Bonjour, Habr! Je m'appelle Nikolai Izhikov, je travaille pour Sberbank Technologies dans l'équipe de développement de solutions Open Source. Derrière 15 ans de développement commercial en Java. Je suis un contributeur Apache Ignite et un contributeur Apache Kafka.
Sous le chat, vous trouverez une version vidéo et texte de mon rapport sur Apache Ignite Meetup sur la façon d'utiliser Apache Ignite avec Apache Spark et les fonctionnalités que nous avons mises en œuvre pour cela.
Ce qu'Apache Spark peut faire
Qu'est-ce que Apache Spark? Il s'agit d'un produit qui vous permet d'effectuer rapidement des requêtes de calcul et d'analyse distribuées. Fondamentalement, Apache Spark est écrit en Scala.
Apache Spark possède une API riche pour se connecter à différents systèmes de stockage ou recevoir des données. L'une des caractéristiques du produit est un moteur de requête universel de type SQL pour les données reçues de diverses sources. Si vous avez plusieurs sources d'informations, que vous souhaitez les combiner et obtenir des résultats, Apache Spark est ce dont vous avez besoin.
L'une des abstractions clés que Spark fournit est Data Frame, DataSet. En termes de base de données relationnelle, il s'agit d'une table, une source qui fournit des données de manière structurée. La structure, le type de chaque colonne, son nom, etc., est connu. Les trames de données peuvent être créées à partir de diverses sources. Les exemples incluent les fichiers json, les bases de données relationnelles, divers systèmes hadoop et Apache Ignite.
Spark prend en charge les jointures dans les requêtes SQL. Vous pouvez combiner des données provenant de diverses sources et obtenir des résultats, effectuer des requêtes analytiques. De plus, il existe une API pour enregistrer les données. Lorsque vous avez terminé les requêtes, effectué une étude, Spark offre la possibilité d'enregistrer les résultats sur le récepteur qui prend en charge cette fonctionnalité et, en conséquence, de résoudre le problème du traitement des données.
Quelles fonctionnalités avons-nous mises en œuvre pour intégrer Apache Spark à Apache Ignite
- Lecture des données des tables SQL Apache Ignite.
- Écriture de données dans des tables SQL Apache Ignite.
- IgniteCatalog dans IgniteSparkSession - la possibilité d'utiliser toutes les tables Ignite SQL existantes sans s'enregistrer «à la main».
- Optimisation SQL - la possibilité d'exécuter des instructions SQL dans Ignite.
Apache Spark peut lire les données des tables SQL Apache Ignite et les écrire sous la forme d'une telle table. Tout DataFrame formé dans Spark peut être enregistré en tant que table Apache Ignite SQL.
Apache Ignite vous permet d'utiliser toutes les tables SQL Ignite existantes dans Spark Session sans vous inscrire «à la main» - en utilisant IgniteCatalog dans l'extension SparkSession standard - IgniteSparkSession.
Ici, vous devez aller un peu plus loin dans l'appareil Spark. En termes de base de données régulière, un répertoire est un endroit où les méta-informations sont stockées: quelles tables sont disponibles, quelles colonnes s'y trouvent, etc. Lorsqu'une demande arrive, les méta-informations sont extraites du catalogue et le moteur SQL fait quelque chose avec les tables et les données. Par défaut, dans Spark, toutes les tables de lecture (peu importe, à partir d'une base de données relationnelle, Ignite, Hadoop) doivent être enregistrées manuellement dans la session. Par conséquent, vous avez la possibilité d'effectuer une requête SQL sur ces tables. Spark les découvre.
Pour travailler avec les données que nous avons téléchargées sur Ignite, nous devons enregistrer les tables. Mais au lieu d'enregistrer chaque table avec nos mains, nous avons implémenté la possibilité d'accéder automatiquement à toutes les tables Ignite.
Quelle est la fonctionnalité ici? Pour une raison inconnue, le répertoire dans Spark est une API interne, c'est-à-dire un étranger ne peut pas venir créer sa propre implémentation de catalogue. Et, depuis que Spark est sorti de Hadoop, il ne prend en charge que Hive. Et vous devez enregistrer tout le reste avec vos mains. Les utilisateurs demandent souvent comment contourner ce problème et effectuer immédiatement des requêtes SQL. J'ai implémenté un répertoire qui vous permet de parcourir et d'accéder aux tables Ignite sans enregistrer ~ et sms ~, et j'ai initialement proposé ce patch dans la communauté Spark, auquel j'ai reçu une réponse: un tel patch n'est pas intéressant pour certaines raisons internes. Et ils n'ont pas donné l'API interne.
Désormais, le catalogue Ignite est une fonctionnalité intéressante implémentée à l'aide de l'API interne de Spark. Pour utiliser ce répertoire, nous avons notre propre implémentation de la session, c'est la SparkSession habituelle, dans laquelle vous pouvez faire des requêtes, traiter des données. Les différences sont que nous y avons intégré ExternalCatalog pour travailler avec les tables Ignite, ainsi que IgniteOptimization, qui sera décrit ci-dessous.
Optimisation SQL - la possibilité d'exécuter des instructions SQL dans Ignite. Par défaut, lors de l'exécution d'une jointure, d'un regroupement, d'un calcul d'agrégation et d'autres requêtes SQL complexes, Spark lit les données ligne par ligne. La seule chose que la source de données peut faire est de filtrer efficacement les lignes.
Si vous utilisez la jointure ou le regroupement, Spark extrait toutes les données de la table dans sa mémoire vers le programme de travail, à l'aide des filtres spécifiés, puis les regroupe ou effectue d'autres opérations SQL. Dans le cas d'Ignite, ce n'est pas optimal, car Ignite lui-même a une architecture distribuée et a connaissance des données qui y sont stockées. Par conséquent, Ignite lui-même peut calculer efficacement les agrégats et effectuer le regroupement. De plus, il peut y avoir beaucoup de données, et pour les regrouper, vous devrez tout soustraire, augmenter toutes les données dans Spark, ce qui est assez cher.
Spark fournit une API avec laquelle vous pouvez modifier le plan initial de la requête SQL, effectuer une optimisation et transférer la partie de la requête SQL qui peut y être exécutée dans Ignite. Cela sera efficace en termes de vitesse et de consommation de mémoire, car nous ne l'utiliserons pas pour extraire des données qui seront immédiatement regroupées.
Comment ça marche
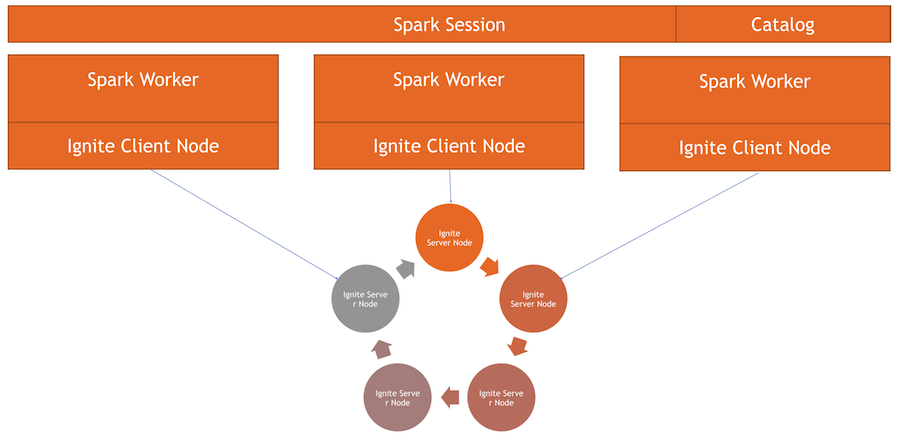
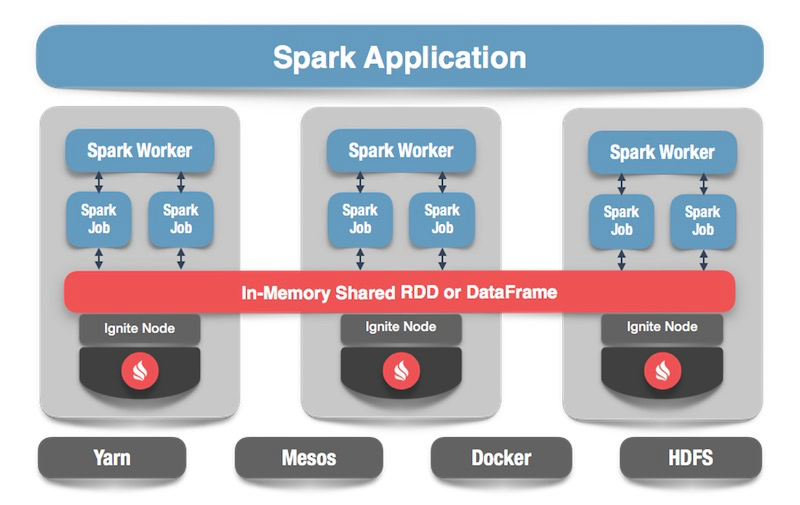
Nous avons un cluster Ignite - c'est la moitié inférieure de l'image. Il n'y a pas de gardien de zoo, car il n'y a que cinq nœuds. Il y a des ouvriers spark, à l'intérieur de chaque ouvrier le nœud client Ignite est levé. Grâce à lui, nous pouvons faire une demande et lire les données, interagir avec le cluster. En outre, le nœud client monte dans IgniteSparkSession pour que le répertoire fonctionne.
Allumer la trame de données
Passons au code: comment lire les données d'une table SQL? Dans le cas de Spark, tout est assez simple et bon: nous disons que nous voulons calculer certaines données, indiquer le format - c'est une certaine constante. De plus, nous avons plusieurs options - le chemin d'accès au fichier de configuration pour le nœud client, qui démarre lors de la lecture des données. Nous indiquons la table que nous voulons lire et demandons à Spark de charger. Nous obtenons les données et nous pouvons en faire ce que nous voulons.
spark.read .format(FORMAT_IGNITE) .option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE) .option(OPTION_TABLE, "person") .load()
Après avoir généré les données - éventuellement depuis Ignite, à partir de n'importe quelle source - nous pouvons tout aussi facilement tout sauvegarder en spécifiant le format et le tableau correspondant. Nous demandons à Spark d'écrire, nous spécifions un format. Dans la configuration, nous prescrivons à quel cluster se connecter. Spécifiez la table dans laquelle nous voulons enregistrer. De plus, nous pouvons prescrire des options d'utilitaire - spécifiez la clé primaire que nous créons sur ce tableau. Si les données bouleversent simplement sans créer de table, ce paramètre n'est pas nécessaire. À la fin, cliquez sur Enregistrer et les données sont écrites.
tbl.write. format(FORMAT_IGNITE). option(OPTION_CONFIG_FILE, CFG_PATH). option(OPTION_TABLE, tableName). option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk). save
Voyons maintenant comment tout cela fonctionne.
 LoadDataExample.scala
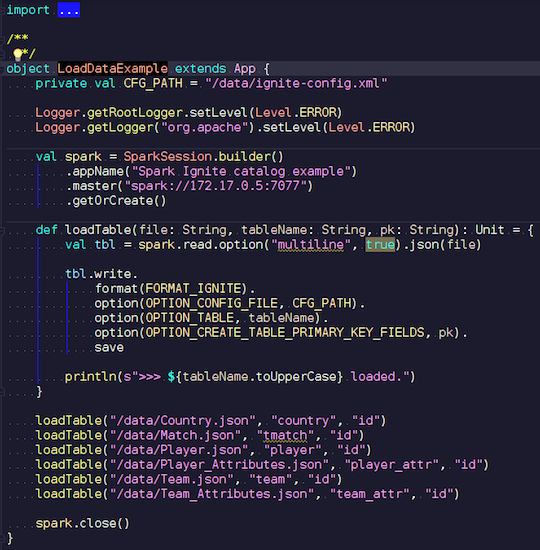
LoadDataExample.scalaCette application évidente démontrera d'abord les capacités d'enregistrement. Par exemple, j'ai choisi les données sur les matchs de football, les statistiques téléchargées à partir d'une ressource bien connue. Il contient des informations sur les tournois: ligues, matches, joueurs, équipes, attributs des joueurs, attributs des équipes - données qui décrivent les matchs de football dans les ligues des pays européens (Angleterre, France, Espagne, etc.).
Je veux les télécharger sur Ignite. Nous créons une session Spark, spécifions l'adresse de l'assistant et appelons le chargement de ces tables en passant des paramètres. L'exemple est en Scala, pas en Java, car Scala est moins verbeux et donc meilleur par exemple.
Nous transférons le nom du fichier, le lisons, indiquons qu'il est multiligne, il s'agit d'un fichier json standard. Ensuite, nous écrivons dans Ignite. La structure de notre fichier n'est nulle part à décrire - Spark lui-même détermine quelles données nous avons et quelle est leur structure. Si tout se passe bien, une table est créée dans laquelle se trouvent tous les champs nécessaires des types de données requis. C'est ainsi que nous pouvons tout charger dans Ignite.
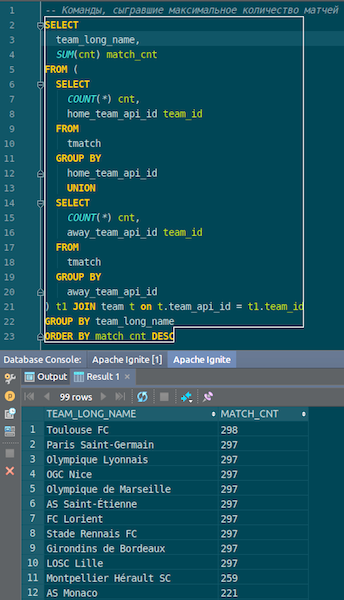
Lorsque les données sont chargées, nous pouvons les voir dans Ignite et les utiliser immédiatement. À titre d'exemple simple, une requête qui vous permet de savoir quelle équipe a joué le plus de matchs. Nous avons deux colonnes: hometeam et awayteam, hôtes et invités. Nous sélectionnons, groupons, comptons, additionnons et joignons les données de la commande - pour entrer le nom de la commande. Ta-dam - et les données de json-chiks que nous avons obtenues dans Ignite. Nous voyons Paris Saint-Germain, Toulouse - nous avons beaucoup de données sur les équipes françaises.
Nous résumons. Nous avons maintenant téléchargé des données depuis la source, le fichier json, vers Ignite, et assez rapidement. Peut-être, du point de vue des mégadonnées, ce n'est pas trop grand, mais décent pour un ordinateur local. Le schéma de la table est extrait du fichier json dans sa forme d'origine. La table a été créée, les noms des colonnes ont été copiés à partir du fichier source, la clé primaire a été créée. L'ID est partout et la clé primaire est l'ID. Ces données sont entrées dans Ignite, nous pouvons les utiliser.
IgniteSparkSession et IgniteCatalog
Voyons comment cela fonctionne.
 CatalogExample.scala
CatalogExample.scalaD'une manière assez simple, vous pouvez accéder à toutes vos données et les interroger. Dans le dernier exemple, nous avons démarré la session spark standard. Et il n'y avait aucune spécificité Ignite là-bas - sauf que vous devez mettre un pot avec la bonne source de données - un travail complètement standard via l'API publique. Mais, si vous souhaitez accéder automatiquement aux tables Ignite, vous pouvez utiliser notre extension. La différence est qu'au lieu de SparkSession, nous écrivons IgniteSparkSession.
Dès que vous créez un objet IgniteSparkSession, vous voyez dans le répertoire toutes les tables qui viennent d'être chargées dans Ignite. Vous pouvez voir leur diagramme et toutes les informations. Spark connaît déjà les tables qu'Ignite possède et vous pouvez facilement obtenir toutes les données.
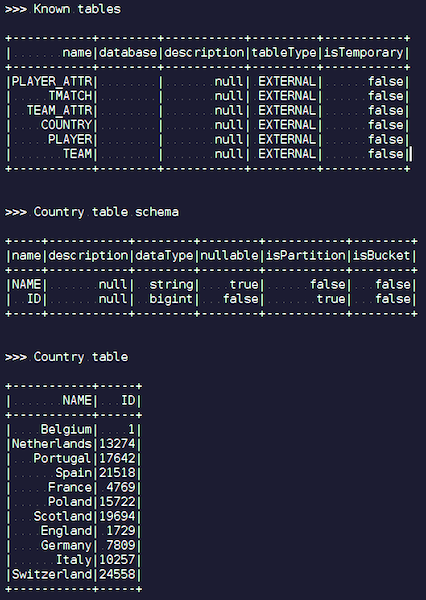
Igniteoptimization
Lorsque vous effectuez des requêtes complexes dans Ignite à l'aide de JOIN, Spark extrait d'abord les données, puis seulement JOIN les regroupe. Pour optimiser le processus, nous avons créé la fonction IgniteOptimization - elle optimise le plan de requête Spark et vous permet de transmettre les parties de la demande qui peuvent être exécutées dans Ignite dans Ignite. Nous montrons l'optimisation sur une demande spécifique.
SQL Query: SELECT city_id, count(*) FROM person p GROUP BY city_id HAVING count(*) > 1
Nous satisfaisons la demande. Nous avons une table de personnes - certains employés, des gens. Chaque employé connaît l'identifiant de la ville dans laquelle il vit. Nous voulons savoir combien de personnes vivent dans chaque ville. Nous filtrons - dans quelle ville vit plus d'une personne. Voici le plan initial que Spark construit:
== Analyzed Logical Plan == city_id: bigint, count(1): bigint Project [city_id#19L, count(1)#52L] +- Filter (count(1)#54L > cast(1 as bigint)) +- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L] +- SubqueryAlias p +- SubqueryAlias person +- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L] IgniteSQLRelation[table=PERSON]
La relation n'est qu'une table Ignite. Il n'y a pas de filtres - nous pompons simplement toutes les données de la table Person sur le réseau à partir du cluster. Ensuite, Spark agrège tout cela - conformément à la demande et renvoie le résultat de la demande.
Il est facile de voir que tous ces sous-arbres avec filtre et agrégation peuvent être exécutés dans Ignite. Cela sera beaucoup plus efficace que d'extraire toutes les données d'une table potentiellement grande dans Spark - c'est ce que fait notre fonction IgniteOptimization. Après avoir analysé et optimisé l'arbre, nous obtenons le plan suivant:
== Optimized Logical Plan == Relation[CITY_ID#19L,COUNT(1)#52L] IgniteSQLAccumulatorRelation( columns=[CITY_ID, COUNT(1)], qry=SELECT CITY_ID, COUNT(1) FROM PERSON GROUP BY city_id HAVING count(1) > 1)
En conséquence, nous n'obtenons qu'une seule relation, car nous avons optimisé tout l'arbre. Et à l'intérieur, vous pouvez déjà voir qu'Ignite enverra une demande suffisamment proche de la demande d'origine.
Supposons que nous joignions différentes sources de données: par exemple, nous avons un DataFrame d'Ignite, le second de json, le troisième d'Ignite à nouveau et le quatrième d'une sorte de base de données relationnelle. Dans ce cas, seul le sous-arbre sera optimisé dans le plan. Nous optimisons ce que nous pouvons, le déposons dans Ignite et Spark fera le reste. Pour cette raison, nous obtenons un gain de vitesse.
Un autre exemple avec JOIN:
SQL Query - SELECT jt1.id as id1, jt1.val1, jt2.id as id2, jt2.val2 FROM jt1 JOIN jt2 ON jt1.val1 = jt2.val2
Nous avons deux tableaux. Nous restons unis par valeur et sélectionnons parmi eux tous - ID, valeurs. Spark propose un tel plan:
== Analyzed Logical Plan == id1: bigint, val1: string, id2: bigint, val2: string Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5] +- Join Inner, (val1#3 = val2#5) :- SubqueryAlias jt1 : +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1] +- SubqueryAlias jt2 +- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]
Nous voyons qu'il va extraire toutes les données d'une table, toutes les données de la seconde, les joindre en lui et donner les résultats. Après le traitement et l'optimisation, nous obtenons exactement la même demande qui va à Ignite, où elle est exécutée relativement rapidement.
== Optimized Logical Plan == Relation[ID#84L,VAL1#3,ID#85L,VAL2#5] IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2], qry= SELECT JT1.ID AS id1, JT1.VAL1, JT2.ID AS id2, JT2.VAL2 FROM JT1 JOIN JT2 ON JT1.val1 = JT2.val2 WHERE JT1.val1 IS NOT NULL AND JT2.val2 IS NOT NULL)
Je vais vous montrer un exemple.
 OptimizationExample.scala
OptimizationExample.scalaNous créons une session IgniteSpark dans laquelle toutes nos capacités d'optimisation sont déjà automatiquement incluses. Voici la demande: trouvez les joueurs avec la note la plus élevée et affichez leurs noms. Dans la table des joueurs, leurs attributs et données. Nous nous joignons, filtrons les données indésirables et affichons les joueurs avec la note la plus élevée. Voyons quel type de plan nous avons obtenu après l'optimisation et montrons les résultats de cette requête.
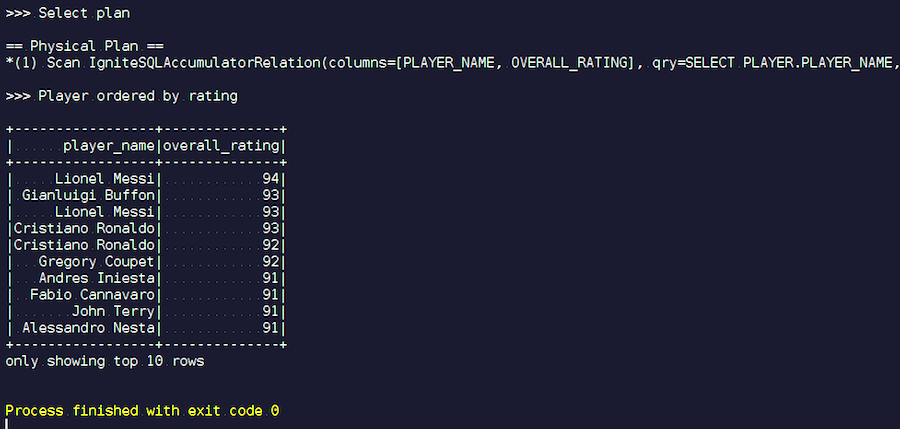
Nous commençons. Nous voyons des noms de famille familiers: Messi, Buffon, Ronaldo, etc. Soit dit en passant, certains pour une raison quelconque se rencontrent sous deux formes - Messi et Ronaldo. Les amateurs de football peuvent trouver étrange que des joueurs inconnus apparaissent sur la liste. Ce sont des gardiens de but, des joueurs avec des caractéristiques assez élevées - dans le contexte des autres joueurs. Maintenant, nous regardons le plan de requête qui a été exécuté. Dans Spark, presque rien n'a été fait, c'est-à-dire que nous avons de nouveau envoyé la demande entière à Ignite.
Apache Ignite Development
Notre projet est un produit open source, nous sommes donc toujours satisfaits des correctifs et des commentaires des développeurs. Votre aide, vos commentaires, vos correctifs sont les bienvenus. Nous les attendons. 90% de la communauté Ignite est russophone. Par exemple, pour moi, jusqu'à ce que je commence à travailler sur Apache Ignite, la meilleure connaissance de l'anglais n'était pas dissuasive. Cela ne vaut guère la peine d'écrire en russe sur une liste de développeurs, mais même si vous écrivez quelque chose de mal, ils vous répondront et vous aideront.
Que peut-on améliorer sur cette intégration? Comment puis-je vous aider si vous avez un tel désir? Liste ci-dessous. Les astérisques indiquent la complexité.

Pour tester l'optimisation, vous devez écrire des tests avec des requêtes complexes. Ci-dessus, j'ai montré quelques requêtes évidentes. Il est clair que si vous écrivez beaucoup de groupements et beaucoup de jointures, alors quelque chose peut tomber. C'est une tâche très simple - venez le faire. Si nous trouvons des bogues basés sur les résultats des tests, ils devront être corrigés. Ce sera plus difficile là-bas.
Une autre tâche claire et intéressante est l'intégration de Spark avec un client léger. Il est initialement capable de spécifier certains ensembles d'adresses IP, et cela suffit pour rejoindre le cluster Ignite, ce qui est pratique en cas d'intégration avec un système externe. Si vous souhaitez soudainement rejoindre la solution à ce problème, je vais personnellement vous aider.
Si vous souhaitez rejoindre la communauté Apache Ignite, voici quelques liens utiles:
Nous avons une liste de développeurs réactifs, qui vous aidera. C'est encore loin d'être idéal, mais en comparaison avec d'autres projets, il est vraiment vivant.
Si vous connaissez Java ou C ++, vous cherchez du travail et souhaitez développer l'Open Source (Apache Ignite, Apache Kafka, Tarantool, etc.) écrivez ici: join-open-source@sberbank.ru.