Salut Habr! Aujourd'hui, nous continuons la dernière histoire sur l'ADN. Dans ce document, nous avons parlé de combien
cela se produit, comment l'ADN est stocké et pourquoi il est si important . Aujourd'hui, nous commencerons par un historique et terminerons avec les bases du codage des informations dans l'ADN.
L'histoire
L'ADN lui-même a été isolé en 1869 par Johann Friedrich Mischer des globules blancs qu'il a reçus du pus. Les globules blancs sont des globules blancs qui remplissent une fonction protectrice. Il y en a beaucoup dans le pus, car ils ont tendance à endommager les tissus, où les cellules bactériennes les «mangent». Il a isolé une substance qui contient de l'azote et du phosphore. Au début, il a été appelé nuclein, cependant, quand il a découvert des propriétés acides, le nom a été changé en acide nucléique. La fonction biologique de la substance nouvellement découverte n'était pas claire et pendant longtemps, on a cru que le phosphore y était stocké. Même au début du 20e siècle, de nombreux biologistes pensaient que l'ADN n'avait rien à voir avec le transfert d'informations, car la structure de la molécule, comme il semblait alors, était trop monotone et ne pouvait pas coder autant d'informations.
En 1901, Albrecht Kossel a isolé et décrit les cinq bases azotées qui composent l'ADN et l'ARN. Et un peu plus tard, Peter Leuven a découvert que le composant glucidique des acides nucléiques était le désoxyribose et le ribose. Les acides nucléiques, qui comprennent le ribose, étaient appelés acides ribonucléiques ou, en bref, ARN, et ceux qui contenaient du désoxyribose, des acides désoxyribonucléiques ou de l'ADN.
Maintenant, la question s'est posée de savoir comment les liens individuels sont interconnectés. Pour cela, le brin d'ADN devait être détruit et regarder ce qui se passerait après la destruction. Pour cela, le polymère d'ADN a été hydrolysé. Cependant, Louvain a changé la méthode d'hydrolyse. Maintenant, au lieu de bouillir pendant de nombreuses heures dans un environnement acide, il a utilisé des enzymes. Cette fois, non seulement l'adénine, la guanine, la thymine, la cytosine, le désoxyribose et l'acide phosphorique ont été isolés à partir d'hydrolysats, mais aussi de plus gros fragments, par exemple, des composés de bases azotées avec des glucides ou des glucides avec de l'acide phosphorique. En même temps
, aucun composé constitué de deux bases azotées ou de composés de type acide phosphorique base n'a été trouvé dans les hydrolysats d'acide nucléique . Autrement dit, il est devenu clair que l'acide phosphorique se combine avec le sucre et, à son tour, avec une base azotée. On a proposé que les composés de bases azotées avec un hydrate de carbone soient appelés nucléosides, et les esters phosphoriques de nucléosides ont été appelés nucléotides.
À la suite de ces travaux, Leuven a conclu que les acides nucléiques sont des polymères. Les nucléotides servent de monomères. Le contenu de chacun des quatre nucléotides dans l'ADN, ou ARN, selon l'analyse chimique de l'époque, semblait égal à Leven. Par conséquent, Louvain a proposé la théorie suivante de la structure des acides nucléiques: ce sont des polymères dont les monomères sont des blocs de quatre nucléotides connectés en série.
La théorie de la structure des tétranucléotides à cette époque semblait tout à fait justifiée, étant entrée dans tous les manuels de la période d'avant-guerre. Cependant, la question de la fonction de l'ADN n'est pas claire. Il a fallu près d'un demi-siècle pour clarifier cette question.
Il y a eu une période durant laquelle les biologistes ont accumulé des informations sur la distribution des acides nucléiques dans divers types de tissus animaux et végétaux, dans les bactéries et les virus, dans certains organismes unicellulaires.
À cette époque, la communauté scientifique croyait sérieusement que ce sont les protéines qui étaient responsables du stockage des informations génétiques. L'idée traditionnelle du rôle principal des protéines dans le processus de vie ne nous a pas permis de penser qu'une substance aussi importante qu'une substance héréditaire pourrait être tout sauf une protéine. Les protéines étaient extrêmement diverses dans leur structure, ce qui ne pouvait pas dire alors sur les acides nucléiques. Le célèbre généticien-cytologiste soviétique N.K. Koltsov a calculé qu'en faisant varier la séquence de 20 acides aminés qui composent la molécule de protéine, des billions de protéines dissemblables peuvent être créées.
Si nous voulions imprimer sous la forme la plus simplifiée la façon dont les tableaux logarithmiques sont imprimés, ce billion de molécules fournirait toutes les imprimeries existantes du monde pour réaliser ce plan, produisant 50000 volumes de 100 feuilles imprimées par an, alors tant de temps se serait écoulé avant la fin des travaux entrepris, combien s'est passé depuis la période archéenne de nos jours.
Vraiment beaucoup ... 20 dans le 20 ... Mais les séquences sont bien plus longues que 20 acides aminés.
Et voici ce que A. R. Kizel écrit à ce sujet - l'un des biochimistes les plus érudits de l'époque.
Du point de vue qui vient d'être donné sur le rôle de l'acide nucléique ... il s'ensuit qu'il n'est pas impliqué dans la structure des gènes et il s'ensuit que les gènes sont constitués d'un autre matériel. Nous ne connaissons toujours pas ce matériau de manière fiable, malgré le fait que dans la plupart des cas, il est directement appelé protéine.
Le premier succès est venu de la microbiologie. En 1944, les résultats des expériences d'Avery et de ses employés (USA) sur la transformation des bactéries ont été publiés. Quelques mots sur la transformation.
La transformation elle-même a été découverte en 1928 par le microbiologiste Griffiths.
Griffith a travaillé avec des cultures de pneumocoque (Streptococcus pneumoniae), l'agent causal de l'une des formes de pneumonie. Certaines souches de cette bactérie sont virulentes, provoquant une pneumonie. Leurs cellules sont recouvertes d'une capsule de polysaccharide qui protège la bactérie de l'action du système immunitaire. En culture, ces bactéries forment de grandes colonies lisses de forme sphérique régulière. Pour cette raison, elles sont appelées souches S (de l'anglais smooth - smooth).
Il existe différentes souches virulentes de pneumocoque, elles diffèrent par les anticorps qui sont produits dans l'organisme lorsque les bactéries y pénètrent. Elles sont appelées IS, IIS, IIIS, etc. De temps en temps, certaines cellules de souches S virulentes mutent, perdant la capacité de synthétiser la membrane polysaccharidique et deviennent avirulentes. En culture, ils forment de petites colonies rugueuses de forme irrégulière, à cause de cela ils sont appelés R-souches (de l'anglais rugueux - rugueux). Parfois, des mutations inverses se produisent, rétablissant la capacité de synthétiser la membrane polysaccharidique, mais uniquement dans des groupes de souches correspondantes:
IIS - IIR
IIIS - IIIR
Cela suggère que les souches R avirulentes correspondent toujours à la souche S virulente parentale.
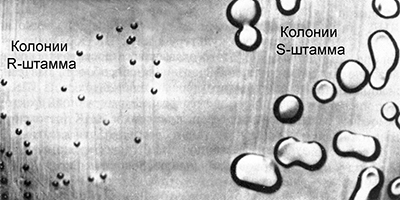
Griffith a introduit différents groupes de souris de laboratoire, une souche virulente et avirulente de pneumocoque. Dans le premier groupe témoin, l'injection d'une souche virulente de IIIS a entraîné la mort d'animaux. Les animaux du deuxième groupe témoin sont restés en vie après l'injection de la souche avirulente IIR. Après cela, Griffith a chauffé la solution avec la culture de la souche virulente IIIS à une température de 60 ° C, ce qui a entraîné la mort des bactéries. Il a introduit des bactéries tuées par chauffage dans le troisième groupe de souris expérimentales. Les animaux sont restés en vie, ce qui était en principe attendu. Mais ce n'est pas tout. Il a introduit des parties de souris survivantes aux bactéries de la souche avirulente IIR.
Il semblait que cela ne pouvait entraîner de terribles conséquences pour les souris. Cependant, contrairement aux attentes, les animaux sont morts. Lorsque des bactéries ont été isolées de leur corps et semées en culture, il s'est avéré qu'elles appartenaient à la souche virulente IIIS.

Le fait que les cellules provoquant la mort de souris aient synthétisé une membrane polysaccharidique de type III, plutôt que II, indiquait qu'elles ne pouvaient pas être apparues à la suite de la mutation inverse IIR - IIS. De cela, Griffith a tiré une conclusion très importante. Les bactéries avirulentes de la souche IIR peuvent se transformer en bactéries virulentes interagissant d'une manière ou d'une autre avec des bactéries tuées par la chaleur de la souche IIIS qui sont restées dans le corps des souris. En d'autres termes, les bactéries avirulentes de la souche IIR reçoivent un facteur des bactéries mortes de la souche IIIS qui les transforme en virus virulents. Cependant, quel était ce facteur, Griffith ne le savait pas.
En fait, ce phénomène a été appelé transformation bactérienne. Il s'agit d'un transfert unidirectionnel de traits héréditaires d'une cellule bactérienne à une autre.
Revenons maintenant aux expériences d'Avery. La conception de leurs expériences est quelque peu similaire aux expériences de Griffiths. Avery et le personnel se sont donné pour tâche de découvrir la nature chimique de l'agent de transformation. Ils ont détruit la suspension de pneumocoques et retiré les protéines, le polysaccharide capsulaire et l'ARN de l'extrait, cependant, l'activité transformante de l'extrait est restée. L'activité transformante du médicament n'a pas été perdue lors de son traitement avec de la trypsine cristalline ou de la chymotrypsine (protéines destructrices), de la ribonucléase (détruit l'ARN). Il était clair que le médicament n'était ni une protéine ni un ARN. Cependant, l'activité transformante du médicament a été complètement perdue lorsqu'il a été traité avec une désoxyribonucléase (endommageant l'ADN), et des quantités négligeables de l'enzyme ont provoqué une inactivation complète du médicament. Ainsi, il a été constaté que le facteur de transformation des bactéries est l'ADN pur. Cette conclusion était une découverte importante, et Avery en était bien conscient. Il a écrit que c'est exactement ce dont la génétique a longtemps rêvé, à savoir la substance du gène. Ici, cela semble être une preuve. Mais trop forte était la croyance en la protéine, en tant que substance de l'hérédité. Certains pensaient que la transformation pouvait causer et ces impuretés protéiques insignifiantes qui restaient dans le médicament.
La nouvelle preuve du rôle génétique direct de l'ADN est l'expérience des virologues Hershey et Chase. Ils ont travaillé avec le bactériophage T2 (bactériophages - virus bactériens), qui infecte la bactérie
Escherichia coli (E. coli).
En fait, ce qu'ils ont fait. Ils incluaient du phosphore radioactif dans la composition de l'ADN de certains bactériophages (P32) et l'isotope du soufre dans la composition des protéines d'autres (S35). Pour cela, certaines bactéries ont été cultivées sur un milieu avec l'ajout de phosphore radioactif dans l'ion phosphate, tandis que d'autres ont été cultivées dans un milieu avec l'ajout de soufre radioactif dans l'ion sulfate. Ensuite, le bactériophage T2 a été ajouté à ces bactéries qui, se multipliant dans les cellules bactériennes, ont inclus un marqueur radioactif dans son ADN (P est dans l'ADN, mais pas dans les protéines), ou des protéines (S est dans les protéines, mais pas dans l'ADN).
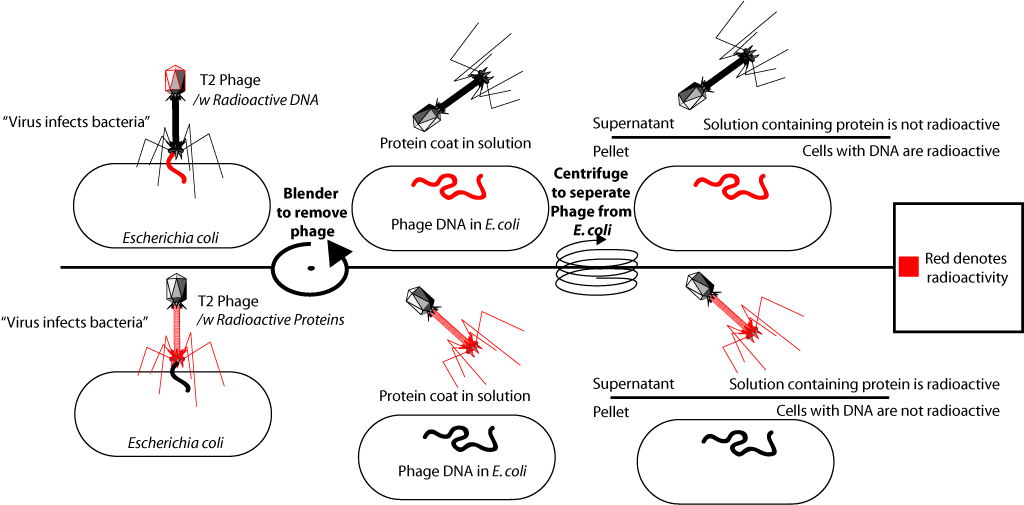
Après isolement des bactériophages radioactivement marqués, ils ont été ajoutés à la culture de bactéries fraîches (sans isotopes). Ce qui a conduit à l'infection de ces bactéries. Le bactériophage se lie à la cellule bactérienne et «injecte» son ADN. Après cela, le milieu avec les bactéries a été secoué vigoureusement dans un mélangeur spécial (il a été montré que dans ce cas les membranes des phages étaient séparées de la surface des cellules bactériennes), puis les bactéries infectées ont été séparées du milieu. Lors de la première expérience, des bactériophages marqués au phosphore 32 ont été ajoutés aux bactéries, il s'est avéré que le marqueur radioactif se trouvait dans les cellules bactériennes. Lorsque, dans la deuxième expérience, des bactériophages marqués au soufre-35 ont été ajoutés aux bactéries, le marqueur a été trouvé dans une fraction du milieu avec des enrobages protéiques, mais il ne se trouvait pas dans les cellules bactériennes. Cela a confirmé que le matériel qui a infecté la bactérie était de l'ADN. Étant donné que des particules virales complètes contenant des protéines virales se forment à l'intérieur de bactéries infectées, cette expérience est devenue l'une des preuves décisives du fait que l'information génétique (informations sur la structure des protéines) est contenue dans l'ADN.
Ces découvertes ont grandement influencé de nombreux biologistes de l'époque. En particulier sur le célèbre pour ses règles, Chargaff. Il pensait qu'Avery avait essentiellement découvert une «nouvelle langue», ou du moins montré où la chercher.
Charguff a commencé à rechercher une différence dans la composition nucléotidique et la disposition des nucléotides dans les préparations d'ADN obtenues à partir de diverses sources. Et, comme il n'y avait pas de méthode pour donner avec précision la caractérisation chimique de l'ADN, à ce moment-là ... il a dû les inventer. On lui a montré que l'ancienne théorie des tétranucléotides sur la structure des acides nucléiques est incorrecte. L'ADN dans différents organismes est très différent dans sa composition et sa structure. Dans le même temps, de nouveaux faits ont été découverts qui n'avaient pas été établis auparavant pour d'autres polymères naturels, à savoir la régularité du rapport des bases individuelles dans la composition de tout l'ADN étudié. Maintenant, même les écoliers les connaissent comme les règles de Chargaff.
- La quantité d'adénine est égale à la quantité de thymine et de guanine à la cytosine: A = T, G = Ts.
- Le nombre de purines est égal au nombre de pyrimidines: A + G = T + C.
- Il découle du premier et du second. Le nombre de bases avec des groupes amino en position 6 est égal au nombre de bases avec des groupes céto en position 6: A + C = T + G.
Nous avons évoqué le mécanisme
dans le dernier article , je ne m'y attarderai donc pas ici.
Lentement, nous avons approché deux personnes légendaires qui ont découvert la structure de l'ADN. Francis Crick et James Watson se sont rencontrés pour la première fois en 1951. Watson a alors décidé de s'attaquer à la structure de l'ADN. En tant que biologiste, il a compris que lors du choix d'une structure d'ADN spécifique, il fallait tenir compte de l'existence d'un principe simple de doublement de la molécule d'ADN incrustée dans sa structure. En effet, l'une des propriétés les plus importantes des gènes est la transmission d'informations héréditaires.
Crick a créé la théorie de la diffraction des rayons X par des spirales, qui permet de déterminer si la structure étudiée est en conformation en spirale ou non. À cette époque, des radiographies d'ADN existaient déjà. Ils ont été reçus à Londres par Maurice Wilkins et Rosalind Franklin.
Par la nature des rayons X de l'ADN, Watson et Crick ont réalisé que la structure à l'étude était en forme de spirale. Ils savaient également qu'une molécule d'ADN est une longue chaîne polymère linéaire constituée de monomères nucléotidiques. Le squelette phosphodésoxyribose de ce polymère est continu et des bases azotées sont fixées sur le côté des résidus de désoxyribose. Pour construire les modèles, il restait à résoudre la question du nombre de chaînes de polymère linéaire empilées dans une structure compacte.
Sur la base des rayons X de l'ADN sous forme B, Watson et Crick ont suggéré que la molécule d'ADN se compose de deux chaînes polynucléotidiques linéaires avec un squelette phosphodésoxyribose à l'extérieur de la molécule et des bases azotées à l'intérieur. Ce qui a ensuite été confirmé. Il ne restait plus qu'à résoudre la question de l'arrangement des bases azotées des deux chaînes à l'intérieur du bispiral.
En considérant les combinaisons possibles de paires de bases azotées, Watson a découvert que les paires adénine - thymine et guanine - cytosine sont de la même taille et sont stabilisées par des liaisons hydrogène. Les règles de Chargaff ont été immédiatement expliquées: si dans une double hélice, l'ADN adénine d'une chaîne se connecte toujours avec la thymine d'une autre chaîne, et la guanine est toujours associée à la cytosine, alors l'adénine dans l'ADN doit toujours être autant que la thymine et la guanine - autant combien de cytosine. Il était également clair comment le doublement de la molécule d'ADN devait se produire. Chaque brin est complémentaire de l'autre, et dans le processus de réplication de l'ADN, les brins à double hélice doivent se séparer et chaque brin qui lui est complémentaire doit être complété sur chaque brin polynucléotidique. Il y avait aussi plusieurs théories, mais à leur sujet dans une semaine, dans le prochain article.
Informations de codage
Donc, nous savons que l'ADN est porteur d'informations, nous savons de quoi il s'agit. Mais la façon dont les informations sont codées n'est pas encore claire.
Allons de la tâche. L'ADN code pour 20 acides aminés (nous pouvons dire que 21, mais jusqu'à présent, nous ne touchons pas à la sélénocysténine). Il existe 4 options pour les nucléotides. Autrement dit, un nucléotide peut coder pour 4 variantes, 2 - 16, 3 -64. Il est logique de supposer que le code est un triplet (c'est-à-dire que trois bases codent pour un acide aminé). Vous pouvez lire sur la confirmation expérimentale
ici . J'ai peur qu'il y ait déjà beaucoup d'histoire ...
En fait, nous avons 64 variantes et 20 acides aminés. Les acides aminés peuvent être codés par différents codons. Il existe également des codons de démarrage et d'arrêt à partir desquels la lecture commence.
N'oubliez pas que l'ADN est d'abord lu dans l'ARN, avec lequel il lit déjà dans la protéine.
Le tableau ci-dessous montre la correspondance des codons d'ARN avec les acides aminés. N'oubliez pas qu'il n'y a pas de thymine dans l'ARN, mais l'uracile est utilisé à la place.

Si vous n'avez pas trouvé le codon de départ dans le tableau, recherchez AUG. Il code la méthionine et est également le premier. Lors de la traduction des gènes des procaryotes, des plastides et des gènes mitochondriaux, l'acide aminé de départ est la N-formylméthionine (c'est juste pour référence).
Si vous peignez tout le chemin de l'ADN aux protéines, nous obtenons quelque chose comme ça.
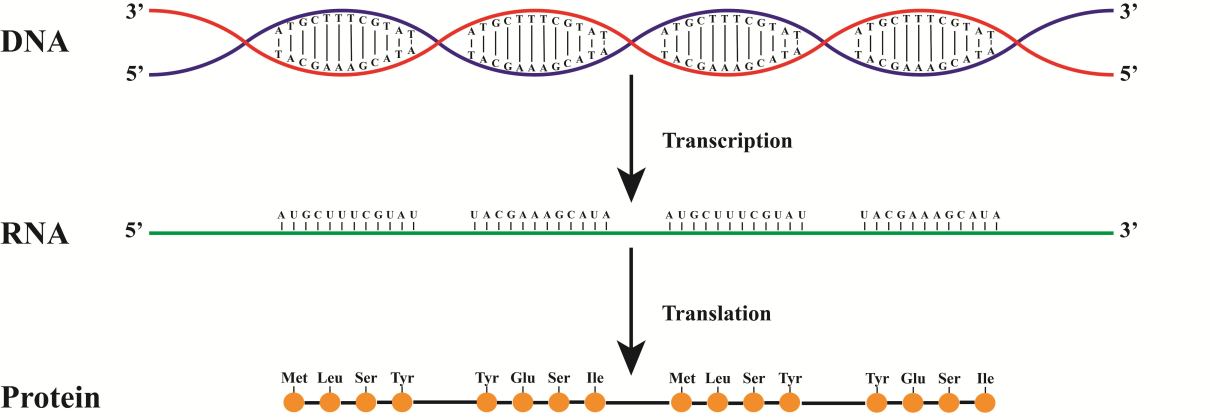
Sur cette figure, la synthèse est issue de la chaîne rouge. En conséquence, l'ARN coïncidera avec la chaîne bleue (n'oubliez pas de remplacer T par Y)
Comme je l'ai dit, plusieurs codons peuvent coder pour chaque acide aminé. À première vue, cela ne semble pas être un effet secondaire particulièrement nécessaire de la redondance des codons. Mais il a en fait un rôle assez important.
Ici, nous aborderons un peu les mutations. Ils viennent dans différents types. Des chromosomes, lorsque des morceaux entiers de chromosomes sont retirés du génome, sont échangés, dupliqués, vers des points, lorsqu'une base azotée est remplacée par une autre. Concentrez-vous sur les mutations ponctuelles.
À quoi peuvent mener les mutations ponctuelles?
Le codon peut commencer à coder un autre acide aminé, ce qui n'est pas toujours effrayant. De telles mutations sont appelées mutatsimi faux-sens (c'est-à-dire avec un changement de sens). Cela peut affecter la structure de la protéine.
Par exemple, si un acide aminé chargé positivement est remplacé par un acide chargé négativement, cela peut rendre la protéine instable, ou conduire à son repliement dans une autre conformation (oui, la séquence linéaire des acides aminés se replie généralement sous une certaine forme) et ne peut pas remplir ses fonctions (ou commence à le faire) mieux, ça sent déjà l’évolution).Plus précisément, l'hémoglobine S a un seul changement de nucléotide (A à T) dans le gène codant. En conséquence, le triplet GAG codant pour le glutamate est remplacé par la valine codant pour THG. L'hémoglobine S peut également transporter de l'oxygène, mais elle est pire que l'hémoglobine ordinaire.Dans la molécule d'hémoglobine Hikari, l'asparagine remplace la lysine, cependant, il est toujours bon de transférer l'oxygène.Comme exemple de perte de fonction, considérons l'hémoglobine M. Une autre mutation ponctuelle du gène de l'hémoglobine entraîne une perte complète de fonction (l'histidine se transforme en tyrosine dans le centre actif).Soit dit en passant, le repliement des protéines ressemble à ceci si vous omettez toutes les nuances. Que pourrait-il arriver d'autre?Le remplacement d'une base azotée peut également entraîner l'apparition d'un codon d'arrêt au centre de la séquence, ou vice versa, le codon d'arrêt disparaîtra à la fin. La sortie sera soit un circuit incomplet soit un circuit extrêmement long, qui de toute façon ne pourra pas fonctionner normalement. Ces mutations sont appelées non-sens.
Que pourrait-il arriver d'autre?Le remplacement d'une base azotée peut également entraîner l'apparition d'un codon d'arrêt au centre de la séquence, ou vice versa, le codon d'arrêt disparaîtra à la fin. La sortie sera soit un circuit incomplet soit un circuit extrêmement long, qui de toute façon ne pourra pas fonctionner normalement. Ces mutations sont appelées non-sens.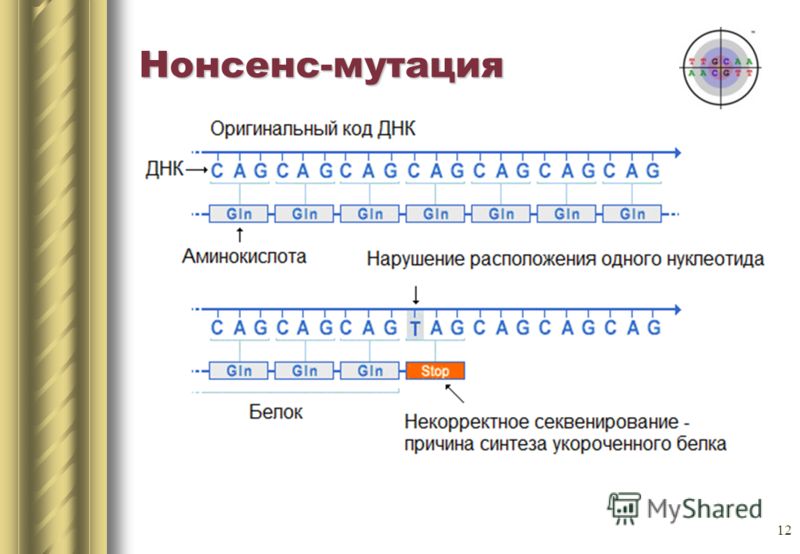 Il existe un troisième type de mutation: la mutation silencieuse. En fait, le codon est remplacé par un autre codant pour le même acide aminé. Les propriétés de la protéine ne changent pas.Pour résumer le schéma général.
Il existe un troisième type de mutation: la mutation silencieuse. En fait, le codon est remplacé par un autre codant pour le même acide aminé. Les propriétés de la protéine ne changent pas.Pour résumer le schéma général.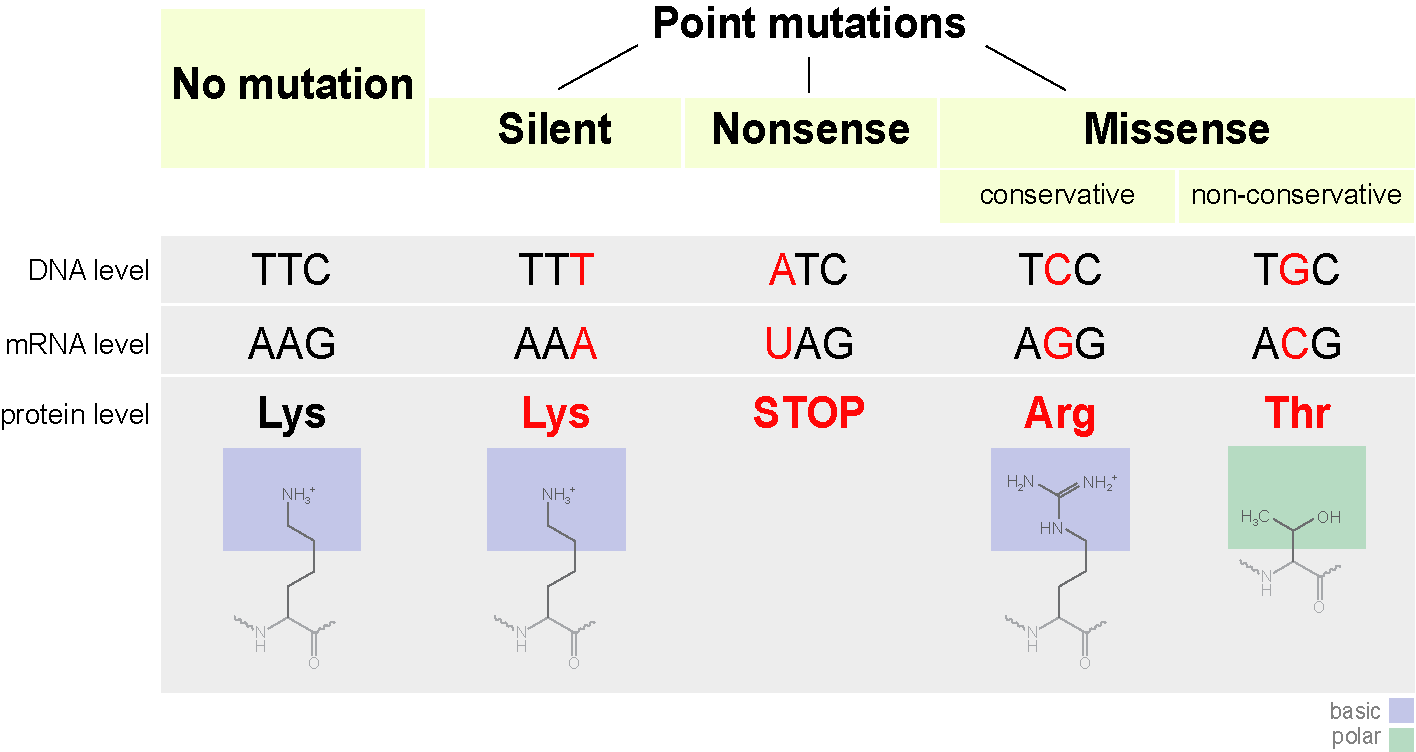 En conclusion, je voudrais également parler d'une caractéristique intéressante. Un seul acide aminé peut être codé par plusieurs codons. Nous le savons. Mais qu'est-ce que cela signifie? Le corps utilise tous les codons à la fois pour le codage. Mais certains plus souvent, certains moins.Comparer les humains et ... E. coli ( Escherichia coli ) dans la fréquence d'utilisation des codons codant pour la cystéine.Il est codé par deux codons UGU et UGC. UGUhumain10,6UGC 12,6Escherichia coli (souche O127: H6)UGU 19,1UGC 0,0chiffres est l'occurrence d'un triplet pour mille. On peut voir que nous utilisons les deux codons avec approximativement la même fréquence, tandis que E. coli n'utilise presque aucun codon UGC.Cette caractéristique doit être rappelée, surtout lorsque vous êtes engagé dans le génie génétique et que vous souhaitez produire le produit génique d'un organisme dans un autre. Si vous essayez d'insérer un gène humain avec la présence fréquente du codon UGC dans E. coli de cette souche, vous serez déçu. Dans une cellule, les acides aminés sont associés à des ARN de transport, chacun correspondant à son propre codon. Ainsi, l'ARNt correspondant au codon UGC sera extrêmement petit, ce qui ralentira considérablement la synthèse.Si vous êtes intéressé, alors vous pouvez voir les différences dans la composition des codons d'organismes différents.La composition des codons peut varier considérablement entre des organismes de différentes espèces et différentes souches. Alors Escherichia coliO157: H7 EDL933 est de moins en moins même en termes d'UGC et d'UGU. Ou voici un autre exemple. Les souches de bacilles tuberculeux isolées dans différents pays ont également une composition de code différente .
En conclusion, je voudrais également parler d'une caractéristique intéressante. Un seul acide aminé peut être codé par plusieurs codons. Nous le savons. Mais qu'est-ce que cela signifie? Le corps utilise tous les codons à la fois pour le codage. Mais certains plus souvent, certains moins.Comparer les humains et ... E. coli ( Escherichia coli ) dans la fréquence d'utilisation des codons codant pour la cystéine.Il est codé par deux codons UGU et UGC. UGUhumain10,6UGC 12,6Escherichia coli (souche O127: H6)UGU 19,1UGC 0,0chiffres est l'occurrence d'un triplet pour mille. On peut voir que nous utilisons les deux codons avec approximativement la même fréquence, tandis que E. coli n'utilise presque aucun codon UGC.Cette caractéristique doit être rappelée, surtout lorsque vous êtes engagé dans le génie génétique et que vous souhaitez produire le produit génique d'un organisme dans un autre. Si vous essayez d'insérer un gène humain avec la présence fréquente du codon UGC dans E. coli de cette souche, vous serez déçu. Dans une cellule, les acides aminés sont associés à des ARN de transport, chacun correspondant à son propre codon. Ainsi, l'ARNt correspondant au codon UGC sera extrêmement petit, ce qui ralentira considérablement la synthèse.Si vous êtes intéressé, alors vous pouvez voir les différences dans la composition des codons d'organismes différents.La composition des codons peut varier considérablement entre des organismes de différentes espèces et différentes souches. Alors Escherichia coliO157: H7 EDL933 est de moins en moins même en termes d'UGC et d'UGU. Ou voici un autre exemple. Les souches de bacilles tuberculeux isolées dans différents pays ont également une composition de code différente .Pour résumer
Cette fois, il y avait beaucoup d'histoire et relativement peu de biologie. Cela ne se reproduira plus. Nous avons expliqué comment il est devenu clair que l'ADN est le moyen d'information, comment il est stocké dans l'ADN lui-même. Nous avons parlé de la redondance du code génétique et de ses conséquences. Les mutations et la différence de fréquence d'utilisation de certains codons ont été légèrement affectées.La prochaine fois, nous parlerons de la réplication de l'ADN.PS: il y aura aussi de l'histoire, mais beaucoup moins. J'essaierai de ne plus faire de telles pauses par écrit.