Une fois, j'ai déjà écrit ici sur le passage de l'Asie à l'Europe , et maintenant je veux écrire ce que je fais dans cette Europe. Il y a une telle profession - DevOps , ou plutôt pas, mais il se trouve que c'est exactement ce que je fais maintenant. Maintenant, pour l'orchestration de tout ce qui fonctionne dans le docker, nous utilisons un éleveur , dont j'ai également parlé . Mais une chose terrible s'est produite, Rancher 2.0 est sorti et est passé à kubernetes (ci-après simplement k8s) et comme k8s est maintenant vraiment la norme pour la gestion du cluster, il y avait un désir de reconstruire toute l'infrastructure avec le blackjack et les bibliothécaires. Ce qui ajoute du piquant à cela, c'est que l'entreprise embauche constamment différents spécialistes de différents pays et avec des traditions différentes, et quelqu'un apporte des puppet - puppet , quelqu'un est ansible , et quelqu'un pense généralement que Makefile + bash est notre tout. Par conséquent, il n'y a tout simplement pas d'opinion sans équivoque sur la façon dont tout devrait fonctionner, mais je le veux vraiment.
Un tel zoo de technologies et d'outils a déjà été assemblé:

Gestion des infrastructures
- Minikube
- Rke
- Terraform
- Kops
- Kubespray
- Ansible
Gestion des applications
- Kubernetes
- Rancher
- Kubectl
- Heaume
- Confd
- Kompose
- Jenkins
Journalisation et surveillance
- Elasticsearch
- Kibana
- Peu fluide
- Telegraf
- Influxdb
- Zabbix
- Prométhée
- Grafana
- Kapacitor
Ensuite, je vais essayer de décrire brièvement chaque point de ce zoo, expliquer pourquoi il est nécessaire et pourquoi cette solution a été choisie. En fait, presque n'importe quel article peut être remplacé par une douzaine d'analogues et nous ne sommes toujours pas complètement sûrs du choix, donc si quelqu'un a une opinion ou des recommandations, je le lirai avec plaisir dans les commentaires.
Kubernetes sera au centre de tout, car il s'agit désormais d'une solution qui n'a tout simplement pas d'alternatives, qui est prise en charge par tous les fournisseurs d'Amazon et de Microsoft à mail.ru. Comment les alternatives ont été envisagées
Swarm - qui n'a jamais décolléNomad - qui semble être écrit par des étrangers pour les prédateursCattle est le moteur du ranger 1.x, sur lequel nous vivons maintenant, en principe, tout va bien, mais l'éleveur l'a déjà abandonné au profit des k8 donc il n'y aura pas de développement.
Construction d'infrastructures
Tout d'abord, nous devons créer l'infrastructure et y déployer un cluster k8s. Il existe plusieurs options, elles fonctionnent toutes et il est donc difficile de choisir la meilleure.
Minikube est une excellente option pour démarrer un cluster sur la machine d'un développeur, à des fins de test.
Rke - Moteur Kubernetes Rancher, aussi simple qu'une porte; configuration minimale pour créer un look de cluster
nodes: - address: localhost role: [controlplane,worker,etcd]
Et c'est tout, cela suffit pour démarrer le cluster sur la machine locale, tout en vous permettant de créer des clusters HA prêts pour la production, de modifier la configuration, de mettre à niveau le cluster, de vider la base de données etcd et bien plus encore.
Kops - vous permet non seulement de créer un cluster, mais aussi de pré-créer des instances dans aws ou gce. Il vous permet également de générer une configuration pour terraform. Un outil intéressant, mais nous n'avons pas encore pris racine. Il est complètement remplacé par terraform + rke alors qu'il est plus simple et plus flexible.
Kubespray - en fait, c'est juste un rôle ansible qui crée un cluster k8s, sacrément puissant, flexible, configurable. Il s'agit pratiquement de la solution par défaut pour le déploiement de k8s.
Terraform est un outil pour la construction d'infrastructures dans aws, azur ou un tas d'autres endroits. Flexible, stable - je recommande.
Ansible ne concerne pas vraiment les k8, mais nous l'utilisons partout et ici aussi: peaufiner les configurations, installer / mettre à jour les logiciels, distribuer les certificats. Pas cher et gai.
Gestion des applications
Donc, nous avons un cluster, maintenant nous devons commencer quelque chose d'utile, il ne reste plus qu'à savoir comment faire cela.
Première option: utilisez des k8 nus tous déployés à l'aide de kubectl . En principe, cette option a droit à la vie. Kubectl est un outil assez puissant qui nous permet de faire tout ce dont nous avons besoin, y compris le déploiement, la mise à niveau, la surveillance de l'état actuel, la modification de la configuration à la volée, l'affichage des journaux et la connexion à des conteneurs spécifiques. Mais parfois, je veux que tout soit un peu plus pratique, alors nous allons de l'avant.
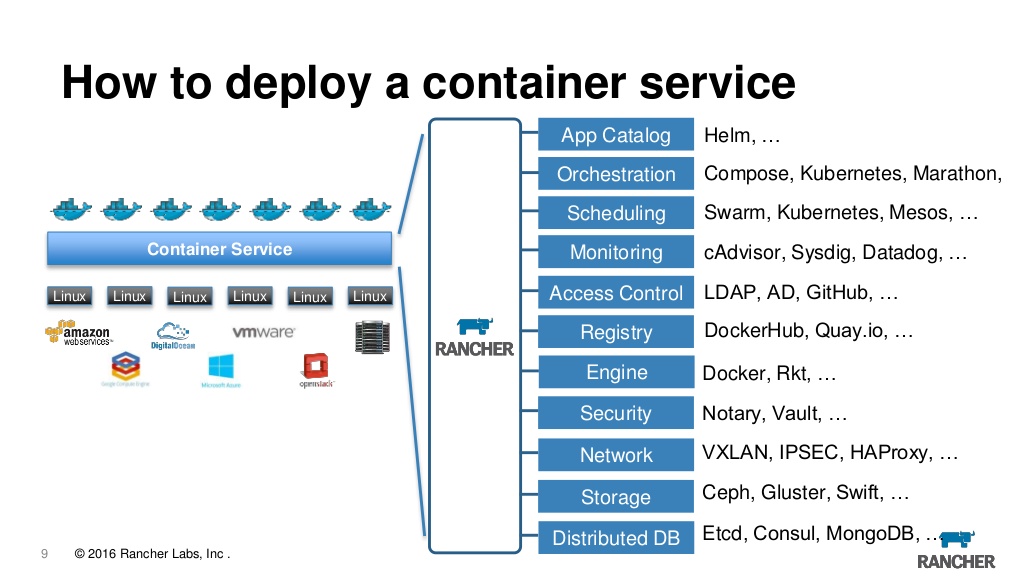
En fait, maintenant rancher est un museau Web pour gérer les k8 et en même temps beaucoup de petits pains qui ajoutent de la commodité. Ici, vous pouvez afficher les journaux, accéder à la console et configurer et mettre à niveau les applications et le contrôle d'accès basé sur les rôles et un serveur de métadonnées intégré, les alarmes, la redirection des journaux, la gestion des secrets et bien plus encore. Nous utilisons la première version rancher depuis plusieurs années maintenant et nous en sommes entièrement satisfaits, même si nous devons admettre que lors du passage au k8, la question se pose de savoir si nous en avons vraiment besoin. C'est bien que vous puissiez importer n'importe quel cluster précédemment créé dans l'éleveur, et de n'importe quel fournisseur, c'est-à-dire que vous pouvez importer un cluster depuis EKS à partir d'azure et créé localement et les conduire d'un endroit à un serveur. De plus, si vous vous ennuyez soudainement, vous pouvez simplement démolir le serveur et continuer à utiliser le cluster directement via kubeclt ou tout autre outil.
Le concept très correct de tout comme code est maintenant populaire. Par exemple, l'infrastructure en tant que code est implémentée à l'aide de terraform , l'assembly en tant que code est implémenté via le jenkins pipeline . Maintenant, c'est au tour de l'application. L'installation et la configuration de l'application doivent également être décrites dans un manifeste et enregistrées dans git. Les versions Rancher 1.x utilisaient le docker-compose.yml standard et tout allait bien, mais quand ils sont passés aux k8, ils sont passés aux helm charts . Helm est, de mon point de vue, un partage absolument terrible avec une logique et une architecture étranges. C'est l'un de ces projets dont le sentiment demeure qu'il a été écrit par des prédateurs pour des étrangers ou vice versa. Le seul problème est que dans le monde de la barre k8s il n'y a tout simplement pas d'alternatives et c'est de facto la norme. Par conséquent, nous serons piqués de pleurer, mais continuerons à utiliser le casque. Dans la version 3.x, les développeurs promettent de le réécrire à partir de zéro, en supprimant toutes les bizarreries et en simplifiant l'architecture. C'est alors que nous guérirons, mais pour l'instant nous mangerons ce qui est.
Nous devons également mentionner au moins jenkins ici, il ne concerne pas directement le sujet de kubernetis, mais c'est avec son aide que les applications sont déployées sur le cluster. Il l'est, il travaille et il fait l'objet d'un article séparé.
Suivi
Maintenant, nous avons un cluster et il tourne même une sorte d'application, il semblerait que vous puissiez expirer, mais en fait, tout ne fait que commencer. Quelle est la stabilité de notre application? À quelle vitesse At-il suffisamment de ressources? Que se passe-t-il généralement dans le cluster?
Oui, le sujet suivant est la surveillance et la journalisation. Il n'y a que trois réponses définitives. Stockez les journaux dans elasticsearch , regardez-les à travers kibana dessinez des graphiques dans grafana . Pour toutes les autres questions, il existe une douzaine de bonnes réponses.
Ici, nous commençons par grafana seul, il ne fait pratiquement rien, mais il peut être fixé comme un beau visage à l'un des systèmes décrits ci-dessous et obtenir des graphiques magnifiques et parfois clairs, en plus, vous pouvez immédiatement configurer des alarmes, mais il est préférable d'utiliser d'autres solutions pour cela, par exemple prometheus alertmanager et ElastAlert .
De mon point de vue, c'est actuellement le meilleur agrégateur et routeur de journaux, en plus, dès la sortie de la boîte, il prend en charge k8s. Il y a aussi Fluentd mais il est écrit en roubles et tire trop de code hérité, ce qui le rend beaucoup moins attrayant. Donc, si vous avez besoin d'un module spécifique de fluentd qui n'a pas encore été porté sur fluent-bit, utilisez-le, dans tout le reste - bit est le meilleur choix. Il est plus rapide, plus stable, consomme moins de mémoire. Vous permet de collecter des journaux de tous ou à partir de conteneurs sélectionnés, de les filtrer, de les enrichir en ajoutant des données spécifiques à kubernetis et de les envoyer à elasticsearch ou à de nombreux autres référentiels. Si vous le comparez avec logstash + docker-bit + file-bit traditionnel logstash + docker-bit + file-bit cette solution est certainement meilleure à tous égards. Historiquement, nous utilisons toujours logspout + logstash mais fluent-bit gagne définitivement.
Un système de surveillance écrit spécifiquement pour l'architecture de microservices. La norme de facto dans l'industrie, en outre, il existe également un projet appelé Prometheus Operator , écrit spécifiquement pour les k8. Tout le monde décide quoi choisir, mais il vaut mieux commencer par un prométhée nu, juste pour comprendre la logique de son travail, c'est assez différent des systèmes habituels. Nous devons également mentionner le node-exporter qui vous permet de collecter des métriques au niveau de la machine et prometheus-rancher-exportateur qui vous permet de collecter des métriques via l'api rancher. En général, si vous avez un cluster sur kubernetes, prometheus est un must have.
On pourrait s'arrêter là, mais historiquement, nous avons plusieurs autres systèmes de surveillance. Premièrement, il zabbix très pratique pour zabbix de voir tous les problèmes de l'infrastructure entière sur un seul panneau. La présence de la découverte automatique vous permet de trouver et d'ajouter rapidement de nouveaux réseaux, nœuds, services et généralement presque tout à la surveillance, ce qui en fait plus qu'un outil pratique pour surveiller les infrastructures dynamiques. De plus, dans la version 4.0, une collection de métriques des exportateurs de prometheus a été ajoutée à zabbix et il s'avère que tout cela peut être très bien intégré dans un seul système. Bien qu'il n'y ait toujours pas de réponse définitive quant à la nécessité de faire glisser zabbix dans un cluster k8s, il est certainement intéressant d'essayer.
Tout comme une alternative, vous pouvez utiliser TIG (telegraf + influxdb + grafana) configuré simplement, il fonctionne de manière stable, il vous permet d'agréger des métriques par conteneurs, applications, nœuds, etc., mais en fait il duplique complètement la fonctionnalité prometheus, et il ne devrait en rester qu'une seule.
Et il s'avère donc qu'avant de commencer quelque chose d'utile, vous devez installer et configurer la liaison à partir de quelques dizaines de services et d'outils auxiliaires. Dans le même temps, l'article n'a pas soulevé de problèmes de gestion des données persistantes, des secrets et d'autres choses étranges, chacune pouvant être tirée vers une publication distincte.
Et comment voyez-vous l'infrastructure idéale?
Si vous avez une opinion, veuillez écrire dans les commentaires, ou peut-être même rejoindre notre équipe et aider à mettre tout cela ensemble.