Le spamming sur les réseaux sociaux et les messageries instantanées est une douleur. Douleur pour les utilisateurs honnêtes et les développeurs. Comment ils le combattent à Badoo, a déclaré Mikhail Ovchinnikov sur Highload ++, puis la version texte de ce rapport.
À propos de l'orateur: Mikhail Ovchinnikov travaille chez Badoo et est un anti-spam depuis cinq ans.
Badoo compte 390 millions d'utilisateurs enregistrés (données d'octobre 2017). Si nous comparons la taille de l'audience du service avec la population de la Russie, nous pouvons dire que dans notre pays, selon les statistiques, chaque 100 millions de personnes sont protégées par 500000 policiers, et à Badoo, un seul employé Antispam protège chaque 100 millions d'utilisateurs du spam. Mais même un si petit nombre de programmeurs peut protéger les utilisateurs contre divers problèmes sur Internet.
Nous avons un large public, et il peut avoir différents utilisateurs:
- Bon et très bon, nos clients payants préférés;
- Les mauvais sont ceux qui, au contraire, essaient de gagner de l'argent avec nous: ils envoient du spam, fraudent de l'argent et se livrent à la fraude.
Qui doit se battre
Le spam peut être différent, il est souvent impossible de le distinguer du comportement d'un utilisateur ordinaire. Cela peut être manuel ou automatique - les bots qui sont engagés dans le mailing automatique veulent également nous contacter.
Peut-être que vous avez également écrit des robots - créiez des scripts pour la publication automatique. Si vous faites cela maintenant, il vaut mieux ne pas lire plus loin - vous ne devriez en aucun cas savoir ce que je vais vous dire maintenant.
Ceci, bien sûr, est une blague. L'article ne contiendra aucune information qui simplifiera la vie des spammeurs.

Alors avec qui devons-nous nous battre? Ce sont des spammeurs et des escrocs.
Le spam est apparu il y a longtemps, dès le tout début du développement d'Internet. Dans notre service, les spammeurs essaient généralement d'enregistrer un compte en y téléchargeant une
photo d'une jolie fille . Dans la forme la plus simple, ils commencent à envoyer les types de liens de spam les plus évidents.
Une option plus compliquée consiste à ce que les gens n’envoient rien d’explicite, n’envoient aucun lien, ne fassent aucune publicité, mais
attirent l’utilisateur vers un endroit plus pratique pour eux, par exemple, des messageries instantanées : Skype, Viber, WhatsApp. Là, ils peuvent, sans notre contrôle, vendre quoi que ce soit à l'utilisateur, promouvoir, etc.
Mais les
spammeurs ne sont pas le plus gros problème . Ils sont évidents et faciles à combattre. Des personnages beaucoup plus complexes et intéressants sont des
escrocs qui prétendent être une autre personne et essaient de tromper les utilisateurs de toutes les manières qui se trouvent sur Internet.
Bien sûr, les actions des spammeurs et des escrocs ne sont pas toujours très différentes du comportement des utilisateurs ordinaires qui le font aussi parfois. Il existe de nombreux signes formels dans les deux qui ne permettent pas de tracer une ligne claire entre eux. Ce n'est presque jamais possible.
Comment faire face au spam au Mésozoïque
- La chose la plus simple qui pouvait être faite était d'écrire des expressions régulières distinctes pour chaque type de spam et d'entrer chaque mauvais mot et chaque domaine distinct dans ce régulier. Tout cela a été fait manuellement et, bien sûr, c'était aussi gênant et inefficace que possible.
- Vous pouvez rechercher manuellement des adresses IP douteuses et les saisir dans la configuration du serveur afin que les utilisateurs suspects n'accèdent plus jamais à votre ressource. Ceci est inefficace car les adresses IP sont constamment réaffectées, redistribuées.
- Écrivez des scripts uniques pour chaque type de spammeur ou de bot, raclez leurs journaux, trouvez manuellement des modèles. Si un petit quelque chose change dans le comportement du spammeur, tout cesse de fonctionner - également complètement inefficace.

Tout d'abord, je vais vous montrer les méthodes les plus simples de lutte contre le spam que chacun peut mettre en œuvre par lui-même. Ensuite, je vous parlerai en détail des systèmes plus complexes que nous avons développés en utilisant l'apprentissage automatique et d'autres pièces d'artillerie lourde.
Les moyens les plus simples de lutter contre le spam
Modération manuelle
Dans n'importe quel service, vous pouvez embaucher des modérateurs qui afficheront manuellement le contenu et le profil de l'utilisateur, et décideront quoi faire avec cet utilisateur. En règle générale, ce processus ressemble à la recherche d'une aiguille dans une botte de foin. Nous avons un grand nombre d'utilisateurs, moins de modérateurs.

En plus du fait que les modérateurs ont évidemment besoin de beaucoup, vous avez besoin de beaucoup d'infrastructure. Mais, en fait, la chose la plus difficile en est une autre - un problème se pose: comment, au contraire, protéger les utilisateurs des modérateurs.
Il est nécessaire de s'assurer que les modérateurs n'ont pas accès aux données personnelles. Ceci est important car les modérateurs peuvent théoriquement aussi essayer de nuire. Autrement dit, nous avons besoin d'antispam pour antispam, afin que les modérateurs soient sous contrôle strict.
De toute évidence, vous ne pouvez pas vérifier tous les utilisateurs de cette manière. Néanmoins, la
modération est en tout cas nécessaire , car tout système à l'avenir aura besoin d'une formation et d'une main humaine qui déterminera ce qu'il faut faire avec l'utilisateur.
Collecte de statistiques
Vous pouvez essayer d'utiliser des statistiques - pour collecter divers paramètres pour chaque utilisateur.
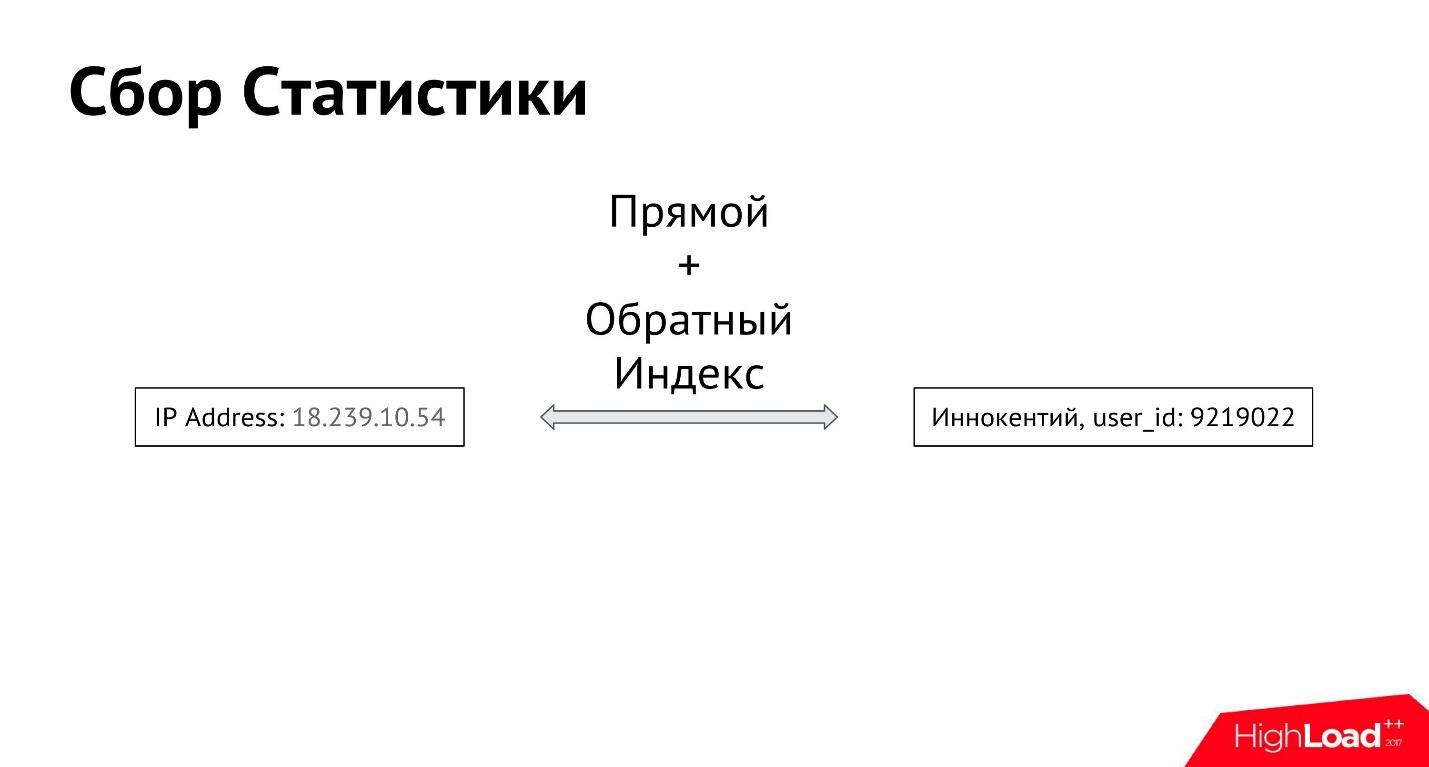
L'utilisateur Innokenty se connecte à partir de son adresse IP. La première chose que nous faisons est de vous connecter à l'adresse IP saisie. Ensuite, nous construisons un index avant et arrière entre toutes les adresses IP et tous les utilisateurs, afin que vous puissiez obtenir toutes les adresses IP à partir desquelles un utilisateur spécifique se connecte, ainsi que tous les utilisateurs qui se connectent à partir d'une adresse IP spécifique.
De cette façon, nous obtenons la connexion entre l'attribut et l'utilisateur. Il peut y avoir beaucoup de tels attributs. Nous pouvons commencer à collecter des informations non seulement sur les adresses IP, mais aussi sur les photos, les appareils à partir desquels l'utilisateur est entré - sur tout ce que nous pouvons déterminer.
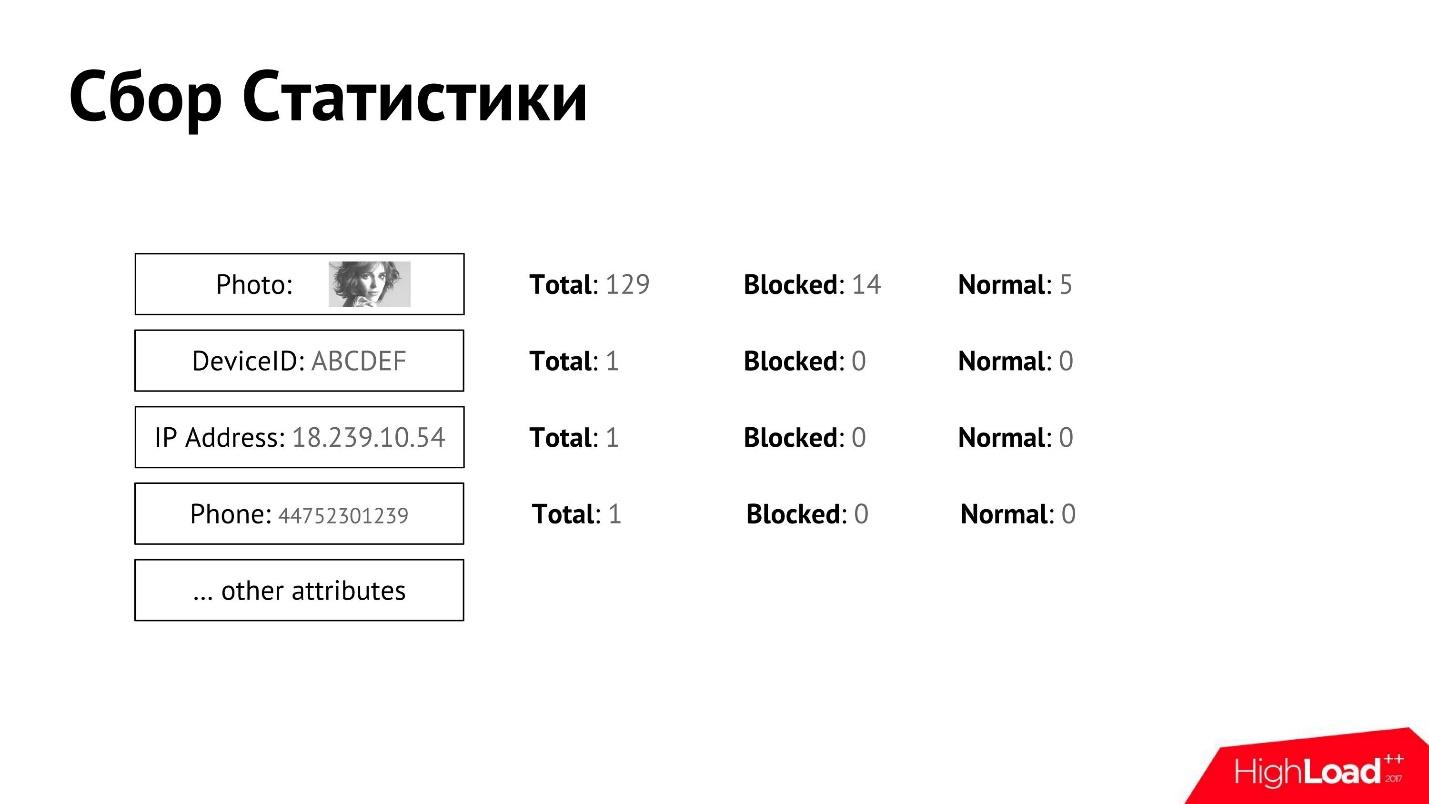
Nous collectons ces statistiques et l'associons à l'utilisateur. Pour chacun des attributs, nous pouvons collecter des compteurs détaillés.
Nous avons une modération manuelle qui décide quel utilisateur est bon, lequel est mauvais, et à un moment donné, l'utilisateur est bloqué ou reconnu comme normal. Nous pouvons obtenir séparément des données pour chaque attribut, combien d'utilisateurs au total, combien d'entre eux sont bloqués, combien sont reconnus comme normaux.
Ayant de telles statistiques pour chacun des attributs, nous pouvons à peu près déterminer qui est le spammeur, qui ne l'est pas.

Disons que nous avons deux adresses IP - 80% des spammeurs sur une et 1% sur la seconde. Évidemment, le premier est beaucoup plus spammé, vous devez en faire quelque chose et appliquer une sorte de sanction.
Le plus simple est d'écrire
des règles heuristiques . Par exemple, si les utilisateurs bloqués représentent plus de 80% et ceux qui sont considérés comme normaux - moins de 5%, cette adresse IP est considérée comme incorrecte. Ensuite, nous interdisons ou faisons autre chose avec tous les utilisateurs avec cette adresse IP.
Collecte de statistiques à partir de textes
En plus des attributs évidents des utilisateurs, vous pouvez également effectuer une analyse de texte. Vous pouvez analyser automatiquement les messages des utilisateurs, en isoler tout ce qui est lié au spam: mentionner les messagers, les téléphones, les e-mails, les liens, les domaines, etc., et collecter exactement les mêmes statistiques auprès d'eux.

Par exemple, si un nom de domaine a été envoyé dans des messages par 100 utilisateurs, dont 50 ont été bloqués, alors ce nom de domaine est mauvais. Il peut être mis sur liste noire.
Nous recevrons une grande quantité de statistiques supplémentaires pour chacun des utilisateurs sur la base des textes des messages. Aucun apprentissage automatique n'est nécessaire pour cela.
Arrêter les mots
En plus des éléments évidents - téléphones et liens - vous pouvez extraire des phrases ou des mots du texte qui sont particulièrement courants pour les spammeurs. Vous pouvez gérer cette liste de mots vides manuellement.
Par exemple, sur les comptes des spammeurs et des escrocs, la phrase: «Il y a beaucoup de contrefaçons» est souvent trouvée. Ils écrivent qu'ils sont généralement les seuls ici qui sont mis en place pour quelque chose de sérieux, tous les autres faux, qui en aucun cas ne peuvent faire confiance.
Sur les sites de rencontres selon les statistiques, les spammeurs utilisent plus souvent que les gens ordinaires la phrase: "Je recherche une relation sérieuse". Il est peu probable qu'une personne ordinaire écrive ceci sur un site de rencontres - avec une probabilité de 70%, il s'agit d'un spammeur qui essaie d'attirer quelqu'un.
Rechercher des comptes similaires
Avec des statistiques sur les attributs et les mots vides trouvés dans les textes, vous pouvez créer un système pour rechercher des comptes similaires. Cela est nécessaire pour rechercher et interdire tous les comptes créés par la même personne. Un spammeur qui a été bloqué peut immédiatement enregistrer un nouveau compte.
Par exemple, un utilisateur Harold se connecte, se connecte au site et fournit ses attributs plutôt uniques: adresse IP, photo, mot stop qu'il a utilisé. Peut-être qu'il s'est même inscrit avec un faux compte Facebook.
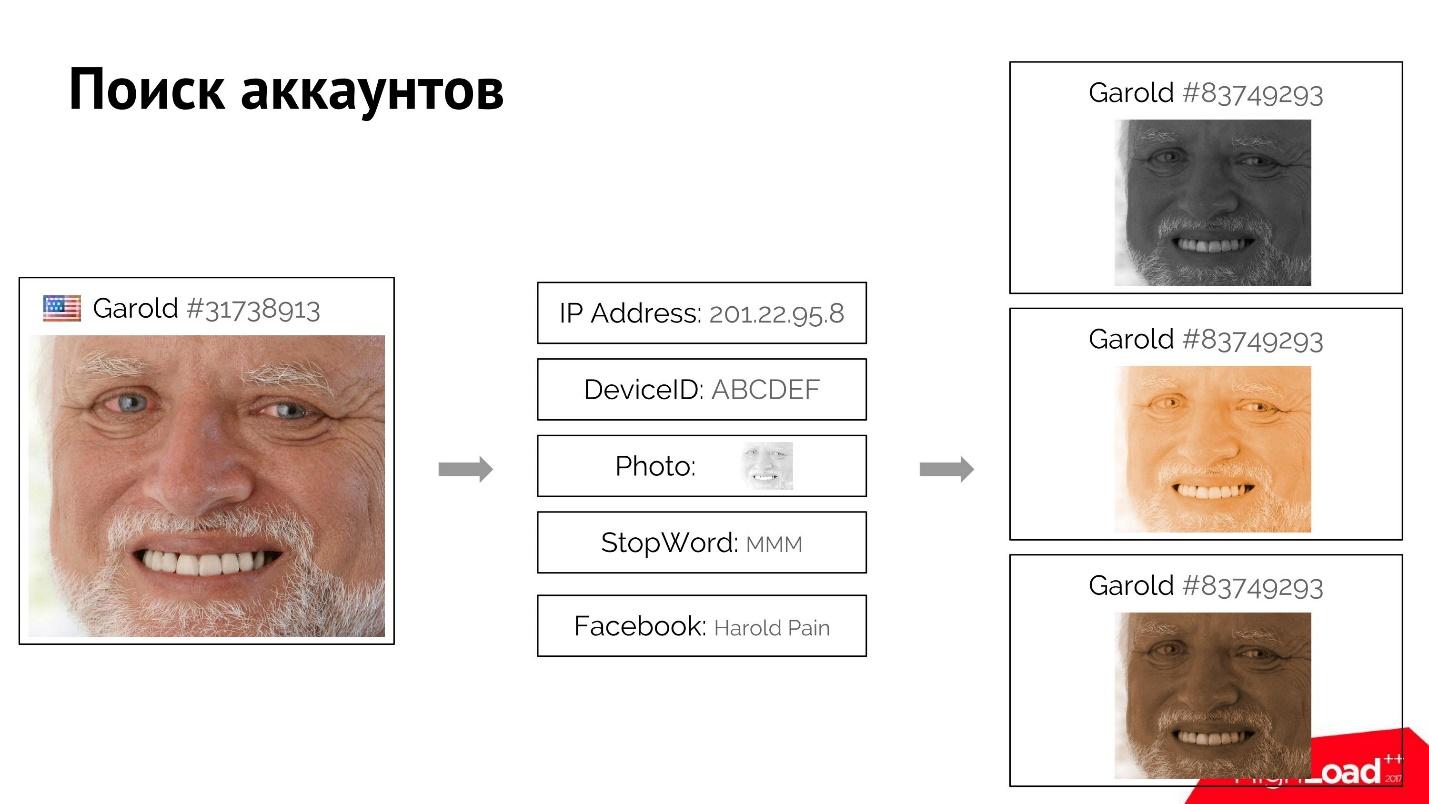
Nous pouvons trouver tous les utilisateurs similaires à lui qui ont un ou plusieurs de ces attributs correspondants. Lorsque nous savons avec certitude que ces utilisateurs sont connectés, en utilisant l'index très direct et inversé, nous trouvons les attributs, et par eux de tous les utilisateurs, et les classons. Si, disons le premier Harold, nous bloquons, le reste est également facile à "tuer" en utilisant ce système.
Toutes les méthodes que je viens de décrire sont très simples: il est facile de collecter des statistiques, puis il est facile de rechercher des utilisateurs à l'aide de ces attributs. Mais, malgré la facilité, à l'aide de choses aussi simples - modération simple, statistiques simples, mots vides simples - ils parviennent
à vaincre 50% du spam .
Dans notre entreprise, pour les six premiers mois de travail, le service Antispam a vaincu 50% des spams. Les 50% restants, comme vous le savez, sont beaucoup plus compliqués.
Comment rendre la vie difficile aux spammeurs
Les spammeurs inventent quelque chose, essayent de compliquer nos vies, et nous essayons de les combattre. C'est une guerre sans fin. Il y en a beaucoup plus que nous, et à chaque étape, nous trouvons leur propre chemin d'accès multiple.
Je suis sûr qu'il y a quelque part des conférences de spammeurs où les conférenciers parlent de la façon dont ils ont vaincu Badoo Antispam, de leurs KPI ou de la façon de créer un spam évolutif tolérant aux pannes en utilisant les dernières technologies.
Malheureusement, nous ne sommes pas invités à de telles conférences.
Mais nous pouvons rendre la vie difficile aux spammeurs. Par exemple, au lieu d'afficher directement à l'utilisateur la fenêtre «Vous êtes verrouillé», vous pouvez utiliser le soi-disant
bannissement furtif - c'est lorsque nous ne disons pas à l'utilisateur qu'il est banni. Il ne devrait même pas le soupçonner.

L'utilisateur entre dans le bac à sable (Silent Hill), où tout semble être réel: vous pouvez envoyer des messages, voter, mais en fait tout va dans le vide, dans le brouillard. Personne ne verra et n'entendra jamais, personne ne recevra ses messages et votes.
Nous avons eu un cas où un spammeur a spammé pendant longtemps, a fait la promotion de ses mauvais produits et services, et six mois plus tard, a décidé d'utiliser le service comme prévu. Il a enregistré son vrai compte: vraies photos, nom, etc. Naturellement, notre moteur de recherche de comptes similaires l'a rapidement compris et l'a mis en interdiction furtive. Après cela, il a écrit pendant six mois dans le vide qu'il était très seul, personne n'a répondu. En général, il a déversé toute son âme dans le brouillard de Silent Hill, mais n'a reçu aucune réponse.
Les spammeurs, bien sûr, ne sont pas des imbéciles. Ils essaient d'une manière ou d'une autre de déterminer qu'ils sont entrés dans le bac à sable et qu'ils ont été bloqués, quitter l'ancien compte et en trouver un nouveau. Nous avons parfois même l'idée qu'il serait bien d'envoyer plusieurs de ces spammeurs dans le bac à sable ensemble, afin qu'ils se vendent tout ce qu'ils veulent et s'amusent comme vous le souhaitez. Mais bien que nous n'ayons pas atteint ce point, nous concevons d'autres méthodes, par exemple, la vérification photo et téléphonique.

Comme vous le savez, il est difficile pour un spammeur qui est un bot et non une personne de passer la vérification par téléphone ou photo.
Dans notre cas, la vérification par photo ressemble à ceci: l'utilisateur est invité à prendre une photo avec un certain geste, la photo résultante est comparée avec des photos déjà chargées dans le profil. Si les visages sont les mêmes, alors la personne est probablement réelle, a téléchargé ses vraies photos et peut être laissée pour quelque temps.
Il n'est pas facile pour les spammeurs de réussir ce test. Nous avons même eu un petit jeu au sein de l'entreprise appelé Guess Who the Spammer. Étant donné quatre photos, vous devez comprendre laquelle est un spammeur.
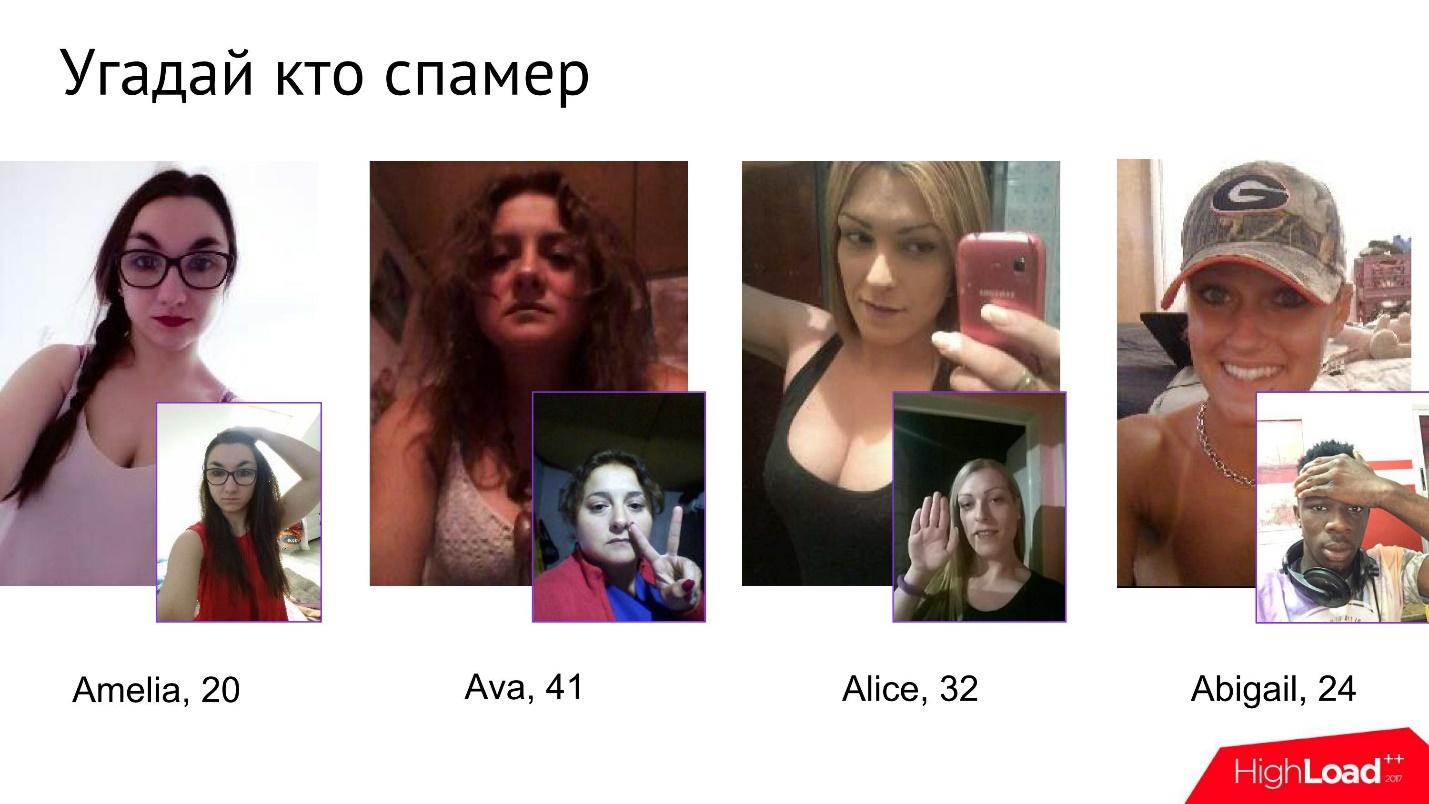
À première vue, ces filles ont l'air complètement inoffensives, mais dès qu'elles commencent à subir une photo-vérification, il devient clair à un moment donné que l'une d'entre elles n'est absolument pas ce qu'elle prétend être.
Dans tous les cas, les spammeurs ont du mal à lutter contre la vérification photo. Ils souffrent vraiment, essaient de le contourner, de tromper et de démontrer toutes leurs compétences Photoshop.

Les spammeurs font tout ce qu'ils peuvent, et parfois ils pensent, probablement, que tout cela est complètement traité par des technologies modernes incroyables qui sont si mal construites qu'elles sont si faciles à tromper.
Ils ne savent pas que chaque photo est ensuite à nouveau vérifiée manuellement par les modérateurs.
Pas de temps
En fait, malgré le fait que nous trouvions différentes façons de rendre la vie difficile aux spammeurs, il n'y a généralement pas assez de temps, car l'anti-spam devrait fonctionner instantanément. Il doit trouver et neutraliser l'utilisateur avant de commencer son activité négative.
La meilleure chose à faire est de déterminer au stade de l'inscription que l'utilisateur n'est pas très bon. Cela peut être fait, par exemple, en utilisant le clustering.
Regroupement d'utilisateurs
Nous pouvons collecter toutes les informations possibles juste après l'inscription. Nous n'avons toujours pas d'appareils avec lesquels l'utilisateur se connecte, ni de photos, il n'y a pas de statistiques. Nous n'avons rien à lui envoyer pour vérification, il n'a rien fait de suspect. Mais nous avons déjà des informations primaires:
- sexe
- l'âge
- pays d'enregistrement;
- pays et fournisseur IP;
- Domaine de messagerie
- opérateur téléphonique (le cas échéant);
- données de fb (le cas échéant) - combien d'amis il a, combien de photos il a téléchargées, combien de temps il s'y est inscrit, etc.
Toutes ces informations peuvent être utilisées pour localiser les clusters d'utilisateurs. Nous utilisons l'algorithme de clustering
K-means simple et populaire. Il est parfaitement implémenté partout, il est pris en charge dans toutes les bibliothèques MachineLearning, il est parfaitement parallèle, il fonctionne rapidement. Il existe des versions en streaming de cet algorithme qui vous permettent de répartir les utilisateurs sur des clusters à la volée. Même dans nos volumes, tout cela fonctionne assez rapidement.
Après avoir reçu de tels groupes d'utilisateurs (clusters), nous pouvons effectuer toutes les actions. Si les utilisateurs sont très similaires (le cluster est fortement connecté), il s'agit très probablement d'un enregistrement de masse, il doit être arrêté immédiatement. L'utilisateur n'a pas encore eu le temps de faire quoi que ce soit, il suffit de cliquer sur le bouton "S'inscrire" - et c'est tout, il est déjà entré dans le bac à sable.
Des statistiques peuvent être collectées sur les clusters - si 50% du cluster est bloqué, les 50% restants peuvent être envoyés pour vérification, ou modéré individuellement tous les clusters manuellement, regardez les attributs par lesquels ils coïncident et prenez une décision. Sur la base de ces données, les analystes peuvent identifier des modèles.
Patterns
Les modèles sont des ensembles d'attributs utilisateur les plus simples que nous connaissons immédiatement. Certains modèles fonctionnent en fait très efficacement contre certains types de spammeurs.
Par exemple, considérons une combinaison de trois attributs complètement indépendants et assez communs:
- L'utilisateur est enregistré aux États-Unis;
- Son fournisseur est Privax LTD (opérateur VPN);
- Domaine de messagerie: [mail.ru, list.ru, bk.ru, mailbox.ru].
Ces trois attributs, ne représentant apparemment rien d'eux-mêmes, donnent ensemble la probabilité qu'il s'agisse d'un spammeur, près de 90%.
Vous pouvez extraire autant de schémas que vous le souhaitez pour chaque type de spammeur. C'est beaucoup plus efficace et plus facile que d'afficher manuellement tous les comptes ou même les clusters.
Regroupement de texte
En plus de regrouper les utilisateurs par attributs, vous pouvez trouver des utilisateurs qui écrivent les mêmes textes. Bien sûr, ce n'est pas si simple. Le fait est que notre service fonctionne dans de nombreuses langues. De plus, les utilisateurs écrivent souvent avec des abréviations, de l'argot, parfois avec des erreurs. Eh bien, les messages eux-mêmes sont généralement très courts, littéralement 3 à 4 mots (environ 25 caractères).
Par conséquent, si nous voulons trouver des textes similaires parmi les milliards de messages que les utilisateurs écrivent, nous devons trouver quelque chose d'inhabituel. Si vous essayez d'utiliser des méthodes classiques basées sur l'analyse de la morphologie et un véritable traitement honnête de la langue, alors avec toutes ces restrictions, argots, acronymes et un tas de langues, c'est très difficile.
Vous pouvez faire un peu plus simplement - appliquez l'algorithme
n-gram . Chaque message qui apparaît est décomposé en n-grammes. Si n = 2, alors ce sont des bigrammes (paires de lettres). Progressivement, le message entier est divisé en paires de lettres et des statistiques sont collectées, combien de fois chaque bigramme apparaît dans le texte.

Vous ne pouvez pas vous arrêter aux bigrammes, mais ajoutez des trigrammes, des skipgrams (statistiques sur les lettres après 1, 2, etc. lettres). Plus nous obtenons d'informations, mieux c'est. Mais même les bigrammes fonctionnent déjà assez bien.
Ensuite, nous obtenons un vecteur des bigrammes de chaque message dont la longueur est égale au carré de la longueur de l'alphabet.
Il est très pratique de travailler avec ce vecteur et de le regrouper, car:
- se compose de chiffres;
- compressé, il n'y a pas de vide;
- taille toujours fixe.
- l'algorithme k-means avec de tels vecteurs compressés de taille fixe est très rapide. Nos milliards de messages sont regroupés en quelques minutes.
Mais ce n'est pas tout. Malheureusement, si nous collectons simplement tous les messages dont la fréquence est similaire à celle des bigrammes, nous obtenons des messages dont la fréquence est similaire à celle des bigrammes. Cependant, il n'est pas nécessaire qu'ils soient en fait au moins quelque peu similaires dans leur sens. Il y a souvent de longs textes dans lesquels les vecteurs sont très proches, presque les mêmes, mais les textes eux-mêmes sont complètement différents. De plus, à partir d'une certaine longueur de texte, cette méthode de clustering cessera généralement de fonctionner, car les fréquences des bigrammes sont égales.

Par conséquent, vous devez ajouter un filtrage. Étant donné que les clusters existent déjà, ils sont assez petits, nous pouvons facilement filtrer l'intérieur du cluster en utilisant Stemming ou Bag of Words. À l'intérieur d'un petit cluster, vous pouvez littéralement comparer tous les messages avec tout le monde et obtenir le cluster dans lequel il est garanti que les mêmes messages coïncident non seulement dans les statistiques, mais aussi dans la réalité.
, — , , ( ) . , - .
— VPN, TOR, Proxy, . , , , .
, , « IP».

VPN — , IP- , IP- VPN, Proxy .
:
- ISP (Internet Service Provider), IP- . , .
- Whois . IP- Whois : ; ; , IP-; , IP- .. , IP-.
- GeolP. , IP- , , IP- , , , IP- - .
- — IP- , GeolP, Whois, .
, , , IP- VPN .
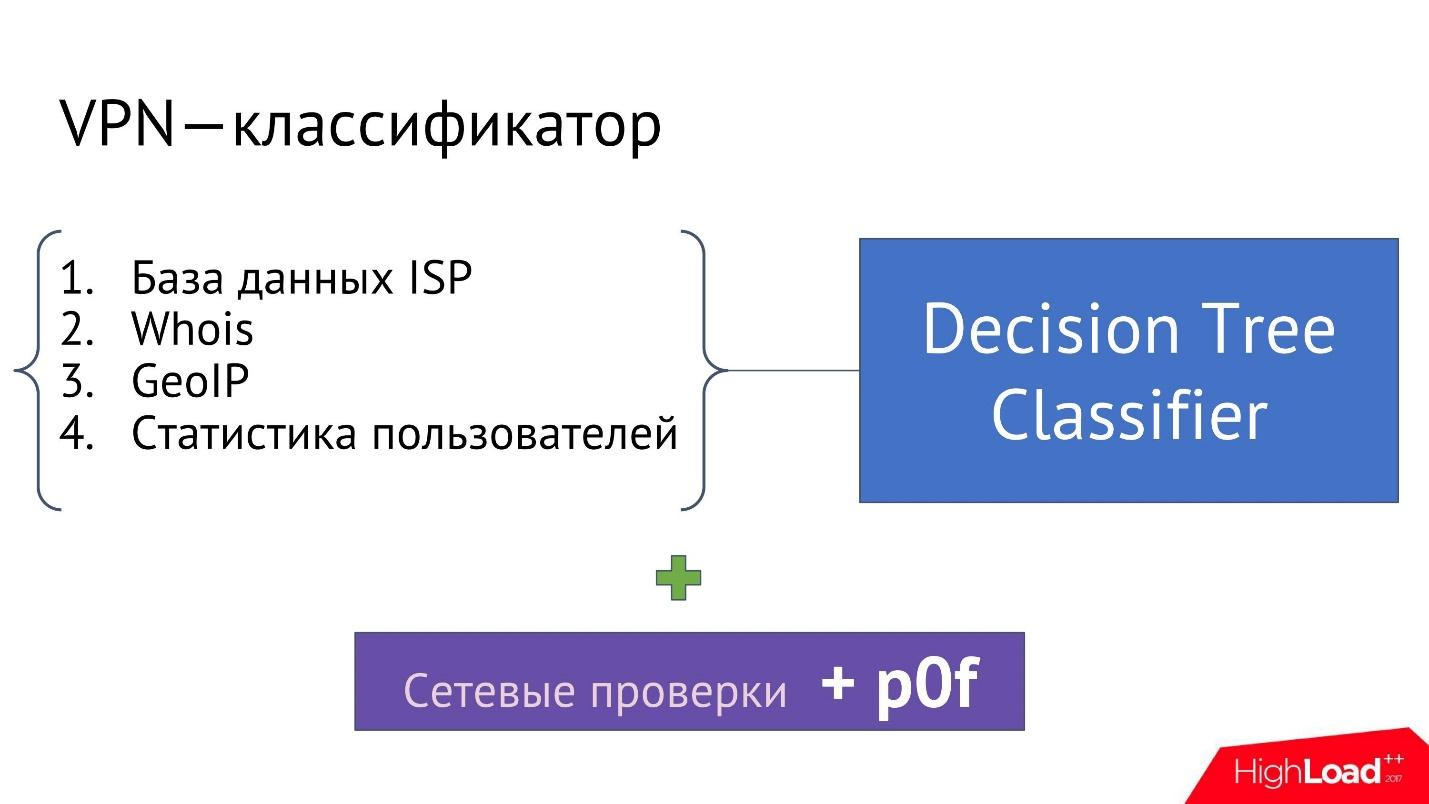
, — , , .., , IP- VPN.
, . , advanced-, 100% . .
, IP- VPN, , IP- . , , . SOCKS-proxy, IP- .
, , ,
p0f . , fingerprinting , : , VPN-, Proxy .. , .
, , , , , : ? — ! , , , .
— ? . 2 , .
, , , , , , , .

, , ?
«User Decency»
— , .
«» :
.
. , , , .
, , «
». , , , , . .
1, , , , — .
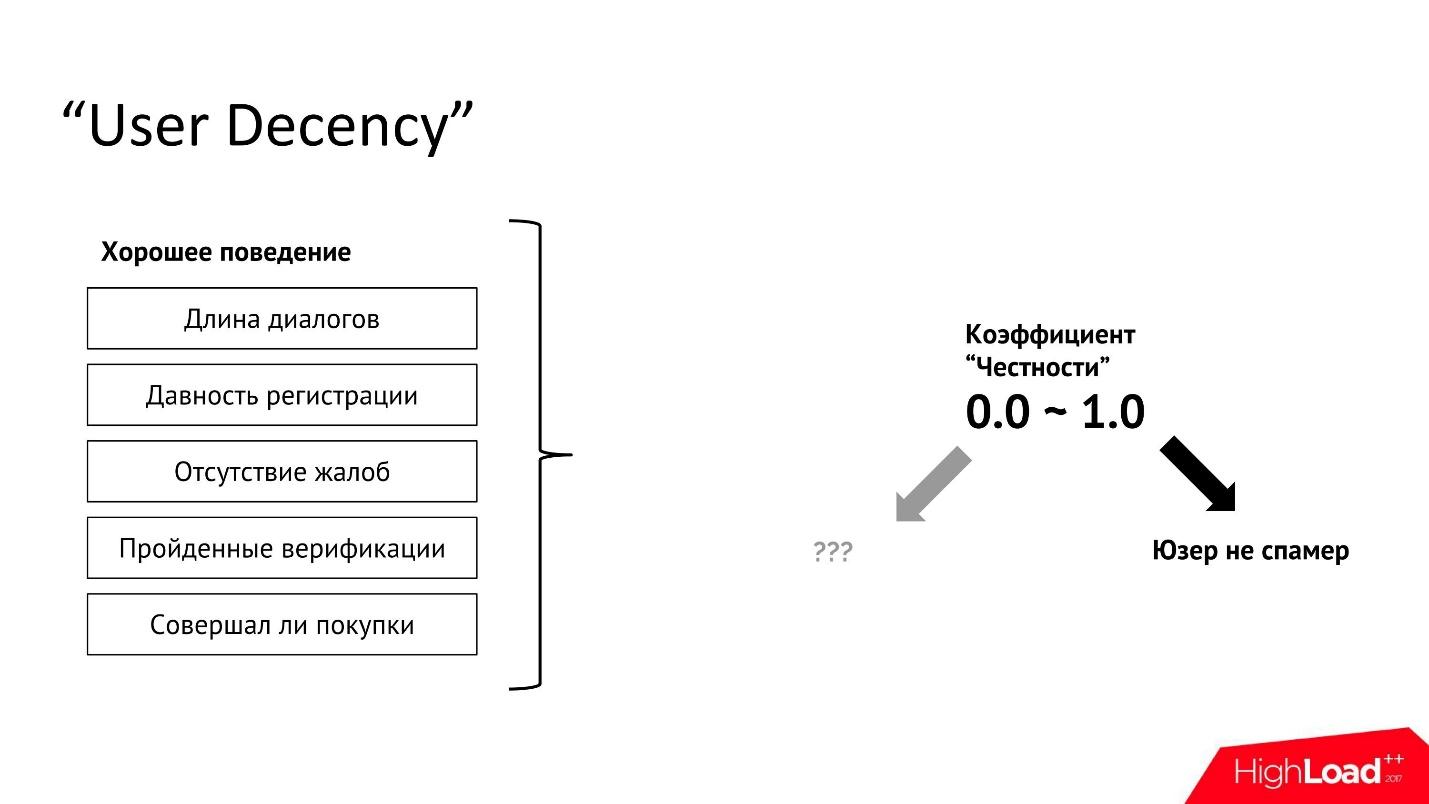
.
False positive
, — . , IP-. , -, . , fingerprint, , , — , , , , - .
: : «, — Pornhub — ?» , - , .
. , , , .
- «Pornhub». - , - .
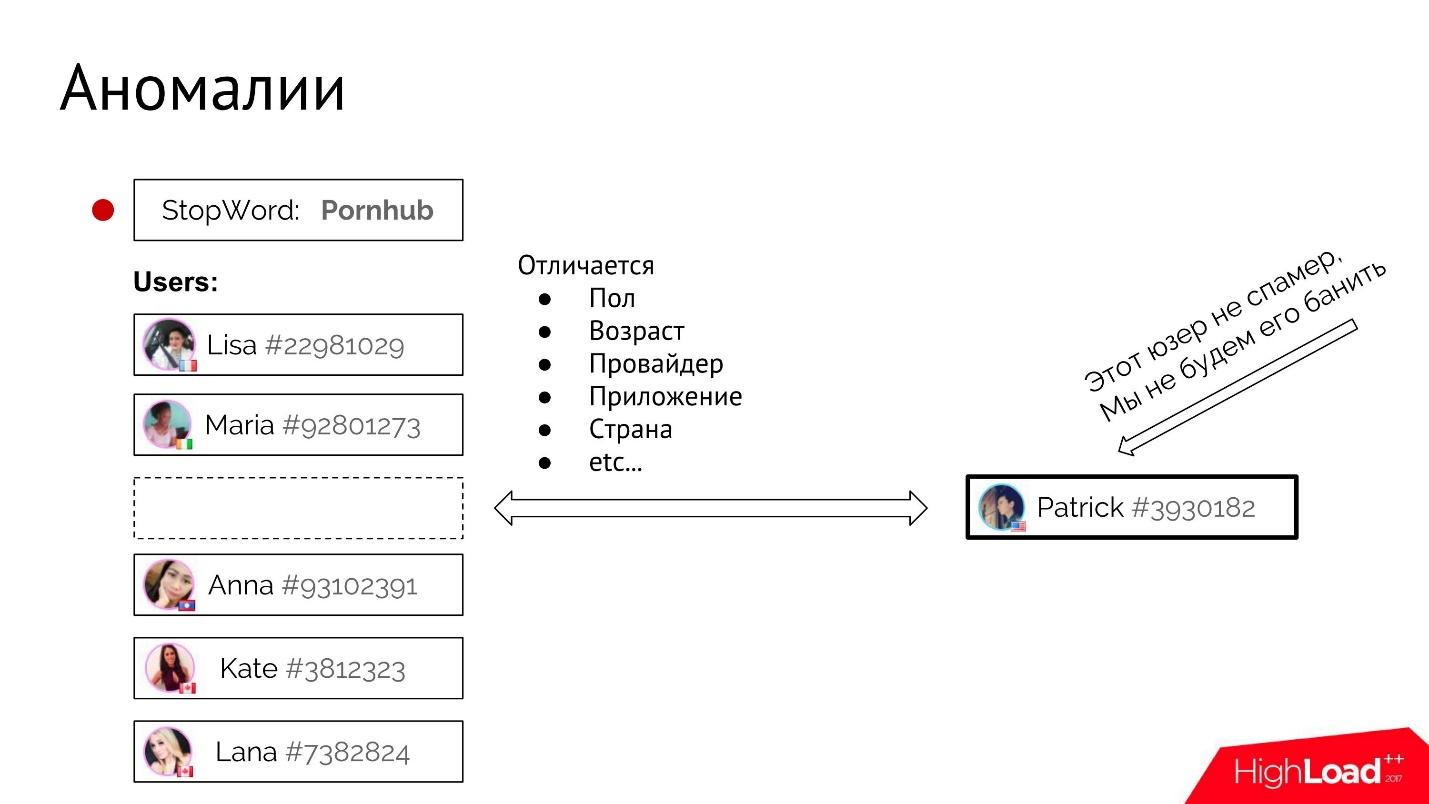
- -, .
, , . : , , , , .. , «» . , , , . , , .
, .
-
— MachineLearning, , 0 1 — .
, ,
, . , , . , - , .
, — . — , .
, ( ) , , . , , , : , , . .
HighLoad++ 2018 , , :
- ML- ,
- NVIDIA , .
- use case .
youtube- , — , .