Bonjour, je m'appelle Maxim, je suis administrateur système. Il y a trois ans, mes collègues et moi avons commencé à transférer des produits vers des microservices et avons décidé d'utiliser Openstack comme plate-forme, et nous avons rencontré un certain nombre de râteaux non évidents lors de l'automatisation des circuits de test. Cet article porte sur les nuances de la configuration d'OpenStack, que l'on ne trouve guère sur la cinquième page des résultats des moteurs de recherche (ou mieux, elles sont facilement sur la première).
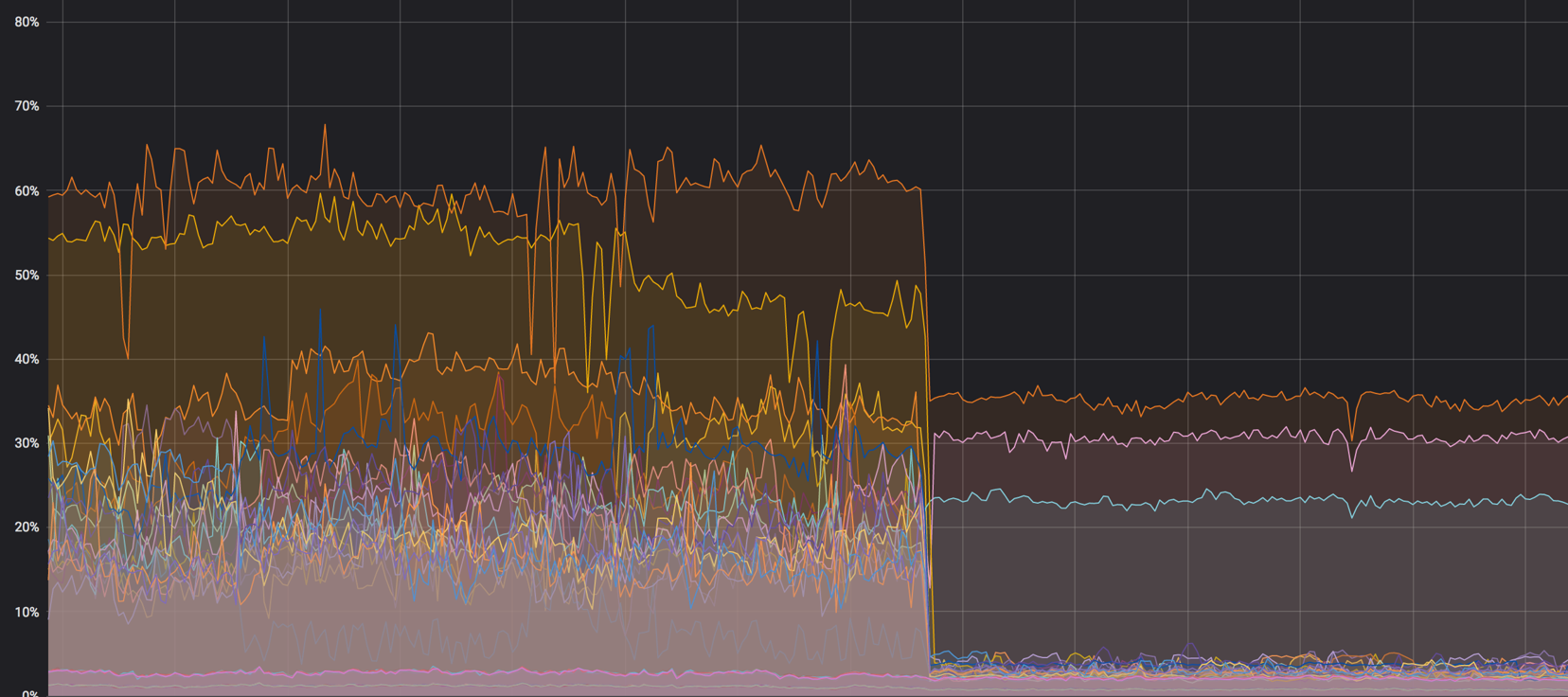
La charge sur les noyaux: c'était - c'est devenu
NAT
Dans certains cas, nous utilisons dualstack. C'est lorsque la machine virtuelle reçoit deux adresses à la fois - IPv4 et IPv6. Tout d'abord, nous nous sommes assurés que l'adresse v4 «flottante» a été attribuée dans le réseau interne via NAT et la machine a reçu la v6 via BGP, mais cela pose quelques problèmes.
NAT - un nœud supplémentaire dans le réseau, où même sans lui, vous devez surveiller la répartition normale de la charge. L'apparition de NAT sur le réseau entraîne presque toujours des difficultés de débogage - il y a une IP sur l'hôte, l'autre dans la base de données, et il devient difficile de suivre la demande. Les recherches en masse commencent et la solution sera toujours dans OpenStack.
NAT ne permet toujours pas de segmenter normalement l'accès entre les projets. Tous les projets ont leurs propres sous-réseaux, les IP flottantes migrent constamment et avec NAT, il devient absolument impossible de gérer cela. Certaines installations parlent d'utiliser NAT 1 en 1 (l'adresse interne ne diffère pas de l'adresse externe), mais cela laisse encore des liens inutiles dans la chaîne d'interaction avec les services externes. Nous sommes arrivés à la conclusion que pour nous, la meilleure option est un réseau BGP.
Plus c'est simple, mieux c'est
Nous avons essayé divers outils d'automatisation, mais nous nous sommes installés sur Ansible. C'est un bon outil, mais ses fonctionnalités standard (même en tenant compte de modules supplémentaires) peuvent ne pas être suffisantes dans certaines situations difficiles.
Par exemple, via le module Ansible, vous ne pouvez pas spécifier à partir de quelles adresses de sous-réseau allouer. Autrement dit, vous pouvez spécifier un réseau, mais vous ne pouvez pas définir un pool d'adresses spécifique. La commande shell qui crée l'IP flottante vous aidera ici:
openstack floating ip create -c floating_ip_address -f value -project \ {{ project name }} —subnet private-v4 CLOUD_NET
Un autre exemple de fonctionnalité manquante: en raison de la double pile, nous ne pouvons pas créer correctement un routeur avec deux ports pour v4 et v6. C'est là qu'un script bash est utile:
Le script crée un routeur, lui ajoute des sous-réseaux v4 et v6 et lui attribue une passerelle externe.
Réessayer
Dans toute situation incompréhensible - redémarrez. Réessayez, créez une instance, un routeur ou un enregistrement DNS, car vous ne comprenez pas toujours rapidement quel est votre problème. Réessayer peut retarder la dégradation du service, et à ce moment, vous pouvez calmement et sans nerfs résoudre le problème.
Tous les conseils ci-dessus fonctionnent parfaitement avec Terraform, Puppet et tout le reste.
Tout a sa place
Tout service important (OpenStack ne fait pas exception) combine de nombreux services plus petits qui peuvent interférer les uns avec les autres. Voici un exemple.
Agent réseau Neutron-L2-agent est responsable de la connectivité réseau dans OpenStack. Si tous les autres agents sont partiellement sur les contrôleurs, alors L2, en raison des spécificités, est présent partout.
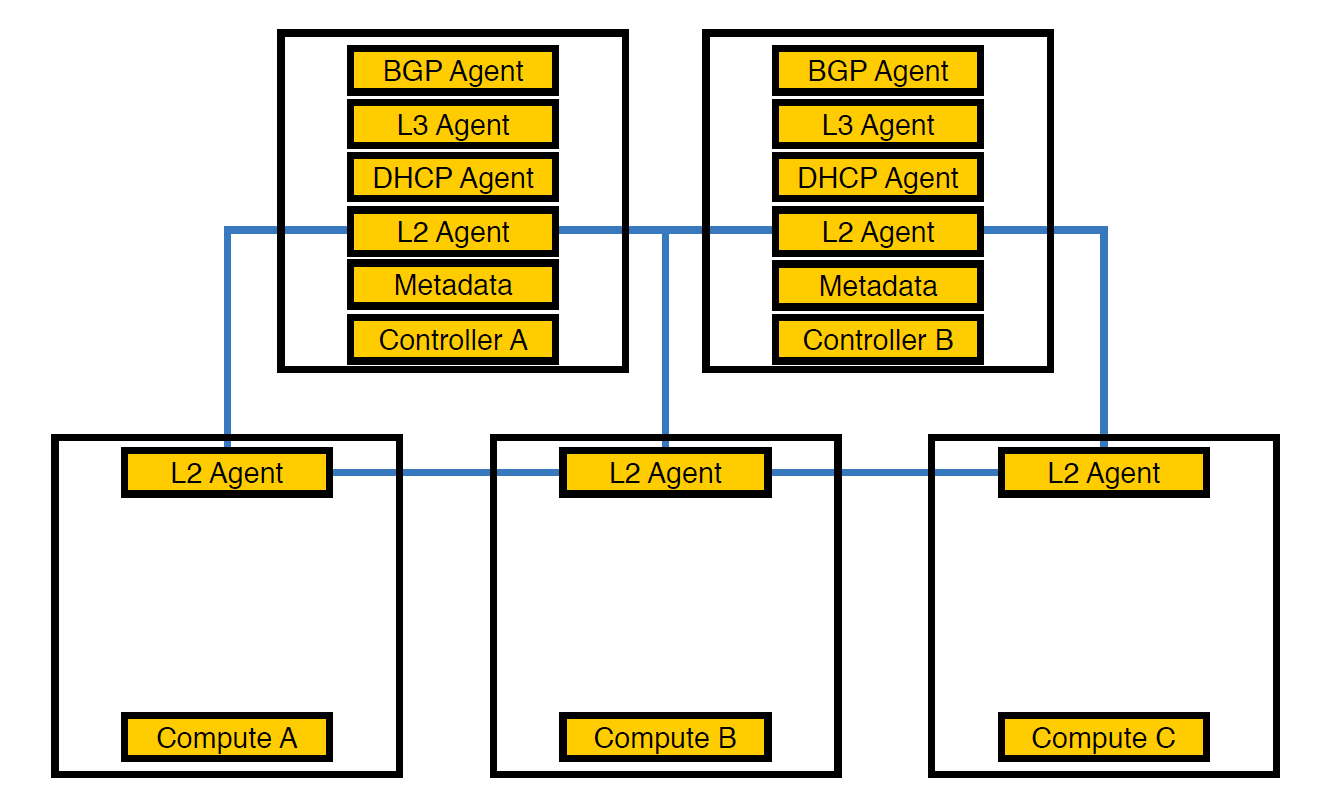
Voici à quoi ressemblait notre infrastructure au tout début, jusqu'à ce que le nombre de projets dépasse 50
À ce stade, nous avons réalisé qu'en raison de cette disposition des agents, les contrôleurs ne pouvaient pas faire face à la charge, et transféré les agents aux nœuds de calcul. Ils sont plus puissants que les contrôleurs et, en outre, le contrôleur n'a pas à gérer tout le traitement - il doit confier la tâche au nœud d'exécution et le nœud l'exécutera.

Agents transférés aux nœuds de calcul
Cependant, cela ne suffisait pas, car un tel arrangement avait un mauvais effet sur les performances des machines virtuelles. Avec une densité de 14 cœurs virtuels par physique, si un agent réseau commençait à charger le flux, cela pouvait affecter plusieurs machines virtuelles à la fois.
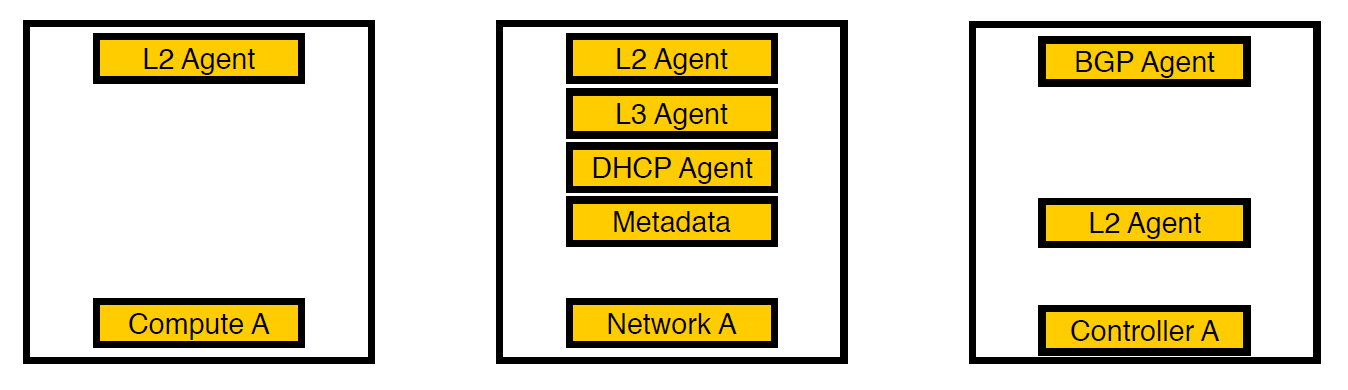
Troisième itération. Des nœuds sélectionnés sont apparus.
Nous avons pensé et déplacé les agents vers des nœuds de réseau distincts. Désormais, seuls les services pour les machines virtuelles restent sur les nœuds de calcul, tous les agents travaillent sur les nœuds du réseau et seuls les agents bgp qui traitent du réseau v6 restent sur les contrôleurs (puisqu'un agent bgp ne peut servir qu'un seul type de réseau). La L2 est restée partout, car sans elle, comme nous l'avons écrit plus haut, il n'y aurait pas de connectivité sur le réseau.
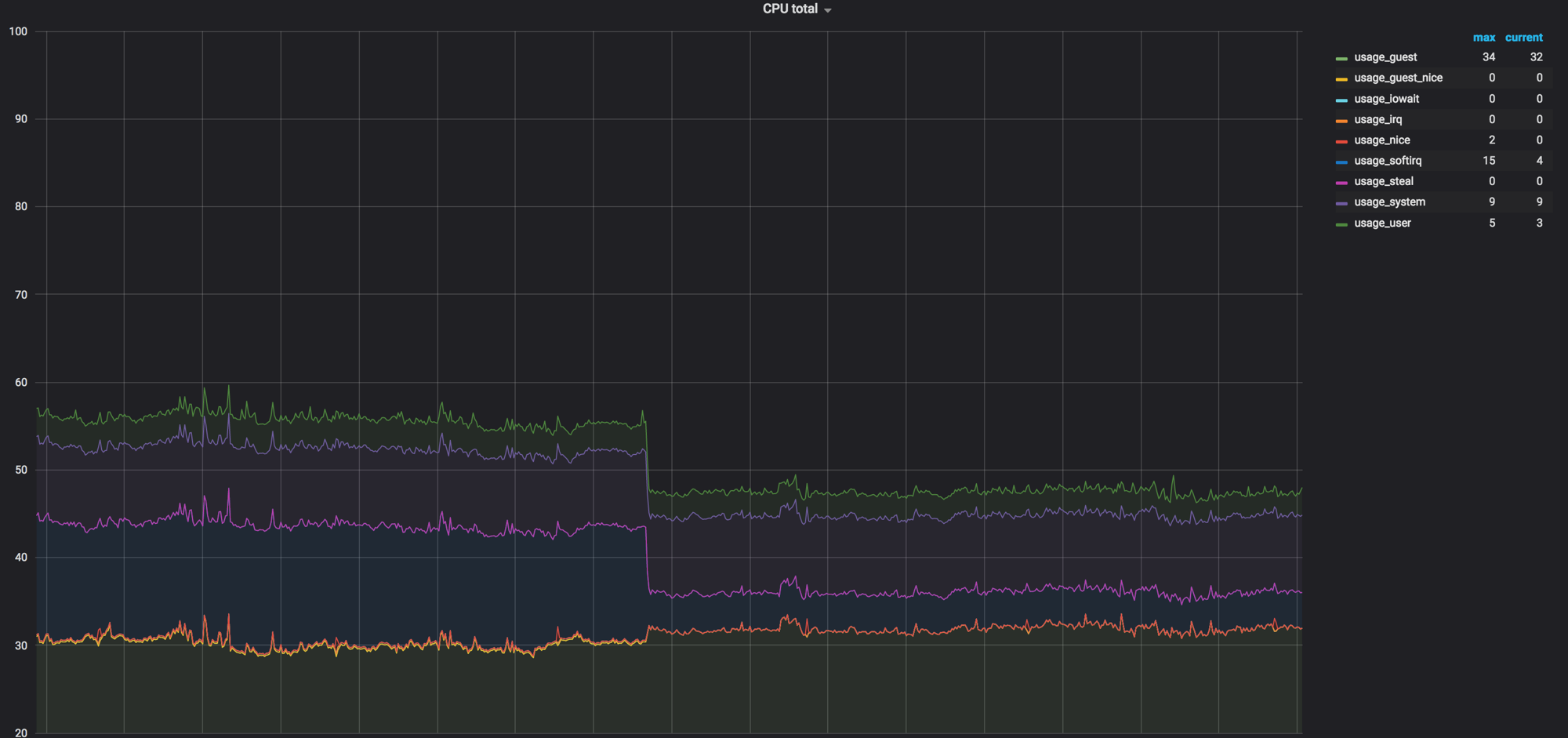
Chargez le graphique des nœuds de calcul avant que tout soit mélangé. Il était d'environ 60%, mais la charge a chuté de manière insignifiante

La charge sur softirq avant que les agents réseau ne suppriment les nœuds de calcul. 3 noyaux sont restés chargés. A cette époque, nous pensions que c'était normal
Code comme documentation
Parfois, il arrive que le code soit la documentation, en particulier dans des services aussi importants que OpenStack. Avec un cycle de publication de six mois, les développeurs oublient ou n'ont tout simplement pas le temps de documenter certaines choses, et cela se passe comme dans l'exemple ci-dessous.
À propos des délais
Une fois que nous avons vu que les appels de Neutron à Open vSwitch ne tiennent pas en cinq secondes et tombent en timeout.
127.0.0.1:29696: no response to inactivity probe after 10 seconds, disconnecting neutron.agent.ovsdb.native.commands TimeoutException: Commands [DbSetCommand(table=Port, col_values=(('tag', 11),), record=qtoq69a81c6-e2)] exceeded timeout 5 seconds
Bien sûr, nous avons supposé que quelque part dans les paramètres, cela était fixe. Nous avons regardé dans les configurations, la documentation et le paquet deb, mais au début, ils n’ont rien trouvé. En conséquence, la description du paramètre souhaité a été trouvée sur la cinquième page des résultats de la recherche - nous avons réexaminé le code et trouvé le bon endroit. Le réglage est le suivant:
ovs_vsctl_timeout = 30
Nous l'avons réglé pendant 30 secondes (il était de 5), et tout a commencé à fonctionner un peu mieux.
Voici une autre évidence: lorsque vous redémarrez des composants réseau, certains paramètres d'Open vSwitch peuvent être réinitialisés. Cela se produit, par exemple, avec ovs-vsctl inactivity_probe. C'est également un délai d'attente, mais cela affecte les appels d'ovs-vsctl lui-même à sa base de données. Nous l'avons ajouté à systemd init, ce qui nous a permis de démarrer tous les commutateurs avec les paramètres dont nous avons besoin au démarrage.
ovs-vsctl set Controller "br-int" inactivity_probe=30000
À propos des paramètres de pile réseau
Nous avons également dû nous éloigner un peu des paramètres généralement acceptés dans la pile réseau, que nous utilisons sur nos autres serveurs.
Voici le paramètre de durée de stockage des enregistrements ARP dans une table:
net.ipv4.neigh.default.base_reachable_time = 60 net.ipv4.neigh.default.gc_stale_time=60
La valeur par défaut est 1 jour. En général, un schéma peut vivre pendant quelques semaines, mais pendant une journée, les schémas peuvent être recréés 4 à 6 fois, tandis que la correspondance de l'adresse MAC et de l'adresse IP change constamment. Pour que les déchets ne s'accumulent pas, nous avons réglé le temps sur une minute.
net.ipv4.conf.default.arp_notify = 1 net.nf_conntrack_max = 1000000 (default 262144) net.netfilter.nf_conntrack_max = 1000000 (default 262144)
De plus, nous avons forcé l'envoi de notifications ARP lors de l'augmentation de l'interface réseau. Nous avons également augmenté la table conntrack, car lors de l'utilisation de NAT et d'ip flottante, nous n'avions pas la valeur par défaut. Passé à un million (avec 262 144 par défaut), tout est devenu encore meilleur.
Nous corrigeons la taille de la table MAC d'Open vSwitch lui-même:
ovs-vsctl set bridge bt-int other-config:mac-table-size=50000 (default 2048)

Après tous les réglages, 40% de la charge est devenue presque nulle
rx-flow-hash
Pour répartir le traitement du trafic udp entre toutes les files d'attente et les threads de processeur, nous avons inclus rx-flow-hash. Sur les cartes réseau Intel, notamment dans le pilote i40e, cette option est désactivée par défaut. Nous avons des hyperviseurs avec 72 cœurs dans notre infrastructure, et si un seul est occupé, ce n'est pas très optimal.
C'est fait comme ceci:
ethtool -N eno50 rx-flow-hash udp4 sdfn

Une conclusion importante: vous pouvez tout configurer du tout. La configuration par défaut s'intégrera à un moment donné (comme nous l'avons fait), mais le problème avec les délais d'attente a rendu nécessaire la recherche. Et c'est normal.
Règles de sécurité
Selon les exigences du service de sécurité, tous les projets au sein de l'entreprise ont des règles personnelles et globales - il y en a beaucoup. Lorsque nous avons déménagé à l'étranger de 300 machines virtuelles vers un seul hyperviseur, tout cela s'est traduit par 80 000 règles pour iptables. Pour iptables lui-même, ce n'est pas un problème, mais Neutron charge ces règles de RabbitMQ dans un seul flux (car il est écrit en Python, et tout est triste avec le multithreading là-bas). L'agent Neutron se bloque, perd la connexion avec RabbitMQ et une réaction en chaîne suite à des délais d'attente, et après la récupération, Neutron redemande toutes les règles, démarre la synchronisation et tout recommence.
Parallèlement à cela, le temps de création des stands est passé de 20 à 40 minutes à, au mieux, une heure.
Au début, nous avons simplement tout emballé avec des récupérations (déjà à ce stade, nous avons réalisé que le problème ne pouvait pas être résolu si rapidement), puis nous avons commencé à utiliser FWaaS . Avec lui, nous avons supprimé des règles de sécurité avec des nœuds de calcul pour séparer les nœuds du réseau où se trouve le routeur lui-même.

Source - docs.openstack.org
Ainsi, à l'intérieur du projet, il y a un accès complet à tout ce qui est nécessaire et des règles de sécurité sont appliquées pour les connexions externes. Nous avons donc réduit la charge sur Neutron et sommes revenus à 20-30 minutes de création d'un environnement de test.
Résumé
OpenStack est une chose intéressante dans laquelle vous pouvez recycler le fer, créer un cloud interne et créer quelque chose d'autre à partir de celui-ci. En plus de cela, il y a une grande communauté et un groupe actif à Telegram , où ils nous ont informés des temps morts.
C’est tout. Posez des questions, mes collègues et moi sommes prêts à répondre et à partager notre expérience.