Bonjour, les gardes. La publication d'aujourd'hui portera sur la façon de ne pas se perdre dans la nature des nombreuses options d'utilisation de TensorFlow pour l'apprentissage automatique et d'atteindre votre objectif. L'article est conçu pour que le lecteur connaisse les bases des principes de l'apprentissage automatique, mais n'a pas encore essayé de le faire de ses propres mains. En conséquence, nous obtenons une démo fonctionnelle sur Android, qui reconnaît quelque chose avec une précision assez élevée. Mais tout d'abord.

Après avoir examiné les derniers documents, il a été décidé de faire appel à Tensorflow , qui prend maintenant de l'ampleur, et les articles en anglais et en russe semblent être suffisants pour ne pas creuser dans cela et réussir à comprendre ce qui est quoi.
Passer deux semaines, étudier des articles et de nombreux ex-échantillons au bureau. site, j'ai réalisé que je ne comprenais rien. Trop d'informations et d'options sur la façon dont Tensorflow peut être utilisé. Ma tête est déjà gonflée de voir à quel point ils proposent des solutions différentes et ce que j'en fais, tel qu'appliqué à ma tâche.

J'ai ensuite décidé de tout essayer, des options les plus simples et les plus prêtes à l'emploi (dans lesquelles je devais enregistrer une dépendance dans gradle et ajouter quelques lignes de code) aux plus complexes (dans lesquelles je devrais créer et former nous-mêmes des modèles graphiques et apprendre à les utiliser dans un mobile application).
Au final, j'ai dû utiliser une version compliquée, qui sera discutée plus en détail ci-dessous. En attendant, j'ai compilé pour vous une liste d'options plus simples et tout aussi efficaces, chacune s'adaptant à son objectif.

La solution la plus simple à utiliser - quelques lignes de code que vous pouvez utiliser:
- Reconnaissance de texte (texte, caractères latins)
- Détection des visages (visages, émotions)
- Numérisation de codes-barres (code-barres, code qr)
- Étiquetage d'image (un nombre limité de types d'objets dans l'image)
- Reconnaissance historique (attractions)
C'est un peu plus compliqué. Avec cette solution, vous pouvez également utiliser votre propre modèle TensorFlow Lite, mais la conversion à ce format a posé des problèmes, donc cet élément n'a pas été essayé.
Comme l'écrivent les créateurs de cette progéniture, la plupart des tâches peuvent être résolues à l'aide de ces développements. Mais si cela ne s'applique pas à votre tâche, vous devrez utiliser des modèles personnalisés.

Un outil très pratique pour créer et former vos modèles personnalisés à l'aide d'images.
Des pros - il existe une version gratuite qui vous permet de garder un projet.
Des inconvénients - la version gratuite limite le nombre d'images «entrantes» à 3 000. Pour essayer de créer un réseau de précision médiocre - cela suffit. Pour des tâches plus précises, vous en avez besoin de plus.
Tout ce qui est requis de l'utilisateur est d'ajouter des images avec une marque (par exemple - image1 est "racoon", image2 est "sun"), former et exporter le graphique pour une utilisation future.
Caring Microsoft propose même son propre échantillon , avec lequel vous pouvez essayer votre graphique reçu.
Pour ceux qui sont déjà «dans le sujet» - le graphique est déjà généré à l'état Frozen, c'est-à-dire vous n'avez pas besoin de faire / convertir quoi que ce soit avec.
Cette solution est bonne lorsque vous avez un grand échantillon et (beaucoup d'attention) de différentes classes en formation. Parce que sinon, il y aura de nombreuses fausses définitions dans la pratique. Par exemple, vous vous êtes entraîné sur les ratons laveurs et les soleils, et s'il y a une personne à l'entrée, alors elle peut, avec une probabilité égale, être définie par un système comme l'un ou l'autre. Bien qu'en fait - ni l'un ni l'autre.
3. Création manuelle d'un modèle

Lorsque vous devez affiner vous-même le modèle pour la reconnaissance d'image, des manipulations plus complexes avec la sélection d'image d'entrée entrent en jeu.
Par exemple, nous ne voulons pas avoir de restrictions sur le volume de l'échantillon d'entrée (comme dans le paragraphe précédent), ou nous voulons former le modèle plus précisément en définissant nous-mêmes le nombre d'époque et d'autres paramètres d'apprentissage.
Dans cette approche, il existe plusieurs exemples de Tensorflow qui décrivent la procédure et le résultat final.
Voici quelques exemples:
Il donne un exemple de la façon de créer un classificateur de types de couleurs basé sur la base de données d'images ouverte ImageNet - préparer des images, puis former le modèle. Une petite mention est également faite de la façon dont vous pouvez travailler avec un outil plutôt intéressant - TensorBoard. De ses fonctions les plus simples - il démontre clairement la structure de votre modèle fini, ainsi que le processus d'apprentissage à bien des égards.
Kodlab Tensorflow for Poets 2 - poursuite du travail avec le classificateur de couleurs. Il montre comment si vous avez les fichiers graphiques et leurs étiquettes (qui ont été obtenus dans le codelab précédent), vous pouvez exécuter l'application sur Android. Un des points du codelab est la conversion du format graphique "habituel" ".pb" au format Tensorflow lite (qui implique des optimisations de fichier pour réduire la taille finale du fichier graphique, car les appareils mobiles en ont besoin).
Reconnaissance de l'écriture manuscrite MNIST .
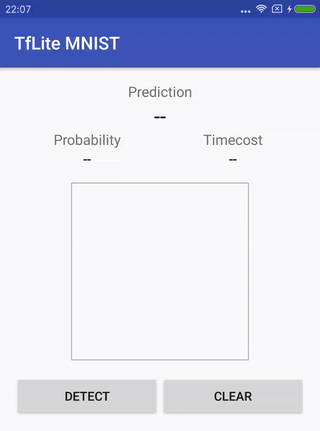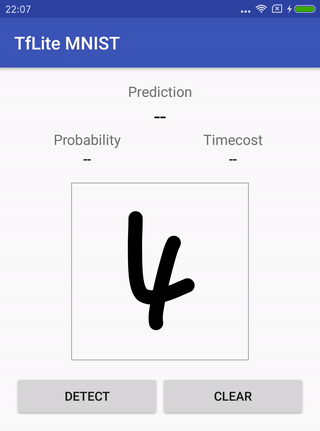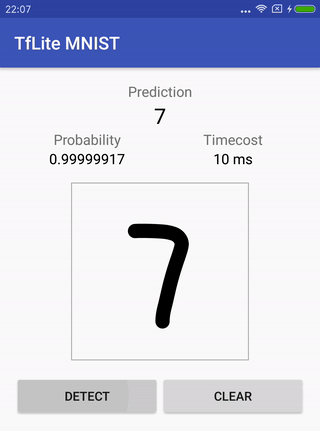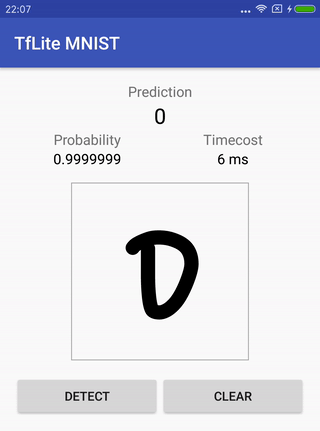
Le navet contient le modèle d'origine (qui a déjà été préparé pour cette tâche), des instructions sur la façon de le former, le convertir et comment exécuter un projet pour Android à la fin pour vérifier comment tout cela fonctionne.
Sur la base de ces exemples, vous pouvez comprendre comment travailler avec des modèles personnalisés dans Tensorflow et essayer de créer le vôtre ou de prendre l'un des modèles pré-formés qui sont assemblés sur un github:
Modèles de Tensorflow
Parlant de modèles "pré-formés". Nuances intéressantes lors de leur utilisation:
- Leur structure est déjà préparée pour une tâche spécifique.
- Ils sont déjà formés à de grands échantillons.
Par conséquent, si votre échantillon n'est pas suffisamment rempli, vous pouvez prendre un modèle pré-formé qui est proche de la portée de votre tâche. En utilisant ce modèle, en ajoutant vos propres règles de formation, vous obtiendrez un meilleur résultat que vous n'essaieriez de former le modèle à partir de zéro.
4. API de détection d'objets + création manuelle de modèle
Cependant, tous les paragraphes précédents n'ont pas donné le résultat souhaité. Dès le début, il était difficile de comprendre ce qui devait être fait et avec quelle approche. Ensuite, un article sympa sur l' API de détection d'objets a été trouvé, qui explique comment trouver plusieurs catégories sur une image, ainsi que plusieurs instances de la même catégorie. Dans le processus de travail sur cet exemple, les articles sources et les didacticiels vidéo sur la reconnaissance des objets personnalisés se sont avérés plus pratiques (les liens seront à la fin).
Mais le travail n'aurait pas pu être achevé sans un article sur la reconnaissance de Pikachu - car une nuance très importante y a été soulignée, qui pour une raison quelconque n'est mentionnée nulle part dans un guide ou un exemple. Et sans cela, tout le travail accompli serait vain.
Alors, maintenant enfin sur ce qui restait à faire et ce qui s'est passé à la sortie.
- Tout d'abord, la farine de l'installation Tensorflow. Qui ne peut pas l'installer ou utiliser les scripts standard pour créer, former un modèle - soyez patient et google. Presque tous les problèmes ont déjà été écrits dans des problèmes sur githib ou sur stackoverflow.
Selon les instructions pour la reconnaissance d'objets, nous devons préparer un échantillon d'entrée avant de former le modèle. Ces articles décrivent en détail comment procéder à l'aide d'un outil pratique - labelImg. La seule difficulté ici est de faire un travail très long et minutieux pour mettre en évidence les limites des objets dont nous avons besoin. Dans ce cas, tampons sur des images de documents.
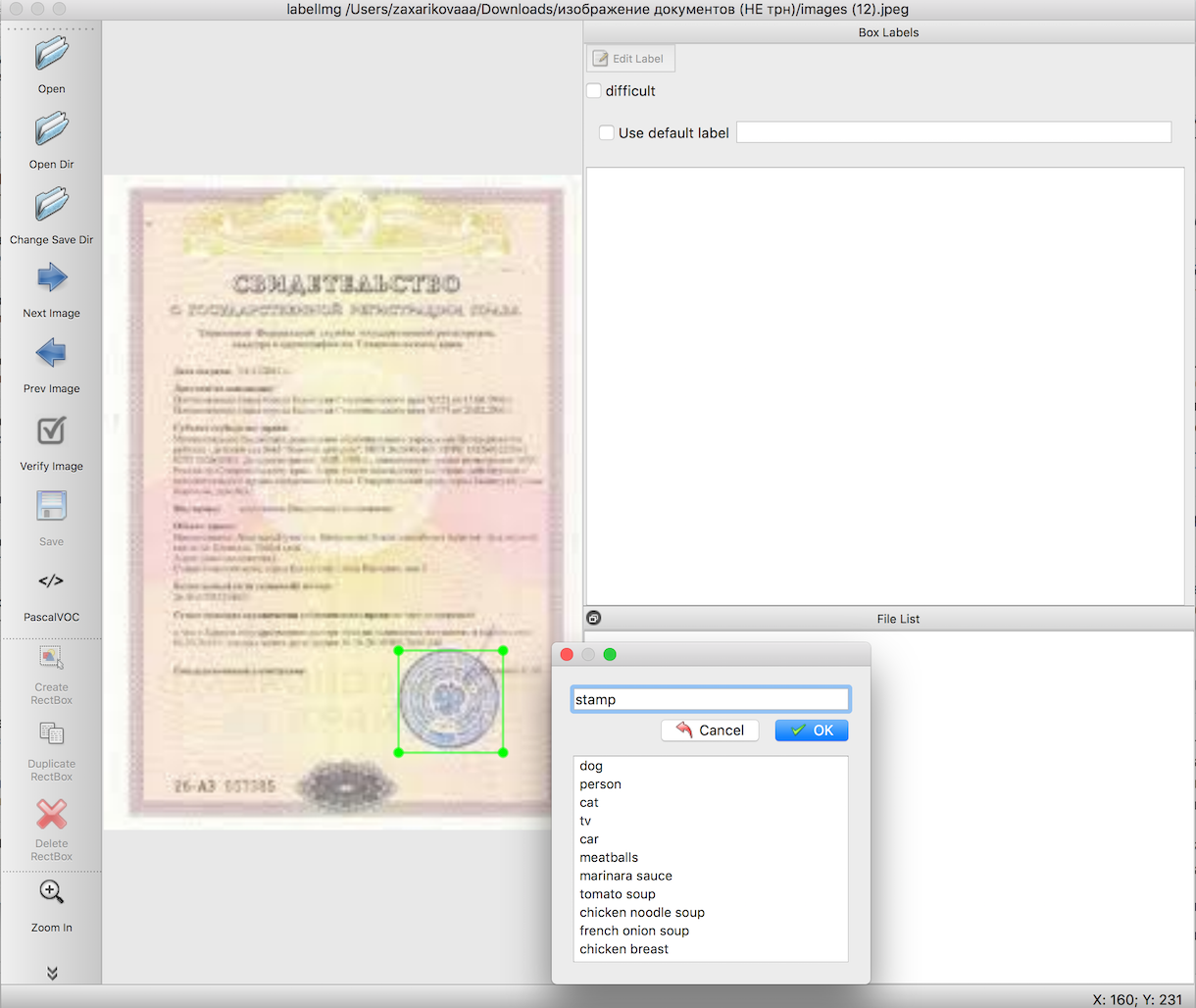
L'étape suivante, à l'aide de scripts prêts à l'emploi, nous exportons les données de l'étape 2 d'abord vers des fichiers csv, puis vers TFRecords - le format de données d'entrée Tensorflow. Aucune difficulté ne devrait survenir ici.
Le choix d'un modèle pré-formé, sur la base duquel nous allons pré-former le graphique, ainsi que la formation elle-même. C'est là que le plus grand nombre d'erreurs inconnues peut se produire, dont la cause est les packages désinstallés (ou installés de manière incorrecte) nécessaires au travail. Mais vous réussirez, ne désespérez pas, le résultat en vaut la peine.

Exportez le fichier reçu après la formation au format 'pb'. Sélectionnez simplement le dernier fichier 'ckpt' et exportez-le.
Exécution d'un exemple de travail sur Android.
Téléchargement de l'échantillon de reconnaissance d'objet officiel à partir du github Tensorflow -
TF Detect . Insérez-y votre modèle et votre fichier avec des étiquettes. Mais. Rien ne fonctionnera.

C'est là que le plus grand gag dans tout le travail vient de se produire, assez curieusement - eh bien, les échantillons Tensorflow ne voulaient en aucun cas fonctionner. Tout est tombé. Seul le puissant Pikachu avec son article a réussi à tout faire fonctionner.
La première ligne du fichier labels.txt doit être l'inscription "???", car par défaut dans l'API Object Detection, les numéros d'identification des objets ne commencent pas par 0 comme d'habitude, mais par 1. En raison du fait que la classe null est réservée, des questions magiques doivent être indiquées. C'est-à-dire votre fichier de balises ressemblera à ceci:
??? stamp
Et puis - exécutez l'échantillon et voyez la reconnaissance des objets et le niveau de confiance avec lequel il a été reçu.
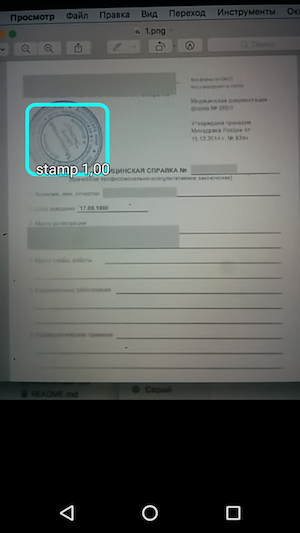
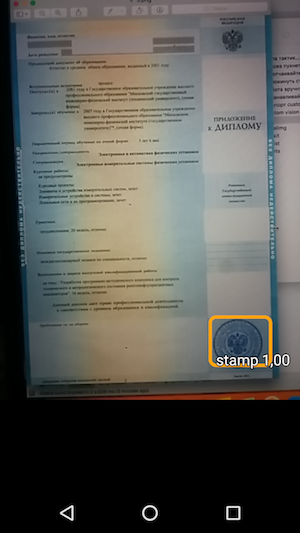
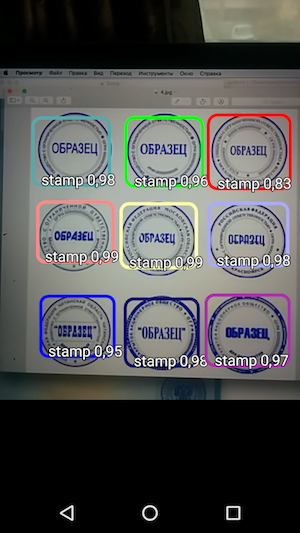
Ainsi, le résultat est une application simple qui, lorsque vous survolez l'appareil photo, reconnaît les limites du tampon sur le document et les indique avec la précision de reconnaissance.
Et si l'on exclut le temps passé à chercher la bonne approche et à essayer de la lancer, alors, dans l'ensemble, le travail s'est avéré assez rapide et vraiment pas compliqué. Vous avez juste besoin de connaître les nuances avant de commencer à travailler.
Déjà en tant que section supplémentaire (ici, vous pouvez déjà fermer l'article si vous êtes fatigué des informations), je voudrais écrire quelques astuces de vie qui ont aidé à travailler avec tout cela.
assez souvent, les scripts tensorflow ne fonctionnaient pas car ils étaient exécutés à partir de mauvais répertoires. De plus, c'était différent sur différents PC: quelqu'un devait s'exécuter à partir du tensroflowmodels/models/research pour travailler, et quelqu'un tensroflowmodels/models/research/object-detection niveau plus profond à partir du tensroflowmodels/models/research/object-detection
rappelez-vous que pour chaque terminal ouvert, vous devez réexporter le chemin à l'aide de la commande
export PYTHONPATH=/ /tensroflowmodels/models/research/slim:$PYTHONPATH
si vous n'utilisez pas votre propre graphique et que vous souhaitez en savoir plus (par exemple, " input_node_name ", qui sera requis plus tard), exécutez deux commandes à partir du dossier racine:
bazel build tensorflow/tools/graph_transforms:summarize_graph bazel-bin/tensorflow/tools/graph_transforms/summarize_graph --in_graph="/ /frozen_inference_graph.pb"
où " / /frozen_inference_graph.pb " est le chemin d'accès au graphique que vous souhaitez connaître
Pour afficher des informations sur le graphique, vous pouvez utiliser Tensorboard.
python import_pb_to_tensorboard.py --model_dir=output/frozen_inference_graph.pb --log_dir=training
où vous devez spécifier le chemin d'accès au graphique ( model_dir ) et le chemin d'accès aux fichiers reçus pendant la formation ( log_dir ). Ensuite, ouvrez simplement localhost dans le navigateur et regardez ce qui vous intéresse.
Et la dernière partie - sur l'utilisation des scripts python dans les instructions de l'API Object Detection - une petite feuille de triche ci-dessous avec des commandes et des conseils a été préparée pour vous.
Feuille de tricheExporter de labelimg vers csv (depuis le répertoire object_detection)
python xml_to_csv.py
De plus, toutes les étapes énumérées ci-dessous doivent être effectuées à partir du même dossier Tensorflow (" tensroflowmodels/models/research/object-detection " ou d'un niveau supérieur - selon la façon dont vous allez) - c'est tout les images de la sélection d'entrée, des TFRecords et d'autres fichiers doivent être copiés dans ce répertoire avant de commencer le travail.
Exporter de csv vers tfrecord
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record
* N'oubliez pas de changer les lignes 'train' et 'test' dans les chemins du fichier lui-même (generate_tfrecord.py), ainsi que
le nom des classes reconnues dans la fonction class_text_to_int (qui doit être dupliquée dans le fichier pbtxt que vous allez créer avant d'entraîner le graphique).
La formation
python legacy/train.py —logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config
** Avant l'entraînement, n'oubliez pas de vérifier le fichier " training/object-detection.pbtxt " - il devrait y avoir toutes les classes reconnues et le fichier " training/ssd_mobilenet_v1_coco.config " - là vous devez changer le paramètre " num_classes " au nombre de vos classes.
Exporter le modèle vers pb
python export_inference_graph.py \ --input_type=image_tensor \ --pipeline_config_path=training/pipeline.config \ --trained_checkpoint_prefix=training/model.ckpt-110 \ --output_directory=output
Merci de votre intérêt pour ce sujet!
Les références
- Article original sur la reconnaissance d'objets
- Un cycle de vidéo à l'article sur la reconnaissance des objets en anglais
- L'ensemble des scripts utilisés dans l'article d'origine