Cet article se concentrera sur l'écriture et la prise en charge d'une spécification utile et pertinente pour un projet d'API REST, ce qui permettra d'économiser beaucoup de code supplémentaire, ainsi que d'améliorer sérieusement l'intégrité, la fiabilité et la transparence du projet dans son ensemble.
Qu'est-ce qu'une API RESTful?
Ceci est un mythe.
Sérieusement, si vous pensez que votre projet a une API RESTful, vous vous trompez certainement. L'idée de RESTful est de construire une API qui à tous égards respecte les règles et restrictions architecturales décrites par le style REST, mais en conditions réelles, cela est presque impossible .
D'une part, REST contient trop de définitions vagues et ambiguës. Par exemple, certains termes des dictionnaires des méthodes HTTP et des codes d'état ne sont pas utilisés dans la pratique pour leur usage prévu, alors que beaucoup d'entre eux ne sont pas du tout utilisés.
D'un autre côté, REST crée trop de restrictions. Par exemple, l'utilisation atomique des ressources dans le monde réel n'est pas rationnelle pour les API utilisées par les applications mobiles. Un refus total de stocker l'état entre les requêtes est essentiellement une interdiction du mécanisme des sessions utilisateur utilisées dans de nombreuses API.
Mais attendez, tout n'est pas si mal!
Pourquoi avons-nous besoin de la spécification REST API?
Malgré ces lacunes, avec une approche raisonnable, REST reste toujours une excellente base pour concevoir des API vraiment cool. Une telle API doit avoir une uniformité interne, une structure claire, une documentation pratique et une bonne couverture des tests unitaires. Tout cela peut être réalisé en développant une spécification de qualité pour votre API.
Le plus souvent, la spécification de l' API REST est associée à sa documentation . Contrairement à la première (qui est une description formelle de votre API), la documentation est destinée à être lue par des personnes: par exemple, les développeurs d'une application mobile ou Web utilisant votre API.
Cependant, en plus de créer réellement de la documentation, une description correcte de l'API peut toujours apporter de nombreux avantages. Dans l'article, je veux partager des exemples de la façon dont, en utilisant l'utilisation compétente de la spécification, vous pouvez:
- rendre les tests unitaires plus simples et plus fiables;
- configurer le prétraitement et la validation des données d'entrée;
- automatiser la sérialisation et garantir l'intégrité des réponses;
- et même profiter de la frappe statique.
Openapi
Le format généralement accepté pour décrire l'API REST aujourd'hui est OpenAPI , également connu sous le nom de Swagger . Cette spécification est un fichier unique au format JSON ou YAML, composé de trois sections:
- un en-tête contenant le nom, la description et la version de l'API, ainsi que des informations supplémentaires;
- une description de toutes les ressources, y compris leurs identifiants, les méthodes HTTP, tous les paramètres d'entrée, ainsi que les codes et les formats du corps de réponse, avec des liens vers les définitions;
- toutes les définitions d'objets au format JSON Schema qui peuvent être utilisées à la fois dans les paramètres d'entrée et dans les réponses.
OpenAPI a un sérieux inconvénient - la complexité de la structure et, souvent, la redondance . Pour un petit projet, le contenu du fichier JSON de spécification peut rapidement atteindre plusieurs milliers de lignes. Il n'est pas possible de gérer ce fichier manuellement dans ce formulaire. C'est une menace sérieuse pour l'idée même de maintenir une spécification à jour à mesure que l'API évolue.
Il existe de nombreux éditeurs visuels qui vous permettent de décrire l'API et de former la spécification OpenAPI résultante. À leur tour, des services et des solutions cloud supplémentaires sont basés sur eux, par exemple Swagger , Apiary , Stoplight , Restlet et autres.
Cependant, pour moi, ces services n'étaient pas très pratiques en raison de la difficulté de modifier rapidement la spécification et de la combiner avec le processus d'écriture de code. Un autre inconvénient est la dépendance à l'égard de l'ensemble des fonctions de chaque service particulier. Par exemple, il est presque impossible de mettre en œuvre des tests unitaires à part entière uniquement au moyen d'un service cloud. La génération de code et même la création de "plugs" pour les terminaux, bien que cela semble très possible, sont pratiquement inutiles dans la pratique.
Tinyspec
Dans cet article, j'utiliserai des exemples basés sur le format de description de l'API REST native - tinyspec . Le format est de petits fichiers qui décrivent les points de terminaison et les modèles de données utilisés dans le projet avec une syntaxe intuitive. Les fichiers sont stockés à côté du code, ce qui vous permet de vérifier avec eux et de les modifier en cours d'écriture. Dans le même temps, tinyspec est automatiquement compilé dans une OpenAPI à part entière, qui peut être immédiatement utilisée dans le projet. Il est temps de vous dire exactement comment.
Dans cet article, je donnerai des exemples de Node.js (koa, express) et Ruby on Rails, bien que ces pratiques s'appliquent à la plupart des technologies, y compris Python, PHP et Java.
Quand la spécification est incroyablement utile
1. Tests unitaires des points finaux
Le développement basé sur le comportement (BDD) est idéal pour développer une API REST. Le moyen le plus pratique d'écrire des tests unitaires n'est pas pour des classes, modèles et contrôleurs individuels, mais pour des points de terminaison spécifiques. Dans chaque test, vous émulez une véritable requête HTTP et vérifiez la réponse du serveur. Dans Node.js, pour émuler les demandes de test, il existe des supertest et chai-http , dans Ruby on Rails - airborne .
Supposons que nous ayons un schéma d' User et un point de terminaison GET /users qui renvoie tous les utilisateurs. Voici la syntaxe tinyspec qui décrit ceci:
- Fichier User.models.tinyspec :
User {name, isAdmin: b, age?: i}
- Fichier users.endpoints.tinyspec :
GET /users => {users: User[]}
Voici à quoi ressemblera notre test:
Node.js
describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200); expect(users[0].name).to.be('string'); expect(users[0].isAdmin).to.be('boolean'); expect(users[0].age).to.be.oneOf(['boolean', null]); }); });
Ruby on Rails
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect_json_types('users.*', { name: :string, isAdmin: :boolean, age: :integer_or_null, }) end end
Lorsque nous avons une spécification qui décrit les formats de réponse du serveur, nous pouvons simplifier le test et vérifier simplement la réponse par rapport à cette spécification . Pour ce faire, nous profiterons du fait que nos modèles tinyspec sont transformés en définitions OpenAPI, qui à leur tour correspondent au format de schéma JSON.
Tout objet littéral en JS (ou Hash en Ruby, un dict en Python, un tableau associatif en PHP et même une Map en Java) peut être testé pour la conformité avec un schéma JSON. Et il existe même des plugins correspondants pour tester les frameworks, par exemple jest-ajv (npm), chai-ajv-json-schema (npm) et json_matchers (rubygem) pour RSpec.
Avant d'utiliser les schémas, vous devez les connecter au projet. Tout d'abord, nous allons générer le fichier de spécifications openapi.json basé sur tinyspec (cette action peut être effectuée automatiquement avant chaque exécution de test):
tinyspec -j -o openapi.json
Node.js
Maintenant, nous pouvons utiliser le JSON reçu dans le projet et en extraire la clé de definitions , qui contient tous les schémas JSON. Les schémas peuvent contenir des références croisées ( $ref ), par conséquent, si nous avons des schémas imbriqués (par exemple, Blog {posts: Post[]} ), nous devons les "développer" afin de les utiliser dans les validations. Pour ce faire, nous utiliserons json-schema-deref-sync (npm).
import deref from 'json-schema-deref-sync'; const spec = require('./openapi.json'); const schemas = deref(spec).definitions; describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200);
Ruby on Rails
json_matchers peut gérer les liens $ref , mais nécessite des fichiers séparés avec des schémas dans le système de fichiers d'une certaine manière, donc vous devez d'abord "diviser" swagger.json en plusieurs petits fichiers (plus à ce sujet ici ):
Après cela, nous pouvons écrire notre test comme ceci:
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect(result[:users][0]).to match_json_schema('User') end end
Remarque: l'écriture de tests de cette manière est incroyablement pratique. Surtout si votre IDE prend en charge l'exécution de tests et le débogage (tels que WebStorm, RubyMine et Visual Studio). Ainsi, vous ne pouvez pas utiliser d'autre logiciel du tout, et le cycle de développement complet de l'API est réduit à 3 étapes consécutives:
- conception des spécifications (par exemple dans tinyspec);
- écrire un ensemble complet de tests pour les points d'extrémité ajoutés / modifiés;
- développer du code qui satisfait tous les tests.
2. Validation des entrées
OpenAPI décrit le format non seulement des réponses, mais aussi des données d'entrée. Cela nous permet de valider les données reçues du droit de l'utilisateur lors de la demande.
Supposons que nous ayons la spécification suivante qui décrit la mise à jour des données utilisateur, ainsi que tous les champs qui peuvent être modifiés:
Plus tôt, nous avons examiné les plugins pour la validation dans les tests, mais pour les cas plus généraux, il existe des modules de validation ajv (npm) et json-schema (rubygem), utilisons-les et écrivons un contrôleur avec validation.
Node.js (Koa)
Ceci est un exemple pour Koa , le successeur d'Express, mais pour Express, le code sera similaire.
import Router from 'koa-router'; import Ajv from 'ajv'; import { schemas } from './schemas'; const router = new Router();
Dans cet exemple, si les données d'entrée ne répondent pas à la spécification, le serveur renverra une réponse 500 Internal Server Error au client. Pour éviter que cela ne se produise, nous pouvons intercepter l'erreur du validateur et former notre propre réponse, qui contiendra des informations plus détaillées sur des champs spécifiques qui n'ont pas réussi le test, et également conforme à la spécification .
Ajoutez une description du modèle FieldsValidationError dans le fichier FieldsValidationError :
Error {error: b, message} InvalidField {name, message} FieldsValidationError < Error {fields: InvalidField[]}
Et maintenant, nous l'indiquons comme l'une des réponses possibles de notre point final:
PATCH /users/:id {user: UserUpdate} => 200 {success: b} => 422 FieldsValidationError
Cette approche vous permettra d'écrire des tests unitaires qui vérifient l'exactitude de la formation d'erreurs avec des données incorrectes reçues du client.
3. Sérialisation des modèles
Presque tous les frameworks de serveurs modernes utilisent ORM d'une manière ou d'une autre. Cela signifie que la plupart des ressources utilisées dans l'API à l'intérieur du système sont présentées sous forme de modèles, leurs instances et collections.
Le processus de génération d'une représentation JSON de ces entités pour transmission dans la réponse API est appelé sérialisation . Il existe un certain nombre de plugins pour différents frameworks qui exécutent des fonctions de sérialisation, par exemple: sequelize-to-json (npm), actes_as_api (rubygem), jsonapi-rails (rubygem). En fait, ces plugins permettent à un modèle spécifique de spécifier une liste de champs qui doivent être inclus dans l'objet JSON, ainsi que des règles supplémentaires, par exemple, pour les renommer ou calculer dynamiquement des valeurs.
Les difficultés commencent lorsque nous devons avoir plusieurs représentations JSON différentes du même modèle ou lorsqu'un objet contient des entités imbriquées - des associations. Il existe un besoin d' héritage, de réutilisation et de liaison des sérialiseurs .
Différents modules résolvent ces problèmes de différentes manières, mais réfléchissons, la spécification peut-elle nous aider à nouveau? En effet, en fait, toutes les informations sur les exigences pour les représentations JSON, toutes les combinaisons possibles de champs, y compris les entités imbriquées, s'y trouvent déjà. Nous pouvons donc écrire un sérialiseur automatique.
J'attire votre attention sur un petit module sequelize-serialize (npm), qui vous permet de le faire pour les modèles Sequelize. Il prend une instance du modèle ou d'un tableau, ainsi que le circuit requis, et construit de manière itérative un objet sérialisé, en tenant compte de tous les champs requis et en utilisant des circuits imbriqués pour les entités associées.
Supposons donc que nous ayons besoin de renvoyer de l'API tous les utilisateurs qui ont des articles de blog, y compris des commentaires sur ces articles. Nous décrivons cela en utilisant la spécification suivante:
Nous pouvons maintenant créer la requête à l'aide de Sequelize et renvoyer un objet sérialisé qui correspond exactement à la spécification décrite ci-dessus:
import Router from 'koa-router'; import serialize from 'sequelize-serialize'; import { schemas } from './schemas'; const router = new Router(); router.get('/blog/users', async (ctx) => { const users = await User.findAll({ include: [{ association: User.posts, required: true, include: [Post.comments] }] }); ctx.body = serialize(users, schemas.UserWithPosts); });
C'est presque magique, non?
4. Typage statique
Si vous êtes si cool que vous utilisez TypeScript ou Flow, vous vous êtes peut-être déjà demandé: "Et mes chers types statiques?!" . À l'aide des modules sw2dts ou swagger-to-flowtype, vous pouvez générer toutes les définitions nécessaires basées sur les schémas JSON et les utiliser pour le typage statique des tests, des données d'entrée et des sérialiseurs.
tinyspec -j sw2dts ./swagger.json -o Api.d.ts --namespace Api
Maintenant, nous pouvons utiliser des types dans les contrôleurs:
router.patch('/users/:id', async (ctx) => { // Specify type for request data object const userData: Api.UserUpdate = ctx.request.body.user; // Run spec validation await validate(schemas.UserUpdate, userData); // Query the database const user = await User.findById(ctx.params.id); await user.update(userData); // Return serialized result const serialized: Api.User = serialize(user, schemas.User); ctx.body = { user: serialized }; });
Et dans les tests:
it('Update user', async () => { // Static check for test input data. const updateData: Api.UserUpdate = { name: MODIFIED }; const res = await request.patch('/users/1', { user: updateData }); // Type helper for request response: const user: Api.User = res.body.user; expect(user).to.be.validWithSchema(schemas.User); expect(user).to.containSubset(updateData); });
Veuillez noter que les définitions de type générées peuvent être utilisées non seulement dans le projet API lui-même, mais également dans les projets d'application client pour décrire les types de fonctions dans lesquelles l'API fonctionne. Les développeurs de clients angulaires seront particulièrement satisfaits de ce cadeau.
5. Conversion de type de chaîne de requête
Si, pour une raison quelconque, votre API accepte les demandes avec le type MIME application/x-www-form-urlencoded et non application/json , le corps de la demande ressemblera à ceci:
param1=value¶m2=777¶m3=false
Il en va de même pour les paramètres de requête (par exemple, dans les requêtes GET). Dans ce cas, le serveur Web ne pourra pas reconnaître automatiquement les types - toutes les données seront sous forme de chaînes ( voici une discussion dans le référentiel du module qpm npm), donc après l'analyse, vous obtiendrez l'objet suivant:
{ param1: 'value', param2: '777', param3: 'false' }
Dans ce cas, la demande ne sera pas validée selon le schéma, ce qui signifie qu'il faudra vérifier manuellement que chaque paramètre a le format correct et l'amener au type souhaité.
Comme vous pouvez le deviner, cela peut être fait en utilisant tous les mêmes schémas de notre spécification. Imaginez que nous ayons un tel point final et un tel schéma:
Voici un exemple de demande à un tel point de terminaison
GET /posts?search=needle&offset=10&limit=1&filter[isRead]=true
castQuery une fonction castQuery , qui castQuery tous les paramètres en types nécessaires pour nous. Cela ressemblera à ceci:
function castQuery(query, schema) { _.mapValues(query, (value, key) => { const { type } = schema.properties[key] || {}; if (!value || !type) { return value; } switch (type) { case 'integer': return parseInt(value, 10); case 'number': return parseFloat(value); case 'boolean': return value !== 'false'; default: return value; } }); }
Son implémentation plus complète avec prise en charge des schémas, tableaux et types null imbriqués est disponible en cast-with-schema (npm). Maintenant, nous pouvons l'utiliser dans notre code:
router.get('/posts', async (ctx) => {
Remarquez comment des quatre lignes du code de point de terminaison, les trois schémas d'utilisation de la spécification.
Meilleures pratiques
Schémas distincts pour la création et la modification
En règle générale, les schémas qui décrivent la réponse du serveur sont différents de ceux qui décrivent l'entrée utilisée pour créer et modifier des modèles. Par exemple, la liste des champs disponibles pour les requêtes POST et PATCH doit être strictement limitée, tandis que dans les requêtes PATCH , tous les champs du schéma sont généralement rendus facultatifs. Les schémas qui déterminent la réponse peuvent être plus gratuits.
La génération automatique des points de terminaison tinyspec CRUDL utilise les postfixes New et Update . User* peuvent être définis comme suit:
User {id, email, name, isAdmin: b} UserNew !{email, name} UserUpdate !{email?, name?}
Essayez de ne pas utiliser les mêmes schémas pour différents types d'actions afin d'éviter des problèmes de sécurité accidentels dus à la réutilisation ou à l'héritage d'anciens schémas.
Sémantique dans les noms de schéma
Le contenu des mêmes modèles peut varier selon différents points de terminaison. Utilisez les suffixes With* et For* dans les noms de schéma pour montrer en quoi ils diffèrent et à quoi ils servent. Dans les modèles tinyspec, les modèles peuvent également être hérités les uns des autres. Par exemple:
User {name, surname} UserWithPhotos < User {photos: Photo[]} UserForAdmin < User {id, email, lastLoginAt: d}
Les suffixes peuvent être variés et combinés. L'essentiel est que leur nom reflète l'essence et simplifie la familiarité avec la documentation.
Séparation des points de terminaison par type de client
Souvent, les mêmes points de terminaison renvoient des données différentes en fonction du type de client ou du rôle de l'utilisateur accédant au point de terminaison. Par exemple, les points de terminaison de GET /users et GET /messages peuvent être très différents pour les utilisateurs de votre application mobile et pour les gestionnaires de back-office. Dans le même temps, la modification du nom du point de terminaison lui-même peut être trop compliquée.
Pour décrire plusieurs fois le même point de terminaison, vous pouvez ajouter son type entre crochets après le chemin. De plus, il est utile d'utiliser des balises: cela vous aidera à diviser la documentation de vos points de terminaison en groupes, chacun étant conçu pour un groupe spécifique de clients de votre API. Par exemple:
Mobile app: GET /users (mobile) => UserForMobile[] CRM admin panel: GET /users (admin) => UserForAdmin[]
Documentation de l'API REST
Une fois que vous avez une spécification au format tinyspec ou OpenAPI, vous pouvez générer une belle documentation en HTML et la publier pour le plus grand plaisir des développeurs utilisant votre API.
En plus des services cloud mentionnés précédemment, il existe des outils CLI qui convertissent OpenAPI 2.0 en HTML et PDF, après quoi vous pouvez le télécharger sur n'importe quel hébergement statique. Exemples:
Connaissez-vous plus d'exemples? Partagez-les dans les commentaires.
Malheureusement, OpenAPI 3.0, sorti il y a un an, est toujours mal pris en charge, et je n'ai trouvé aucun exemple de documentation digne de ce nom: ni parmi les solutions cloud, ni parmi les outils CLI. Pour la même raison, OpenAPI 3.0 n'est pas encore pris en charge dans tinyspec.
Publier sur GitHub
L'une des façons les plus simples de publier de la documentation est GitHub Pages . Activez simplement la prise en charge des pages statiques pour le répertoire /docs dans les paramètres de votre référentiel et stockez la documentation HTML dans ce dossier.
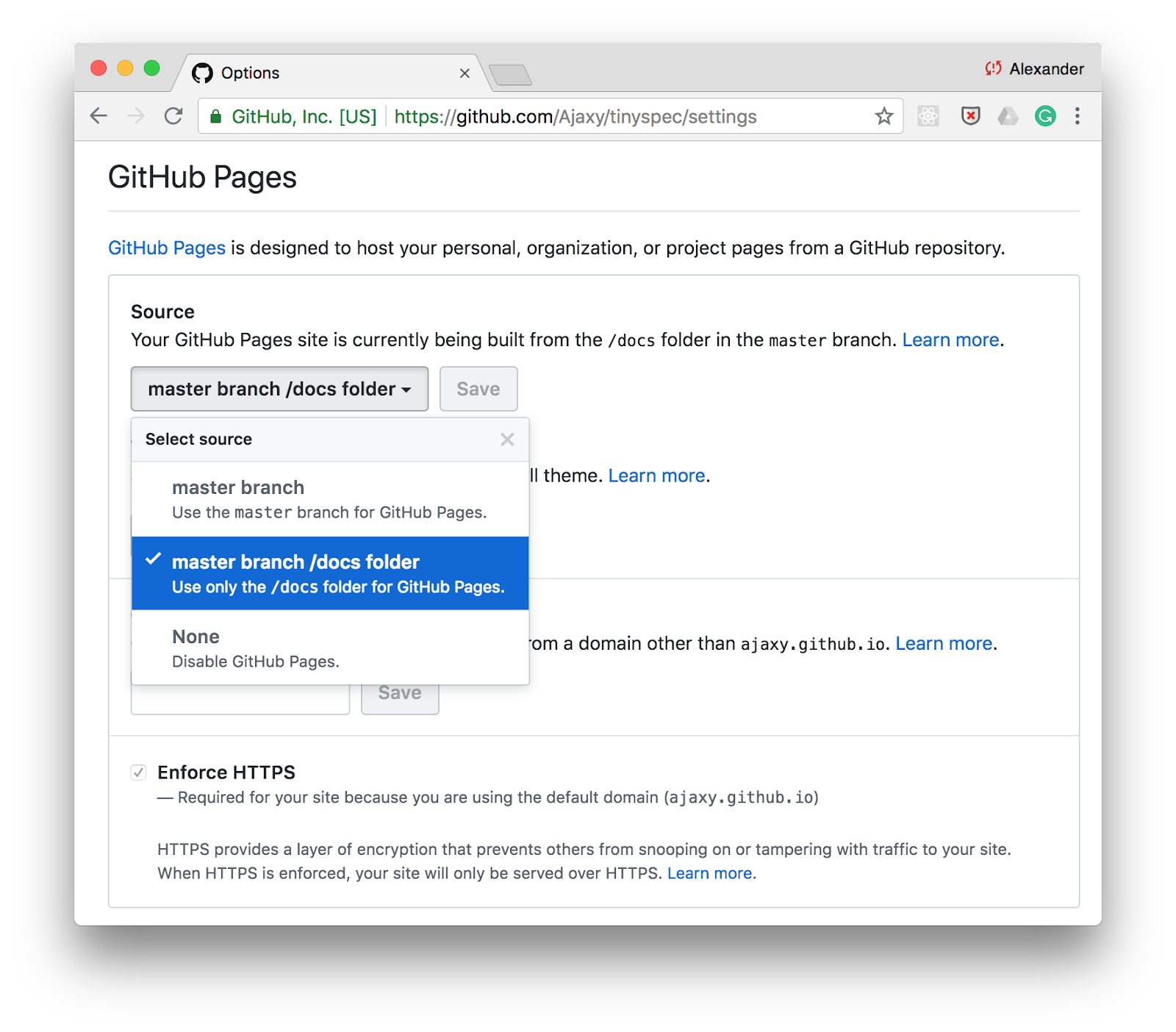
Vous pouvez ajouter une commande pour générer de la documentation via tinyspec ou un autre outil CLI dans les scripts dans package.json et mettre à jour la documentation avec chaque commit:
"scripts": { "docs": "tinyspec -h -o docs/", "precommit": "npm run docs" }
Intégration continue
Vous pouvez inclure la génération de documentation dans le cycle CI et la publier, par exemple, dans Amazon S3 sous différentes adresses en fonction de l'environnement ou de la version de votre API, par exemple: /docs/2.0 , /docs/stable , /docs/staging .
Nuage de Tinyspec
Si vous avez aimé la syntaxe tinyspec, vous pouvez vous inscrire en tant que premier adoptant sur tinyspec.cloud . Nous allons construire sur sa base un service cloud et CLI pour la publication automatique de la documentation avec une large sélection de modèles et la possibilité de développer nos propres modèles.
Conclusion
Développer une API REST est peut-être l'activité la plus agréable de toutes celles qui existent dans le processus de travail sur les services Web et mobiles modernes. Il n'y a pas de zoo de navigateurs, de systèmes d'exploitation et de tailles d'écran, tout est entièrement sous notre contrôle - «à portée de main».
Le maintien des spécifications actuelles et des bonus sous la forme de diverses automatisations, qui sont fournies en même temps, rendent ce processus encore plus agréable. Une telle API devient structurée, transparente et fiable.
En effet, en fait, même si nous sommes engagés dans la création d'un mythe, alors pourquoi ne le rendons-nous pas beau?