
Cet article est une traduction de l'
article original
de Paid Nidrinhouse, ingénieur logiciel full-stack. Sa principale spécialité est JavaScript, mais Paige étudie également d'autres langages et frameworks. Et il partage son expérience avec ses lecteurs. Soit dit en passant, l'article sera intéressant pour les débutants.
Récemment, j'ai été confronté à une tâche qui m'intéressait - il était nécessaire d'extraire certaines données de l'énorme volume de fichiers non structurés de la US Federal Election Commission. Je n'ai pas trop travaillé avec des données brutes, j'ai donc décidé de relever le défi et de me charger de cette tâche. Pour le résoudre, j'ai choisi Node.js.
Skillbox recommande: Le cours en ligne Frontend Developer Profession .
Nous vous rappelons: pour tous les lecteurs de «Habr» - une remise de 10 000 roubles lors de l'inscription à un cours Skillbox en utilisant le code promotionnel «Habr».
La tâche a été décrite en quatre points:
- Le programme doit calculer le nombre total de lignes dans le fichier.
- Chaque huitième colonne contient le nom d'une personne. Vous devez charger ces données et créer un tableau avec tous les noms contenus dans le fichier. Il est nécessaire d'afficher les noms 432e et 43 243e.
- Chaque cinquième colonne contient la date du don des bénévoles. Comptez le nombre total de dons effectués chaque mois et imprimez le résultat total.
- Chaque huitième colonne contient le nom d'une personne. Créez un tableau en sélectionnant uniquement le prénom, sans le nom de famille. Découvrez quel nom est le plus souvent trouvé et combien de fois?
(La tâche d'origine peut être
consultée ici sur ce lien .)
Le fichier avec lequel vous devez travailler est un .txt régulier de 2,55 Go. Il existe également un dossier qui contient des parties du fichier principal (vous pouvez déboguer le programme dessus sans avoir à analyser l'ensemble du tableau énorme).
Deux solutions possibles sur Node.js
En principe, travailler avec des fichiers volumineux n'effraie pas un spécialiste JavaScript. De plus, c'est l'une des principales fonctions de Node.js. Il existe plusieurs solutions possibles pour lire et écrire dans des fichiers.
Le familier est fs.readFile (). Il vous permet de lire l'intégralité du fichier, de le mettre en mémoire, puis d'utiliser Node.
Une alternative est fs.createReadStream (), une fonction qui transmet des données similaires à la façon dont elles sont organisées dans d'autres langages - par exemple, en Python ou Java.
La solution que j'ai choisie
Comme j'avais besoin de calculer le nombre total de lignes et d'analyser les données pour analyser les noms et les dates, j'ai décidé de m'arrêter sur la deuxième option. Ici, je pourrais utiliser la fonction rl.on ('line', ...) pour obtenir les données nécessaires à partir des lignes.
Code Node.js CreateReadStream () et ReadFile ()
Voici le code que j'ai écrit en utilisant Node.js et la fonction fs.createReadStream ().
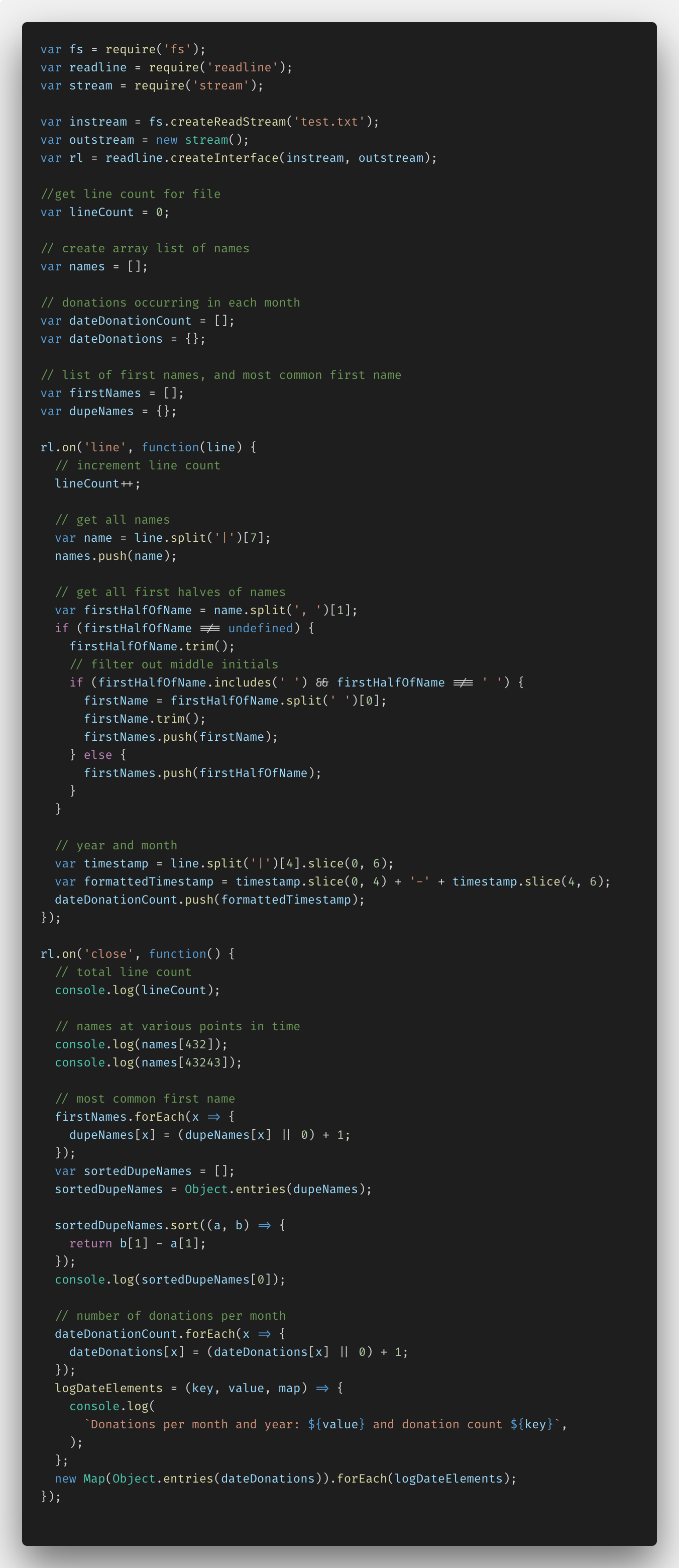
Au départ, je devais tout configurer, réalisant que l'importation de données nécessite des fonctions Node.js telles que fs (système de fichiers), readline et stream. Ensuite, j'ai pu créer instream et outstream avec readLine.createInterface (). Le code résultant a permis d'analyser le fichier ligne par ligne, en prenant les données nécessaires.
De plus, j'ai ajouté plusieurs variables et commentaires pour travailler avec des données spécifiques. Ce sont lineCount, dupeNames et des tableaux de noms, donation et prénoms.
Dans la fonction rl.on ('line', ...), j'ai pu définir l'analyse de fichiers ligne par ligne. J'ai donc entré la variable lineCount pour chaque ligne. J'ai utilisé la méthode JavaScript split () pour analyser les noms en les ajoutant à mon tableau de noms. Ensuite, je n'ai séparé que les noms sans nom, tout en soulignant les exceptions, comme la présence de doubles noms, les initiales au milieu du nom, etc. Ensuite, j'ai séparé l'année et la date de la colonne de données, convertissant tout cela au format YYYY-MM et ajoutant le dateDonationCount au tableau.
Dans la fonction rl.on ('close', ...), j'ai effectué toutes les transformations des données ajoutées aux tableaux, avec les informations reçues dans console.log.
lineCount et names sont nécessaires pour déterminer les noms 432th et 43,243rd; aucune conversion n'est requise ici. Mais l'identification du nom le plus courant dans le tableau et la détermination du nombre de dons sont des tâches plus compliquées.
Afin d'identifier le nom le plus courant, j'ai dû créer un objet de paires de valeurs pour chaque nom (clé) et le nombre de références à Object.entries (). (valeur), puis convertissez le tout en un tableau de tableaux à l'aide de la fonction ES6. Après cela, la tâche de trier les noms et d'identifier le plus de doublons n'était plus difficile.
Avec les dons, j'ai fait à peu près la même astuce: j'ai créé un objet de paires de valeurs et la fonction logDateElements (), qui m'a permis, en utilisant l'interpolation ES6, d'afficher les clés et les valeurs pour chaque mois. J'ai ensuite créé un nouveau Map (), convertissant l'objet dateDonations en un metamarray, et parcouru chaque tableau à l'aide de logDateElements (). (Cela n'a pas été aussi simple qu'il y paraissait au début.)
Mais cela a fonctionné, j'ai pu lire un fichier relativement petit de 400 Mo, mettant en évidence les informations nécessaires.
Après cela, j'ai essayé fs.createReadStream () - J'ai implémenté la tâche sur fs.readFile () afin de voir la différence. Voici le code:
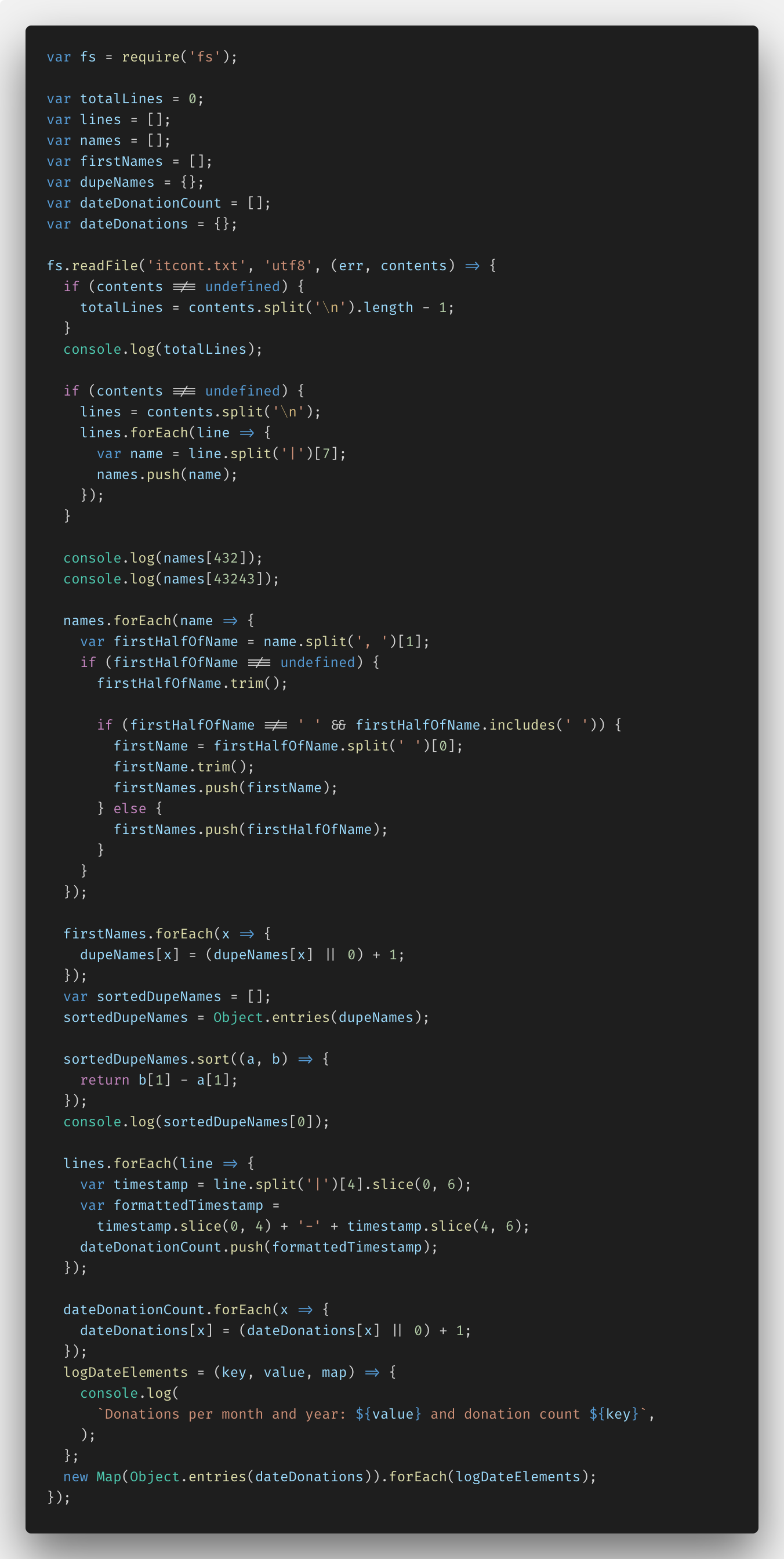
Vous pouvez voir toute la solution
ici .
Résultats de travail avec Node.js
La solution s'est avérée efficace. J'ai ajouté le chemin d'accès au fichier readFileStream.js et ... j'ai regardé le serveur Node se bloquer avec une erreur JavaScript de mémoire insuffisante.

Il s'est avéré que, bien que tout fonctionnait, mais cette solution a essayé de transférer tout le contenu du fichier en mémoire, ce qui était impossible avec une capacité de 2,55 Go. Le nœud peut fonctionner simultanément avec 1,5 Go de mémoire, pas plus.
Par conséquent, aucune de mes décisions n'a été prise. Il en a fallu un nouveau qui pourrait fonctionner même avec des fichiers aussi volumineux.
Nouvelle solution
Il s'est avéré qu'il était nécessaire d'utiliser le populaire module NPM EventStream.
Après avoir étudié la documentation, j'ai pu comprendre ce qui devait être fait. Voici la troisième version du code du programme.

La documentation du module indique que le flux de données doit être divisé en éléments séparés en utilisant le caractère \ n à la fin de chaque ligne du fichier txt.
Fondamentalement, la seule chose que j'ai dû changer était la réponse des noms. Je ne pouvais pas mettre 130 millions de noms dans la baie - l'erreur de manque de mémoire est à nouveau apparue. J'ai résolu le problème en calculant les noms 432e et 43 243e et en les ajoutant à mon propre tableau. Un peu pas ce qui a été demandé dans les conditions, mais qui a dit qu'on ne pouvait pas être créatif?
Round 2. Nous essayons le programme en cours
Oui, tout de même fichier avec un volume de 2,55 Go, on croise les doigts et on suit le résultat.
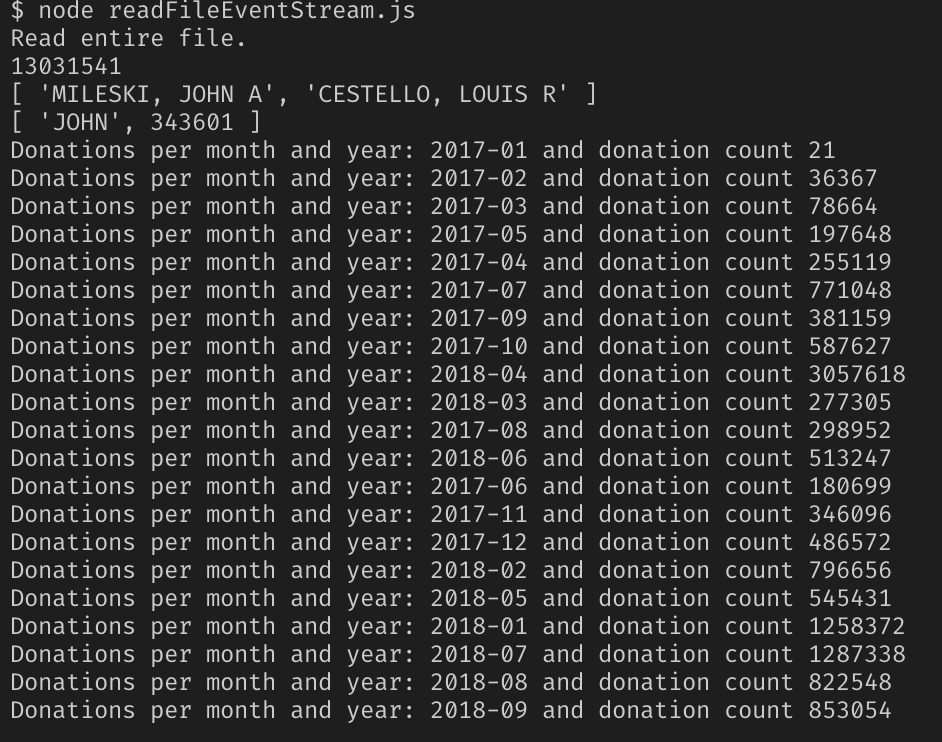
Succès!
Il s'est avéré que seul Node.js ne convient pas pour résoudre de tels problèmes, ses capacités sont quelque peu limitées. Mais en les développant à l'aide de modules, vous pouvez travailler avec des fichiers aussi volumineux.
Skillbox recommande: