Remarque perev. : L'article original a été écrit par un rédacteur technique de Google, travaillant sur la documentation pour Kubernetes (Andrew Chen), et directeur de l'ingénierie logicielle de SAP (Dominik Tornow). Son objectif est d'expliquer clairement et clairement les bases de l'organisation et de la mise en œuvre de la haute disponibilité dans Kubernetes. Il nous semble que les auteurs ont réussi, nous sommes donc heureux de partager la traduction.
Kubernetes est un moteur d'orchestration de conteneurs conçu pour exécuter des applications conteneurisées sur plusieurs nœuds, communément appelés cluster. Dans ces publications, nous utilisons une approche de modélisation des systèmes pour améliorer la compréhension de Kubernetes et de ses concepts sous-jacents. Les lecteurs sont encouragés à avoir déjà une compréhension de base de Kubernetes.
Kubernetes est un moteur d'orchestration de conteneurs évolutif et fiable. L'évolutivité est ici déterminée par la réactivité en présence de charge, et la fiabilité est déterminée par la réactivité en présence de pannes.
Notez que l'évolutivité et la fiabilité de Kubernetes ne signifient pas l'évolutivité et la fiabilité de l'application qui y est exécutée. Kubernetes est une plate-forme évolutive et fiable, mais chaque application K8 n'a pas encore franchi certaines étapes pour en devenir une et éviter les goulots d'étranglement et les points de défaillance uniques.
Par exemple, si l'application est déployée en tant que ReplicaSet ou Deployment, Kubernetes (re) planifie et (re) lance des pods affectés par des plantages de nœuds. Cependant, si l'application est déployée en tant que pod, Kubernetes ne prendra aucune mesure en cas de défaillance d'un nœud. Par conséquent, bien que Kubernetes lui-même reste opérationnel, la réactivité de votre application dépend de l'architecture choisie et des décisions de déploiement.
Cette publication se concentre sur la fiabilité de Kubernetes. Elle explique comment Kubernetes maintient sa réactivité en présence d'échecs.
Architecture de Kubernetes
 Schéma 1. Maître et travailleur
Schéma 1. Maître et travailleurAu niveau conceptuel, les composants Kubernetes sont regroupés en deux classes distinctes: les composants
Master et les composants
Worker .
Les maîtres sont chargés de tout gérer sauf l'exécution des foyers. Les composants de l'assistant incluent:
Les travailleurs sont responsables de la gestion de l'exécution des foyers. Ils ont un composant:
Les travailleurs sont d'une fiabilité triviale: une défaillance temporaire ou permanente de tout travailleur dans un cluster n'affecte pas le maître ou les autres travailleurs du cluster. Si l'application est déployée correctement, Kubernetes (re) planifie et (re) lance toute personne affectée par l'échec du travailleur.
Configuration d'un assistant unique
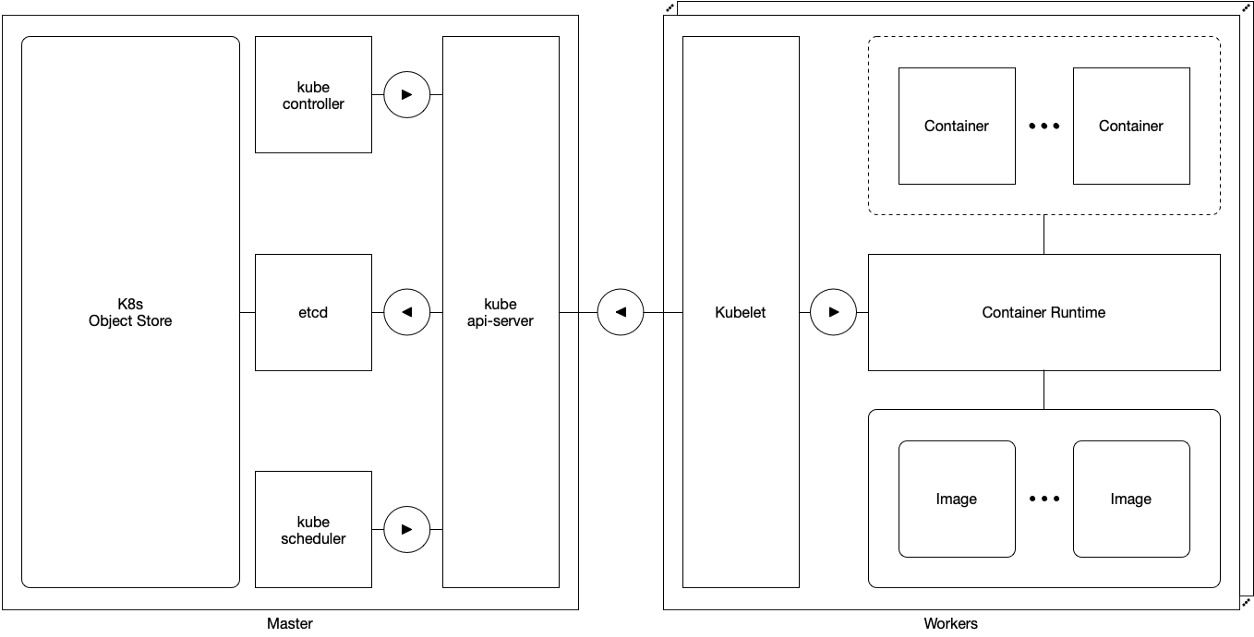 Schéma 2. Configuration avec un seul maître
Schéma 2. Configuration avec un seul maîtreDans une configuration à maître unique, le cluster Kubernetes se compose d'un maître et de plusieurs travailleurs. Ces derniers sont directement connectés à l'assistant kube-apiserver et interagissent avec lui.
Dans cette configuration, la réactivité de Kubernetes dépend:
- le seul maître
- connecter les travailleurs à un seul maître.
Étant donné que le seul maître est un point de défaillance unique, cette configuration n'appartient pas à la catégorie de haute disponibilité.
Configuration multi-assistant
 Schéma 3. Configuration avec de nombreux maîtres
Schéma 3. Configuration avec de nombreux maîtresDans une configuration multi-maîtres, le cluster Kubernetes est composé de nombreux maîtres et de nombreux travailleurs. Les travailleurs se connectent à n'importe quel serveur kube-apiserver et interagissent avec lui via un équilibreur de charge hautement accessible.
Dans cette configuration, Kubernetes
est indépendant de:
- le seul maître
- connecter les travailleurs à un seul maître.
Comme il n'y a pas de point de défaillance unique dans cette configuration, elle est considérée comme hautement accessible.
Leader et suiveur à Kubernetes
Dans une configuration multi-assistant, de nombreux gestionnaires de contrôleurs de kube et programmateurs de kube sont impliqués. Si deux composants modifient les mêmes objets, des conflits peuvent survenir.
Afin d'éviter des conflits potentiels, pour kube-controller-manager et kube-scheduler Kubernetes implémente le modèle "
maître-esclave "
(leader / suiveur) . Chaque groupe choisit un leader
(ou leader) et les autres membres du groupe jouent le rôle d'adeptes. À un moment donné, un seul chef est actif et les suiveurs sont passifs.
 Figure 4. Assistant de composant de déploiement redondant en détail
Figure 4. Assistant de composant de déploiement redondant en détailCette illustration montre un exemple détaillé dans lequel kube-controller-1 et kube-scheduler-2 sont en tête parmi les kube-controller-managers et kube-schedulers. Étant donné que chaque groupe choisit son propre chef, ils ne doivent pas du tout être sur le même maître.
Sélection de leads
Un nouveau leader est sélectionné par les membres du groupe au moment du lancement ou en cas de chute d'un leader. Lead - un membre avec le soi-disant
bail de leader (actuellement le statut de leader «loué»).
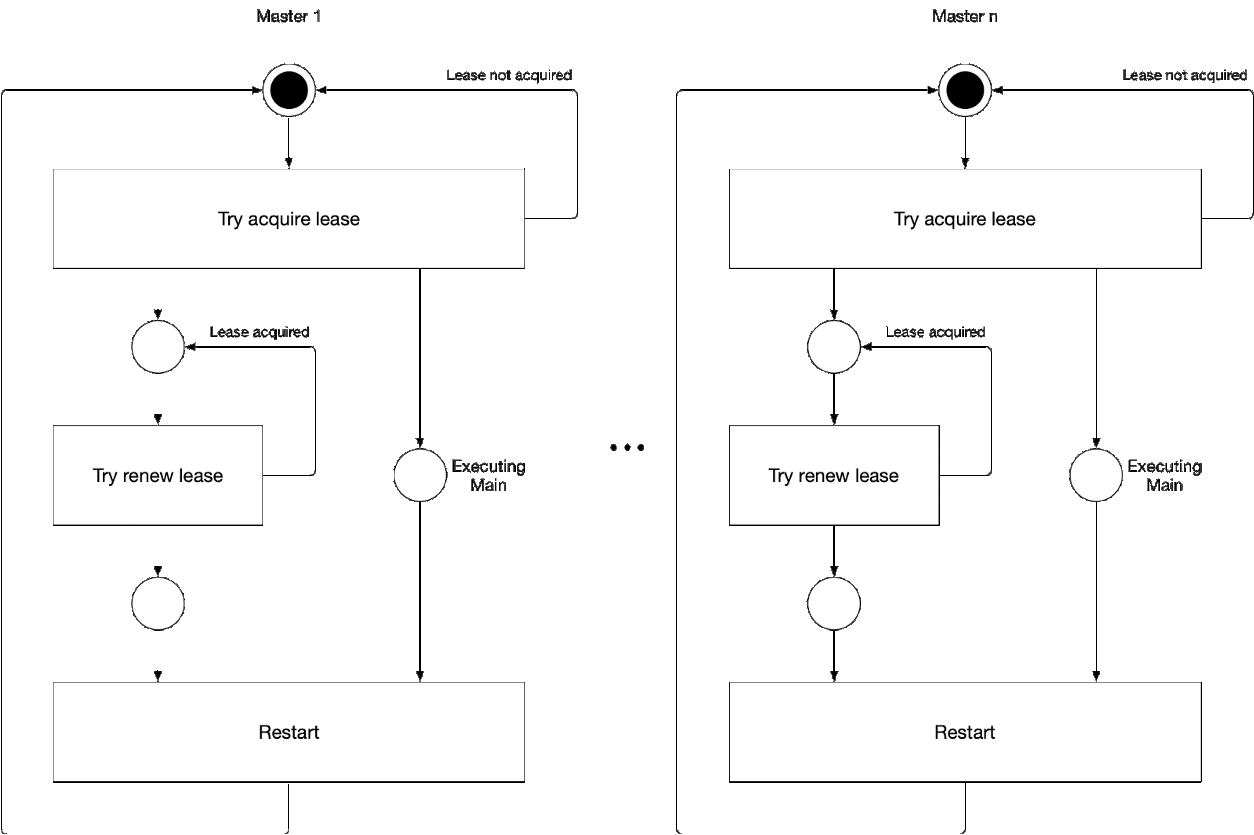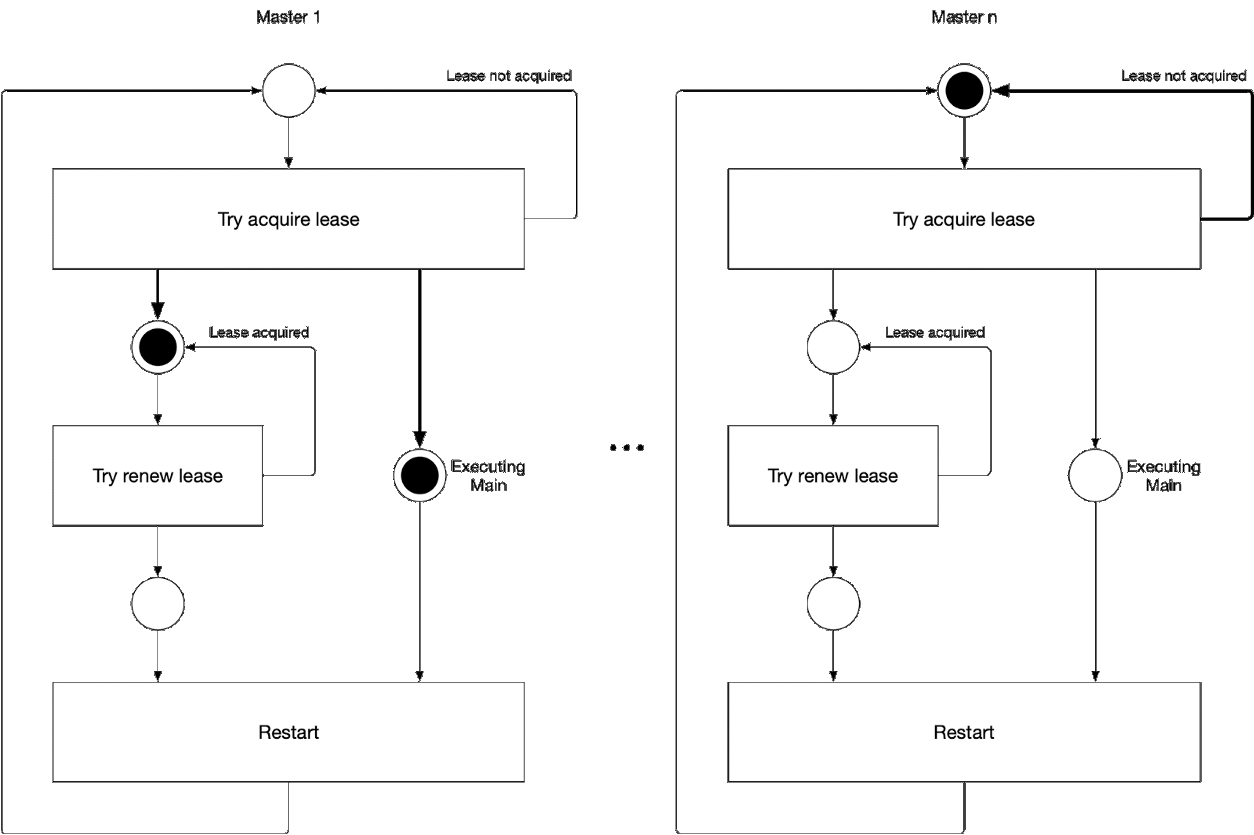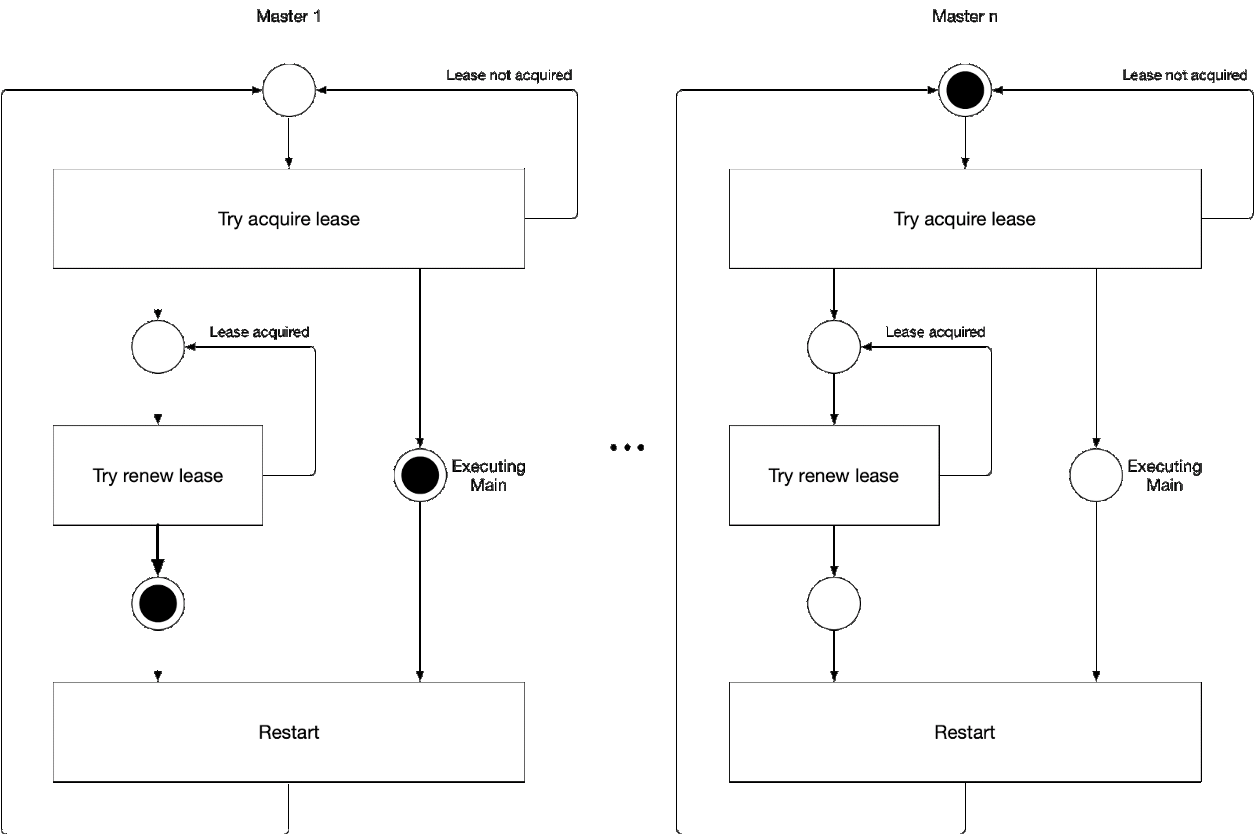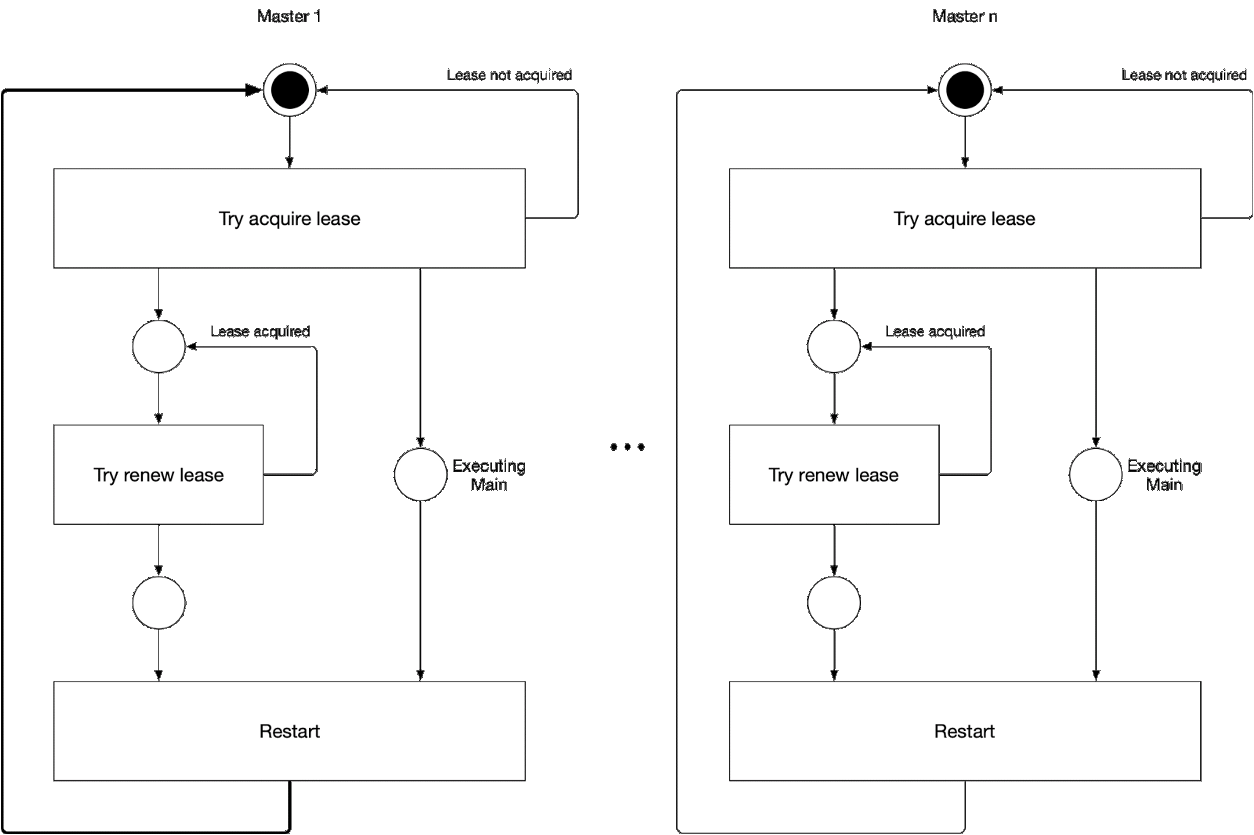 Diagramme 5. Processus de sélection du composant maître de l'assistant
Diagramme 5. Processus de sélection du composant maître de l'assistantCette illustration illustre le processus de sélection principal pour kube-controller-manager et kube-scheduler. La logique de ce processus est la suivante:
' ' , :
-
-
' ' , :
- leader lease
-
- holderIdentity 'self'Suivi principal
Les statuts de leader actuels pour kube-controller-manager et kube-scheduler sont stockés en permanence dans le stockage d'objets Kubernetes en tant
qu'objets de noeuds finaux dans l'espace de noms
kube-system . Étant donné que deux objets Kubernetes ne peuvent pas avoir le même nom, le type
(kind) et l'espace de noms en même temps, il ne peut y avoir qu'un seul
point de
terminaison pour kube-scheduler et pour kube-controller-manager.
Démo utilisant l'
kubectl console
kubectl :
$ kubectl get endpoints -n kube-system NAME ENDPOINTS AGE kube-scheduler <none> 30m kube-controller-manager <none> 30m
Le kube-scheduler et le kube-controller-manager du
point de
terminaison stockent les informations de leader dans l'annotation
control-plane.alpha.kubernetes.io/leader :
$ kubectl describe endpoints kube-scheduler -n kube-system Name: kube-scheduler Annotations: control-plane.alpha.kubernetes.io/leader= { "holderIdentity": "scheduler-2", "leaseDurationSeconds": 15, "acquireTime": "2018-01-01T08:00:00Z" "renewTime": "2018-01-01T08:00:30Z" }
Bien que Kubernetes garantisse qu'il y aura un maître à la fois, Kubernetes ne garantit pas que deux ou plusieurs composants de l'assistant ne
croiront pas à
tort qu'ils dirigent actuellement - cet état est connu sous le nom de
cerveau divisé .
Une discussion instructive sur le sujet du cerveau divisé et les solutions possibles peut être trouvée dans l'article de Martin Kleppmann
sur le verrouillage distribué .
Kubernetes n'utilise aucune contre-mesure du cerveau divisé. Au lieu de cela, il compte sur sa capacité à viser l'état souhaité au fil du temps, ce qui atténue les conséquences des décisions de conflit.
Conclusion
Dans une configuration multi-maîtres, Kubernetes est un moteur d'orchestration de conteneurs évolutif et fiable. Dans cette configuration, Kubernetes offre une fiabilité à l'aide d'une variété d'assistants et de nombreux travailleurs. De nombreux maîtres travaillent sur le modèle maître / esclave et les travailleurs travaillent en parallèle. Kubernetes possède son propre processus de sélection d'hôte, dans lequel les informations sur l'hôte sont stockées en tant
qu'objets de points de
terminaison .
Pour plus d'informations sur la préparation d'un cluster Kubernetes à haute disponibilité pour son fonctionnement, consultez la
documentation officielle .
À propos de la publication
Ce poste fait partie d'une initiative conjointe de CNCF, Google et SAP pour améliorer la compréhension de Kubernetes et de ses concepts sous-jacents.PS du traducteur
Lisez aussi dans notre blog: