
Avec les tests du code, tout est clair (enfin, au moins le fait qu'ils doivent être écrits). Avec les tests de configuration, tout est beaucoup moins évident, à commencer par leur existence même. Quelqu'un les écrit-il? Est-ce important? C'est dur? Quels types de résultats peuvent être obtenus avec leur aide?
Il s'avère que cela est également très utile, commencer à le faire est très simple, et en même temps, il existe de nombreuses nuances dans le test de la configuration. Lesquelles - peintes sous la coupe en fonction de l'expérience pratique.
Le matériel est basé sur une transcription d'un rapport de Ruslan cheremin Cheremin (développeur Java à la Deutsche Bank). Vient ensuite le discours à la première personne.Je m'appelle Ruslan, je travaille pour la Deutsche Bank. Nous commençons par ceci:

Il y a beaucoup de texte, de loin il peut sembler qu'il est russe. Mais ce n'est pas vrai. C'est une langue très ancienne et dangereuse. J'ai fait une traduction en russe simple:
- Tous les personnages sont constitués
- À utiliser avec prudence
- Funérailles à ses frais
Je décrirai brièvement de quoi je vais parler aujourd'hui. Supposons que nous ayons un code:

Autrement dit, au départ, nous avions une sorte de tâche, nous écrivons un code pour le résoudre, et cela nous rapporte soi-disant de l'argent. Si pour une raison quelconque, ce code ne fonctionne pas correctement, il résout la mauvaise tâche et nous rapporte le mauvais argent. Les entreprises n'aiment pas ce genre d'argent - elles semblent mauvaises dans les états financiers.
Par conséquent, pour notre code important, nous avons des tests:

Habituellement là. Maintenant, probablement, presque tout le monde l'a. Les tests vérifient que le code résout le bon problème et fait le bon argent. Mais le service n'est pas limité au code, et à côté du code il y a aussi une configuration:

Au moins dans presque tous les projets auxquels j'ai participé, cette configuration était, sous une forme ou une autre. (Je ne me souviens que de quelques cas de mes premières années d'interface utilisateur, où il n'y avait pas de fichiers de configuration, mais tout a été configuré via l'interface utilisateur). Dans cette configuration, il y a des ports, des adresses et des paramètres d'algorithme.
Pourquoi la configuration est-elle importante à tester?
Voici l'astuce: les erreurs dans la configuration nuisent à l'exécution du programme pas moins que les erreurs dans le code. Eux aussi peuvent provoquer l'exécution incorrecte du code - et voir ci-dessus.
Et trouver des erreurs dans la configuration est encore plus difficile que dans le code, car la configuration ne se compile généralement pas. J'ai cité les propriétés-fichiers à titre d'exemple, en général, il existe différentes options (JSON, XML, quelqu'un stocke dans YAML), mais il est important que rien de tout cela ne soit compilé et, par conséquent, ne soit pas vérifié. Si vous avez accidentellement scellé un fichier Java - très probablement, il ne passera tout simplement pas la compilation. Une faute de frappe aléatoire dans la propriété n'excitera personne, elle fonctionnera.
Et l'IDE ne met pas non plus en évidence l'erreur dans la configuration, car il ne connaît que les plus primitifs sur le format (par exemple) des fichiers de propriétés: qu'il doit y avoir une clé et une valeur, et entre eux est "égal", deux points ou un espace. Mais le fait que la valeur doit être un nombre, un port réseau ou une adresse - l'IDE ne sait rien.
Et même si vous testez l'application dans un UAT ou dans un environnement de transfert, cela ne garantit rien non plus. Parce que la configuration, en règle générale, dans chaque environnement est différente, et dans l'UAT, vous avez uniquement testé la configuration UAT.
Une autre subtilité est que même en production, les erreurs de configuration n'apparaissent parfois pas immédiatement. Un service peut ne pas démarrer du tout - et c'est un bon scénario. Mais il peut démarrer et fonctionner très longtemps - jusqu'au moment X, où il faudra exactement le paramètre dans lequel l'erreur. Et ici, vous constatez qu'un service qui n'a même pas beaucoup changé récemment a soudainement cessé de fonctionner.
Après tout ce que j'ai dit - il semblerait que le test des configurations devrait être un sujet brûlant. Mais en pratique, cela ressemble à ceci:
C'était du moins le cas pour nous - jusqu'à un certain point. Et l'une des tâches de mon rapport est de cesser de ressembler à ceci pour vous aussi. J'espère que je pourrai vous pousser à cela.
Il y a trois ans dans notre Deutsche Bank, dans mon équipe, Andrei Satarin a travaillé en tant que responsable QA. C'est lui qui a donné l'idée de tester les configurations - c'est-à-dire qu'il a simplement pris et commis le premier test de ce type. Il y a six mois, lors du précédent Heisenbug, il a
parlé de tester la configuration telle qu'il la voit. Je vous recommande de regarder, car là, il a donné un large aperçu du problème: à la fois du côté des articles scientifiques et de l'expérience des grandes entreprises qui ont rencontré des erreurs de configuration et leurs conséquences.
Mon rapport sera plus étroit - sur l'expérience pratique. Je parlerai des problèmes que j'ai rencontrés en tant que développeur lorsque j'ai écrit des tests de configuration et comment j'ai résolu ces problèmes. Mes décisions peuvent ne pas être les meilleures décisions, ce ne sont pas les meilleures pratiques - c'est mon expérience personnelle, j'ai essayé de ne pas faire de généralisations générales.
Aperçu général du rapport:
- «Ce que vous pouvez faire avant le lundi après-midi»: exemples simples et utiles.
- «Lundi, deux ans plus tard»: où et comment faire mieux.
- Prise en charge de la refactorisation de la configuration: comment obtenir une couverture dense; modèle de configuration logicielle.
La première partie est motivante: je décrirai les tests les plus simples avec lesquels tout a commencé avec nous. Il y aura une grande variété d'exemples. J'espère qu'au moins l'un d'entre eux résonne avec vous, c'est-à-dire que vous verrez une sorte de problème similaire et sa solution.
Les tests eux-mêmes dans la première partie sont simples, voire primitifs - d'un point de vue technique, il n'y a pas de science de fusée. Mais le simple fait qu'elles puissent être faites rapidement est particulièrement précieux. Il s'agit d'une «entrée facile» dans les tests de configuration, et c'est important car il y a une barrière psychologique à l'écriture de ces tests. Et je veux montrer que "vous pouvez le faire": maintenant, nous l'avons fait, cela a bien fonctionné pour nous, et bien que personne ne soit mort, nous vivons depuis trois ans maintenant.
La deuxième partie concerne ce qu'il faut faire après. Lorsque vous avez écrit de nombreux tests simples, la question du support se pose. Certains d'entre eux commencent à tomber, vous comprenez les erreurs qu'ils auraient mises en évidence. Il s'avère que ce n'est pas toujours pratique. Et la question se pose d'écrire des tests plus complexes - après tout, vous avez déjà couvert des cas simples, je veux quelque chose de plus intéressant. Et là encore, il n'y a pas de meilleures pratiques, je vais simplement décrire certaines des solutions qui ont fonctionné pour nous.
La troisième partie concerne la façon dont les tests peuvent prendre en charge la refactorisation d'une configuration plutôt complexe et déroutante. Encore une fois, étude de cas - comment nous l'avons fait. De mon point de vue, c'est un exemple de la façon dont les tests de configuration peuvent être mis à l'échelle pour résoudre des tâches plus importantes, et pas seulement pour boucher de petits trous.
Partie 1. «Vous pouvez le faire comme ça»
Il est maintenant difficile de comprendre quel était le premier test de configuration avec nous. Andrei est assis dans le couloir, il peut dire que j'ai menti. Mais il me semble que tout a commencé par ceci:

La situation est la suivante: nous avons n services sur le même hôte, chacun d'eux lève son propre serveur JMX sur son port, exporte quelques JMX de surveillance. Les ports de tous les services sont configurés dans le fichier. Mais le fichier occupe plusieurs pages, et il existe de nombreuses autres propriétés - il s'avère souvent que les ports de différents services entrent en conflit. Il est facile de se tromper. Ensuite, tout est trivial: certains services n'augmentent pas, après cela, ils n'augmentent pas pour ceux qui en dépendent - les testeurs sont furieux.
Ce problème est résolu en plusieurs lignes. Ce test, qui (il me semble) était le premier, ressemblait à ceci:

Ce n'est rien de compliqué: on parcourt le dossier où se trouvent les fichiers de configuration, on les charge, on les analyse en tant que propriétés, on filtre les valeurs dont le nom contient «jmx.port», et on vérifie que toutes les valeurs sont uniques. Il n'est même pas nécessaire de convertir les valeurs en entier. Vraisemblablement, il n'y a que des ports.
Ma première réaction quand j'ai vu cela a été mitigée:
Première impression: qu'est-ce que c'est dans mes beaux tests unitaires? Pourquoi avons-nous grimpé dans le système de fichiers?
Et puis la surprise est venue: "Quoi, est-ce possible?"
J'en parle parce qu'il semble y avoir une sorte de barrière psychologique qui rend difficile la rédaction de tels tests. Trois ans se sont écoulés depuis, le projet regorge de tels tests, mais je constate souvent que mes collègues, tombant sur une erreur commise dans la configuration, n'y écrivent pas de tests. Pour le code, tout le monde a déjà l'habitude d'écrire des tests de régression - pour que l'erreur trouvée ne soit plus reproduite. Mais ils ne le font pas pour la configuration, quelque chose interfère. Il y a une sorte de barrière psychologique qui doit être surmontée - c'est pourquoi je mentionne une telle réaction afin que vous la reconnaissiez de vous-même si elle apparaît.
L'exemple suivant est presque le même, mais légèrement modifié - j'ai supprimé tous les «jmx». Cette fois, nous vérifions toutes les propriétés appelées quelque chose de là-bas. Ils doivent être des valeurs entières et être un port réseau valide. Matcher validNetworkPort () cache notre matcher hamcrest personnalisé, qui vérifie que la valeur est au-dessus de la plage de ports système, en dessous de la plage de ports éphémères, eh bien, nous savons que certains ports de nos serveurs sont pré-occupés - voici la liste complète d'entre eux est également cachée dans c'est matcher.
Ce test est encore très primitif. Notez qu'il n'y a aucune indication sur la propriété spécifique que nous vérifions - elle est massive. Un seul de ces tests peut vérifier 500 propriétés avec le nom "... port" et vérifier que tous sont des entiers dans la plage souhaitée, avec toutes les conditions nécessaires. Une fois qu'ils ont écrit, une douzaine de lignes - et c'est tout. C'est une fonctionnalité très pratique, elle apparaît car la configuration a un format simple: deux colonnes, une clé et une valeur. Par conséquent, il peut être traité en masse.
Un autre exemple de test. Que vérifions-nous ici?

Il vérifie que les vrais mots de passe ne fuient pas en production. Tous les mots de passe doivent ressembler à ceci:

Vous pouvez écrire de nombreux tests pour les fichiers de propriétés. Je ne donnerai pas plus d'exemples - je ne veux pas me répéter, l'idée est très simple, alors tout doit être clair.
... et après avoir écrit suffisamment de ces tests, une question intéressante surgit: qu'entendons-nous par configuration, où est sa frontière? Nous considérons le fichier de propriétés comme une configuration, nous l'avons couvert - et quoi d'autre peut être couvert dans le même style?
Que considérer une configuration
Il s'avère qu'il existe de nombreux fichiers texte dans le projet qui ne sont pas compilés - du moins dans le processus de construction normal. Ils ne sont en aucun cas vérifiés tant qu'ils ne sont pas exécutés sur le serveur, c'est-à-dire que les erreurs y apparaissent tardivement. Tous ces fichiers - avec une certaine extension - peuvent être appelés une configuration. Au moins, ils seront testés à peu près de la même manière.
Par exemple, nous avons un système de correctifs SQL qui sont transférés sur la base de données pendant le processus de déploiement.

Ils sont écrits pour SQL * Plus. SQL * Plus est un outil des années 60, et il nécessite toutes sortes de choses étranges: par exemple, pour s'assurer que la fin du fichier est sur une nouvelle ligne. Bien sûr, les gens oublient régulièrement d'y mettre fin, car ils ne sont pas nés dans les années 60.
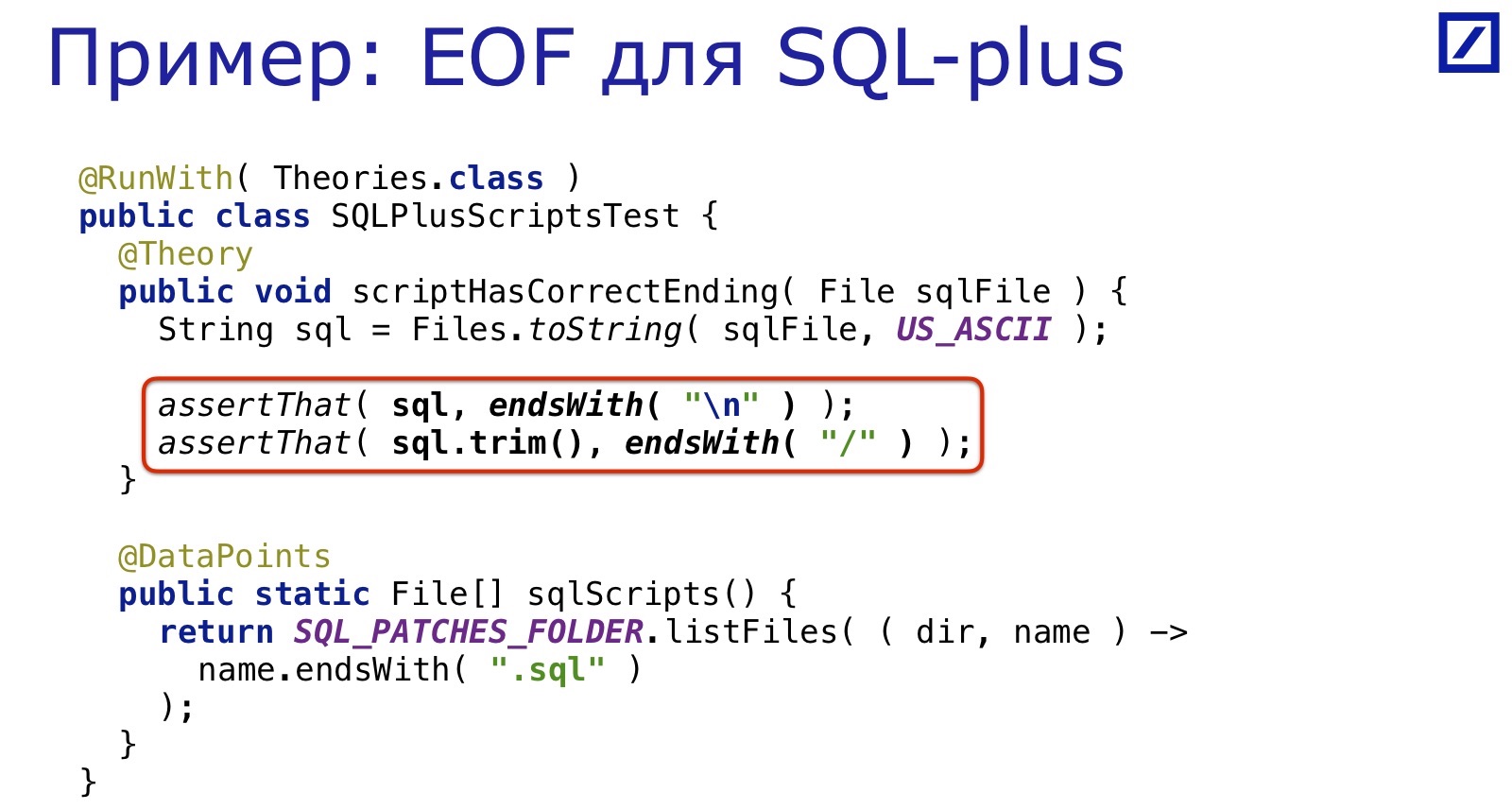
Et encore une fois, il est résolu par la même douzaine de lignes: nous sélectionnons tous les fichiers SQL, vérifions qu'il y a une barre oblique à la fin. Simple, pratique, rapide.
Les crontabs sont un autre exemple de «comme un fichier texte». Nos services crontab démarrent et s'arrêtent. Ils provoquent le plus souvent deux erreurs:
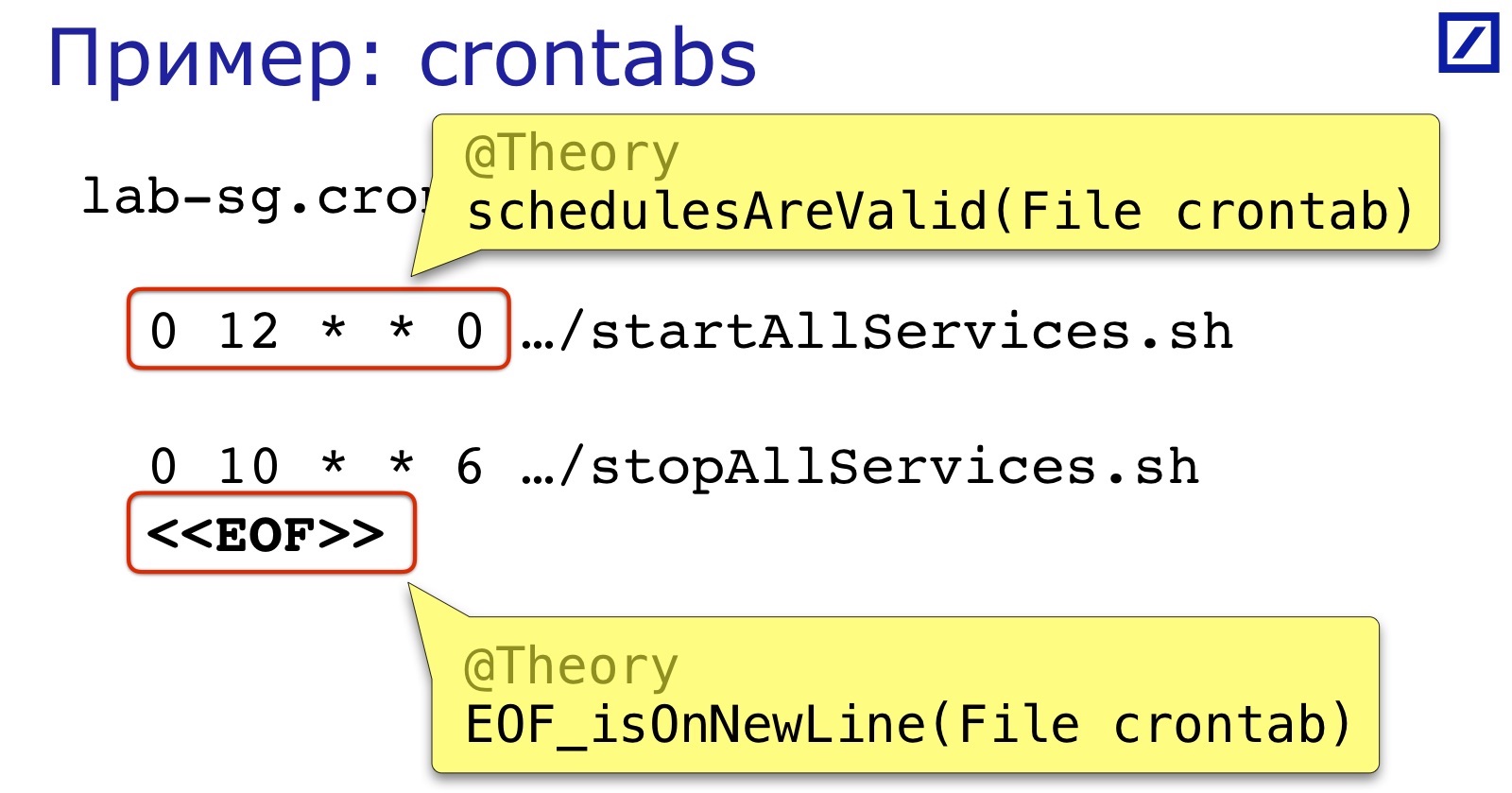
Tout d'abord, le format d'expression de planification. Ce n'est pas si compliqué, mais personne ne le vérifie avant le lancement, il est donc facile de mettre un espace supplémentaire, une virgule, etc.
Deuxièmement, comme dans l'exemple précédent, la fin du fichier doit également se trouver sur une nouvelle ligne.
Et tout cela est assez facile à vérifier. La fin du fichier est compréhensible, mais pour vérifier le calendrier, vous pouvez trouver des bibliothèques prêtes à l'emploi qui analysent l'expression cron. Avant le rapport, j'ai fait une recherche sur Google: il y en avait au moins six. J'en ai trouvé six, mais en général il peut y en avoir plus. Lorsque nous avons écrit, nous avons pris la plus simple de celles trouvées, car nous n'avions pas besoin de vérifier le contenu de l'expression, mais seulement sa justesse syntaxique, afin que cron la charge avec succès.
En principe, vous pouvez liquider plus de chèques - vérifiez que vous commencez le bon jour de la semaine, que vous n'arrêtez pas les services au milieu de la journée de travail. Mais cela s'est avéré ne pas être si utile pour nous, et nous n'avons pas pris la peine.
Les scripts shell sont une autre idée qui fonctionne très bien. Bien sûr, écrire en Java un analyseur à part entière de scripts bash est un plaisir pour les courageux. Mais l'essentiel est qu'un grand nombre de ces scripts ne sont pas un bash complet. Oui, il y a des scripts bash où le code est direct, enfer et enfer, où ils tombent une fois par an et, jurant, s'enfuient. Mais de nombreux scripts bash ont les mêmes configurations. Il existe un certain nombre de variables système et de variables d'environnement qui sont définies sur la valeur souhaitée, configurant ainsi d'autres scripts qui utilisent ces variables. Et ces variables sont faciles à comprendre à partir de ce fichier bash et à vérifier quelque chose à leur sujet.

Par exemple, vérifiez que JAVA_HOME est installé sur chaque environnement ou que la bibliothèque jni que nous utilisons se trouve dans LD_LIBRARY_PATH. D'une manière ou d'une autre, nous sommes passés d'une version de Java à une autre et avons étendu le test: nous avons vérifié que JAVA_HOME contient «1,8» sur ce même sous-ensemble d'environnement, que nous avons progressivement transféré vers la nouvelle version.
Voici quelques exemples. Permettez-moi de résumer la première partie des conclusions:
- Les tests de configuration sont déroutants au début, il y a une barrière psychologique. Mais après l'avoir surmonté, il existe de nombreux endroits dans l'application qui ne sont pas couverts par les chèques et peuvent l'être.
- Ensuite, ils sont écrits facilement et joyeusement : il y a beaucoup de «fruits bas» qui donnent rapidement de grands avantages).
- Réduisez le coût de détection et de correction des erreurs de configuration. Comme il s'agit en fait de tests unitaires, vous pouvez les exécuter sur votre ordinateur, même avant de vous engager - cela réduit considérablement la boucle de rétroaction. Beaucoup d'entre eux, bien sûr, auraient été testés au stade du déploiement des tests, par exemple. Et beaucoup ne seraient pas testés - s'il s'agit d'une configuration de production. Et donc ils sont vérifiés directement sur l'ordinateur local.
- Ils donnent une seconde jeunesse. En ce sens qu'il y a le sentiment que vous pouvez toujours tester beaucoup de choses intéressantes. En effet, dans le code il n'est plus si facile de trouver ce que l'on peut tester.
Partie 2. Cas plus complexes
Passons à des tests plus complexes. Après avoir couvert la plupart des vérifications triviales, telles que celles présentées ici, la question se pose: est-il possible de vérifier quelque chose de plus compliqué?
Qu'est-ce que cela signifie «plus difficile»? Les tests que je viens de décrire ont approximativement la structure suivante:

Ils vérifient quelque chose par rapport à un fichier spécifique. Autrement dit, nous parcourons les fichiers, appliquons une certaine vérification de condition à chacun. Ainsi, beaucoup de choses peuvent être vérifiées, mais il existe des scénarios plus utiles:
- L'application d'interface utilisateur se connecte au serveur de son environnement.
- Tous les services du même environnement se connectent au même serveur de gestion.
- Tous les services dans le même environnement utilisent la même base de données.
Par exemple, une application d'interface utilisateur se connecte à son serveur d'environnement. Très probablement, l'interface utilisateur et le serveur sont des modules différents, sinon des projets du tout, et ils ont des configurations différentes, il est peu probable qu'ils utilisent les mêmes fichiers de configuration. Par conséquent, vous devrez les lier afin que tous les services d'un environnement soient connectés à un serveur de gestion de clés via lequel les commandes sont distribuées. Encore une fois, très probablement, ce sont différents modules, différents services et généralement différentes équipes les développent.
Ou tous les services utilisent la même base de données, la même chose - des services dans différents modules.
En fait, il y a une telle image: beaucoup de services, chacun d'eux a sa propre structure de configurations, vous devez en réduire quelques-uns et vérifier quelque chose à l'intersection:

Bien sûr, vous pouvez faire exactement cela: charger un, le second, retirer quelque chose quelque part, le coller dans le code de test. Mais vous pouvez imaginer la taille du code et sa lisibilité. Nous sommes partis de cela, mais nous avons réalisé à quel point c'était difficile. Comment faire mieux?
Si vous rêvez, ce serait plus pratique, alors j'ai rêvé que le test ressemblerait à l'expliquer en langage humain:
@Theory public void eachEnvironmentIsXXX( Environment environment ) { for( Server server : environment.servers() ) { for( Service service : server.services() ) { Properties config = buildConfigFor( environment, server, service );
Pour chaque environnement, une condition est remplie. Pour vérifier cela, vous avez besoin de l'environnement pour trouver une liste de serveurs, une liste de services. Chargez ensuite les configurations et vérifiez quelque chose à l'intersection. Par conséquent, j'ai besoin d'une telle chose, je l'ai appelée Disposition de déploiement.
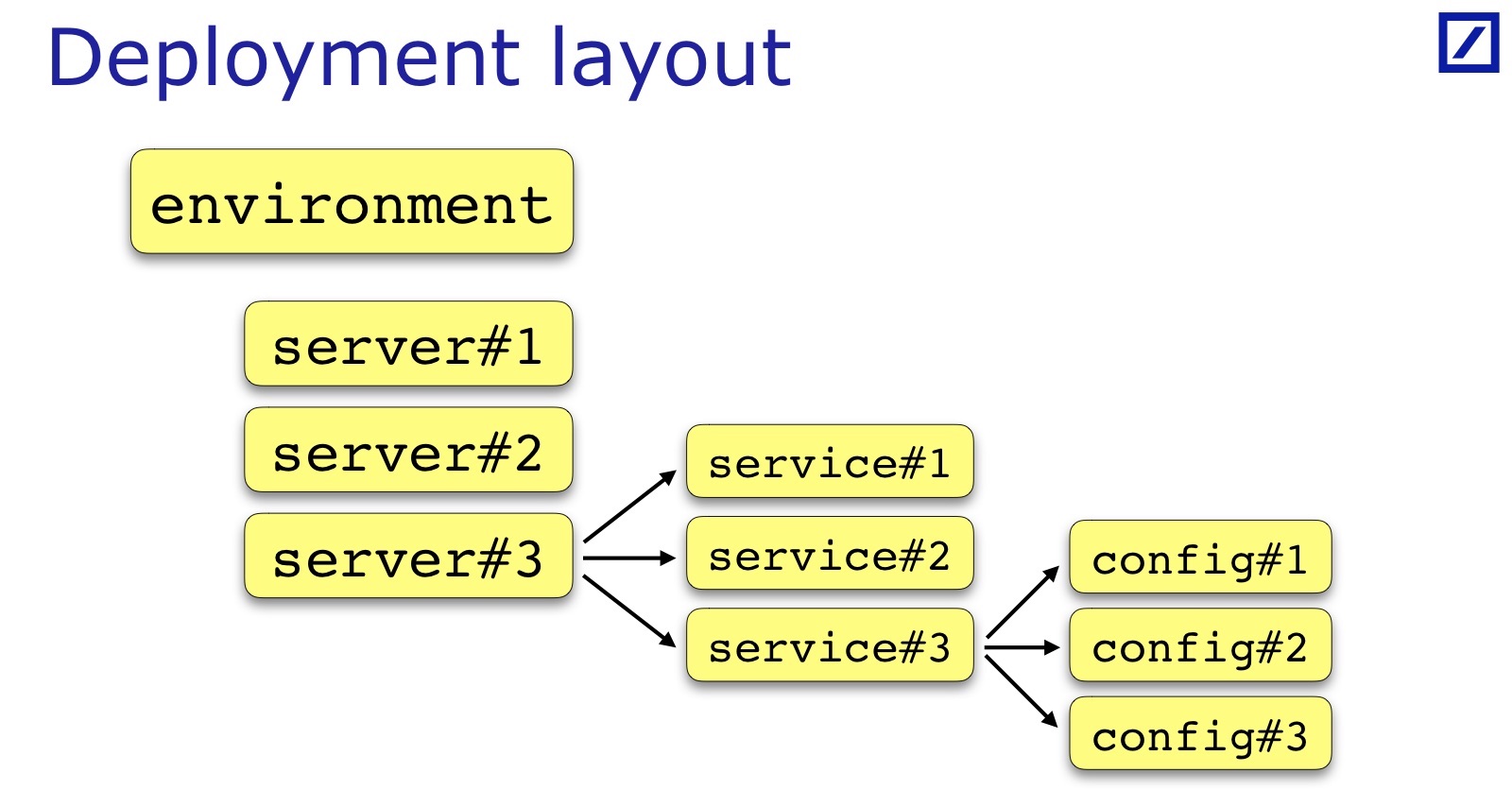
Nous avons besoin d'une opportunité du code pour accéder à la façon dont l'application est déployée: sur quels serveurs quels services sont placés, dans quel environnement - pour obtenir cette structure de données. Et à partir de là, je commence à charger la configuration et à la traiter.
La disposition de déploiement est spécifique à chaque équipe et à chaque projet. J'ai dessiné - c'est un cas général: généralement il y a un ensemble de serveurs, de services, un service a parfois un ensemble de fichiers de configuration, et pas seulement un. Parfois, des paramètres supplémentaires sont nécessaires qui sont utiles pour les tests, ils doivent être ajoutés. Par exemple, le rack dans lequel se trouve le serveur peut être important. Andrey dans son rapport a donné un exemple lorsqu'il était important pour leurs services que les services de sauvegarde / primaires doivent être dans des racks différents - pour son cas, il aurait besoin de garder une indication du rack dans la disposition de déploiement:
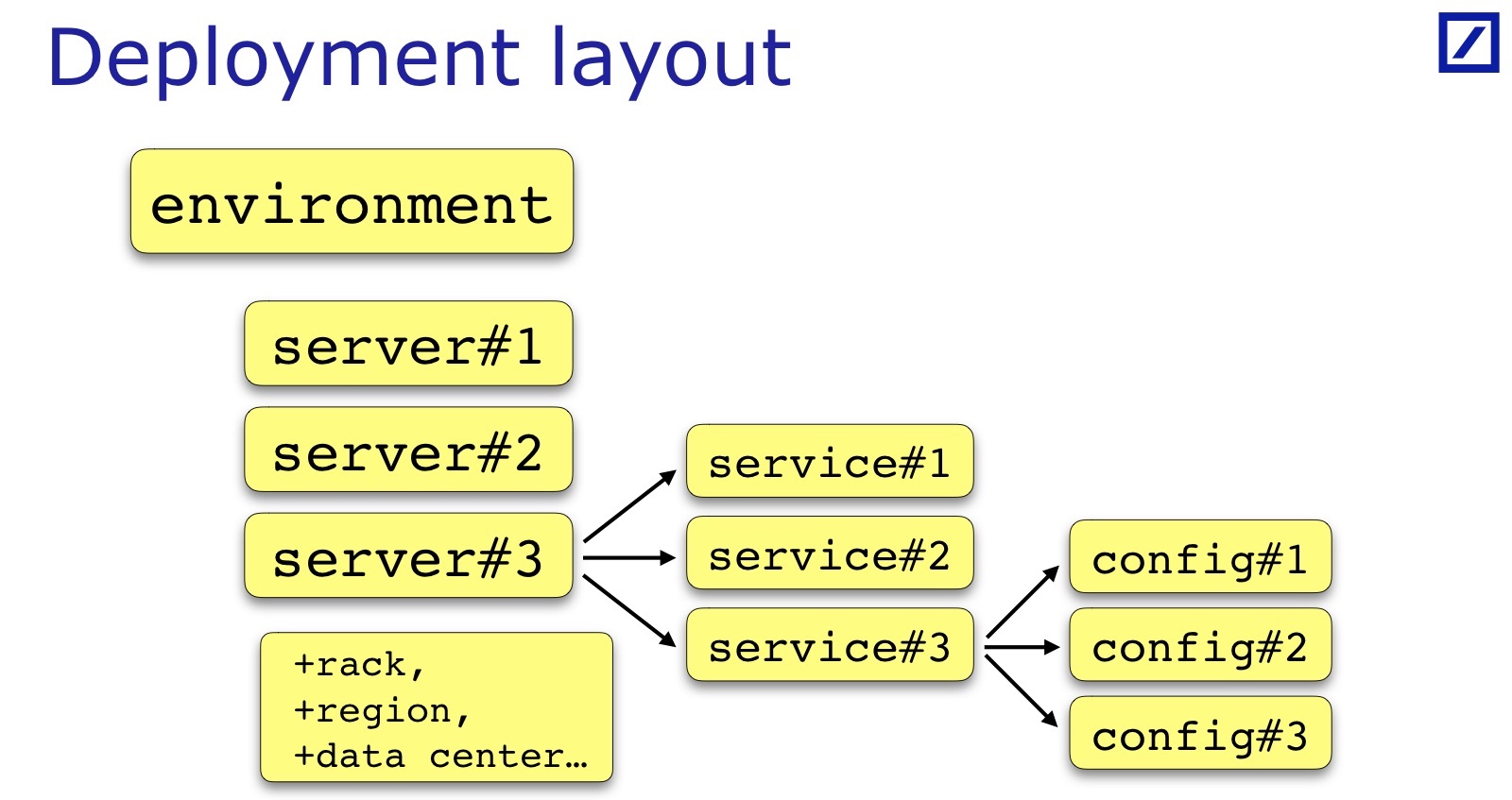
Pour nos besoins, la région du serveur est importante, le centre de données spécifique, en principe également, de sorte que la sauvegarde / primaire se trouve dans différents centres de données. Ce sont toutes des propriétés de serveur supplémentaires, elles sont spécifiques au projet, mais sur la diapositive, c'est un dénominateur commun.
Où obtenir la disposition du déploiement? Il semble que dans toute grande entreprise, il existe un système de gestion des infrastructures, tout y est décrit, il est fiable, fiable et tout ça ... en fait pas.
Au moins, ma pratique dans deux projets a montré qu'il est plus facile de coder en dur d'abord, puis, après trois ans ... de laisser la peau dure.
Nous vivons avec ce projet depuis trois ans maintenant. Dans le second, semble-t-il, nous nous intégrons toujours à la gestion des infrastructures en un an, mais toutes ces années nous avons vécu comme ça. Par expérience, il est judicieux de différer la tâche d'intégration avec IM afin d'obtenir des tests prêts à l'emploi dès que possible, ce qui montrera qu'ils fonctionnent et sont utiles. Et puis, il se peut que cette intégration ne soit pas si nécessaire, car la distribution des services sur les serveurs n'est pas si souvent modifiée.
Le code dur peut littéralement ressembler à ceci:
public enum Environment { PROD( PROD_UK_PRIMARY, PROD_UK_BACKUP, PROD_US_PRIMARY, PROD_US_BACKUP, PROD_SG_PRIMARY, PROD_SG_BACKUP ) … public Server[] servers() {…} } public enum Server { PROD_UK_PRIMARY(“rflx-ldn-1"), PROD_UK_BACKUP("rflx-ldn-2"), PROD_US_PRIMARY(“rflx-nyc-1"), PROD_US_BACKUP("rflx-nyc-2"), PROD_SG_PRIMARY(“rflx-sng-1"), PROD_SG_BACKUP("rflx-sng-2"), public Service[] services() {…} }
La façon la plus simple que nous utilisons dans notre premier projet est d'énumérer l'environnement avec une liste de serveurs dans chacun d'eux. Il y a une liste de serveurs et, il semblerait, il devrait y avoir une liste de services, mais nous avons triché: nous avons des scripts de démarrage (qui font également partie de la configuration).

Ils exécutent des services pour chaque environnement. Et la méthode services () grep'a simplement tous les services du fichier de son serveur. Cela est dû au fait qu'il n'y a pas tant d'environnements et que les serveurs sont également rarement ajoutés ou supprimés - mais il existe de nombreux services et ils sont mélangés assez souvent. Il était logique de charger la disposition réelle des services à partir de scripts afin de ne pas changer trop souvent la disposition codée en dur.
Après avoir créé un tel modèle de configuration logicielle, des bonus agréables apparaissent. Par exemple, vous pouvez écrire un test comme celui-ci:

Le test est que sur chaque environnement tous les services clés sont présents. Supposons qu'il existe quatre services clés, et que les autres le soient ou non, mais sans ces quatre, cela n'a aucun sens. Vous pouvez vérifier que vous ne les avez oubliés nulle part, qu'ils ont tous des sauvegardes dans le même environnement. Le plus souvent, ces erreurs se produisent lors de la configuration de l'UAT de ces instances, mais elles peuvent également fuir dans PROD. Au final, les erreurs dans l'UAT font également perdre du temps et des nerfs aux testeurs.
La question se pose de maintenir la pertinence du modèle de configuration. Vous pouvez également écrire un test pour cela.
public class HardCodedLayoutConsistencyTest { @Theory eachHardCodedEnvironmentHasConfigFiles(Environment env){ … } @Theory eachConfigFileHasHardCodedEnvironment(File configFile){ … } }
Il existe des fichiers de configuration et une disposition de déploiement dans le code. Et vous pouvez le vérifier pour chaque environnement / serveur / etc. il existe un fichier de configuration correspondant, et pour chaque fichier du format requis - l'environnement correspondant. Dès que vous oubliez d'ajouter quelque chose à un endroit, le test tombe.
L'essentiel est la disposition du déploiement:
- Simplifie l'écriture de tests complexes qui rassemblent des configurations de différentes parties de l'application.
- Les rend plus clairs et plus lisibles. Ils regardent la façon dont vous pensez d'eux à un niveau élevé, et non la façon dont ils passent par les configurations.
- Lors de sa création, lorsque les gens posent des questions, il se révèle beaucoup de choses intéressantes sur le déploiement. Des limitations, des connaissances sacrées implicites, surgissent, par exemple, concernant la possibilité d'héberger deux environnements sur un même serveur. Il s'avère que les développeurs pensent différemment et écrivent leurs services en conséquence. Et ces moments sont utiles pour s'installer entre les développeurs.
- Complète bien la documentation (surtout si ce n'est pas le cas). Même s'il y en a, il est plus agréable pour moi, en tant que développeur, de voir cela dans le code. De plus, vous pouvez y écrire des commentaires importants pour moi et non pour quelqu'un d'autre. Et vous pouvez également coder en dur. Autrement dit, si vous décidez qu'il ne peut pas y avoir deux environnements sur le même serveur, vous pouvez insérer un chèque, et maintenant ce ne sera pas le cas. Au moins, vous saurez si quelqu'un essaie. Autrement dit, il s'agit d'une documentation avec la possibilité de l'appliquer. C'est très utile.
Continuons. Après avoir passé les tests, ils se sont «installés» pendant un an, certains commencent à tomber. Certains commencent à tomber plus tôt, mais ce n'est pas si effrayant. C'est effrayant quand un test écrit il y a un an tombe, vous regardez son message d'erreur et vous ne comprenez pas.

Supposons que je comprenne et accepte qu'il s'agit d'un port réseau non valide - mais où est-il? Avant la conférence, j'ai examiné le fait que nous avons 1 200 fichiers de propriétés dans le projet, répartis sur 90 modules, avec un total de 24 000 lignes. (Bien que j'ai été surpris, mais si vous comptez, ce n'est pas un si grand nombre - pour un service pour 4 fichiers.) Où est ce port?
Il est clair que assertThat () a un argument de message, vous pouvez y entrer quelque chose qui aidera à identifier le lieu. Mais quand vous écrivez un test, vous n'y pensez pas. Et même si vous pensez, vous devez toujours deviner quelle description sera suffisamment détaillée pour être comprise dans un an. Je voudrais automatiser ce moment, afin qu'il existe un moyen d'écrire des tests avec génération automatique d'une description plus ou moins claire, par laquelle vous pouvez trouver une erreur.
Encore une fois, j'ai rêvé et rêvé de quelque chose comme ça:
SELECT environment, server, component, configLocation, propertyName, propertyValue FROM configuration(environment, server, component) WHERE propertyName like “%.port%” and propertyValue is not validNetworkPort()
C'est un tel pseudo-SQL - eh bien, je connais juste SQL, et le cerveau a jeté la solution de ce qui est familier. L'idée est que la plupart des tests de configuration consistent en plusieurs morceaux du même type. Tout d'abord, un sous-ensemble de paramètres est sélectionné par la condition:

Ensuite, concernant ce sous-ensemble, nous vérifions quelque chose par rapport à la valeur:

Et puis, s'il y avait des propriétés dont les valeurs ne satisfont pas le souhait, c'est la «feuille» que nous voulons recevoir dans le message d'erreur:

À un moment donné, je me suis même demandé si je pouvais écrire un analyseur comme SQL, car maintenant ce n'est pas difficile. Mais je me suis alors rendu compte que l'EDI ne le prendrait pas en charge et ne le suggérerait pas, donc les gens devront écrire aveuglément sur ce «SQL» autodidacte, sans invites IDE, sans compilation, sans vérification - ce n'est pas très pratique. J'ai donc dû chercher des solutions supportées par notre langage de programmation. Si nous avions .NET, LINQ aiderait, c'est presque comme SQL.
Il n'y a pas de LINQ en Java, aussi proche que possible des flux. Voici à quoi devrait ressembler ce test dans les flux:
ValueWithContext[] incorrectPorts = flattenedProperties( environment ) .filter( propertyNameContains( ".port" ) ) .filter( !isInteger( propertyValue ) || !isValidNetworkPort( propertyValue ) ) .toArray(); assertThat( incorrectPorts, emptyArray() );
flattenedProperties () prend toutes les configurations de cet environnement, tous les fichiers pour tous les serveurs, services et les développe dans une grande table. Il s'agit essentiellement d'une table de type SQL, mais sous la forme d'un ensemble d'objets Java. Et flattenedProperties () renvoie cet ensemble de chaînes sous forme de flux.

Ensuite, vous ajoutez quelques conditions sur cet ensemble d'objets Java. Dans cet exemple: nous sélectionnons ceux contenant "port" dans le nom de propriété et filtrons ceux dont les valeurs ne sont pas converties en entier, ou non dans la plage valide. Ce sont des valeurs erronées et, en théorie, elles devraient être un ensemble vide.

S'ils ne sont pas un ensemble vide, nous lançons une erreur qui ressemblera à ceci:

Partie 3. Les tests comme support pour la refactorisation
En règle générale, le test de code est l'un des supports de refactorisation les plus puissants. Le refactoring est un processus dangereux, beaucoup de refaire, et je veux m'assurer qu'après cela l'application est toujours viable. Une façon de s'en assurer est de tout superposer tout d'abord avec des tests de tous les côtés, puis de le refactoriser.
Et maintenant, devant moi était la tâche de refactoriser la configuration. Il y a une application qui a été écrite il y a sept ans par une personne intelligente. La configuration de cette application ressemble à ceci:

Ceci est un exemple, il y en a beaucoup plus. Triple permutations d'imbrication, et ceci est utilisé tout au long de la configuration:

Il y a peu de fichiers dans la configuration elle-même, mais ils sont inclus les uns dans les autres. Il utilise une petite extension des propriétés iu - Configuration Apache Commons, qui prend simplement en charge les inclusions et les autorisations entre accolades.
Et l'auteur a fait un travail fantastique en utilisant seulement ces deux choses. Je pense qu'il y a construit une machine de Turing. À certains endroits, il semble vraiment qu'il essaie de faire des calculs en utilisant des inclusions et des substitutions. Je ne sais pas si ce système de Turing est complet, mais il a, à mon avis, essayé de prouver que c'est le cas.
Et l'homme est parti. A écrit, l'application fonctionne, et il a quitté la banque. Tout fonctionne, seul personne ne comprend parfaitement la configuration.
Si nous prenons un service séparé, alors il s'avère 10 inclusions, à une profondeur triple, et au total, si tout est étendu, 450 paramètres. En fait, ce service particulier en utilise 10 à 15%, les autres paramètres sont pour d'autres services, car les fichiers sont partagés, ils sont utilisés par plusieurs services. Mais ce que 10 à 15% utilisent exactement ce service particulier n'est pas si facile à comprendre. L'auteur a apparemment compris. Personne très intelligente, très.
La tâche, respectivement, était de simplifier la configuration, sa refactorisation. En même temps, je voulais que l'application continue de fonctionner, car dans cette situation, les chances sont faibles. Je veux:
- Simplifiez la configuration.
- Pour qu'après refactoring, chaque service ait toujours tous ses paramètres nécessaires.
- Pour qu'il n'ait pas de paramètres supplémentaires. 85% de ceux qui ne lui sont pas liés ne devraient pas encombrer la page.
- Ces services sont toujours connectés avec succès dans des clusters et ont effectué une collaboration.
Le problème est qu'on ne sait pas à quel point ils se connectent maintenant, car le système est très redondant. Par exemple, pour l'avenir: lors de la refactorisation, il s'est avéré que dans l'une des configurations de production, il devait y avoir quatre serveurs dans le clip de sauvegarde, mais en fait il y en avait deux. En raison du niveau élevé de redondance, personne ne l'a remarqué - l'erreur est apparue accidentellement, mais en fait, le niveau de redondance a été longtemps inférieur à ce que nous attendions. Le fait est que nous ne pouvons pas compter sur le fait que la configuration actuelle est correcte partout.
Je mène au fait que vous ne pouvez pas simplement comparer la nouvelle configuration avec l'ancienne. Il peut être équivalent, mais rester en même temps quelque part mal. Il est nécessaire de vérifier le contenu logique.
Programme minimum: isolez chaque paramètre distinct de chaque service dont il a besoin et vérifiez l'exactitude, que le port est un port, l'adresse est une adresse, TTL est un nombre positif, etc. Et vérifiez les relations clés que les services connectent essentiellement aux principaux points de terminaison. Je voulais au moins y parvenir. Autrement dit, contrairement aux exemples précédents, la tâche ici n'est pas de vérifier des paramètres individuels, mais de couvrir la configuration entière avec un réseau complet de vérifications.
Comment le tester?
public class SimpleComponent { … public void configure( final Configuration conf ) { int port = conf.getInt( "Port", -1 ); if( port < 0 ) throw new ConfigurationException(); String ip = conf.getString( "Address", null ); if( ip == null ) throw new ConfigurationException(); … } … }
Comment ai-je résolu ce problème? Il y a un composant simple, dans l'exemple il est simplifié au maximum. (Pour ceux qui n'ont pas rencontré la configuration Apache Commons: l'objet Configuration est comme Propriétés, mais il a toujours les méthodes typées getInt (), getLong (), etc.; nous pouvons supposer que ce sont des juProperties sur de petits stéroïdes.) Supposons qu'un composant nécessite deux paramètres: par exemple, une adresse TCP et un port TCP. Nous les retirons et vérifions. Quelles sont les quatre parties communes ici?

Il s'agit du nom du paramètre, du type, des valeurs par défaut (ici elles sont triviales: null et -1, parfois il y a des valeurs sensées) et quelques validations. Le port ici est validé trop simplement, incomplètement - vous pouvez spécifier le port qui le traversera, mais ce ne sera pas un port réseau valide. Par conséquent, je voudrais également améliorer ce moment. Mais tout d'abord, je veux transformer ces quatre choses en une seule. Par exemple, ceci:
IProperty<Integer> PORT_PROPERTY = intProperty( "Port" ) .withDefaultValue( -1 ) .matchedWith( validNetworkPort() ); IProperty<String> ADDRESS_PROPERTY = stringProperty( "Address" ) .withDefaultValue( null ) .matchedWith( validIPAddress() );
Un tel objet composite est une description d'une propriété qui connaît son nom, sa valeur par défaut, peut faire la validation (ici, j'utilise à nouveau le matcher hamcrest). Et cet objet a quelque chose comme cette interface:
interface IProperty<T> { FetchedValue<T> fetch( final Configuration config ) } class FetchedValue<T> { public final String propertyName; public final T propertyValue; … }
Autrement dit, après avoir créé un objet spécifique à une implémentation spécifique, vous pouvez lui demander d'extraire le paramètre qu'il représente de la configuration. Et il va retirer ce paramètre, vérifier dans le processus, s'il n'y a pas de paramètre, il donnera une valeur par défaut, conduira au type souhaité et le renverra immédiatement avec le nom.
Autrement dit, voici le nom du paramètre et une valeur réelle telle que le service verra s'il demande à cette configuration. Cela vous permet d'envelopper plusieurs lignes de code dans une seule entité, c'est la première simplification dont j'ai besoin.
La deuxième simplification dont j'avais besoin pour résoudre le problème était d'introduire un composant qui a besoin de plusieurs propriétés pour sa configuration. Modèle de configuration des composants:

Nous avions un composant utilisant ces deux propriétés, il existe un modèle pour sa configuration - l'interface IConfigurationModel, que cette classe implémente. IConfigurationModel fait tout ce que fait le composant, mais seulement la partie qui se rapporte à la configuration. Si le composant a besoin de paramètres dans un certain ordre avec certaines valeurs par défaut - IConfigurationModel combine ces informations en elles-mêmes, les encapsule. Toutes les autres actions du composant ne sont pas importantes pour lui. Il s'agit d'un modèle de composant en termes d'accès à la configuration.

L'astuce de cette vue est que les modèles sont combinables. S'il existe un composant qui utilise d'autres composants, et qu'ils y sont combinés, alors de la même manière le modèle de ce composant complexe peut fusionner les résultats des appels de deux sous-composants.
Autrement dit, il est possible de construire une hiérarchie de modèles de configuration parallèle à la hiérarchie des composants eux-mêmes. Sur le modèle supérieur, appelez fetch (), qui renverra la feuille des paramètres qu'il a extraits de la configuration avec leurs noms - exactement ceux dont le composant correspondant aura besoin en temps réel. Si nous avons écrit tous les modèles correctement, bien sûr.
Autrement dit, la tâche consiste à écrire de tels modèles pour chaque composant de l'application qui a accès à la configuration. Dans mon application, il y avait pas mal de tels composants: l'application elle-même est assez feuillue, mais réutilise activement le code, donc seulement 70 classes principales sont configurées. Pour eux, j'ai dû écrire 70 modèles.
Ce qu'il en coûte:
- 12 services
- 70 classes configurables
- => 70 ConfigurationModels (~ 60 sont triviaux);
- 1 à 2 semaines par personne.
J'ai simplement ouvert l'écran avec le code du composant qui se configure lui-même, et sur l'écran suivant, j'ai écrit le code du ConfigurationModel correspondant. La plupart d'entre eux sont triviaux, comme l'exemple illustré. Dans certains cas, il y a des branches et des transitions conditionnelles - là, le code devient plus ramifié, mais tout est également résolu. En une semaine et demie à deux semaines, j'ai résolu ce problème, pour les 70 composants, j'ai décrit les modèles.
Par conséquent, lorsque nous mettons tout cela ensemble, nous obtenons le code suivant:

Pour chaque service / environnement / etc. nous prenons le modèle de configuration, c'est-à-dire le nœud supérieur de cet arbre, et demandons de tout récupérer dans la configuration. À ce stade, toutes les validations passent à l'intérieur, chacune des propriétés, lorsqu'elle se retire de la configuration, vérifie l'exactitude de sa valeur. Si au moins un ne passe pas, une exception s'envolera. Tout le code est obtenu en vérifiant que toutes les valeurs sont valides isolément.
Interdépendances de service
Nous avions encore une question sur la façon de vérifier l'interdépendance des services. C'est un peu plus compliqué, vous devez regarder quel genre d'interdépendance il y a. Il s'est avéré pour moi que les interdépendances se résument au fait que les services doivent «se rencontrer» sur les points de terminaison du réseau. Le service A doit écouter exactement l'adresse à laquelle le service B envoie des paquets, et vice versa. Dans mon exemple, toutes les dépendances entre les configurations des différents services se résumaient à cela. Il était possible de résoudre ce problème d'une manière aussi simple: obtenir des ports et des adresses de différents services et les vérifier. Il y aurait de nombreux tests, ils seraient encombrants. Je suis une personne paresseuse et je ne voulais pas ça. J'ai donc fait autrement.
Tout d'abord, je voulais en quelque sorte résumer ce point de terminaison de réseau lui-même. Par exemple, pour une connexion TCP, vous n'avez besoin que de deux paramètres: l'adresse et le port. Pour une connexion multicast, quatre paramètres. Je voudrais l'écraser dans une sorte d'objet. J'ai fait cela dans l'objet Endpoint, qui cache à l'intérieur tout ce dont vous avez besoin. La diapositive est un exemple d'OutcomingTCPEndpoint, une connexion réseau TCP sortante.
IProperty<IEndpoint> TCP_REQUEST = outcomingTCP(
En dehors, l'interface Endpoint est émise par la seule méthode matches (), dans laquelle vous pouvez donner un autre Endpoint et savoir si cette paire est similaire aux parties serveur et client d'une connexion.Pourquoi est-ce "comme"? Parce que nous ne savons pas ce qui se passera dans la réalité: peut-être, formellement, il devrait se connecter aux adresses de port, mais sur un vrai réseau, il y a un pare-feu entre ces nœuds - nous ne pouvons le vérifier que par configuration. Mais nous pouvons savoir s'ils ne correspondent pas officiellement aux ports / adresses. Alors, très probablement, et en réalité, eux aussi, ne se connecteront pas entre eux.En conséquence, au lieu des valeurs de propriété primitives, des groupes d'adresses de port-multidiffusion, nous avons maintenant une propriété complexe qui renvoie Endpoint. Et dans tous les ConfigurationModels, au lieu de propriétés distinctes, il y en a de si complexes. Qu'est-ce que cela nous donne? Cela nous donne ce type de vérification de la connectivité du cluster: ValueWithContext[] allEndpoints = flattenedConfigurationValues(environment) .filter( valueIsEndpoint() ) .toArray(); ValueWithContext[] unpairedEndpoints = Arrays.stream( allEndpoints ) .filter( e -> !hasMatchedEndpoint(e, allEndpoints) ) .toArray(); assertThat( unpairedEndpoints, emptyArray() );
De toutes les propriétés de cet environnement, nous sélectionnons des points de terminaison, puis nous spécifions simplement s'il y en a qui ne se connectent à personne et ne se connectent à personne. Toutes les machines précédentes vous permettent d'effectuer cette vérification sur plusieurs lignes. Ici, plus précisément, la complexité de la vérification de «tout le monde avec tout le monde» sera O (n ^ 2), mais ce n'est pas si important, car il existe une centaine de points de terminaison, vous ne pouvez même pas les optimiser.C'est-à-dire que pour chaque Endpoint, nous passons par tout le reste et découvrons s'il y en a au moins un qui s'y connecte. Si aucun n'a été trouvé, il aurait probablement dû être là, mais à cause d'une erreur, il était parti.En général, il se peut que le service présente des trous qui dépassent, c'est-à-dire aux services externes, en dehors de l'application actuelle. Ces trous devront être explicitement filtrés. J'ai eu de la chance, dans mon cas, les clients externes se connectent à travers les mêmes trous que le service lui-même utilise à l'intérieur de lui-même. C'est un tel fermé et économique dans le sens des connexions réseau.Ceci est la solution au problème de test. Et la tâche principale, je me souviens, était la refactorisation. Et j'étais prêt à faire le refactoring avec mes mains, mais quand j'ai fait tous ces tests et qu'ils ont commencé à travailler, j'ai réalisé que j'étais en mesure de faire le refactoring automatiquement pour le changement.Toute cette hiérarchie ConfigurationModel vous permet de:- Convertir dans un autre format
- Effectuer des demandes de configuration («tous les ports udp utilisés par les services sur ce serveur»)
- .
Je peux faire glisser la configuration entière dans la mémoire de telle manière que chaque propriété retrace son origine. Après cela, je peux convertir cette configuration en mémoire et la verser dans d'autres fichiers, dans un ordre différent, dans un format différent - comme cela me convient. Alors je l'ai fait: j'ai écrit un petit code pour convertir cette feuille sous la forme dans laquelle je voulais la convertir. En fait, j'ai dû le faire plusieurs fois, car au départ, il n'était pas évident de savoir quel format serait pratique et compréhensible, et j'ai dû faire plusieurs visites pour l'essayer.Mais cela ne suffit pas. Avec cette construction, en utilisant ConfigurationModels, je peux exécuter des demandes de configuration. Soulevez-le en mémoire et découvrez quels ports UDP spécifiques sont utilisés sur ce serveur par différents services, demandez une liste des ports utilisés, avec les instructions des services.De plus, je peux connecter les services sur des endpoints et les afficher sous forme de diagramme, exporter vers .dot. Et d'autres demandes similaires sont facilement faites. Le résultat a été un tel couteau suisse - les coûts de sa construction ont payé assez bien.C'est là que je termine. Conclusions:
- À mon avis, d'après mon expérience, tester la configuration est important et amusant.
- Il y a beaucoup de fruits bas, le seuil d'entrée pour un début est bas. Vous pouvez résoudre des problèmes complexes, mais il existe également de nombreux problèmes simples.
- Si vous utilisez un petit cerveau, vous pouvez obtenir des outils puissants qui vous permettent non seulement de tester, mais aussi d'avoir beaucoup à voir avec la configuration.
Si vous avez aimé ce reportage du Heisenbug 2018 Piter, veuillez noter: du 6 au 7 décembre, le prochain Heisenbug se tiendra à Moscou . La plupart des descriptions des nouveaux rapports sont déjà disponibles sur le site Web de la conférence . Et à partir du 1er novembre, le prix des billets augmente - il est donc logique de prendre une décision maintenant.