Partie I. R extrait et dessine
Bien sûr, PostgreSQL a été créé dès le début comme un SGBD universel, et non comme un système OLAP spécialisé. Mais l'un des grands avantages de Postgres est sa prise en charge des langages de programmation, avec lesquels vous pouvez en tirer quelque chose. Étant donné l'abondance des langages procéduraux intégrés, il n'a tout simplement pas d'égal. PL / R - implémentation serveur de
R - le langage préféré des analystes - l'un d'eux. Mais plus à ce sujet plus tard.
R est un langage étonnant avec des types de données particuliers - la
list , par exemple, peut inclure non seulement des données de différents types, mais aussi des fonctions (en général, le langage est éclectique, et nous ne parlerons pas de son appartenance à une famille particulière, afin de ne pas provoquer de discussions distrayantes). Il a un joli type de données
data.frame qui imite une table RDBMS - c'est une matrice dans laquelle les colonnes contiennent différents types de données qui sont communs au niveau de la colonne. Par conséquent (et pour d'autres raisons), travailler avec des bases de données dans R est très pratique.
Nous travaillerons sur la ligne de commande dans l'environnement
RStudio et nous nous connecterons à PostgreSQL via le
pilote ODBC RpostgreSQL . Ils sont faciles à installer.
Puisque R a été créé comme une sorte de variante du langage
S pour ceux qui sont engagés dans les statistiques, nous donnerons également des exemples de statistiques simples avec des graphiques simples. Nous n'avons aucun objectif d'introduire le langage, mais il y a un objectif de montrer l'interaction de
R et PostgreSQL .
Il existe trois façons de traiter les données stockées dans PostgreSQL.
Premièrement, vous pouvez pomper des données à partir de la base de données par n'importe quel moyen pratique, les emballer, par exemple, dans JSON - R les comprend - et les traiter plus loin dans R. Ce n'est généralement pas le moyen le plus efficace et certainement pas le plus intéressant, nous ne le considérerons pas ici.
Deuxièmement, vous pouvez communiquer avec la base de données - lire à partir de celle-ci et y vider des données - à partir de l'environnement R en tant que client, en utilisant le pilote ODBC / DBI, en traitant les données dans R. Nous montrerons comment cela se fait.
Et enfin, vous pouvez effectuer le traitement avec les outils R déjà sur le serveur de base de données, en utilisant PL / R comme langage procédural intégré. Cela a du sens dans un certain nombre de cas, car dans R, il existe, par exemple, des moyens pratiques d'agréger des données qui ne sont pas dans
pl/pgsql . Nous le montrerons aussi.
Une approche courante consiste à utiliser les 2e et 3e options dans différentes phases du projet: déboguez d'abord le code en tant que programme externe, puis transférez-le dans la base de données.
Commençons. R langage interprété. Par conséquent, vous pouvez suivre les étapes ou vider le code dans un script. Une question de goût: les exemples de cet article sont courts.
Tout d'abord, bien sûr, vous devez connecter le pilote approprié:
# install.packages("RPostgreSQL") require("RPostgreSQL") drv <- dbDriver("PostgreSQL")
L'opération d'affectation apparaît dans R, comme vous pouvez le voir, particulière. En général, dans R a <- b, cela signifie la même chose que b -> a, mais la première façon d'écrire est plus courante.
Nous allons prendre la base de données terminée: la base de données sur le
transport aérien , qui est utilisée par les
supports de formation Postgres Professional . Sur
cette page, vous pouvez choisir l'option de base de données à goûter (c'est-à-dire la taille) et lire sa description. Nous reproduisons le schéma de données pour plus de commodité:
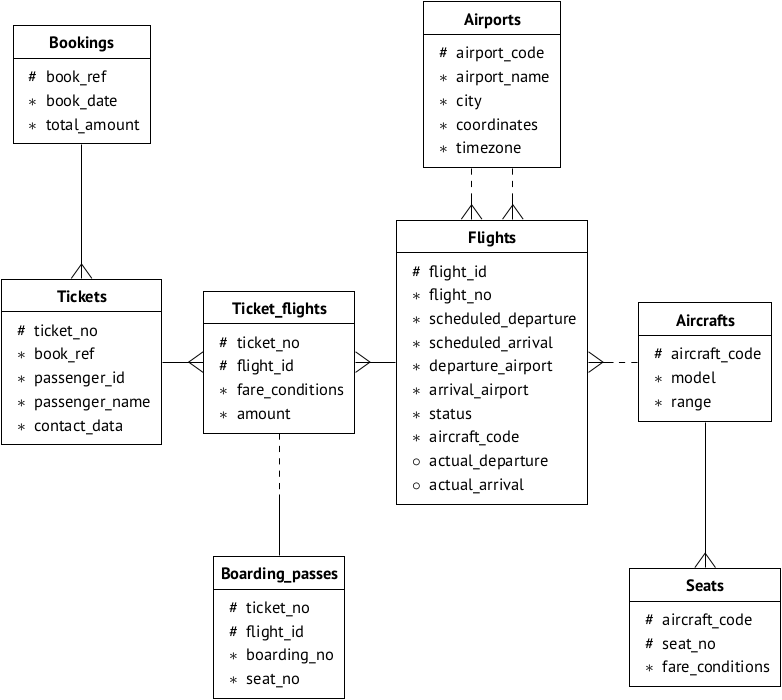
Supposons que la base soit installée sur le serveur 192.168.1.100 et s'appelle
demo . Connectez-vous:
con <- dbConnect(drv, dbname = "demo", host = "192.168.1.100", port = 5434, user = "u_r")
Nous continuons. Voyons avec une telle demande à quelles villes les vols sont le plus souvent en retard:
SELECT ap.city, avg(extract(EPOCH FROM f.actual_arrival) - extract(EPOCH FROM f.scheduled_arrival))/60.0 t FROM airports ap, flights f WHERE ap.airport_code = f.departure_airport AND f.scheduled_arrival < f.actual_arrival AND f.departure_airport = ap.airport_code GROUP BY ap.city ORDER BY t DESC LIMIT 10;
Pour obtenir des minutes de retard, nous avons utilisé la construction d'extrait postgres
extract(EPOCH FROM ...) pour extraire les secondes "absolues" d'un champ d'
timestamp et divisées par 60,0, plutôt que 60, pour éviter de jeter le reste lors de la division, compris comme entier.
EXTRACT MINUTE ne peut pas être utilisé, car il y a des retards de plus d'une heure. Nous faisons la moyenne du retard par l'opérateur
avg .
Nous passons le texte à la variable et envoyons la requête au serveur:
sql1 <- "SELECT ... ;" res1 <- dbGetQuery(con, sql1)
Nous allons maintenant déterminer sous quelle forme la demande est arrivée. Pour ce faire, le langage R a une fonction
class() class (res1)
Cela montrera que le résultat a été compressé dans le type
data.frame , c'est-à-dire que nous rappelons qu'il s'agit d'un analogue de la table de base: en fait, c'est une matrice avec des colonnes de types arbitraires. Soit dit en passant, elle connaît les noms des colonnes, et les colonnes, le cas échéant, sont accessibles, par exemple, comme ceci:
print (res1$city)
Il est temps de réfléchir à la façon de visualiser les résultats. Pour ce faire, vous pouvez voir ce que nous avons. Par exemple, sélectionnez le programme approprié dans
cette liste :
- Graphiques R-Bar (Bar)
- R-Boxplots (stock)
- Histogrammes R
- Graphiques R-Line (graphiques)
- Diagrammes de dispersion R (point)
Il convient de garder à l'esprit que pour chaque type d'entrée, un type de données adapté à l'image est fourni. Choisissez un graphique à barres (barres allongées). Il nécessite deux vecteurs pour les valeurs axiales. Le type "vecteur" dans R est simplement un ensemble de valeurs du même type.
c() est un constructeur vectoriel.
Vous pouvez générer les deux vecteurs nécessaires à partir d'un résultat du type
data.frame comme suit:
Time <- res1[,c('t')] City <- res1[,c('city')] class (Time) class (City)
Les expressions sur le côté droit semblent étranges, mais c'est une technique pratique. De plus, diverses expressions peuvent être écrites de manière très compacte dans R. Entre crochets avant la virgule, l'index de la série, après la virgule - l'index de la colonne. Le fait que la virgule ne vaille rien signifie seulement que toutes les valeurs seront sélectionnées dans la colonne correspondante.
La classe Time est
numeric et la classe City est un
character . Ce sont des variétés de vecteurs.
Vous pouvez maintenant effectuer la visualisation elle-même. Vous devez spécifier un fichier image.
png(file = "/home/igor_le/R/pics/bars_horiz.png")
Après cela, une procédure fastidieuse suit: définissez les paramètres (
par ) des graphiques. Et pour ne pas dire que tout dans les packages graphiques R était intuitif. Par exemple, le paramètre
las détermine la position des étiquettes avec des valeurs le long des axes par rapport aux axes eux-mêmes:
- 0 et par défaut parallèle aux axes;
- 1 - toujours horizontal;
- 2 - perpendiculaire aux axes;
- 3 - toujours debout
Nous ne peindrons pas tous les paramètres. En général, il y en a beaucoup: champs, échelles, couleurs - recherchez, expérimentez à votre guise.
par(las=1) par(mai=c(1,2,1,1))
Enfin, nous construisons un graphique à partir des colonnes couchées:
barplot(Time, names.arg=City, horiz=TRUE, xlab=" ()", col="green", main=" ", border="red", cex.names=0.9)
Ce n'est pas tout. Je dois dire une dernière chose:
dev.off()

Pour changer, nous allons encore dessiner le diagramme à points du retard. Supprimez LIMIT de la demande, le reste est le même. Mais un nuage de points a besoin d'un vecteur, pas de deux.
Dots <- res2[,c('t')] png(file = "/home/igor_le/R/scripts/scatter.png") plot(input5, xlab="",ylab="",main=" ") dev.off()
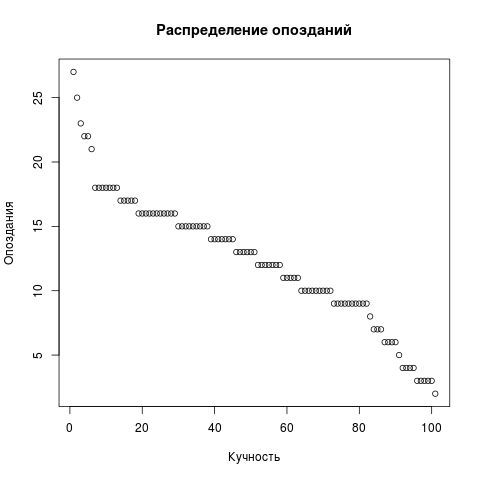
Pour la visualisation, nous avons utilisé des packages standard. Il est clair que R est un langage populaire et les packages existent autour de l'infini. Vous pouvez poser des questions sur ceux déjà installés comme celui-ci:
library()
Partie II R génère des retraités
R est pratique à utiliser non seulement pour l'analyse des données, mais aussi pour leur génération. Là où il existe de riches fonctions statistiques, il ne peut y avoir une variété d'algorithmes pour créer des séquences aléatoires. En particulier, vous pouvez utiliser des distributions typiques (gaussiennes) et pas tout à fait typiques (Zipf) pour simuler des requêtes de base de données.
Mais plus à ce sujet dans la partie suivante.