Normalisation totale
J'ai préparé ce matériel pour mon discours à la conférence et j'ai demandé à notre directeur technique quelle était la principale caractéristique de Kubernetes pour notre organisation. Il a répondu:
Les développeurs eux-mêmes ne comprennent pas combien de travail supplémentaire ils ont accompli.
Apparemment, il a été inspiré par le livre «Factfulness» récemment lu - il est difficile de remarquer des changements mineurs et continus pour le mieux, et nous perdons constamment de vue nos progrès.
Mais le passage à Kubernetes n'est certainement pas insignifiant.

Près de 30 de nos équipes exécutent tout ou partie des charges de travail sur les clusters. Environ 70% de notre trafic HTTP est généré par des applications sur des clusters Kubernetes. Il s'agit probablement de la plus grande convergence de technologies depuis que j'ai rejoint l'entreprise après le rachat de uSwitch par Forward en 2010, lorsque nous sommes passés de .NET et de serveurs physiques à AWS et d'un système monolithique aux microservices .
Et tout s'est passé très rapidement. Fin 2017, toutes les équipes utilisaient leur infrastructure AWS. Ils ont mis en place des équilibreurs de charge, des instances EC2, des mises à jour de cluster ECS et des trucs comme ça. Un peu plus d'un an s'est écoulé et tout a changé.
Nous avons passé un minimum de temps à converger et, par conséquent, Kubernetes nous a aidés à résoudre des problèmes urgents - notre cloud se développait, l'organisation devenait plus compliquée et nous pouvions à peine intégrer de nouvelles personnes dans les équipes. Nous n'avons pas changé l'organisation pour utiliser Kubernetes. Au contraire, nous avons utilisé Kubernetes pour changer l'organisation.
Les développeurs n'ont peut-être pas remarqué de grands changements, mais les données parlent d'elles-mêmes. Plus d'informations à ce sujet plus tard.
Il y a de nombreuses années, j'étais à une conférence de Clojure et j'ai entendu une conférence de Michael Nygard sur l'architecture qui ne peut pas être amenée à son état final . Il m'a ouvert les yeux. Un système ordonné et ordonné semble caricatural lorsqu'il compare les magasins de télévision aux produits de cuisine et à l'architecture logicielle à grande échelle - le système existant ressemble à un couteau stupide, et une sorte de bouillie sort au lieu de tranches égales. Sans un nouveau couteau, il n'y a rien à penser à la salade.
Il s'agit de la façon dont les organisations adorent les projets sur trois ans: la première année est le développement et la préparation, la deuxième année est la mise en œuvre, la troisième est le retour. Dans une conférence, il dit que ces projets se font généralement en continu et arrivent rarement à la fin de la deuxième année (souvent en raison de l'acquisition par une autre entreprise et d'un changement de direction et de stratégie), donc l'architecture habituelle est
stratification du changement dans un semblant de stabilité.
Et uSwitch est un excellent exemple.
Nous sommes passés à AWS pour de nombreuses raisons - notre système ne pouvait pas faire face aux pics de charge, et l'organisation était entravée par un système trop rigide et des équipes étroitement liées formées pour des projets spécifiques et divisées par spécialisation.
Nous n'allions pas tout quitter, transférer tous les systèmes et recommencer. Nous avons créé de nouveaux services avec proxy via l'équilibreur de charge existant et étouffé progressivement l'ancienne application. Nous voulions montrer immédiatement le retour et dans la première semaine nous avons effectué des tests A / B de la première version du nouveau service en production. En conséquence, nous avons pris des produits à long terme et avons commencé à former des équipes pour eux de développeurs, designers, analystes, etc. Et nous avons immédiatement vu le résultat. En 2010, cela semblait être une véritable révolution.
Année après année, nous avons ajouté de nouvelles équipes, de nouveaux services et applications et «étranglé» progressivement le système monolithique. Les équipes ont progressé rapidement - maintenant, elles travaillent indépendamment les unes des autres et se composent de spécialistes dans tous les domaines nécessaires. Nous avons minimisé les interactions d'équipe pour les versions de produits. Nous avons alloué plusieurs commandes uniquement pour la configuration de l'équilibreur de charge.
Les équipes elles-mêmes ont choisi des méthodes de développement, des outils et des langages. Nous leur avons assigné une tâche, et ils ont eux-mêmes trouvé une solution, car ils étaient les mieux informés en la matière. Avec AWS, ces changements sont devenus plus faciles.
Nous avons intuitivement suivi les principes de la programmation - les équipes qui sont peu connectées les unes aux autres seront moins susceptibles de communiquer et nous n'aurons pas à dépenser de précieuses ressources pour coordonner leur travail. Tout cela est très bien décrit dans le livre récemment publié Accelerate .
En conséquence, comme Michael Nygard l'a décrit, nous avons obtenu un système de plusieurs couches de changements - certains systèmes ont été automatisés avec Puppet, certains avec Terraform, quelque part nous avons utilisé ECS, quelque part EC2.
En 2012, nous étions fiers de notre architecture, qui pouvait être facilement modifiée pour expérimenter , trouver des solutions réussies et les développer.
Mais en 2017, nous avons réalisé que beaucoup de choses avaient changé.
AWS est désormais beaucoup plus complexe qu'en 2010. Il offre une tonne d'options et de fonctionnalités, mais non sans conséquences. Aujourd'hui, toute équipe qui travaille avec EC2 doit choisir un VPC, une configuration réseau et bien plus encore.
Nous l'avons vécu par nous-mêmes - les équipes ont commencé à se plaindre qu'elles consacraient de plus en plus de temps à la maintenance de l'infrastructure, par exemple, la mise à jour des instances dans les clusters AWS ECS , les machines EC2, le passage des équilibreurs ELB à ALB, etc.
Mi-2017, lors d'un événement d'entreprise, j'ai exhorté chacun à standardiser son travail afin d'améliorer la qualité globale des systèmes. J'ai utilisé la métaphore de l'iceberg hackneyed pour montrer comment nous créons et maintenons le logiciel:

J'ai dit que la plupart des équipes de notre entreprise devraient créer des services ou des produits et se concentrer sur la résolution de problèmes, le code d'application, les plates-formes et les bibliothèques, etc. Dans cet ordre. Beaucoup de travail reste sous l'eau - intégration des journaux, augmentation de l'observabilité, gestion des secrets, etc.
À cette époque, chaque équipe de développeurs d'applications a géré la quasi-totalité de l'iceberg et a pris toutes les décisions par elle-même - en choisissant le langage, l'environnement de développement, la bibliothèque et l'outil de métriques, le système d'exploitation, le type d'instance, le stockage.
À la base de la pyramide, nous avions une infrastructure Amazon Web Services. Mais tous les services AWS ne sont pas identiques. Ils ont un Backend-as-a-Service (BaaS) , par exemple pour l'authentification et le stockage des données. Et il existe d'autres services de niveau relativement bas, comme EC2. Je voulais étudier les données et comprendre que les équipes ont des raisons de se plaindre et qu'elles passent vraiment plus de temps à travailler avec des services de bas niveau et prennent beaucoup de décisions pas les plus importantes.
J'ai divisé les services en catégories, en utilisant CloudTrail, j'ai collecté toutes les statistiques disponibles, puis j'ai utilisé BigQuery , Athena et ggplot2 pour voir comment la situation des développeurs a changé récemment. Une croissance pour des services tels que RDS, Redshift, etc., que nous considérons souhaitable (et attendue), et une croissance pour EC2, CloudFormation, etc. - au contraire.

Chaque point du diagramme montre les 90e (rouge), 80e (vert) et 50e (bleu) centiles pour le nombre de services de bas niveau que nos employés ont utilisés chaque semaine pendant une certaine période. J'ai ajouté des lignes de lissage pour montrer la tendance.
Bien que nous ayons visé des abstractions de niveau supérieur lors du déploiement de logiciels, par exemple à l'aide de conteneurs et d' Amazon ECS , nos développeurs ont régulièrement utilisé de plus en plus de services AWS et n'ont pas suffisamment ignoré les difficultés de gestion des systèmes. En deux ans, le nombre de services a doublé pour 50% des salariés et presque triplé pour 20%.
Cela a limité la croissance de notre entreprise. Les équipes ont cherché l'autonomie, mais comment embaucher de nouvelles personnes? Nous avions besoin de développeurs d'applications et de produits solides et d'une connaissance du système AWS de plus en plus sophistiqué.
Nous voulions élargir nos équipes et en même temps préserver les principes avec lesquels nous avons réussi: autonomie, coordination minimale et infrastructure libre-service.
Avec Kubernetes, nous avons accompli cela avec des abstractions axées sur les applications et la possibilité de maintenir et de configurer des clusters avec une coordination d'équipe minimale.
Abstractions axées sur l'application
Les concepts de Kubernetes sont faciles à associer au langage utilisé par le développeur d'applications. Supposons que vous gérez des versions d'application en tant que déploiement . Vous pouvez exécuter plusieurs répliques derrière le service et les mapper à HTTP via Ingress . Et grâce aux ressources utilisateur, vous pouvez étendre et spécialiser cette langue en fonction de vos besoins.
Les équipes travaillent plus efficacement avec ces abstractions. Fondamentalement, cet exemple contient tout ce dont vous avez besoin pour déployer et exécuter une application Web. Le reste est Kubernetes.
Dans l'image avec l'iceberg, ces concepts sont au niveau de l'eau et combinent les tâches du développeur d'en haut avec la plate-forme ci-dessous. L'équipe de gestion du cluster peut prendre des décisions de bas niveau et insignifiantes (concernant la gestion des métriques, la journalisation, etc.) et en même temps parler le même langage avec les développeurs au-dessus de l'eau.
En 2010, uSwitch avait des équipes traditionnelles pour la maintenance d'un système monolithique, et plus récemment, nous avions un service informatique qui gérait partiellement notre compte AWS. Il me semble que le manque de concepts communs a sérieusement entravé le travail de cette équipe.
Essayez de dire quelque chose d'utile si vous n'avez que des instances EC2 dans votre vocabulaire, des équilibreurs de charge et des sous-réseaux. Il était difficile, voire impossible, de décrire l'essence de la demande. Il peut s'agir d'un paquet Debian, d'un déploiement via Capistrano, etc. Nous n'avons pas pu décrire l'application dans une langue commune à tous.
Au début des années 2000, j'ai travaillé chez ThoughtWorks à Londres. Lors de l'entrevue, on m'a conseillé de lire la conception axée sur les problèmes d' Eric Evans. J'ai acheté un livre sur le chemin du retour et j'ai commencé à lire dans le train. Depuis lors, je me souviens d'elle dans presque tous les projets et systèmes.
L'un des principaux concepts du livre est une langue unique dans laquelle différentes équipes communiquent. Kubernetes fournit simplement un tel langage unifié aux développeurs et aux équipes de maintenance des infrastructures, et c'est l'un de ses principaux avantages. De plus, il peut être étendu et complété par d'autres domaines et secteurs d'activité.
La communication dans un langage commun est plus productive, mais nous devons quand même limiter autant que possible l'interaction entre les équipes.
Minimum d'interaction nécessaire
Les auteurs d' Accelerate mettent en évidence les caractéristiques d'une architecture faiblement couplée avec laquelle les équipes informatiques travaillent plus efficacement:
En 2017, le succès de la livraison continue dépendait de la capacité de l'équipe à:
Changez sérieusement la structure de votre système sans l'autorisation de la direction.
Changez sérieusement la structure de votre système, sans attendre que les autres équipes changent la leur, et sans créer beaucoup de travail inutile pour les autres équipes.
Effectuer leurs tâches sans communiquer ni coordonner leur travail avec les autres équipes.
Déployez et publiez un produit ou un service à la demande, quels que soient les autres services qui lui sont associés.
Faites la plupart des tests à la demande, sans environnement de test intégré.
Nous avions besoin de grappes logicielles multi-locataires centralisées pour toutes les équipes, mais en même temps, nous voulions maintenir ces caractéristiques. Nous n'avons pas encore atteint l'idéal, mais nous essayons du mieux que nous pouvons:
- Nous avons plusieurs clusters de travail, et les équipes choisissent elles-mêmes où exécuter l'application. Nous n'utilisons pas encore la fédération (nous attendons la prise en charge d'AWS), mais nous avons Envoy pour l'équilibrage de charge sur les équilibreurs Ingress dans différents clusters. Nous automatisons la plupart de ces tâches à l'aide du pipeline de livraison continue (nous avons Drone ) et d'autres services AWS.
- Tous les clusters ont le même espace de noms . Environ un pour chaque équipe.
- Nous contrôlons l'accès aux espaces de noms via RBAC (contrôle d'accès basé sur les rôles). Pour l'authentification et l'autorisation, nous utilisons l'identité d'entreprise dans Active Directory.
- Les clusters évoluent automatiquement et nous faisons de notre mieux pour optimiser le temps de démarrage du nœud. Cela prend encore quelques minutes, mais, en général, même avec de grandes charges de travail, nous faisons sans coordination.
- Les applications évoluent automatiquement en fonction des mesures au niveau de l'application de Prometheus. Les équipes de développement contrôlent la mise à l'échelle automatique de leur application par des métriques de requête par seconde, des opérations par seconde, etc. Grâce à la mise à l'échelle automatique du cluster, le système prépare les nœuds lorsque la demande dépasse les capacités du cluster actuel.
- Nous avons écrit Go avec un outil en ligne de commande appelé u qui standardise l'authentification des commandes dans Kubernetes, utilise Vault , les demandes d'informations d'identification AWS temporaires, etc.
Je ne suis pas sûr qu'avec Kubernetes nous ayons plus d'autonomie, mais il est définitivement resté à un niveau élevé, et en même temps nous nous sommes débarrassés de certains problèmes.
Le passage à Kubernetes a été rapide. Le diagramme montre le nombre total d'espaces de noms (approximativement égal au nombre de commandes) dans nos clusters de travail. Le premier est apparu en février 2017.
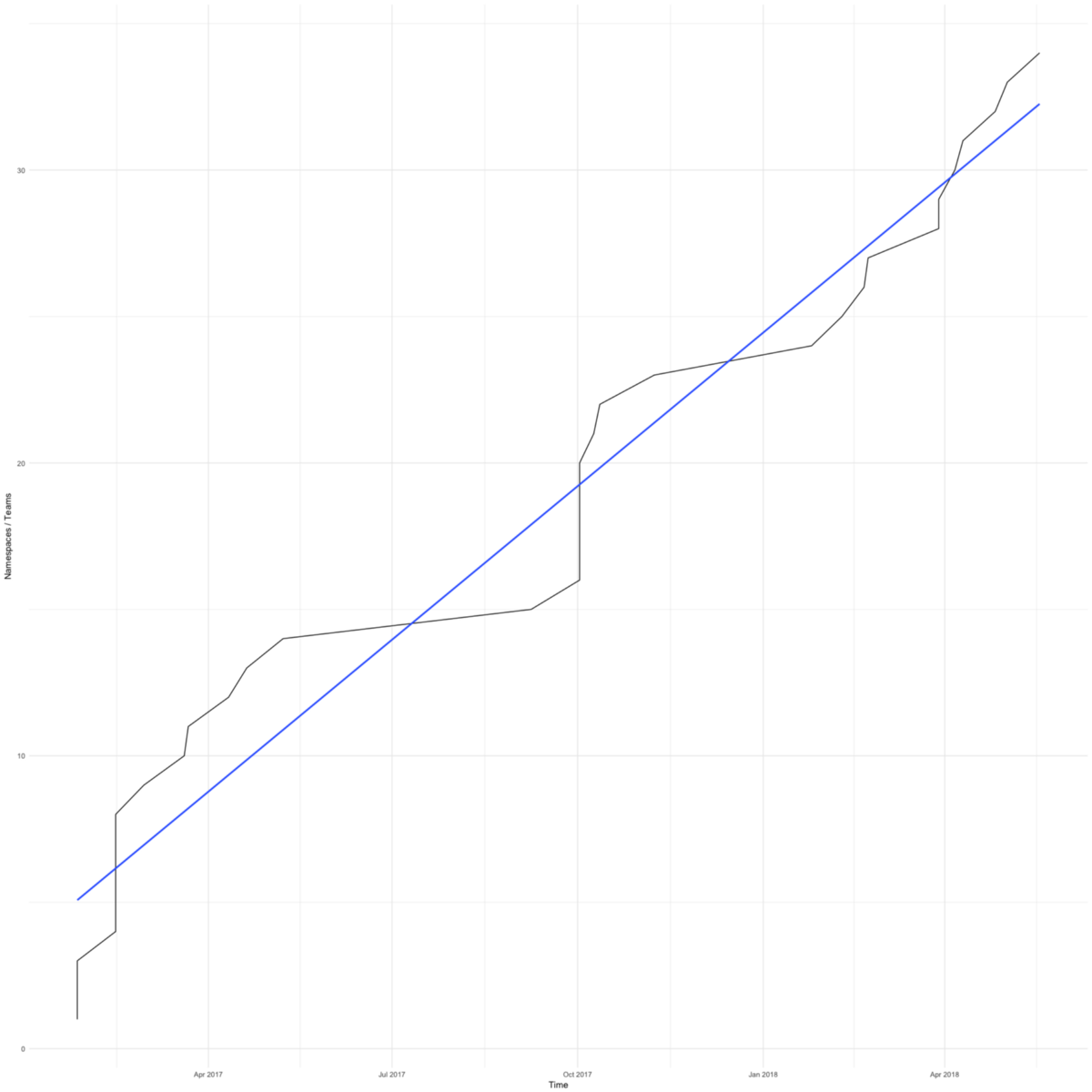
Nous avions des raisons de nous précipiter - nous voulions éviter que les petites équipes focalisées sur leur produit ne se soucient de l'infrastructure.
La première équipe a accepté de passer à Kubernetes lorsque leur serveur d'applications a manqué d'espace en raison de paramètres de rotation du journal incorrects. La transition n'a pris que quelques jours et ils se sont de nouveau mis au travail.
Récemment, les équipes sont passées à Kubetnetes pour des outils améliorés. Les clusters Kubernetes simplifient l'intégration avec notre Hashicorp Vault , Google Cloud Trace et des outils similaires. Toutes nos équipes bénéficient de fonctionnalités encore plus efficaces.
J'ai déjà montré un graphique avec des centiles du nombre de services que nos employés ont utilisés chaque semaine de la fin de 2014 à 2017. Et voici une suite de ce diagramme à ce jour.
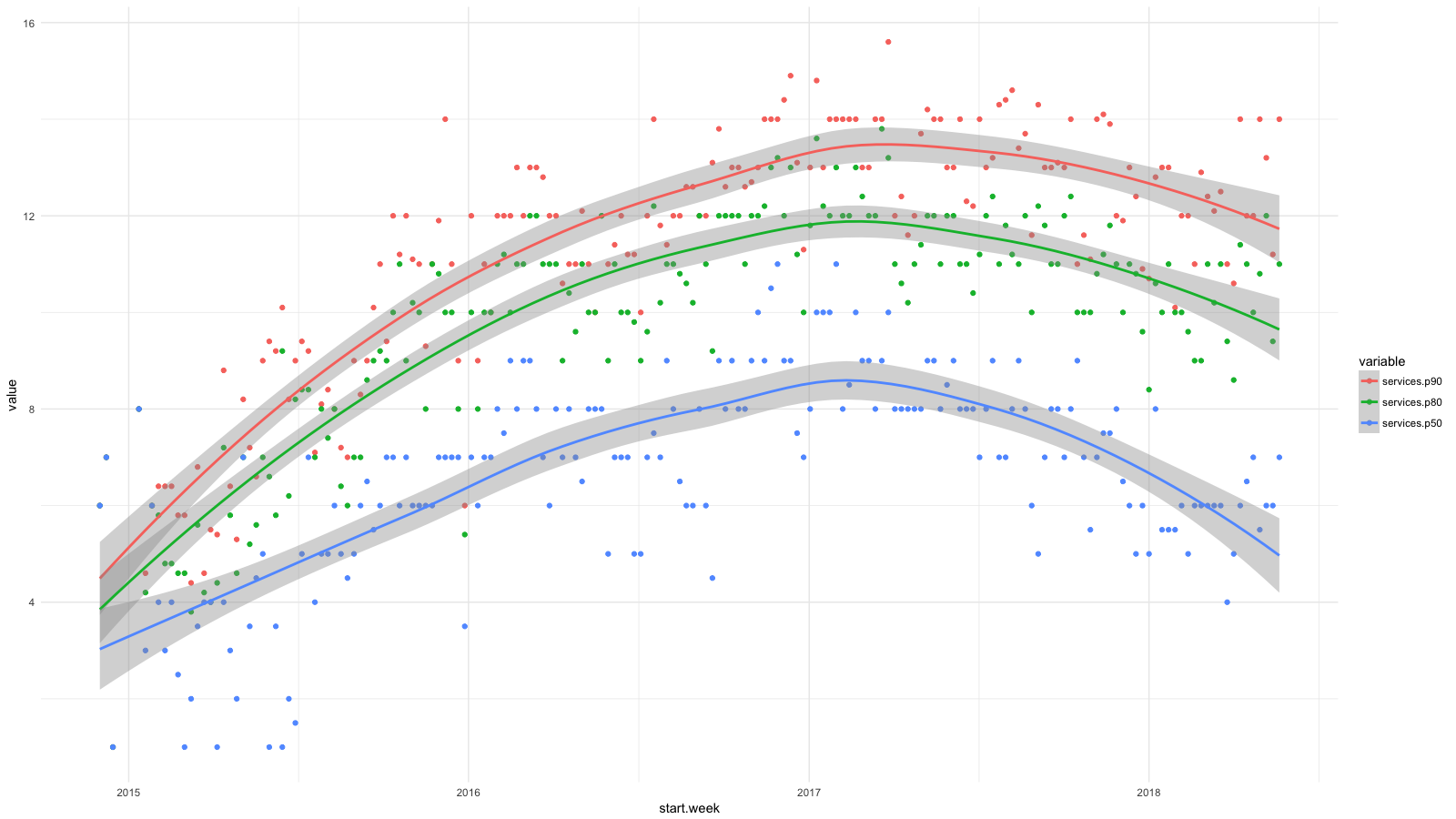
Nous avons progressé dans la gestion du cadre AWS complexe. Je suis heureux que maintenant la moitié des employés fassent la même chose qu'au début de 2015. Nous avons 4 à 6 employés dans l'équipe de cloud computing, quelque part autour de 10% du nombre total - il n'est pas surprenant que le 90e centile n'ait presque pas bougé. Mais j'espère que des progrès ici aussi.
Enfin, je vais parler de la façon dont notre cycle de développement a changé, et encore une fois rappeler le livre Accelerate récemment lu.
Le livre mentionne deux mesures de développement allégées: le délai d'exécution et la taille du package. Le délai est pris en compte de la demande à la livraison de la solution finie. La taille de l'emballage est la quantité de travail. Plus la taille de l'emballage est petite, plus le travail est efficace:
Plus l'emballage est petit, plus le cycle de production est court, moins la variabilité du processus, moins de risques, de coûts et de coûts, nous obtenons des commentaires plus rapidement, travaillons plus efficacement, nous avons plus de motivation, nous essayons de terminer plus rapidement et de reporter la livraison moins souvent.
Le livre suggère de mesurer la taille des paquets par fréquence de déploiement - plus le déploiement est fréquent, plus les paquets sont petits.
Nous avons des données pour certains déploiements. Les données ne sont pas tout à fait exactes - certaines équipes envoient des versions directement à la branche principale du référentiel, d'autres utilisent d'autres mécanismes. Cela ne comprend pas toutes les demandes, mais les données sur 12 mois peuvent être considérées comme indicatives.
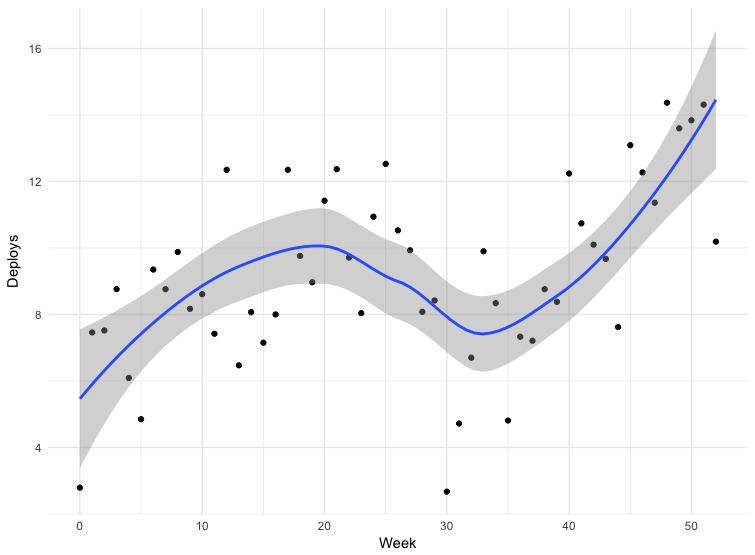
L'échec de la trentième semaine est Noël. Pour le reste, nous voyons que la fréquence de déploiement augmente, ce qui signifie que la taille des paquets diminue. De mars à mai 2018, la fréquence des sorties a presque doublé, et récemment nous faisons parfois plus d'une centaine de numéros par jour.
Le passage à Kubernetes n'est qu'une partie de notre stratégie de standardisation, d'automatisation et d'amélioration des outils. Très probablement, tous ces facteurs ont influencé la fréquence des rejets.
Accelerate parle également de la relation entre la fréquence de déploiement et le nombre d'employés, et de la rapidité avec laquelle une entreprise peut travailler si le personnel est augmenté. Les auteurs soulignent les limites de l'architecture et des équipes associées:
On pense traditionnellement que l'expansion d'une équipe augmente la productivité globale, mais diminue la productivité des développeurs individuels.
Si nous prenons les mêmes données sur la fréquence des déploiements et faisons un diagramme de la dépendance au nombre d'utilisateurs, nous pouvons voir que nous pouvons augmenter la fréquence des versions, même si nous avons plus de personnes.

Au début de l'article, j'ai mentionné le livre Factfulness (qui a inspiré notre CTO). La transition vers Kubernetes est devenue pour nos développeurs la convergence technologique la plus importante et la plus rapide. Nous progressons par petites étapes, et il est facile de ne pas remarquer à quel point tout a changé pour le mieux. C'est bien que nous ayons des données, et elles montrent que nous avons réalisé ce que nous voulons - nos employés sont engagés dans leur produit et prennent des décisions importantes dans leur domaine.
Avant, c'était bon pour nous. Nous avions des microservices, AWS, des équipes bien établies pour les produits, des développeurs responsables de leurs services en production, des équipes et une architecture faiblement couplées. J'en ai parlé dans le rapport «Notre âge des Lumières» («Notre âge des Lumières») lors d'une conférence en 2012. Mais il n'y a pas de limite à la perfection.
En fin de compte, je veux citer un autre livre - Scale . Je l'ai commencé récemment et il y a un fragment intéressant sur la consommation d'énergie dans les systèmes complexes:
Pour maintenir l'ordre et la structure dans un système en développement, un apport constant d'énergie est nécessaire et crée un désordre. Par conséquent, pour maintenir la vie, nous devons manger tout le temps afin de vaincre l'entropie inévitable.
Nous combattons l'entropie en fournissant plus d'énergie pour la croissance, l'innovation, l'entretien et la réparation, ce qui devient plus difficile avec le vieillissement du système, et cette bataille est la base de toute discussion sérieuse sur le vieillissement, la mortalité, la durabilité et l'autosuffisance de tout système, qu'il s'agisse d'un organisme vivant , entreprise ou société.
Je pense que vous pouvez ajouter des systèmes informatiques ici. J'espère que nos derniers efforts garderont l'entropie même pendant un certain temps.