Une fois, dans une interview, un musicien russe bien connu a déclaré: "Nous travaillons à mentir et à cracher au plafond." Je ne peux pas être en désaccord avec cette affirmation, car le fait que la paresse est le moteur du développement de la technologie ne peut être contesté. En effet, ce n'est qu'au siècle dernier que nous sommes passés des machines à vapeur à l'industrialisation numérique, et maintenant l'intelligence artificielle, qui a été écrite par des écrivains de science-fiction et des futurologues du siècle dernier, devient chaque jour une réalité sans cesse croissante de notre monde. Jeux informatiques, appareils mobiles, montres intelligentes et bien plus encore utiliser essentiellement des algorithmes associés à des mécanismes d'apprentissage automatique.
De nos jours, en raison de la croissance des capacités de calcul des processeurs graphiques et de la grande quantité de données qui sont apparues, les réseaux de neurones ont gagné en popularité, à l'aide desquels ils résolvent les problèmes de classification et de régression, en les formant sur les données préparées. De nombreux articles ont déjà été écrits sur la façon de former les réseaux de neurones et les cadres à utiliser pour cela. Mais il y a une tâche antérieure qui doit également être résolue, et c'est la tâche de former un tableau de données - un ensemble de données, pour la formation continue du réseau neuronal. Cela sera discuté dans cet article.
Il n'y a pas si longtemps, il était nécessaire de construire un classificateur de bruit acoustique de voiture capable d'extraire des données d'un flux audio commun: vitre cassée, ouverture des portes et fonctionnement d'un moteur de voiture dans différents modes. Le développement du classificateur n'a pas été difficile, mais où obtenir l'ensemble de données pour qu'il réponde à toutes les exigences?
Google est venu à la rescousse (sans offenser Yandex - je parlerai de ses avantages un peu plus tard), avec l'aide duquel il a été possible de distinguer plusieurs clusters principaux contenant les données nécessaires. Je tiens à noter à l'avance que les sources indiquées dans cet article incluent une grande quantité d'informations acoustiques, avec différentes classes, ce qui vous permet de créer un ensemble de données pour différentes tâches. Nous passons maintenant à un aperçu de ces sources.
Freesound.org
Très probablement,
Freesound.org fournit le plus grand volume de données acoustiques, étant un référentiel conjoint d'échantillons de musique sous licence, qui compte actuellement plus de 230 000 copies d'effets sonores. Chaque échantillon sonore peut être distribué sous une licence différente, il est donc préférable de vous familiariser avec l'
accord de licence à l' avance. Par exemple, la licence
zéro (cc0) a le statut «Aucun droit d'auteur» et vous permet de copier, modifier et distribuer, y compris à des fins commerciales, et vous permet d'utiliser les données de manière absolument légale.
Pour la commodité de trouver des éléments d'informations acoustiques dans une variété de freesound.org, les développeurs ont fourni une
API conçue pour analyser, rechercher et télécharger des données à partir de référentiels. Pour travailler avec, vous devez avoir accès, pour cela, vous devez aller dans le
formulaire et remplir tous les champs nécessaires, après quoi la clé individuelle sera générée.

Les développeurs de Freesound.org fournissent des
API pour différents langages de programmation, permettant ainsi de résoudre le même problème avec différents outils. La liste des langues prises en charge et les liens pour y accéder sur GitHub sont répertoriés ci-dessous.
Pour atteindre l'objectif, python a été utilisé, car ce beau langage de programmation de frappe dynamique a gagné en popularité en raison de sa facilité d'utilisation, effaçant complètement le mythe de la complexité du développement logiciel.
Le module pour travailler avec freesound.org pour python peut être cloné à partir du référentiel github.com.
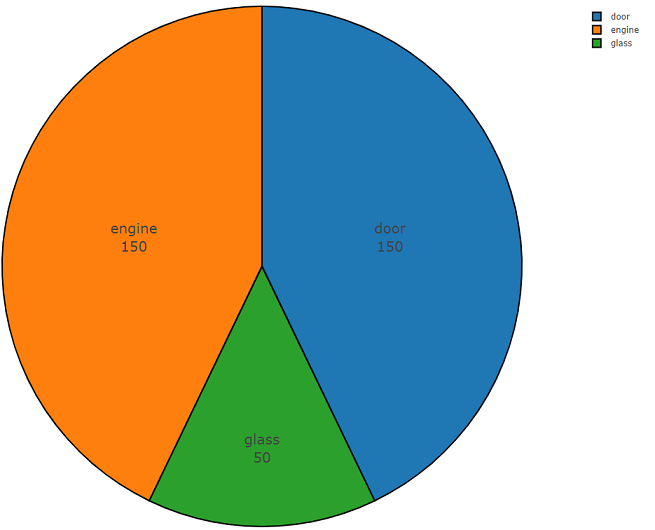
Vous trouverez ci-dessous le code en deux parties qui démontre la facilité d'utilisation de cette API. La première partie du code du programme effectue la tâche d'analyse des données, dont le résultat est la densité de distribution des données pour chaque classe demandée, et la seconde partie télécharge les données des référentiels freesound.org pour les classes sélectionnées. La densité de distribution lors de la recherche d'informations acoustiques avec les mots-clés
verre, moteur, porte est présentée ci-dessous dans un graphique circulaire à titre d'exemple.
Exemple de code d'analyse de données Freesound.org
import plotly import plotly.graph_objs as go import freesound import os import termcolor
Exemple de code pour télécharger des données freesound.org
Une caractéristique de freesound est que l'analyse des données audio peut être effectuée sans télécharger de fichier audio, vous permettant d'obtenir le MFCC, l'énergie spectrale, le centroïde spectral et d'autres coefficients. En savoir plus sur les informations de bas niveau dans la
documentation freesound.ord .
Grâce à l'API freesound.org, le temps passé à récupérer et télécharger des données est minimisé, ce qui vous permet de gagner des heures de travail en étudiant d'autres sources d'informations, car les classificateurs acoustiques de haute précision nécessitent un grand ensemble de données avec une grande variabilité, représentant des données avec différentes harmoniques sur une seule et la même classe d'événements.
YouTube-8M et AudioSet
Je pense que YouTube n'est pas particulièrement requis dans la présentation, mais néanmoins, Wikipedia nous dit que YouTube est un site d'hébergement vidéo qui fournit aux utilisateurs des services d'affichage vidéo, oubliant de dire que YouTube est une énorme base de données, et cette source doit être utilisée dans le machine learning et Google Inc nous fournit un projet appelé
YouTube-8M Dataset .
YouTube-8M Dataset est un ensemble de données qui comprend plus d'un million de fichiers vidéo de YouTube en haute qualité, pour donner des informations plus précises.En mai 2018, il y avait 6,1 millions de vidéos avec 3862 classes. Ce jeu de données est sous licence
Creative Commons Attribution 4.0 International (CC BY 4.0) . Une telle licence vous permet de copier et de distribuer du matériel sur n'importe quel support et format.
Vous vous demandez probablement: où les données vidéo entrent-elles lorsque des informations acoustiques sont nécessaires pour la tâche, et vous aurez tout à fait raison. Le fait est que Google fournit non seulement du contenu vidéo, mais a également alloué séparément un sous-projet avec des données audio appelé
AudioSet .
 AudioSet
AudioSet - fournit un ensemble de données obtenues à partir de vidéos YouTube, où de nombreuses données sont présentées dans une hiérarchie de classes à l'aide d'
un fichier d'ontologie , sa représentation graphique est située ci-dessous.
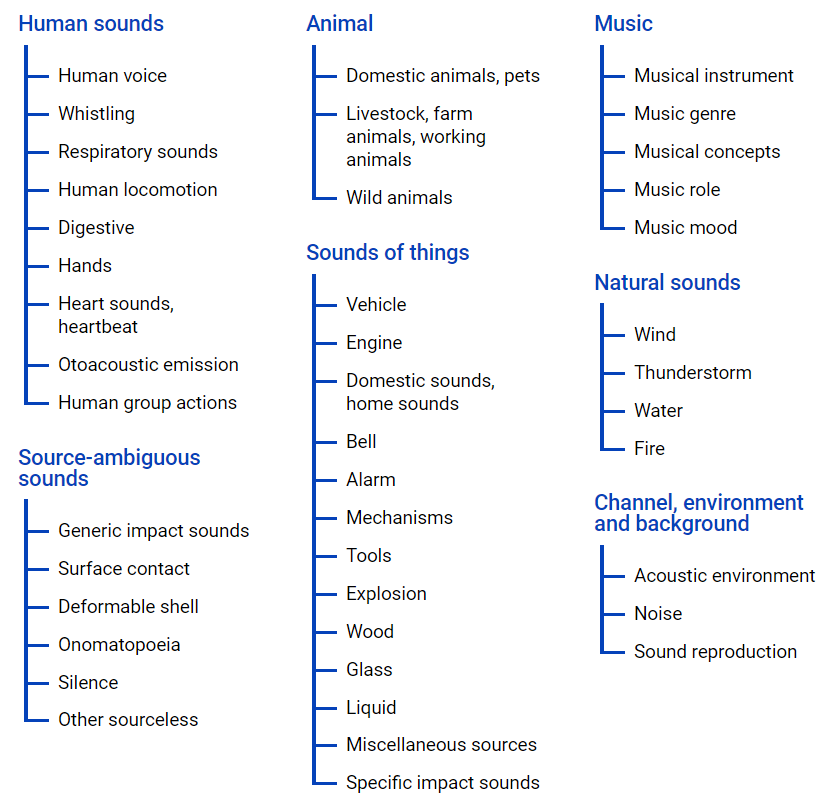
Ce fichier vous permet de vous faire une idée de l'imbrication des classes, ainsi que d'accéder aux vidéos youtube. Pour télécharger des données depuis l'espace Internet, vous pouvez utiliser le module python - youtube-dl, qui vous permet de télécharger du contenu audio ou vidéo, selon la tâche requise.
AudioSet représente un cluster divisé en trois ensembles: ensemble de données de test, d'apprentissage (équilibré) et d'apprentissage (asymétrique).
Examinons ce cluster et analysons chacun de ces ensembles séparément pour avoir une idée des classes contenues.
Entraînement (équilibré)Selon la documentation, cet ensemble de données se compose de
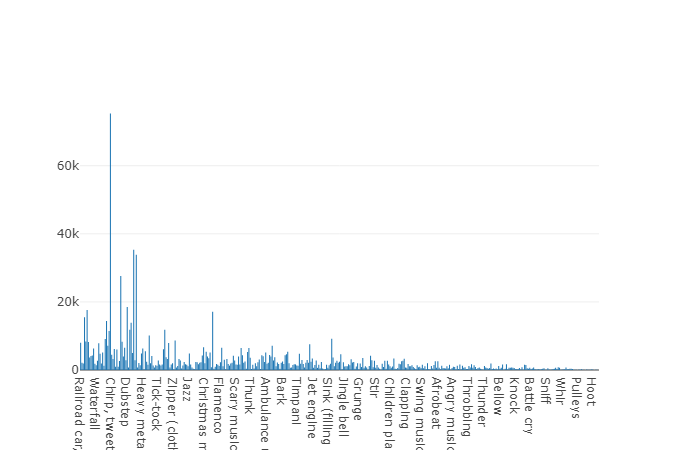
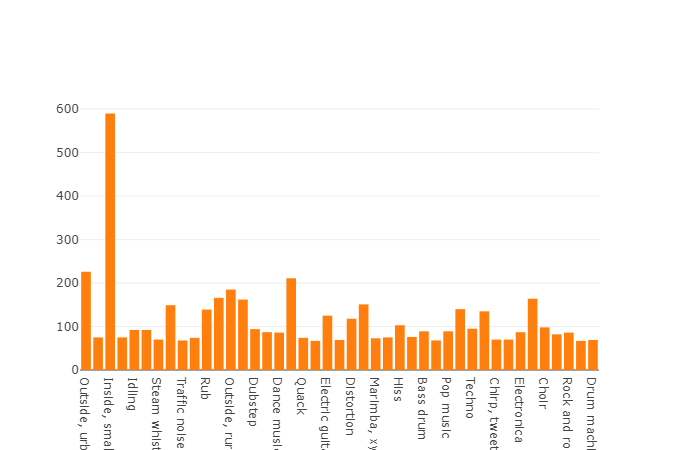
22 176 segments obtenus à partir de diverses vidéos sélectionnées par mots-clés, fournissant à chaque classe au moins 59 copies. Si nous regardons la densité de distribution des classes racines dans la hiérarchie de l'ensemble, nous verrons que la classe Music est le plus grand groupe de fichiers audio.
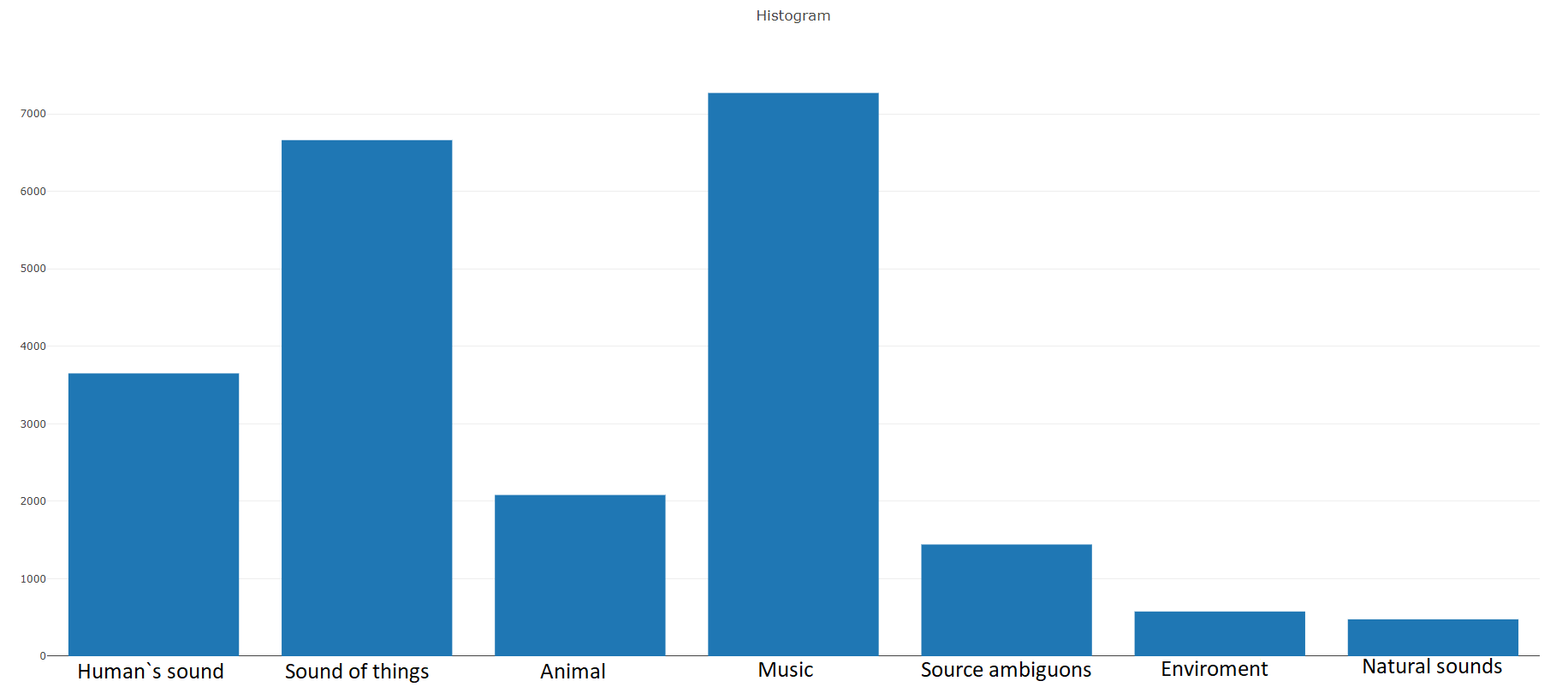
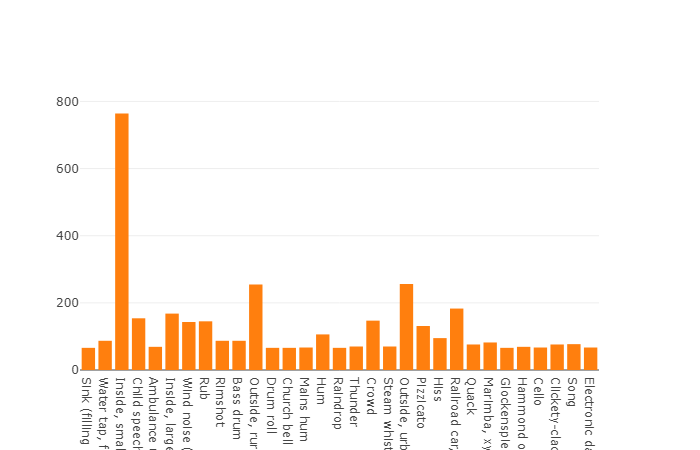
Les classes organisées sont décomposées en sous-ensembles de classes, ce qui vous permet d'obtenir des informations plus détaillées lors de son utilisation. Cet ensemble d'entraînement équilibré a une densité de distribution sur laquelle il est clair que l'équilibre est présent, mais aussi les classes individuelles sont très distinguées de la vue générale.
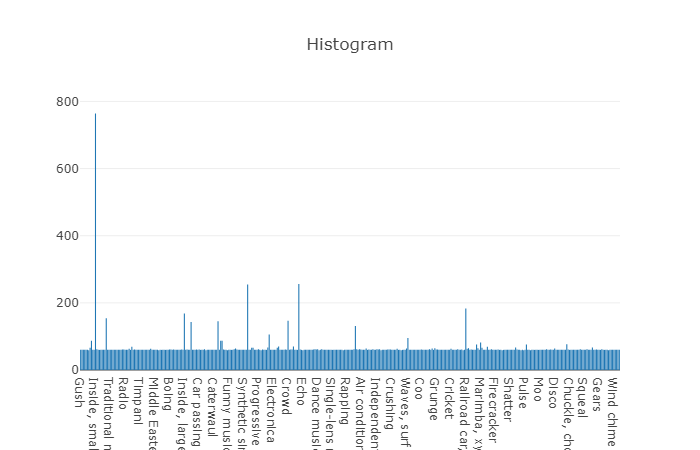
La répartition des classes dont le nombre d'éléments dépasse la valeur moyenne
La durée moyenne de chacun des fichiers audio est de 10 secondes, des informations plus détaillées sont présentées par le schéma du disque, qui montre que la durée de certains fichiers diffère de celle de l'ensemble principal. Ce graphique est également présenté.
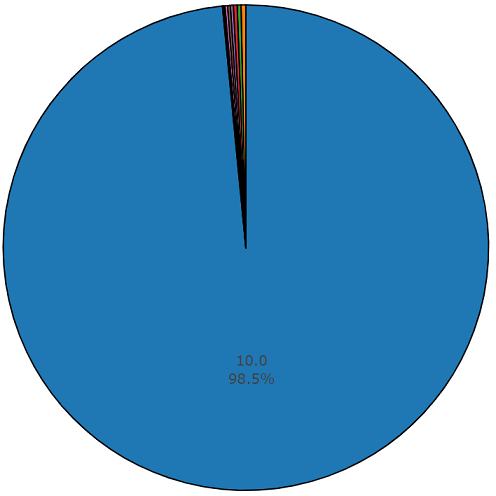
Diagramme d'une durée non moyenne de 1,5% à partir d'un ensemble audio équilibré
 Entraînement (déséquilibré)
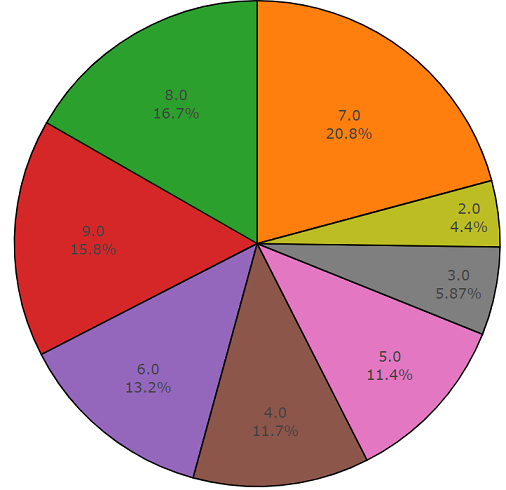
Entraînement (déséquilibré)L'avantage de cet ensemble de données est sa taille. Imaginez simplement que, selon la documentation, cet ensemble comprend 2 042 985 segments et, par rapport aux ensembles de données équilibrés, représente une grande variabilité, mais l'entropie de cet ensemble est beaucoup plus élevée.
Dans cet ensemble, la durée moyenne de chacun des fichiers audio est également égale à 10 secondes, le diagramme du disque pour cet ensemble de données est présenté ci-dessous.
Graphique de durée non moyenne d'un ensemble audio déséquilibré
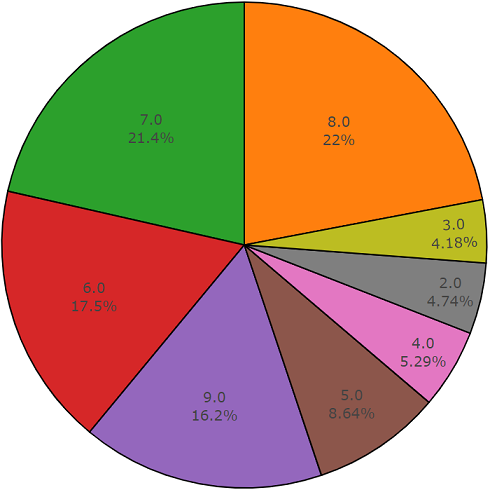
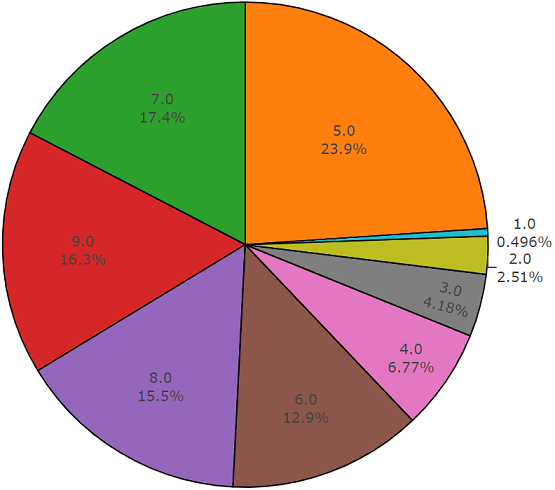 Ensemble de test
Ensemble de testCet ensemble est très similaire à un ensemble équilibré avec l'avantage que les éléments de ces ensembles ne se croisent pas. Leur répartition est présentée ci-dessous.
La répartition des classes dont le nombre d'éléments dépasse la valeur moyenne
La durée moyenne d'un segment de cet ensemble de données est également égale à 10 secondes
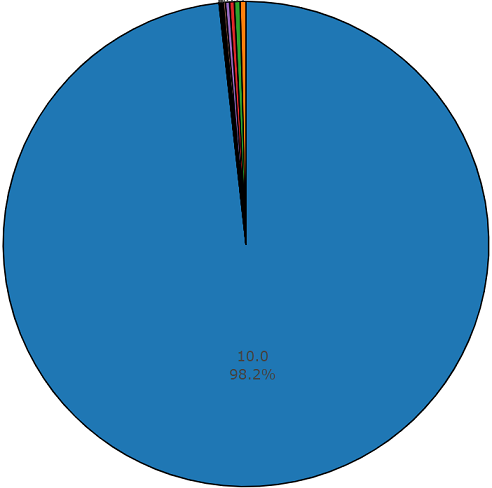
et le reste a la durée indiquée sur le schéma du disque
Exemple de code pour analyser et télécharger des données acoustiques conformément à l'ensemble de données sélectionné:
import plotly import plotly.graph_objs as go from collections import Counter import numpy as np import os import termcolor import csv import json import youtube_dl import subprocess
Pour obtenir des informations plus détaillées sur l'analyse des données de l'ensemble audio ou pour télécharger ces données à partir de l'espace yotube conformément au
fichier d'ontologie et à l'
ensemble audio sélectionné, le code du programme est disponible gratuitement dans
le référentiel GitHub .
Urbansound
Urbansound est l'un des plus grands ensembles de données avec des événements sonores balisés, dont les classes appartiennent à l'environnement urbain. Cet ensemble est appelé taxonomique (catégorique), c'est-à-dire chaque classe est divisée en ses sous-classes. Une telle multitude peut être représentée sous la forme d'un arbre.
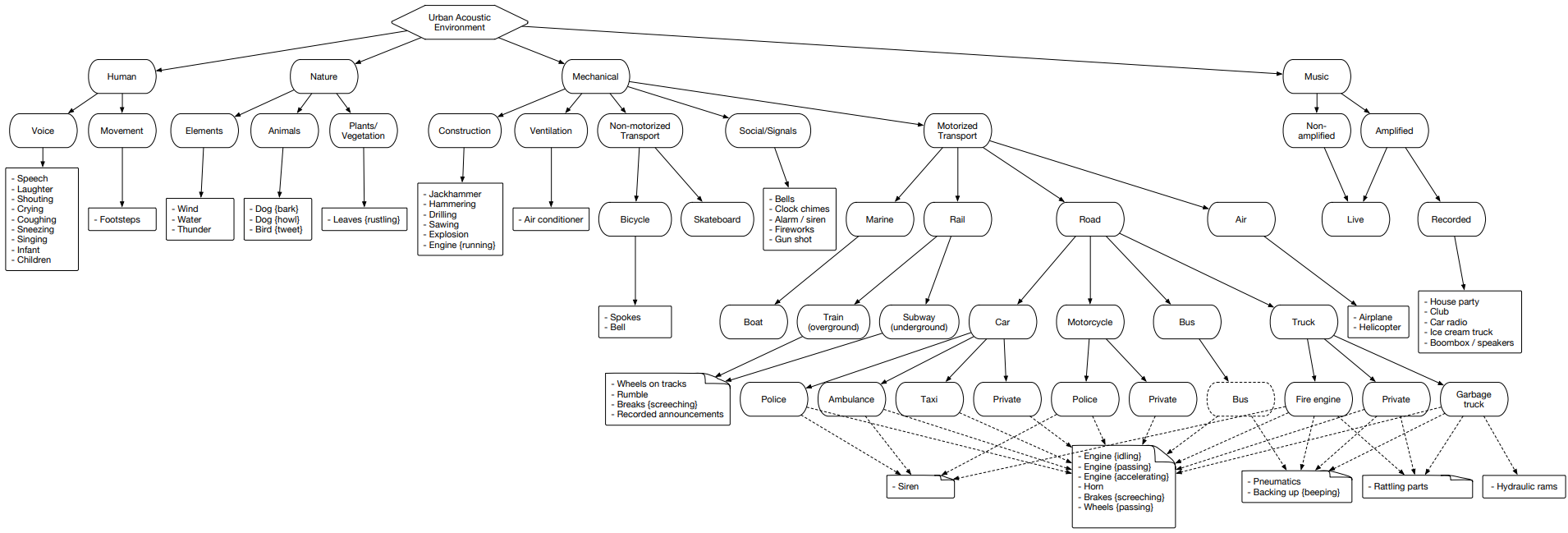
Pour télécharger des données urbansound pour une utilisation ultérieure, accédez simplement à la page et cliquez sur
télécharger .
Puisqu'il n'est pas nécessaire d'utiliser toutes les sous-classes dans la tâche et que vous n'avez besoin que d'une seule classe associée à la voiture, vous devez d'abord filtrer les classes nécessaires en utilisant le méta-fichier situé à la racine du répertoire obtenu lors de la décompression du fichier téléchargé.
Après avoir déchargé toutes les données nécessaires des sources répertoriées, il s'est avéré former un ensemble de données contenant plus de 15 000 fichiers. Un tel volume de données nous permet de passer à la tâche de former le classificateur acoustique, mais il reste un problème non résolu concernant la `` pureté '' des données, c'est-à-dire l'ensemble de formation comprend des données non liées aux classes nécessaires du problème à résoudre. Par exemple, lorsque vous écoutez des fichiers de la classe «briser le verre», vous pouvez trouver des gens qui parlent de «comment il n'est pas bon de briser le verre». Par conséquent, nous sommes confrontés à la tâche de filtrer les données et, comme outil pour résoudre ce type de problème, un outil est parfaitement adapté, dont le noyau a été développé par des gars biélorusses et a reçu le nom étrange "Yandex.Toloka".
Yandex.Toloka
Yandex.Toloka est un projet de financement participatif créé en 2014 pour baliser ou collecter une grande quantité de données pour une utilisation ultérieure dans l'apprentissage automatique. En fait, cet outil vous permet de collecter, marquer et filtrer des données à l'aide d'une ressource humaine. Oui, ce projet vous permet non seulement de résoudre des problèmes, mais permet également à d'autres personnes de gagner de l'argent. Dans ce cas, le fardeau financier vous incombe, mais en raison du fait que plus de 10 000 tolkers agissent de la part des artistes interprètes ou exécutants, les résultats du travail seront reçus dans un avenir proche. Une bonne description du fonctionnement de cet outil peut être trouvée sur le
blog Yandex .
En général, l'utilisation de l'écrasement n'est pas particulièrement difficile, car la publication d'une tâche ne nécessite qu'une inscription sur le
site , un montant minimum de 10 US dollars et une tâche correctement exécutée. Comment formuler correctement une tâche, vous pouvez voir la
documentation Yandex.Tolok ou il n'y a pas un mauvais
article sur Habr . De moi à cet article, je veux ajouter que même si un modèle adapté à l'exigence de votre tâche est manquant, son développement ne prendra pas plus de quelques heures de travail, avec une pause pour le café et la cigarette, et les résultats des artistes pourront être obtenus d'ici la fin de la journée de travail.
ConclusionDans l'apprentissage automatique, lors de la résolution du problème de classification ou de régression, l'une des principales tâches consiste à développer un ensemble de données fiable - un ensemble de données. Dans cet article, les sources d'information avec une grande quantité de données acoustiques ont été considérées qui ont permis de former et d'équilibrer l'ensemble de données nécessaire pour une tâche spécifique. Le code de programme présenté nous permet de simplifier au minimum le téléchargement de données, réduisant ainsi le temps de réception des données et de consacrer le reste à l'élaboration d'un classificateur.
Quant à ma tâche, après avoir collecté des données de toutes les sources présentées dans cet article et filtré les données par la suite, j'ai réussi à former l'ensemble de données nécessaire à la formation du classificateur acoustique, qui est basé sur un réseau de neurones. J'espère que cet article vous permettra, ainsi qu'à votre équipe, de gagner du temps et de le consacrer au développement de nouvelles technologies.
PS Un module logiciel développé en python, pour l'analyse et le téléchargement de données acoustiques pour chacune des sources présentées, que vous pouvez trouver dans
le référentiel github