Cet article est une traduction de l'article de Kevin Goldberg «Une analyse des performances des serveurs Python WSGI: partie 2» dzone.com/articles/a-performance-analysis-of-python-wsgi-servers-part avec quelques ajouts du traducteur.
Présentation
Dans la
première partie de cette série, vous avez rencontré
WSGI et les six serveurs les plus populaires selon l'auteur de
WSGI . Dans cette partie, vous verrez le résultat de l'analyse des performances de ces serveurs. À cet effet, un bac à sable de test spécial a été créé.
Concurrents
En raison de contraintes de temps, la recherche a été limitée à six serveurs WSGI. Toutes les instructions de démarrage de ce projet
sont hébergées sur GitHub . Peut-être qu'avec le temps, le projet s'élargira et des analyses de performances pour d'autres serveurs WSGI seront présentées. Mais pour l'instant, nous parlerons de six serveurs:
- Bjoern se décrit comme un «serveur WSGI ultra-rapide» et se vante d'être «le serveur WSGI le plus rapide, le plus petit et le plus léger». Nous avons créé une petite application qui utilise la plupart des paramètres de bibliothèque par défaut.
- CherryPy est un framework et un serveur WSGI extrêmement populaires et stables. Ce petit script a été utilisé pour servir notre exemple d'application via CherryPy .
- Gunicorn a été inspiré par le serveur Ruby's Unicorn (d'où son nom). Il affirme modestement qu'il est "simplement implémenté, facile à utiliser et assez rapide". Contrairement à Bjoern et CherryPy , Gunicorn est un serveur autonome. Nous l'avons créé à l'aide de cette commande . Le paramètre "WORKER_COUNT" a été défini sur deux fois le nombre de cœurs de processeur disponibles, plus un. Cela a été fait sur la base des recommandations de la documentation Gunicorn .
- Meinheld est un serveur Web hautes performances compatible WSGI qui prétend être léger. Sur la base de l'exemple montré sur le site du serveur, nous avons créé notre application .
- mod_wsgi a été créé par le même créateur que mod_python . Comme mod_python , il n'est disponible que pour Apache. Cependant, il inclut un outil appelé "mod_wsgi express" qui crée la plus petite instance Apache possible. Nous avons configuré et utilisé mod_wsgi express avec cette commande . Pour correspondre à Gunicorn , nous avons réglé mod_wsgi pour créer deux fois plus de travailleurs que de cœurs de processeur.
- uWSGI est un serveur d'applications complet. En règle générale, uWSGI est associé à un serveur proxy (par exemple: Nginx). Cependant, afin de mieux évaluer les performances de chaque serveur, nous avons essayé de n'utiliser que des serveurs nus et avons créé deux travailleurs pour chaque cœur de processeur disponible.
Benchmark
Pour rendre le test aussi objectif que possible, un conteneur
Docker a été créé pour isoler le serveur testé du reste du système. En outre, l'utilisation du conteneur Docker a garanti que chaque lancement recommence à zéro.
Serveur:
- Isolé dans un conteneur docker.
- 2 cœurs de processeur alloués.
- La RAM du conteneur était limitée à 512 Mo.
Test:
- wrk , un outil de benchmarking HTTP moderne, a effectué des tests.
- Les serveurs ont été testés dans un ordre aléatoire avec une augmentation du nombre de connexions simultanées de l'ordre de 100 à 10 000.
- wrk était limité à deux cœurs de processeur non utilisés par Docker.
- Chaque test a duré 30 secondes et a été répété 4 fois.
Métrique:
- Wrk a fourni le nombre moyen de demandes persistantes, d'erreurs et de retards.
- Intégrée à Docker, la surveillance a montré les niveaux d'utilisation du processeur et de la RAM.
- Les valeurs les plus élevées et les plus basses ont été rejetées et les valeurs restantes ont été moyennées.
- Pour les curieux, nous avons envoyé le script complet à GitHub .
Résultats
Tous les indicateurs de performance initiaux
ont été inclus dans le référentiel du projet , et un
fichier CSV résumé
a également
été fourni. De plus, pour la visualisation, des graphiques ont été créés dans l'environnement
Google-doc .
RPS par rapport au nombre de connexions simultanées
Ce graphique montre le nombre moyen de demandes simultanées; Plus le nombre est élevé, mieux c'est.
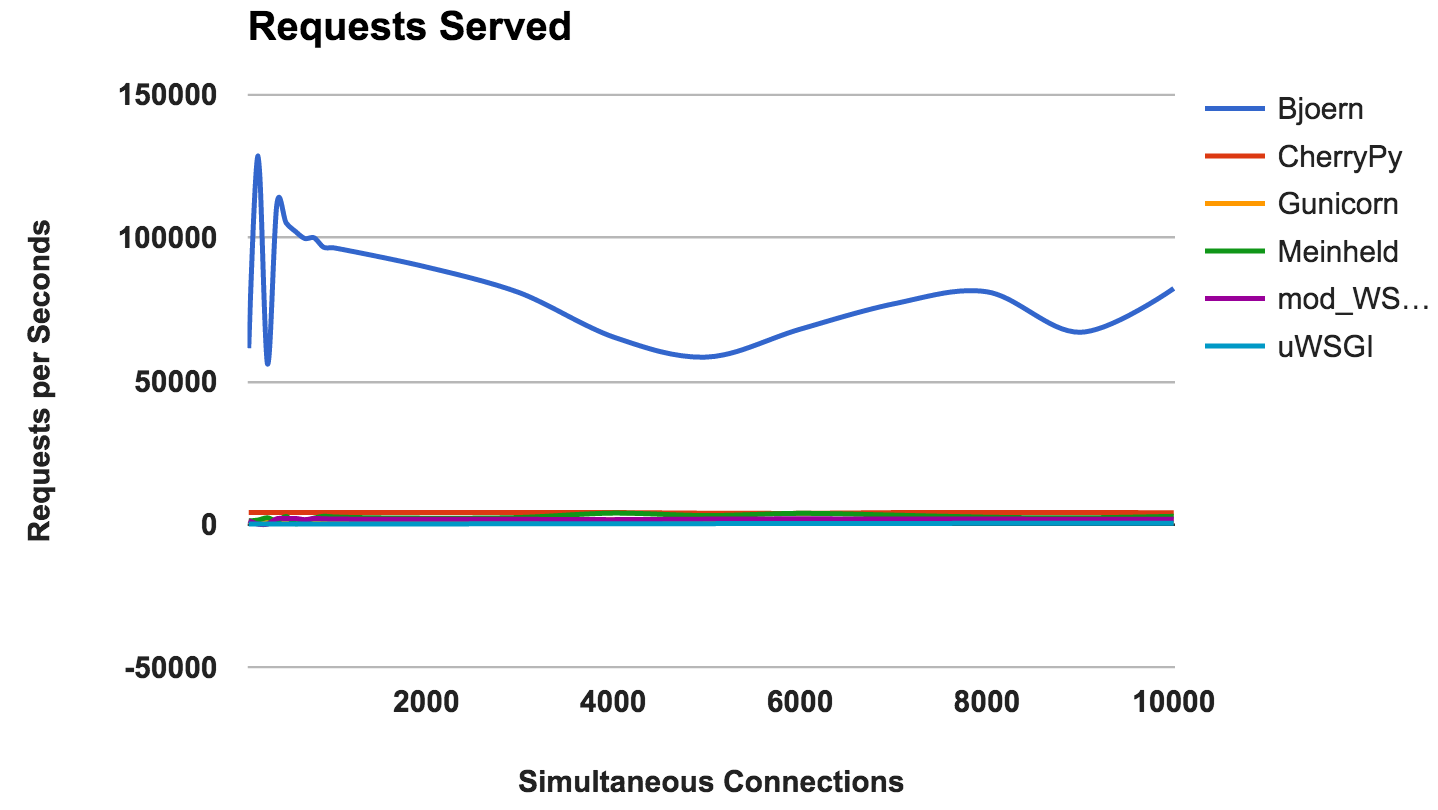
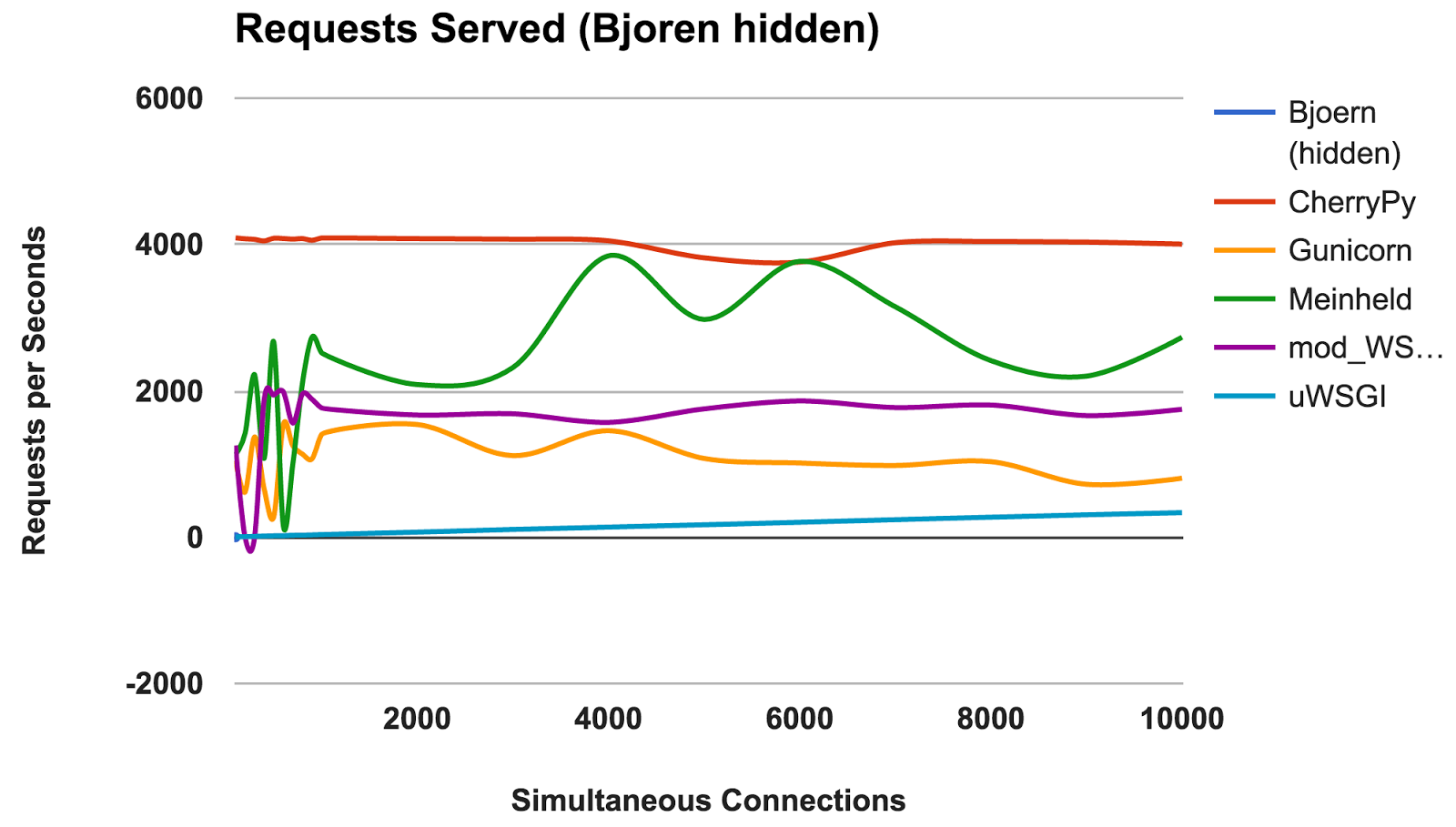
- Bjoern: Un gagnant clair.
- CherryPy: Bien qu'il soit écrit en pur Python, il était le meilleur interprète.
- Meinheld: Excellentes performances compte tenu des ressources limitées des conteneurs.
- mod_wsgi: Pas le plus rapide, mais les performances étaient cohérentes et adéquates.
- Gunicorn: Bonnes performances à faibles charges, mais il y a un combat avec un grand nombre de connexions.
- uWSGI: Frustré avec de mauvais résultats.
VAINQUEUR: BjoernBjoern
Par le nombre de demandes constantes,
Bjoern est clairement le gagnant. Cependant, étant donné que les chiffres sont beaucoup plus élevés que ceux des concurrents, nous sommes un peu sceptiques. Nous ne sommes pas sûrs que
Bjoern soit vraiment incroyablement rapide. Au début, nous avons testé les serveurs par ordre alphabétique et nous pensions que
Bjoern avait un avantage injuste. Cependant, même après le démarrage des serveurs dans un ordre de serveur aléatoire et un nouveau test, le résultat reste le même.
uWSGI
Nous avons été déçus par les faibles résultats de l'
uWSGI . Nous nous attendions à ce qu'il soit en tête. Lors des tests, nous avons remarqué que les journaux
uWSGI s'imprimaient à l'écran, et nous avons initialement expliqué le manque de performances avec le travail supplémentaire effectué par le serveur. Cependant, même après que l'
option «
--disable-logging » a été ajoutée,
uWSGI est toujours le serveur le plus lent.
Comme mentionné dans le manuel
uWSGI , il s'interface généralement avec un serveur proxy tel que Nginx. Cependant, nous ne sommes pas sûrs que cela puisse expliquer une si grande différence.
Retard
Le délai est le temps écoulé entre la demande et sa réponse. Les nombres inférieurs sont meilleurs.
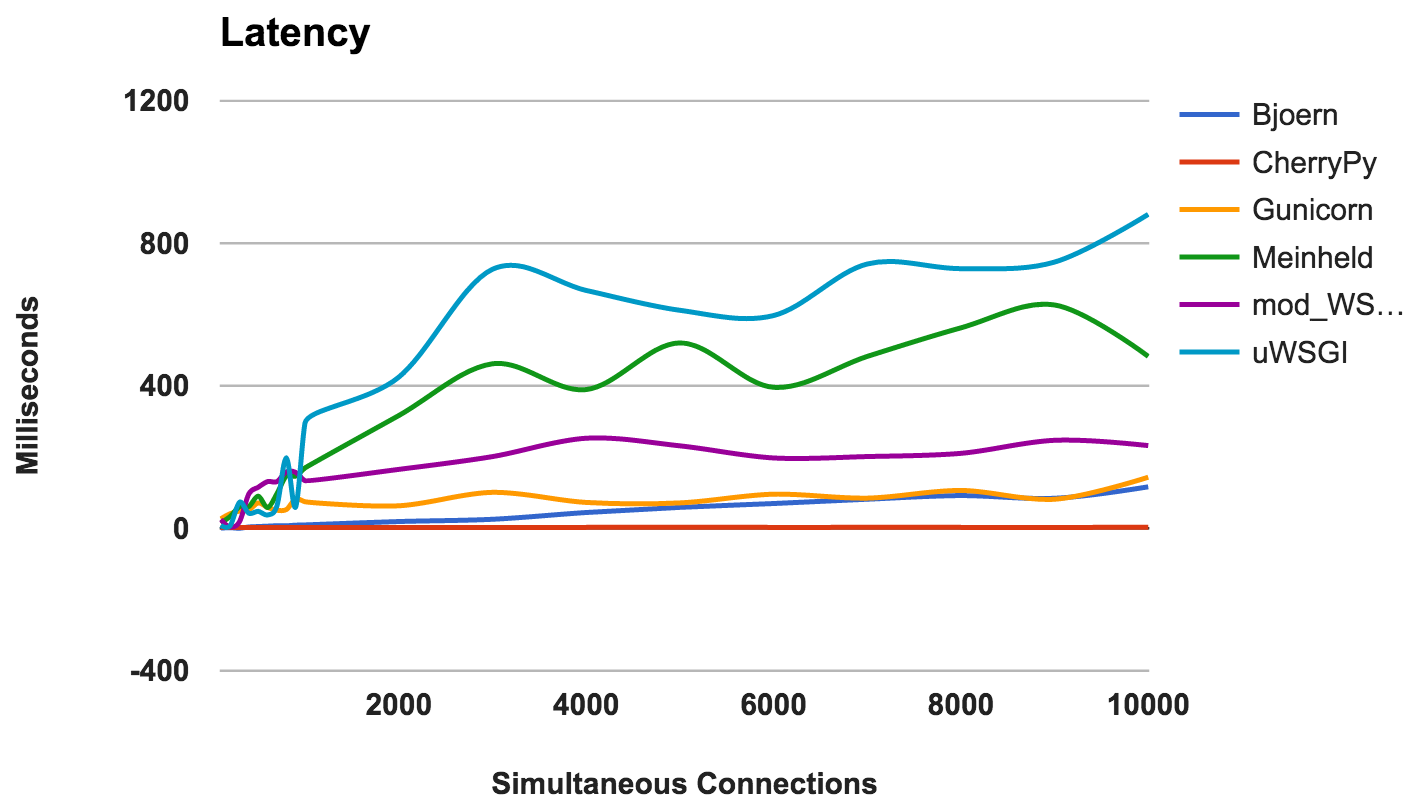
- CherryPy: Bien géré la charge.
- Bjoern: Latence généralement faible, mais fonctionne mieux avec moins de connexions simultanées.
- Gunicorn: bon et cohérent.
- mod_wsgi: performances moyennes, même avec un grand nombre de connexions simultanées.
- Meinheld: Performance globale acceptable.
- uWSGI: uWSGI est à nouveau à la dernière place.
GAGNANT: CherryPyUtilisation de la RAM
Cette métrique montre les besoins en mémoire et la «légèreté» de chaque serveur. Les nombres inférieurs sont meilleurs.
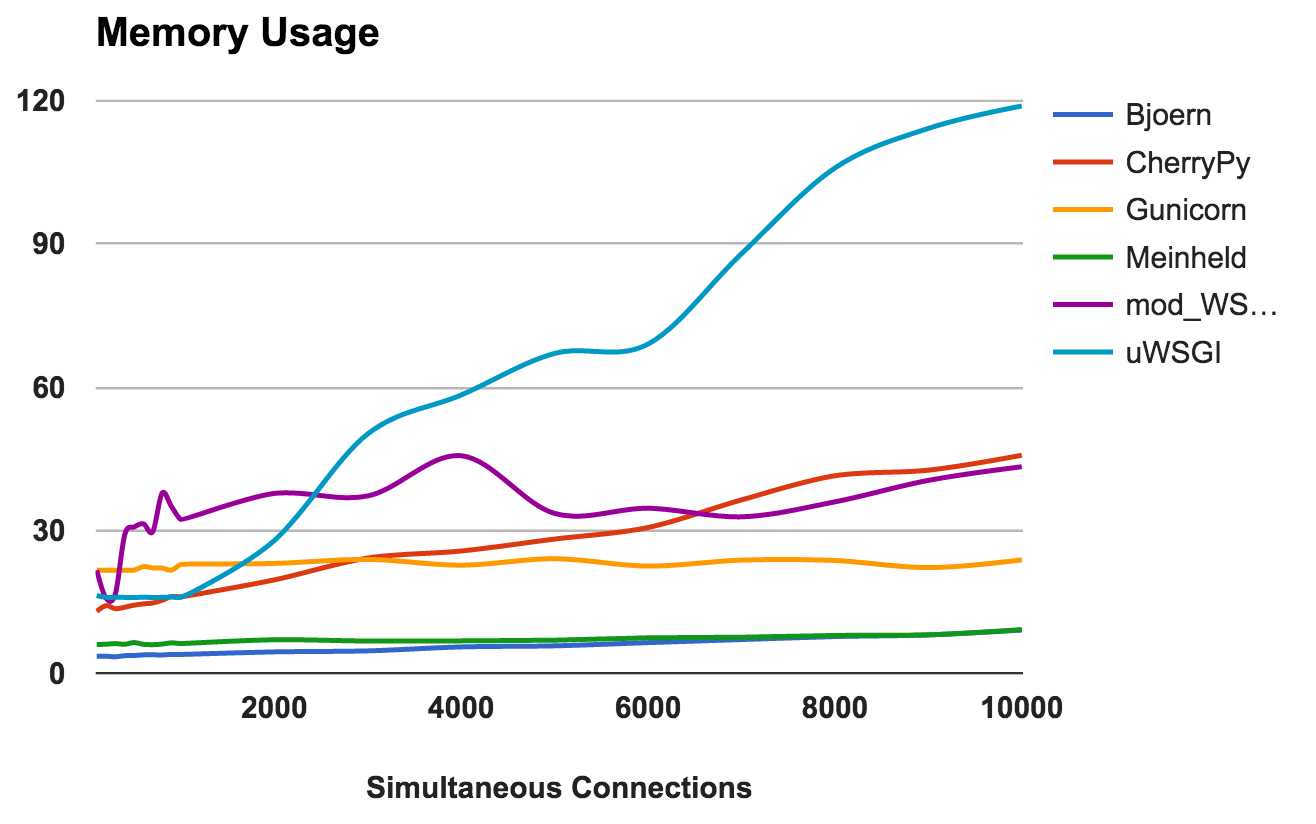
- Bjoern: Extrêmement léger. Il utilise seulement 9 Mo de RAM pour traiter 10 000 requêtes simultanées.
- Meinheld: Identique à Bjoern .
- Gunicorn: adapte habilement les charges élevées avec une consommation de mémoire à peine perceptible.
- CherryPy: Initialement, il avait besoin d'une petite quantité de RAM, mais son utilisation a augmenté rapidement avec l'augmentation de la charge.
- mod_wsgi: Aux niveaux inférieurs, c'était l'un des plus intenses en mémoire, mais il est resté assez cohérent.
- uWSGI: Évidemment, la version que nous testons a des problèmes avec la quantité de mémoire consommée.
GAGNANTS: Bjoern et MeinheldNombre d'erreurs
Une erreur se produit lorsque le serveur se bloque, est interrompu ou que la demande expire. Le plus bas sera le mieux.
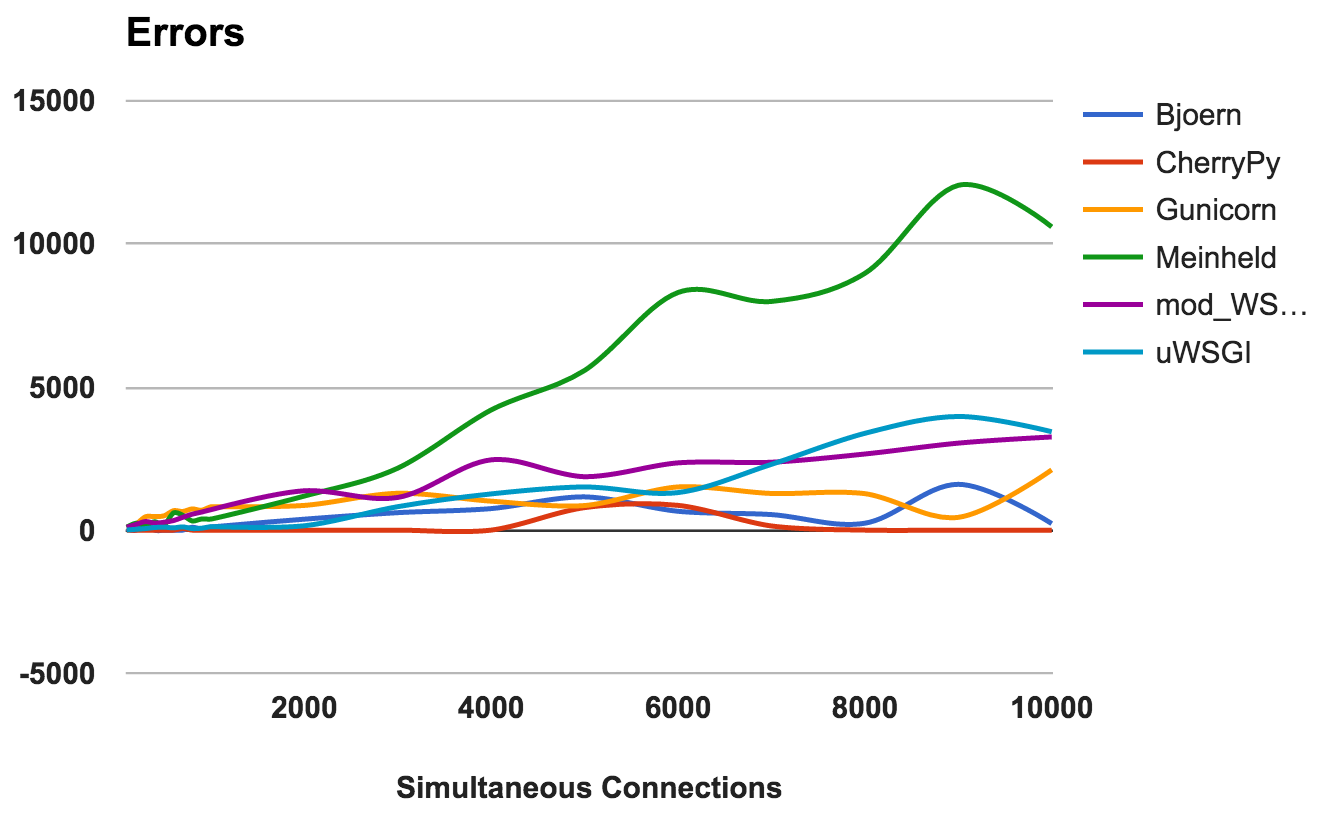
Pour chaque serveur, nous avons calculé le ratio du ratio total du nombre de requêtes sur le nombre d'erreurs:
- CherryPy: taux d'erreur autour de 0, même avec un nombre élevé de connexions.
- Bjoern: Des erreurs se sont produites, mais cela a été compensé par le nombre de demandes traitées.
- mod_wsgi: Fonctionne bien avec un taux d'erreur acceptable de 6%.
- Gunicorn: Fonctionne avec un taux d'erreur de 9%.
- uWSGI: Compte tenu du faible nombre de demandes traitées, il s'est retrouvé avec un taux d'erreur de 34%.
- Meinheld: est tombé à des charges plus élevées, provoquant plus de 10 000 erreurs lors du test le plus exigeant.
GAGNANT: CherryPyUtilisation du processeur
Une utilisation élevée du processeur n'est ni bonne ni mauvaise si le serveur fonctionne bien. Cependant, cela fournit des informations intéressantes sur le serveur. Étant donné que deux cœurs de processeur ont été utilisés, l'utilisation maximale possible est de 200%.
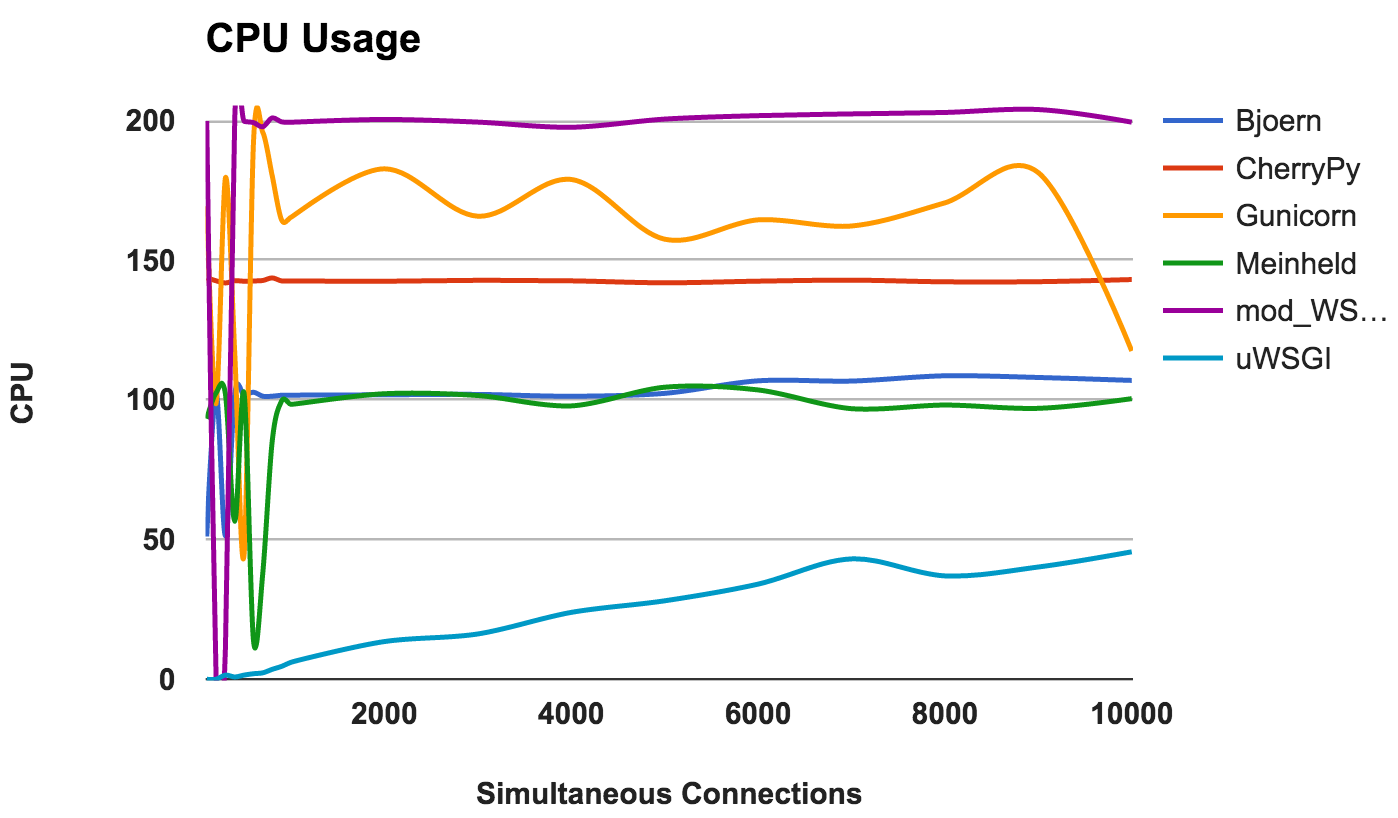
- Bjoern: un serveur à thread unique, comme en témoigne son utilisation cohérente de 100% CPU.
- CherryPy: multithread, mais bloqué à 150%. Cela peut être dû à Python GIL .
- Gunicorn: utilise plusieurs processus avec une utilisation complète des ressources CPU à des niveaux inférieurs.
- Meinheld: un serveur à thread unique utilisant des ressources CPU comme Bjoern.
- mod_wsgi: un serveur multi-thread utilisant tous les cœurs de CPU à travers toutes les mesures
- uWSGI: très faible utilisation du CPU. La consommation du processeur ne dépasse pas 50%. Ceci est une preuve que uWSGI n'est pas configuré correctement.
GAGNANT: Non, car il s'agit plus d'une observation de comportement que d'une comparaison de performances.Conclusion
Pour résumer! Voici quelques idées générales que vous pouvez tirer des résultats de chaque serveur:
- Bjoern: se justifie comme un «serveur WSGI ultra-rapide et ultra-léger».
- CherryPy: hautes performances, faible consommation de mémoire et faibles taux d'erreur. Pas mal pour du pur Python.
- Gunicorn: Un bon serveur pour des charges moyennes.
- Meinheld: Fonctionne bien et nécessite un minimum de ressources. Cependant, aux prises avec des charges plus élevées.
- mod_wsgi: S'intègre à Apache et fonctionne très bien.
- uWSGI: Très déçu. Soit nous avons configuré uWSGI de manière incorrecte, soit la version que nous avons installée contient des erreurs de base.