Un autre entretien avec
Pixonic DevGAMM Talks - cette fois de nos collègues de PanzerDog. L'ingénieur logiciel en chef de la société Pavel Platto a démonté le méta-serveur du jeu avec une architecture orientée services, a expliqué quelles solutions et technologies ont été choisies, ce qu'elles ont fait et comment elles ont évolué, et quelles difficultés elles ont dû affronter. Le texte du rapport, des diapositives et des liens vers d'autres discours du mitap, comme toujours, sous la coupe.
Tout d'abord, je veux montrer une petite bande-annonce de notre jeu:
Le rapport comprendra 3 parties. Dans le premier, je parlerai des technologies que nous avons choisies et pourquoi, dans le second - comment notre méta-serveur est organisé, et dans le troisième, je parlerai des diverses infrastructures de support que nous utilisons, et comment nous avons mis en œuvre la mise à jour sans temps d'arrêt .
 Pile technologique
Pile technologiqueLe méta serveur est hébergé sur Amazon et écrit en Elixir. Il s'agit d'un langage de programmation fonctionnel avec un modèle de calcul acteur. Comme nous n'avons pas d'Ops, les programmeurs sont impliqués dans l'opération, et la plupart de l'infrastructure est décrite comme du code utilisant HashiCorp Terraform.
Tacticool est actuellement en version bêta ouverte, le méta-serveur est en développement depuis un peu plus d'un an et fonctionne depuis près d'un an. Voyons comment tout a commencé.

Lorsque j'ai rejoint l'entreprise, nous avions déjà implémenté des fonctionnalités de base sous la forme d'un monolithe sur un mix C / C ++ et un stockage PostageSQL. Cette mise en œuvre a rencontré certains problèmes.
Tout d'abord, en raison du faible niveau de C, il y avait pas mal de bugs insaisissables. Par exemple, pour certains joueurs, le matchmaking se bloque en raison d'une mise à zéro incorrecte du tableau avant sa réutilisation. Bien sûr, trouver la relation entre ces deux événements était assez difficile. Et puisque l'état de plusieurs threads a été universellement modifié dans le code, les conditions de course n'étaient pas sans.
Le traitement parallèle d'un grand nombre de tâches était également hors de question, car le serveur a démarré au début d'une dizaine de processus de travail, bloqués par des requêtes vers Amazon ou la base de données. Et même si nous oublions ces demandes de blocage, le service a commencé à s'effondrer sur quelques centaines de connexions qui n'ont effectué aucune opération à l'exception du ping. De plus, le service n'a pas pu être mis à l'échelle horizontalement.
Après quelques semaines passées à trouver et à corriger les bogues les plus critiques, nous avons décidé qu'il était plus facile de tout réécrire à partir de zéro que d'essayer de corriger toutes les lacunes de la solution actuelle.
Et lorsque vous partez de zéro, il est logique d'essayer de choisir une langue qui vous aidera à éviter certains des problèmes précédents. Nous avions trois candidats:

C # figurait sur la liste des «connaissances», le client et le serveur de jeu sont écrits en Unity, et la plupart de l'expérience de l'équipe était avec ce langage de programmation. Go et Elixir ont été pris en compte car ce sont des langages modernes et assez populaires créés pour développer des applications serveur.
Les problèmes de l'itération précédente nous ont aidés à déterminer les critères d'évaluation des candidats.
Le premier critère était la commodité de travailler avec des opérations asynchrones. En C #, le travail pratique avec les opérations asynchrones n'apparaissait pas du premier coup. Cela a conduit au fait que nous avons un «zoo» de solutions qui, à mon avis, sont encore un peu en retrait. Dans Go et Elixir, ce problème a été pris en compte lors de la conception de ces langages, ils utilisent tous les deux des threads légers (dans Go ce sont des goroutines, dans Elixir ce sont des processus). Ces flux ont une surcharge beaucoup plus petite que les threads système, et comme nous pouvons les créer par dizaines et centaines de milliers, nous ne sommes pas fâchés de les bloquer.
Le deuxième critère était la capacité de travailler avec des processus compétitifs. C # prêt à l'emploi n'offre rien d'autre que des pools de threads et de la mémoire partagée, dont l'accès doit être protégé à l'aide de diverses primitives de synchronisation. Go a un modèle moins sujet aux erreurs sous la forme de goroutines et de canaux. Elixir, quant à lui, propose un modèle d'acteur sans mémoire partagée avec messagerie. Le manque de mémoire partagée a permis de mettre en œuvre des technologies utiles pour un environnement d'exécution compétitif lors de l'exécution, telles que le multitâche à emporter honnête et la collecte des ordures sans interruption dans le monde.
Le troisième critère était la disponibilité d'outils pour travailler avec des types de données immuables. Toute mon expérience de développement a montré qu'une partie assez importante des bogues est associée à des modifications de données incorrectes. Il existe une solution à cela il y a longtemps - des types de données immuables. En C #, ces types de données peuvent être créés, mais au prix d'une tonne de passe-partout. Dans Go, ce n'est pas possible du tout. Et dans Elixir, tous les types de données sont immuables.
Et le dernier critère était le nombre de spécialistes. Ici, les résultats sont évidents. Au final, nous avons opté pour Elixir.
Avec le choix de l'hébergement, tout était beaucoup plus simple. Nous avons déjà hébergé des serveurs de jeux dans Amazon GameLift, en outre, Amazon propose un grand nombre de services qui nous permettraient de réduire le temps de développement.
Nous nous sommes complètement abandonnés au cloud et ne déployons nous-mêmes aucune solution tierce - bases de données, files d'attente de messages - tout cela est géré par Amazon pour nous. À mon avis, c'est la seule solution pour une petite équipe qui veut développer un jeu en ligne, et non l'infrastructure pour cela.
Nous avons compris le choix des technologies, passons au fonctionnement du méta-serveur.
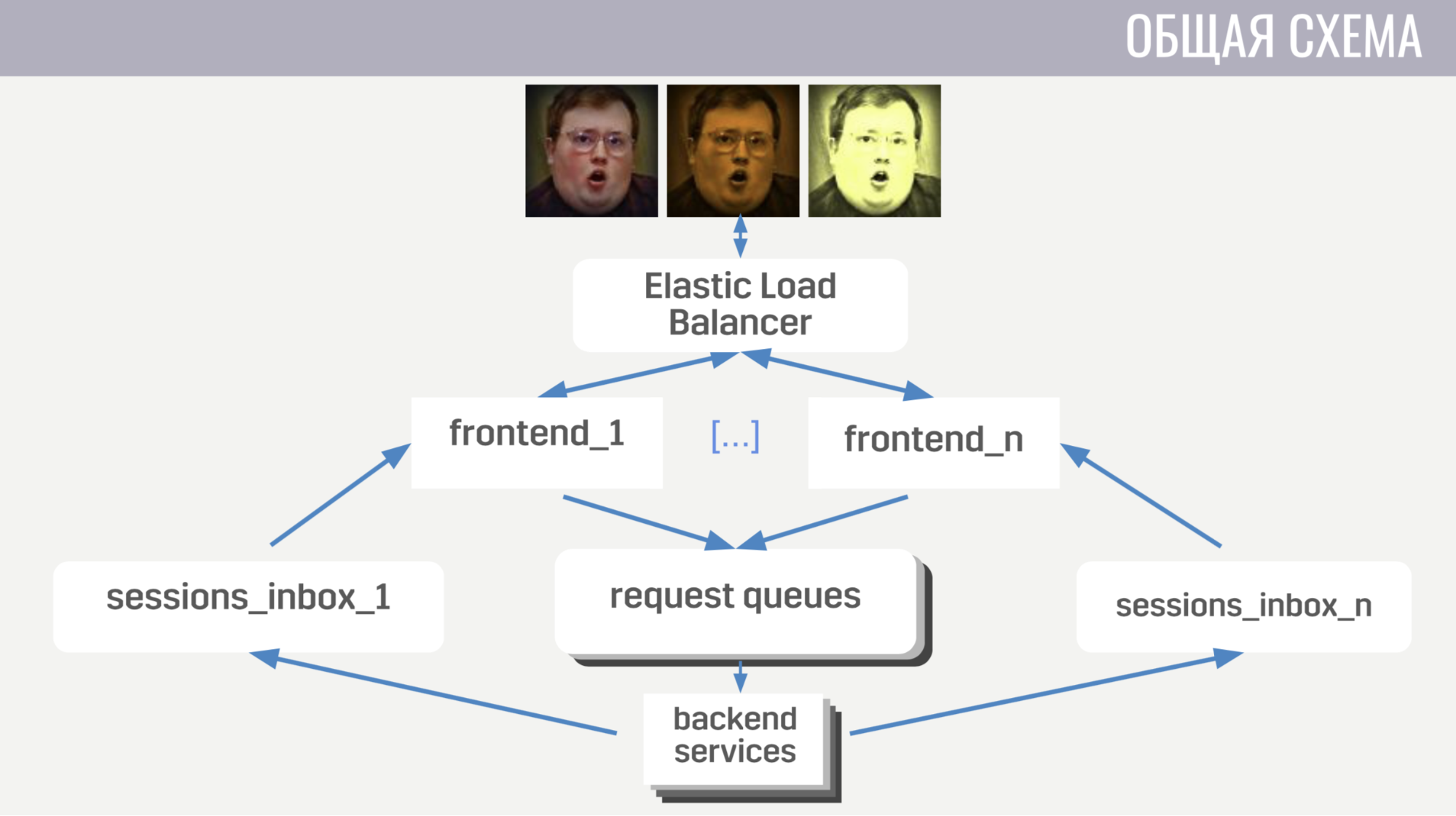
En général: les clients se connectent à l'équilibreur de charge d'Amazon via des connexions de socket Web; l'équilibreur diffuse ces connexions entre plusieurs instances frontales, le frontal envoie des requêtes client aux backends. Mais le front-end et le back-end communiquent indirectement, via des files d'attente de messages. Il existe une file d'attente distincte pour chaque type de message, et le frontend, par le type de message, détermine où l'écrire, et les backends écoutent ces files d'attente.
Pour que le backend puisse envoyer une réponse à la demande au client, ou une sorte d'événement, chaque frontend a une file d'attente distincte (spécialement allouée pour cela). Et dans chaque demande, le backend reçoit un identifiant de frontend pour déterminer dans quelle file d'attente la réponse doit être écrite. S'il doit envoyer un événement, il appelle la base de données pour savoir à quelle instance frontend le client est connecté.
Avec le schéma général, passons aux détails.

Tout d'abord, je parlerai de certaines caractéristiques de l'interaction client-serveur. Nous utilisons notre protocole binaire car il est assez efficace et permet d'économiser du trafic. Deuxièmement, pour toutes les opérations avec un compte qui le modifient, le serveur n'envoie pas ces modifications au client, mais la version complète (mise à jour) de ce compte. C'est un peu moins efficace, mais cela ne prend pas beaucoup d'espace de toute façon et simplifie considérablement notre vie à la fois sur le client et sur le serveur. De plus, le frontend garantit que le client n'exécute pas plus d'une demande à la fois. Cela vous permet d'attraper des bogues sur le client, par exemple, lorsqu'il passe à un autre écran avant que le joueur ne voie le résultat de l'opération précédente.
Maintenant, un peu sur la façon dont le frontend est organisé.

Un frontend est essentiellement un serveur Web qui écoute les connexions de socket Web. Pour chaque session, deux processus sont créés. Le premier processus sert la connexion de socket Web elle-même, et le second est une machine d'état qui décrit l'état actuel du client. Sur la base de cet état, il détermine la validité des demandes du client. Par exemple, presque toutes les demandes ne peuvent pas être traitées tant que l'autorisation n'est pas terminée. Puisqu'il n'y a aucun état sur le frontend en dehors de ces sessions, il est très facile d'ajouter de nouvelles instances frontend, mais il est un peu plus difficile de supprimer les anciennes. Avant la désinstallation, vous devez laisser tous les clients terminer leurs demandes en cours et leur demander de se reconnecter à une autre instance.
Maintenant, à quoi ressemble le backend. À l'heure actuelle, il se compose de cinq services.
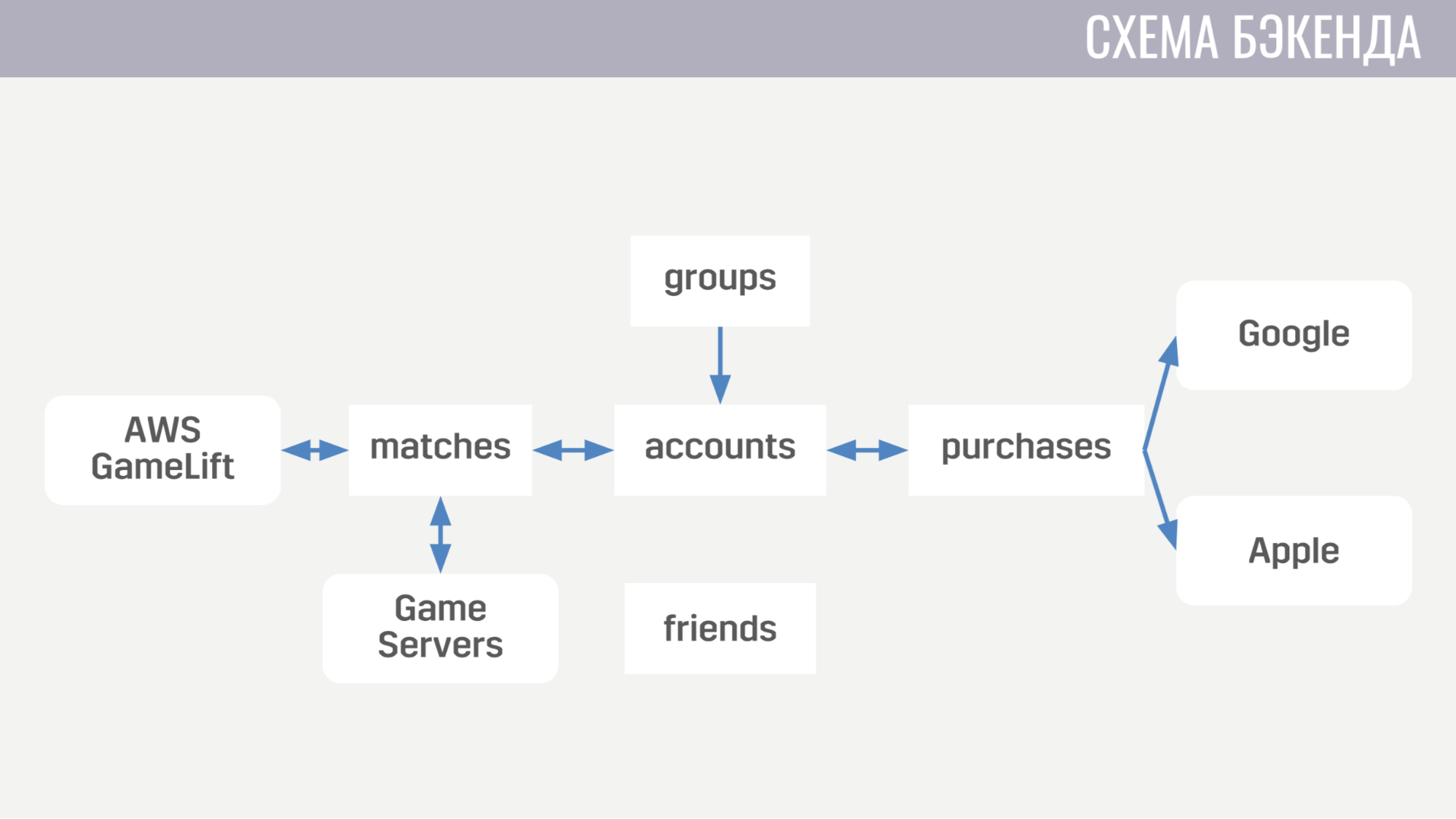
Le premier traite de tout ce qui concerne les comptes - des achats de devises dans le jeu à la réalisation de quêtes. Le second fonctionne avec tout ce qui concerne les matchs - il interagit directement avec GameLift et les serveurs de jeux. Le troisième service consiste à acheter de l'argent réel. Le quatrième et le cinquième sont responsables des interactions sociales - l'un pour les amis, l'autre pour un jeu de société.
Chacun des services backend d'un point de vue architectural est absolument identique. Il s'agit d'un ensemble de pipelines, chacun traitant un type de message. Le pipeline comprend deux éléments: le producteur et le consommateur.

La seule tâche du producteur est de lire les messages de la file d'attente. Par conséquent, il est mis en œuvre sous une forme complètement générale et pour chaque pipeline, nous n'avons qu'à indiquer le nombre de producteurs, la file d'attente à lire et le nombre de consommateurs que chaque producteur servira. Le consommateur, d'autre part, est implémenté séparément pour chaque pipeline et est un module avec la seule fonction obligatoire qui accepte un message, effectue tout le travail nécessaire et renvoie une liste de messages qui doivent être envoyés à d'autres services au client ou au serveur de jeu. Le producteur met également en place une contre-pression afin qu'avec une forte augmentation du nombre de messages il n'y ait pas de surcharge, et ne demande pas plus de messages qu'il n'a de consommateurs gratuits.
Les services principaux ne contiennent aucun état, il nous est donc facile d'ajouter et de supprimer d'anciennes instances. La seule chose à faire avant de supprimer est de demander aux producteurs d'arrêter de lire les nouveaux messages et de donner aux consommateurs un peu de temps pour terminer le traitement des messages actifs.
Comment l'interaction avec GameLift se produit-elle? GameLift se compose de plusieurs composants. Parmi ceux que nous utilisons, il s'agit d'un entremetteur FlexMatch, une file d'attente de placement qui détermine dans quelle région particulière héberger une session de jeu avec ces joueurs, et les flottes elles-mêmes, composées de serveurs de jeu.
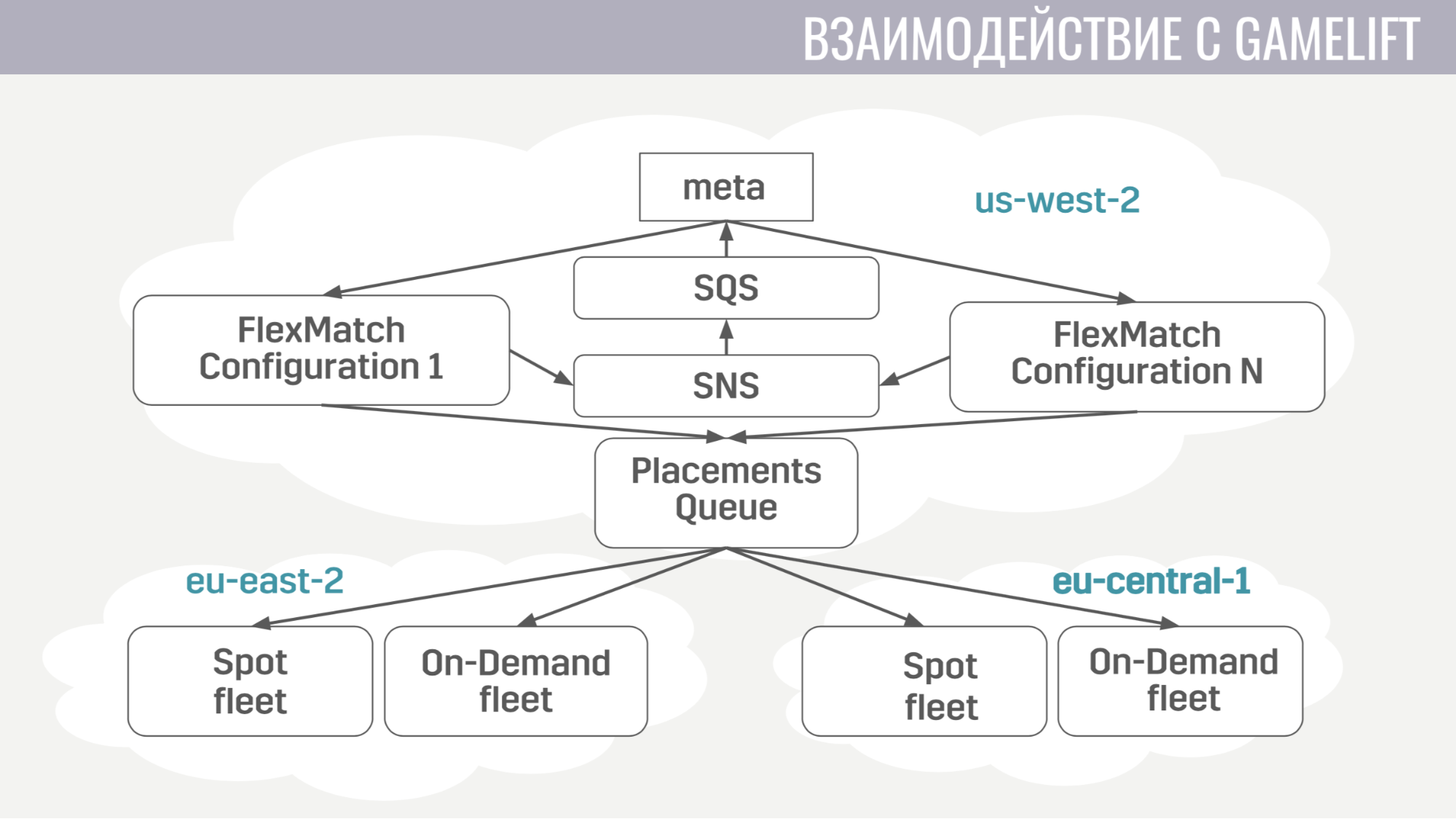
Comment se passe cette interaction? Meta ne communique directement qu'avec le marieur, lui envoie des demandes pour trouver le match. Et il notifie la méta de tous les événements pendant le matchmaking via les mêmes files d'attente de messages. Et dès qu'il trouve un groupe de joueurs approprié pour commencer le match, il envoie une demande à la file d'attente de placement, qui à son tour sélectionne un serveur pour eux.
L'interaction de la méta avec le serveur de jeu est extrêmement simple. Le serveur de jeu a besoin d'informations sur les comptes, les robots et une carte, et la méta envoie toutes ces informations à la file d'attente créée spécifiquement pour cette correspondance dans un seul message.

Et le serveur de jeu, lors de l'activation, commence à écouter cette file d'attente et reçoit toutes les données dont il a besoin. À la fin du match, il envoie ses résultats à la file d'attente générale que la méta écoute.
Passons maintenant à l'infrastructure supplémentaire que nous utilisons.

Le déploiement de services est assez simple. Ils fonctionnent tous dans des conteneurs Docker et nous utilisons Amazon ECS pour l'orchestration. Il est beaucoup plus simple que Kubernetes, bien sûr, moins sophistiqué, mais il effectue les tâches dont nous avons besoin. À savoir: les services de mise à l'échelle et les versions glissantes, lorsque nous devons remplir une sorte de correction de bogue.
Et le dernier service que nous utilisons également est AWS Fargate. Cela nous évite d'avoir à gérer de manière indépendante le cluster de machines sur lequel nos conteneurs Docker fonctionnent.

En tant que stockage principal, nous utilisons DynamoDB. Tout d'abord, nous l'avons choisi car il est très simple d'utilisation et de mise à l'échelle. Nous utilisons également Redis comme stockage supplémentaire via le service géré Amazon ElasiCache. Nous l'utilisons pour la tâche globale de classement des joueurs et pour la mise en cache des informations de base sur les comptes dans les situations où nous devons renvoyer immédiatement des données sur des centaines de comptes de jeu au client (par exemple, dans le même tableau de classement ou dans la liste d'amis).
Pour stocker des configurations, des mécanismes de méta-gameplay, des descriptions d'armes, de héros, etc. nous utilisons un fichier JSON que nous attachons aux images des services qui en ont besoin. Parce qu'il est beaucoup plus facile pour nous de déployer une nouvelle version du service avec des données mises à jour (si un bogue a été découvert) que de prendre une décision qui mettra à jour dynamiquement ces données à partir d'un stockage externe pendant l'exécution.
Pour la journalisation et la surveillance, nous utilisons plusieurs services.
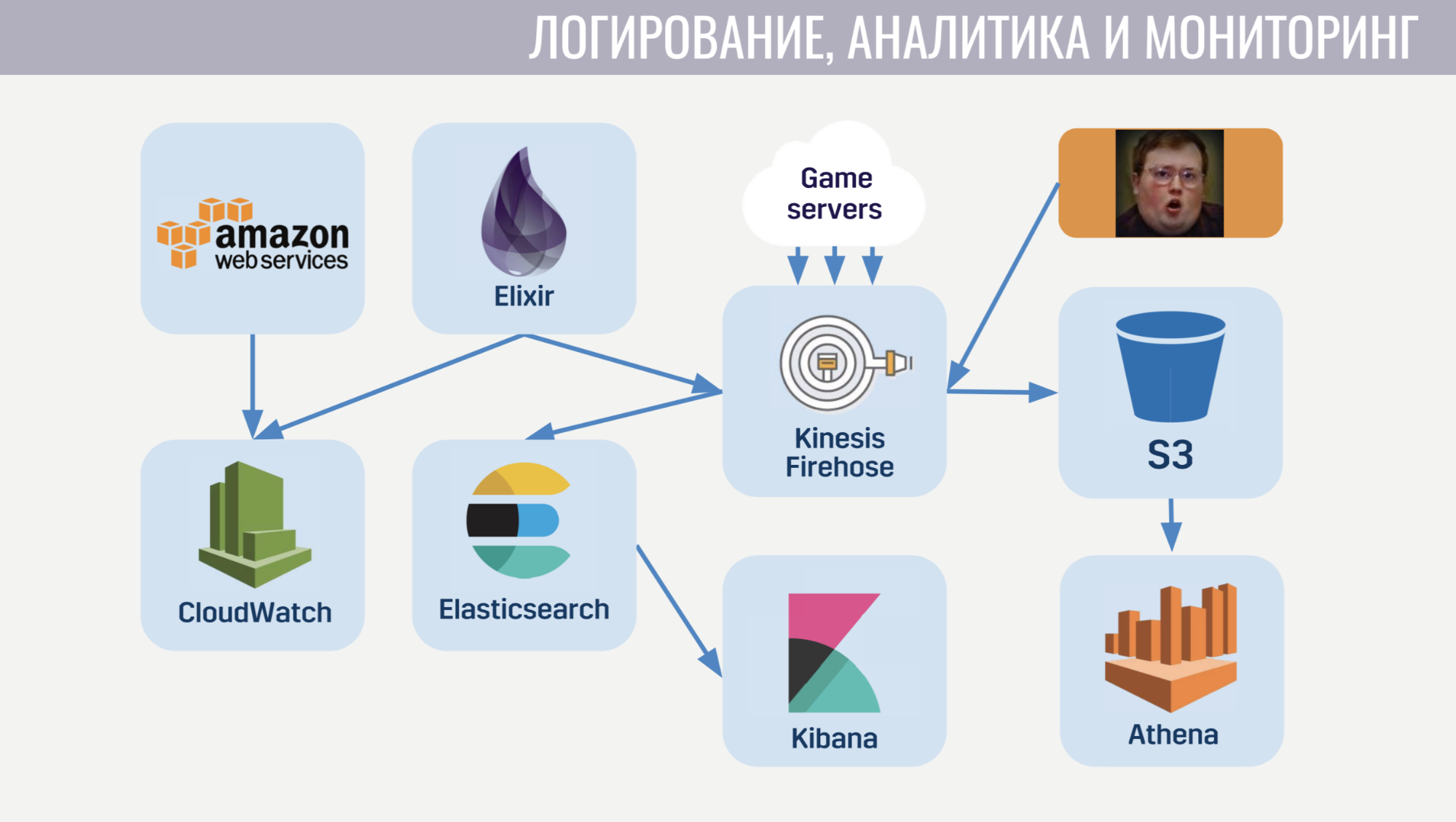
Commençons par CloudWatch. Il s'agit d'un service de surveillance dans lequel les métriques de tous les services Amazon affluent. Par conséquent, nous avons décidé d'envoyer les métriques de notre serveur méta là aussi. Et pour la journalisation, nous utilisons une approche commune à la fois sur le client et sur le serveur de jeu et sur le méta-serveur. Nous envoyons tous les journaux au service amazonien Kinesis Firehose, qui les transfère à son tour à Elasticseach et S3.
Dans Elasticseach, nous ne stockons que des données relativement récentes et avec l'aide de Kibana, nous recherchons les erreurs, résolvons certaines des tâches d'analyse de jeu et créons des tableaux de bord opérationnels, par exemple, avec un calendrier CCU et le nombre de nouvelles installations. S3 contient toutes les données historiques et nous les utilisons via le service Athena, qui fournit une interface SQL en plus des données dans S3.
Maintenant, un peu sur la façon dont nous utilisons Terraform.

Terraform est un outil qui vous permet de décrire de manière déclarative l'infrastructure et, en cas de changement de description, il détermine automatiquement les actions que vous devez entreprendre pour mettre votre infrastructure à jour. Ainsi, ayant une seule description, nous obtenons un environnement presque identique pour la mise en scène et la production. De plus, ces environnements sont complètement isolés, car ils sont déployés sous différents comptes. Le seul inconvénient significatif de Terraform pour nous est le support incomplet de GameLift.
Je parlerai également de la façon dont nous avons mis en œuvre la mise à jour sans interruption.

Lorsque nous publions des mises à jour, nous collectons une copie de la plupart des ressources: services, files d'attente de messages, certaines étiquettes dans la base de données. Et les joueurs qui téléchargent la nouvelle version du jeu se connecteront à ce cluster mis à jour. Mais les joueurs qui n'ont pas encore mis à jour peuvent continuer à jouer pendant un certain temps sur l'ancienne version du jeu, en se connectant à l'ancien cluster.
Comment nous l'avons mis en œuvre. Tout d'abord, en utilisant le moteur de module dans Terraform. Nous avons alloué un module dans lequel nous avons décrit toutes les ressources versionnées. Et ces modules peuvent être importés plusieurs fois, avec différents paramètres. En conséquence, pour chaque version, nous importons ce module, en indiquant le numéro de cette version. L'absence de schéma dans DynamoDB nous a également aidés, ce qui permet d'effectuer des migrations de données non pas lors de la mise à jour, mais de les reporter pour chaque compte jusqu'à ce que son propriétaire se connecte à la nouvelle version du jeu. Et dans l'équilibreur, nous indiquons simplement pour chaque version de la règle afin qu'il sache où acheminer les joueurs avec différentes versions.
Enfin, quelques choses que nous avons apprises. Tout d'abord, la configuration de l'ensemble de l'infrastructure doit être automatisée. C'est-à-dire nous avons mis en place certaines choses avec nos mains pendant un certain temps, mais tôt ou tard, nous avons fait une erreur dans les paramètres, à cause de laquelle il y avait des fakaps.

Et la dernière chose - vous devez avoir une réplique ou une copie de sauvegarde pour chaque élément de votre infrastructure. Et si vous ne le faites pas pour quelque chose, alors cette chose particulière nous décevra jamais.
Questions du public
- Mais cela ne vous dérange pas que la mise à l'échelle automatique puisse trop coller à cause d'une sorte d'erreur et vous obtiendrez beaucoup d'argent?- Pour la mise à l'échelle automatique, des limites sont toujours définies. Nous ne fixerons pas de limite trop importante pour ne pas tomber pour beaucoup d'argent. C'est la principale solution + surveillance. Vous pouvez définir des alertes si quelque chose est trop fort.
- Quelles sont vos limites actuelles? Par rapport à l'infrastructure actuelle en pourcentage.- Nous avons maintenant une phase de test bêta ouvert dans 11 pays, donc ce n'est pas un si gros CCU à évaluer d'une manière ou d'une autre. Maintenant, l'infrastructure est trop surprovisionnée pour le nombre de personnes que nous avons.
- Et il n'y a pas encore de limites?- Oui, c'est juste qu'ils sont 10 à 100 fois plus que notre CCU. Ne faites pas moins.
- Vous avez dit que vous aviez des lignes entre le front et le backend - c'est très inhabituel. Pourquoi pas directement?- Nous voulions que les services sans état implémentent facilement le mécanisme de sauvegarde, afin que le service ne demande pas plus de messages qu'il n'en a de gestionnaires gratuits. En outre, par exemple, lorsqu'un gestionnaire échoue, la file d'attente transmet le même message à un autre gestionnaire - elle réussira peut-être.
- La file d'attente persiste-t-elle d'une manière ou d'une autre?- Oui. Il s'agit d'un service SQS amazonien.
- Concernant les files d'attente: combien de canaux sont créés pendant le jeu? Avez-vous un certain nombre de chaînes pour chaque match?- Il crée relativement peu. La plupart des files d'attente, telles que les files d'attente de demandes, sont statiques. Il y a une file d'attente de demandes d'autorisation, il y a une file d'attente pour le début du match. Parmi les files d'attente créées dynamiquement, nous n'avons que des files d'attente pour chaque frontend (cela crée des messages entrants pour les clients au démarrage) et pour chaque correspondance, nous créons une file d'attente. Dans ce service, cela ne coûte presque rien, ils ont toute demande facturée de la même manière. C'est-à-dire toute demande à SQS (créer une file d'attente, en lire quelque chose) coûte la même chose et en même temps nous ne supprimons pas ces files d'attente pour les enregistrer, elles seront supprimées plus tard. Et le fait qu'ils existent ne nous coûte rien.
- Dans cette architecture, cela ne sera pas une limite pour vous?- Non.
Plus d'entretiens avec Pixonic DevGAMM Talks