
Cet été, nous avons appris au réseau neuronal à déterminer si un document est présent sur l'image, et si oui, lequel.
Pourquoi est-il nécessaire
Pour décharger les employés et protéger les gens contre les escrocs. Nous utilisons le nouveau réseau de neurones dans deux domaines: lorsque l'utilisateur retrouve l'accès à la page et pour masquer les documents personnels de la recherche générale.
Restauration de l'accès aux pages. Les photos des documents aident à restituer les comptes à leurs véritables propriétaires. Par exemple, un utilisateur peut avoir perdu l'accès à son numéro de téléphone ou une authentification en deux étapes a été activée sur la page, et il n'y a plus aucune possibilité de recevoir un code unique pour confirmer l'entrée. Le nouveau développement accélère la prise en compte des applications: les modérateurs n'ont plus à renvoyer à chaque fois des applications mal remplies. Le système ne permet tout simplement pas au visiteur de soumettre le formulaire sans les images nécessaires et demande de remplacer l'image aléatoire par un document. Bien sûr, nous ne pouvons retourner l'accès à la page elle-même que si elle contient de vraies photos du propriétaire. Nous parlons de la sécurité des comptes et de la conservation des données personnelles - ce qui signifie qu'il ne peut tout simplement pas y avoir de bévues et d'accidents.
Filtrage des résultats de recherche dans la section " Documents ". Tous les documents que les utilisateurs téléchargent dans cette section ou envoient via des messages privés sont cachés par défaut aux regards indiscrets et ne tombent pas dans les résultats de recherche. Mais le niveau de confidentialité peut être configuré manuellement vous-même - pour chaque fichier individuel. Avant l'avènement du réseau neuronal, on pouvait trouver une quantité décente de documents contenant des données sensibles à l'aide de mots clés. Les propriétaires de ces fichiers eux-mêmes ont modifié les paramètres de confidentialité. Nous avons sécurisé les utilisateurs et commencé
à supprimer des photos
d'une recherche publique dans laquelle nous pouvons déterminer la présence d'un document.
Comment nous avons résolu le problème
Il semble que la façon la plus simple d'identifier des documents dans une image soit de mettre en place un réseau neuronal ou de le former à partir de zéro dans un grand échantillon. Mais pas si simple.
L'échantillon doit être représentatif. Il est difficile de trouver un nombre suffisant d'échantillons réels pour chaque option: il n'y a pas de bases de données publiques avec ces documents dans le domaine public.
Il existe de nombreux systèmes qui reconnaissent et analysent les documents. Ils visent généralement à obtenir des informations spécifiques à partir d'une photographie et suggèrent la qualité idéale de l'image originale. Par exemple, un utilisateur peut être amené à aligner le passeport le long des bords du modèle, car il fonctionne sur le portail des services d'État.
De tels systèmes ne conviennent pas à nos tâches. Nous clarifions séparément que lorsqu'il nous contacte pour la restauration de l'accès, l'utilisateur
peut fermer toutes les données sur le document, à l'exception des photos, prénom, nom et impression. En même temps, nous devons encore déterminer le document - même si la série et le numéro y sont cachés, si le passeport est pris avec l'environnement, ou, inversement, seule une partie du document avec la photographie est apparue sur l'image. Encore faut-il considérer différents éclairages et angles. Le réseau neuronal doit accepter tous ces matériaux. La question est de savoir comment lui apprendre cela.

Il y a d'autres difficultés. Par exemple, il est difficile de séparer le passeport des autres types de documents, ainsi que de divers papiers manuscrits et imprimés.
Essayer de suivre la voie facile n'a pas été très réussi. Le classificateur résultant s'est avéré faible, avec une petite erreur du premier type et une grande erreur du second. Par exemple, il y a eu des cas intéressants où une personne a écrit un nom et un prénom à la main, dessiné une photographie, la couverture d'un passeport - et le système a accepté nonchalamment un tel document.
Où en sommes-nous
Dans notre situation, la meilleure solution au problème était d'utiliser un ensemble de grilles et de détecteurs de visage pour reconnaître un document et déterminer son type. Nous avons également ajouté un classificateur différentiel, qui comprend un encodeur pour mettre en évidence les caractéristiques, et un classificateur de formulaire qui vous permet de distinguer les images de document des fichiers non pertinents. De plus, un regroupement préliminaire de l'ensemble d'apprentissage est effectué afin de normaliser l'ensemble de données. Parmi les architectures,
VGG et
ResNet ont fait
leurs preuves.
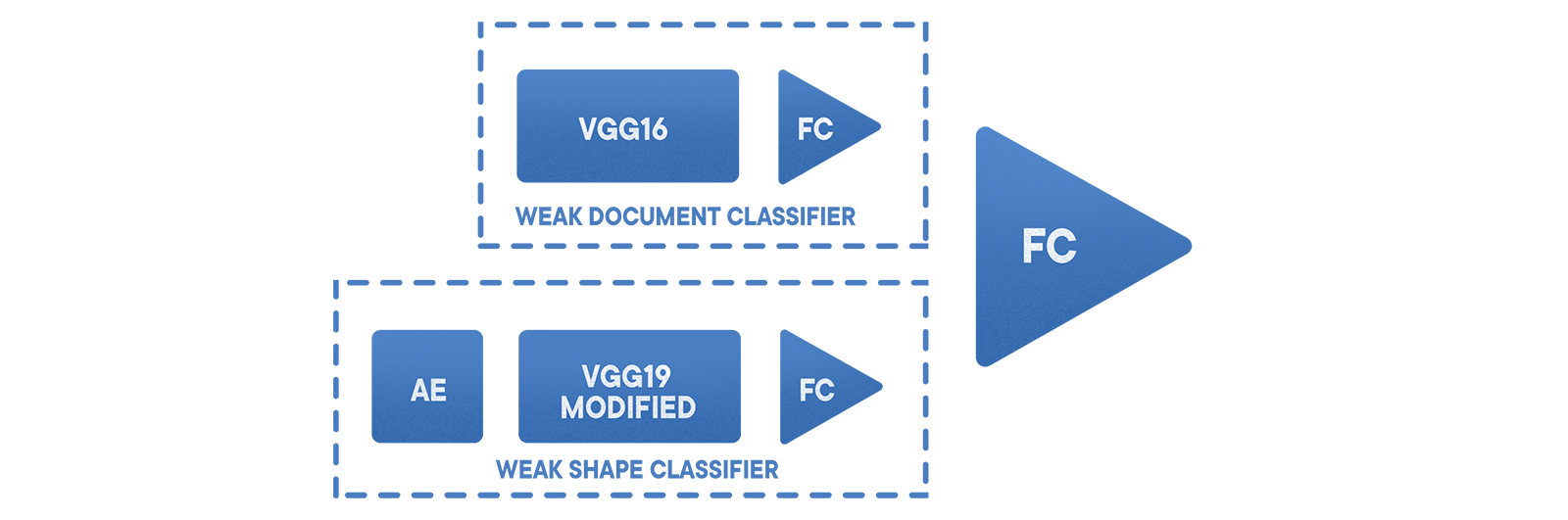
Le classificateur de base «document / non-document» fonctionne sur la base d'un VGG réglé avec 19 couches et un échantillon zoné. De plus, un ensemble combiné de classificateurs est utilisé, ce qui réduit l'erreur du second type et différencie le résultat. Vient d'abord l'
échantillonnage stratifié , puis un encodeur pour extraire les informations en boucle proche, puis un VGG modifié et enfin une seule grille. Cette approche a permis de minimiser les erreurs du premier type à un niveau d'environ 0,002. La probabilité de faux négatifs dans ce cas dépend de l'ensemble de données sélectionné et de l'application spécifique.
Nous avons maintenant appris à détecter automatiquement la présence de passeports et de permis de conduire sur la photo. La reconnaissance se produit avec succès sous n'importe quel angle, avec n'importe quel arrière-plan, même dans de mauvaises conditions d'éclairage - l'essentiel est que l'image contienne une partie du document avec une photo et un nom. Cependant, pour identifier d'autres types de documents, seuls les jeux de données pertinents seront nécessaires. Nous formons le réseau sur nos propres données, la taille de l'échantillon des documents est de cinq à dix mille (mais ce n'est pas représentatif). Pour d'autres images, l'échantillon est arbitraire, mais il y a a priori un clustering là et là.
D'un point de vue technique, le système est écrit en python /
keras /
tensorflow /
glib /
opencv . Pour une application pratique du nouveau système, il suffit de l'intégrer dans les gestionnaires python de l'infrastructure d'apprentissage automatique. Au même stade, un détecteur de changement de photo dans les éditeurs graphiques est ajouté, mais ce sujet mérite un article séparé.
Quel est le résultat
Désormais, 6% des demandes de restauration de l'accès sont automatiquement retournées à l'auteur avec une demande d'ajout ou de remplacement d'une photo du document, et 2,5% des demandes sont rejetées. Si vous regardez l'analyse des images dans son ensemble, y compris l'heuristique et la recherche de visages dans une image, cela
automatise jusqu'à 20% du travail du département .
Après le lancement du réseau neuronal, nous avons également pu calculer le nombre de passeports téléchargés dans la section «Documents». Il s'est avéré que dans les résultats de recherche généraux, il y avait chaque jour environ deux mille cartes d'identité. Maintenant, la probabilité qu'ils tombent entre des mains étrangères est minime.
Les réseaux de neurones nous aident déjà à lutter contre le spam et toutes sortes de fraudes. Nous n'arrêtons pas les expériences et continuons d'en parler dans notre blog.