutée: Inconnu.
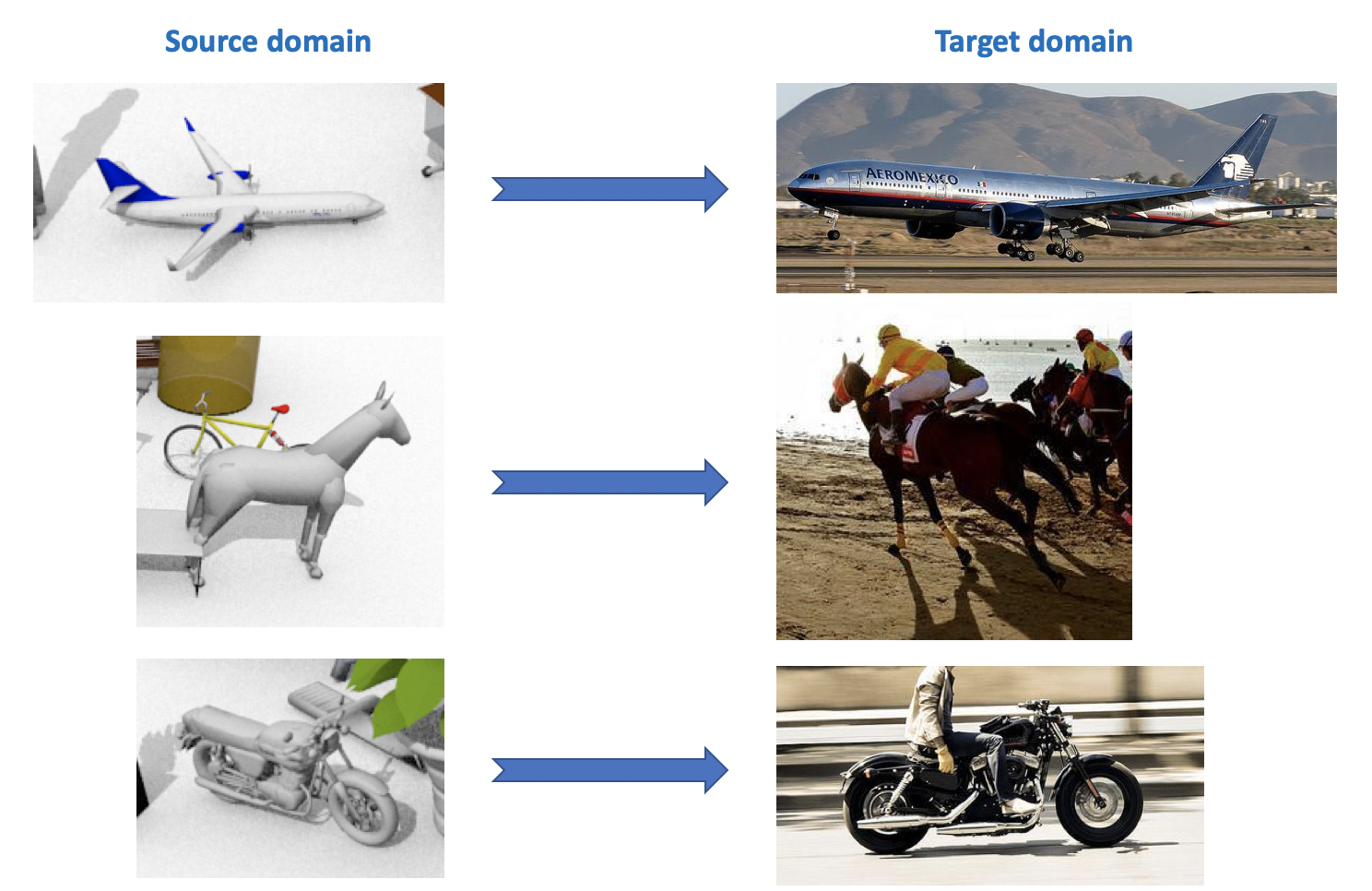
Comme vous pouvez le voir à partir de tout ce qui précède, il existe de nombreux ensembles de données intéressants et divers pour l'adaptation du domaine, vous pouvez former et tester des modèles sur eux pour diverses tâches (classification, segmentation, détection) et diverses conditions (données synthétiques, photos, vues de rue).
Adaptation de domaine profond
Il existe une classification assez vaste et variée des méthodes d'adaptation de domaine (par exemple , voir ici ). Je donnerai dans cet article une répartition simplifiée des méthodes en fonction de leurs principales caractéristiques. Les méthodes modernes d'adaptation de domaine profond peuvent être divisées en 3 grands groupes:
- Basée sur les écarts: approches basées sur la minimisation de la distance entre les représentations vectorielles sur les domaines source et cible en introduisant cette distance dans la fonction de perte.
- Adversarial-Based : ces approches utilisent la fonction de perte accusatoire introduite dans les GAN pour former un réseau invariant de domaine. Les méthodes de cette famille ont été activement développées ces dernières années.
- Méthodes mixtes qui n'utilisent pas la perte contradictoire, mais appliquent les idées de la famille basée sur les écarts, ainsi que les derniers développements de l'apprentissage profond: auto-assemblage, nouvelles couches, fonctions de perte, etc. Ces approches montrent les meilleurs résultats dans la compétition VisDA.
À partir de chaque section, plusieurs résultats de base, à mon avis, seront pris en compte.
Basé sur les écarts
Lorsque survient le problème de l'adaptation d'un modèle à de nouvelles données, la première chose qui vient à l'esprit est l'utilisation d'un réglage fin, c'est-à-dire recycler le modèle sur de nouvelles données. Pour ce faire, tenez compte de l'écart entre les domaines. Ce type d'adaptation de domaine peut être divisé en trois approches: critère de classe, critère statistique et critère d'architecture.
Critère de classe
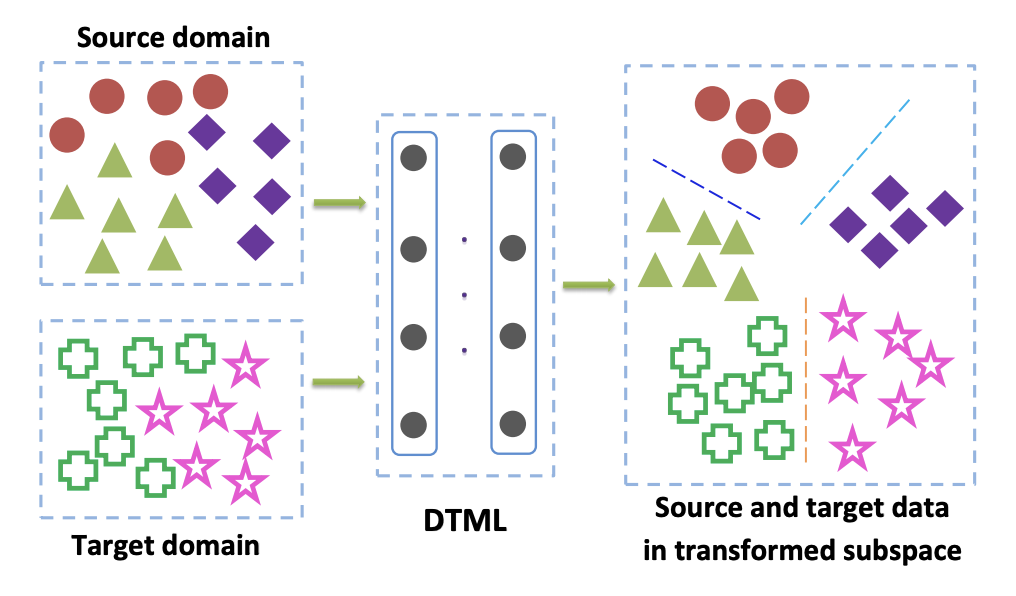
Les méthodes de cette famille sont principalement utilisées lorsque nous avons accès aux données balisées du domaine cible. L'une des options populaires pour le critère de classe est l'approche d' apprentissage métrique de transfert profond . Comme son nom l'indique, il est basé sur l'apprentissage métrique, dont l'essence est de former une telle représentation vectorielle obtenue à partir d'un réseau de neurones que les représentants d'une classe seront proches les uns des autres dans cette représentation selon une métrique donnée (le plus souvent utiliser L 2 ou métriques cosinus). Dans l'article Deep transfer metric learning (DTML) , une perte constituée de la somme des termes est utilisée pour implémenter cette approche:
- La proximité des représentants d'une classe les uns aux autres (compacité intraclasse);
- Augmentation de la distance entre les représentants de différentes classes (séparabilité interclasse);
- Mesure de l'écart moyen maximal (MMD) entre les domaines. Cette métrique appartient à la famille de critères statistiques (voir ci-dessous), mais elle est également utilisée dans le critère de classe.
MMD entre les domaines est écrit comme
MMD2(Ds,Dt)= Vert frac1M sumMi=1 phi(xsi)− frac1N sumNj=1 phi(xtj) Vert2H,
où phi(x) - c'est un noyau, dans notre cas - une représentation vectorielle du réseau, xsi,i in1 ldotsM - les données du domaine source, xti,i in1 ldotsN - les données du domaine cible. Ainsi, lors de la minimisation de la métrique MMD pendant la formation, un tel réseau est sélectionné phi(x) de sorte que ses représentations vectorielles moyennes sur les deux domaines sont proches. L'idée principale de DTML:
Si les données du domaine cible ne sont pas étiquetées (adaptation de domaine non supervisée), la méthode décrite dans Attention au biais de pondération de classe: écart moyen maximal pondéré pour l'adaptation de domaine non supervisé propose de former le modèle sur le domaine source et de l'utiliser pour obtenir des pseudo-étiquettes (pseudo- étiquettes) sur le domaine cible. C'est-à-dire les données du domaine cible sont exécutées via le réseau et le résultat est appelé pseudo-étiquettes. Ensuite, ils sont utilisés comme balisage pour le domaine cible, ce qui permet d'appliquer le critère MMD dans la fonction de perte (avec des poids différents pour les composants responsables de différents domaines).
Critère statistique
Des méthodes liées à cette famille sont utilisées pour résoudre le problème d'adaptation de domaine non supervisé. Le cas où le domaine cible n'est pas affecté se produit dans de nombreux problèmes et toutes les méthodes d'adaptation de domaine, qui seront discutées plus loin dans cet article, résolvent exactement un tel problème.
Des approches basées sur des critères statistiques tentent de mesurer la différence entre les distributions de la représentation vectorielle du réseau obtenues à partir des données des domaines source et cible. Ils utilisent ensuite la différence calculée pour rapprocher ces deux distributions.
L'un de ces critères est l' écart moyen maximal (MMD) déjà décrit ci-dessus. Ses variantes sont utilisées dans plusieurs méthodes:
Les schémas de ces trois méthodes sont présentés ci-dessous. Dans celles-ci, les variantes MMD sont utilisées pour déterminer la différence entre les distributions sur les couches du réseau neuronal convolutionnel appliquées aux domaines source et cible. Veuillez noter que chacun d'eux utilise la modification MMD comme une perte entre les couches de réseaux de convolution (chiffres jaunes sur le diagramme).

Le critère CORAL (CORrelation ALignment) et son extension à l'aide des réseaux Deep CORAL visent à apprendre une telle représentation des données afin que les statistiques de second ordre entre domaines correspondent au maximum. Pour cela, des matrices de covariance des représentations vectorielles du réseau sont utilisées. La convergence des statistiques de second ordre sur les deux domaines permet dans certains cas d'obtenir de meilleurs résultats d'adaptation que pour MMD.
LCORAL= frac14d2 VertCS−CT Vert2F,
où ||∗||2F Est le carré de la norme de la matrice Frobenius, et Cs et Ct - les données de la matrice de covariance des domaines source et cible, respectivement, d - la dimension de la représentation vectorielle.
Sur l'ensemble de données Office, la qualité moyenne d'adaptation à l'aide de Deep CORAL pour les paires de domaines Amazon et Webcam est de 72,1%. Sur Synth Signs -> GTSRB road sign domaines, le résultat est également très moyen: 86,9% de précision sur le domaine cible.
Le développement des idées MMD et CORAL est le critère Central Moment Discrepancy (CMD) , qui compare les moments centraux des données des domaines source et cible de toutes les commandes jusqu'à K inclus ( K - paramètre de l'algorithme). Sur l'ensemble de données Office, la qualité moyenne d'adaptation CMD pour les paires de domaines Amazon et Webcam est de 77,0%.
Critère d'architecture
Les algorithmes de ce type sont basés sur l'hypothèse que les informations de base qui sont responsables de l'adaptation à un nouveau domaine sont intégrées dans les paramètres d'un réseau neuronal.
Dans un certain nombre d'articles [1] , [2], lors de la formation de réseaux pour les domaines source et cible en utilisant des fonctions de perte pour chaque paire de couches, des informations invariantes par rapport au domaine sont étudiées sur les poids de ces couches. Un exemple de telles architectures est donné ci-dessous.
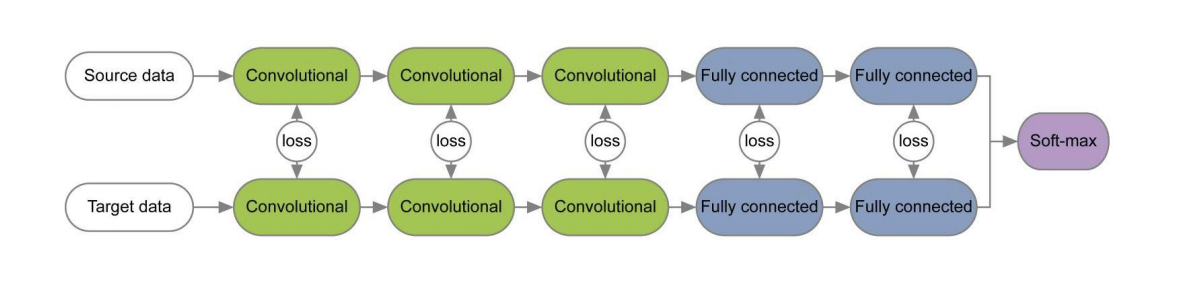
Dans l'article « Revisiter la normalisation des lots pour l'adaptation pratique du domaine», l'idée a été avancée que les échelles du réseau contiennent des informations relatives aux classes sur lesquelles le réseau étudie et que les informations du domaine sont intégrées dans les statistiques (moyenne et écart-type) des couches de normalisation des lots (BN). Par conséquent, pour l'adaptation, il est nécessaire de recalculer ces statistiques sur les données du domaine cible. L'utilisation de cette technique avec CORAL peut améliorer la qualité de l'adaptation sur l'ensemble de données Office pour les paires de domaines Amazon et Webcam jusqu'à 75,0%. Il a ensuite été démontré que l'utilisation de la couche de normalisation d'instance (IN) au lieu de BN améliore encore la qualité de l'adaptation. Contrairement à BN, qui normalise le tenseur d'entrée pour les lots, IN calcule les statistiques de normalisation par canaux et, par conséquent, ne dépend pas du lot.
Approches basées sur le contradictoire
Au cours des 1 à 2 dernières années, la plupart des résultats de l'adaptation dans le domaine profond sont liés à l'approche basée sur la confrontation. Cela est dû en grande partie au développement rapide et à la popularité des Réseaux Génératifs d'Adversariat (GAN) , parce que l'approche basée sur le contradictoire pour l'adaptation du domaine utilise la même fonction objective contradictoire dans la formation que le GAN. En l'optimisant, ces méthodes d'adaptation de domaine profond minimisent la distance entre les distributions empiriques des représentations de données vectorielles sur les domaines source et cible. En formant le réseau de cette manière, ils essaient de le rendre invariant par rapport au domaine.
GAN se compose de deux modèles: générateur G , à la sortie desquels des données d'une certaine distribution cible sont obtenues; et discriminateur D , qui détermine si les données de l'ensemble d'apprentissage ou générées à l'aide de G . Ces deux modèles sont entraînés à l'aide de la fonction objectif contradictoire:
minG maxDV(D,G)= mathbbEx simpdata(x)[ logD(x)]+ mathbbEz simp(z)[1− logD(G(z))].
Avec une telle formation, le générateur apprend à "tromper" le discriminateur, ce qui vous permet de rapprocher la distribution des domaines cible et source.
Il existe deux grandes approches dans l'adaptation de domaine basée sur l'adversaire qui diffèrent selon qu'un générateur est utilisé ou non. G .
Modèles non génératifs
Une caractéristique clé des méthodes de cette famille est la formation d'un réseau neuronal avec une représentation vectorielle invariante par rapport aux domaines source et cible. Ensuite, le réseau formé sur le domaine source marqué peut être utilisé sur le domaine cible, idéalement - pratiquement sans perte de qualité de classification.
Introduit en 2015, l' algorithme ( code ) de formation des réseaux de neurones (DANN) de domaine-adversaire se compose de 3 parties:
- Le réseau principal, à l'aide duquel une représentation vectorielle (extracteur de caractéristiques) est obtenue (la partie verte dans l'illustration ci-dessous);
- "Têtes" responsables du classement sur le domaine source (partie bleue sur l'illustration);
- Une «tête» qui apprend à distinguer les données du domaine source du domaine cible (la partie rouge dans l'illustration).
Lors de la formation à l'aide de la descente de gradient (SGD) (flèches à saisir dans l'illustration), les pertes de classification et de domaine sont minimisées. De plus, lorsque l'erreur d'apprentissage se propage vers l'arrière pour la «tête» responsable des domaines, la couche d'inversion de gradient (la partie noire dans l'illustration) est utilisée, qui multiplie le gradient qui la traverse par une constante négative, augmentant la perte de domaine. Cela garantit que les distributions des représentations vectorielles sur les deux domaines deviennent proches.
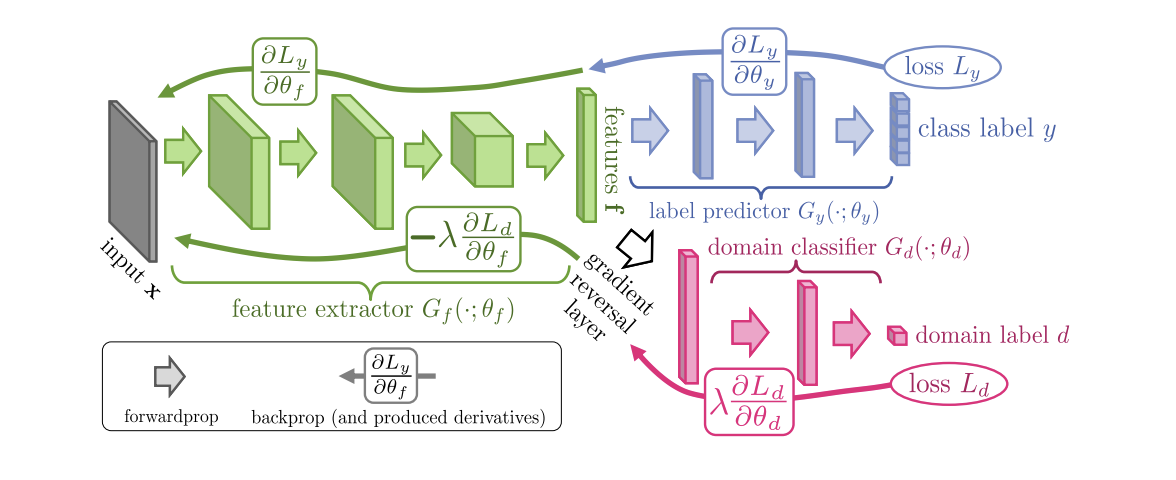
Résultats du benchmark DANN:
- Sur une paire de domaines numériques Numéros de synthèse -> SVHN: 91,09%.
- Sur Synth Signs -> GTSRB, il surpasse CORAL avec un résultat de 88,7%.
- Sur l'ensemble de données Office, la qualité moyenne d'adaptation pour les paires de domaines Amazon et Webcam est de 73,0%.
Le prochain représentant important de la famille des modèles non génératifs est la méthode ( code ) d' Adversarial Discriminative Domain Adaptation (ADDA ), qui implique la séparation du réseau pour le domaine source et du réseau pour le domaine cible. L'algorithme comprend les étapes suivantes:
- Tout d'abord, nous formons le réseau de classification sur le domaine source. On note sa représentation vectorielle Ms et mathbfXs - domaine source.
- Maintenant, initialisez le réseau neuronal pour le domaine cible en utilisant le réseau formé de l'étape précédente. Laisse-la Mt et mathbfXt - domaine cible.
- Passons à la formation contradictoire: nous formerons le discriminateur D à fixe Ms et Mt en utilisant la fonction objectif suivante:
minDLadvD( mathbfXs, mathbfXt,Ms,Mt)=− mathbbExs sim mathbfXs[ logD(Ms(xs))]− mathbbExt sim mathbfXt[ log(1−D(Mt(xt))))]
- Geler le discriminateur et le recyclage Mt sur le domaine cible:
minMs,MtLadvM( mathbfXs, mathbfXt,D)=− mathbbExt sim mathbfXt[ logD(Mt(xt))]
3 4 . ADDA , , adversarial- , . :
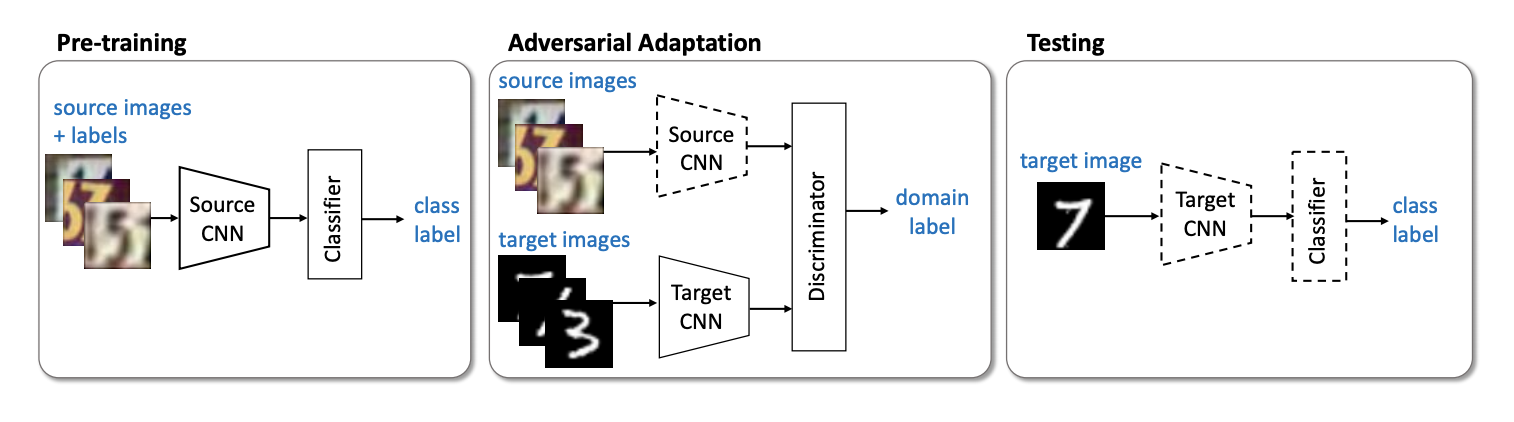
USPS -> MNIST ADDA 90,1 % .
ADDA ICML-2018 M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning ( ).
, M-ADDA metric learning, L2 -. 1 ADDA - Triplet loss ( ( ) ). , K ( K — ). Cj,j∈1…K .
ADDA, .. 2-4. 4 , Cj , :
Ext∼Xt[minj||Mt(xt)−Cj||2].
.
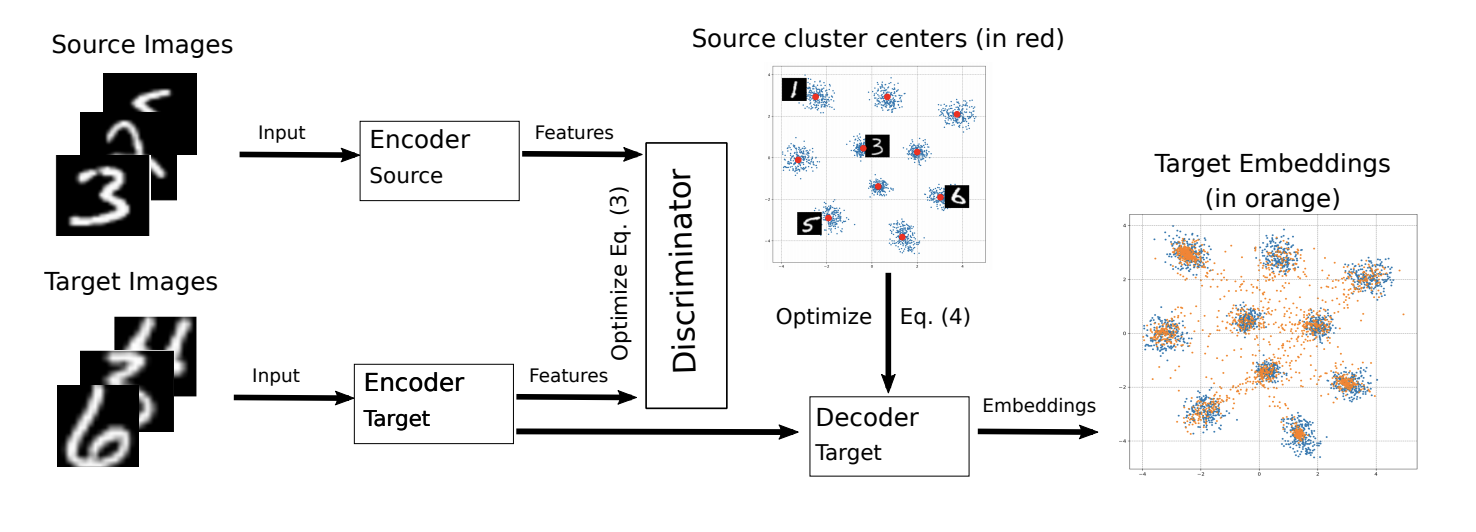
M-ADDA USPS -> MNIST 94,0 %.
non-generative Maximum Classifier Discrepancy for Unsupervised Domain Adaptation ( ). (), . , , .
G — , F1 et F2 — , . , G , F1 et F2 -; , ; , ; F1 et F2 .
, adversarial-, G , .
(Discrepancy Loss)
d(p1,p2)=1KK∑k=1|p1k−p2k|,
où K — , p1kp2k — softmax k - F1 et F2 .
3 :
- A. G , F1 et F2 .
- B. , .
- C . , , Discrepancy Loss.
n ( ). B C:
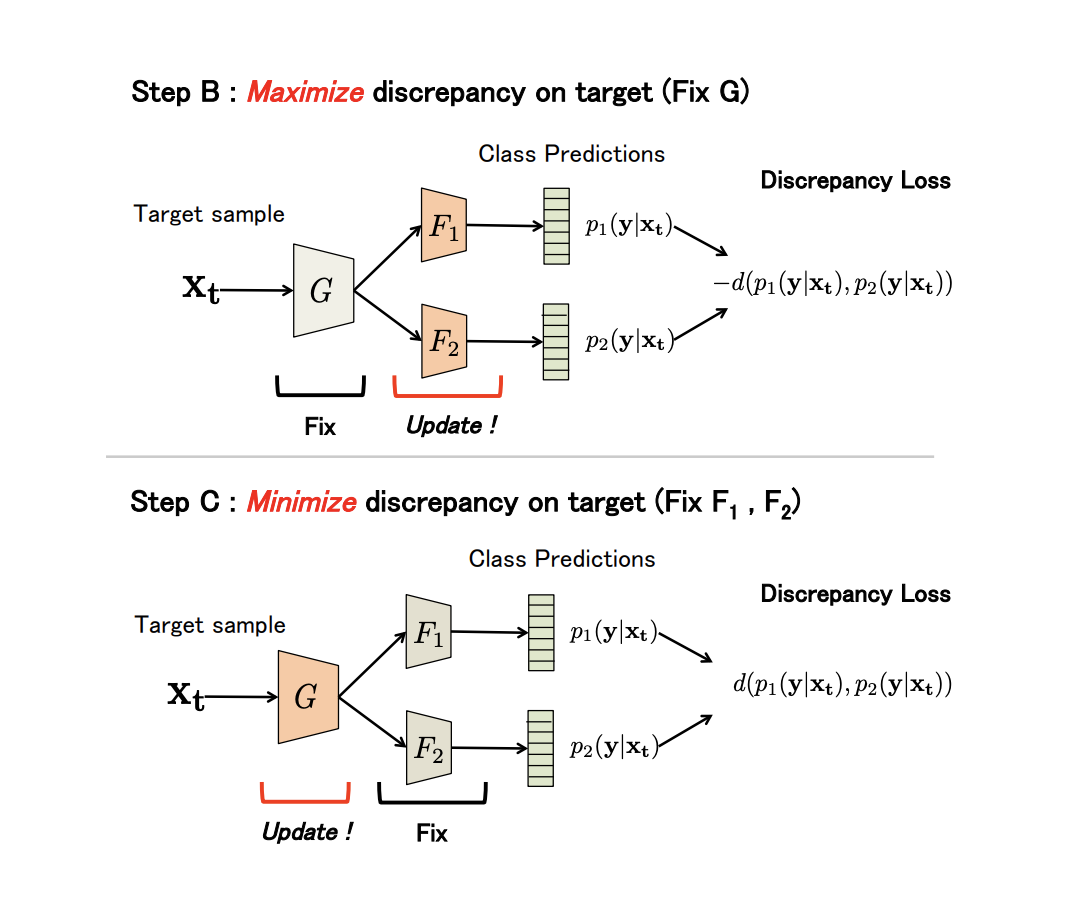
:
- USPS -> MNIST: 94,1 %.
- Synth Signs -> GTSRB : 94,4 %.
- VisDA 12 Unknown: 71,9 %.
- GTA 5 -> Cityscapes: Mean IoU = 39,7 %, Synthia -> Cityscapes: Mean IoU = 37,3 %
non-generative models:
.
Nous avons examiné les principaux ensembles de données pour l'adaptation de domaine, les approches basées sur les écarts: critère de classe, critère statistique et critère d'architecture, ainsi que la première famille non générative de méthodes basées sur la confrontation. Les modèles issus de ces approches montrent de bonnes performances sur les benchmarks et sont applicables à de nombreuses tâches d'adaptation. Dans la prochaine partie, nous examinerons les approches les plus complexes et les plus efficaces: les modèles génératifs et les méthodes mixtes non contradictoires.