En septembre, le sixième Hyperbaton a eu lieu - la conférence Yandex sur tout ce qui concerne la documentation technique. Nous publierons plusieurs conférences d'Hyperbaton qui, à notre avis, pourraient intéresser le plus les lecteurs de Habr.
Svetlana Kayushina, chef du service documentation et localisation:
- Il semble que dans le monde il n'y ait plus de personnes qui traduisent manuellement. Aujourd'hui, nous voulons parler d'outils et d'approches qui aident les entreprises à organiser un processus de localisation efficace, et les traducteurs facilitent la résolution de leurs problèmes quotidiens. Aujourd'hui, nous allons parler de la traduction automatique, de l'évaluation de l'efficacité des moteurs de machine et des systèmes de traduction automatisés pour les traducteurs.
Commençons par le rapport de nos collègues. J'invite Irina Rybnikova et Anastasia Ponomareva - elles parleront de l'expérience de Yandex dans l'introduction de la traduction automatique dans nos processus de localisation.
Irina Rybnikova:
- Merci. Nous vous expliquerons l'historique de la traduction automatique et comment nous l'utilisons dans Yandex.

Au 17e siècle, les scientifiques pensaient à l'existence d'une langue qui relie d'autres langues, et c'est probablement trop long. Revenons plus près. Nous voulons tous comprendre les gens qui nous entourent - peu importe d'où nous venons - nous voulons voir ce qui est écrit sur les panneaux, nous voulons lire les annonces, les informations sur les concerts. L'idée du poisson babylonien sillonne l'esprit des scientifiques, se retrouve partout dans la littérature, le cinéma. Nous voulons réduire le temps pendant lequel nous avons accès à l'information. Nous voulons lire des articles sur les technologies chinoises, comprendre tous les sites que nous voyons et vouloir les obtenir ici et maintenant.

Dans ce contexte, il est impossible de ne pas parler de traduction automatique. C'est ce qui aide à résoudre ce problème.

Le point de départ est 1954, lorsque 60 phrases sur le sujet général de la chimie organique ont été traduites du russe vers l'anglais aux États-Unis sur une machine IBM 701, et tout cela était basé sur 250 termes de glossaire et six règles grammaticales. Cela s'appelait l'expérience de Georgetown, et c'était tellement choquant que les journaux étaient pleins de gros titres que pendant encore trois à cinq ans, et le problème sera complètement résolu, tout le monde sera heureux. Mais comme vous le savez, tout s'est un peu différent.
Dans les années 70, la traduction automatique basée sur des règles est apparue. Il était également basé sur des dictionnaires bilingues, mais aussi sur ces mêmes ensembles de règles qui aidaient à décrire n'importe quelle langue. Tout, mais avec des limitations.

Des experts linguistiques sérieux qui fixaient les règles étaient nécessaires. C'est un travail assez compliqué, il ne pouvait toujours pas prendre en compte le contexte, couvrir complètement n'importe quelle langue, mais ils étaient experts, et puis une puissance de calcul élevée n'était pas requise.

Si nous parlons de qualité, un exemple classique est une citation de la Bible, qui a ensuite été traduite comme ceci. Pas encore assez. Par conséquent, les gens ont continué à travailler sur la qualité. Dans les années 90, un modèle de traduction statistique, SMT, est apparu, qui parlait de la distribution probabiliste des mots et des phrases, et ce système était fondamentalement différent en ce qu'il ne savait rien du tout des règles et de la linguistique. Elle a reçu une énorme quantité de textes identiques, jumelés dans une langue et une autre, puis a pris elle-même les décisions. Il était facile à entretenir, aucun tas d'experts n'était nécessaire, aucune attente. Vous pouvez télécharger et obtenir le résultat.

Les besoins en données entrantes étaient assez moyens, de 1 à 10 millions de segments. Segments - phrases, petites phrases. Mais leurs difficultés persistent et le contexte n'est pas pris en compte, tout n'est pas très facile. Et en Russie, par exemple, de tels cas sont apparus.

J'aime aussi l'exemple de la traduction de jeux GTA, le résultat était super. Tout ne s'est pas arrêté. 2016 a été une étape importante lorsque la traduction automatique de neurones a commencé. C'était un événement plutôt marquant qui a profondément changé la vie. Mon collègue, après avoir regardé les traductions et comment nous les utilisons, a déclaré: "Cool, il parle avec mes mots." Et c'était vraiment super.
Quelles fonctionnalités? Exigences d'entrée élevées, matériel de formation. Il est difficile à maintenir au sein de l'entreprise, mais une augmentation significative de la qualité est ce pour quoi il a été conçu. Seule une traduction de haute qualité résoudra les tâches et facilitera la vie de tous les participants au processus, les mêmes traducteurs qui ne veulent pas corriger une mauvaise traduction, ils veulent faire de nouvelles tâches créatives et donner des phrases de routine à la machine.
Il existe deux approches de la traduction automatique. Expertise / analyse linguistique des textes, c'est-à-dire vérification par de vrais linguistes, experts du respect du sens, alphabétisation de la langue. Dans certains cas, des experts étaient encore plantés, ils étaient autorisés à soustraire le texte traduit et à évaluer son efficacité de ce point de vue.

Quelles sont les caractéristiques de cette méthode? Aucun exemple de traduction n'est requis, nous examinons maintenant le texte traduit fini et l'évaluons objectivement pour n'importe quelle section. Mais c'est cher et long.

Il existe une deuxième approche - les mesures de référence automatiques. Il y en a beaucoup, chacun a ses avantages et ses inconvénients. Je n'irai pas plus loin. Vous pourrez en savoir plus sur ces mots clés plus tard.
Quelle fonctionnalité? En fait, il s'agit d'une comparaison de textes traduits automatiquement avec une traduction exemplaire. Ce sont des mesures quantitatives qui montrent l'écart entre la traduction exemplaire et ce qui s'est passé. C'est rapide, bon marché et peut être fait très facilement. Mais il y a des fonctionnalités.

En fait, le plus souvent, ils utilisent des méthodes hybrides. C'est lorsque quelque chose est automatiquement évalué initialement, puis une matrice d'erreur est analysée, puis une analyse linguistique experte est effectuée sur un corps de textes plus petit.

Récemment, la pratique est encore très répandue quand on n'y appelle pas des linguistes, mais simplement des utilisateurs. Une interface est en cours de création - montrez quelle traduction vous préférez. Ou lorsque vous accédez à des traducteurs en ligne, vous saisissez du texte et vous pouvez souvent voter sur ce que vous préférez, que cette approche soit appropriée ou non. En fait, nous formons tous maintenant ces moteurs, et ils utilisent tout pour s'entraîner pour s'entraîner et travailler sur leur qualité.
Je voudrais dire comment nous utilisons la traduction automatique dans notre travail. Je passe le mot à Anastasia.
Anastasia Ponomareva:
- Chez Yandex dans le département de localisation, nous avons réalisé assez rapidement que la technologie de traduction automatique a un grand potentiel, et avons décidé d'essayer de l'utiliser dans nos tâches quotidiennes. Par où avons-nous commencé? Nous avons décidé de mener une petite expérience. Nous avons décidé de traduire les mêmes textes par le biais d'un traducteur de réseau de neurones régulier et d'assembler également un traducteur automatique qualifié. Pour ce faire, nous avons préparé un corpus de textes dans une paire de russe-anglais pour les années où nous, à Yandex, nous étions engagés dans la localisation de textes dans ces langues. Ensuite, nous sommes venus avec ce corpus de textes à nos collègues de Yandex.Translate et avons demandé à former le moteur.

Lorsque le moteur a été formé, nous avons traduit le prochain lot de textes et, comme l'a dit Irina, avec l'aide d'experts, nous avons évalué les résultats. Nous avons demandé aux traducteurs d'étudier l'alphabétisation, le style, l'orthographe et la transmission du sens. Mais le tournant a été lorsque l'un des traducteurs a dit: "Je reconnais mon style, je reconnais mes traductions".
Pour renforcer ces sensations, nous avons décidé de calculer les indicateurs statistiques. Tout d'abord, nous avons calculé le coefficient BLEU pour les transferts effectués via un moteur de réseau neuronal régulier, et nous avons obtenu ce chiffre (0,34). Il semblerait que cela doive être comparé à quelque chose. Nous sommes à nouveau allés voir des collègues de Yandex.Translator et avons demandé d'expliquer quel coefficient BLEU est considéré comme seuil pour les transferts effectués par une personne réelle. C'est de 0,6.
Ensuite, nous avons décidé de vérifier les résultats des traductions formées. Got 0.5. Les résultats sont vraiment encourageants.

Je donne un exemple. Ceci est une véritable phrase russe de la documentation de Direct. Ensuite, il a été transféré via un moteur de réseau neuronal régulier, puis via un moteur de réseau neuronal formé dans nos textes. Déjà dans la toute première ligne, nous remarquons que le type traditionnel de publicité pour Direct n'est pas reconnu. Et déjà dans le moteur de réseau neuronal formé, notre traduction apparaît, et même l'abréviation est presque correcte.
Nous avons été très encouragés par les résultats et avons décidé qu'il valait probablement la peine d'utiliser le moteur dans d'autres paires, dans d'autres textes, pas seulement sur cet ensemble de base de documentation technique. Une série d'expériences a été réalisée pendant plusieurs mois. Face à de nombreuses fonctionnalités et problèmes, ce sont les problèmes les plus courants que nous avons dû résoudre.

Je vais vous en dire plus sur chacun.

Si vous, comme nous, envisagez de créer un moteur personnalisé, vous aurez besoin d'une quantité assez importante de données parallèles de haute qualité. Le gros moteur peut être formé sur le montant de 10 000 offres, dans notre cas, nous avons préparé 135 000 offres parallèles.

Pas sur tous les types de texte, votre moteur affichera des résultats tout aussi bons. Dans la documentation technique, où il y a de longues phrases, la structure, la documentation utilisateur, et même dans l'interface, où il y a des boutons courts mais clairs, vous irez très probablement bien. Mais peut-être, comme chez nous, vous rencontrerez des problèmes de marketing.
Nous avons mené une expérience, traduit des listes de lecture de musique, et obtenu un tel exemple.

C'est ce que pense un traducteur automatique des ouvriers d'usine. Quels sont les batteurs du travail.

Lors de la traduction via un moteur de machine, le contexte n'est pas pris en compte. Ce n'est plus un exemple aussi ridicule, mais bien réel, de la documentation technique de Yandex.Direct. Il semblerait que ceux-ci soient compréhensibles lorsque vous lisez la documentation technique, ce sont les aspects techniques. Mais non, le moteur n'a pas touché.

Vous devez également considérer que la qualité et le sens de la traduction dépendront largement de la langue d'origine. Nous traduisons la phrase en français du russe, nous obtenons un résultat. Nous obtenons une phrase similaire avec la même signification, mais de l'anglais, et nous obtenons un résultat différent.

Si vous, comme dans notre texte, avez un grand nombre de balises, de balisage, de certaines fonctionnalités techniques, vous devrez très probablement les suivre, éditer et écrire certains scripts.
Voici des exemples de phrases réelles provenant du navigateur. Entre parenthèses se trouvent des informations techniques qui ne doivent pas être traduites, en particulier des formulaires multiples. En anglais, ils sont en anglais et en allemand, ils doivent également rester en anglais, mais ils sont traduits. Vous devrez garder une trace de ces points.
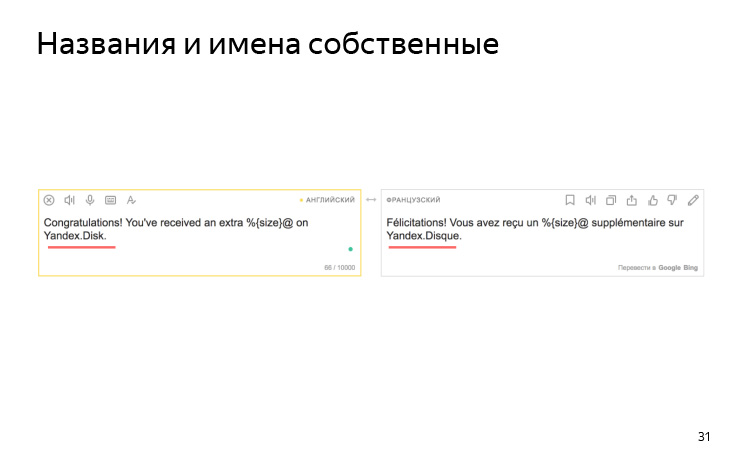
Le moteur ne sait rien de vos conventions de dénomination. Par exemple, nous avons un accord que nous appelons toujours Yandex.Disk en latin dans toutes les langues. Mais en français, il se transforme en disque en français.

Les abréviations sont parfois reconnues correctement, parfois non. Dans cet exemple, BY, indiquant l'appartenance aux exigences techniques biélorusses pour la publicité, se transforme en excuse en anglais.

Un de mes exemples préférés est les mots nouveaux et empruntés. Voici un exemple sympa, le mot de non-responsabilité, "essentiellement russe". La terminologie devra être vérifiée pour chaque partie du texte.
Et un problème de plus, pas si important - une écriture obsolète.

Auparavant, Internet était une nouveauté, il était capitalisé dans tous les textes, et lorsque nous formions notre moteur, partout Internet était capitalisé. C'est maintenant une nouvelle ère, Internet s'écrit déjà avec une petite lettre. Si vous voulez que votre moteur continue à écrire sur Internet avec une petite lettre, vous devrez le recycler.

Nous n'avons pas désespéré, résolu ces problèmes. D'abord, ils ont changé le corps des textes, ont essayé de traduire sur d'autres sujets. Nous avons transmis nos commentaires à des collègues de Yandex.Translator, re-formé le réseau neuronal et examiné les résultats, évalué et demandé de finaliser. Par exemple, la reconnaissance des balises, le traitement du balisage HTML.
Je vais montrer des cas d'utilisation réels. Nous avons une bonne traduction automatique pour la documentation technique. Ceci est un vrai cas.

Voici la phrase en anglais et en russe. Le traducteur qui a traité cette documentation a été très encouragé par le choix approprié de la terminologie. Un autre exemple.

Le traducteur a apprécié que le choix soit au lieu du tiret, que la structure de la phrase ait changé en anglais, un choix adéquat du terme qui est correct et du mot vous, qui n'est pas dans l'original, mais cela rend cette traduction exactement anglaise, naturelle.

Un autre cas est la traduction des interfaces à la volée. L'un des services a décidé de ne pas se soucier de la localisation et de traduire les textes directement au démarrage. Mais après avoir changé le moteur environ une fois par mois, le mot «livraison» a changé en cercle. Nous avons suggéré que l'équipe ne connecte pas un moteur de réseau neuronal ordinaire, mais le nôtre, formé sur la documentation technique, afin que le même terme soit toujours utilisé, convenu avec l'équipe qui est déjà dans la documentation.

Comment tout cela fonctionne-t-il pendant un moment monétaire? À l'origine, il s'est avéré qu'une paire de russe-ukrainien nécessite une révision minimale de la traduction ukrainienne. Par conséquent, il y a quelques mois, nous avons décidé de passer à un système de post-édition. C'est ainsi que nos économies augmentent. Septembre n'est pas encore terminé, mais nous avons pensé que nous avions réduit nos coûts de post-édition d'environ un tiers en ukrainien, et nous allons éditer presque tout sauf les textes marketing. Le mot Irina pour résumer.
Irina:
- Pour tout le monde, il devient évident qu'il faut l'utiliser, c'est déjà notre réalité, et il est impossible de l'exclure de nos processus et intérêts. Mais vous devez penser à quelques choses.

Décidez des types de documents, du contexte dans lequel vous travaillez. Cette technologie vous convient-elle?
Deuxième moment. Nous avons parlé de Yandex.Translator, parce que nous sommes dans une bonne relation, nous avons un accès direct aux développeurs, etc., mais en fait, vous devez décider quel moteur sera le plus optimal pour vous spécifiquement, pour votre langue, votre sujet. Le
prochain rapport sera consacré à ce sujet. Soyez prêt qu'il y a encore des difficultés, les développeurs des moteurs travaillent ensemble pour résoudre les difficultés, mais jusqu'à présent, ils se rencontrent toujours.

Je voudrais comprendre ce qui nous attend à l'avenir. Mais en fait, ce n'est pas plus loin, mais notre heure actuelle, ce qui se passe ici et maintenant. Nous avons tous plutôt besoin d'une personnalisation de notre terminologie, de nos textes, et c'est ce qui devient maintenant public. Maintenant, tout le monde travaille pour s'assurer que vous n'entrez pas dans l'entreprise, ne soyez pas d'accord avec les développeurs d'un moteur particulier, comment l'optimiser pour vous. Vous pourrez le recevoir dans des moteurs ouverts publics sur API.
La personnalisation n'est pas seulement dans les textes, mais aussi dans la terminologie, pour configurer la terminologie pour vos propres besoins. Ceci est un point important. Le deuxième sujet est la traduction interactive. Lorsqu'un traducteur traduit un texte, la technologie lui permet de prédire les mots suivants en tenant compte de la langue source, le texte source. Cette tarière peut grandement faciliter le travail.
C'est maintenant vraiment cher. Tout le monde pense comment enseigner certains moteurs beaucoup moins efficacement avec moins de texte. C'est ce qui se passe partout et fonctionne partout. Je pense que le sujet est très intéressant, et ce sera encore plus intéressant.
Nous avons rassemblé plusieurs articles qui pourraient vous intéresser. Je vous remercie!
-
Deux modèles valent mieux qu'un. Expérience de Yandex.Translator-
Comment Yandex a appliqué la technologie d'intelligence artificielle pour traduire des pages Web-
Traduction automatique. De la guerre froide à la diplomatie