Quelle est la clé pour réussir la mise en place de la livraison continue sur les projets? Travail bien coordonné d'ingénieurs en développement, tests et infrastructure. Merci, casquette, comme on dit :) Mais comment le mettre en pratique? Dans cet article, nous partagerons nos meilleures pratiques sur la façon d'organiser et de mettre en œuvre tout cela.
Nous avons résumé les bases de base dans une feuille de triche pour nous-mêmes et partageons avec vous:
Il est peu probable que les ingénieurs expérimentés apprennent quelque chose de nouveau de l'article, mais nous espérons que ces informations seront utiles aux débutants.

Quelles sont les exigences et comment sont-elles caractérisées
Chaque projet a un certain nombre d'exigences. Il est important de les comprendre tous et de ne pas les confondre.
Les exigences métier déterminent ce qu'un système doit faire d'un point de vue commercial.
Par exemple: l'application doit permettre à l'utilisateur de vendre des billets et des services supplémentaires afin d'augmenter les ventes d'agents.Les exigences des utilisateurs décrivent les buts et objectifs des utilisateurs qui travailleront dans le système pour mettre en œuvre les exigences commerciales. Les besoins des utilisateurs sont souvent présentés comme des cas d'utilisateurs.
Par exemple: en tant qu'utilisateur, je dois vendre des services pour des miles.Exigences fonctionnelles - ce que le système doit faire. Déterminez la fonctionnalité (comportement) du système, qui doit être créée par les développeurs afin que les utilisateurs puissent répondre aux exigences des utilisateurs.
Exigences non fonctionnelles - comment le système devrait fonctionner. Cela inclut les exigences de performances, de qualité, de limitations, de convivialité, etc.
Types de tâches et ordre de leur description dans Issue tracker
Nous avons donc décrit les types d'exigences. Nous allons maintenant les diviser en types de tâches, déchiffrer chaque type et expliquer comment le décrire correctement.

Commençons par le plus épique, c'est-à-dire avec Epic.
Epic est une tâche courante, dans laquelle toutes les histoires d'utilisateurs sont collectées en tenant compte du temps de développement du service. Il décrit l'objectif principal d'un produit ou d'un service. Le but principal d'Epic est de collecter les tâches et de les stocker en un seul endroit, quelles que soient les nouvelles exigences mises en avant pour le produit. Epic est toujours plus qu'une histoire d'utilisateur et peut même ne pas tenir dans une seule itération.
La solution du problème Epic vous permet de créer
MVP (Minimal Viable Product) - le produit minimum viable. En d'autres termes, ce qui doit être publié afin d'apprendre et d'adapter le produit en fonction des commentaires des utilisateurs finaux.
En quoi Epic est-il différent de User Story?
- Epic n'est qu'une grande histoire d'utilisateur, dont la caractéristique principale est la présence d'une valeur claire pour l'utilisateur.
- Commençant à former des user stories, c'est-à-dire à collecter les exigences d'un projet, nous passons généralement du général au particulier - nous déterminons d'abord le concept du projet, sélectionnons les personnes principales (utilisateurs du système), créons une liste des principales fonctionnalités, puis ces fonctionnalités sont détaillées dans des souhaits séparés - Histoire d'utilisateur.
La description d'Epic est la suivante:
- Titre / Titre résumé - le nom de la nouvelle fonctionnalité.
- Description / Description - est écrit selon le modèle:
Le rôle de l'utilisateur (en tant qu'utilisateur, je ...) / L'action de l'utilisateur (je veux faire quelque chose ...) / Le résultat de l'action (pour obtenir un tel résultat que ...) / Intérêt ou avantage (me permettra d'obtenir tel ou tel avantage ...). - Un exemple de plan de mise en œuvre ou une brève description des principales histoires d'utilisateurs qui seront mises en œuvre dans le cadre d'Epic avec MVP.
- Pièces jointes / pièces jointes - joindre la correspondance, la technologie et d'autres informations nécessaires.
Comment créer une User Story et une Tech Story
La différence entre User story et Tech story est que Tech Story se réfère à des exigences fonctionnelles qui doivent être prises en compte et décrites dans la tâche lors du développement du produit. Et dans le rôle des consommateurs, il y a des parties du système.
Les décrire est facile. La principale chose à retenir est pourquoi tout cela est fait.

L'ordre de description de la user story est assez standard:
- Titre / Résumé / Titre - une brève description de la nouvelle fonctionnalité ou des améliorations dans un langage compréhensible pour le client.
- Description / Description comprend l'objectif principal et le résultat souhaité. Comme, <rôle d'utilisateur>, je <veux obtenir>, dans le but de <résultat des actions>.
- Les critères d'acceptation sont une liste de critères de produits prioritaires. C'est-à-dire une définition mesurable de ce qui doit être fait avec le produit afin qu'il soit accepté par les parties prenantes du projet.
- Notes techniques, modèles, mises en page, mises en page.
- Pièces jointes / Pièces jointes - toutes les technologies nécessaires, documents, correspondance avec le client.
Comment décrire les bugs
Quelles informations doivent être indiquées lors du signalement d'un bug:
1.
Titre / Résumé / Titre décrit brièvement l'essence de l'erreur et indique l'emplacement du problème.
2. La description contient les étapes suivantes:
• comment reproduire les étapes d'erreur / lecture,
• résultat actuel,
• résultat attendu.
3.
Pièces jointes / pièces jointes - tous les journaux, captures d'écran, liens nécessaires vers Kibana et d'autres fichiers nécessaires.
4.
Environnement - une marque dans quel environnement l'erreur est reproduite et la catégorie à laquelle appartient le problème. Par exemple, une erreur d'interface utilisateur, une erreur CORE, une erreur SWS, etc.
5. La
priorité permettra à chaque membre de l'équipe d'évaluer la gravité du problème et au manager de le voir dans la liste des premiers candidats au sprint.
Et n'oubliez pas de définir le niveau de priorité correct :)
Maintenant que nous avons compris les principes généraux du travail, nous allons vous expliquer comment organiser le pipeline de déploiement.
Configuration du pipeline de déploiement
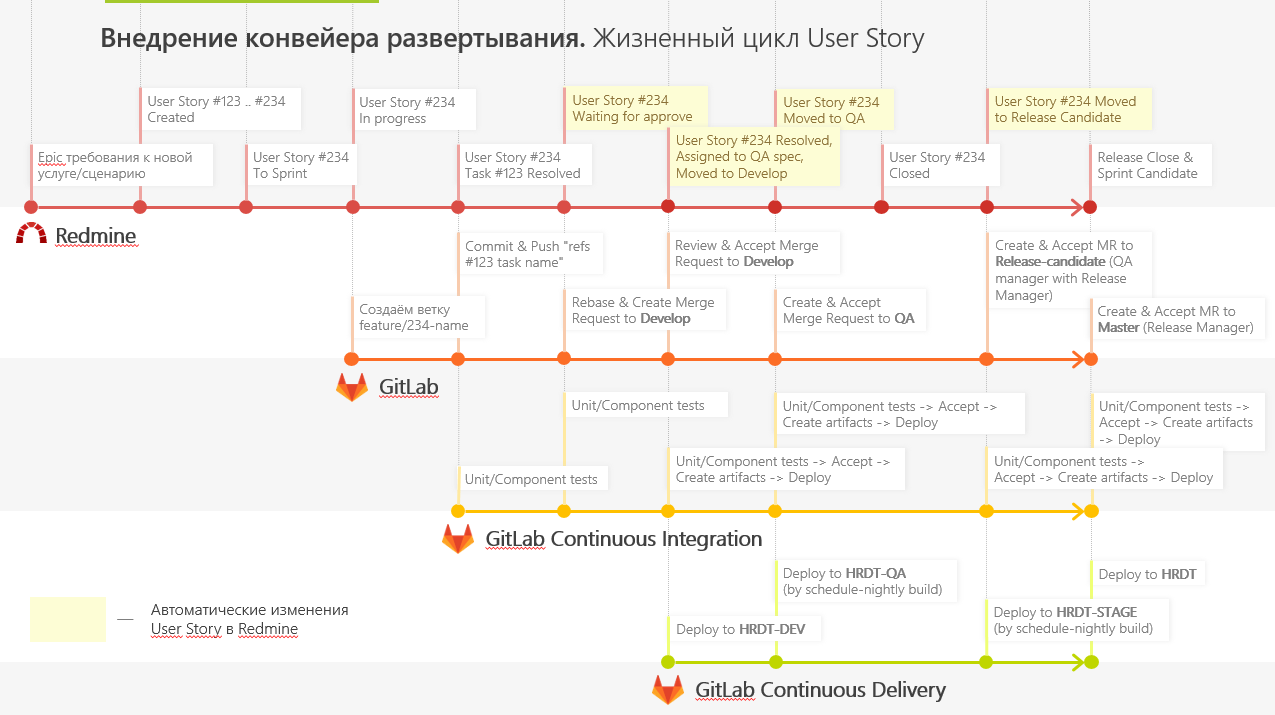
Pour accélérer la livraison de nos services à la production, nous introduisons un nouveau pipeline de déploiement et utilisons GitFlow pour travailler avec du code.
Pour ce faire rapidement et dynamiquement, nous avons déployé plusieurs runners GitLab qui ont exécuté toutes les tâches push des développeurs. Grâce à l'approche de GitLab Flow, nous avons plusieurs serveurs: Develop, QA, Release-candidate et Production.
L'intégration continue a commencé à collecter et à exécuter des tests pour chaque validation, à exécuter des tests unitaires et des tests d'intégration, à ajouter des artefacts à la livraison de l'application.

Le développement se déroule comme ceci:
- Le développeur ajoute de nouvelles fonctionnalités dans une branche distincte (branche de fonctionnalité). Après cela, il crée une demande de fusion de sa branche avec la branche principale de développement (branche Merge Request to Develop).
- D'autres développeurs regardent la demande de fusion, l'acceptent (ou non) et corrigent les commentaires. Après la fusion, un environnement spécial se déroule dans la branche du tronc, sur lequel des tests d'élévation de l'environnement sont effectués.
- Une fois toutes ces étapes terminées, l'ingénieur QA prend les modifications dans sa branche «QA» et effectue les tests.
- Si l'ingénieur QA accepte le travail effectué, les modifications vont à la branche Release-Candidate et se déploient dans un environnement accessible aux utilisateurs externes. Dans cet environnement, le client accepte et vérifie les technologies. Ensuite, nous distillons tout dans la production.
Si à un certain stade il y a des erreurs, c'est dans cette branche que nous les résolvons, après quoi nous publions le résultat dans Develop.
Nous avons également créé un petit plugin pour que Redmine puisse nous dire à quel stade se trouve la fonctionnalité. Cela aide les testeurs à évaluer à quelle étape vous devez vous connecter à la tâche et les développeurs à corriger les erreurs. Ils voient donc à quel stade l'échec s'est produit, peuvent aller dans une branche spécifique et y jouer.
Nous espérons que cela vous sera utile.