Je travaille en tant que développeur chez
hh.ru , et je veux aller dans les bases de données, mais pour l'instant il n'y a pas assez de compétences. Par conséquent, pendant mon temps libre, j'étudie l'apprentissage automatique et essaie de résoudre des problèmes pratiques dans ce domaine. Récemment, ils m'ont lancé la tâche de regrouper nos CV. Le post sera sur la façon dont je l'ai résolu en utilisant le clustering hiérarchique aggloméré. Si vous ne voulez pas lire, mais que le résultat est intéressant, vous pouvez voir la
démo tout de suite.

Contexte
Le marché du travail est en constante dynamique, de nouveaux métiers émergent, d'autres disparaissent, et je veux avoir une catégorisation pertinente des CV. Le catalogue des domaines professionnels et des spécialisations sur hh.ru est depuis longtemps dépassé: beaucoup y est lié, ils n'ont donc pas apporté de modifications depuis longtemps. Il serait utile d'apprendre à éditer sans douleur ces catégories. J'essaie d'identifier automatiquement ces catégories. J'espère qu'à l'avenir cela contribuera à résoudre le problème.
À propos de l'approche choisie et du clustering
En regroupant, je comprendrai la combinaison d'objets avec les fonctionnalités les plus similaires dans un groupe. Dans mon cas, sous l'objet est considéré comme un CV, et sous les signes de l'objet se trouvent les données résumées: par exemple, la fréquence du mot «manager» dans le CV ou la taille du salaire. La similitude des objets est déterminée par une métrique présélectionnée. Pour l'instant, vous pouvez le considérer comme une boîte noire qui reçoit deux objets à l'entrée, et la sortie produit un nombre qui reflète, par exemple, la distance entre les objets dans l'espace vectoriel: plus la distance est petite, plus les objets sont similaires.
L'approche que j'ai utilisée peut être appelée clustering hiérarchique agglomératif ascendant. Le résultat du clustering est un arbre binaire, où dans les feuilles il y a des éléments individuels, et la racine de l'arbre est une collection de tous les éléments. Il est appelé ascendant car le clustering commence au niveau le plus bas de l'arbre, avec des feuilles, où chaque élément individuel est considéré comme un cluster.

Ensuite, vous devez trouver les deux clusters les plus proches et les fusionner dans un nouveau cluster. Cette procédure doit être répétée jusqu'à ce qu'il n'y ait qu'un seul cluster avec tous les objets à l'intérieur. Lorsque les clusters sont combinés, la distance entre eux est enregistrée. À l'avenir, ces distances peuvent être utilisées pour déterminer l'endroit où ces distances sont suffisamment grandes pour considérer les grappes sélectionnées comme distinctes.
La plupart des méthodes de clustering supposent que le nombre de clusters est connu à l'avance, ou tentent d'isoler les clusters indépendamment, en fonction de l'algorithme et des paramètres de cet algorithme. L'avantage du clustering hiérarchique est que vous pouvez essayer de déterminer le nombre de clusters requis en examinant les propriétés de l'arborescence résultante, par exemple, sélectionner des sous-arbres avec des distances différentes entre différents groupes. Il est pratique de travailler avec la structure résultante pour y rechercher des clusters. De manière pratique, une telle structure est construite une seule fois et n'a pas besoin d'être reconstruite lors de la recherche du nombre requis de clusters.
Parmi les lacunes, je mentionnerais que l'algorithme est assez exigeant sur la mémoire consommée. Et au lieu d'attribuer une classe spécifique, j'aimerais avoir la probabilité que le CV appartienne à la classe afin de regarder non pas la spécialité la plus proche, mais la totalité.
Collecte et préparation des données
La partie la plus importante du travail avec les données est la préparation, la sélection et la récupération des attributs. C'est en fonction des signes qui seront finalement obtenus, cela dépendra de la présence ou non de schémas, de la correspondance de ces schémas avec le résultat attendu et de la possibilité de ce «résultat attendu». Avant de fournir des données à un type d'algorithme d'apprentissage automatique, vous devez avoir une idée de chaque signe, s'il y a des lacunes, à quel type le signe appartient, quelles propriétés ce type de signe possède et quelle est la distribution des valeurs dans ce signe. Il est également très important de choisir le bon algorithme avec lequel les données disponibles seront traitées.
J'ai pris des CV mis à jour au cours des six derniers mois. Il s'est avéré 2,7 millions. A partir des données du CV, j'ai choisi les signes les plus simples, sur lesquels, il me semble, la composition du CV doit dépendre de l'un ou l'autre groupe. Pour l'avenir, je dirai que le résultat du regroupement de tous les CV à la fois ne m'a pas satisfait. Par conséquent, nous avons d'abord dû diviser le curriculum vitae par les 28 domaines professionnels existants.
Pour chaque caractéristique, j'ai tracé la distribution pour avoir une idée de l'apparence des données. Peut-être devraient-ils être en quelque sorte convertis ou complètement abandonnés.
Région Afin que les valeurs de cette fonctionnalité puissent être comparées les unes aux autres, j'ai attribué le nombre total de CV qui appartiennent à cette région à chaque région et j'ai pris le logarithme de ce nombre pour lisser la différence entre les très grandes et les petites villes.
Paul Converti en signe binaire.
Date de naissance . Compté en nombre de mois. Tout le monde n'a pas d'anniversaire. J'ai rempli les lacunes avec les valeurs moyennes de l'âge de la spécialisation à laquelle appartient ce CV.
Niveau d'éducation . Ceci est un signe catégorique. Je l'ai encodé avec un
LabelBinarizer .
Nom de l'élément de campagne . J'ai conduit à travers
TfidfVectorizer avec ngram_range = (1,2), utilisé un
stemmer .
Salaire . Traduit toutes les valeurs en roubles. J'ai comblé les lacunes de la même manière qu'à mon âge. A pris le logarithme de la valeur.
Horaire de travail . LabelBinarizer encodé.
Taux d'emploi . Je l'ai rendu binaire, en le divisant en deux parties: à temps plein et tout le reste.
Compétence linguistique . J'ai choisi le top le plus utilisé. Chaque langue est définie comme une fonction distincte. Les niveaux de propriété sont associés à des nombres de 0 à 5.
Compétences clés . J'ai conduit à travers TfidfVectorizer. En guise de mot d’arrêt, j’ai constitué un petit dictionnaire de compétences générales et de mots qui, il me semble, n’affectent pas la spécialité. Tous les mots passent par le stemmer. Chaque compétence clé peut être constituée non seulement d'un mot, mais également de plusieurs. Dans le cas de plusieurs mots de la compétence clé, j'ai trié les mots et j'ai également utilisé chaque mot comme attribut distinct. Cette fonctionnalité ne s'est bien passée que dans le domaine professionnel «Technologies de l'information, Internet, Télécom», car les gens indiquent souvent des compétences pertinentes à leur spécialité. Dans d'autres domaines professionnels, je ne l'ai pas utilisé en raison de l'abondance des compétences des mots généraux.
Spécialisations J'ai défini chacune des spécialisations spécifiées par l'utilisateur en tant qu'attribut binaire.
Expérience professionnelle . Pris le logarithme du nombre de mois + 1, car il y a des gens sans expérience de travail.
Normalisation
En conséquence, chaque CV a commencé à être un vecteur de signes numériques. L'algorithme de regroupement sélectionné est basé sur le calcul de la distance entre les objets. Comment déterminer comment chaque entité devrait contribuer à cette distance? Par exemple, il y a un signe binaire - 0 et 1, et un autre signe peut prendre beaucoup de valeurs de 0 à 1000.
La normalisation vient à la rescousse. J'ai utilisé
StandardScaler . Il transforme chaque trait de telle manière que sa valeur moyenne soit nulle et que l'écart type par rapport à la moyenne soit un. Ainsi, nous essayons d'amener toutes les données à la même distribution - la normale standard. Bien entendu, il est loin d'être vrai que les données elles-mêmes ont la nature d'une distribution normale. Ce n'est qu'une des raisons pour construire des graphiques de la distribution de leurs paramètres et être heureux qu'ils ressemblent à un gaussien.
Ainsi, par exemple, un tableau de répartition des salaires ressemblait.

On peut voir qu'il a une queue très lourde. Pour rendre la distribution plus normale, vous pouvez prendre le logarithme de ces données. Dans le même temps, les émissions ne seront pas si fortes.
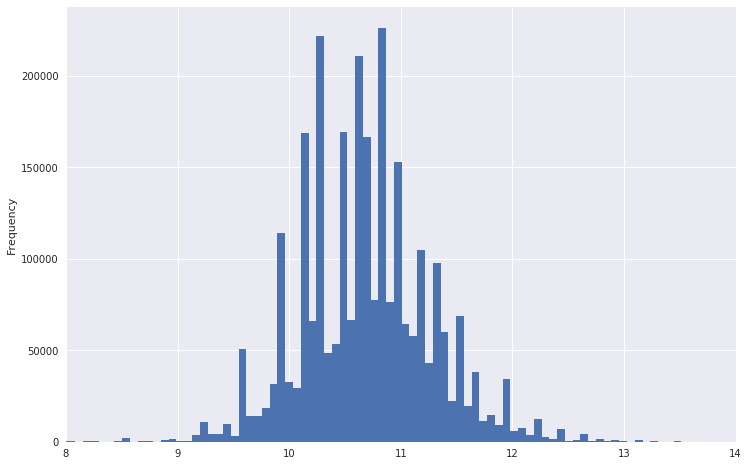
Rétrograder
Maintenant, il est logique de transférer les données vers un espace de plus petite dimension, afin qu'à l'avenir, l'algorithme de clustering puisse les digérer dans un temps et une mémoire acceptables. J'ai utilisé
TruncatedSVD ,
car il sait comment travailler avec des matrices clairsemées et en sortie, il donne la matrice dense habituelle, dont nous aurons besoin pour d'autres travaux. Soit dit en passant, TruncatedSVD doit également soumettre des données normalisées.
Au même stade, il vaut la peine d'essayer de visualiser l'ensemble de données résultant, en le traduisant dans un espace à deux dimensions à l'aide de
t-SNE . Il s'agit d'une étape très importante. Si aucune structure n'est visible dans l'image résultante ou, inversement, cette structure semble très étrange, alors soit vos données n'ont pas la régularité nécessaire, soit une erreur a été commise quelque part.
J'ai eu beaucoup d'images très suspectes avant que tout se passe bien. Par exemple, une fois qu'il y avait une si belle image:

La raison des vers résultants était d'obtenir des identifiants de reprise dans l'ensemble de données. Et voici quelque chose de plus similaire à la vérité:

Regroupement
Si tout semble être en ordre avec les données, vous pouvez commencer le clustering. J'ai utilisé le package de
clustering hiérarchique de SciPy. Il permet le clustering en utilisant la
méthode de liaison . J'ai essayé toutes les métriques de distance de cluster suggérées dans l'algorithme. Le meilleur résultat a été donné par
la méthode Ward .
Le principal problème que j'ai rencontré est l'algorithme de clustering qui calcule la matrice de distance entre tous les éléments, ce qui signifie une dépendance quadratique en mémoire du nombre d'éléments. Pour 2,7 millions de CV, je n'ai pas réussi, car La quantité de mémoire requise est de téraoctets. Tous les calculs ont été effectués sur un ordinateur ordinaire. Je n'ai pas autant de RAM. Par conséquent, il m'a semblé raisonnable que vous puissiez d'abord combiner les CV qui se trouvent à proximité, prendre les centres des groupes résultants et les regrouper déjà avec l'algorithme souhaité. J'ai pris
MiniBatchKMeans , formé 30 000 clusters avec lui et les ai envoyés à un clustering hiérarchique. Cela a fonctionné, mais le résultat a été moyen. Beaucoup des groupes de CV les plus marquants se sont démarqués, mais les détails ne suffisent pas pour trouver des spécialisations à un bon niveau.
Pour améliorer la qualité des spécialisations obtenues, j'ai décomposé les données en domaines professionnels. Il s'est avéré que les ensembles de données provenaient de 400 000 CV et moins. À ce moment, il m'est venu à l'esprit qu'il était préférable de regrouper un échantillon de données que d'utiliser deux algorithmes d'affilée. J'ai donc abandonné MiniBatchKMeans et pris jusqu'à 100 000 CV pour chaque spécialisation afin que la méthode de liaison puisse les digérer. 32 Go de RAM n'étaient pas suffisants, j'ai donc alloué 100 Go supplémentaires pour le swap. Par conséquent, la liaison fournit une matrice avec les distances entre les grappes combinées à chaque étape et le nombre d'éléments dans la grappe résultante.
En tant que mesure de contrôle de qualité pour comparer différentes versions d'ensembles de données et différentes méthodes de calcul de la distance entre les clusters, l'algorithme a utilisé le coefficient de corrélation cophénétique obtenu à partir de
cophenet . Ce coefficient montre à quel point le dendrogramme résultant reflète la dissimilarité des objets entre eux. Plus la valeur est proche de l'unité, mieux c'est.
Visualisation
La meilleure façon de valider la qualité du clustering était la visualisation. La méthode du
dendrogramme dessine les dendrogrammes résultants sur lesquels vous pouvez sélectionner des clusters par distance ou par niveau dans l'arborescence:

Le graphique suivant montre la dépendance de la distance entre les clusters sur le numéro de l'étape d'itération, à laquelle les deux clusters les plus proches sont combinés en un nouveau. La ligne verte montre comment l'accélération change - la vitesse de la distance entre les grappes jointes.
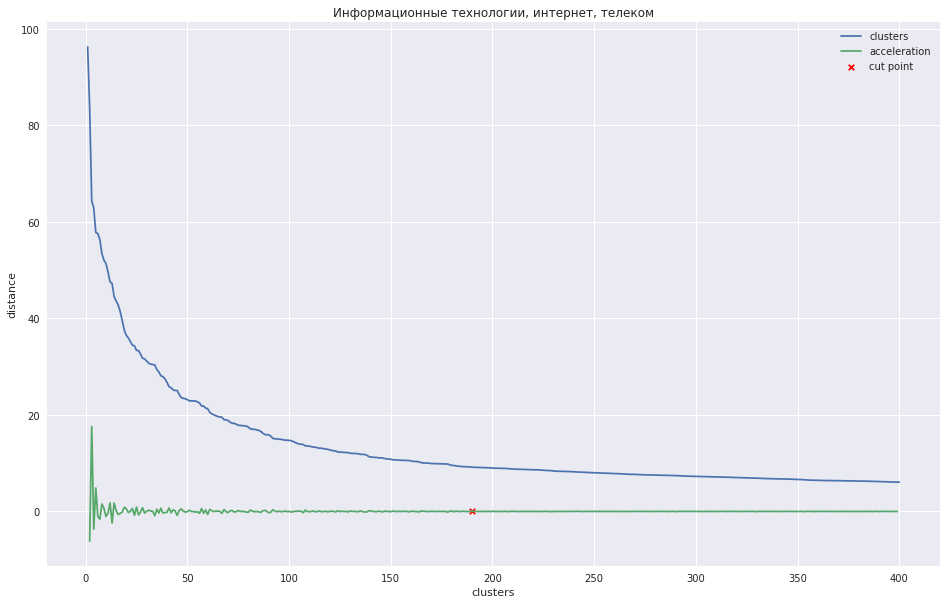
Dans le cas d'un petit nombre de grappes, on pourrait essayer d'élaguer l'arbre au point où l'accélération est maximale, c'est-à-dire que la distance au moment où les deux grappes ont été combinées était encore plus grande, et déjà plus petite à l'étape suivante. Dans mon cas, tout est différent - j'ai de nombreux clusters, et j'ai suggéré qu'il vaut mieux couper le dendrogramme au point où l'accélération commence à diminuer de façon plus monotone, c'est-à-dire que les distances entre les clusters à ce niveau n'indiquent plus un groupe distinct. Sur le graphique, cet endroit est approximativement au point où la ligne verte cesse de danser.
On pourrait trouver une sorte de méthode programmatique, mais il s'est avéré plus rapide de marquer ces endroits avec 28 mains pour 28 domaines professionnels et de
passer le nombre souhaité de clusters à la méthode
fcluster , qui coupera l'arbre au bon endroit.
J'ai sauvegardé les données obtenues précédemment de t-SNE et noté les clusters résultants sur eux. Ça a l'air plutôt bien:

En conséquence, j'ai créé une interface Web où vous pouvez voir le résumé de chaque cluster, sa position sur le graphique et donner un nom significatif. Pour plus de commodité, j'ai déduit le titre le plus courant du CV - il caractérise souvent bien le nom du cluster.
Vous pouvez voir le résultat du clustering
ici .
J'ai conclu par moi-même que le système fonctionnait. Bien que la répartition en grappes soit imparfaite et que certains groupes soient très similaires les uns aux autres, mais certains pourraient, au contraire, être divisés en parties, mais les principales tendances du marché spécialisé sont clairement visibles. Vous pouvez également voir comment se forment les nouveaux groupes. Le déchargement du CV a été fait en été, les
pilotes qui voulaient travailler à la Coupe du monde se sont donc démarqués, par exemple. Si vous apprenez à faire correspondre les clusters entre eux d'un lancement à l'autre, vous pouvez observer comment les principaux domaines de spécialisation évoluent au fil du temps. En fait, les idées pour améliorer la qualité et le développement sont encore pleines. Si je peux trouver la bonne motivation en moi, je développerai davantage.
Matériel supplémentaire
Vidéo sur le clustering hiérarchique aggloméré du cours sur la recherche d'une structure dans les données
À propos de la mise à l'échelle et de la normalisation des signesTutoriel sur le clustering hiérarchique de la bibliothèque SciPy, que j'ai pris comme base pour ma tâche
Comparaison de différents types de clustering en utilisant les bibliothèques sklearn comme exemple
Petit bonus. J'ai trouvé intéressant de voir comment quelqu'un travaille sur une tâche. Je veux dire que dans certains problèmes, j'ai bien pompé pendant que je faisais ce projet. J'ai essayé différentes options, étudié, réfléchi au fonctionnement de telle ou telle chose. Dans de nombreux endroits, l'absence d'une bonne base mathématique a été compensée par l'ingéniosité et un grand nombre de tentatives. Et je voudrais partager la
feuille evernote souffert dans laquelle j'ai pris des notes tout en travaillant sur la tâche. Les réflexions qu'il contient étaient destinées uniquement à moi, il y a beaucoup d'hérésies et d'incompréhensions, mais je pense que c'est normal.
UPD: J'ai posté des ordinateurs portables avec
un code de
préparation des données et de
clustering . Je n'avais pas prévu de télécharger le code, donc désolé pour la qualité.